Python学习路线 - Python语言基础入门 - Python异常、模块与包
Python学习路线 - Python语言基础入门 - Python异常、模块与包
-
- 了解异常
-
- 什么是异常
- bug单词的诞生
- 异常演示
- 异常的捕获方法
-
- 为什么要捕获异常
- 捕获常规异常
- 捕获指定异常
- 捕获多个异常
- 捕获异常并输出描述信息
- 捕获所有异常
- 异常 else
- 异常的finally
- 异常的传递
- Python模块
-
- 什么是模块
- 模块的导入方式
- import模块名
- from模块名import功能名
- from模块名import*
- as定义别名
- 制作自定义模块
- 注意事项
- 测试模块
- __all__
- Python包
-
- 什么是Python包
- 快速入门
- 导入包
-
- 方式一
- 方式二
- 安装第三方Python包
-
- 什么是第三方包
- 安装第三方包 - pip
- pip的网络优化
- 安装第三方包 - PyCharm
- 综合案例
了解异常
什么是异常
当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的"异常",也就是我们常说的BUG

bug单词的诞生
早期计算机采用大量继电器工作,马克二型计算机就是这样的。
1945年9月9日,下午三点,马克二型计算机无法正常工作了,技术人员试了很多办法,最后定位到第70号继电器出错。负责人哈伯观察这个出错的继电器,发现一只飞蛾在中间,已经被继电器打死。她小心地用镊子将蛾子夹出来,用透明胶布贴到"事件记录本"中,并注明"第一个发现虫子的实例。" 自此之后,引发软件失效的缺陷,便被称为Bug。

异常演示
例如:以’r’的方式打开一个不存在的文件。
![]()
执行结果:

总结:
1.什么是异常:
异常就是程序运行的过程中出现了错误
2.bug是什么意思:
bug就是指异常的意思,因为历史因为小虫子导致计算机失灵的案例,所以延续至今,bug就代表软件出现错误。
代码演示:
"""
主动写一段错误代码,演示异常的出现
"""
# 通过open,读取一个不存在的文件
f = open("D:/abc.tex", "r", encoding="UTF-8")

异常的捕获方法
为什么要捕获异常
世间上没有完美的程序,任何程序在运行的过程中,都有可能出现:异常,也就是出现Bug,导致程序无法完美运行下去。
我们要做的,不是力求程序完美运行。而是在力所能及的范围内,对可能出现的bug,进行提前准备、提前处理。
这种行为我们称之为:异常处理(捕获异常)
当我们的程序遇到了BUG,那么接下来有两种情况:
① 整个程序因为一个BUG停止运行
② 对BUG进行提醒, 整个程序继续运行
显然在之前的学习中,我们所有的程序遇到BUG就会出现①的这种情况,也就是整个程序直接奔溃,但是在真实工作中,我们肯定不能因为一个小的BUG就让整个程序全部奔溃,也就是我们希望的是达到②的这种情况,那这里我们就需要使用到捕获异常
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段。
捕获常规异常
基本语法:

快速入门
需求:尝试以’r’模式打开文件,如果文件不存在,则以’w’方式打开。

捕获指定异常
基本语法:

注意事项:
① 如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常。
② 一般try下方只放一行尝试执行的代码。
捕获多个异常
当捕获多个异常时,可以把要捕获的异常类型的名字,放到except后,并使用元组的方式进行书写。

执行结果:

捕获异常并输出描述信息
基本语法:

执行结果:

捕获所有异常
基本语法:

执行结果:

异常 else
else表示的是如果没有异常要执行的代码。

执行结果:

异常的finally
finally表示的是无论是否异常都要执行的代码,例如关闭文件。

总结:
1.为什么要捕获异常?
在可能发生异常的地方,进行捕获。当异常出现的时候,提供解决方式,而不是任由其导致程序无法运行。
2.捕获异常的语法?

