理解堆:一个美丽的混乱
Understanding the Heap - a beautiful mess
理解堆——一个美丽的混乱
2023-01-01
In this blog, I am going to explain the important concepts of Heap and use the ptmalloc in the Glibc 2.31 library as an example.
在这篇博客中,我将解释堆的重要概念,并以 Glibc 2.31 库中的 ptmalloc 为例。
The heap is a beautiful mess
堆真是一个美丽的混乱:)
I really like the saying shown above. The word Heap we always use refers to the dynamically allocated segment in the virtual memory space of a process, but it actually stands for the implementation of the memory pool(the dynamic memory allocator) behind, which is quite complex and maybe vary on different machines, thus giving us a chance to exploit it. Here I am going to explain the important concepts of Heap and use the ptmalloc in the Glibc 2.31 library as an example.
我真的很喜欢上面这句话。我们经常使用的 Heap 这个词指的是进程虚拟内存空间中动态分配的段,但它实际上代表了背后内存池(动态内存分配器)的实现,相当复杂并且可能在不同的机器上有所不同,从而给我们一个利用它的机会。这里我将解释Heap的重要概念,并以Glibc 2.31库中的 ptmalloc 为例。
I found that the available online material, while very extensive and detailed, may not be friendly for beginners to learn. I just found the pwn.college gives a really really really great lecture on the heap or dynamic memory allocator. However, I still like to try a different ways to introduce these concepts.
我发现网上提供的资料虽然非常广泛和详细,但对于初学者来说可能不太友好。我刚刚发现 pwn.college 提供了关于堆或动态内存分配器的非常非常非常好的讲座。不过,我仍然喜欢尝试不同的方式来介绍这些概念。
Firstly, I will start from the single-thread case and introduce the following points:
首先从单线程的情况出发,介绍以下几点:
-
high-level behavior behind
malloc:sbrkandmmap
malloc背后的高级行为:sbrk和mmap -
the overall layout of heap and chunks
堆和块的整体布局 -
the data structures used for management:
malloc_chunk,malloc_stateandbinning
用于管理的数据结构:malloc_chunk、malloc_state和binning -
low-level behavior of
malloc: algorithms for allocating and freeing memory chunks (todo: creating, initialing, and deleting heaps)
malloc的低级行为:分配和释放内存块的算法(todo:创建、初始化和删除堆)
Then, I will get multi-threading involved and supplement the following points:
然后我会涉及到多线程,并补充以下几点:
-
t-cache
-
the overall layout of arenas and heaps
arena 和 heap 的整体布局 -
updating the data structures:
malloc_stateandheap_info
更新数据结构:malloc_state和heap_info
// comes from https://guyinatuxedo.github.io/25-heap/index.html
+--------------------+----------------------------+-----------------------+
| Bug Used | Bin Attack | House |
+--------------------+----------------------------+-----------------------+
| | Fast Bin Attack | House of Spirit |
| Double Free | tcache attack | House of Lore |
| Heap Overflow | Unsorted Bin Attck | House of Force |
| Use After Free | Small / Large Bin Attck | House of Einherjar |
| | Unsafe Unlink | House of Orange |
+--------------------+----------------------------+-----------------------+
Overview of Heap 堆概述
Pools are a common design pattern in computing technology, which involves: pre-allocating and keeping a pool of core resources that are frequently used in a program, which are self-managed by the program, in order to improve resource utilization and ensure that the program has a fixed number of resources.
池化是计算技术中常见的设计模式,它涉及:预先分配并保留一个程序中经常使用的核心资源池,由程序自行管理,以提高资源利用率并保证程序有固定数量的资源。
Memory pools are a technique for dynamically allocating and managing memory. Typically, programmers are used to directly using APIs such as new, delete, malloc, and free to allocate and release memory, which can result in a large number of memory fragments over time when the program is run for a long time and the size of the allocated memory blocks is not fixed, reducing the performance of the program and the operating system.
内存池是一种动态分配和管理内存的技术。通常,程序员习惯直接使用new、delete、malloc、free等API来分配和释放内存,这会导致程序长时间运行时,会产生大量的内存碎片,大小分配的内存块不固定,降低了程序和操作系统的性能。
Before actually using memory, a memory pool pre-allocates a large block of memory (the memory pool) as a reserve. When a programmer requests memory, a block is dynamically allocated from the pool. When the programmer releases the memory, it is returned to the pool and can be used again when requested, and is merged with surrounding free memory blocks as much as possible. If the memory pool is not sufficient, the memory pool is automatically expanded and a larger memory pool is requested from the operating system.
在实际使用内存之前,内存池会预先分配一大块内存(内存池)作为保留。当程序员请求内存时,会从池中动态分配一个块。当程序员释放内存时,它会返回到池中,并可以在请求时再次使用,并尽可能与周围的空闲内存块合并。如果内存池不足,则自动扩展内存池,并向操作系统请求更大的内存池。
The benefits of using memory pools include:
使用内存池的好处包括:
- Reducing internal fragmentation by using chunk merging to minimize internal fragmentation as much as possible;
减少内部碎片,通过使用块合并来尽可能减少内部碎片; - Reducing external fragmentation by requesting a large block of memory from memory at once;
通过一次性向内存请求大块内存来减少外部碎片; - Improving the efficiency of memory allocation by requesting a large block of memory from memory at once and using it slowly, avoiding frequent requests to memory for memory operations.
