opencv图像算法
图像的对比度增强
一: 绘制直方图
就是把各个像素值所含有的个数统计出来,然后画图表示。 可以看到在当前图像中,哪个像素值的个数最多。 同时,可以看当前图像总体的像素值大小在哪些范围。。靠近0的话,说明图像偏暗。 靠近255,说明图像偏亮
import cv2
import numpy as np
import matplotlib.pyplot as plt
import math
# # 绘制灰度直方图
def calcGrayHist(image):
'''
统计像素值
:param image:
:return:
'''
# 灰度图像的高,宽
rows, cols = image.shape
# 存储灰度直方图
grayHist = np.zeros([256], np.uint64)
for r in range(rows):
for c in range(cols):
grayHist[image[r][c]] += 1
return grayHist
image = cv2.imread('p2.jpg', cv2.IMREAD_GRAYSCALE)
grayHist = calcGrayHist(image)
# 采用matplotlib进行画图
x_range = range(256)
plt.plot(x_range, grayHist, 'r', linewidth=2, c='black')
plt.show()
输出结果:

总的来说,还是偏暗 。像素值几种在40到50之间。
二:通过线性变化增强对比度

# 通过线性变化增强对比度
in_image =cv2.imread('p2.jpg', cv2.IMREAD_GRAYSCALE)
a = 2
out_image = float(a) * in_image
# 进行数据截断, 大于255的值要截断为255
out_image[out_image > 255] = 255
# 数据类型转化
out_image = np.round(out_image)
out_image = out_image.astype(np.uint8)
# 显示原图像和线性变化后的结果
cv2.imshow('IN', in_image)
cv2.imshow('OUT', out_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出结果:

三: 通过直方图正规化增强对比度

python代码
# 通过直方图正规化增强对比度
in_image = cv2.imread('p2.jpg', cv2.IMREAD_GRAYSCALE)
# 求输入图片像素最大值和最小值
Imax = np.max(in_image)
Imin = np.min(in_image)
# 要输出的最小灰度级和最大灰度级
Omin, Omax = 0, 255
# 计算a 和 b的值
a = float(Omax - Omin)/(Imax - Imin)
b = Omin - a* Imin
# 矩阵的线性变化
out_image = a*in_image + b
# 数据类型的转化
out_image = out_image.astype(np.uint8)
# 显示原图和直方图正规化的效果
cv2.imshow('IN', in_image)
cv2.imshow('OUT', out_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
结果
四: 伽马变化

python代码
# 伽马变换增强对比度
in_image = cv2.imread('p2.jpg', cv2.IMREAD_GRAYSCALE)
# 图像归一化
fI = in_image/255.0
# 伽马变化
gamma = 0.5
out_image = np.power(fI, gamma)
# 显示原图和伽马变化后的效果
cv2.imshow('IN', in_image)
cv2.imshow('OUT', out_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
结果
五:全局直方图均衡化



python实现
def calcGrayHist(image):
'''
统计像素值
:param image:
:return:
'''
# 灰度图像的高,宽
rows, cols = image.shape
# 存储灰度直方图
grayHist = np.zeros([256], np.uint64)
for r in range(rows):
for c in range(cols):
grayHist[image[r][c]] += 1
return grayHist
# 全局直方图均衡化
def equalHist(image):
# 灰度图像矩阵的高,宽
rows, cols = image.shape
# 第一步:计算灰度直方图
grayHist = calcGrayHist(image)
# 第二步:计算累加灰度直方图
zeroCumuMoment = np.zeros([256], np.uint32)
for p in range(256):
if p == 0:
zeroCumuMoment[0] = grayHist[0]
else:
zeroCumuMoment[p] = zeroCumuMoment[p-1]+grayHist[p]
# 第三步:根据累加灰度直方图得到输入灰度级和输出灰度级之间的映射关系
output_q = np.zeros([256], np.uint8)
cofficient = 256.0 / (rows*cols)
for p in range(256):
q = cofficient * float(zeroCumuMoment[p]) - 1
if q >= 0:
output_q[p] = math.floor(q)
else:
output_q[p] = 0
# 第四步:得到直方图均衡化后的图像
equalHistImage = np.zeros(image.shape, np.uint8)
for r in range(rows):
for c in range(cols):
equalHistImage[r][c] = output_q[image[r][c]]
return equalHistImage
image = cv2.imread('p2.jpg', cv2.IMREAD_GRAYSCALE)
grayHist = equalHist(image)
cv2.imshow('origin_image', image)
cv2.imshow('equal_image', grayHist)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出结果:
六: 限制对比度的自适应直方图均衡化

Python代码:
# 限制对比度的自适应直方图均衡化
image = cv2.imread('p2.jpg', cv2.IMREAD_GRAYSCALE)
# 创建ClAHE对象
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
# 限制对比度的自适应阈值均衡化
dst = clahe.apply(image)
# 显示
cv2.imshow('src', image)
cv2.imshow('dst', dst)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出结果:
七:Retinex 增强算法(SSR、MSR、MSRCR)
视网膜-大脑皮层(Retinex)理论认为世界是无色的,人眼看到的世界是光与物质相互作用的结果,也就是说,映射到人眼中的图像和光的长波(R)、中波(G)、短波(B)以及物体的反射性质有关

其中I是人眼中看到的图像,R是物体的反射分量,L是环境光照射分量,(x, y)是二维图像对应的位置
基于上面的原理,看下Retinex常见的几种增强算法
1. SSR(Single Scale Retinex)单尺度Retinex算法
它通过估算L来计算R,具体来说,L可以通过高斯模糊和I做卷积运算求得,用公式表示为:

其中F是高斯模糊的滤波器,“ * ”表示卷积运算

其中σ称为高斯周围空间常数(Gaussian Surround Space Constant),也就是算法中所谓的尺度,对图像处理有比较大的影响,对于二维图像对应于图像中位置,即:
因此,这个算法的思路就可以归结为以下几步:
1、输入: 原始图像数据I(x,y),尺度(也就是高斯函数中的σ)
2、①计算原始图像按指定尺度进行模糊后的图像 L(x,y);
②按照log®=log(I)-log(L)公式的计算方法计算出 Log[R(x,y)]的值
③将 Log[R(x,y)]量化为0到255范围的像素值,作为最终的输出,量化公式:R(x,y) = ( Value - Min ) / (Max - Min) * (255-0)(注:无需将Log[R(x,y)]进行Exp函数的运算,而是直接利用Log[R(x,y)]进行量化,即上述公式中的value值)

效果图(左边是原图,右边是SSR效果图):(其中σ=300,即代码中的sigma=300)


2. MSR(Multi-Scale Retinex)多尺度Retinex算法
多尺度视网膜增强算法(MSR, Multi-Scale Retinex),最为经典的就是3尺度的,大、中、小,既能实现图像动态范围的压缩,又能保持色感的一致性较好。基于单尺度Retinex算法,多尺度Retinex算法描述如下:
1、需要对原始图像进行每个尺度的高斯模糊,得到模糊后的图像Li(x,y),其中小标i表示尺度数。
2、对每个尺度下进行累加计算 Log[R(x,y)] = Log[R(x,y)] + Weight(i)* ( Log[Ii(x,y)]-Log[Li(x,y)]); 其中Weight(i)表示每个尺度对应的权重,要求各尺度权重之和必须为1,经典的取值为等权重。
如果尺度数为3,则:W1=W2=W3=1/3
代码如下:

效果图(左边是原图,中间是SSR效果图,右边是MSR效果图)



3. MSRCR(Multi-Scale Retinex with Color Restoration)具有色彩恢复的多尺度Retinex算法
在前面的增强过程中,图像可能会因为增加了噪声,而使得图像的局部细节色彩失真,不能显现出物体的真正颜色,整体视觉效果变差。针对这一点不足,MSRCR在MSR的基础上,加入了色彩恢复因子C来调节由于图像局部区域对比度增强而导致颜色失真的缺陷.
先看一组公式:
RMSRCR(x,y)'=G⋅RMSRCR(x,y)+b
RMSRCR (x,y)=C(x,y)RMSR(x,y)
C(x,y)=f[I’(x,y)]=f[I(x,y)/∑I(x,y)]Ci(x,y)=f[Ii′(x,y)]=f[Ii(x,y)∑j=1NIj(x,y)]
f[I’(x,y)]=βlog[αI’(x,y)]=β{log[αI’(x,y)]−log[∑I(x,y)]}
如果是灰度图像,只需要计算一次即可,如果是彩色图像,如RGB三通道,则每个通道均需要如上进行计算
G表示增益Gain(一般取值:5)
b表示偏差Offset(一般取值:25)
I (x, y)表示某个通道的图像
C表示某个通道的彩色回复因子,用来调节3个通道颜色的比例;
f(·)表示颜色空间的映射函数;
β是增益常数(一般取值:46);
α是受控制的非线性强度(一般取值:125)
MSRCR算法利用彩色恢复因子C,调节原始图像中3个颜色通道之间的比例关系,从而把相对较暗区域的信息凸显出来,达到了消除图像色彩失真的缺陷。 处理后的图像局部对比度提高,亮度与真实场景相似,在人们视觉感知下,图像显得更加逼真;但是MSRCR算法处理图像后,像素值一般会出现负值。所以从对数域r(x, y)转换为实数域R(x, y)后,需要通过改变增益Gain,偏差Offset对图像进行修正。
另外:介绍下什么是颜色的简单白平衡(simplest Color Balance)
白平衡的意思就是:是图片中最亮的部分为白色,最暗的部分为黑色。其余部分进行拉伸
简单的说就是:在RGB三通道上分别统计每个像素值的出现次数。将1%的最大值和最小值设置为255和0。其余值映射到(0,255),这样使得每个值通道的值在RGB中分布较均匀。达到颜色平衡的结果
MSRCR代码如下:

效果图(左上:原图,右上:SSR,左下:MSR,右下:MSRCR)


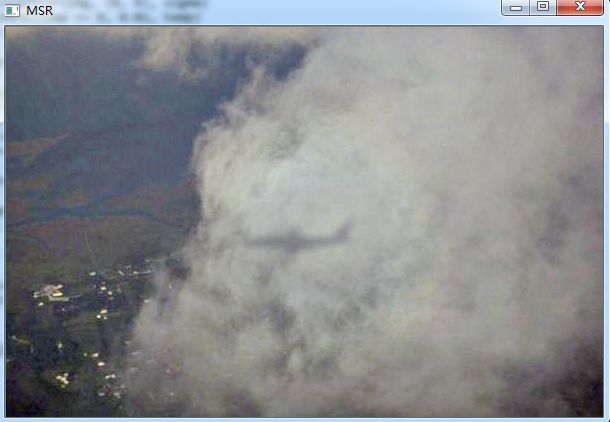

以上算法基于图片的去雾化处理
python代码经供参考
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 直方图均衡增强
def hist(image):
r, g, b = cv2.split(image)
r1 = cv2.equalizeHist(r)
g1 = cv2.equalizeHist(g)
b1 = cv2.equalizeHist(b)
image_equal_clo = cv2.merge([r1, g1, b1])
return image_equal_clo
# 拉普拉斯算子
def laplacian(image):
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]])
image_lap = cv2.filter2D(image, cv2.CV_8UC3, kernel)
# cv2.imwrite('th1.jpg', image_lap)
return image_lap
# 对数变换
def log(image):
image_log = np.uint8(np.log(np.array(image) + 1))
cv2.normalize(image_log, image_log, 0, 255, cv2.NORM_MINMAX)
# 转换成8bit图像显示
cv2.convertScaleAbs(image_log, image_log)
return image_log
# 伽马变换
def gamma(image):
fgamma = 2
image_gamma = np.uint8(np.power((np.array(image) / 255.0), fgamma) * 255.0)
cv2.normalize(image_gamma, image_gamma, 0, 255, cv2.NORM_MINMAX)
cv2.convertScaleAbs(image_gamma, image_gamma)
return image_gamma
# 限制对比度自适应直方图均衡化CLAHE
def clahe(image):
b, g, r = cv2.split(image)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
b = clahe.apply(b)
g = clahe.apply(g)
r = clahe.apply(r)
image_clahe = cv2.merge([b, g, r])
return image_clahe
def replaceZeroes(data):
min_nonzero = min(data[np.nonzero(data)])
data[data == 0] = min_nonzero
return data
# retinex SSR
def SSR(src_img, size):
L_blur = cv2.GaussianBlur(src_img, (size, size), 0)
img = replaceZeroes(src_img)
L_blur = replaceZeroes(L_blur)
dst_Img = cv2.log(img/255.0)
dst_Lblur = cv2.log(L_blur/255.0)
dst_IxL = cv2.multiply(dst_Img, dst_Lblur)
log_R = cv2.subtract(dst_Img, dst_IxL)
dst_R = cv2.normalize(log_R,None, 0, 255, cv2.NORM_MINMAX)
log_uint8 = cv2.convertScaleAbs(dst_R)
return log_uint8
def SSR_image(image):
size = 3
b_gray, g_gray, r_gray = cv2.split(image)
b_gray = SSR(b_gray, size)
g_gray = SSR(g_gray, size)
r_gray = SSR(r_gray, size)
result = cv2.merge([b_gray, g_gray, r_gray])
return result
# retinex MMR
def MSR(img, scales):
weight = 1 / 3.0
scales_size = len(scales)
h, w = img.shape[:2]
log_R = np.zeros((h, w), dtype=np.float32)
for i in range(scales_size):
img = replaceZeroes(img)
L_blur = cv2.GaussianBlur(img, (scales[i], scales[i]), 0)
L_blur = replaceZeroes(L_blur)
dst_Img = cv2.log(img/255.0)
dst_Lblur = cv2.log(L_blur/255.0)
dst_Ixl = cv2.multiply(dst_Img, dst_Lblur)
log_R += weight * cv2.subtract(dst_Img, dst_Ixl)
dst_R = cv2.normalize(log_R,None, 0, 255, cv2.NORM_MINMAX)
log_uint8 = cv2.convertScaleAbs(dst_R)
return log_uint8
def MSR_image(image):
scales = [15, 101, 301] # [3,5,9]
b_gray, g_gray, r_gray = cv2.split(image)
b_gray = MSR(b_gray, scales)
g_gray = MSR(g_gray, scales)
r_gray = MSR(r_gray, scales)
result = cv2.merge([b_gray, g_gray, r_gray])
return result
if __name__ == "__main__":
image = cv2.imread('img/FJ(93).png')
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
plt.subplot(4, 2, 1)
plt.imshow(image)
plt.axis('off')
plt.title('Offical')
# 直方图均衡增强
image_equal_clo = hist(image)
plt.subplot(4, 2, 2)
plt.imshow(image_equal_clo)
plt.axis('off')
plt.title('equal_enhance')
# 拉普拉斯算法增强
image_lap = laplacian(image)
plt.subplot(4, 2, 3)
plt.imshow(image_lap)
plt.axis('off')
plt.title('laplacian_enhance')
# LoG对象算法增强
image_log = log(image)
plt.subplot(4, 2, 4)
plt.imshow(image_log)
plt.axis('off')
plt.title('log_enhance')
# # 伽马变换
image_gamma = gamma(image)
plt.subplot(4, 2, 5)
plt.imshow(image_gamma)
plt.axis('off')
plt.title('gamma_enhance')
# CLAHE
image_clahe = clahe(image)
plt.subplot(4, 2, 6)
plt.imshow(image_clahe)
plt.axis('off')
plt.title('CLAHE')
# retinex_ssr
image_ssr = SSR_image(image)
plt.subplot(4, 2, 7)
plt.imshow(image_ssr)
plt.axis('off')
plt.title('SSR')
# retinex_msr
image_msr = MSR_image(image)
plt.subplot(4, 2, 8)
plt.imshow(image_msr)
plt.axis('off')
plt.title('MSR')
plt.show()
自适应降噪
图像的实质是一种二维信号,滤波是信号处理中的一个重要概念。在图像处理中,滤波是一常见的技术,它们的原理非常简单,但是其思想却十分值得借鉴,滤波是很多图像算法的前置步骤或基础,掌握图像滤波对理解卷积神经网络也有一定帮助。
学习目标:
了解图像滤波的分类和基本概念
理解几种图像滤波的原理
掌握OpenCV框架下滤波API的使用
理论介绍
滤波器分类
线性滤波:对邻域中的像素的计算为线性运算时,如利用窗口函数进行平滑加权求和的运算,或者某种卷积运算,都可以称为线性滤波。常见的线性滤波有:方框滤波、均值滤波、高斯滤波、拉普拉斯滤波等等,通常线性滤波器之间只是模版的系数不同。
非线性滤波:非线性滤波利用原始图像跟模版之间的一种逻辑关系得到结果,如最值滤波器,中值滤波器。比较常用的有中值滤波器和双边滤波器。
卷积核
数字图像是一个二维的数组,对数字图像做卷积操作其实就是利用卷积核在图像上滑动,将图像点上的像素值与对应的卷积核上的数值相乘,然后将所有相乘后的值相加作为卷积核中间像素点的像素值,并最终滑动完所有图像的过程。
通常,卷积核的宽度和高度一般是奇数,这样才有中心的像素点,所以卷积核一般都是3x3,5x5或者7x7等。 n × n n×n n×n的卷积核的半径为 ( n − 1 ) / 2 (n-1)/2 (n−1)/2,例如5x5大小的卷积核的半径就是2。
两种常见噪声
函数介绍:python中的skimage图像处理模块,该函数可以方便的为图像添加各种类型的噪声。
skimage.util.random_noise(image, mode, seed=None, clip=True, **kwargs)
参数:
image 为输入图像数据,类型为ndarray,输入后将转换为float64格式。
mode 选择添加噪声的类别。字符串str类型。
'gaussian' 高斯加性噪声
'poisson' 泊松分布的噪声
'salt' 盐噪声,随机用1替换像素。属于高灰度噪声。
'peppe' 胡椒噪声,随机用0或-1替换像素。属于低灰度噪声。
's&p' 椒盐噪声,盐噪声和胡椒噪声同时出现,呈现出黑白杂点。
'localvar' 高斯加性噪声,每点具有特定的局部方差。
'speckle' 使用 out = image + n *image 的乘法噪声,其中n是具有指定均值和方差的均匀噪声。
seed int类型。将在生成噪声之前设置随机种子,以进行有效的伪随机比较。
clip bool类型。若为True则在加入噪声后进行剪切以保证图像数据点都在[0,1]或[-1.1]之间。若为False,则数据可能超出这个范围。
1、椒盐噪声(脉冲噪声)
椒盐噪声也称为脉冲噪声,是图像中常常见到的一种噪声,它是一种随机出现的白点或者黑点,可能是亮的区域有黑色像素或是在暗的区域有白色像素(或是两者皆有)。产生具有椒盐噪声的图像:(python)
from skimage import util
import cv2
if __name__ == "__main__":
img = cv2.imread("D:\\yt\\pictures2\\wink.jpg")
#产生椒盐噪声,处理后图像变为float64格式
noise_sp_img = util.random_noise(img, mode="s&p")
#显示图像
cv2.imshow("origin image",img)
cv2.imshow("sp noise",noise_sp_img)
#将图像转换为uint8格式,否则保存后是全黑的。
noise_sp_img = cv2.normalize(noise_sp_img, None, 0, 255, cv2.NORM_MINMAX, cv2.CV_8U)
#储存图像
cv2.imwrite("D:\\yt\\pictures2\\sp_noise.jpg",noise_sp_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果:左边为原图,右边加入了椒盐噪声

