图像融合论文:CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
图像融合论文阅读:CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
@inproceedings{zhao2023cddfuse,
title={Cddfuse: Correlation-driven dual-branch feature decomposition for multi-modality image fusion},
author={Zhao, Zixiang and Bai, Haowen and Zhang, Jiangshe and Zhang, Yulun and Xu, Shuang and Lin, Zudi and Timofte, Radu and Van Gool, Luc},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={5906–5916},
year={2023}
}
原文地址
github
文章目录
- 图像融合论文阅读:CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
- 摘要
- 1. Introduction
-
- 1.1 背景
- 1.2 发展
- 1.3 方法1:增减高低频率相关性促进特有/共有特征提取
- 1.4 方法2:整合CNN和Transformer
- 1.5 方法3:提出了INN
- 1.6 贡献
- 2. Related Work
-
- 2.1 基于深度学习的多模态图像融合
- 2.2 ViT及变体
- 2.3 INN
- 2.4 与现有方法比较
- 3. 方法
-
- 3.1 概述
- 3.2 编码器
- 3.3 融合层
- 3.4 解码器
- 3.5 两阶段训练
- 4.红外与可见光融合
-
- 4.1 Setup
- 4.2 baseline
- 4.3 Ablation studies
- 4.4 下游VIF应用
-
- 4.4.1 目标检测
- 4.4.2 语义分割
- 5. 医学图像融合
- 6. 结论
- 传送门
-
- 图像融合相关论文阅读笔记
- 图像融合论文baseline总结
- 其他论文
- 其他总结
- ✨精品文章总结
摘要
- 简介:多模态图像融合旨在生成可以保持不同模态优点的融合图像。
- 挑战:为了解决跨模态特征建模和分解所需的模态特定和模态共享特征的挑战,我们提出了一种新颖的相关驱动特征分解融合网络(Correlation-Driven feature Decomposition Fusion (CDDFuse) network)。
- 方法:
- 首先使用Restormer提取跨模态浅层特征。
- 然后引入了双分支Transformer-CNN特征提取器,Lite Transformer(LT)块利用远程注意力处理低频全局特征,Invertible Neural Networks(INN)可逆神经网络块关注高频局部信息。
- 进一步,提出了相关驱动损失(correlation-driven loss),基于嵌入信息(embedded information)使低频特征相关,而高频特征不相关。
- 然后,基于LT的全局融合层和基于INN的局部融合层输出融合图像。
- 贡献:
- 大量实验表明,CDDFuse在红外与可见光及医学图像融合性能卓越。
- 此外,证明了CDDFuse在统一的benchmark中,在红外可见光语义分割及目标检测下游任务的性能也提升了。
- 代码开源。
1. Introduction
1.1 背景
①图像融合定义:通过组合源图像融合生成信息丰富的融合图像。
②图像融合分类:数字、多模态(红外-可见光、医学)、遥感等。
③多模态图像融合定义:对多传感器跨模态特征进行建模从而生成融合图像。
④VIF的目标:保留红外图像的热辐射信息和可见光图像的纹理细节信息。从而避免可见光对光线条件敏感及红外图像噪声大、分辨率低的问题。
⑤多模态融合应用:提升下游任务(识别、多模态显著检测、目标检测、语义分割、协助医学诊断等)性能。
1.2 发展
①发展现状:MMIF中主要的方法为CNN、AE

②现有方法缺点1:因为CNN内部机制难以控制和解释,所以跨模态特征提取不足。如图1a中的I和II,共享编码器无法区分特定模态特征,III中私有编码器忽略了共享特征。
③现有方法缺点2:上下文无关且感受野太小,导致只提取了局部信息忽略了全局信息。
④现有方法缺点3:前向传播会导致高频信息损失。
⑤提出方法:探索一种更合理的范式来应对特征提取和融合的挑战。
1.3 方法1:增减高低频率相关性促进特有/共有特征提取
①对提取出的特征添加相关性限制并限制解空间,提升特征提取的可控性和可解释性。
②跨模态输入在低频处相关,代表模态共享信息;高频处不相关,代表模态特有信息。
③举例:VIF中,红外-可见光图像来自同一场景,低频信息包含统计共现(背景及大尺度环境特征);相反,高频信息互相独立,【可见光的纹理和细节信息】以及【红外图像的热辐射信息】。
④因此,分别通过增减低频高频特征相关性,促进模态特定及共享特征的提取。
1.4 方法2:整合CNN和Transformer
①ViT介绍:ViT具有自注意力机制和全局特征提取,但是计算成本高。
②方法:整合了【CNN的局部上下文特征提取和计算效率】以及【ViT的全局注意力和远程依赖建模】的优势,来完成MMIF任务。
1.5 方法3:提出了INN
①挑战:为了解决丢失需要的高频信息挑战,采用了可逆神经网络(Invertible Neural Network, INN。
②方法:因为INN的设计具有可逆性,所以可以【防止输入及输出特征的相互生成从而丢失信息】,并且符合保留融合图像中高频特征的目标。
1.6 贡献
①因此,提出了CDDFusion,使用双分支编码器实现模态特定特征和共享特征提取,使用解码器重构融合图像。贡献分别如图1a和图2所示。