通过一次性向内存申请大块内存并慢慢使用,提高内存分配效率,避免频繁请求内存进行内存操作。
In a C program, we always use built-in functions likemalloc(), calloc(), and realloc(),which indeed invoke the memory allocator ptmalloc, to get a dynamically allocated memory space. The ptmalloc is the implementation of the memory pool in Glibc library used by default.
在 C 程序中,我们总是使用 malloc() 、 calloc() 和 realloc(), 等内置函数,它们确实调用内存分配器 ptmalloc ,获取动态分配的内存空间。 ptmalloc 是Glibc库中默认使用的内存池的实现。
System calls behind malloc
malloc 系统调用的幕后
In ptmalloc’s implementation, malloc use (s)brk or mmap system call for memory allocation.
在ptmalloc的实现中, malloc 使用 (s)brk 或 mmap 系统调用进行内存分配。
According to the man pages of (s)brk:
根据 (s)brk 的手册页:
brk() and sbrk() change the location of the program break, whichdefines the end of the process's data segment (i.e., the program break is the first location after the end of the uninitializeddata segment). Increasing the program break has the effect ofallocating memory to the process; decreasing the break deallocates memory.
According to the man pages of mmap:
根据 mmap 的手册页:
mmap() creates a new mapping in the virtual address space of the calling process. The starting address for the new mapping is specified in addr. The length argument specifies the length ofthe mapping (which must be greater than 0).
In short, both(s)brkand mmap are the system calls that provide the functionality to create new memory space(with custom permissions). However, (s)brk only can create memory space following the .data segment(change the location of program break);
简而言之, (s)brk 和 mmap 都是提供创建新内存空间(具有自定义权限)功能的系统调用。但 (s)brk 只能在 .data 段之后创建内存空间(改变程序断点的位置);
**Calling (s)brk or mmap? **
调用 (s)brk 或 mmap?
According to this page: 根据这个页面:
mallopt() could set parameters to control behavior of malloc(), and there is a parameter named M_MMAP_THRESHOLD, in general:
mallopt() 可以设置参数来控制 malloc() 的行为,其中有一个名为 M_MMAP_THRESHOLD 的参数,一般来说:
- If the requested memory is less than it,
brk()will be used;
如果请求的内存小于它,将使用brk(); - If the requested memory is larger than or equal to it,
mmap()will be used;
如果请求的内存大于或等于它,则使用mmap();
The default value of the parameter is 128KB (on my system). And what has been mentioned in the pwn.college is that set M_MMAP_THRESHOLD could cause more overhead.
该参数的默认值为 128KB (在我的系统上)。 pwn.college 中提到的是设置 M_MMAP_THRESHOLD 可能会导致更多开销。
Overall layout of Heap
Heap的总体布局
In ptmalloc memory allocator, chunks of various sizes exist within a larger region of memory (a “heap”). The heap grows up from the lower address. The main heap(the heap initialized by the main thread) starts by following the .BSS segment (the original program breakpoint).
在 ptmalloc 内存分配器中,不同大小的块存在于更大的内存区域(“堆”)中。堆从低地址开始增长。主堆(由主线程初始化的堆)从 .BSS 段(原始程序断点)开始。
Heap 堆
A contiguous region of memory that is subdivided into chunks to be allocated.
被细分为要分配的块的连续内存区域。
Chunk 块
A small range of memory that can be allocated (owned by the application), freed (owned by glibc), or combined with adjacent chunks into larger ranges. Note that a chunk is a wrapper around the block of memory that is given to the application.
可以分配(由应用程序拥有)、释放(由 glibc 拥有)或与相邻块组合成更大范围的小范围内存。请注意,块是提供给应用程序的内存块的包装器。
Data structures for heap
堆的数据结构
The heap metadata is organized with the help of the following three data structures: malloc_chunk(chunk header), malloc_state, and heap_info(introduced later).
堆元数据是通过以下三个数据结构来组织的:malloc_chunk(chunk header)、malloc_state和heap_info(稍后介绍)。
- malloc_chunk: The chunk is the smallest unit allocated by malloc, and each chunk has its own
malloc_chunkheader structure.
malloc_chunk:chunk是malloc分配的最小单元,每个chunk都有自己的malloc_chunk头结构。 - malloc_state: heaps are governed by a single
malloc_stateheader structure. This structure tells the allocator where the top chunk (chunk at the highest address), last remainder chunk, bins, etc. are.
malloc_state:堆由单个malloc_state标头结构控制。该结构告诉分配器顶部块(位于最高地址的块)、最后剩余块、容器等在哪里。
malloc_chunk(chunk header)
malloc_chunk(块头)
The chunk is the smallest unit allocated by malloc. Chunks have two different states: in-use or free.
