- Item 1
- Item 2
- Item 3
网络爬虫第1天之数据解析库的使用
一、正则表达式
正则表达式(Regular Expression 简称regex或regexp)是一种强大的文本处理工具,它可以帮助实现快速的检索、替换或验证字符串中的特定模式。
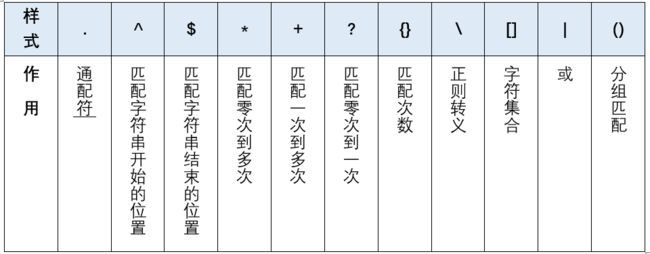

1、match
match()方法会尝试从字符串开始的位置到字符结束的位置匹配正则表达式,如果匹配,返回匹配的结果,不匹配返回None。
import re
content = 'Hello 123456 welcome to tuling'
print(len(content))
result = re.match('Hello\s\d\d\d\s\d{3}\w{9}',content)
print(result)
print(result.group())
pritn(result.span())
# group()返回本正则匹配的字符串
# start()返回匹配开始的位置
# span()返回一个元组包含匹配(开始,结束)的位置(1)匹配数字
import re
content = 'Hello 123456 welcome to tuling'
print(len(content))
result = re.match('Hello\s\d\d\d\s\d{3}\w{9}',content)
print(result)
print(result.group())
pritn(result.span())
# group()返回本正则匹配的字符串
# start()返回匹配开始的位置
# span()返回一个元组包含匹配(开始,结束)的位置(2)通用匹配
import re
content = 'Hello 123 456 welcome to tuling'
result = re.match('^Hello\s(\d+)\swelcome',content)
print(result)
print(result.span())(3)贪婪和非贪婪
python默认贪婪模式(匹配的更多)
在“*”,“?”,“+”,“{m,n}”后面加上?,使贪婪变成非贪婪
import re
concent = 'https://feier.com/yyds'
result1 = re.match('http.*?com/(.*?)',content)
result2 = re.match('http.*?com/(.*)',content)
print('result1:',result1.group()) #输出:result1: https://feier.com/
print('result2:',result2.group()) #输出:result2: https://feier.com/yyds(4)修饰符