②分:
- 提出了一种双分支的Transformer-CNN框架提取融合全局特征和局部特征,以此更好的反应不同模态的特定和共享特征。
- 改进了CNN和Transformer模块。使用INN块用来无损伤信息传输,使用LT块权衡融合质量及计算成本。
- 提出了相关性驱动的损失函数来限制私有特征和共享特征分解,以此使跨模态共享特征相关,高频特征去相关。
- 所提方法在VIF和MIF性能卓越。同时提出了一种统一的评测基准证明了VIF融合图像如何促进下游多模态目标检测和语义分割任务。

2. Related Work
此节简短的回顾了基于DL的MMIF,以及CDDFusion中使用的LT,Restormer,INN模块。
2.1 基于深度学习的多模态图像融合
①基于CNN的MMIF分类:GAN,AE,统一模型(unified models)和算法展开模型(algorithm unrolling models)。
②GAN:GAN被用来同时使融合图像分布与输入图像相似,并在感知上令人满意。
③AE:使用编码器和解码器。
④统一模型:通过跨任务学习,可以解决训练数据有限和缺少ground truth的问题。
⑤算法展开模型:在传统优化和DL方法建立了连接,建立了模型驱动的可解释CNN。
⑥其他近期研究:
- 图像融合+检测;利用分割和检测的损失指导融合图像的生成。
- 自监督学习结构处理未配准图像融合任务;在融合模块前加预处理的配准模块可以解决配准错误。
- 用于综合场景感知的基于多视角多模态融合的拼接方法。
2.2 ViT及变体
①发展过程:用于自然语言处理(Natural Language Processing, NLP)的Transformer提出后,计算机视觉领域的Transformer也被提出,即ViT。许多基于Transformer的变体被应用于分类、目标检测、分割和多模态学习等任务并取得了令人满意的结果。
②对低级视觉任务,融合了多任务学习和Swin Transformer块的Transformer比基于CNN的方法效果更好。
③其他近期研究:
- 为解决空间自注意力计算开销大,用于移动NLP任务的轻量级LT结构被提出。通过长短期注意力和扁平化前馈完网络,保持性能的同时降低了网络参数量。
- 为促进多尺度全局局部表达学习,Restormer改进了Transformer块(通过门控Dconv网络和多Dconv头部注意力转置模块)。下图分别为Gated-Dconv feed-forward network (GDFN)和multi-Dconv head transposed attention (MDTA)


2.3 INN
①介绍:INN是标准化流模型(一种生成模型)的一个重要模块。
③应用:因为可以提升backbone的特征提取能力并且节省内存,因此在分类、图像着色、图像隐藏、图像重缩放、图像视频超分等图像处理任务中被有效使用。
2.4 与现有方法比较
①相同:相似于基于AE的方法。
②不同:
- 提取不同结构的局部和全局特征比纯CNN更合理且直观。
- 基于相关性驱动的分解损失可以有效抑制冗余信息,在特征提取能力方面优于传统损失函数。
3. 方法
此节介绍了CDDFusion的流程和各模块的详细结构。(为了便于表达,低频全局特征=基础(base)特征,高频局部特征=细节(detail)特征)。
3.1 概述
①总结构:CDDFuse包含四个模块: 总结构如图2所示。
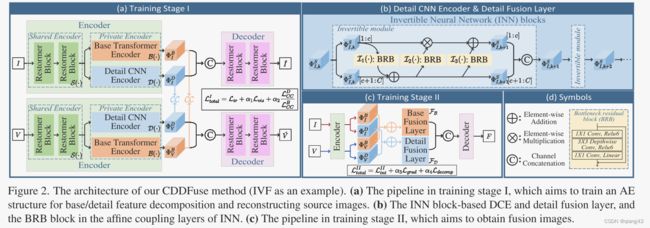
- 双分支编码器,用于特征提取和分解。
- 解码器,用于重构图像(训练1阶段)或者生成融合图像(训练2阶段)。
- 基础/细节融合层,用于分别融合不同频率特征。(这算两个模块)。
②CDDFuse是通用的多模态图像融合网络。
3.2 编码器
①组成:编码器有3个组件:
- 基于Restormer块的共享特征编码器(share feature encoder ,SFE)
- 基于LT块的基本Transformer编码器(base transformer encoder ,BTE)
- 基于INN块的细节CNN编码器(detail CNN encoder ,DCE)
符号定义

