【扩散模型】8、DALL-E2 | 借助 CLIP 的图文对齐能力来实现文本到图像的生成

文章目录
-
- 一、背景
- 二、方法
-
- 2.1 Decoder
- 2.2 Prior
- 三、图像控制
-
- 3.1 Variations
- 3.2 Interpolations
- 3.3 Text Diffs
- 四、探索 CLIP 的潜在空间
- 五、文本到图像的生成
-
- 5.1 先验的重要性
- 5.2 人类评价
- 5.3 多样性和保真性的平衡
- 5.3 在 COCO 上对比
论文:DALLE.2
代码:https://github.com/lucidrains/DALLE2-pytorch
出处:OPENAI
时间:2022.08
DALLE-2 的关键过程:
- 给定一个文本,先用clip模型生成一个文本特征,这一步是固定的,这里的clip模型是锁死的,接下来就到了两阶段模型
- 第一阶段:根据文本特征生成图像特征(prior),当然clip在这里也有用,因为clip生成的图像特征是要用做 ground truth 的。
- 第二阶段:一旦有了图像特征,就需要decoder来生成最后的图像,就完成了从文本到图像的过程。
一、背景
使用类似于 CLIP 的对比学习的模型已经被证明能够很好的学习图像的表达,也能够捕捉语义和风格特征,所以能不能将 CLIP 和扩散模型结合起来,实现文本控制的图像或视频生成呢
本文作者就将这两个方法结合起来,来解决 text-conditional 图像的生成
- 训练一个 diffusion decoder 来逆转 CLIP 图像编码器。这个逆转过程是非确定性的,也就是说,对于给定的图像嵌入(embedding),它可以生成多个对应的图像。逆转的意思就是将 CLIP 抽取图像特征的过程反过来,从特征恢复图像。
- 使用 CLIP 的一个好处在于可以通过语音描述来控制生成的图像的特征
- 为了得到完整生成模型, 作者将 CLIP 的 image embedding decoder 与先验模型结合起来, 根据给定的 text caption 来生成 CLIP image embedding
作者把本文提出的 text-conditional image generation 方法称为 unCLIP,因为这种生成方法其实是 CLIP image encoder 的逆过程
unCLIP模型基于"Contrastive Language–Image Pretraining"(对比语言-图像预训练)技术,这也就是“CLIP”的来源。然而,“un”表示“解开”,所以“unCLIP”实际上意味着该模型可以逆向工作,即不仅可以从文本生成相关图像,还能从图像生成相关文本。
例如,如果你给unCLIP一个描述性词句(如"太阳下山了"),它可能会产生一个与描述匹配的图片。相反地,如果你给它一张图片(如一张夕阳照片),它可能会生成一个描述该图片内容的句子。
二、方法
训练数据:图像 x 和 文本描述 y 组成的 pairs (x,y)
给定 image x x x,CLIP 的 image 和 text embedding 分别为 z i z_i zi 和 z t z_t zt
本文生成过程包括两个部分:
- prior P ( z i ∣ y ) P(z_i|y) P(zi∣y):这是一个条件概率,表示在给定文本描述 y y y 时产生 CLIP image embedding z i z_i zi 的概率。使用文本输入 CLIP 的 text encoder 之后,会得到文本特征,这里的 prior 就是根据这个文本特征来预测对应的图像特征。
- decoder P ( x ∣ z i , y ) P(x|z_i,y) P(x∣zi,y):这个解码器接收 prior 预测到的 CLIP image embedding z i z_i zi 以及可选地接收文本描述,然后生成相应的图像 x x x。也就是根据编码来生成图片
根据这两个过程,可以得到在给定文本描述 y 时,产生图像 x 的概率
![]()
-
P ( x ∣ y ) P(x|y) P(x∣y): 这表示在给定文本描述 y 时,产生图像 x 的概率。也就是说,如果你有一个文本描述(比如"一只黑色的猫在跳跃"),这个模型能够生成符合这个描述的图像。
-
P ( x , z i ∣ y ) = P ( x ∣ z i , y ) P ( z i ∣ y ) P(x, zi | y) = P(x|zi , y)P(zi | y) P(x,zi∣y)=P(x∣zi,y)P(zi∣y): 这里使用了贝叶斯规则来分解上述概率。在给定文本 y 时,产生图像 x 和嵌入zi 的联合概率可以分解为:在给定 image embedding z i z_i zi 和文本 y 时产生图像 x 的条件概率(由解码器计算)和在给定文本 y 时产生 image embedding z i z_i zi 的条件概率(由先验计算)。
-
P(x|zi, y):这部分是由解码器提供的,在已知 CLIP image embedding z i z_i zi 和文本描述 y y y 的情况下,生成图片 x x x 的条件概率。
-
P(zi | y):这部分是先验,在已知文字说明 y 情况下得到 CLIP 图片嵌入 z i z_i zi 的条件概率。
-
通过将两者相乘,可以得到完整模型 P ( x ∣ y ) P(x|y) P(x∣y),它可以根据输入语句生成相关联且符合该语句内容的图片。
