PyCaret-低代码ML库使用指南
| 在本文中,我将演示如何使用PyCaret快速轻松地构建机器学习项目并为部署准备最终模型。 |
当我们研究监督的机器学习问题时,如果我们对结果感到满意,那么很容易看到随机森林或梯度提升模型如何执行并停止实验。如果您仅用一行代码就可以比较许多不同的模型,该怎么办?如果您可以将数据科学过程的每个步骤(从功能工程到模型部署)减少到仅几行代码,该怎么办?

这正是PyCaret发挥作用的地方。PyCaret是一个高级,低代码的Python库,它使仅需几行代码即可轻松比较,训练,评估,调整和部署机器学习模型。从本质上讲,PyCaret基本上只是许多Scikit-learn,Yellowbrick,SHAP,Optuna和Spacy等数据科学库的大型包装。是的,您可以将这些库用于相同的任务,但是如果您不想编写大量代码,PyCaret可以节省大量时间。
在本文中,我将演示如何使用PyCaret快速轻松地构建机器学习项目并为部署准备最终模型。
安装PyCaret
PyCaret是一个具有很多依赖项的大型库。我建议使用Conda为PyCaret创建一个虚拟环境,这样安装不会影响您现有的任何库。要在Conda中创建和激活虚拟环境,请运行以下命令:
conda create --name pycaret_env python=3.6
conda activate pycaret_env
要安装仅具有所需依赖项的默认较小版本的PyCaret,可以运行以下命令。
pip install pycaret
要安装完整版本的PyCaret,您应该运行以下命令。
pip install pycaret[full]
一旦安装了PyCaret,请停用虚拟环境,然后使用以下命令将其添加到Jupyter。
conda deactivate
python -m ipykernel install --user --name pycaret_env --display-name "pycaret_env"
现在,在浏览器中启动Jupyter Notebook之后,您应该能够看到将环境更改为刚创建的选项的选项。
> Changing the Conda virtual environment in Jupyter.
导入库
您可以在此GitHub存储库中找到本文的完整代码。在下面的代码中,我仅导入了Numpy和Pandas来处理此演示的数据。
import numpy as np
import pandas as pd
读取数据
对于此示例,我使用了Kaggle上可用的“加利福尼亚住房价格”数据集。在下面的代码中,我将此数据集读入一个数据框,并显示了该数据框的前十行。
housing_data = pd.read_csv('./data/housing.csv')housing_data.head(10)

> First ten rows of the housing dataset.
上面的输出使我们对数据的外观有所了解。数据主要包含数字特征和一个分类特征,用于每个房屋与海洋的接近度。我们试图预测的目标列是“ median_house_value”列。整个数据集总共包含20,640个观测值。
初始化实验
现在我们有了数据,我们可以初始化一个PyCaret实验,该实验将对数据进行预处理并为将在此数据集上训练的所有模型启用日志记录。
from pycaret.regression import *
reg_experiment = setup(housing_data,
target = 'median_house_value',
session_id=123,
log_experiment=True,
experiment_name='ca_housing')
如下面的GIF中所示,运行上面的代码会对数据进行预处理,然后生成带有实验选项的数据框。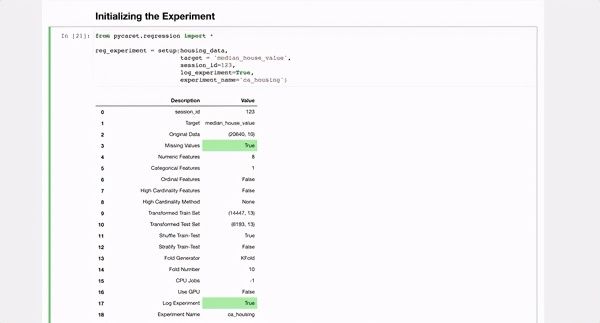
> Pycaret setup function output.