chunk是malloc分配的最小单元。块有两种不同的状态:正在使用或空闲。
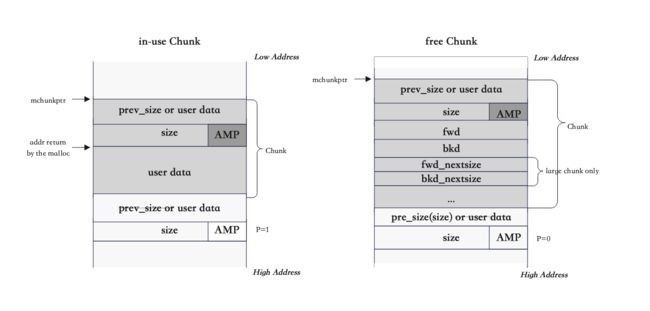
An in-use chunk consists of 3 parts: the previous chunk size or the previous chunk user data, the chunk size(8 bytes in 64-bit machines), the AMP flag(3-bit), and user data. The user data will be padded to align with 16 bytes on 64-bit machines, which means the last three bits of the size of user data in hex format will always be zero. Therefore, we could take advantage of the alignment and use them as flags.
正在使用的 chunk 由 3 部分组成:前一个 chunk 大小或前一个 chunk 用户数据、chunk 大小(64 位机器中为 8 字节)、AMP 标志(3 位)和用户数据。用户数据将被填充以与 64 位计算机上的 16 字节对齐,这意味着十六进制格式的用户数据大小的最后三位将始终为零。因此,我们可以利用对齐方式并将它们用作标志。
An free chunk consists of 4 parts. The first 16 bytes stay the same. Now that this chunk is free, two new parts (fwd and bkd) will be written into this chunk and one(pre_size) into the next chunk. The forward pointer fwd stores the address of the next free chunk in the list, and the back pointer bkd saves the address of the previous free chunk in the list if any. Lastly, the pre_size of the next chunk will be set to this chunk’s CHUNK SIZE.
一个空闲块由 4 部分组成。前 16 个字节保持不变。现在该块已空闲,两个新部分(fwd 和 bkd)将被写入该块中,一个(pre_size)将写入下一个块中。前向指针 fwd 存储列表中下一个空闲块的地址,后向指针 bkd 保存列表中上一个空闲块的地址(如果有)。最后,下一个块的 pre_size 将被设置为该块的 CHUNK SIZE。
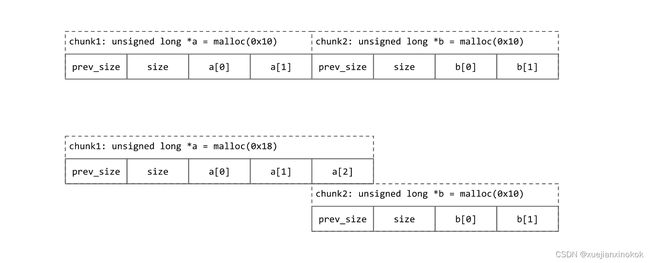
the overlapping part 重叠部分
An interesting point here is that the first 8 bytes might be the overlapping part of the previous chunk. If the previous chunk is in use, then this part will hold the previous last 8 bytes of data, and if the previous chunk is free, it will hold the previous’ chunk size.
这里有趣的一点是前 8 个字节可能是前一个块的重叠部分。如果前一个 chunk 正在使用,那么这部分将保存前一个 chunk 的最后 8 个字节的数据,如果前一个 chunk 空闲,它将保存前一个 chunk 的大小。
This is because the size of a chunk should be multiple of 0x10, and if the asked memory size ends with 0x8 or round to 0x8, to improve the space usage, ptmalloc would make chunk overlapped. Specifically, for example if we are trying to allocate 0x18 bytes, you would get a total 0x18+0x10(header)+0x8(padding)=0x30 bytes for the current chunk, and the size field would be 0x20 bytes and next chunk pointer would be placed to current mchunptr + 0x30 - 0x8 which indicating the next chunk would overlap with the current chunk. However, it doesn’t matter since the first 8 bytes of next chunk won’t used until the current chunk is freed, this key insight help us saving 8 bytes memory.
这是因为一个 chunk 的大小应该是 0x10 的倍数,如果请求的内存大小以 0x8 结尾或者舍入到 0x8,为了提高空间利用率,ptmalloc 会让 chunk 重叠。具体来说,例如,如果我们尝试分配 0x18 字节,则当前块总共会得到 0x18+0x10(header)+0x8(padding)=0x30 字节,大小字段将为 0x20 字节,下一个块指针将为被放置到当前的 mchunptr + 0x30 - 0x8,这表明下一个块将与当前块重叠。不过,这并不重要,因为在释放当前块之前不会使用下一个块的前 8 个字节,这一关键见解可以帮助我们节省 8 字节内存。
AMP flags AMP 标志
A, Allocated Arena - the main arena uses the application’s heap. Other arenas use mmap’d heaps. To map a chunk to a heap, you need to know which case applies. If this bit is 0, the chunk comes from the main arena and the main heap. If this bit is 1, the chunk comes from mmap’d memory and the location of the heap can be computed from the chunk’s address.
