并发编程-1.并发线程与等待通知机制
学习内容:
1.并发编程基础概念
2.hello,线程
3.线程的状态/生命周期
4.线程的优先级和调度
5.辨析线程和协程
6.管道输入输出流
7.join方法详解
8.详解synchronized
9.volatile详解
10.并发的等待通知机制
11.CompleteableFuture详解
基础概念
进程和线程
进程
应用程序由指令和数据组成。
进程就可以视为程序的一个实例。大部分程序可以同时运行多个实例进程(例如记事本、画图、浏览器 等),也有的程序只能启动一个实例进程(例如网易云音乐、360 安全卫士等)。显然,程序是死的、静态的,进程是活的、动态的。进程可以分为系统进程和用户进程。凡是用于完成操作系统的各种功能的进程就是系统进程,它们就是处于运行状态下的操作系统本身,用户进程就是所有由你启动的进程。
站在操作系统的角度,进程是程序运行资源分配(以内存为主)的最小单位。
线程
线程是CPU调度的最小单位。
线程必须依赖于进程而存在,线程是进程中的一个实体,是CPU调度和分派的基本单位,它是比进程更小的、能独立运行的基本单位。线程自己基本上不拥有系统资源,,只拥有在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。一个进程可以拥有多个线程,一个线程必须有一个父进程。线程,有时也被称为轻量级进程(Lightweight Process,LWP),早期Linux的线程实现几乎就是复用的进程,后来才独立出自己的API。
Java线程的无处不在
Java中不管任何程序都必须启动一个main函数的主线程; Java Web开发里面的定时任务、定时器、JSP和 Servlet、异步消息处理机制,远程访问接口RM等,任何一个监听事件,onclick的触发事件等都离不开线程和并发的知识。
进程间的通信
同一台计算机的进程通信称为 IPC(Inter-process communication),不同计算机之间的进程通信被称为R(mote)PC,需要通过网络,并遵守共同的协议,比如大家熟悉的Dubbo就是一个RPC框架,而Http协议也经常用在RPC上,比如SpringCloud微服务。
进程间通信有几种方式?
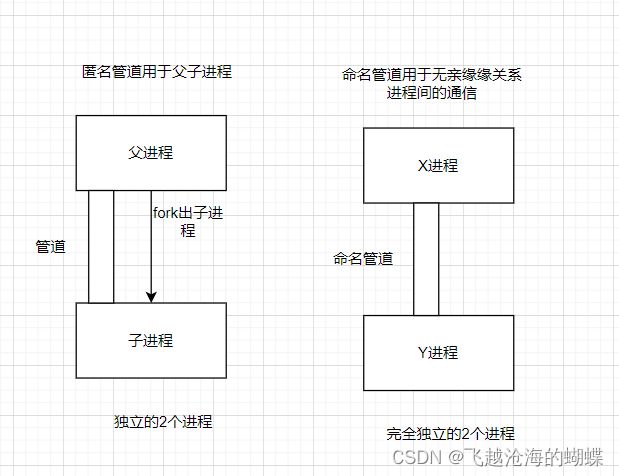
1. 管道,分为匿名管道(pipe)及命名管道(named pipe):匿名管道可用于具有亲缘关系的父子进程间的通信,命名管道除了具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。
2. 信号(signal):信号是在软件层次上对中断机制的一种模拟,它是比较复杂的通信方式,用于通知进程有某事件发生,一个进程收到一个信号与处理器收到一个中断请求效果上可以说是一致的。
3. 消息队列(message queue):消息队列是消息的链接表,它克服了上两种通信方式中信号量有限的缺点,具有写权限得进程可以按照一定得规则向消息队列中添加新信息;对消息队列有读权限得进程则可以从消息队列中读取信息。
4. 共享内存(shared memory):可以说这是最有用的进程间通信方式。它使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据得更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。
5. 信号量(semaphore):主要作为进程之间及同一种进程的不同线程之间得同步和互斥手段。
6. 套接字(socket):这是一种更为一般得进程间通信机制,它可用于网络中不同机器之间的进程间通信,应用非常广泛。同一机器中的进程还可以使用Unix domain socket(比如同一机器中MySQL中的控制台mysql shell和MySQL服务程序的连接),这种方式不需要经过网络协议栈,不需要打包拆包、计算校验和、维护序号和应答等,比纯粹基于网络的进程间通信肯定效率更高。
CPU核心数和线程数的关系
CPU内核和同时运行的线程数是1:1的关系,也就是说8核CPU同时可以执行8个线程的代码。但 Intel引入超线程技术后,产生了逻辑处理器的概念,使核心数与线程数形成1:2的关系。
在Java中提供了Runtime.getRuntime().availableProcessors(),可以获取当前的CPU核心数,注意这个核心数指的是逻辑处理器数。
并发编程下的性能优化往往和CPU核心数密切相关。
上下文切换(Context switch)
CPU从一个进程或线程到另一个进程或线程的切换。
引发上下文切换的原因一般包括:线程、进程切换、系统调用等等。上下文切换通常是计算密集型的,因为涉及一系列数据在各种寄存器、 缓存中的来回拷贝。就CPU时间而言,一次上下文切换大概需要5000~20000个时钟周期,相对一个简单指令几个乃至十几个左右的执行时钟周期,可以看出这个成本的巨大。

