机器学习——模型评估与选择(拟合、)
【说明】文章内容来自《机器学习——基于sklearn》,用于学习记录。若有争议联系删除。
1、拟合
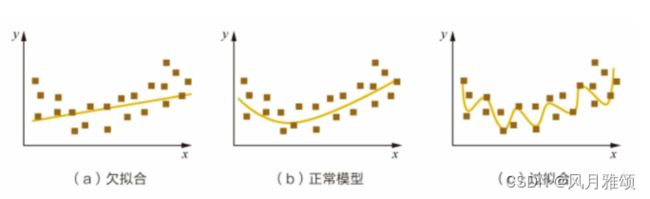
拟合是指机器学习模型在训练的过程中,通过更新参数,使得模型不断契合可观测数据(训练集)的过程。欠拟合指的是模型在训练和预测表现都不好,往往由于模型过于简单,如图(a)所示。正常模型指的是模型在训练和预测表现都好,如图 (b)所示。过拟合是指由于模型过于复杂,模型在训练集上的表现很好,但在测试集上表现较差,如图 (c)所示。
1.1 欠拟合
欠拟合往往是由于模型的数据特征过少或者模型复杂度较低所致。因此,可以通过如下办法解决欠拟合问题:
通过特征工程添加更多特征项。当特征不足或者现有特征与样本标签的相关性不强时,通过组合特征进行处理。
进行模型优化,提升模型复杂度。提升模型的复杂度能够增强模型的拟合能力。例如,在线性模型中可以通过添加高次项等提升模型的复杂度。
减小正则项权重。正则化的目的是防止过拟合,但是现在模型出现了欠拟合,因此需要减小正则项的权重
使用集成方法。融合几个有差异的弱模型,使其成为一个强模型
1.2 过拟合
过拟合指的是模型在训练集上表现得很好,但是在交叉验证集合测试集上表现得一般,也就是说模型对未知样本的预测表现得一般,泛化(generalization)能力较差。过拟合产生的原因往往有以下几个:
- 训练数据不足,数据太少,导致无法描述问题的真实分布。根据统计学的大数定律,在试验不变的条件下,重复试验多次,随机事件的频率将趋近其概率。模型在求解最小值的过程中需要兼顾真实数据拟合和随机误差拟合。
- 数据有噪声。噪声数据使得更复杂的模型会尽量覆盖噪声点,即对数据过拟合。
- 对模型训练过度,导致模型非常复杂。
针对过拟合产生的原因,抑制过拟合的几种方法如下:
- 获取更多的训练样本。通过获取更多的训练样本,可以衰减噪声数据的权重。
- 增加正则项权重,减少高次项的影响。例如,通过L1或 L2正则化提高模型的泛
- 数据处理。
- 进行数据清洗,纠正错误的标签,删除错误数据。
- 进行特征共性检查,利用皮尔逊相关系数计算变量之间的线性相关性,进行特征选择。
- 重要特征筛选,例如,对决策树模型进行求最大深度、剪枝等操作。
- 数据降维,通过主成分分析等保留重要特征。
1.3 正则化
正则化(regularization)目的在于提高模型在未知测试数据上的泛化能力,避免参数过拟合。常用方法是在原模型优化目标的基础上增加针对参数的惩罚(penalty)项,一般有L1正则化与L2正则化两种方法。
L1正则化是基于L1范数实现的,也就是 LASSO 回归,即在目标函数后面加上参数的绝对值之和与参数的积项。
![]()
L2正则化是基于L2范数实现的,也就是岭回归,即在目标函数后面加上参数的平方之和与参数的积项:
![]()
L1范数: 指向量中各个元素绝对值之和
![]()
L2范数: 指向量各元素的平方和然后求平方根
![]()
2、模型调参
模型调参是指从数据特征入手,通过调整模型中的超参数来解决欠拟合和过拟合问题。
Sklearn 提供了网格搜索和随机搜索两种参数调优方法。
2.1 网格搜索
GridSearchCV可以自动进行超参数组合,通过交叉验证评估模型的优劣。GridSearchCV拆分为GridSearch 和 CV两部分,即网格搜索和交叉验证。网格搜索是指在指定的参数范围内,通过循环和比较调整参数,训练预估器。假设模型有两个参数a,b,参数a有3个取值,参数b有4个取值,共有3X4=12个取值,则依次搜索这12个网格。交叉验证将训练数据集划分为K份(默认为10),依次取其中一份作为测试集,其余为训练集。model_selection 模块提供了GridSearchCV函数用于网格搜索,格式如下:
GridSearchCV(eatimator,param_grid)【参数说明】
- estimator:选择使用的分类器,并且传人除需要优化的参数之外的其他参数。每一个分类器都需要一个 scoring参数或者 score方法。
- param_grid:需要优化的参数的取值,值的类型为字典或者列表。
示例:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
#加载鸢尾花数据
iris = datasets.load_iris()
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target,
random_state = 3)
#标准化
transfer = StandardScaler()
X_train = transfer.fit_transform(X_train)
X_test = transfer.transform(X_test)
#KNN算法预估器
estimator = KNeighborsClassifier()
#多个超参数,引入网格搜索
param_dict = {'n_neighbors':[1,3,5,7,9,11]}
estimator = GridSearchCV(estimator, param_grid = param_dict, cv =10)
estimator.fit(X_train, y_train)
#模型评估
#最佳参数
print('最佳参数:\n',estimator.best_params_)
#最佳结果
print('最佳结果:\n',estimator.best_score_)
#最佳评估器
print('最佳评估器:\n',estimator.best_estimator_)
#交叉验证结果
print('交叉验证结果:\n',estimator.cv_results_)【运行结果】

2.2 随机搜索
在处理较少的超参数组合时,GridSearchCV方法比较适用。GridSearchCV可以保证在指定的参数范围内找到精度最高的参数,但是这也是网格搜索的缺陷所在,要求遍历所有可能参数的合,在面对大数据集和多参数的情况下,非常耗时。RandomizedSearchCV随机参数搜索的方法相对于网格搜索方法,找到模型的最优参数的可能性比较大,并且也比较省时。
Sklearn的model_selection模块RandomizedSearchCV方法用于随机搜索,代码如下:
meta_clf = RandomForestClassifier(n_estimators = 20)
给定参数搜索范围:list or distribution
param_dist = {"max_depth": [3, None], #给定list树的最大深度,如果None,节点扩展直到所有叶子
"max_features": sp_randint(1, 11), #给定distribution寻找最佳分裂点时考虑的特征数目。可选值,int(具体的数目),float(数目的百分比
"min_samples_split": sp_randint(2, 11), #分裂内部节点需要的最少样例数。int(具体数目),float(数目的百分比)
"bootstrap": [True, False], #构建数是不是采用有放回样本的方式
"criterion": ["gini", "entropy"]} #度量分裂的标准。可选值:“mse”,均方差(mean squared error)
# 用RandomiSearch+CV选取超参数
n_iter_search = 20
random_search = RandomizedSearchCV(clf, param_distributions=param_dist,
n_iter=n_iter_search, cv=5, iid=False)
random_search.fit(X, y)
示例:
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
iris = datasets.load_iris()
iris_feature = iris['data']
iris_target = iris['target']
#建模分析
forest_clf = RandomForestClassifier(random_state = 42)
param_distribs = {'n_estimators': range(10, 100), 'max_depth': range(5, 20)}
random_search = RandomizedSearchCV(forest_clf, param_distribs, n_iter = 50, cv = 3)
random_search.fit(iris_feature, iris_target)
print(random_search.best_params_)
best_model = random_search.best_estimator_【运行结果】
![]()