一、了解 K-means。
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛。K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体方法。包括初始化优化K-Means++, 距离计算优化elkan K-Means算法和大数据情况下的优化Mini Batch K-Means算法。
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
二、传统K-Means算法流程。
1、随机选择K个聚类的初始中心。
2、对任意一个样本点,求其到K个聚类中心的距离,将样本点归类到距离最小的中心的聚类。
3、每次迭代过程中,利用均值等方法更新各个聚类的中心点(质心)。
4、对K个聚类中心,利用2、3步迭代更新后,如果位置点变化很小(可以设置阈值),则认为达到稳定状态,迭代结束。(画图时,可以对不同的聚类块和聚类中心可选择不同的颜色标注)
优点
1、原理比较简单,实现也是很容易,收敛速度快。
2、聚类效果较优。
3、算法的可解释度比较强。
4、主要需要调参的参数仅仅是簇数k。
缺点
1、K值的选取不好把握
2、对于不是凸的数据集比较难收敛
3、如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳。
4、 最终结果和初始点的选择有关,容易陷入局部最优。
5、对噪音和异常点比较的敏感。
三、 K-Means初始化优化
二分K-Means
解决K-Means算法对初始簇心比较敏感的问题,二分K-Means算法是一种弱化初始质心的一种算法。
算法流程:
1、将所有样本数据作为一个簇放到一个队列中。
2、从队列中选择一个簇进行K-Means算法划分,划分为两个子簇,并将子簇添加到队列中。
3、循环迭代步骤2操作,直到中止条件达到(聚簇数量、最小平方误差、迭代次数等)。
4、队列中的簇就是最终的分类簇集合。
从队列中选择划分聚簇的规则一般有两种方式;分别如下:
1、对所有簇计算误差和SSE(SSE也可以认为是距离函数的一种变种),选择SSE最大的聚簇进行划分操作(优选这种策略)。
2、选择样本数据量最多的簇进行划分操作:
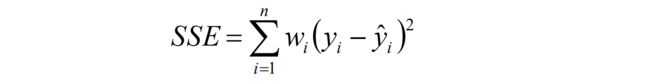
K-Means++
由于 K-means 算法的分类结果会受到初始点的选取而有所区别,因此有提出这种算法的改进: K-means++ 。
其实这个算法也只是对初始点的选择有改进而已,其他步骤都一样。初始质心选取的基本思路就是,初始的聚类中心之间的相互距离要尽可能的远。
算法流程:
1、随机选取一个样本作为第一个聚类中心 c1;
2、计算每个样本与当前已有类聚中心最短距离(即与最近一个聚类中心的距离),用 D(x)表示;这个值越大,表示被选取作为聚类中心的概率较大;最后,用轮盘法选出下一个聚类中心。
3、重复步骤2,知道选出 k 个聚类中心。
4、选出初始点(聚类中心),就继续使用标准的 k-means 算法了。
尽管K-Means++在聚类中心的计算上浪费了很多时间,但是在迭代过程中,k-mean 本身能快速收敛,因此算法实际上降低了计算时间。
K-Means||
解决K-Means++算法缺点而产生的一种算法;主要思路是改变每次遍历时候的取样规则,并非按照K-Means++算法每次遍历只获取一个样本,而是每次获取K个样本,重复该取样操作O(logn)次(n是样本的个数),然后再将这些抽样出来的样本聚类出K个点,最后使用这K个点作为K-Means算法的初始聚簇中心点。实践证明:一般5次重复采用就可以保证一个比较好的聚簇中心点。
算法流程:
1、在N个样本中抽K个样本,一共抽logn次,形成一个新的样本集,一共有Klogn个数据。
2、在新数据集中使用K-Means算法,找到K个聚簇中心。
3、把这K个聚簇中心放到最初的样本集中,作为初始聚簇中心。
4、原数据集根据上述初始聚簇中心,再用K-Means算法计算出最终的聚簇。
Canopy算法
Canopy属于一种‘粗’聚类算法,即使用一种简单、快捷的距离计算方法将数据集分为若干可重叠的子集canopy,这种算法不需要指定k值、但精度较低,可以结合K-means算法一起使用:先由Canopy算法进行粗聚类得到k个质心,再使用K-means算法进行聚类。
算法流程:
1、将原始样本集随机排列成样本列表L=[x1,x2,...,xm](排列好后不再更改),根据先验知识或交叉验证调参设定初始距离阈值T1、T2,且T1>T2 。
2、从列表L中随机选取一个样本P作为第一个canopy的质心,并将P从列表中删除。
3、从列表L中随机选取一个样本Q,计算Q到所有质心的距离,考察其中最小的距离D:
如果D≤T1,则给Q一个弱标记,表示Q属于该canopy,并将Q加入其中;
如果D≤T2,则给Q一个强标记,表示Q属于该canopy,且和质心非常接近,所以将该canopy的质心设为所有强标记样本的中心位置,并将Q从列表L中删除;
如果D>T1,则Q形成一个新的聚簇,并将Q从列表L中删除。
4、重复第三步直到列表L中元素个数为零。
注意
1、‘粗’距离计算的选择对canopy的分布非常重要,如选择其中某个属性、其他外部属性、欧式距离等。
2、当T2 3、T1、T2的取值影响canopy的重叠率及粒度:当T1过大时,会使样本属于多个canopy,各个canopy间区别不明显;当T2过大时,会减少canopy个数,而当T2过小时,会增加canopy个数,同时增加计算时间。 4、canopy之间可能存在重叠的情况,但是不会存在某个样本不属于任何canopy的情况。 5、Canopy算法可以消除孤立点,即删除包含样本数目较少的canopy,往往这些canopy包含的是孤立点或噪音点。 由于K-Means算法存在初始聚簇中心点敏感的问题,常用使用Canopy+K-Means算法混合形式进行模型构建。 1、先使用canopy算法进行“粗”聚类得到K个聚类中心点。 2、K-Means算法使用Canopy算法得到的K个聚类中心点作为初始中心点,进行“细”聚类。 1、执行速度快(先进行了一次聚簇中心点选择的预处理); 2、不需要给定K值,应用场景多。 3、能够缓解K-Means算法对于初始聚类中心点敏感的问题。 Mini Batch K-Means算法是K-Means算法的一种优化变种,采用小规模的数据子集(每次训练使用的数据集是在训练算法的时候随机抽取的数据子集)减少计算时间,同时试图优化目标函数;Mini Batch K-Means算法可以减少K-Means算法的收敛时间,而且产生的结果效果只是略差于标准K-Means算法。 1、首先抽取部分数据集,使用K-Means算法构建出K个聚簇点的模型。 2、继续抽取训练数据集中的部分数据集样本数据,并将其添加到模型中,分配给距离最近的聚簇中心点。 3、更新聚簇的中心点值。 4、循环迭代第二步和第三步操作,直到中心点稳定或者达到迭代次数,停止计算操作。 https://www.jianshu.com/p/f0727880c9c0Canopy算法常用应用场景
优点
Mini Batch K-Means
算法流程:
四、聚类大纲