项目实操四-性能测试过程实时监控分析

这里写目录标题
- 一、JMeter性能测试技巧
-
- 1、CSV文件驱动
- 2、定时器
-
- a、泊松随机定时器
- b、固定定时器
- c、高斯随机定时器
- d、均衡随机定时器
- e、同步定时器
- f、固定吞吐量定时器
- g、精准吞吐量定时器
- 3、全局变量 - 跨线程数据传递
- 4、Debug调试器
- 5、JMeter执行机端口被占用
- 二、JMeter性能测试结果查看三大方式
-
- 1、GUI界面报告+插件
-
- a、聚合报告
- b、汇总报告
- c、Basic Graphs图表
- 2、CLI命令行运行+HTML报表
-
- a、命令参数详解
- b、命令行的测试进度报告
- 3、后端监听器接仪表盘
- 三、InfluxDB+Grafana Jmeter测试监控大屏
-
- 1、整体架构梳理
- 2、Linux环境中InfluxDB安装与配置
- 3、JMeter后端监听器链接InfluxDB
-
- a、jmeter配置
- b、influxdb创建对应的数据库
- 4、Linux环境中Grafana环境搭建
-
- a、进入安装包所在目录执行命令
- b、解压
- c、启动
- d、启动命令
- e、工作中:后台启动
- f、web访问
- 5、Jmeter - InfluxDB -Grafana完整构建调试
-
- a、添加数据源
- b、配置大屏数据展示
- 6、常见问题
- 7、优点
- 四、性能测试领域细分概念:以目的进行划分
-
- 1、基准测试:理论推断
- 2、负载测试:实际性能数据(小规模)
- 3、压力测试:
- 4、耐久性测试(疲劳测试)(在压力测试和负载测试之间)
- 5、尖峰测试
- 五、业务流程性能测试
-
- 以流程:打开首页——》选择自己喜欢的小说为例
- 携带token的怎么处理?
一、JMeter性能测试技巧
1、CSV文件驱动
jmeter读取csv文件数据,一行一行的循环读取
单线程、多线程都是一致的
当读取最后一条后,会从头开始继续读取

2、定时器
a、泊松随机定时器


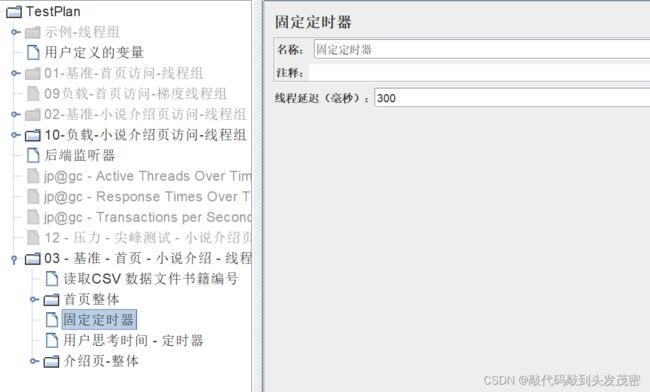
b、固定定时器
通过Thread Delay设定每个线程请求之前的等待时间(单位为毫秒)。注意:固定定时器的延时不会计入当前sampler的响应时间里,但是会计入事务控制器的时间。 对于事务控制器来说,定时器相当于loadrunner中的think time(思考时间:实际操作中,模拟真实用户在操作过程中的等待时间)
通常所说的响应时间,大部分情况下是针对某一个具体的sampler (http请求),而不是针对一组sampler组合的事务。
c、高斯随机定时器
如果需要每个线程的延迟时间是符合标准正态分布的随机时间停顿,那么使用这个定时器,总延迟=高斯分布值(平均Q.O和标准偏差1.0)*指定的偏差值+固定延迟偏移
(Math.abs((this.random.nextGaussian()*偏差值)+固定延迟偏移))

d、均衡随机定时器

e、同步定时器
作用:阻塞线程,直到指定的线程数量到达后,再一起释放,可以瞬间产生很大的压力

f、固定吞吐量定时器

g、精准吞吐量定时器

3、全局变量 - 跨线程数据传递

用到了Jmeter元件:
计数器:记录当前执行的是第几次,并通过 number 变量保存
JSON提取器:提取登录接口响应体中的token
BeanShell断言:将token设置为全局变量,可以跨线程组使用
HTTP Cookie管理器:提取上面保存的全局变量
4、Debug调试器
查看Jmeter变量以及属性