并行和并发
并发Concurrent:指应用能够交替执行不同的任务
并行Parallel:指应用能够同时执行不同的任务
两者区别:一个是交替执行,一个是同时执行
认识Java里的线程
Java程序天生就是多线程的
一个Java程序从main()方法开始执行,然后按照既定的代码逻辑执行,看似没有其他线程参与,但实际上Java程序天生就是多线程程序,因为执行main()方法的是一个名称为main的线程。
而一个Java程序的运行就算是没有用户自己开启的线程,实际也有有很多JVM自行启动的线程,一般来说有:
[6] Monitor Ctrl-Break //监控Ctrl-Break中断信号的
[5] Attach Listener //内存dump,线程dump,类信息统计,获取系统属性等
[4] Signal Dispatcher // 分发处理发送给JVM信号的线程
[3] Finalizer // 调用对象finalize方法的线程
[2] Reference Handler//清除Reference的线程
[1] main //main线程,用户程序入口
尽管这些线程根据不同的JDK版本会有差异,但是依然证明了Java程序天生就是多线程的。
线程的启动与中止
启动
启动线程的方式有:
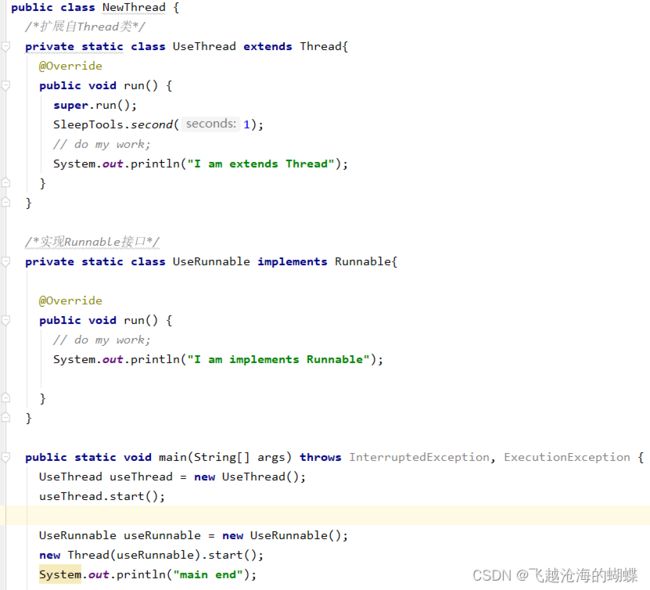
1、X extends Thread;,然后X.start

2、X implements Runnable;然后交给Thread运行

运行代码示例:
Thread和Runnable的区别
Thread才是Java里对线程的唯一抽象,Runnable只是对任务(业务逻辑)的抽象。Thread可以接受任意一个Runnable的实例并执行。
Callable、Future和FutureTask
Runnable是一个接口,在它里面只声明了一个run()方法,由于run()方法返回值为void类型,所以在执行完任务之后无法返回任何结果。
Callable位于java.util.concurrent包下,它也是一个接口,在它里面也只声明了一个方法,只不过这个方法叫做call(),这是一个泛型接口,call()函数返回的类型就是传递进来的V类型。
Future就是对于具体的Runnable或者Callable任务的执行结果进行取消、查询是否完成、获取结果。必要时可以通过get方法获取执行结果,该方法会阻塞直到任务返回结果。