A,分配的竞技场 - 主竞技场使用应用程序的堆。其他 arena 使用 mmap 堆。要将块映射到堆,您需要知道适用哪种情况。如果该位为0,则该块来自主arena和主堆。如果该位为 1,则块来自 mmap 内存,并且可以根据块的地址计算堆的位置。
M, MMap’d chunk - this chunk was allocated with a single call to mmap and is not part of a heap at all.
M,MMap 的块 - 该块是通过对 mmap 的一次调用来分配的,并且根本不是堆的一部分。
P, Previous chunk is in use - if set, the previous chunk is still being used by the application, and thus the prev_size field is invalid. Note - some chunks, such as those in fastbins (see below) will have this bit set despite being free’d by the application. This bit really means that the previous chunk should not be considered a candidate for coalescing - it’s “in use” by either the application or some other optimization layered atop malloc’s original code.
P,前一个块正在使用中 - 如果设置,则应用程序仍在使用前一个块,因此 prev_size 字段无效。注意 - 某些块,例如 fastbins 中的块(见下文),尽管已被应用程序释放,但仍将设置此位。这一点实际上意味着前一个块不应被视为合并的候选者 - 它正在被应用程序或位于 malloc 原始代码之上的其他一些优化“使用”。
minimum size of the chunk
块的最小大小
In order to ensure that a chunk’s payload area is large enough to hold the overhead needed by malloc, the minimum size of a chunk is 4*sizeof(void*) (unless size_t is not the same size as void*). The minimum size may be larger if the ABI of the platform requires additional alignment. Note that prev_size does not increase the minimum chunk size to 5*sizeof(void*) because when the chunk is small the bk_nextsize pointer is unused, and when the chunk is large enough to use it there is more than enough space at the end.
为了确保块的有效负载区域足够大以容纳 malloc 所需的开销,块的最小大小为 4*sizeof(void*) (除非 size_t 与 size_t 的大小不同) b2>)。如果平台的 ABI 需要额外的对齐,则最小尺寸可能会更大。请注意, prev_size 不会将最小块大小增加到 5*sizeof(void*) ,因为当块很小时, bk_nextsize 指针未使用,而当块足够大时, bk_nextsize 指针不会被使用。使用它时,末尾有足够的空间。
the malloc_chunk struct type
malloc_chunk 结构类型
/* This struct declaration is misleading (but accurate and necessary). It declares a "view" into memory allowing access to necessary fields at known offsets from a given base. See explanation below.*/
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
malloc_state
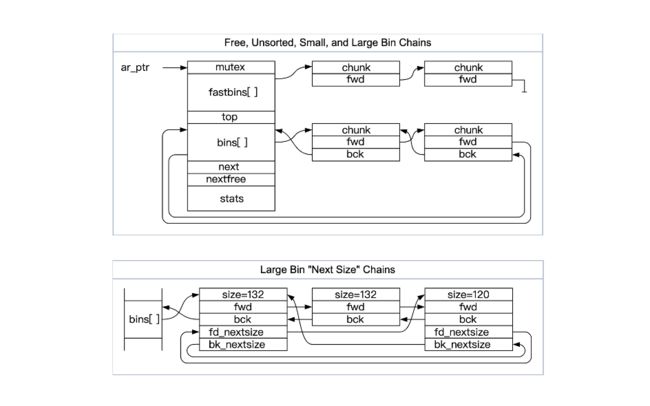
Struct malloc_state contains the necessary variables to manage the free memory chunks. The struct malloc_state of the main thread (the main heap) is stored in the memory mapping segment as a global variable.
结构体 malloc_state 包含管理空闲内存块所需的变量。主线程(主堆)的struct malloc_state 作为全局变量存储在内存映射段中。
struct malloc_state
{
/* Serialize access. */
__libc_lock_define (, mutex);
/* Flags (formerly in max_fast). */
int flags;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on the free list. Access to this field is serialized by free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
typedef struct malloc_state *mstate;
binning 分档
Free chunks are stored in various free lists based on size and history so that the allocator can find suitable chunks to satisfy allocation requests quickly. The free lists are actually called bins. Bins are in-memory linked structures that keep track of all the freed chunks.
空闲块根据大小和历史记录存储在各种空闲列表中,以便分配器可以快速找到合适的块来满足分配请求。空闲列表实际上称为垃圾箱。 bin 是内存中的链接结构,用于跟踪所有已释放的块。
Fast Bins
Most programs often request and release relatively small chunks of memory. If some smaller chunks are freed, and a free chunk adjacent to them is found and merged, the next time a chunk of the same size is requested, the chunk needs to be partitioned, which greatly reduces the efficiency of heap utilization. Therefore, fastbin has been proposed to keep access fast by keeping minimal logic.