5、JMeter执行机端口被占用

二、JMeter性能测试结果查看三大方式
1、GUI界面报告+插件
缺点:界面模式运行,会额外占用(脚本执行机器)更多的资源
既要模拟对服务器发起请求,还要汇总页面、图片、图标、统计数据。CPU是有限的
jmeter作为施压机 - 核心工作 - 模拟并发
实时做统计,导致并发效果不能匹配性能场景
a、聚合报告

90%百分位:表示1000个请求有900个请求的响应时间是小于等于36毫秒
95%百分位:表示1000个请求有950个请求的响应时间是小于等于60毫秒返回
99%百分位:表示1000个请求有990个请求的响应时间小于等于135毫秒返回,有10个请求的响应时间大于135毫秒
90%百分位、95%百分位、99%百分位:各个响应时间段的占比
聚合报告相比较汇总报告,多了三个响应时间分布信息
中位数:表示有1000个请求,其中有500个请求小于等于27毫秒,相当于分界线。
b、汇总报告
具体各个字段的说明在上一篇文章

c、Basic Graphs图表

2、CLI命令行运行+HTML报表
这个命令会生成html报表
jmeter -n -t[jmx file] -l [results file] -e -o [Path to web report folder]
a、命令参数详解
-n:在非GUI模式下运行Jmeter
-t:测试文件
要运行的jmeter测试文件(.jmx).
“-t LAST”:将最后加载用过的文件
-l:日志文件,要将样本记录到文件,例如test001.jtl
-e:–报告的ndofloadtests,负载测试后生成报告仪表盘
-o:保存html报告的路径,此文件夹必须为空或者不存在
b、命令行的测试进度报告

我们通常会在一个linux机器上面去执行
缺点:命令行去运行—推荐的;但是:最终要生成测试结果报告,虽然没有UI界面那么大的消耗,但是依然会有资源压力;
最大的缺点:当测试时间很长时,我们并不能实时的监控
当我们对系统进行12个小时的测试时,但是第1个小时就出现问题,此时并不能看出问题。等12个小时后里面出现几十万次报错,此次测试没用,
测试机器有问题;测试应该停止,而不能继续测试。
3、后端监听器接仪表盘
常用的方案
InfluxDB+Grafana
三、InfluxDB+Grafana Jmeter测试监控大屏
1、整体架构梳理
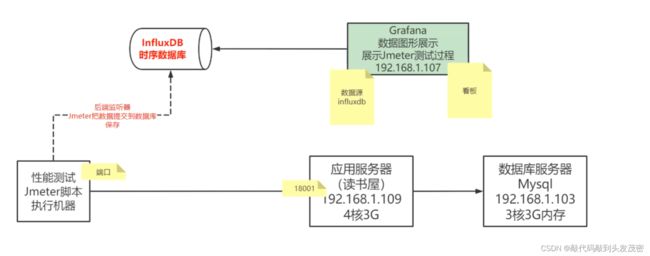
2、Linux环境中InfluxDB安装与配置
https://blog.csdn.net/YZL40514131/article/details/134933846
3、JMeter后端监听器链接InfluxDB
a、jmeter配置

b、influxdb创建对应的数据库
1、第一步:在influxdb服务器上面,输入influx命令进入influx
2、第二步:influx中输入语句:创建jmeter数据库
create database jmeter;
3、第三步:退出influx
quit