2、高斯噪声
高斯噪声是指它的概率密度函数服从高斯分布(即正态分布)的一类噪声。如果一个噪声,它的幅度分布服从高斯分布,而它的功率谱密度又是均匀分布的,则称它为高斯白噪声。
高斯白噪声的二阶矩不相关,一阶矩为常数,是指先后信号在时间上的相关性。高斯噪声是与光强没有关系的噪声,无论像素值是多少,噪声的平均水平(一般是0)不变。产生具有高斯噪声的图像:(python)
from skimage import util
import cv2
if __name__ == "__main__":
img = cv2.imread("D:\\yt\\pictures2\\wink.jpg")
#产生高斯噪声,处理后图像变为float64格式
noise_gs_img = util.random_noise(img, mode="gaussian")
#显示图像
cv2.imshow("origin image",img)
cv2.imshow("gaussian noise",noise_gs_img
#将图像转换为uint8格式,否则保存后是全黑的。
noise_gs_img = cv2.normalize(noise_gs_img, None, 0, 255, cv2.NORM_MINMAX, cv2.CV_8U)
#储存图像
cv2.imwrite("D:\\yt\\pictures2\\gs_noise.jpg",noise_gs_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果:左边为原图,右边加入了高斯噪声

几种图像滤波
1、方框(盒子)滤波
方框滤波是一种非常有用的线性滤波,也叫盒子滤波。
积分图:图像积分图中每个点的值是原图像中该点左上角的所有像素值之和。建立一个数组作为积分图像,其宽度和高度与原图像相等.,然后对这个数组赋值,每个点存储的是原图像中该点左上角的所有像素值之和。
对一个灰度图而言,事先将其积分图构建好,当需要计算灰度图某个区域内所有像素点的像素值之和的时候,都可以通过查表的方法和有限次简单运算,迅速得到结果。
优势:它可以使复杂度为O(MN)的求和,求方差等运算降低到O(1)或近似于O(1)的复杂度,也就是说与邻域尺寸无关了,有点类似积分图,但是比积分图更快(与它的实现方式有关)。
方框滤波采用下面的卷积核与图像进行卷积:

应用:
可以说,一切需要求某个邻域内像素之和的场合,都有方框滤波的用武之地,比如:均值滤波、引导滤波、计算Haar特征等等。方框滤波还可以用来计算每个像素邻域上的各种积分特性,方差、协方差,平方和等等。
2、均值滤波
均值滤波就是方框滤波归一化的特殊情况。使卷积核所有的元素之和等于1。卷积核如下:

α为卷积核中点的个数。
均值滤波是方框滤波的特殊情况,均值滤波方法是:对要处理的像素,选择一个模板,该模板由其邻域内的若干个像素组成,用模板的均值来替代原像素的值。可见,归一化了就是均值滤波;不归一化则是方框滤波。
均值滤波的缺点:
均值滤波本身存在着固有的缺陷,即它不能很好地保护图像细节,在图像去噪的同时也破坏了图像的细节部分,从而使图像变得模糊,不能很好地去除噪声点。特别是椒盐噪声。
利用均值滤波处理图像:

应用:
均值模糊可以模糊图像以便得到感兴趣物体的粗略描述,也就是说,去除图像中的不相关细节,其中“不相关”是指与滤波器模板尺寸相比较小的像素区域,从而对图像有一个整体的认知。即为了对感兴趣的物体得到一个大致的整体的描述而模糊一幅图像,忽略细小的细节。
3. 高斯滤波
在进行均值滤波和方框滤波时。其邻域内每个像素的权重是相等的。在高斯滤波中,会将中心点的权重值加大,原理中心点的权重值减小,在此基础上计算邻域内各个像素值不同权重的和。
在高斯滤波中,核的宽度和高度可以不相同,但是它们都必须是奇数。
在实际应用中,卷积核都会经过归一化,归一化后可以表示为小数形式或分数形式。没有进行归一化的卷积核进行滤波,结果往往是错误的。
高斯滤波和均值滤波一样,都是利用一个掩膜和图像进行卷积求解。不同之处在于:均值滤波器的模板系数都是相同的为1,而高斯滤波器的模板系数,则随着距离模板中心的增大而系数减小(服从二维高斯分布)。所以,高斯滤波器相比于均值滤波器对图像的模糊程度较小,更能够保持图像的整体细节。
高斯滤波卷积核:
先介绍一下二维高斯分布:

首先我们要确定卷积核的尺寸ksize,然后设定高斯分布的标准差。生成的过程,首先根据模板的大小,找到模板的中心位置。 然后遍历,将模板中每个坐标带入高斯分布的函数,计算每个位置的系数。
具体过程如下:
不必纠结于系数,因为它只是一个常数,并不会影响互相之间的比例关系,并且最终都要进行归一化,所以在实际计算时我们忽略它而只计算后半部分。
根据二维高斯分布公式,其中为卷积核内任一点的坐标,为卷积核中心点的坐标,通常为;σ是标准差。
例如:要产生一个3×3的高斯滤波器模板,以模板的中心位置为坐标原点。模板中各个位置的坐标,如下图所示。

这时,高斯分布的函数可以改为:

然后,将各个位置的坐标带入到高斯函数中,得到的值就是模板的系数。
通常模板有两种形式:小数形式和整数形式。
小数形式:模板的每个系数除以所有系数的和。就得到了归一化后的模板,通常为小数形式。
整数形式:处理方式为,将小数模板左上角的值归一化为1,其他每个系数都除以左上角原来的系数,然后四舍五入取整。使用整数的模板时,需要在模板的前面加一个系数,系数为模板系数和的倒数。
不难发现,高斯滤波器模板的生成最重要的参数就是高斯分布的标准差σ。标准差代表着数据的离散程度,如果σ较小,那么生成的模板的中心系数较大,而周围的系数较小,这样对图像的平滑效果就不是很明显;反之,σ较大,则生成的模板的各个系数相差就不是很大,比较类似均值模板,对图像的平滑效果比较明显。
一维高斯分布的概率分布密度图:图中,紫色的σ较小,青色的σ较大。

利用高斯滤波处理图像:

应用: 高斯滤波是一种线性平滑滤波器,对于服从正态分布的噪声有很好的抑制作用。在实际场景中,我们通常会假定图像包含的噪声为高斯白噪声,所以在许多实际应用的预处理部分,都会采用高斯滤波抑制噪声,如传统车牌识别等。
中值滤波
中值滤波不再采用加权求和的方式计算滤波结果,它用邻域内所有像素值的中间值来代替当前像素点的像素值。
中值滤波会取当前像素点及其周围临近像素点的像素值,一般有奇数个像素点,将这些像素值排序,将排序后位于中间位置的像素值作为当前像素点的像素值。
中值滤波对于斑点噪声(speckle noise)和椒盐噪声(salt-and-pepper noise)来说尤其有用,因为它不依赖于邻域内那些与典型值差别很大的值,而且噪声成分很难被选上,所以可以在几乎不影响原有图像的情况下去除全部噪声。但是由于需要进行排序操作,中值滤波的计算量较大。
中值滤波器在处理连续图像窗函数时与线性滤波器的工作方式类似,但滤波过程却不再是加权运算。
如下图:滤波核大小为3,邻域内的像素值排序后为[56,66,90,91,93,94,95,97,101],中值为93,所以用93替换中心点原来的像素值56。

双边滤波
双边滤波是综合考虑空间信息和色彩信息的滤波方式,在滤波过程中能有效的保护图像内的边缘信息。
双边滤波在计算某一个像素点的像素值时,同时考虑距离信息(距离越远,权重越小)和色彩信息(色彩差别越大,权重越小)。既能去除噪声,又能较好的保护边缘信息。
如下图:左边为原图,中间为均值滤波可能的结果,右边为双边滤波的结果

-
在双边滤波中,计算左侧白色区域的滤波结果时:
-
对于白色的点,权重较大
-
对于黑色的点,与白色的色彩差别较大(0和255),所以可以将他们的权重设置为0。
-
计算右侧黑色区域的滤波结果时:
-
对于黑色的点,权重较大
-
对于白色的点,与黑色的色彩差别较大(255和0),所以可以将他们的权重设置为0。
这样,左侧白色的滤波结果仍是白色,黑色的像素点权重为0,对它不会有影响;右侧黑色的滤波结果仍是黑色,白色的像素点权重为0,对它不会有影响。所以,双边滤波会将边缘信息保留。
边界处理
对于图像的边界点,不存在n×n的邻域区域,例如左上角第一行第一列的像素点,如果以其为中心取3×3的领域,则部分区域位于图像外部,图像外部是没有像素点和像素值的,所以无法计算像素和。在实际处理过程中需要对图像边界进行扩充,如下图。

扩充后的点需要填充像素值,常见的几种方式:
-
BORDER_DEFAULT:以边界像素点为轴,填充对称的像素点处的像素值。也是OpenCV的默认方式。
-
BORDER_CONSTANT:使用常数填充,可以是0或其他常数。
-
BORDER_REPLICATE:复制最近的一行或一列像素并一直延伸至添加边缘的宽度或高度;
-
BORDER_REFLECT:以边界为轴,填充对称的像素点处的像素值。
-
BORDER_WRAP:将对面的像素进行映射。
为了更直观的体现填充情况,这里设卷积核为5×5的,填充情况如下:



#### 基于OpenCV的实现
1、方框滤波 (c++)
void boxFilter( InputArray src, OutputArray dst,
int ddepth,
Size ksize,
Point anchor = Point(-1,-1),
bool normalize = true,
int borderType = BORDER_DEFAULT );
参数:
src 输入图像
dst 输出图像,和输入图像有相同尺寸和类型
ddepth 输出图像的深度,-1代表使用原图深度
ksize 滤波核的大小,一般写成Size(w,h),w表示宽度,h表示高度。Size(3,3)就表示3x3的核大小,Size(5,5)就表示5x5的核大小
anchor 表示锚点(即被平滑的那个点),默认值为Point(-1,-1),表示当前计算的点位于核中心的位置。如果这个点坐标是负值,就表示取核的中心为锚点。在特殊情况下可以指定不同的点作为锚点
normalize – 表示在滤波时是否进行归一化。
当normalize=1或true时,表示要进行归一化处理;计算的就是均值滤波。
当normalize=0或false时,表示不进行归一化处理。
borderType – 边界样式,决定了以何种方式处理边界,一般采用默认值即可。
关于是否归一化:

如果没有进行归一化处理,邻域内的像素值和基本都会超过像素的最大值255,最后得到的图像接近纯白色,部分点处有颜色。有颜色的点是因为这些点周围邻域的像素值均较小,相加后仍小于255。如下图

2、均值滤波 (c++)
void blur( InputArray src,
OutputArray dst,
Size ksize,
Point anchor = Point(-1,-1),
int borderType = BORDER_DEFAULT);
参数:
src 输入图像
dst 输出图像,和输入图像有相同尺寸和类型
ddepth 输出图像的深度,-1代表使用原图深度
ksize 滤波核的大小,一般写成Size(w,h),w表示宽度,h表示高度。Size(3,3)就表示3x3的核大小,Size(5,5)就表示5x5的核大小
anchor 表示锚点(即被平滑的那个点),默认值为Point(-1,-1),表示当前计算的点位于核中心的位置。如果这个点坐标是负值,就表示取核的中心为锚点。在特殊情况下可以指定不同的点作为锚点
borderType – 边界样式,决定了以何种方式处理边界,一般采用默认值即可。
3、高斯滤波 (c++)
void GaussianBlur(InputArray src, OutputArray dst,
Size ksize,
double sigmaX, double sigmaY=0,
int borderType=BORDER_DEFAULT )
参数:
src 输入图像
dst 输出图像,和输入图像有相同尺寸和类型
ddepth 输出图像的深度,-1代表使用原图深度
ksize 滤波核的大小,一般写成Size(w,h),w表示宽度,h表示高度。Size(3,3)就表示3x3的核大小,Size(5,5)就表示5x5的核大小
sigmaX 表示卷积核在X方向的的标准偏差。
sigmaY 表示卷积核在Y方向的的标准偏差。若sigmaY为零,就将它设为sigmaX,如果sigmaX和sigmaY都是0,那么就由ksize.width和ksize.height计算出来。
sigmaX=0.3×[(ksize.width-1)×0.5-1]+0.8
sigmaY=0.3×[(ksize.height-1)×0.5-1]+0.8
borderType – 边界样式,决定了以何种方式处理边界,一般采用默认值即可。
4、中值滤波
void medianBlur(InputArray src, OutputArray dst, int ksize);
参数:
src 输入图像
dst 输出图像,和输入图像有相同尺寸和类型
ksize 滤波核的大小,注意这里是int形式的ksize,输入一个整数即可,3就表示3x3的核大小,5就表示5x5的核大小
5、双边滤波
void bilateralFilter(InputArray src, OutputArray dst,
int d,
double sigmaColor, double sigmaSpace,
int borderType=BORDER_DEFAULT )
参数:
src 输入图像
dst 输出图像,和输入图像有相同尺寸和类型
d 滤波时选取的空间距离参数,这里表示以当前像素点为中心点的直径。如果d为非正数,自动从sigmaSpace计算得到。如果滤波空间较大,速度会较慢。实际应用中,推荐d=5。
sigmaColor 滤波时选取的颜色范围,该值决定了哪些像素点可以参与到滤波中。该值为0时,滤波失去意义;该值为255时,指定直径内的所有点都能参与运算。
sigmaSpace 表示滤波时选取的颜色范围。它的值越大,有越多的点能够参与到滤波计算中。当d>0时,无论sigmaSpace的值为多少,d都指定邻域大小。否则,d与sigmaSpace与成比例。
borderType – 边界样式,决定了以何种方式处理边界,一般采用默认值即可。
c++代码实现
1、方框滤波、均值滤波、高斯滤波
#include
#include
#include
using namespace cv;
using namespace std;
int main()
{
//载入图像
Mat img1 = imread("D:\\yt\\picture\\blur\\gs_noise5.jpg");
Mat dst1,dst2,dst3,dst4;
//方框滤波
boxFilter(img1, dst1, -1, Size(5, 5), Point(-1, -1), true, BORDER_CONSTANT);
//均值滤波
blur(img1, dst2, Size(5, 5));
//高斯滤波
GaussianBlur(img3, dst4, Size(5, 5), 0.8);
//显示图像
imshow("方框滤波效果图", dst1);
imshow("均值滤波效果图", dst2);
imshow("高斯滤波效果图", dst3);
//储存图像
imwrite("D:\\yt\\picture\\blur\\boxFilter_jay.jpg", dst1);
imwrite("D:\\yt\\picture\\blur\\blur_jay.jpg", dst2);
imwrite("D:\\yt\\picture\\blur\\gs_blur_jay.jpg", dst3);
waitKey(0);
return 0;
}
效果:可以看出,均值滤波与方框滤波归一化后的结果是一样的
2、中值滤波
#include
#include
#include
using namespace cv;
using namespace std;
int main()
{
//载入图像
Mat img1 = imread("D:\\yt\\picture\\blur\\sp_noise5.jpg");
Mat dst1,dst2;
//高斯滤波
GaussianBlur(img1, dst1, Size(5, 5), 0.8);
//中值滤波
medianBlur(img1,dst2, 5);
//显示图像
imshow("高斯滤波效果图", dst1);
imshow("中值滤波效果图", dst2);
//储存图像
imwrite("D:\\yt\\picture\\blur\\gs_blur_jay3.jpg", dst1);
imwrite("D:\\yt\\picture\\blur\\medianblur_jay2.jpg", dst2);
waitKey(0);
return 0;
}
效果:可以看出,中值滤波消除椒盐噪声的效果比高斯滤波好