大多数程序经常请求和释放相对较小的内存块。如果释放了一些较小的chunk,并找到与它们相邻的空闲chunk并合并,则下次请求相同大小的chunk时,需要对该chunk进行分区,这大大降低了堆的利用效率。因此, fastbin 被提议通过保持最少的逻辑来保持快速访问。
- 7 bins are used by default, however, the number of bins in
fastbinsis defined byNFASTBINS
默认使用 7 个 bin,但是fastbins中的 bin 数量由NFASTBINS定义 - The fast bins are singly-linked lists, and the chunks in each list are all the same size and chunks in the middle of the list need never be accessed.
fast bin 是单链表,每个列表中的块大小都相同,并且列表中间的块永远不需要访问。 - On
x64machines, the sizes range from0x20-0x80by default. The size of each bin increase by 0x10 bytes. So a chunk of size0x20-0x2fwould fit intoidx0, a chunk of size0x30-0x3fwould fit intoidx1, and so on and so forth.
在x64计算机上,默认情况下大小范围为0x20-0x80。每个 bin 的大小增加 0x10 字节。因此,大小为0x20-0x2f的块将适合idx0,大小为0x30-0x3f的块将适合idx1,依此类推。 - The in-use flag of chunks added to a fast bin is always set to 1 so that they will not combine with adjacent chunks to keep access fast (hence fast bins). However, if the chunks in fast/small bins cannot satisfy, the fast bin would be consolidated.
添加到快速容器的块的使用中标志始终设置为 1,以便它们不会与相邻块组合以保持快速访问(因此是快速容器)。然而,如果快速/小型容器中的块不能满足,则快速容器将被合并。 - LIFO manner 后进先出方式
Unsorted Bin
The bins[] actually contains 3 different kind of bins: unsorted bin, small bins andlarge bins.
bins[] 实际上包含 3 种不同类型的 bin: unsorted bin 、 small bins 和 large bins 。
The bins[1] is unsorted bin (bins[0] is unused). When chunks are free, they’re initially stored in a single bin. They’re sorted later, in malloc, in order to give them one chance to be quickly re-used. This also means that the sorting logic only needs to exist at one point - everyone else just puts free chunks into this bin, and they’ll get sorted later. The “unsorted” bin is simply the first of the regular bins.
bins[1] 是未排序的 bin(bins[0] 未使用)。当块空闲时,它们最初存储在单个容器中。稍后在 malloc 中对它们进行排序,以便给它们一次快速重用的机会。这也意味着排序逻辑只需要在某一点存在——其他人只需将空闲块放入这个垃圾箱中,然后它们就会被排序。 “未分类”垃圾箱只是常规垃圾箱中的第一个。
We would see how unsorted bin be used later in the allocation algorithm.
稍后我们将在分配算法中看到如何使用 unsorted bin 。
Small Bins
- There are 62 small bins (index 2-63), and each bin is a doubly-linked list;
有62个小bin(索引2-63),每个bin是一个双向链表; - Each bin(list) has an identical size. The bin with index
nhas a chunk size(16n, 16n+16);
每个箱(列表)具有相同的大小。索引为n的 bin 的块大小为(16n, 16n+16); - The max size of small bins is defined by MIN_LARGE_SIZE, which usually be 1024B(1KB);
Small bin 的最大大小由 MIN_LARGE_SIZE 定义,通常为 1024B(1KB); - FIFO manner; 先进先出方式;
Large Bins
-
There are 63 small bins (index 64-127), and each bin is a doubly-linked list;
有63个小bin(索引64-127),每个bin是一个双向链表; -
A particular large bin has chunks of different sizes, sorted in decreasing order (i.e. largest chunk at the ‘HEAD’ and smallest chunk at the ‘TAIL’).
特定的大垃圾箱具有不同大小的块,按降序排序(即最大块位于“HEAD”,最小块位于“TAIL”)。 -
Chunk size in large bins is between
1024 Band128 KBinclusive (or whatever valueM_MMAP_THRESHOLDis set to)
大垃圾箱中的块大小介于1024 B和128 KB之间(包含1024 B和128 KB之间(或设置M_MMAP_THRESHOLD的任何值) -
Insertions and removals happen at any position within the list.
插入和删除发生在列表中的任何位置。
low-level behavior of malloc
malloc 的低级行为
chunk allocation algorithm
块分配算法
- Obtain the lock for the allocation area to prevent multi-threaded conflicts.
获取分配区域的锁,防止多线程冲突。 - Calculate the actual size of the chunk of memory that needs to be allocated.
计算需要分配的内存块的实际大小。 - If the chunk size is less than the max size of fast bins (128 bytes), try to find a suitable chunk in the fast bins. If one is found, allocation is complete. Otherwise, proceed to the next step.
如果块大小小于 fast bin 的最大大小(128 字节),请尝试在 fast bin 中找到合适的块。如果找到,则分配完成。否则,继续下一步。 - If the chunk size is less than the max size of small bins (1KB), search the small bins for a suitable chunk. If one is found, allocation is complete. Otherwise, proceed to the next step.