2.1 Decoder
作者借鉴了 GLIDE 的结构,将 CLIP embedding 加到了 timestep embedding 中,且将 CLIP embedding 映射到了 4 个 额外的 token,和 GLIDE 的text encoder 输出进行 concat。
虽然可以直接从解码器条件分布进行采样,但过去使用扩散模型工作表明使用 conditional information 指导能够大大改善样本质量。所以本文中通过随机将 CLIP embedding 设为零,并在训练期间随机丢弃 50% 的文本字幕来实现无分类器指导。
为了生成高分辨率图像,作者训练两个扩散上采样模型:一个用于从64×64上采样至256×256分辨率图像;另一个进一步把那些图像上采样至1024×1024分辨率。为提高上采样器稳健性,在训练期间轻微破坏图片。对于第一个上采样阶段, 使用高斯模糊, 对于第二个阶段, 我们使用更多元化BSR降级处理。
为减少训练的计算和提高数值稳定性, 我们按照Rombach等人[42]建议在目标尺寸四分之一大小随机裁剪图片进行培训. 在模型里我们只用空间卷积 (也就是说不包含注意力层),并且在推断时直接应用目标解析度下的模型,观察它是否能很好地适应更高解析度。
2.2 Prior
虽然 decoder 可以通过 CLIP 的逆向操作来从 image embedding z i z_i zi 生成图像 x x x,但还需要一个先验模型来从文本输入 y y y 中来预测出需要用到的 image embedding z i z_i zi。
作者对比了两种不同的先验模型:
- 自回归先验 Autoregressive (AR) prior:将CLIP图像嵌入 z i z_i zi 转换为一系列离散编码,并在 y y y 的条件下自回归预测。
- 扩散先验 Diffusion prior:直接使用以标题 y y y 为条件的高斯扩散模型对连续向量 z i z_i zi进行建模。
CLIP 的 text embedding z t z_t zt 也可以用作 condition prior
为了提高样本质量,作者在训练过程中随机丢弃10%的文本条件信息,以实现 classifier-free guidance 的AR和扩散先验采样。
对于 AR 先验:
-
为了更有效地训练和从AR先验中采样,首先通过应用主成分分析(PCA)[37]来降低CLIP图像嵌入zi的维度。当使用SAM [15] 训练CLIP时,CLIP 表示空间的秩大幅降低,并略微改善评估指标。通过只保留原始1024个主成分中的319个主成分,能够保留几乎所有信息。
-
使用 PCA 后,按照特征值大小递减顺序排列主成分,并将每个319维度量化到1024个离散桶内,并使用带有因果注意力掩码的Transformer [53]模型预测生成序列。这使得推理期间预测 token 数量减少三倍,并提高了训练稳定性。
-
将文本标题和 CLIP embedding 作为前缀以控制 AR 先验。此外, 在序列前加上一个标记, 标记表示文本嵌入与图像嵌入之间(量化)点积, zi · zt. 这使得模型可以依赖更高点积进行条件设置, 因为更高文字-图片点积对应于更好地描述图片的标题
-
在实践中, 作者发现从顶部一半的分布中抽取点积更好
对于扩散先验:
-
在一个序列上训练了一个只有 decoder-only 的 Transformer模型,该序列包含:encoded text、CLIP text embedding、扩散时间步长的嵌入、带噪声的 CLIP image embedding,以及从 Transformer 中输出用于预测无噪声的 CLIP image embedding。
-
通过生成两个 zi 样本并选择与 zt 点积更高的那个来提高采样时质量。对此预测使用均方误差损失:
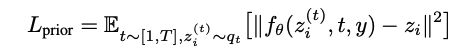
三、图像控制
本文的方法可以将任何给定的图像 x x x 编码为一个双边潜在表达 ( z i , x T ) (z_i, x_T) (zi,xT):
- z i z_i zi:使用 CLIP 的 image encoder 编码得到的图像特征
- x T x_T xT:使用 diffusion decoder 得到的生成的结果(conditioning on z i z_i zi)
作者这里展示了 3 种不同的方式
3.1 Variations
给定图像 x x x,可以通过语言描述来让模型生成和主要元素有关但方向或形状不同的图像
实现的方式就是使用 DDIM 作为扩散模型,使用 η > 0 \eta>0 η>0 来控制采样:
- η = 0 \eta=0 η=0 时,扩散模型解码器就是确定的,会产生和原图一样的图片
- η \eta η 越大,就会对采样引入一定的随机性,产生一些变体
3.2 Interpolations
本文方法也支持将两张图片混合,通过将两个图片变换到 CLIP image embedding space 然后通过球面混合来实现
![]()
θ \theta θ 从 0 到 1,控制着两个图片的。球面插值(slerp)就像一个平滑过渡器,它能帮助我们从苹果(zi1)平滑过渡到香蕉(zi2)。θ值从0到1改变时,我们可以得到中间的各种"混合水果"状态。
-
第一种方法就是在原始图像对应的DDIM反向潜变量之间进行类似上述球面插值般地过度, 这样会得到一个连续轨迹且起点为苹果、终点为香蕉.
