The Cherno C++笔记02
目录
Part 06 How the C++ Compiler Works
1.编译过程
2.C++并不关心文件
3.翻译单元(Translation Unit)
4. 实际用代码感受一下编译过程
4.1 预处理
4.1.1 预处理的本质
4.1.2 预处理后的.i文件
4.1.3 骚操作
4.2 .asm文件(汇编语言源文件)
4.2.1 直观感受优化
4.2.2 常量折叠(Constant Folding)
Part 06 How the C++ Compiler Works
1.编译过程
我们在编译软件上写的内容,实际上就是文本,那从文本到可执行的程序,中间需要经过两步,编译和链接。编译就是将文本转化为.obj后缀的目标文件。
编译又可以分为几个步骤:
①预处理(Preprocessing)
②词法分析(Lexical Analysi)
③语法分析(Syntax Analysis)
④语义分析(Semantic Analysis)
⑤优化(Optimization)
⑥代码生成(Code Generation)
我们可以用一个简单的例子来直观感受一下每个过程
源代码:
#include
int main() {
int a = 5;
int b = 7;
int sum = a + b;
printf("Sum is: %d\n", sum);
return 0;
}
词法分析生成词法单元(Tokens)
Keyword: include
Identifier:
Keyword: int
Identifier: main
Punctuation: (
Punctuation: )
Punctuation: {
Keyword: int
Identifier: a
Operator: =
Number: 5
Punctuation: ;
...
语法分析生成抽象语法树(AST)
Program
|
└── Function: main
├── Declaration: int a
├── Assignment: a = 5
├── Declaration: int b
├── Assignment: b = 7
├── Declaration: int sum
├── Assignment: sum = a + b
├── Function Call: printf
│ ├── String: "Sum is: %d\n"
│ ├── Argument: sum
└── Return: 0
语义分析:
- 语义信息:
- 类型检查通过,变量和函数引用有效。
- 符号表记录了变量的类型和位置。
优化(Optimization):
int a = 5;
int b = 7;
int sum = a + b;
printf("Sum is: %d\n", sum);
return 0;
代码生成(Code Generation)