注意事项influxdb与jmeter之间一定要网络互通
如果是虚拟机或者其他linux最好关闭防火墙
4、Linux环境中Grafana环境搭建
a、进入安装包所在目录执行命令
root@hecs-213321:~/performance_testing/monitor# tar -zxvf grafana-9.0.0.linux-amd64.tar.gz
b、解压
root@hecs-213321:~/performance_testing/monitor# ls
grafana-9.0.0 influxdb_1.8.0-2_amd64.deb prometheus-2.36.1.linux-amd64.tar.gz
grafana-9.0.0.linux-amd64.tar.gz influxdb-1.8.0.x86_64.rpm
c、启动
cd grafana-9.0.0
记得启动相关的命令,在解压后的文件夹里面
例如
root@hecs-213321:~/performance_testing/monitor/grafana-9.0.0#
d、启动命令
root@hecs-213321:~/performance_testing/monitor/grafana-9.0.0# ./bin/grafana-server web
停止:ctrl+c
关闭ssh窗口,程序就停止了
e、工作中:后台启动
nohup ./bin/grafana-server web > grafana-server.log 2>&1 &
root@hecs-213321:~/performance_testing/monitor/grafana-9.0.0# nohup ./bin/grafana-server web > grafana-server.log 2>&1 &[1] 3481095
root@hecs-213321:~/performance_testing/monitor/grafana-9.0.0# ls
bin conf data grafana-server.log LICENSE NOTICE.md plugins-bundled public README.md scripts VERSION
f、web访问
http:ip:3000
默认端口3000
默认用户名和密码都是admin
5、Jmeter - InfluxDB -Grafana完整构建调试
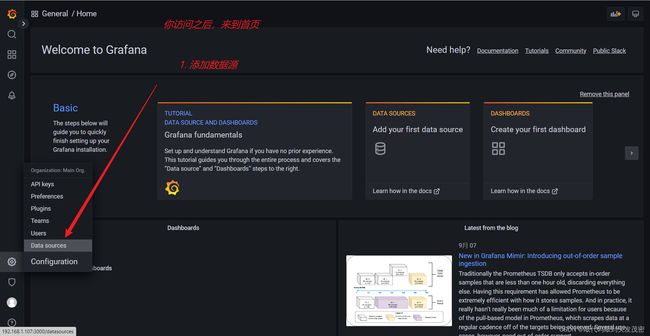
a、添加数据源
选择InfluxDB
配置InfluxDB地址

配置InfluxDB对应的表和访问方式
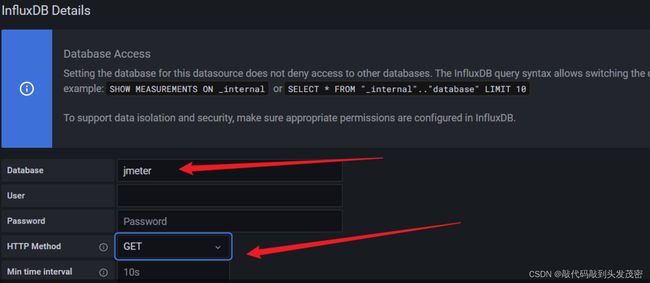
b、配置大屏数据展示
导入模板

导入json文件

配置模板

6、常见问题
1、网络不通,检查网络IP是否写对,防火墙是否关闭
2、jmeter里面的influxdb地址里面的db=jmeter:和你在influxdb里面创建的数据库一致
3、后端监听器里面measurement:默认携程jmeter和grafana监控大屏模板相对应