3、双边滤波
#include
using namespace cv;
using namespace std;
int main()
{
//载入图像
Mat img1 = imread("D:\\yt\\picture\\blur\\the_eight_dimensions.jpg");
Mat dst1,dst2;
//高斯滤波
GaussianBlur(img1, dst1, Size(5, 5), 0.8);
//双边滤波
bilateralFilter(img2,dst2,5,100,100);
//显示图像
imshow("高斯滤波效果图", dst1);
imshow("双边滤波效果图", dst2);
//储存图像
imwrite("D:\\yt\\picture\\blur\\medianblur_jay2.jpg", dst1);
imwrite("D:\\yt\\picture\\blur\\bilateralFilter_jay2.jpg", dst2);
waitKey(0);
return 0;
}
效果:可以看出,双边滤波后的边缘保留的比高斯滤波好

python代码实现
1、方框滤波、均值滤波、高斯滤波
import cv2
import numpy as np
if __name__ == "__main__":
img = cv2.imread('D:/yt/picture/blur/gs_tiger.jpg', cv2.IMREAD_COLOR)
#方框滤波
dst1 = cv2.boxFilter(img, -1,(5,5),normalize=1)
#均值滤波
dst2 = cv2.blur(img,(5,5))
#高斯滤波
dst3 = cv2.GaussianBlur(img,(5,5),0,0)
# 显示图像
cv2.imshow("origin image", img)
cv2.imshow("boxFilter image", dst1)
cv2.imshow("blur image", dst2)
cv2.imshow("gsBlur image", dst3)
# 保存图像
cv2.imwrite("D:/yt/picture/blur/boxFilter_tiger.jpg", dst1)
cv2.imwrite("D:/yt/picture/blur/blur_tiger.jpg", dst2)
cv2.imwrite("D:/yt/picture/blur/gsBlur_tiger.jpg", dst3)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果:
2、中值滤波
import cv2
import numpy as np
if __name__ == "__main__":
img = cv2.imread('D:/yt/picture/blur/harbin.jpg', cv2.IMREAD_COLOR)
#高斯滤波
dst4 = cv2.GaussianBlur(img,(5,5),0,0)
#中值滤波
dst5 = cv2.medianBlur(img,5)
# 显示图像
cv2.imshow("origin image", img)
cv2.imshow("gaussian",dst4)
cv2.imshow("median",dst5)
# 保存图像
cv2.imwrite("D:/yt/picture/blur/gsBlur_img.jpg",dst4)
cv2.imwrite("D:/yt/picture/blur/medianBlur_img.jpg",dst5)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果:左边为原图,右边是中值滤波处理后

下图左边为原图,右边是高斯滤波处理后。可以看出 高斯滤波对椒盐噪声的效果不如中值滤波。

3、双边滤波
import cv2
import numpy as np
if __name__ == "__main__":
img = cv2.imread('D:/yt/picture/blur/white_black.jpg', cv2.IMREAD_COLOR)
#高斯滤波
dst4 = cv2.GaussianBlur(img,(25,25),0,0)
#双边滤波
dst6 = cv2.bilateralFilter(img,25,100,100)
# 显示图像
cv2.imshow("origin image", img)
cv2.imshow("gaussian", dst4)
cv2.imshow("bilateral",dst6)
# 保存图像
cv2.imwrite("D:/yt/picture/blur/gsblur_wb.jpg",dst4)
cv2.imwrite("D:/yt/picture/blur/bilateral_wb.jpg",dst6)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果:左边为原图,中间为中值滤波处理,右边为高斯滤波处理。可以看出,经过高斯滤波的边缘被模糊虚化了,经过双边滤波的边缘得到了较好的保留。

形态学图像处理
形态学图像处理(简称形态学)是指一系列处理图像形状特征的图像处理技术。
形态学的基本思想是利用一种特殊的结构元来测量或提取输入图像中相应的形状或特征,以便进一步进行图像分析和目标识别。
形态学方法的基础是集合论。
基础概念
不做特殊说明,输入图像为二值图像。图像中1是前景,0是背景。
结构元(Structuring Elements,SE)可以是任意形状,SE中的的值可以是0或1。常见的结构元有矩形和十字形。结构元有一个锚点O,O一般定义为结构元的中心(也可以自由定义位置)。如下图所示是几个不同形状的结构元,紫红色区域为锚点O。

记 f 为原图像, s 为结构元。
膨胀(Dilation)
将结构元s 在图像 f 上滑动,把结构元锚点位置的图像像素点的灰度值设置为结构元值为1的区域对应图像区域像素的最大值。用公式表示如下,其中element为结构元,(x,y)为锚点O的位置,x’和y’为结构元值为1的像素相对锚点O的位置偏移,src表示原图,dst表示结果图。
dst(x,y)=max(x′,y′):element(x′,y′)≠0src(x+x′,y+y′)
膨胀运算示意图如下,从视觉上看图像中的前景仿佛“膨胀”了一样:
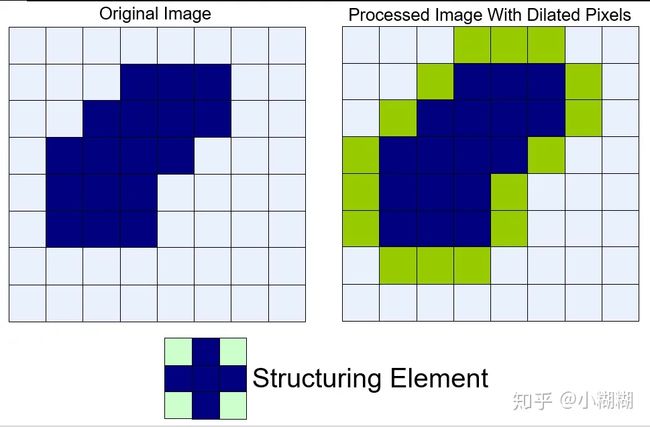
膨胀示意图
膨胀运算用公式符号记为:f⊕s
膨胀相当于是腐蚀反向操作,图像中较亮的物体尺寸会变大,较暗的物体尺寸会减小。还是相同的例子,在21的十字邻域内找最大值,最大值为234,将234赋值到这个位置。

经过膨胀操作,图像区域的边缘可能会变得平滑,区域的像素将会增加,不相连的部分可能会连接起来,这些都与腐蚀操作正好相反。即使如此,原本不相连的区域任然属于各自的区域,不会因为像素重叠就发生合并。
膨胀运算是将图像中的像素点赋值为其局部邻域中灰度的最大值,经过膨胀处理后,图像整体灰度值增大,图像中亮的区域扩大,较暗的小区域消失。
腐蚀(Erosion)
将结构元 s 在图像 f 上滑动,把结构元锚点位置的图像像素点的灰度值设置为结构元值为1的区域对应图像区域像素的最小值。用公式表示如下,其中element为结构元,(x,y)为锚点O的位置,x’和y’为结构元值为1的像素相对锚点O的位置偏移,src表示原图,dst表示结果图。
dst(x,y)=min(x′,y′):element(x′,y′)≠0src(x+x′,y+y′)
腐蚀运算示意图如下,从视觉上看图像中的前景仿佛被“腐蚀”了一样:

腐蚀示意图
腐蚀运算用公式符号记为: f⊖s
腐蚀操作时取每一个位置的矩形邻域内值的最小值作为该位置的输出灰度值。这里的邻域可以是矩形结构,也可以是椭圆形结构、十字交叉形结构等,这个结构被定义为结构元,实际上就是个01二值矩阵。
举个例子
给定一个矩阵,也就是我们要做处理的图像