因为Future只是一个接口,所以是无法直接用来创建对象使用的,因此就有了下面的FutureTask。


FutureTask类实现了RunnableFuture接口,RunnableFuture继承了Runnable接口和Future接口。所以它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值。

因此通过一个线程运行Callable,但是Thread不支持构造方法中传递Callable的实例,所以需要通过FutureTask把一个Callable包装成Runnable,然后再通过这个FutureTask拿到Callable运行后的返回值。
要new一个FutureTask的实例,有两种方法
新启线程有几种方式?
这个问题的答案其实众说纷纭,有2种,3种,4种等等答案,个人认为比较好的说法是:
按照Java源码中Thread上的注释:
* There are two ways to create a new thread of execution. One is to
* declare a class to be a subclass of Thread. This
* subclass should override the run method of class
* Thread. An instance of the subclass can then be
* allocated and started. For example, a thread that computes primes
* larger than a stated value could be written as follows:
*
* class PrimeThread extends Thread {
* long minPrime;
* PrimeThread(long minPrime) {
* this.minPrime = minPrime;
* }
*
* public void run() {
* // compute primes larger than minPrime
* ...
* }
* }
*
*
* The following code would then create a thread and start it running:
*
* PrimeThread p = new PrimeThread(143);
* p.start();
*
*
* The other way to create a thread is to declare a class that
* implements the Runnable interface. That class then
* implements the run method. An instance of the class can
* then be allocated, passed as an argument when creating
* Thread, and started. The same example in this other
* style looks like the following:
*
* class PrimeRun implements Runnable {
* long minPrime;
* PrimeRun(long minPrime) {
* this.minPrime = minPrime;
* }
*
* public void run() {
* // compute primes larger than minPrime
* ...
* }
* }
*
*
* The following code would then create a thread and start it running:
*
* PrimeRun p = new PrimeRun(143);
* new Thread(p).start();
*
* 官方说法是在Java中有两种方式创建一个线程用以执行,一种是派生自Thread类,另一种是实现Runnable接口。
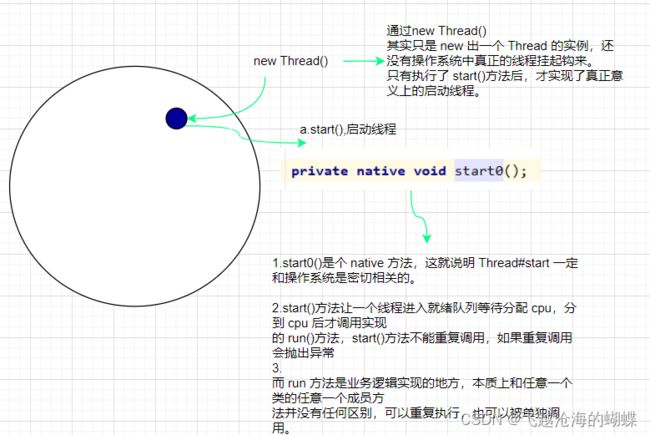
当然本质上Java中实现线程只有一种方式,都是通过new Thread()创建线程对象,调用Thread#start启动线程。
至于基于callable接口的方式,因为最终是要把实现了callable接口的对象通过FutureTask包装成Runnable,再交给Thread去执行,所以这个其实可以和实现Runnable接口看成同一类。
而线程池的方式,本质上是池化技术,是资源的复用,和新启线程没什么关系。
所以,比较赞同官方的说法,有两种方式创建一个线程用以执行。
中止
线程自然终止
要么是run执行完成了,要么是抛出了一个未处理的异常导致线程提前结束。
stop

暂停、恢复和停止操作对应在线程Thread的API就是suspend()、resume()和stop()。但是这些API不建议使用,副作用比较多。
中断
安全的中止则是其他线程通过调用某个线程A的interrupt()方法对其进行中断操作。