比较基准模型
我们可以立即比较不同的基线模型,以找到具有使用compare_models函数的最佳K折交叉验证性能的模型,如下面的代码所示。在下面的示例中,出于演示目的,我已将XGBoost排除在外。
best_model = compare_models(exclude=['xgboost'], fold=5)
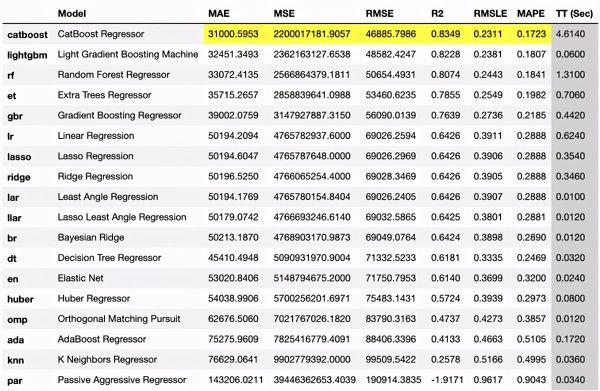
> Results of comparing different models.
该函数将生成一个数据框,其中包含每个模型的性能统计信息,并突出显示性能最佳的模型的指标,在本例中为CatBoost回归器。
建立模型
我们还可以使用PyCaret在单行代码中训练模型。create_model函数仅需要一个与您要训练的模型类型相对应的字符串。您可以在PyCaret文档页面上找到此功能的可接受字符串的完整列表以及相应的回归模型。
catboost = create_model('catboost')
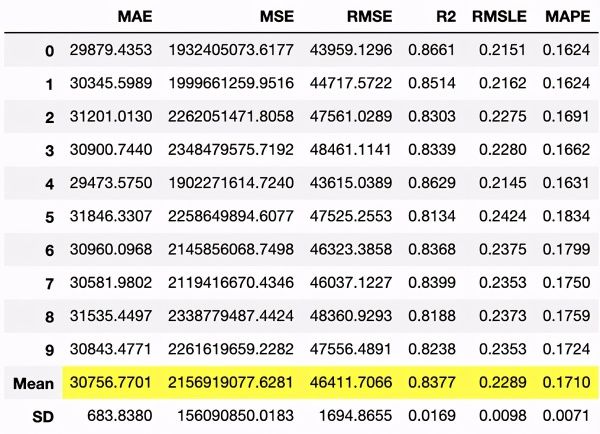
create_model函数使用训练后的CatBoost模型的交叉验证指标来生成上面的数据框。
超参数调整
现在我们有了训练有素的模型,我们可以通过超参数调整进一步优化它。只需一行代码,我们就可以调整该模型的超参数,如下所示。
tuned_catboost = tune_model(catboost, n_iter=50, optimize = 'MAE')
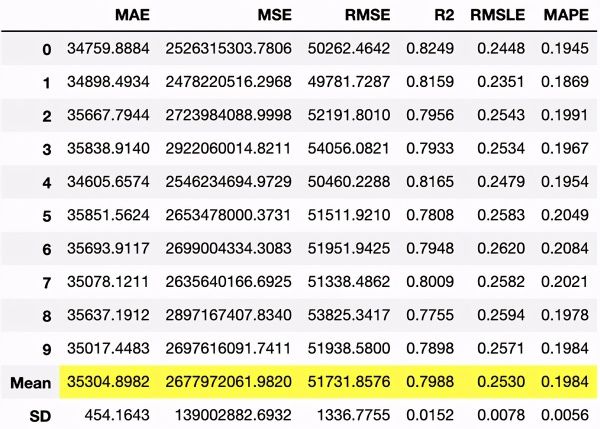
> Results of hyperparameter tuning with 10-fold cross-validation.
最重要的结果(在这种情况下为平均指标)以黄色突出显示。
可视化模型的性能
我们可以使用PyCaret创建许多图表,以可视化模型的性能。PyCaret使用另一个称为Yellowbrick的高级库来构建这些可视化文件。
残留图
默认情况下,plot_model函数将为回归模型生成残差图,如下所示。
plot_model(tuned_catboost)

> Residual plot for the tuned CatBoost model.
预测误差
通过创建预测误差图,我们还可以将预测值相对于实际目标值可视化。
plot_model(tuned_catboost, plot = 'error')

> Prediction error plot for the tuned CatBoost regressor.
