cURL命令详解
cURL是什么
cURL是用于数据传输的命令行工具,支持多种传输协议,包括HTTP、HTTPS、SCP、FTP、SFTP、TELNET、FILE、SMTP、POP3等等。可以使用cURL进行HTTP/HTTPS请求、上传/下载文件等,且支持Cookie、用户身份验证、代理支持、限速等。
参数解析
curl [options] [URL...]
-A/--user-agent <string> 设定使用者的代理发送给服务器
-b/--cookie <name=string/file> 设置cookie文件的读取位置
-c/--cookie-jar <file> 操作结束后把cookie写入到指定文件中
-C/--continue-at <offset> 断点续传
-d/--data "data" 携带HTTP POST请求的data
-D/--dump-header <file> 把header信息写入到指定文件中
-e/--referer 带入来源网址
-F/ 上传二进制文件,也可以当做-d来用
-H/--header 设定请求头
-i/--include 在输出中显示header
-K:指定配置文件
-L:会让HTTP请求跟随服务器的重定向,curl默认不跟随重定向
-m:限制curl完成时间(overall time limit)
-o/--output 把输出内容写入到指定文件中(重命名),等同于wget命令
-O/--remote-name 把输出内容写入到指定文件中,并保留原文件名
-r/--range <range> 返回HTTP/1.1或FTP服务器响应的指定范围字符
-s/--silent 静默模式,不输出任何东西
-T/--upload-file <file> 上传文件
-u/--user <user[:password]> 设定服务器的用户名和密码
-v/--verbose 输出更多信息,便于debug
-w/--write-out [format] 请求完成后指定输出内容
-x/--proxy <host[:port]> 使用HTTP代理
-X/--request [GET|POST|PUT|DELETE|PATCH] 使用指定的 http method 来发出 http request
-Y:设置下载限速
--dump-header:保存Header限速
--limit-rate:用来限制HTTP请求和回应的带宽,模拟慢网速的环境
--local-port:强制使用指定的本地端口号
--resolve HOST:PORT:ADDRESS 强制将 HOST:PORT 解析到指定的 IP ADDRESS
--trace <file>:输出请求的详细信息
-#/--progress-bar 進度條顯示當前的傳送狀態
直接获取网页内容
curl https://www.baidu.com
curl https://www.baidu.com:80 # 可以带端口号
-A/–user-agent:指定 User-Agent
有时候server会阻止curl的下载请求,这时可以透过修改User-Agent来模拟正常使用者发出的请求,比如模拟谷歌浏览器:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36" https://www.baidu.com
-b/-c:读取/存储Cookie
# 发出请求时将 cookie_file 中的数据带入请求中
curl -b cookie_file https://www.baidu.com
# 也可以用以下形式传递cookie
curl -b "oraclelicense=accept-securebackup-cookie" https://www.baidu.com
# 将请求时产生的 cookie 放到 cookie_file 中
curl -c cookie_file https://www.baidu.com
比如使用curl -c cookie_file https://www.baidu.com命令后会在本地生成一个cookie_file 文件,如下:
# Netscape HTTP Cookie File
# https://curl.se/docs/http-cookies.html
# This file was generated by libcurl! Edit at your own risk.
.baidu.com TRUE / FALSE 1678778080 BDORZ 27315
-C:断点续传
C表示Continue-at,文件下载被中断时不需要重新下载整个文件,可以通过-C命令继续下载:
-C offset:从指定的offset位置开始续传,我自己用这个参数测试时没续传成功过,不太确定如何使用;-C -:让curl自己分析该从什么位置开始续传。
使用以下命令下载文件:
curl -o forest.jpg https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
下到一半用ctrl + c中断下载,这里显示只下载了8%:
[外链图片转存中…(img-szXWh88l-1678796995464)]
打开下到一半的图片如下:
[外链图片转存中…(img-Ghpi1jWd-1678796995465)]
然后使用断点续传接着下载:
curl -C - -o forest.jpg https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
打开下载完成的图片:
[外链图片转存中…(img-5k8XsVYN-1678796995465)]
-d:携带POST请求的data
curl -X POST -d "name=andrew&age=22" -F "nm=da" https://www.baidu.com
# 将data编码
curl -X POST --data-urlencode "name=andrew age=22" https://www.baidu.com
注意:-d是发送post参数,-F是发送form-data数据,两者不能同时使用,否则会报错:
curl -X POST -d "name=andrew" -F "age=22" https://www.baidu.com
Warning: You can only select one HTTP request method! You asked for both POST
Warning: (-d, --data) and multipart formpost (-F, --form).