MOV a, 5
MOV b, 7
ADD sum, a, b
PRINT "Sum is: %d\n", sum
HALT
转成obj机器码
2.C++并不关心文件
这主要是跟Java做对比
在Java中,一个源代码文件通常对应一个类,且文件名与类名相同,并以 .java 为扩展名。而在C++中:源代码可以分布在多个文件中,每个文件独立地包含了一部分程序的实现。这些文件可以包含函数、类、变量的定义和实现等。默认情况下编译器看到.h文件会将其作为头文件处理,见到.cpp文件会将其作为源文件处理。你可以改变它,不具有强制性。
总而言之:
在Java中,文件名与类名的匹配是强制性的,而且有严格的规范。这种规范有助于提高代码的可读性和可维护性,但也限制了一定的灵活性。
在C++中,虽然有一些约定(例如使用.cpp作为源文件的扩展名),但这些并非强制性规定。C++更加注重灵活性和兼容性,允许开发者使用不同的扩展名或者甚至没有扩展名。这种灵活性允许开发者更自由地组织和命名源文件,但也可能导致一些不规范的实践。
3.翻译单元(Translation Unit)
在编译过程中被处理的最小单元。在C++中一个源文件和一个头文件通常就是一个翻译单元。一个翻译单元作为编译器的输入,经过编译过程后生成一个目标文件,然后多个目标文件可以被链接在一起形成最终的可执行程序。
4. 实际用代码感受一下编译过程
4.1 预处理
4.1.1 预处理的本质
预处理其实就是复制粘贴头文件的内容
我们写两个源文件感受一下:
math.cpp(没有包含任何头文件)
int Multiply(int a, int b)
{
return a + b;
}Log.cpp(包含iostream头文件)
#include
void Log(const char* message)
{
std::cout << message << std::endl;
}
然后我们单独编译(Ctrl+F7)
得到两个obj文件

大小差距很大,造成这种现象的原因就是包含头文件,预处理会把头文件的内容全部复制到Log.cpp中来。
4.1.2 预处理后的.i文件
.i 文件是指预处理后的源文件。在C和C++编译过程中,预处理器会对源文件进行处理,展开宏、处理条件编译指令等,并生成一个经过预处理的中间文件。这个中间文件的扩展名通常是.i。
我们可以通过更改下面的设置来让他生成预处理后的.i文件
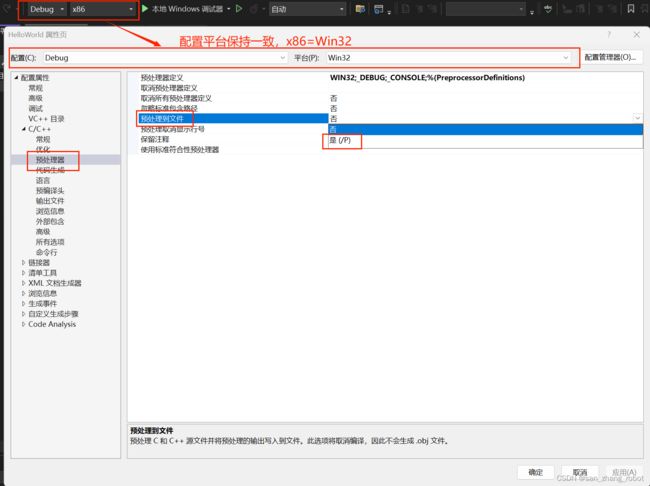
对Main.cpp文件预处理
#include
void Log(const char* message);
int main()
{
Log("Hello World!");//用Log函数实现打印的功能
std::cin.get();
}

文本编辑器打开Main.i文件
我们会直观的发现这个现象
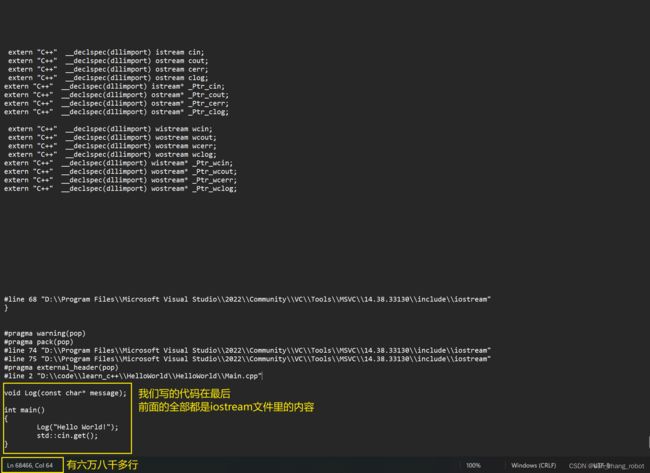