上面的图特别有用,因为它为我们提供了CatBoost模型的R²系数的直观表示。在理想情况下(R²= 1),当预测值与实际目标值完全匹配时,此图将仅包含沿虚线的点。
功能重要性
我们还可以可视化模型的功能重要性,如下所示。
plot_model(tuned_catboost, plot = 'feature')
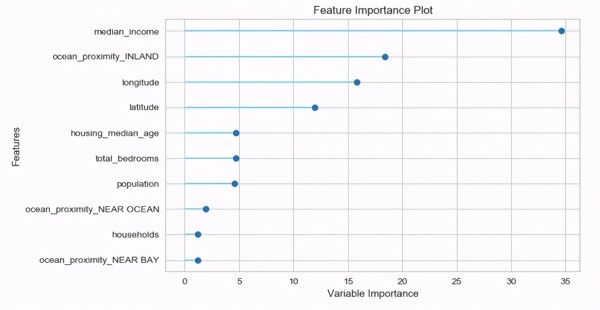
> Feature importance plot for the CatBoost regressor.
从上面的图可以看出,在预测房屋价格时,位数中位数是最重要的特征。由于此特征对应于房屋建造区域的中位数收入,因此此评估非常合理。在高收入地区建造的房屋可能比低收入地区的房屋贵。
使用所有图评估模型
我们还可以创建多个图,以使用validate_model函数评估模型。
evaluate_model(tuned_catboost)
> The interface created using the evaluate_model function.
解释模型
interpret_model函数是用于解释模型预测的有用工具。此函数使用一个称为SHAP的可解释机器学习库,我在下面的文章中介绍了该库。
仅需一行代码,我们就可以为模型创建一个SHAPE蜂群图。
interpret_model(tuned_catboost)
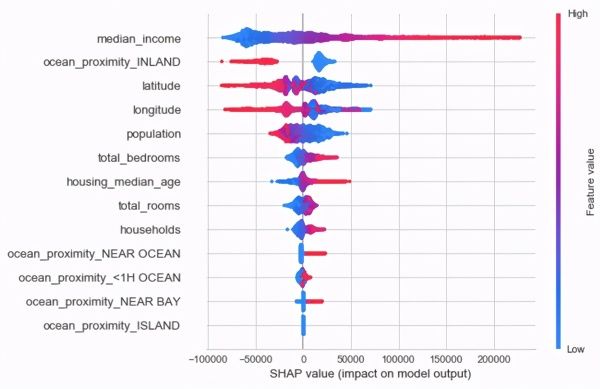
> SHAP plot produced by calling the interpret_model function.
根据上面的图,我们可以看到中位数收入字段对预测房屋价值的影响最大。
自动机器学习
PyCaret还具有运行自动机器学习(AutoML)的功能。我们可以指定我们要优化的损失函数或度量,然后让库接管如下所示。
automlautoml_model = automl(optimize = 'MAE')
在此示例中,AutoML模型也恰好是CatBoost回归变量,我们可以通过打印出该模型进行确认。
print(automl_model)
运行上面的print语句将产生以下输出:
< catboost.core.CatBoostRegressor at 0x7f9f05f4aad0 >
产生预测
预报模型功能允许我们通过使用来自实验的数据或新的看不见的数据来生成预测。
pred_holdouts = predict_model(automl_model)
pred_holdouts.head()
上面的predict_model函数为交叉验证期间用于验证模型的保持数据集生成预测。该代码还为我们提供了一个数据框,其中包含针对AutoML模型生成的预测的性能统计信息。
> Predictions generated by the AutoML model.
在上面的输出中,“标签”列表示由AutoML模型生成的预测。我们还可以对整个数据集进行预测,如下面的代码所示。
new_data = housing_data.copy()
new_data.drop(['median_house_value'], axis=1, inplace=True)
predictions = predict_model(automl_model, data=new_data)
predictions.head()
保存模型
PyCaret还允许我们使用save_model函数保存经过训练的模型。此功能将模型的转换管道保存到pickle文件中。
save_model(automl_model, model_name='automl-model')
我们还可以使用load_model函数加载保存的AutoML模型。
loaded_model = load_model('automl-model')
print(loaded_model)
打印出加载的模型将产生以下输出:
Pipeline(memory=None,
steps=[('dtypes',
DataTypes_Auto_infer(categorical_features=[],
display_types=True, features_todrop=[],
id_columns=[], ml_usecase='regression',
numerical_features=[],
target='median_house_value',
time_features=[])),
('imputer',
Simple_Imputer(categorical_strategy='not_available',
fill_value_categorical=None,
fill_value_numerical=None,
numer...