2、search
匹配时会扫描整个字符串,然后返回第一个匹配成功的结果,如果搜索完还没有找到,就返回None。

二、PyQuery
PyQuery 是一个用于解析HTML和XML文档的Python库,它提供了与jQuery类似的语法,使得从文档中提取信息变得简单快捷。PyQuery 是基于lxml的 etree 库构建的,因此它速度很快,并且可以处理复杂的XML/HTML文档。
使用PyQuery具体步骤如下:
安装PyQuery
首先,你需要安装 PyQuery。通常可以通过pip来安装(使用国内阿里镜像源):
如果以后安装不想输入 -i Simple Index
可以配置pip.ini文件,具体步骤如下:https://mp.csdn.net/mp_blog/creation/editor/135030143
pip install pyquery -i http://mirrors.aliyun.com/pypi/simple/使用PyQuery解析HTML
一旦安装了 PyQuery,你就可以开始使用它来解析HTML或XML了。下面是一个简单的例子:
在这个例子中,pq(html) 创建了一个 PyQuery 对象,然后我们使用CSS选择器 'p' 来查找所有的标签。
from pyquery import PyQuery as pq
# 定义一个HTML字符串
html = """
Hello
World
"""
# 创建PyQuery对象
d = pq(html)
# 查找所有的标签
paragraphs = d('p')
for p in paragraphs.items():
print(p.text())
print(p)
#输出
'''
Hello
Hello
World
World
'''使用PyQuery从网络获取内容
PyQuery 也可以直接从网址或者文件加载内容,例如:
from pyquery import PyQuery as pq
# 从网址获取内容
d = pq(url='http://example.com/')
# 从文件获取内容
# d = pq(filename='path/to/your/file.html')
# 使用CSS选择器
h1 = d('h1').text()
print(h1)
# 输出 Example Domain使用PyQuery进行更高级的选择和操作
PyQuery 支持多种CSS选择器和各种操作,例如:
from pyquery import PyQuery as pq
html = """
"""
d = pq(html)
# 查找第一个li元素
first_li = d('li:first')
print(first_li.text())
# 查找ID为"unique-item"的元素
unique_item = d('#unique-item')
print(unique_item.text())
# 找到所有 class 包含 active 的 li 元素
active_items = d('li.active')
for item in active_items.items():
print(item.text())
# 查找 href 为 "link3.html" 的 a 元素的父元素
parent_li = d('a[href="link3.html"]').parent()
print(parent_li.attr('class'))
'''
输出:
item 1
item 3
item 2
item 4
item-0
'''PyQuery 的强大功能使其成为处理复杂HTML/XML文档时的一个良好选择,尤其对于那些已经熟悉jQuery语法的开发者。
三、Xpath
XPath(XML Path Language)是一种在XML和HTML文档中查找信息的语言。它使用路径表达式来选取文档中的节点或节点集。XPath 由 W3C 作为一个标准发布,被广泛应用于各种XML解析和处理技术中,比如在XSLT(Extensible Stylesheet Language Transformations)中选取数据,或者在Python的lxml库中解析HTML文档。
插件下载:https://chorme.zzzmh.cn/index
XPath 语法允许你指定文档的结构,以便精确选取出你想要的节点,比如元素、属性、文本等。一些基本的XPath选择器包括:
nodename: 选取此节点的所有子节点。/: 从根节点选取。//: 从匹配选择的当前节点选择文档中的节点,不考虑它们的位置。.: 选取当前节点。..: 选取当前节点的父节点。@: 选取属性。
例子
下面是一些XPath表达式的例子及其描述:
/bookstore: 选取根元素bookstore。只有bookstore元素才能被选取。bookstore/book: 选取属于bookstore子元素的所有book元素。//book: 选取所有book子元素,而不管它们在文档中的位置。bookstore//book: 选取属于bookstore元素的后代的所有book元素,而不管它们位于bookstore下的什么位置。//@lang: 选取名为lang的所有属性。
在Python中,可以使用lxml库来执行XPath查询。下面是如何使用lxml和XPath来解析HTML文档的一个例子:
from lxml import etree
# 假设我们有以下HTML文档
html_content = """
"""
# 解析HTML内容
tree = etree.HTML(html_content)
# 使用XPath选取所有的元素
items = tree.xpath('//li')
for item in items:
print(item.text) # 输出: Item 1, Item 2, Item 3
# 使用XPath选取id为"list"的元素下的所有子节点
list_items = tree.xpath('//ul[@id="list"]/li')
for item in list_items:
print(item.text) # 输出: Item 1, Item 2, Item 3
# 使用XPath获取class为"footer"的div的文本
footer = tree.xpath('//div[@class="footer"]/text()')[0]
print(footer) # 输出: Footer information
在上述例子中,我们使用lxml.etree.HTML函数将HTML字符串解析为一个元素树,然后利用xpath方法来执行XPath查询。这是在Python中进行XML和HTML文档处理时的一种常见做法。
四、Beautiful Soup
Beautiful Soup是一个用于从HTML和XML文件中提取数据的Python库。它创建了一个解析树,这便于开发者能够轻松地搜索和修改解析树。Beautiful Soup自动将输入文档转换为Unicode编码,并输出有效的HTML/XML。它适用于多种解析器,如Python标准库中的html.parser、lxml和html5lib。
安装 Beautiful Soup
首先,你需要安装Beautiful Soup库,通常可以通过pip来安装:
pip install beautifulsoup4
使用 Beautiful Soup 解析HTML
安装完成后,你就可以开始使用Beautiful Soup来解析HTML了。下面是一些基本用法的例子:
from bs4 import BeautifulSoup
# 定义一个HTML字符串
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
# 创建一个Beautiful Soup对象
soup = BeautifulSoup(html_doc, 'html.parser')
# 获取标签的内容
title_tag = soup.title
print(title_tag) # 输出: <title>The Dormouse's story
print(title_tag.string) # 输出: The Dormouse's story
# 查找文档中所有的标签
a_tags = soup.find_all('a')
for tag in a_tags:
# 输出每个标签的href属性
print(tag.get('href'))
# 查找文档中所有类属性为"sister"的标签
sisters = soup.find_all('a', class_='sister')
for sister in sisters:
# 输出sister的文本内容
print(sister.string)
在这个例子中,我们使用了BeautifulSoup(html_doc, 'html.parser')来创建一个Beautiful Soup对象。然后我们使用了.title来获取标题标签和.find_all()方法来获取所有的标签。
使用不同的解析器
Beautiful Soup支持不同的解析器,这里是如何选择解析器的例子:
html.parser: 使用Python内置的HTML解析器。lxml: 使用lxml的HTML解析器。lxml-xml: 使用lxml的XML解析器。html5lib: 使用html5lib解析器,它会像浏览器一样解析HTML。
# 使用lxml解析器来创建Beautiful Soup对象
soup = BeautifulSoup(html_doc, 'lxml')
# 其他用法与html.parser相同
请注意,使用lxml或html5lib可能需要你先安装这些库(可以使用pip安装)。
pip install lxml
pip install html5lib
Beautiful Soup库在爬虫和数据挖掘中非常有用,因为它可以轻松处理网页中的复杂元素和嵌套。