3.如何捕获所有异常?
异常的种类多种多样,如果想要不管什么类型的异常都能捕获到,那么使用:
- except:
- except Exception:
- 两种方式捕获全部的异常
代码示例:
"""
演示捕获异常
"""
# 基本捕获语法
try:
f = open("D:/abc.txt", "r", encoding="UTF-8")
except:
print("出现异常了, 因为文件不存在,我将open的模式,改为w模式去打开")
f = open("D:/abc.txt", "w", encoding="UTF-8")
# 捕获指定的异常
try:
print(name)
except NameError as e:
print("出现了变量未定义的异常")
print(e)
# 捕获多个异常
try:
# 1/0
print(name)
except (NameError, ZeroDivisionError) as e:
print("出现了变量未定义 或者 除以0的异常错误")
# 未正确设置捕获异常类型,将无法捕获异常
# 捕获所有异常
try:
# 1 / 0
# print(name)
print("Hello world")
except Exception as e:
print("出现异常了")
else:
print("好高兴,没有异常。")
try:
f = open("D:/123.txt", "r", encoding="UTF-8")
except Exception as e:
print("出现异常了")
f = open("D:/123.txt", "w", encoding="UTF-8")
else:
print("好高兴,没有异常。")
finally:
print("我是finally,有没有异常我都要执行")
f.close()
异常的传递
异常是具有传递性的
当函数func01中发生异常,并且没有捕获处理这个异常的时候,异常会传递到func02,当func02也没有捕获处理这个异常的时候 main函数会捕获这个异常,这就是异常的传递性。

提示:
当所有函数都没有捕获异常的时候,程序就会报错
代码示例:
"""
演示异常的传递性
"""
# 定义一个出现异常的方法
def func1():
print("func1 开始执行")
num = 1 / 0 # 肯定有异常,除以0的异常
print("func1 结束执行")
# 定义一个无异常的方法,调用上面的方法
def func2():
print("func2 开始执行")
func1()
print("func2 结束执行")
# 定义一个方法,调用上面的方法
def main():
try:
func2()
except Exception as e:
print(f"出现异常了,异常的信息是:{e}")
main()

Python模块
什么是模块
Python 模块(Module),是一个Python文件,以.py结尾。模块能定义函数,类和变量,模块里也能包含可执行的代码。
模块的作用:Python中很多各种不同的模块,每一个模块都可以帮助我们快速的实现一些功能,比如实现和时间相关的功能就可以使用time模块。我们可以认为一个模块就是一个工具包,每一个工具包中都有各种不同的工具供我们使用进而实现各种不同的功能。
大白话:模块就是一个Python文件,里面有类、函数、变量等,我们可以拿过来用(导入模块去使用)。
模块的导入方式
模块在使用前需要先导入 导入的语法如下:
![]()
常用的组合形式如:
- import 模块名
- from 模块名 import 类、变量、方法等
- from 模块名 import *
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
import模块名
基本语法:

案例:导入time模块

from模块名import功能名
基本语法:

案例:导入time模块中的sleep方法

from模块名import*
基本语法:

案例:导入time模块中所有的方法

as定义别名
基本语法:

案例:


总结:
1.什么是模块?
模块就是一个Python代码文件,内含类、函数、变量等,我们可以导入进行使用。
2.如何导入模块
![]()
3.注意事项:
- from可以省略,直接import即可
- as别名可以省略
- 通过”.”来确定层级关系
- 模块的导入一般写在代码文件的开头位置
代码示例:
"""
演示Python的模块导入
"""
# 使用import导入time模块使用sleep功能(函数)
# import time # 导入Python内置的time模块(time.py这个代码文件)
# print("你好")
# time.sleep(5) # 通过 . 就可以使用模块内部的全部功能(类、函数、变量)
# print("我好")
# 使用from导入time的sleep功能(函数)
# from time import sleep
# print("你好")
# sleep(5)
# print("我好")
# 使用 * 导入time模块的全部功能
# from time import * # * 表示全部的意思
# print("你好")
# sleep(5)
# print("我好")
# 使用as给特定功能加上别名
# import time as t
# print("你好")
# t.sleep(5)
# print("我好")
from time import sleep as sl
print("你好")
sl(5)
print("我好")
制作自定义模块
Python中已经帮我们实现了很多的模块,不过有时候我们需要一些个性化的模块,这里就可以通过自定义模块实现,也就是自己制作一个模块。
案例:新建一个Python文件,命名为my_module1.py,并定义test函数


注意:
每个Python文件都可以作为一个模块,模块的名字就是文件的名字. 也就是说自定义模块名必须要符合标识符命名规则。
注意事项

注意事项:当导入多个模块的时候,且模块内有同名功能. 当调用这个同名功能的时候,调用到的是后面导入的模块的功能
测试模块
在实际开发中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,
这个开发人员会自行在py文件中添加一些测试信息,例如,在my_module1.py文件中添加测试代码test(1,1)