-D:把header信息写入到指定文件中
# 把请求返回的header信息写入到header_file文件中
curl -D header_file https://www.baidu.com
-e/–referer:带入来源网址referer
部分server为了避免盗链问题会确认引用源是否来自同一个网站,此时就要欺骗服务器的检查机制来取得相关资源。
curl -e "www.google.com" https://www.baidu.com
当某些连接必须通过301或302跳转过去时,用auto参数来让访问更加拟真:
curl -L -v -e ";auto" https://www.baidu.com
效果如下:
[外链图片转存中…(img-zULWi5wE-1678796995466)]
-F/–form:表单提交
curl -X POST -F 'uid="123456789"' https://www.baidu.com
-H/–header:添加请求头
curl --header 'Content-Type: application/x-www-form-urlencoded' https://www.baidu.com
-i/-I:显示response的header
# -i 返回header和网页内容
curl -i http://www.baidu.com
# -I 只返回header
curl -I http://www.baidu.com
效果如下:
[外链图片转存中…(img-bOwjNapG-1678796995466)]
-K/–config:指定配置文件
# -K后接配置文件名,如果使用 - 符号,则通过stdin输入配置
echo "user = user:passwd" | curl -K - https://www.baidu.com
-L:跟随跳转
通常情况下curl命令不会跟随301或302跳转,如果期望跟随跳转可以加上-L参数。
比如我们在访问谷歌或百度时,URL没有加上www前缀,会自动触发301或302跳转,我们可以用curl http://google.com/和curl https://baidu.com/(注意:这里没有加www前缀)命令来测试一下:
[外链图片转存中…(img-52RE25au-1678796995466)]
[外链图片转存中…(img-Rbo4bIvT-1678796995466)]
看到了吧,这样是无法触发自动跳转的。我们再用curl -L http://google.com/来测试一下:
[外链图片转存中…(img-86Ewe7Yi-1678796995467)]
[外链图片转存中…(img-1RSFgTyq-1678796995467)]
已经触发跳转,能够正常返回html页面了。
注:
现在已经有很多网站不使用www前缀了,这种域名叫做裸域名,比如掘金的https://juejin.cn/。
但不管一个网站是否使用裸域名,都要处理一个跳转问题:
-
如果掘金选择
https://juejin.cn/域名,那么它需要设置301跳转如下:https://www.juejin.cn/=>https://juejin.cn/
-
反之,如果掘金选择了
https://www.juejin.cn/域名,那么它需要设置301跳转如下:https://juejin.cn/=>https://www.juejin.cn/
我们可以用curl https://www.juejin.cn/命令测试掘金是否设置了301跳转,如下图:
[外链图片转存中…(img-Z9XFpisa-1678796995467)]
确实是设置了的。
[外链图片转存中…(img-UlNttgfa-1678796995467)]
[外链图片转存中…(img-emiNWQnZ-1678796995467)]
-m:限制完成时间
# 让curl必须在30分钟(1800s)内完成
curl -m 1800 -Y 3000 -y 60 www.far-away-site.com
-o/-O:下载文件
小写的-o代表下载文件并重命名:
curl -o forest.jpg https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
大写的-O代表下载文件并使用原文件名:
curl -O https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
-r:返回指定范围内的字符
# 返回响应的前100个字符
curl -r 0-99 https://www.baidu.com
# 返回响应的最后500个字符
curl -r -500 https://www.baidu.com
效果如下:
[外链图片转存中…(img-0e3LtcBB-1678796995467)]
-s:减少输出的信息
curl -s http://www.baidu.com
-T:上传文件
发送PUT请求。
# 上传所有的stdin标准输入到server,按ctrl+d结束输入,前提是该server能接收PUT类型的请求
curl -T - ftp://ftp.upload.com/myfile
# 也可以通过管道传递stdin
echo "user = user:passwd" | curl -T - ftp://ftp.upload.com/myfile