('cluster_all', 'passthrough'),
('dummy', Dummify(target='median_house_value')),
('fix_perfect', Remove_100(target='median_house_value')),
('clean_names', Clean_Colum_Names()),
('feature_select', 'passthrough'), ('fix_multi', 'passthrough'),
('dfs', 'passthrough'), ('pca', 'passthrough'),
['trained_model',
]],
verbose=False)
从上面的输出中可以看到,PyCaret不仅在流水线的末尾保存了经过训练的模型,还在流水线的开始处保存了特征工程和数据预处理步骤。现在,我们在一个文件中有一个可用于生产的机器学习管道,我们不必担心将管道的各个部分放在一起。
模型部署
现在我们已经准备好可以生产的模型管道,我们还可以使用deploy_model函数将模型部署到诸如AWS的云平台。如果打算将模型部署到S3存储桶,则在运行此功能之前,必须运行以下命令来配置AWS命令行界面:
aws configure
运行上面的代码将触发一系列提示,提示您需要提供诸如AWS Secret Access Key之类的信息。完成此过程后,就可以使用deploy_model函数部署模型了。
deploy_model(automl_model, model_name = 'automl-model-aws',
platform='aws',
authentication = {'bucket' : 'pycaret-ca-housing-model'})
在上面的代码中,我将AutoML模型部署到了AWS中名为pycaret-ca-housing-model的S3存储桶中。从这里,您可以编写一个AWS Lambda函数,该函数从S3中提取模型并在云中运行。PyCaret还允许您使用load_model函数从S3加载模型。
MLflow用户界面
PyCaret的另一个不错的功能是,它可以使用称为MLfLow的机器学习生命周期工具来记录和跟踪您的机器学习实验。运行以下命令将从本地主机在浏览器中启动MLflow用户界面。
!mlflow ui

> MLFlow dashboard.
在上面的仪表板中,我们可以看到MLflow可以跟踪您的PyCaret实验的不同模型的运行情况。您可以查看性能指标以及实验中每次运行的运行时间。
使用PyCaret的利与弊
如果您已经阅读了此书,则现在对如何使用PyCaret有了基本的了解。虽然PyCaret是一个很棒的工具,但它有其自身的优缺点,如果您打算将其用于数据科学项目,则应注意这一点。
优点:
低代码库。
非常适合简单的标准任务和通用机器学习。
为回归,分类,自然语言处理,聚类,异常检测和关联规则挖掘提供支持。
使创建和保存模型的复杂转换管道变得容易。
使可视化模型性能变得容易。
缺点:
到目前为止,由于NLP实用程序仅限于主题建模算法,因此PyCaret对于文本分类而言并不理想。
PyCaret不是深度学习的理想选择,并且不使用Keras或PyTorch模型。
您无法执行更复杂的机器学习任务,例如使用PyCaret(至少在版本2.2.0中)进行图像分类和文本生成。
通过使用PyCaret,您将在某种程度上牺牲对简单和高级代码的控制。
概括
在本文中,我演示了如何使用PyCaret完成机器学习项目中的所有步骤,从数据预处理到模型部署。尽管PyCaret是有用的工具,但是如果您打算将其用于数据科学项目,则应了解其优缺点。PyCaret非常适合使用表格数据进行通用机器学习,但是从2.2.0版本开始,PyCaret不适用于更复杂的自然语言处理,深度学习和计算机视觉任务。但这仍然是一种节省时间的工具,谁知道,也许开发人员将来会增加对更复杂任务的支持?
如前所述,您可以在GitHub上找到本文的完整代码。https://github.com/AmolMavuduru/PyCaretTutorial