问题:
此时,无论是当前文件,还是其他已经导入了该模块的文件,在运行的时候都会自动执行test函数的调用
解决方案:

all
如果一个模块文件中有__all__变量,当使用from xxx import *导入时,只能导入这个列表中的元素

总结:
1.如何自定义模块并导入?
在Python代码文件中正常写代码即可,通过import、from关键字和导入Python内置模块一样导入即可使用。
2.__main__变量的功能是?
if main == “main”表示,只有当程序是直接执行的才会进入if内部,如果是被导入的,则if无法进入
3.注意事项
- 不同模块,同名的功能,如果都被导入,那么后导入的会覆盖先导入的
- __all__变量可以控制import *的时候哪些功能可以被导入
代码示例:
my_module1.py
__all__ = ['test_a']
def test(a, b):
print(a + b)
def test_a(a, b):
print(a + b)
def test_b(a, b):
print(a - b)
if __name__ == '__main__':
test(1, 2)
test_a(1, 2)
my_module2.py
def test(a, b):
print(a - b)
自定义模块.py
"""
演示自定义模块
"""
# 导入自定义模块使用
import my_module1
my_module1.test(1, 2)
# 导入不同模块的同名功能
from my_module1 import test
from my_module2 import test
test(1, 2)
# __main__变量
from my_module1 import test
# 变量
from my_module1 import *
test_a(1,2)
test_b(2, 1)
Python包
基于Python模块,我们可以在编写代码的时候,导入许多外部代码来丰富功能。
但是,如果Python的模块太多了,就可能造成一定的混乱,那么如何管理呢?
通过Python包的功能来管理。
什么是Python包
从物理上看,包就是一个文件夹,在该文件夹下包含了一个__init__.py文件,该文件夹可用于包含多个模块文件。
从逻辑上看,包的本质依然是模块
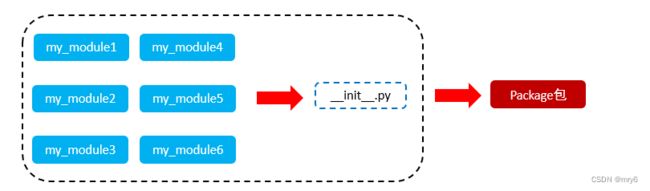
包的作用:
当我们的模块文件越来越多时,包可以帮助我们管理这些模块,包的作用就是包含多个模块,但包的本质依然是模块
快速入门
步骤如下:
① 新建包my_package
② 新建包内模块:my_module1 和 my_module2
③ 模块内代码如下
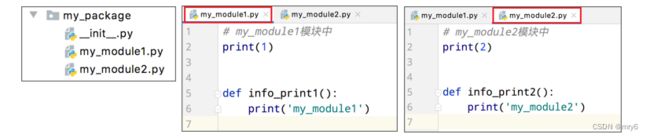
Pycharm中的基本步骤:
[New] ==》[Python Package] ==》输入包名 ==》[OK] ==》新建功能模块(有联系的模块)
注意:新建包后,包内部会自动创建__init__.py文件,这个文件控制着包的导入行为
导入包
方式一


方式二
注意:必须在__init__.py文件中添加__all__ = [],控制允许导入的模块列表



总结:
1.什么是Python的包?
包就是一个文件夹,里面可以存放许多Python的模块(代码文件),通过包,在逻辑上将一批模块归为一类,方便使用。
2.init.py文件的作用?
创建包会默认自动创建的文件,通过这个文件来表示一个文件夹是Python的包,而非普通的文件夹。
3.__all__变量的作用?
同模块中学习到的是一个作用,控制 import * 能够导入的内容
代码示例:
my_package:
1.init.py
__all__ = ['my_module1']
2.my_module1.py
"""
演示自定义模块1
"""
def info_print1():
print("我是模块1的功能函数代码")
3.my_module2.py
"""
演示自定义模块2
"""
def info_print2():
print("我是模块2的功能函数代码")
06_包.py
"""
演示Python的包
"""
# 创建一个包
# 导入自定义的包中的模块,并使用
# import my_package.my_module1
# import my_package.my_module2
#
# my_package.my_module1.info_print1()
# my_package.my_module2.info_print2()
# from my_package import my_module1
# from my_package import my_module2
# my_module1.info_print1()
# my_module2.info_print2()
# from my_package.my_module1 import info_print1
# from my_package.my_module2 import info_print2
# info_print1()
# info_print2()
# 通过__all__变量,控制import *
from my_package import *
my_module1.info_print1()
# my_module2.info_print2() 此处报错
安装第三方Python包
什么是第三方包
我们知道,包可以包含一堆的Python模块,而每个模块又内含许多的功能。所以,我们可以认为:一个包,就是一堆同类型功能的集合体。
在Python程序的生态中,有许多非常多的第三方包(非Python官方),可以极大的帮助我们提高开发效率,如:
- 科学计算中常用的:numpy包
- 数据分析中常用的:pandas包
- 大数据计算中常用的:pyspark、apache-flink包
- 图形可视化常用的:matplotlib、pyecharts
- 人工智能常用的:tensorflow
- 等
这些第三方的包,极大的丰富了Python的生态,提高了开发效率。
但是由于是第三方,所以Python没有内置,所以我们需要安装它们才可以导入使用哦。
安装第三方包 - pip
第三方包的安装非常简单,我们只需要使用Python内置的pip程序即可。
打开我们许久未见的:命令提示符程序,在里面输入:
pip install 包名称
即可通过网络快速安装第三方包