如果块大小小于小垃圾箱的最大大小(1KB),则在小垃圾箱中搜索合适的块。如果找到,则分配完成。否则,继续下一步。 - Tidy the unsorted memory blocks:
整理未排序的内存块:- Ptmalloc will first iterate through the chunks in the fast bins, merging adjacent chunks and linking them to the unsorted bin.
Ptmalloc 将首先迭代快速 bin 中的块,合并相邻块并将它们链接到未排序的 bin。 - Then it will iterate through the unsorted bins. If there is a chunk larger than the one being allocated in the unsorted bins, it will be split, and the remaining chunk will be placed back in the unsorted bins. If there is a chunk of the same size as the one being allocated, it will be returned and removed from the unsorted bins. If a chunk in the unsorted bins is within the range of small bins in size, it will be placed at the head of the small bins. If a chunk in the unsorted bins is within the range of large bins in size, it will be placed in a suitable position in the large bins. (The only place in the code base to put chunks in S/L bins) If the allocation is not successful, proceed to the next step.
然后它将遍历未排序的垃圾箱。如果有一个 chunk 大于 unsorted bin 中分配的 chunk,则会将其拆分,并将剩余的 chunk 放回 unsorted bin 中。如果存在与正在分配的块大小相同的块,则它将被返回并从未排序的垃圾箱中删除。如果unsorted bins中的一个chunk的大小在small bins的范围内,那么它将被放置在small bins的头部。如果unsorted bins中的一个chunk的大小在large bins的范围内,那么它将被放置在large bins中合适的位置。 (代码库中唯一将块放入 S/L bin 的位置)如果分配不成功,请继续下一步。
- Ptmalloc will first iterate through the chunks in the fast bins, merging adjacent chunks and linking them to the unsorted bin.
- Search the large bins for a suitable chunk, then split it, allocating part to the user and placing the remainder in the unsorted bin.
在大垃圾箱中搜索合适的块,然后将其拆分,将一部分分配给用户,并将剩余部分放入未排序的垃圾箱中。 - If no suitable chunk is found in the fast bins or bins, the top chunk must be used for allocation. When the top chunk is larger than the memory requested by the user, it will be split into two parts: the user chunk and the remainder chunk. The remainder chunk becomes the new top chunk.
如果在fast bins或bins中没有找到合适的chunk,则必须使用top chunk进行分配。当top chunk大于用户请求的内存时,它将被分成两部分:用户chunk和剩余chunk。剩余块成为新的顶部块。 - If the top chunk is still not large enough to meet the user’s requested size, we need to extend it through the
sbrk(main arena) ormmap(thread arena) system calls.
如果top chunk仍然不够大,无法满足用户请求的大小,我们需要通过sbrk(主竞技场)或mmap(线程竞技场)系统调用来扩展它。- If
mmapis used, a new chunk with the requested size aligned to a 4KB will be created and added to the top chunk. The top chunk will then be extended by the requested amount.
如果使用mmap,则将创建一个请求大小与4KB对齐的新块,并将其添加到顶部块。然后,顶部块将按请求的数量扩展。 - If
sbrkis used, the top chunk will be extended by the requested amount, and the remainder will be added to the unsorted bin. However, if it is the first time to callmallocin the main thread, a initialization work is needed to allocate a chunk of size (chunk_size + 128KB) align 4KB as the initial heap.
如果使用sbrk,则顶部块将按请求的数量扩展,其余部分将添加到未排序的 bin 中。但是,如果是第一次在主线程中调用malloc,则需要进行初始化工作,分配一个大小为(chunk_size + 128KB)对齐4KB的块作为初始堆。
- If
- Release the lock for the allocation area.
释放分配区域的锁。
When the user requests memory allocation using malloc, the chunk found by ptmalloc2 may not be the same size as the requested memory. In this case, the remaining portion after the split is called the last remainder chunk and is also stored in the unsorted bin.
当用户使用malloc请求内存分配时,ptmalloc2找到的chunk可能与请求的内存大小不同。在这种情况下,分割后的剩余部分称为最后剩余块,也存储在未排序的 bin 中。
chunk free algorithm
- Obtain the lock for the allocation area to ensure thread safety.
获取分配区域的锁,保证线程安全。 - If the pointer being freed is null, return and do nothing.
如果被释放的指针为空,则返回并且不执行任何操作。 - If the chunk size falls within the range of fast bins, place it in the fast bins.
如果块大小在 fast bins 范围内,则将其放入 fast bins 中。 - Check if the current chunk is a memory mapped by the
mmapsystem call. If it is, release it directly usingmunmap(). In the data structure of the previously used chunk, we can see that there is anMto indicate whether it is a memory mapped bymmap.
检查当前块是否是mmap系统调用映射的内存。如果是,则直接使用munmap()释放它。在之前使用的 chunk 的数据结构中,我们可以看到有一个M来表示它是否是mmap映射的内存。 - Check if the chunk being freed is adjacent to another free chunk. If it is, merge them and place the merged block in the unsorted bin. If the size of the merged chunk is greater than
fastbin_coalsed_threshold(128B), trigger the fastbin merge operation, where adjacent free chunks will be merged and placed in the unsorted bin.