# 上传指定文件到server,并指定上传后的文件名为myfile
curl -T uploadfile -u user:passwd ftp://ftp.upload.com/myfile
# 上传指定文件到server,并沿用本地文件名
curl -T uploadfile -u user:passwd ftp://ftp.upload.com/
# -a:使用追加的方式上传文件
curl -T uploadfile -a ftp://ftp.upload.com/myfile
-u:设定用户名和密码
# 比如在访问ftp服务器时需要输入用户名和密码
curl -u name:passwd ftp://machine.domain:port/full/path/to/file
-v:输出完整信息
显示一次http通信的整个过程,通常用于debug。
curl -v http://www.baidu.com
效果如下:
[外链图片转存中…(img-f3dol0iF-1678796995467)]
-V:查看curl版本
cur -V
效果如下:
[外链图片转存中…(img-knj36ovF-1678796995468)]
-w:请求完成后显示自定义信息
# 显示响应状态码
curl -w "%{http_code}\n" -i -s -o /dev/null https://www.baidu.com
# 显示响应 content_type
curl -w "%{content_type}\n" -i -s -o /dev/null https://www.baidu.com
# 获取更多信息见文末参考文献2
效果展示:
[外链图片转存中…(img-KuV2xlss-1678796995468)]
-x:使用代理服务器(proxy)
curl -x 192.168.5.1:8888 http://www.baidu.com
# 如果代理服务器需要账号密码,可以使用 -U 或 --proxy-user 来指定
curl -U username:password -x 192.168.5.1:8888 http://www.baidu.com
# 不使用代理访问
curl --noproxy localhost,get.this http://www.baidu.com
-X/–request:指定请求类型
curl --request GET https://www.baidu.com
curl -X POST https://www.baidu.com
-Y/-y:限制下载速度
# 限制curl的下载速度在每秒3000字节以内,保持60秒
curl -Y 3000 -y 60 www.far-away-site.com
–dump-header:保存header信息
# 将返回的header信息保存到header.txt文件中
curl --dump-header header.txt https://www.baidu.com
–limit-rate:限制下载速度
如果想测试下载是否正常又不想占用太多带宽,可以用limit-rate参数做下载限速:
curl --limit-rate 100k -o forest.jpg https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
注意:该限速只是一个大概的值,不会卡死在指定的速度上。
–local-port:强制使用本地端口号
curl --local-port 8765 https://www.baidu.com
–resolve:强制解析Host为指定IP
curl --resolve www.google.com:443:142.251.35.164 -v https://www.google.com
–trace :输出请求的详细信息
如果用-v还是不能定位问题,可以进一步用--trace以ascii编码格式将更详细的内容输出到指定文件中,据此来debug:
# 将trace信息保存到trace.txt文件中
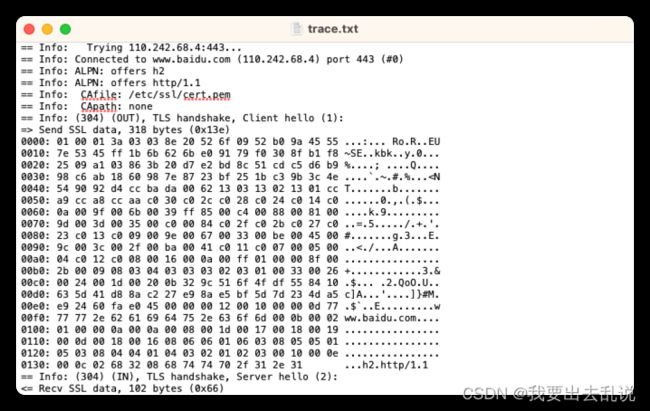
curl --trace trace.txt https://www.baidu.com
trace.txt文件部分内容如下图所示:
[外链图片转存中…(img-zLJNdjmO-1678796995468)]
-# :展示下载进度
通常在下载文件时配合-o/-O使用:
curl -# -o forest.jpg https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
效果如下:
[外链图片转存中…(img-cZh5naA8-1678796995469)]
参考文献
- curl tutorial
- Linux Curl 超詳細教學(常用篇)
- curl -w参数详解
- everything.curl.dev## cURL是什么
cURL是用于数据传输的命令行工具,支持多种传输协议,包括HTTP、HTTPS、SCP、FTP、SFTP、TELNET、FILE、SMTP、POP3等等。可以使用cURL进行HTTP/HTTPS请求、上传/下载文件等,且支持Cookie、用户身份验证、代理支持、限速等。
参数解析
curl [options] [URL...]