以及一个十字交叉结构元

结构元
在对 (1,2) 点出的灰度做处理时,也就是对21这个点做处理时,要在其十字形邻域内找最小值,赋值给(1,2)点。示意图如下。
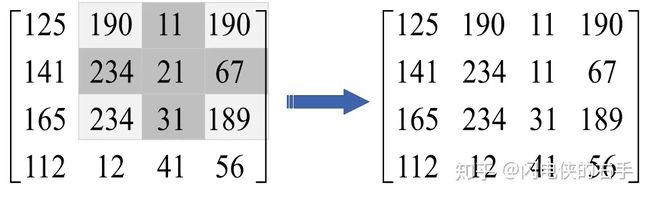
从图中也可以很容易的看出,腐蚀操作将灰度值降低了,也就是说腐蚀后的输出图像总体亮度比原图有所降低,图像中比较亮的区域面积会变小,比较暗的区域面积增大。
腐蚀操作是对所选区域进行“收缩”的一种操作,可以用于消除边缘和杂点。经过腐蚀操作,图像区域的边缘可能会变得平滑,区域的像素将会减少,相连的部分可能会断开。即使如此,各部分仍然属于同一个区域。
腐蚀运算是将图像中的像素点赋值为其局部邻域中灰度的最小值,因此图像整体灰度值减少,图像中暗的区域变得更暗,较亮的小区域被抑制。
开运算(Opening)
对图像 f 用同一结构元 s 先腐蚀再膨胀称之为开运算。记为: f∘s=(f⊖s)⊕s 。
开运算示意图如下,从视觉上看仿佛将原本连接的物体“分开”了一样:
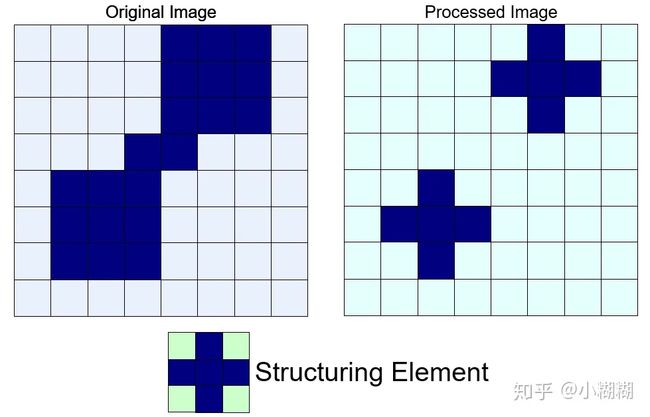
可以消除亮度较高的细小区域,而且不会明显改变其他物体区域的面积。
通过腐蚀运算能去除小的非关健区域,也可以把离得很近的元素分隔开,再通过膨胀填补过度腐蚀留下的空隙。因此,通过开运算能去除孤立的、细小的点,平滑毛糙的边缘线,同时原区域面积也不会有明显的改变,类似于一种“去毛刺”的效果。
闭运算(Closing)
对图像 f 用同一结构元 s 先膨胀再腐蚀称之为闭运算。记为: f∙s=(f⊕s)⊖s 。
开运算示意图如下,从视觉上看仿佛将原本分开的部分“闭合”了一样:
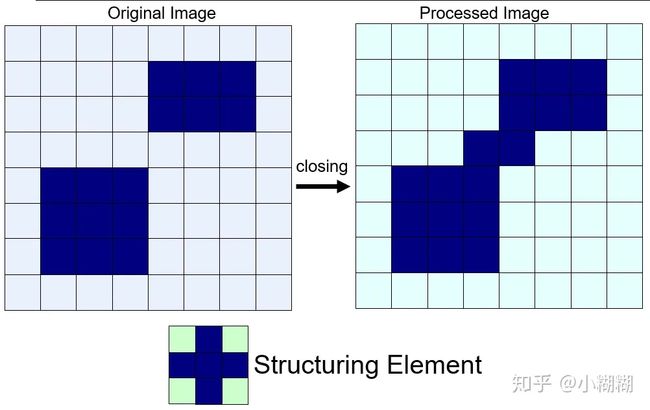
可以消除细小黑色空洞,也不会明显改变其他物体区域面积。
闭运算的计算步骤与开运算正好相反,为先膨胀,后腐蚀。这两步操作能将看起来很接近的元素,如区域内部的空洞或外部孤立的点连接成一体,区域的外观和面积也不会有明显的改变。通俗地说,就是类似于“填空隙”的效果。与单独的膨胀操作不同的是,闭运算在填空隙的同时,不会使图像边缘轮廓加粗。
白色顶帽变换(white top-hat)
白色顶帽变换是原图像与开运算结果图之差,用公式表示为:
Tw(f)=f−f∘s
白色顶帽变换变换可以得到图像中那些面积小于结构元且比周围亮的区域,示意图如下:

黑色顶帽变换(blacktop-hat)
黑色顶帽变换是闭运算结果图与原图之差,用公式表示为:
Tb(f)=f∙s−f
黑色顶帽变换可以得到图像中那些面积小于结构元且比周围暗的区域。
灰度图像腐蚀:图像变暗了,这是因为图像中较亮的局部区域被收缩了,较暗的区域被扩大了,因而图像变暗了。
灰度图像膨胀:较亮的局部区域被“扩大”了,而较暗的区域被“收缩”了,图像整体变得更亮。
灰度图像开运算:图像中较亮的小细节消失。
灰度图像闭运算:图像中较暗的一些点消失了,类似于灰度图像中的“小孔隙”被填补了,同时较亮的区域的边缘更清晰了。
霍夫变换(直线、线段与圆检测)
一、基础理论
1、作用:
提取直线和圆等几何形状。

2、定义
霍夫变换(Hough Transform)是图像处理中的一种特征提取技术,它通过一种投票算法检测具有特定形状的物体。Hough变换是图像处理中从图像中识别几何形状的基本方法之一。Hough变换的基本原理在于利用点与线的对偶性,将原始图像空间的给定的曲线通过曲线表达形式变为参数空间的一个点。这样就把原始图像中给定曲线的检测问题转化为寻找参数空间中的峰值问题。也即把检测整体特性转化为检测局部特性。比如直线、椭圆、圆、弧线等。
原则上霍夫变换可以检测任何形状,但复杂的形状需要的参数就多,霍夫空间的维数就多,因此在程序实现上所需的内存空间以及运行效率上都不利于把标准霍夫变换应用于实际复杂图形的检测中。霍夫梯度法是霍夫变换的改进(圆检测),它的目的是减小霍夫空间的维度,提高效率。
3、原理
直线检测原理:将要检测的对象转到霍夫空间中,利用累加器找到最优解,即为所求直线。
(注:检测前要对图像二值化处理)
圆检检测原理:霍夫梯度法,找到达到阈值的原点和半径。
两个点决定直线的斜率和截距情况:
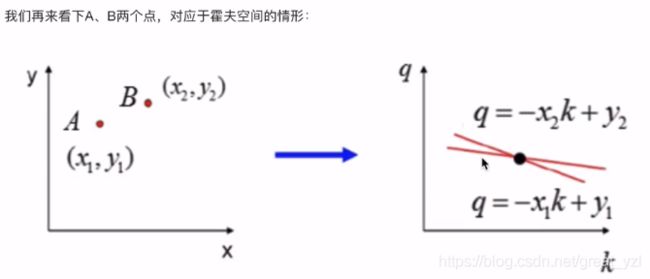
三个点决定直线斜率和截距情况:

极坐标系:
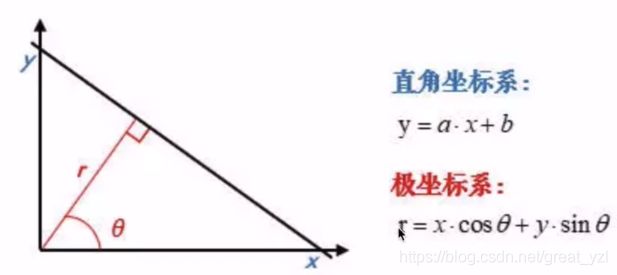
求出了“极坐标”空间下相交的点,自然也就可以用哪个\rho和\theta求出直线的三个点坐标。
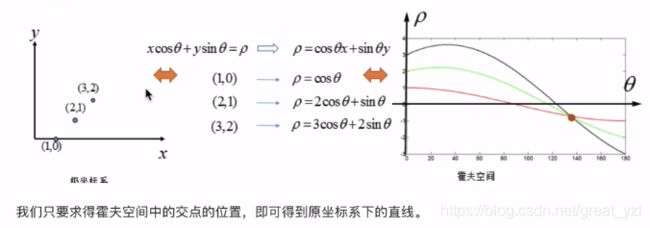
得到曲线:采用不同的\theta遍历\rho值
使用累加器检测直线:
累加器是一个二维数组。

二、直线检测
1、基础理论
霍夫变换 (Hough Line Transform) 是图像处理中的一种特征提取技术. 通过平面空间到极值坐标空间的转换, 可以帮助我们实现直线检测
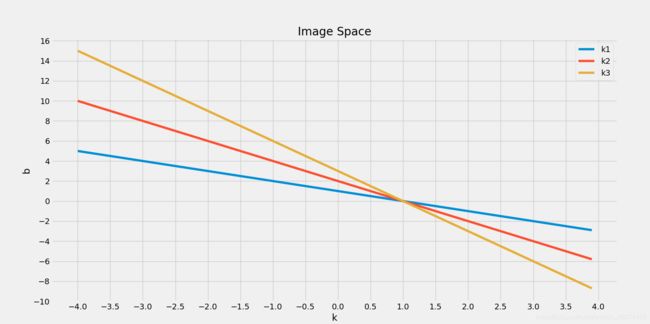
1、原理
1、首先边缘检测,得到许多点
2、遍历第一个点的各个\theta方向的\rho,得到第一个点的曲线
3、遍历每一个点,得到多条曲线
4、多曲线相交,就是最终的\rho和\theta,通过它可以确定最终直线