检查正在释放的块是否与另一个空闲块相邻。如果是,则将它们合并并将合并的块放入未排序的 bin 中。如果合并后的chunk的大小大于fastbin_coalsed_threshold(128B),则触发fastbin合并操作,相邻的空闲chunk将被合并并放入unsorted bin中。 - Check if the chunk is adjacent to the top chunk. If it is, merge it directly with the top chunk. Then, check if the size of the top chunk is greater than the mmap shrink threshold (default 128KB). If it is, for the main allocation area, it will try to return part of the top chunk to the operating system. Free is finished.
检查该块是否与顶部块相邻。如果是,直接与top chunk合并。然后,检查top chunk的大小是否大于mmap收缩阈值(默认128KB)。如果是,对于主分配区域,它将尝试将部分top chunk返回给操作系统。免费完毕。
multi-threading
tcache
The tcache mechanism was introduced in version 2.26 of GNU libc’s malloc implementation, which was released on August 2, 2017, to speed up repeated (small) allocations in a single thread. It is implemented as a singly-linked list, with each thread having a list header for different-sized allocations.
tcache 机制是在 2017 年 8 月 2 日发布的 GNU libc 的 malloc 实现的 2.26 版本中引入的,以加速单个线程中的重复(小)分配。它被实现为单链表,每个线程都有一个用于不同大小分配的列表头。
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
typedef struct tcache_entry
{
struct tcache_entry *next;
struct tcache_perthread_struct *key;
} tcache_entry;
It has been described so clear in the pwn.college on what the t-cache looks like. Basically, the place used to save bkptr in fast, unsorted, and small bins has been assigned to save the tcache_struct, which is thekey.
pwn.college 已经对 t-cache 的样子描述得很清楚了。基本上,用于在快速、未排序和小容器中保存 bk ptr 的位置已被分配用于保存 tcache_struct, ,即 key 。
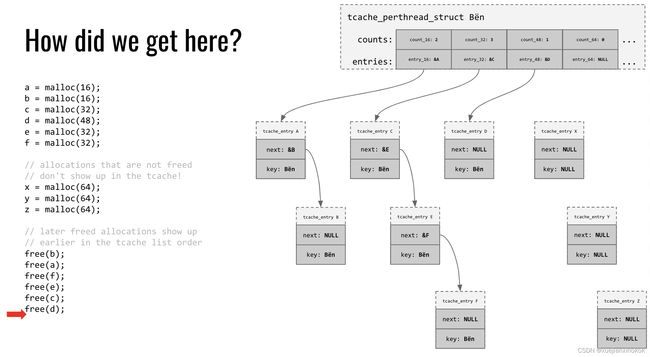
When an allocation request is made, the malloc implementation first checks the tcache for available chunks of the requested size class. If there is an available chunk, the implementation returns it to the caller. If there are no available chunks in the tcache, the malloc implementation reverts to its standard allocation algorithm to find a suitable chunk of memory.
当发出分配请求时,malloc 实现首先检查 tcache 中是否有所请求大小类别的可用块。如果有可用块,则实现将其返回给调用者。如果 tcache 中没有可用块,则 malloc 实现将恢复其标准分配算法以查找合适的内存块。

Overall layout of arenas and heaps
arena 和 heap 的总体布局
Arena per thread
In ptmalloc’s implementation, an Arena is a large, contiguous piece of memory to store per-thread heaps(a memory pool that is managed by a particular program).
在 ptmalloc 的实现中,Arena 是一块大的、连续的内存,用于存储每个线程堆(由特定程序管理的内存池)。
By using the following code, we could better understand the behavior of ptmalloc when multi-threads get involved.
通过使用下面的代码,我们可以更好地理解多线程涉及时ptmalloc的行为。
https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/
/* Per thread arena example. */
#include Before calling malloc in the main thread, we could see that there is no heap segment.
在主线程中调用 malloc 之前,我们可以看到没有堆段。
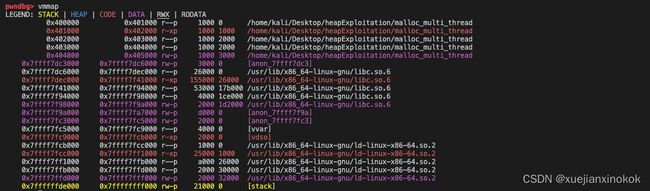
A heap segment will be created after calling malloc in the main thread, and the allocated size is often larger than the requested size to reduce switching times between kernel and user modes, thus improving program efficiency. This contiguous region of heap memory is called an Arena. Since this arena is created by the main thread, its called the main arena. Further allocation requests keep using this arena until it runs out of free space.