-A/--user-agent <string> 设定使用者的代理发送给服务器
-b/--cookie <name=string/file> 设置cookie文件的读取位置
-c/--cookie-jar <file> 操作结束后把cookie写入到指定文件中
-C/--continue-at <offset> 断点续传
-d/--data "data" 携带HTTP POST请求的data
-D/--dump-header <file> 把header信息写入到指定文件中
-e/--referer 带入来源网址
-F/ 上传二进制文件,也可以当做-d来用
-H/--header 设定请求头
-i/--include 在输出中显示header
-K:指定配置文件
-L:会让HTTP请求跟随服务器的重定向,curl默认不跟随重定向
-m:限制curl完成时间(overall time limit)
-o/--output 把输出内容写入到指定文件中(重命名),等同于wget命令
-O/--remote-name 把输出内容写入到指定文件中,并保留原文件名
-r/--range <range> 返回HTTP/1.1或FTP服务器响应的指定范围字符
-s/--silent 静默模式,不输出任何东西
-T/--upload-file <file> 上传文件
-u/--user <user[:password]> 设定服务器的用户名和密码
-v/--verbose 输出更多信息,便于debug
-w/--write-out [format] 请求完成后指定输出内容
-x/--proxy <host[:port]> 使用HTTP代理
-X/--request [GET|POST|PUT|DELETE|PATCH] 使用指定的 http method 来发出 http request
-Y:设置下载限速
--dump-header:保存Header限速
--limit-rate:用来限制HTTP请求和回应的带宽,模拟慢网速的环境
--local-port:强制使用指定的本地端口号
--resolve HOST:PORT:ADDRESS 强制将 HOST:PORT 解析到指定的 IP ADDRESS
--trace <file>:输出请求的详细信息
-#/--progress-bar 進度條顯示當前的傳送狀態
直接获取网页内容
curl https://www.baidu.com
curl https://www.baidu.com:80 # 可以带端口号
-A/–user-agent:指定 User-Agent
有时候server会阻止curl的下载请求,这时可以透过修改User-Agent来模拟正常使用者发出的请求,比如模拟谷歌浏览器:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36" https://www.baidu.com
-b/-c:读取/存储Cookie
# 发出请求时将 cookie_file 中的数据带入请求中
curl -b cookie_file https://www.baidu.com
# 也可以用以下形式传递cookie
curl -b "oraclelicense=accept-securebackup-cookie" https://www.baidu.com
# 将请求时产生的 cookie 放到 cookie_file 中
curl -c cookie_file https://www.baidu.com
比如使用curl -c cookie_file https://www.baidu.com命令后会在本地生成一个cookie_file 文件,如下:
# Netscape HTTP Cookie File
# https://curl.se/docs/http-cookies.html
# This file was generated by libcurl! Edit at your own risk.
.baidu.com TRUE / FALSE 1678778080 BDORZ 27315
-C:断点续传
C表示Continue-at,文件下载被中断时不需要重新下载整个文件,可以通过-C命令继续下载:
-C offset:从指定的offset位置开始续传,我自己用这个参数测试时没续传成功过,不太确定如何使用;-C -:让curl自己分析该从什么位置开始续传。
使用以下命令下载文件:
curl -o forest.jpg https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
下到一半用ctrl + c中断下载,这里显示只下载了8%:

打开下到一半的图片如下:
然后使用断点续传接着下载:
curl -C - -o forest.jpg https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
打开下载完成的图片:
-d:携带POST请求的data
curl -X POST -d "name=andrew&age=22" -F "nm=da" https://www.baidu.com
# 将data编码
curl -X POST --data-urlencode "name=andrew age=22" https://www.baidu.com
注意:-d是发送post参数,-F是发送form-data数据,两者不能同时使用,否则会报错:
curl -X POST -d "name=andrew" -F "age=22" https://www.baidu.com
Warning: You can only select one HTTP request method! You asked for both POST
Warning: (-d, --data) and multipart formpost (-F, --form).