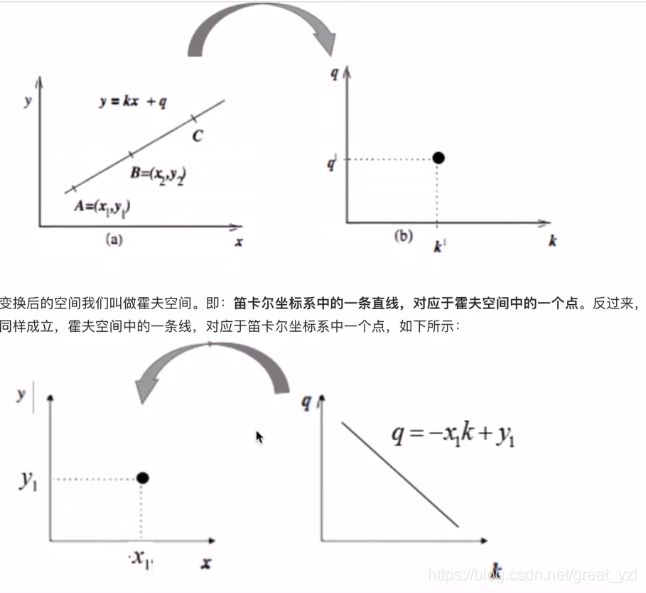
(左:笛卡尔坐标系 右:霍夫空间)
2、过程
1、首先边缘检测,得到许多点
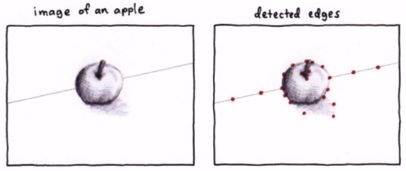
2、遍历第一个点的各个\theta方向的\rho,得到第一个点的曲线
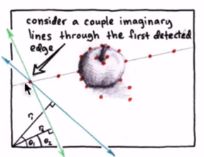
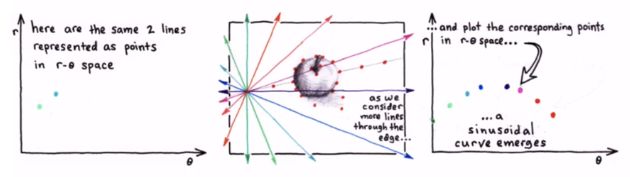

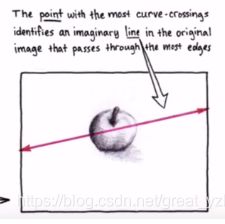
3、遍历每一个点,得到多条曲线

4、多曲线相交,就是最终的\rho和\theta,通过它可以确定最终直线
2、HoughLines函数(直线检测)
HoughLines函数:
void HoughLines(InputArray image, OutputArray lines, double rho, double theta,
int threshold, double srn=0, double stn=0 )
- 第一个参数,InputArray类型的image,输入图像,即源图像,需为8位的单通道二进制图像,可以将任意的源图载入进来后由函数修改成此格式后,再填在这里。
-
第二个参数,InputArray类型的lines,经过调用HoughLines函数后储存了霍夫线变换检测到线条的输出矢量。每一条线由具有两个元素的矢量表示,其中,是离坐标原点((0,0)(也就是图像的左上角)的距离。 是弧度线条旋转角度(0垂直线,π/2水平线)。
-
第三个参数,double类型的rho,以像素为单位的距离精度。另一种形容方式是直线搜索时的进步尺寸的单位半径。PS:Latex中/rho就表示 。
-
第四个参数,double类型的theta,以弧度为单位的角度精度。另一种形容方式是直线搜索时的进步尺寸的单位角度。
第五个参数,int类型的threshold,累加平面的阈值参数,即识别某部分为图中的一条直线时它在累加平面中必须达到的值。大于阈值threshold的线段才可以被检测通过并返回到结果中。 -
第六个参数,double类型的srn,有默认值0。对于多尺度的霍夫变换,这是第三个参数进步尺寸rho的除数距离。粗略的累加器进步尺寸直接是第三个参数rho,而精确的累加器进步尺寸为rho/srn。
-
第七个参数,double类型的stn,有默认值0,对于多尺度霍夫变换,srn表示第四个参数进步尺寸的单位角度theta的除数距离。且如果srn和stn同时为0,就表示使用经典的霍夫变换。否则,这两个参数应该都为正数。
HoughLines(dst, lines, 1, CV_PI / 180, 150);
// 距离精度(像素) 角度精度(弧度) 累加平面阈值
//霍夫直线检测
void Hough_Line()
{
//1、边缘检测
Canny(src, dst, 50, 200, 3);
imshow(“canny edge”, dst);//2、霍夫变换 vectorlines; //定义一个矢量结构lines用于存放得到的线段矢量集合 HoughLines(dst, lines, 1, CV_PI / 180, 150); // 距离精度(像素) 角度精度(弧度) 累加平面阈值 //3、依次绘制每条线段 for (size_t i = 0; i < lines.size(); i++) { float rho = lines[i][0], theta = lines[i][1]; //距离精度、角度精度 Point pt1, pt2; //定义两点p1和p2 double a = cos(theta), b = sin(theta); //a:cos b:sin //以x0和y0作为参照点,求出(x1, y1)和(x2, y2) double x0 = a * rho, y0 = b * rho; pt1.x = cvRound(x0 - 1000 * (-b)); pt1.y = cvRound(y0 - 1000 * (a)); pt2.x = cvRound(x0 + 1000 * (-b)); pt2.y = cvRound(y0 + 1000 * (a)); line(dst, pt1, pt2, Scalar(200, 0, 0), 3); //绘制直线 } imshow("Hough", dst); }