7、优点
横向对比多次性能测试数据
长时间测试,能够实时监控性能测试执行情况
四、性能测试领域细分概念:以目的进行划分
1、基准测试:理论推断
目的:平时负载情况,资源占用情况
2、负载测试:实际性能数据(小规模)
目的:想知道一个系统在多少并发的时候会出现问题,这个问题不只是资源的问题,
基准测试和负载测试共同目的是,探索程序的负载能力
3、压力测试:
取负载测试结果中的最高负载能力-压测
取超出预期负载的测试,看程序的性能反应
4、耐久性测试(疲劳测试)(在压力测试和负载测试之间)
压力测试所持续时间----体现到耐久性
取决于业务场景
生成环境高并发压力,一天中的某几个小时,钉钉打卡(小时为单位,24小时/12小时)
全天都有压力,以天为单位(3天/7天)
5、尖峰测试
模拟突然出现的高并发负载,观察程序在这种情况下出现的反应
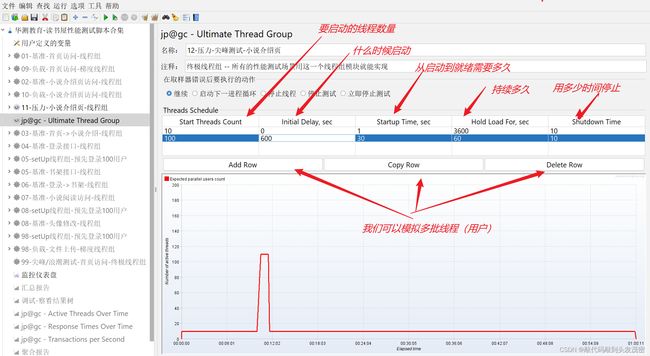
压力测试、耐久性测试、尖峰测试是为了探索程序在高负载情况下的反应
我们作为基准测试,通过基准测试得到负载测试大概率的线程数量通过负载测试,我们可以简单的分析到系统的性能瓶颈达到了,以50ms为响应时间为例,当响应时间小于50ms表示系统性能没有问题。如果超过了50ms代表系统的瓶颈到了,这个时候我就能知道当前线程数为多少。
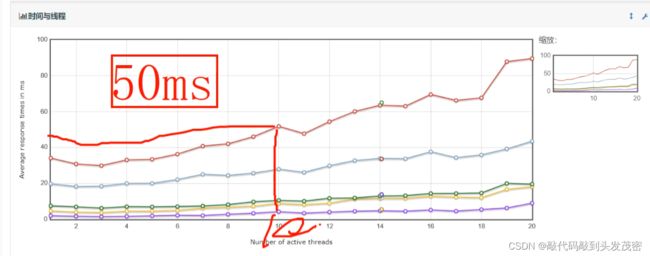
接着拿着这个线程数据去做压力测试,观察这10个线程能不能长期稳定的低于50ms。
五、业务流程性能测试
以流程:打开首页——》选择自己喜欢的小说为例
用户真实操作:打开首页(多个接口加载)——》介绍页打开(多个接口加载)
但是:从首页到小说介绍页——》需要用户思考时间
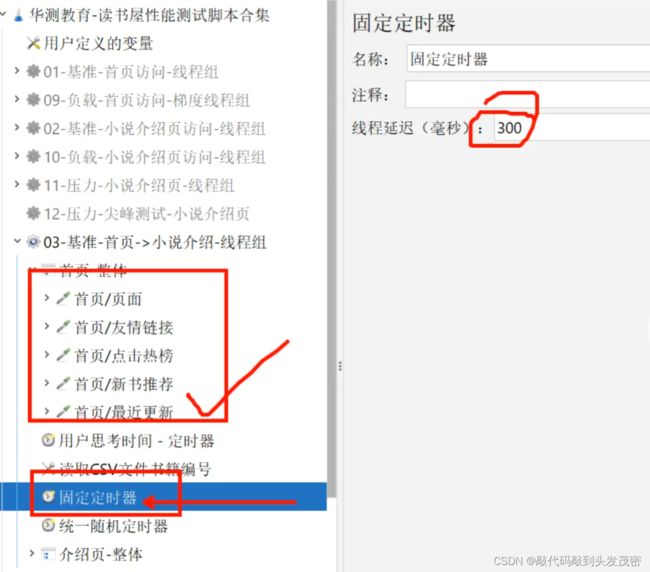
添加定时器
首页与介绍页之间添加1个定时器

通常用到2个定时器
固定定时器
统一随机定时器
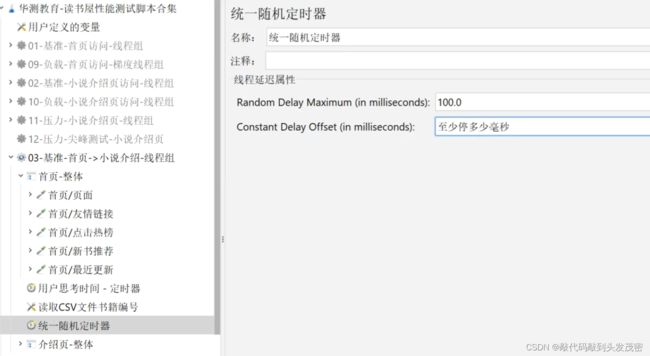
携带token的怎么处理?
例如:访问书架接口,有个前提:先登录
前置条件:100个已登录的账户,线程数为1,循环1000次,访问书架
线程组目录如下
操作步骤:
1、新建setUp线程组 - 预先登录100个用户
设置1个线程,循环100次