-D:把header信息写入到指定文件中
# 把请求返回的header信息写入到header_file文件中
curl -D header_file https://www.baidu.com
-e/–referer:带入来源网址referer
部分server为了避免盗链问题会确认引用源是否来自同一个网站,此时就要欺骗服务器的检查机制来取得相关资源。
curl -e "www.google.com" https://www.baidu.com
当某些连接必须通过301或302跳转过去时,用auto参数来让访问更加拟真:
curl -L -v -e ";auto" https://www.baidu.com
效果如下:
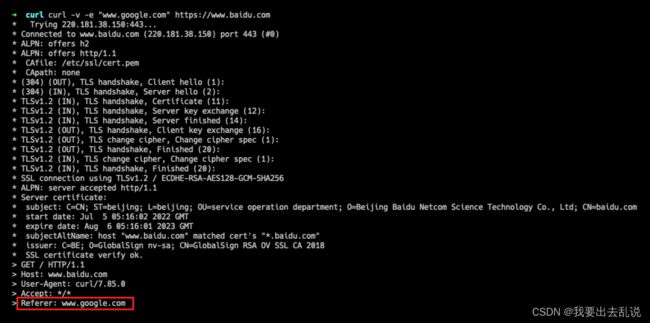
-F/–form:表单提交
curl -X POST -F 'uid="123456789"' https://www.baidu.com
-H/–header:添加请求头
curl --header 'Content-Type: application/x-www-form-urlencoded' https://www.baidu.com
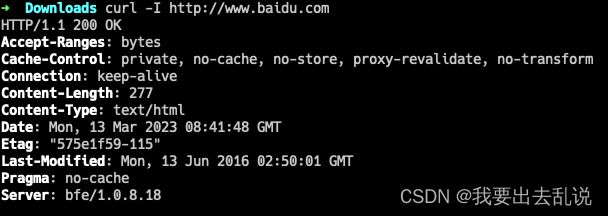
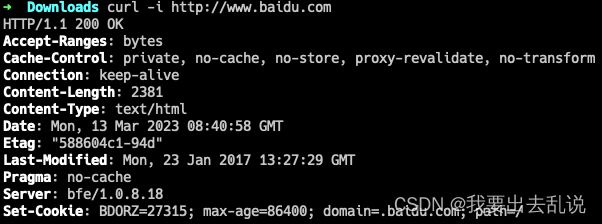
-i/-I:显示response的header
# -i 返回header和网页内容
curl -i http://www.baidu.com
# -I 只返回header
curl -I http://www.baidu.com
效果如下:

-K/–config:指定配置文件
# -K后接配置文件名,如果使用 - 符号,则通过stdin输入配置
echo "user = user:passwd" | curl -K - https://www.baidu.com
-L:跟随跳转
通常情况下curl命令不会跟随301或302跳转,如果期望跟随跳转可以加上-L参数。
比如我们在访问谷歌或百度时,URL没有加上www前缀,会自动触发301或302跳转,我们可以用curl http://google.com/和curl https://baidu.com/(注意:这里没有加www前缀)命令来测试一下:


看到了吧,这样是无法触发自动跳转的。我们再用curl -L http://google.com/来测试一下:


已经触发跳转,能够正常返回html页面了。
注:
现在已经有很多网站不使用www前缀了,这种域名叫做裸域名,比如掘金的https://juejin.cn/。
但不管一个网站是否使用裸域名,都要处理一个跳转问题:
-
如果掘金选择
https://juejin.cn/域名,那么它需要设置301跳转如下:https://www.juejin.cn/=>https://juejin.cn/
-
反之,如果掘金选择了
https://www.juejin.cn/域名,那么它需要设置301跳转如下:https://juejin.cn/=>https://www.juejin.cn/
我们可以用curl https://www.juejin.cn/命令测试掘金是否设置了301跳转,如下图:

确实是设置了的。
-m:限制完成时间
# 让curl必须在30分钟(1800s)内完成
curl -m 1800 -Y 3000 -y 60 www.far-away-site.com
-o/-O:下载文件
小写的-o代表下载文件并重命名:
curl -o forest.jpg https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
大写的-O代表下载文件并使用原文件名:
curl -O https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
-r:返回指定范围内的字符
# 返回响应的前100个字符
curl -r 0-99 https://www.baidu.com
# 返回响应的最后500个字符
curl -r -500 https://www.baidu.com
效果如下:

-s:减少输出的信息
curl -s http://www.baidu.com
-T:上传文件
发送PUT请求。
# 上传所有的stdin标准输入到server,按ctrl+d结束输入,前提是该server能接收PUT类型的请求
curl -T - ftp://ftp.upload.com/myfile