三、圆检测
1、基础理论
1、概念

霍夫圆变换 (Hough Circle Transform) 的原理和霍夫直线变换类似. 对于一条直线, 我们可以用参数 表示, 对于圆我们需要三个参数
表示, 对于圆我们需要三个参数 
因为霍夫圆检测对噪声比较敏感, 所以首先要对图像做中值滤波。
2、原理
霍夫变换圆检测是基于图像梯度实现:
圆心检测的原理︰圆心是圆周法线的交汇处,设置一个阈值,在某点的相交的直线的条数大于这个阈值就认为该交汇点为圆心。
圆半径确定原理:圆心到圆周上的距离〔半径)是相同的,设置一个阈值,只要相同距离的数量大于该阈值,就认为该距离是该圆心的半径。
(霍夫圆检测里面包含有canny边缘检测)
2、HoughCircles函数
C++ API:
void HoughCircles(InputArray image,OutputArray circles, int method, double dp, double minDist,
double param1=100,double param2=100, int minRadius=0, int maxRadius=0 )
第一个参数,InputArray类型的image,输入图像,即源图像,需为8位的灰度单通道图像。
第二个参数,InputArray类型的circles,经过调用HoughCircles函数后此参数存储了检测到的圆的输出矢量,每个矢量由包含了3个元素的浮点矢量(x, y, radius)表示。
第三个参数,int类型的method,即使用的检测方法,目前OpenCV中就霍夫梯度法一种可以使用,它的标识符为CV_HOUGH_GRADIENT,在此参数处填这个标识符即可。
第四个参数,double类型的dp,用来检测圆心的累加器图像的分辨率于输入图像之比的倒数,且此参数允许创建一个比输入图像分辨率低的累加器。上述文字不好理解的话,来看例子吧。例如,如果dp= 1时,累加器和输入图像具有相同的分辨率。如果dp=2,累加器便有输入图像一半那么大的宽度和高度。
第五个参数,double类型的minDist,为霍夫变换检测到的圆的圆心之间的最小距离,即让我们的算法能明显区分的两个不同圆之间的最小距离。这个参数如果太小的话,多个相邻的圆可能被错误地检测成了一个重合的圆。反之,这个参数设置太大的话,某些圆就不能被检测出来了。
第六个参数,double类型的param1,有默认值100。它是第三个参数method设置的检测方法的对应的参数。对当前唯一的方法霍夫梯度法CV_HOUGH_GRADIENT,它表示传递给canny边缘检测算子的高阈值,而低阈值为高阈值的一半。
第七个参数,double类型的param2,也有默认值100。它是第三个参数method设置的检测方法的对应的参数。对当前唯一的方法霍夫梯度法CV_HOUGH_GRADIENT,它表示在检测阶段圆心的累加器阈值。它越小的话,就可以检测到更多根本不存在的圆,而它越大的话,能通过检测的圆就更加接近完美的圆形了。
第八个参数,int类型的minRadius,有默认值0,表示圆半径的最小值。
第九个参数,int类型的maxRadius,也有默认值0,表示圆半径的最大值。
HoughCircles(dst, circles, HOUGH_GRADIENT, 1.5, 10, 200, 100, 0, 0);
// 霍夫梯度法 dp 圆心间最小距离 高阈值 累加阈值 圆半径最小、最大值
python API:
def HoughCircles(image: Any,
method: Any,
dp: Any,
minDist: Any,
circles: Any = None,
param1: Any = None,
param2: Any = None,
minRadius: Any = None,
maxRadius: Any = None) -> None
参数:
第二个参数,int类型的method,即使用的检测方法,目前OpenCV中就霍夫梯度法一种可以使用,它的标识符为CV_HOUGH_GRADIENT,在此参数处填这个标识符即可。
第三个参数,double类型的dp,用来检测圆心的累加器图像的分辨率于输入图像之比的倒数,且此参数允许创建一个比输入图像分辨率低的累加器。上述文字不好理解的话,来看例子吧。例如,如果dp= 1时,累加器和输入图像具有相同的分辨率。如果dp=2,累加器便有输入图像一半那么大的宽度和高度。
第四个参数,double类型的minDist,为霍夫变换检测到的圆的圆心之间的最小距离,即让我们的算法能明显区分的两个不同圆之间的最小距离。这个参数如果太小的话,多个相邻的圆可能被错误地检测成了一个重合的圆。反之,这个参数设置太大的话,某些圆就不能被检测出来了。
第五个参数,InputArray类型的circles,经过调用HoughCircles函数后此参数存储了检测到的圆的输出矢量,每个矢量由包含了3个元素的浮点矢量(x, y, radius)表示。
第六个参数,double类型的param1,有默认值100。它是第三个参数method设置的检测方法的对应的参数。对当前唯一的方法霍夫梯度法CV_HOUGH_GRADIENT,它表示传递给canny边缘检测算子的高阈值,而低阈值为高阈值的一半。
第七个参数,double类型的param2,也有默认值100。它是第三个参数method设置的检测方法的对应的参数。对当前唯一的方法霍夫梯度法CV_HOUGH_GRADIENT,它表示在检测阶段圆心的累加器阈值。它越小的话,就可以检测到更多根本不存在的圆,而它越大的话,能通过检测的圆就更加接近完美的圆形了。
第八个参数,int类型的minRadius,有默认值0,表示圆半径的最小值。
第九个参数,int类型的maxRadius,也有默认值0,表示圆半径的最大值。
//霍夫圆检测
void Hough_Circle()
{
//1、转化为灰度图并图像平滑
cvtColor(src, gray, COLOR_BGR2GRAY);
GaussianBlur(gray, dst, Size(9, 9), 2, 2);
imshow("滤波", dst);
//2、霍夫圆变换(用灰度图)
vector circles;
HoughCircles(dst, circles, HOUGH_GRADIENT, 1.5, 10, 200, 100, 0, 0);
// 霍夫梯度法 dp 圆心间最小距离 高阈值 累加阈值 圆半径最小、最大值
//3、依次在图中绘制出圆
for (size_t i = 0; i < circles.size(); i++)
{
Point center(cvRound(circles[i][0]), cvRound(circles[i][1])); //圆心
int radius = cvRound(circles[i][2]); //半径
//绘制圆心
circle(src, center, 3, Scalar(0, 255, 255), -1);
//绘制圆轮廓
circle(src, center, radius, Scalar(0, 255, 255), 3);
}
imshow("Hough", src);
}
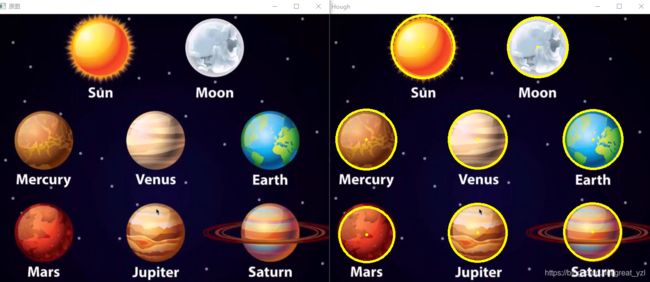
最佳地匹配每个图像,参数不一样
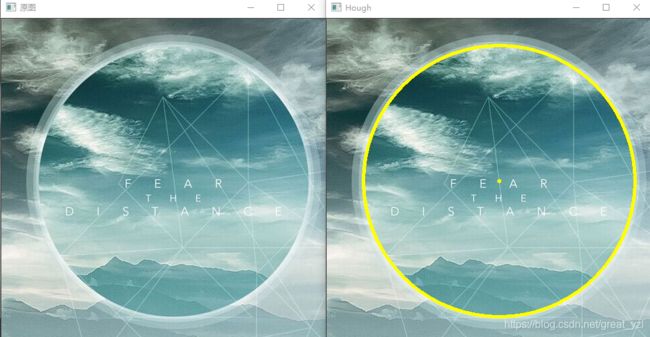
HoughCircles(dst, circles, HOUGH_GRADIENT, 1.5, 10, 50, 100, 0, 0);
HoughCircles(dst, circles, HOUGH_GRADIENT, 1.5, 10, 200, 100, 0, 0);
//霍夫变换(直线和圆检测)
#include
#include
#include
using namespace cv;
using namespace std;
Mat src, dst, gray;
//霍夫直线检测(不推荐)
void Hough_Line()
{
//1、边缘检测
Canny(src, dst, 50, 200, 3);
imshow("canny edge", dst);
//2、霍夫变换
vector lines; //定义一个矢量结构lines用于存放得到的线段矢量集合
HoughLines(dst, lines, 1, CV_PI / 180, 150);
// 距离精度(像素) 角度精度(弧度) 累加平面阈值
//3、依次绘制每条线段
for (size_t i = 0; i < lines.size(); i++)
{
float rho = lines[i][0], theta = lines[i][1]; //距离精度、角度精度
Point pt1, pt2; //定义两点p1和p2
double a = cos(theta), b = sin(theta); //a:cos b:sin
//以x0和y0作为参照点,求出(x1, y1)和(x2, y2)
double x0 = a * rho, y0 = b * rho;
pt1.x = cvRound(x0 - 1000 * (-b));
pt1.y = cvRound(y0 - 1000 * (a));
pt2.x = cvRound(x0 + 1000 * (-b));
pt2.y = cvRound(y0 + 1000 * (a));
line(dst, pt1, pt2, Scalar(200, 0, 0), 3); //绘制直线
}
imshow("Hough", dst);
}
//霍夫线段检测(推荐)
void Hough_LineP()
{
//1、边缘检测
Canny(src, dst, 50, 200, 3);
imshow("canny edge", dst);
//2、霍夫变换
vector lines; //定义一个矢量结构lines用于存放得到的线段矢量集合
HoughLinesP(dst, lines, 1, CV_PI / 180, 80, 100, 10);
// 距离精度(像素) 角度精度(弧度) 累加平面阈值 最低线段长度 同一行点与点连接的最大距离
//3、依次绘制每条线段
for (size_t i = 0; i < lines.size(); i++)
{
Vec4i l = lines[i];
line(dst, Point(l[0], l[1]), Point(l[2], l[3]), Scalar(255, 0, 0), 3);
}
imshow("Hough", dst);
}
//霍夫圆检测
void Hough_Circle()
{
//1、转化为灰度图并图像平滑
cvtColor(src, gray, COLOR_BGR2GRAY);
GaussianBlur(gray, dst, Size(9, 9), 2, 2);
imshow("滤波", dst);
//2、霍夫圆变换(用灰度图)
vector circles;
HoughCircles(dst, circles, HOUGH_GRADIENT, 1.5, 10, 50, 100, 0, 0);
// 霍夫梯度法 dp 圆心间最小距离 高阈值 累加阈值 圆半径最小、最大值
//HoughCircles(dst, circles, HOUGH_GRADIENT, 1.5, 10, 200, 100, 0, 0);
//3、依次在图中绘制出圆
for (size_t i = 0; i < circles.size(); i++)
{
Point center(cvRound(circles[i][0]), cvRound(circles[i][1])); //圆心
int radius = cvRound(circles[i][2]); //半径
//绘制圆心
circle(src, center, 3, Scalar(0, 0, 255), -1);
//绘制圆轮廓
circle(src, center, radius, Scalar(0, 0, 255), 3);
}
imshow("Hough", src);
}
int main()
{
src = imread("Resource/4.jpg");
imshow("原图", src);
Hough_Line(); //霍夫直线检测
Hough_LineP(); //霍夫线段检测
Hough_Circle(); //霍夫圆检测
waitKey(0);
return 0;
}