如果一个线程处于了阻塞状态(如线程调用了thread.sleep、thread.join、thread.wait等),则在线程在检查中断标示时如果发现中断标示为true,则会在这些阻塞方法调用处抛出InterruptedException异常,并且在抛出异常后会立即将线程的中断标示位清除,即重新设置为false。
注意:处于死锁状态的线程无法被中断
理解run()和start()
学习Java的线程
线程的状态/生命周期
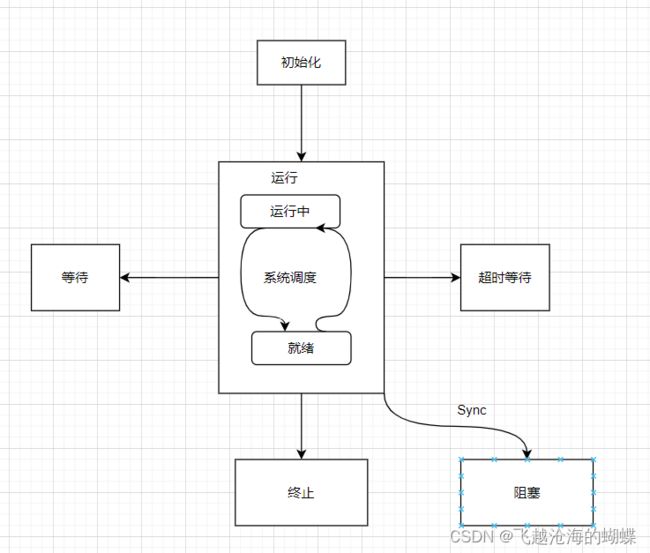
Java中线程的状态分为6种:
1. 初始(NEW):新创建了一个线程对象,但还没有调用start()方法。
2. 运行(RUNNABLE):Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“运行”。
线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取CPU的使用权,此时处于就绪状态(ready)。就绪状态的线程在获得CPU时间片后变为运行中状态(running)。
3. 阻塞(BLOCKED):表示线程阻塞于锁。
4. 等待(WAITING):进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
5. 超时等待(TIMED_WAITING):该状态不同于WAITING,它可以在指定的时间后自行返回。
6. 终止(TERMINATED):表示该线程已经执行完毕。
状态之间的变迁如下图所示
yield()方法:使当前线程让出CPU占有权,但让出的时间是不可设定的。也不会释放锁资源。同时执行yield()的线程有可能在进入到就绪状态后会被操作系统再次选中马上又被执行。
线程的优先级
在Java线程中,通过一个整型成员变量priority来控制优先级,优先级的范围从1~10,在线程构建的时候可以通过setPriority(int)方法来修改优先级,默认优先级是5,优先级高的线程分配时间片的数量要多于优先级低的线程。
在不同的JVM以及操作系统上,线程规划会存在差异,有些操作系统甚至会忽略对线程优先级的设定。
线程的调度
线程调度是指系统为线程分配CPU使用权的过程,主要调度方式有两种:
- 协同式线程调度
- 抢占式线程调度
使用协同式线程调度的多线程系统,线程执行的时间由线程本身来控制,线程把自己的工作执行完之后,要主动通知系统切换到另外一个线程上。使用协同式线程调度的最大好处是实现简单,由于线程要把自己的事情做完后才会通知系统进行线程切换,所以没有线程同步的问题,但是坏处也很明显,如果一个线程出了问题,则程序就会一直阻塞。
使用抢占式线程调度的多线程系统,每个线程执行的时间以及是否切换都由系统决定。在这种情况下,线程的执行时间不可控,所以不会有「一个线程导致整个进程阻塞」的问题出现。
线程和协程
任何语言实现线程主要有三种方式:使用内核线程实现(1:1实现),使用用户线程实现(1:N实现),使用用户线程加轻量级进程混合实现(N:M实现)。
Java线程的实现
以HotSpot为例,它的每一个Java线程都是直接映射到一个操作系统原生线程来实现的,而且中间没有额外的间接结构, 所以HotSpot自己是不会去干涉线程调度的,全权交给底下的操作系统去处理。