# 也可以通过管道传递stdin
echo "user = user:passwd" | curl -T - ftp://ftp.upload.com/myfile
# 上传指定文件到server,并指定上传后的文件名为myfile
curl -T uploadfile -u user:passwd ftp://ftp.upload.com/myfile
# 上传指定文件到server,并沿用本地文件名
curl -T uploadfile -u user:passwd ftp://ftp.upload.com/
# -a:使用追加的方式上传文件
curl -T uploadfile -a ftp://ftp.upload.com/myfile
-u:设定用户名和密码
# 比如在访问ftp服务器时需要输入用户名和密码
curl -u name:passwd ftp://machine.domain:port/full/path/to/file
-v:输出完整信息
显示一次http通信的整个过程,通常用于debug。
curl -v http://www.baidu.com
效果如下:
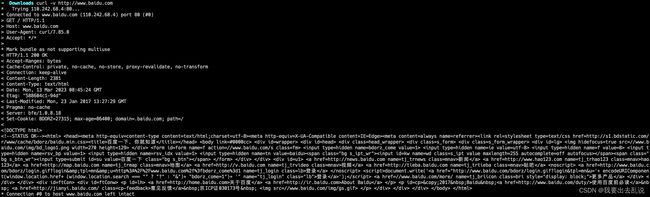
-V:查看curl版本
cur -V
效果如下:
![]()
-w:请求完成后显示自定义信息
# 显示响应状态码
curl -w "%{http_code}\n" -i -s -o /dev/null https://www.baidu.com
# 显示响应 content_type
curl -w "%{content_type}\n" -i -s -o /dev/null https://www.baidu.com
# 获取更多信息见文末参考文献2
效果展示:

-x:使用代理服务器(proxy)
curl -x 192.168.5.1:8888 http://www.baidu.com
# 如果代理服务器需要账号密码,可以使用 -U 或 --proxy-user 来指定
curl -U username:password -x 192.168.5.1:8888 http://www.baidu.com
# 不使用代理访问
curl --noproxy localhost,get.this http://www.baidu.com
-X/–request:指定请求类型
curl --request GET https://www.baidu.com
curl -X POST https://www.baidu.com
-Y/-y:限制下载速度
# 限制curl的下载速度在每秒3000字节以内,保持60秒
curl -Y 3000 -y 60 www.far-away-site.com
–dump-header:保存header信息
# 将返回的header信息保存到header.txt文件中
curl --dump-header header.txt https://www.baidu.com
–limit-rate:限制下载速度
如果想测试下载是否正常又不想占用太多带宽,可以用limit-rate参数做下载限速:
curl --limit-rate 100k -o forest.jpg https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
注意:该限速只是一个大概的值,不会卡死在指定的速度上。
–local-port:强制使用本地端口号
curl --local-port 8765 https://www.baidu.com
–resolve:强制解析Host为指定IP
curl --resolve www.google.com:443:142.251.35.164 -v https://www.google.com
–trace :输出请求的详细信息
如果用-v还是不能定位问题,可以进一步用--trace以ascii编码格式将更详细的内容输出到指定文件中,据此来debug:
# 将trace信息保存到trace.txt文件中
curl --trace trace.txt https://www.baidu.com
trace.txt文件部分内容如下图所示:
-# :展示下载进度
通常在下载文件时配合-o/-O使用:
curl -# -o forest.jpg https://lmg.jj20.com/up/allimg/1114/0406210Z024/2104060Z024-5-1200.jpg
效果如下:
![]()
参考文献
- curl tutorial
- Linux Curl 超詳細教學(常用篇)
- curl -w参数详解
- everything.curl.dev