在主线程中调用 malloc 后会创建一个堆段,分配的大小往往大于请求的大小,以减少内核态和用户态之间的切换次数,从而提高程序效率。堆内存的这个连续区域称为 Arena 。由于这个 arena 是由主线程创建的,所以它被称为 main arena 。进一步的分配请求将继续使用此竞技场,直到可用空间耗尽。
For example, in the following case, ptmalloc2 creates a segment with size 0x21000(132KB) even though we just request 0x1000(4KB) bytes. The rest memory will be managed by ptmalloc2.
例如,在下面的情况下,ptmalloc2 创建了一个大小为 0x21000(132KB) 的段,即使我们只请求 0x1000(4KB) 字节。其余内存将由 ptmalloc2 管理。

After calling the free function in the main thread, the created memory space (heap segment) won’t be reclaimed directly but will be managed by ptmalloc2 again. When a later program requests memory, ptmalloc2 will allocate the corresponding memory to the program according to the heap allocation algorithm.
在主线程中调用 free 函数后,创建的内存空间(堆段)不会被直接回收,而是再次由ptmalloc2管理。当后面的程序请求内存时,ptmalloc2会根据堆分配算法为该程序分配相应的内存。
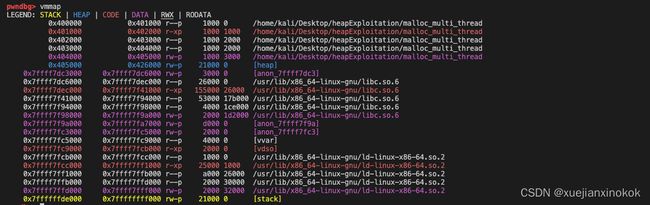
After calling pthread_create to create a thread, a size of 8MB of memory has been allocated in the memory mapping segment for the created thread. The thread has its own stack, which is located in this area. However, currently, I have no idea what does the top 4KB with permission ---p used for.
调用 pthread_create 创建线程后,内存映射段中已经为创建的线程分配了8MB大小的内存。线程有自己的堆栈,位于该区域。但是,目前我不知道具有权限 ---p 的顶部 4KB 有何用途。

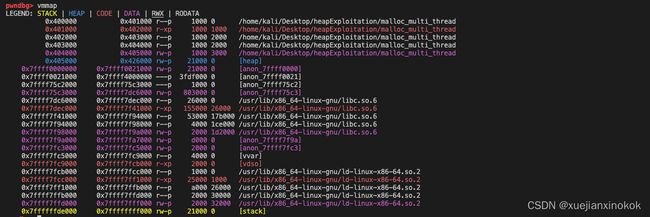
After calling malloc in thread 1, we could see the memory space with a size of 21000 bytes(132KB) again has been allocated by the ptmalloc even though we just requested 1000 bytes(4KB). But this time, the heap is in the memory mapping segment rather than following the program breaking point. This contiguous region of memory (132 KB) is called the thread arena.
在线程 1 中调用 malloc 后,我们可以看到 ptmalloc 再次分配了 21000 字节(132KB)的内存空间,尽管我们刚刚请求了 1000 字节(4KB)。但这一次,堆位于内存映射段中,而不是位于程序断点之后。这个连续的内存区域 (132 KB) 称为线程区域。
After calling free in thread 1, we can see that freeing allocated memory region doesnt release heap memory to the operating system. Instead allocated memory region (of size 1000 bytes) is released to ptmolloc, which adds this freed block to its thread arenas bin.
在线程1中调用 free 后,我们可以看到释放分配的内存区域并没有将堆内存释放给操作系统。相反,分配的内存区域(大小为 1000 字节)被释放到 ptmolloc,它将这个释放的块添加到其线程 arenas bin 中。

Another important point here is that it is not exactly one arena per thread, as expected, since it would become expensive when there are many threads. Hence, the application’s arena limit is based on the number of cores present in the system.
这里的另一个重要点是,它并不像预期的那样每个线程一个竞技场,因为当有很多线程时它会变得昂贵。因此,应用程序的 arena limit is based on the number of cores 存在于系统中。
For 32 bit systems: Number of arena = 2 * number of cores.
For 64 bit systems: Number of arena = 8 * number of cores.
The actual behavior of ptmalloc when one-to-one mapping between threads and arena doesn’t get enough could become much more complicated, so I would stop here for a starter point. More information could refer to: https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/
当线程和 arena 之间的一对一映射不够时,ptmalloc 的实际行为可能会变得更加复杂,因此我将在这里停下来作为起点。更多信息可以参考:https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/
heap_info and malloc_state
heap_info 和 malloc_state
References 参考
https://sensepost.com/blog/2017/painless-intro-to-the-linux-userland-heap/
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/heap-structure/
https://raydenchia.com/heaps-of-fun-with-glibc-malloc/
https://0x434b.dev/overview-of-glibc-heap-exploitation-techniques/
https://sourceware.org/glibc/wiki/MallocInternals
https://blog.csdn.net/weixin_37921201/article/details/119744197
https://heap-exploitation.dhavalkapil.com/attacks/double_free
https://www.zhihu.com/aria/question/447017261/answer/3304990306 内存划分为什么要分为堆和栈,当初设计这两个的时候分别是要解决什么问题?
原文地址