Java线程调度是抢占式调度而且Java中的线程优先级是通过映射到操作系统的原生线程上实现的,所以线程的调度最终取决于操作系统,操作系统中线程的优先级有时并不能和Java中的一一对应,所以Java优先级并不是特别靠谱。
协程
协程简介
由于最初多数的用户线程是被设计成协同式调度(Cooperative Scheduling) 的,所以它有了一个别名——“协程”(Coroutine) 完整地做调用栈的保护、恢复工作,所以今天也被称为“有栈协程”(Stackfull Coroutine)。
协程的主要优势是轻量, 无论是有栈协程还是无栈协程, 都要比传统内核线程要轻量得多。如果进行量化的话, 那么如果不显式设置,则在64位Linux上HotSpot的线程栈容量默认是1MB, 此外内核数据结构(Kernel Data Structures) 还会额外消耗16KB内存。与之相对的, 一个协程的栈通常在几百个字节到几KB之间, 所以Java虚拟机里线程池容量达到两百就已经不算小了, 而很多支持协程的应用中, 同时并存的协程数量可数以十万计。
协程当然也有它的局限, 需要在应用层面实现的内容(调用栈、 调度器这些)特别多,同时因为协程基本上是协同式调度,则协同式调度的缺点自然在协程上也存在。
总的来说,协程机制适用于被阻塞的,且需要大量并发的场景(网络io),不适合大量计算的场景,因为协程提供规模(更高的吞吐量),而不是速度(更低的延迟)。
纤程-Java中的协程
Java开发组就Java中协程的实现也做了很多努力,OpenJDK在2018年创建了Loom项目,这是Java的官方解决方案, 并用了“纤程(Fiber)”这个名字。
目前Java中比较出名的协程库是Quasar(Loom项目的Leader就是Quasar的作者Ron Pressler), Quasar的实现原理是字节码注入,在字节码层面对当前被调用函数中的所有局部变量进行保存和恢复。这种不依赖Java虚拟机的现场保护虽然能够工作,但影响性能。
Quasar实战
本实战的代码是单独的项目quasar。
Quasar的使用其实并不复杂,首先引入Maven依赖
在具体的业务场景上,模拟调用某个远程的服务,假设远程服务处理耗时需要1S,使用休眠1S来代替。为了比较,用多线程和协程分别调用这个服务10000次,来看看两者所需的耗时。
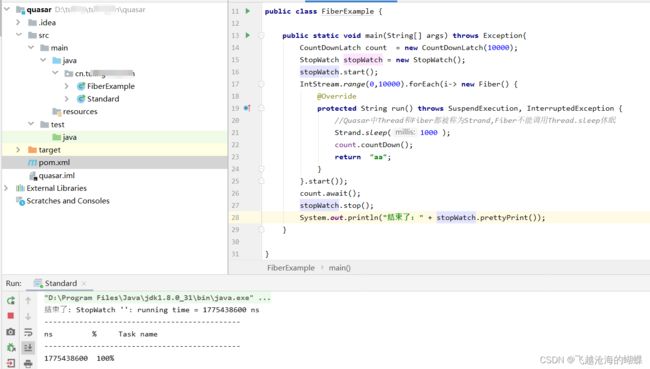
Quasar的:
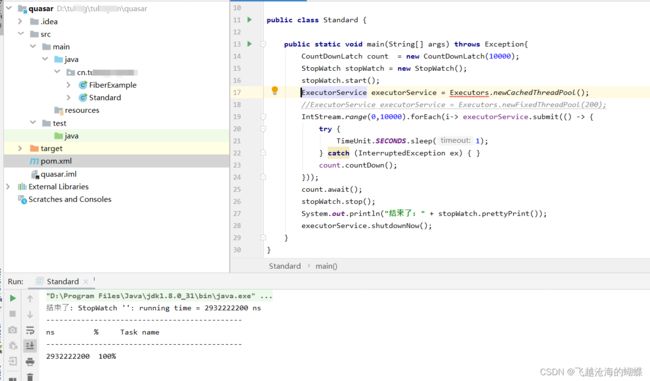
线程的:
其中的Fiber就是Quasar提供的协程相关的类,可以类比为Java中的Thread类。
其他的CountDownLatch(闭锁,线程的某种协调工具类)、Executors.newCachedThreadPool(线程池)。StopWatch是Spring的一个工具类,一个简单的秒表工具,可以计时指定代码段的运行时间以及汇总这个运行时间。
在执行Quasar的代码前,还需要配置VM参数(Quasar的实现原理是字节码注入,所以,在运行应用前,需要配置好quasar-core的java agent地址)
-javaagent:D:\localmaven\maven\co\paralleluniverse\quasar-core\0.7.9\quasar-core-0.7.9.jar