2、添加CSV数据文件设置,提前准备好用户名表
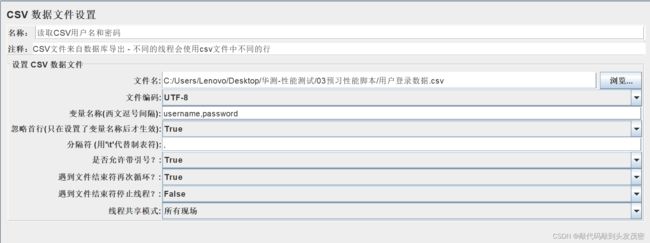
3、添加登录接口

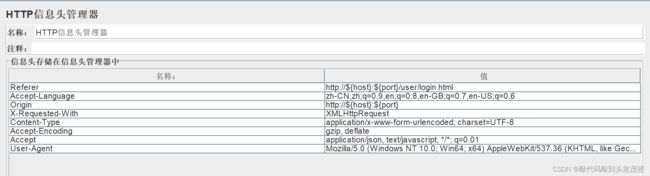
4、添加HTTP信息头管理器
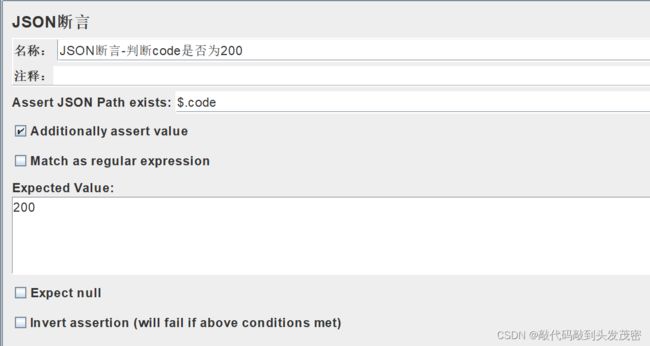
5、添加JSON断言
6、添加JSON提取器
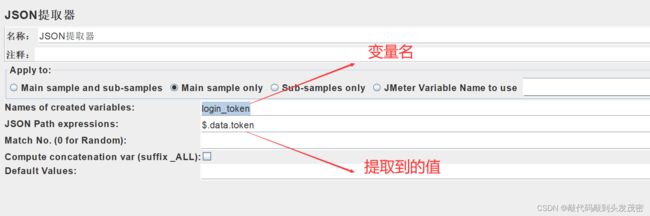
JSON提取器提取的数据不能跨线程使用
变量名login_token:不能跨线程组使用
需要用到BeanShell,将login_token保存为全局变量,共享给其他的线程组
这里有100个login_token保存100个全局属性
7、添加BeanShell断言
将Json提取器中的变量设置为全局变量,目的是跨线程组使用

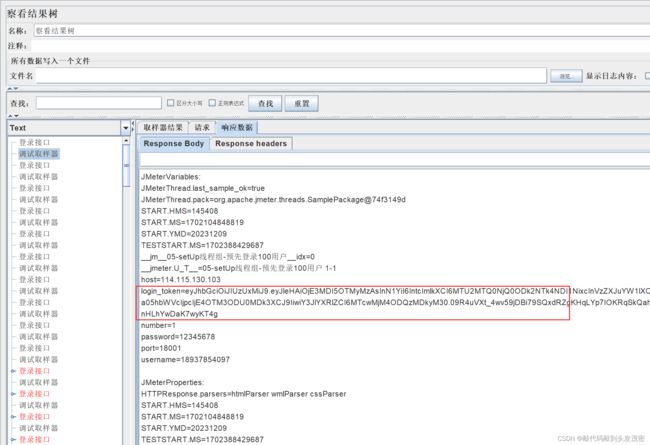
8、添加调试取样器
JMeter属性设置为True
可以查看jmeter的运行信息,例如设置的全局变量

9、添加计数器
记录当前执行的是第几次,并通过 number 变量保存

10、新增书架接口线程组

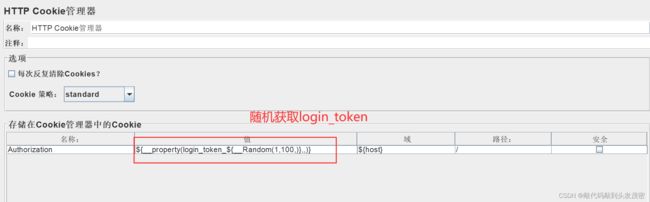
11、线程组下新建HTTP取样器

12、添加HTTP Cookie管理器
13、添加HTTP信息头管理器

14、添加JSON断言

面试:
当时负责什么模块?怎么设计性能测试用例的?
业务流程怎么测试的?
定时器:用户思考时间
登录接口怎么做的?
模拟多少用户登录?
登录完成后去压测某一个接口
用了哪些组件?
怎么去跨线程组共享变量的?