pip的网络优化
由于pip是连接的国外的网站进行包的下载,所以有的时候会速度很慢。
我们可以通过如下命令,让其连接国内的网站进行包的安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称

https://pypi.tuna.tsinghua.edu.cn/simple 是清华大学提供的一个网站,可供pip程序下载第三方包
安装第三方包 - PyCharm
PyCharm也提供了安装第三方包的功能:
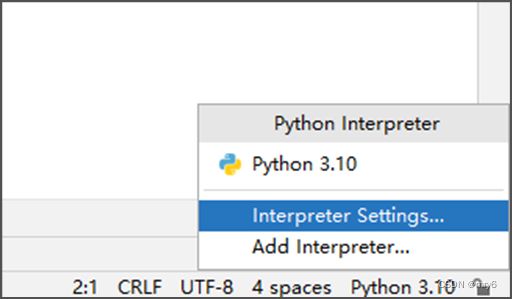


总结:
1.什么是第三方包?有什么作用?
第三方包就是非Python官方内置的包,可以安装它们扩展功能,提高开发效率。
2.如何安装?
- 在命令提示符内:
- pip install 包名称
- pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
- 在PyCharm中安装
综合案例
自定义工具包
创建一个自定义包,名称为:my_utils (我的工具)
在包内提供2个模块
- str_util.py (字符串相关工具,内含:)
- 函数:str_reverse(s),接受传入字符串,将字符串反转返回
- 函数:substr(s, x, y),按照下标x和y,对字符串进行切片
- file_util.py(文件处理相关工具,内含:)
- 函数:print_file_info(file_name),接收传入文件的路径,打印文件的全部内容,如文件不存在则捕获异常,输出提示信息,通过finally关闭文件对象
- 函数:append_to_file(file_name, data),接收文件路径以及传入数据,将数据追加写入到文件中
构建出包后,尝试着用一用自己编写的工具包。
代码示例:
file_util.py
"""
文件处理相关的工具模块
"""
def print_file_info(file_name):
"""
功能是:将给定路径的文件内容输出到控制台中
:param file_name: 即将读取的文件路径
:return:
"""
f = None
try:
f = open(file_name, "r", encoding="UTF-8")
content = f.read()
print("文件的全部内容如下:")
print(content)
except Exception as e:
print(f"程序出现异常了,原因是:{e}")
finally:
if f: # 如果变量是None,表示False,如果有任何内容,就是True
f.close()
def append_to_file(file_name, data):
"""
功能:将指定的数据追加到指定的文件中
:param file_name: 指定的文件的路径
:param data: 指定的数量
:return: None
"""
f = open(file_name, "a", encoding="UTF-8")
f.write(data)
f.write("\n")
f.close()
if __name__ == '__main__':
# print_file_info("D:/abc.txt")
append_to_file("D:/123.txt", "murirm")
str_util.py
"""
字符串相关的工具mok
"""
def str_reverse(s):
"""
功能是将字符串完成反转
:param s: 将被反转的字符串
:return: 反转后的字符串
"""
return s[::-1]
def substr(s, x, y):
"""
功能是安装给定的下标完成给定字符串的切片
:param s: 即将被切片的字符串
:param x: 切片的开始下标
:param y: 切片的结束下标
:return: 切片完成后的字符串
"""
return s[x:y]
if __name__ == '__main__':
str = str_reverse("好好学习")
print(str)
print(substr("好好学习",1,2))
综合案例练习.py
"""
演示异常、模块、包的综合案例练习
"""
# 创建my_utils包,在包内创建:str_util.py 和 file_util.py 2个模块,并提供相应的函数
import my_utils.str_util
from my_utils import file_util
print(my_utils.str_util.str_reverse("123456789"))
print(my_utils.str_util.substr("123456789", 1, 4))
file_util.append_to_file("D:/123.txt", "123456")
file_util.print_file_info("D:/123.txt")