执行结果可以看到性能的提升还是非常明显的。而且上面多线程编程时,并没有指定线程池的大小,在实际开发中是绝不允许的。一般会设置一个固定大小的线程池,因为线程资源是宝贵,线程多了费内存还会带来线程切换的开销。上面的场景在设置200个固定大小线程池时(Executors.newFixedThreadPool(200)),在本机的测试结果达到了50多秒,几乎是数量级的增加。
由这个结果也可以看到协程在需要处理大量IO的情况下非常具有优势,基于固定的几个线程调度,可以轻松实现百万级的协程处理,而且内存消耗非常平稳。
更多Quasar的使用方法和技巧,请自行挖掘和学习。
守护线程
Daemon(守护)线程是一种支持型线程,因为它主要被用作程序中后台调度以及支持性工作。这意味着,当一个Java虚拟机中不存在非Daemon线程的时候,Java虚拟机将会退出。可以通过调用Thread.setDaemon(true)将线程设置为Daemon线程。一般用不上,比如垃圾回收线程就是Daemon线程。
Daemon线程被用作完成支持性工作,但是在Java虚拟机退出时Daemon线程中的finally块并不一定会执行。在构建Daemon线程时,不能依靠finally块中的内容来确保执行关闭或清理资源的逻辑。
线程间的通信和协调、协作
很多的时候,孤零零的一个线程工作并没有什么太多用处,更多的时候,我们是很多线程一起工作,而且是这些线程间进行通信,或者配合着完成某项工作,这就离不开线程间的通信和协调、协作。
管道输入输出流
进程间有好几种通信机制,其中包括了管道,其实Java的线程里也有类似的管道机制,用于线程之间的数据传输,而传输的媒介为内存。
Java中的管道输入/输出流主要包括了如下4种具体实现:PipedOutputStream、PipedInputStream、PipedReader和PipedWriter,前两种面向字节,而后两种面向字符。
join方法
join()
把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行。比如在线程B中调用了线程A的Join()方法,直到线程A执行完毕后,才会继续执行线程B剩下的代码。
synchronized内置锁
线程开始运行,拥有自己的栈空间,就如同一个脚本一样,按照既定的代码一步一步地执行,直到终止。如果多个线程能够相互配合完成工作,包括数据之间的共享,协同处理事情。这将会带来巨大的价值。
Java支持多个线程同时访问一个对象或者对象的成员变量,关键字synchronized可以修饰方法或者以同步块的形式来进行使用,它主要确保多个线程在同一个时刻,只能有一个线程处于方法或者同步块中,它保证了线程对变量访问的可见性和排他性,又称为内置锁机制。
对象锁和类锁:
对象锁是用于对象实例方法,或者一个对象实例上的,类锁是用于类的静态方法或者一个类的class对象上的。类的对象实例可以有很多个,但是每个类只有一个class对象,所以不同对象实例的对象锁是互不干扰的,但是每个类只有一个类锁。
类锁和对象锁之间也是互不干扰的。
错误的加锁和原因分析
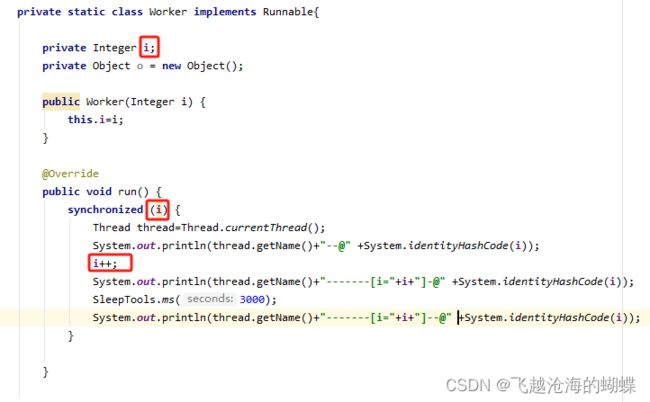
原因:虽然对i进行了加锁,但是