-
第二种方法则更随机:对于每次插入新元素(即新生成的“混合水果”图片),都采取随机选择其 DDIM 潜在值。虽然最后得出来结果可能不再完全符合原始图像(可能看起来既不太象苹果也不太象香蕉),但却能生成无数条独特且多样化的路径.
3.3 Text Diffs
使用 CLIP 和其他方法最大的不同就在于 CLIP 可以把 image 和 text 映射到同一隐空间,所以可以支持使用 language-guided 来控制图像的修改
为了根据文本描述 y y y 来修改图片,首先获取这个 y y y 对应的 text embedding z t z_t zt,同时也获得当前图片对应的 CLIP text embedding z t 0 z_{t_0} zt0,计算 text diff z d = n o r m ( z t − z t 0 ) z_d=norm(z_t-z_{t_0}) zd=norm(zt−zt0)。然后使用球面插值来产生中间的 CLIP representation,使用 DDIM 生成对应的图片即可。球面插值公式如下:
![]()
四、探索 CLIP 的潜在空间
diffusion decoder 的存在,使得可以直接可视化 CLIP 图像编码器所看到的内容,来探索CLIP潜在空间。作为一个示例用例,我们可以重新审视那些CLIP做出错误预测的情况,比如文字攻击[20]。
在这些反面例子中,一段文字被覆盖在物体上面,导致CLIP预测出文字描述的物体而不是图像中描绘的物体。这段文字实际上在输出概率方面隐藏了原始对象。在图 6 中,我们展示了来自[20]的这种攻击的一个例子,在其中一个苹果可能被误分类为iPod。令人惊讶的是,尽管“Granny Smith”(一种苹果)被预测为近乎零概率事件, 我们发现我们的解码器仍然以很高概率生成苹果图片。此标题(指iPod)有非常高相对预测概率, 但模型从未产生过iPod图片.
PCA重构提供了另一种探索 CLIP 潜在空间结构的工具。在图7中,使用少量源图片的 CLIP 图像嵌入,并使用逐渐增加的 PCA 维度进行重构,然后使用我们的解码器和 DDIM 在固定种子上可视化重构的图像嵌入。这使我们能够看到不同维度编码的语义信息。我们观察到早期PCA维度保留了粗粒度语义信息,例如场景中有哪些类型的物体,而后期PCA维度则编码了更为精细的详情,如物体形状和确切形式等。例如,在第一个场景中,早期维度似乎编码了存在食物和可能存在容器这样的信息,而后面几个维度明确地编码了西红柿和瓶子等特定元素。
五、文本到图像的生成
5.1 先验的重要性
使用 UNCLIP的效果最好,仅使用 caption 作为条件的效果最差,在实验中对 AR 和 diffusion priors 进行了比较,发现 diffusion prior 更胜一筹。
5.2 人类评价
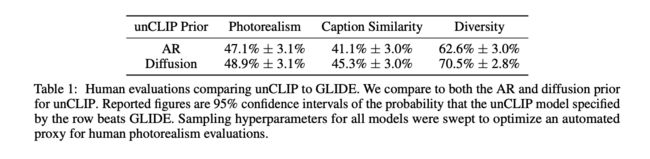
5.3 多样性和保真性的平衡

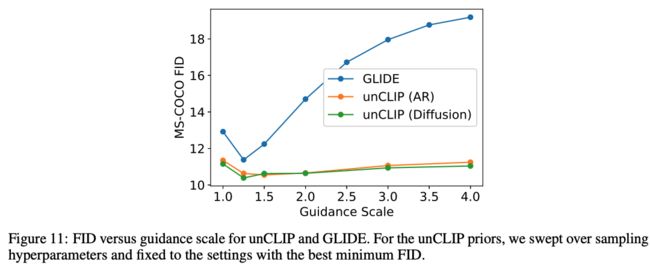
5.3 在 COCO 上对比