4.1.3 骚操作
利用这个特点我们可以实现一些骚操作
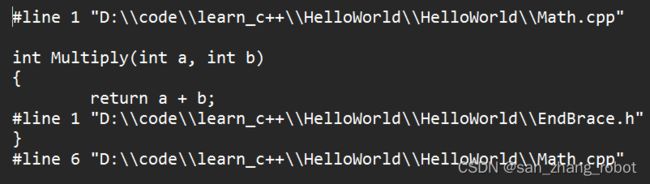
建一个只有一个结束大括号的头文件
EndBrace.h
}然后将原本.cpp文件中的结束大括号改成#include “EndBrace.h”(自己建立的头文件用双引号)还能编译成功吗?
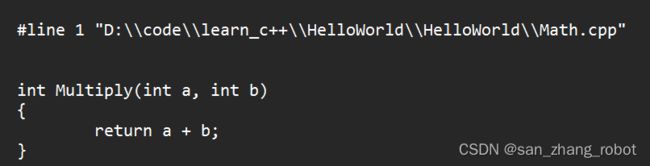
Math.cpp(替换)
int Multiply(int a, int b)
{
return a + b;
#include "EndBrace.h"
成功!
打开生成的.i文件
还可以利用宏定义
#define (被替换的内容) (替换后的内容)
#define Age 18 就是在预处理的时候,把代码里面的Age全部替换成18
Math.cpp(替换)
#define INTEGER int
INTEGER Multiply(INTEGER a, INTEGER b)
{
return a + b;
}
成功!
打开生成的.i文件
#if 预处理指令用于条件编译。它允许根据指定的条件来选择性地包含或排除部分代码。
Math.cpp(替换)
#if 1
int Multiply(int a, int b)
{
return a + b;
}
#endif
打开生成的.i文件

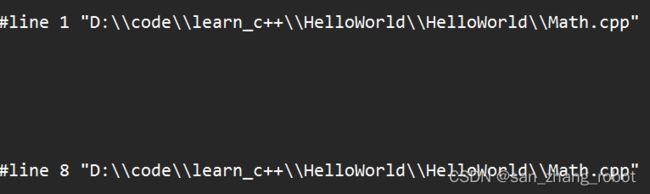
Math.cpp(替换)
#if 0
int Multiply(int a, int b)
{
return a + b;
}
#endif
v打开生成的.i文件
4.2 .asm文件(汇编语言源文件)
关闭刚才的设置
更改汇编语言文件输出

这里我们可以看到源代码的汇编语言格式
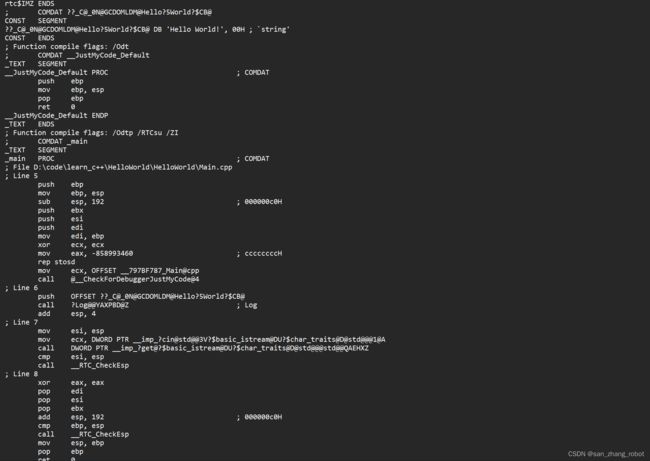
4.2.1 直观感受优化
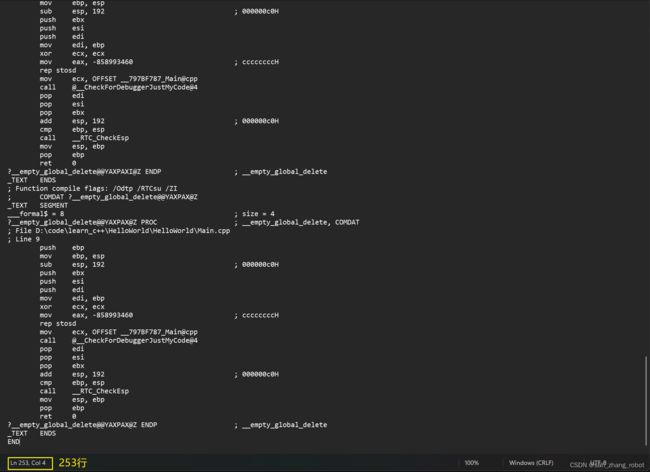
Debug版本总共有253行
如果我们改一下Debug版本的设置为
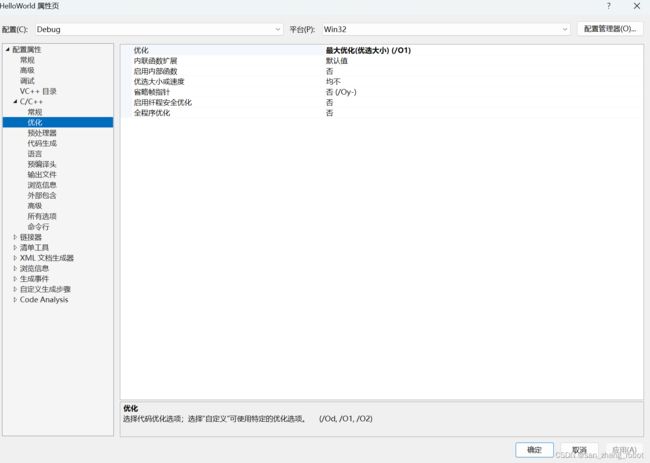
这个时候我们继续运行编译
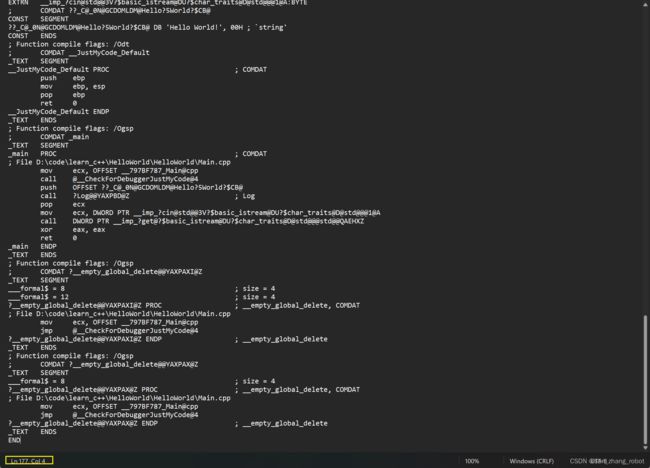
只有177行
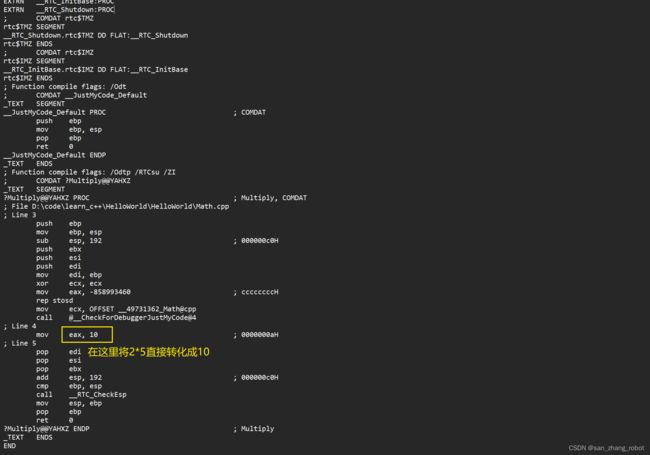
4.2.2 常量折叠(Constant Folding)
常量折叠(Constant Folding)是编译器在编译时对表达式中的常量进行计算和简化的过程。在这个过程中,编译器会尽可能地将表达式中的常量计算出结果,以减少运行时的开销。
改一下Math.h
int Multiply()
{
return 2*5;
}
编译,并查看生成的汇编文件.asm