但是当反编译这个类的class文件后,可以看到i++实际是,

本质上是返回了一个新的Integer对象。也就是每个线程实际加锁的是不同的Integer对象。
volatile,最轻量的通信/同步机制
volatile保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。

不加volatile时,子线程无法感知主线程修改了ready的值,从而不会退出循环,而加了volatile后,子线程可以感知主线程修改了ready的值,迅速退出循环。
但是volatile不能保证数据在多个线程下同时写时的线程安全,volatile最适用的场景:一个线程写,多个线程读。
等待/通知机制
线程之间相互配合,完成某项工作,比如:一个线程A修改了一个对象的值,而另一个线程B感知到了变化,然后进行相应的操作,整个过程开始于一个线程A,而最终执行又是另一个线程B。前者是生产者,后者就是消费者,简单的办法是让消费者线程不断地循环检查变量是否符合预期在while循环中设置不满足的条件,如果条件满足则退出while循环,从而完成消费者的工作。却存在如下问题:
1)难以确保及时性。
2)难以降低开销。
等待/通知机制则可以很好的避免,这种机制是指一个线程A调用了对象O的wait()方法进入等待状态,而另一个线程B调用了对象O的notify()或者notifyAll()方法,线程A收到通知后从对象O的wait()方法返回,进而执行后续操作。
notify():
通知一个在对象上等待的线程,使其从wait方法返回,而返回的前提是该线程获取到了对象的锁,没有获得锁的线程重新进入WAITING状态。
notifyAll():
通知所有等待在该对象上的线程
wait()
调用该方法的线程进入 WAITING状态,只有等待另外线程的通知或被中断才会返回.需要注意,调用wait()方法后,会释放对象的锁
wait(long)
超时等待一段时间,这里的参数时间是毫秒,也就是等待长达n毫秒,如果没有通知就超时返回
wait (long,int)
对于超时时间更细粒度的控制,可以达到纳秒
等待和通知的标准范式
等待方遵循如下原则。
1)获取对象的锁。
2)如果条件不满足,那么调用对象的wait()方法,被通知后仍要检查条件。
3)条件满足则执行对应的逻辑。

通知方遵循如下原则。
1)获得对象的锁。
2)改变条件。
3)通知所有等待在对象上的线程。

注意:尽可能用notifyall(),谨慎使用notify(),因为notify()只会唤醒一个线程,我们无法确保被唤醒的这个线程一定就是我们需要唤醒的线程
等待超时模式实现一个连接池
调用场景:调用一个方法时等待一段时间,如果该方法能够在给定的时间段之内得到结果,那么将结果立刻返回,反之,超时返回默认结果。
假设等待时间段是T,那么可以推断出在当前时间now+T之后就会超时
等待持续时间:REMAINING=T。
•超时时间:FUTURE=now+T。
// 对当前对象加锁
public synchronized Object get(long mills) throws InterruptedException {
long future = System.currentTimeMillis() + mills;
long remaining = mills;
// 当超时大于0并且result返回值不满足要求
while ((result == null) && remaining > 0) {
wait(remaining);
remaining = future - System.currentTimeMillis();
}
return result;
}
客户端获取连接的过程被设定为等待超时的模式,也就是在1000毫秒内如果无法获取到可用连接,将会返回给客户端一个null。设定连接池的大小为10个,然后通过调节客户端的线程数来模拟无法获取连接的场景。
它通过构造函数初始化连接的最大上限,通过一个双向队列来维护连接,调用方需要先调用fetchConnection(long)方法来指定在多少毫秒内超时获取连接,当连接使用完成后,需要调用releaseConnection(Connection)方法将连接放回线程池
方法和锁
yield() 、sleep()被调用后,都不会释放当前线程所持有的锁。
调用wait()方法后,会释放当前线程持有的锁,而且当前被唤醒后,会重新去竞争锁,锁竞争到后才会执行wait方法后面的代码。
调用notify()系列方法后,对锁无影响,线程只有在syn同步代码执行完后才会自然而然的释放锁,所以notify()系列方法一般都是syn同步代码的最后一行。