②SFE:提取浅层特征

原因:通过在特征维度上应用自注意力可以从高分辨率图像中提取全局信息。因此它可以提取跨模态的浅层特征而不增加太多计算量。
③BTE:从共享特征中提取低频信息(基本特征)

为了提取远距离依赖特征,使用具有空间自注意力的Transformer。
为了平衡性能和计算成本,使用LT块作为BTE的基本单元。
④DCE:从共享特征中提取高频信息(细节特征)

DCE中的CNN架构可以保留更多的细节信息(图像纹理边缘和细节特征)。
INN可以看作是一个无损的特征提取块。每个可逆层的变化为:
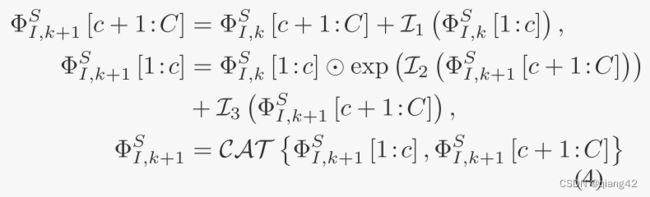
( ⊙ ) (\odot) (⊙)符号代表哈达玛积。哈达玛积(Hadamard product)是矩阵的一类运算,若A=(aij)和B=(bij)是两个同阶矩阵,若cij=aij×bij,则称矩阵C=(cij)为A和B的哈达玛积,或称基本积。即矩阵对应相乘,如下图所示。
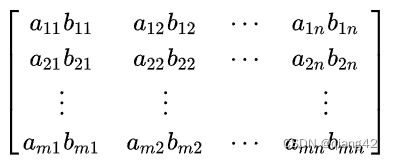
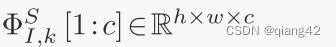
代表第k个可逆层的输入特征的从1到c的通道。
C A T ( ) {CAT()} CAT()代表通道级联。 I i I_i Ii代表任意映射函数。如图2d所示。
在每个可逆层中, I i I_i Ii可以被设置为任何映射,而不影响该可逆层中的无损信息传输。考虑到计算消耗和特征提取能力之间的权衡,采用MobileNetV2中的瓶颈残差块(BRB)块作为 I i I_i Ii。最后,其余符号可以以相同的方式获得,通过替换等式中的下标。
3.3 融合层
基础/细节融合层的功能是分别融合基础/细节特征。
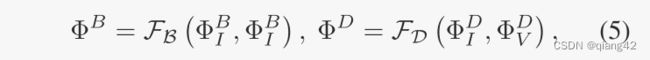
F B F_B FB和 F D F_D FD分别为基础和细节融合层。
3.4 解码器
在解码器DC(·)中,分解的特征在信道维度上被级联作为输入,并且原始图像(训练阶段I)或融合图像(训练阶段II)是解码器的输出,其公式为:

由于这里的输入涉及交叉模态和多频特征,因此保持解码器结构与SFE的设计一致,即使用Restormer块作为解码器的基本单元。
3.5 两阶段训练
①MMIF中的一个挑战是没有ground truth,有监督学习无效,所以提出了2阶段训练
②训练阶段1:
- {I, V}图像对输入SFE提取浅层特征 { Φ I S , Φ V S } \{\Phi_I^S, \Phi_V^S\} {ΦIS,ΦVS}
- 基于LT的BTE和基于INN的DCE分别提取低频 { Φ I B , Φ V B } \{\Phi_I^B, \Phi_V^B\} {ΦIB,ΦVB}和高频 { Φ I D , Φ V D } \{\Phi_I^D, \Phi_V^D\} {ΦID,ΦVD}
- 红外(可见光)图像的基本和细节特征 { Φ I B , Φ I D } \{\Phi_I^B, \Phi_I^D\} {ΦIB,ΦID}( { Φ V B , Φ V D } \{\Phi_V^B, \Phi_V^D\} {ΦVB,ΦVD})级联后输入解码器,用来重建原始的红外(或可见光)图像 I ^ \hat I I^(或 V ^ \hat V V^)
③训练阶段2:
- {I, V}图像对被输入到一个训练好的编码器中以获取特征
- 分解基本特征 { Φ I B , Φ V B } \{\Phi_I^B, \Phi_V^B\} {ΦIB,ΦVB}和细节特征 { Φ I D , Φ V D } \{\Phi_I^D, \Phi_V^D\} {ΦID,ΦVD}分别被输入到融合层 F B \mathcal{F_B} FB和 F D \mathcal{F_D} FD
- 融合特征 { Φ B , Φ D } \{\Phi^B, \Phi^D\} {ΦB,ΦD}被输入到解码器中获得融合图像F
④训练损失
训练阶段1的损失函数为:

L i r \mathcal L_{ir} Lir和 L i r \mathcal L_{ir} Lir分别代表红外和可见光图像的重构损失。 L d e c o m p \mathcal L_{decomp} Ldecomp代表特征分解损失。 α 1 \alpha_1 α1和 α 2 \alpha_2 α2为可调参数。
重建损失是为了确保图像信息在编码和解码时不丢失。

其中 L i n t I = ∥ I − I ^ ∥ 2 2 \mathcal {L_{{\mathop{\rm int}} }^I} = \left\| {I - \hat I} \right\|_2^2 LintI= I−I^ 22 L S S I M ( I − I ^ ) = 1 − S S I M ( I − I ^ ) {L_{SSIM}}\left( {I - \hat I} \right) = 1 - SSIM\left( {I - \hat I} \right) LSSIM(I−I^)=1−SSIM(I−I^)
SSIM是结构相似性指数。 L i r \mathcal L_{ir} Lir可以用相同的方法获得。
特征分解损失 L d e c o m p \mathcal L_{decomp} Ldecomp可以表示为:

其中CC表示相关系数算子。 ϵ \epsilon ϵ为1.01用来确保分母为正。
设计理由:
{ Φ I B , Φ V B } \{\Phi_I^B, \Phi_V^B\} {ΦIB,ΦVB}包含更多的模态共享信息,如背景和大尺度环境。
{ Φ I D , Φ V D } \{\Phi_I^D, \Phi_V^D\} {ΦID,ΦVD}包含更多的模态私有信息,如在V(可见光)中纹理和细节信息,在I(红外)中表示热辐射和清晰边缘信息。因此特征图相关性很低。
经验表明,梯度下降时在 L d e c o m p \mathcal L_{decomp} Ldecomp的指导下, L C C D \mathcal L_{CC}^D LCCD逐渐接近0,而 L C C B \mathcal L_{CC}^B LCCB越来越大。分解的可视化如图5所示。

图5显示了分解的特征。显然,基本特征组中更多的背景信息被激活,并且被激活的区域也是相关的。在细节特征组中,红外特征更多地关注对象高光,而可见光特征更多地关注细节和纹理,这表明模态特定特征被很好地提取。
训练阶段2的损失为:

4.红外与可见光融合
此节详解阐述了网络实施和配置的细节。通过实验验证了模型的有效性和网络结构的合理性。
4.1 Setup
①数据集
- 训练集:在MARS(1083 pairs)
- 验证集:RoadScene(50 pairs)
- 测试集:MARS测试集(361 pairs)、RoadScene测试集(50 pairs)和TNO测试集(25 pairs)
②评价指标
- entropy (EN)
- standard deviation (SD)
- spatial frequency (SF)
- mutual information (MI)
- sum of the correlations of differences (SCD)
- visual information fidelity (VIF)
- QAB/F
- structural similarity index measure (SSIM).
越高越好(Higher metrics indicate that a fusion image is better)
③实施细节
- 训练样本被裁剪为128*128的块
- Adam优化器
- epoch 120,训练1阶段40个,训练2阶段80个
- batch size 16
- lr 1e-4,每20epoch下降为0.5
- α1至α4 分别为 to 1, 2, 10, 2
- SFE中Restormer块数量为4,8个注意力头和64维度
- BTE中LT尺寸64,8个注意力头
- 解码器和编码器配置相同
4.2 baseline
①对比方法:DIDFuse, U2Fusion , SDNet, RFNet, TarDAL, DeFusion and ReCoNet.
②qualitative comparison
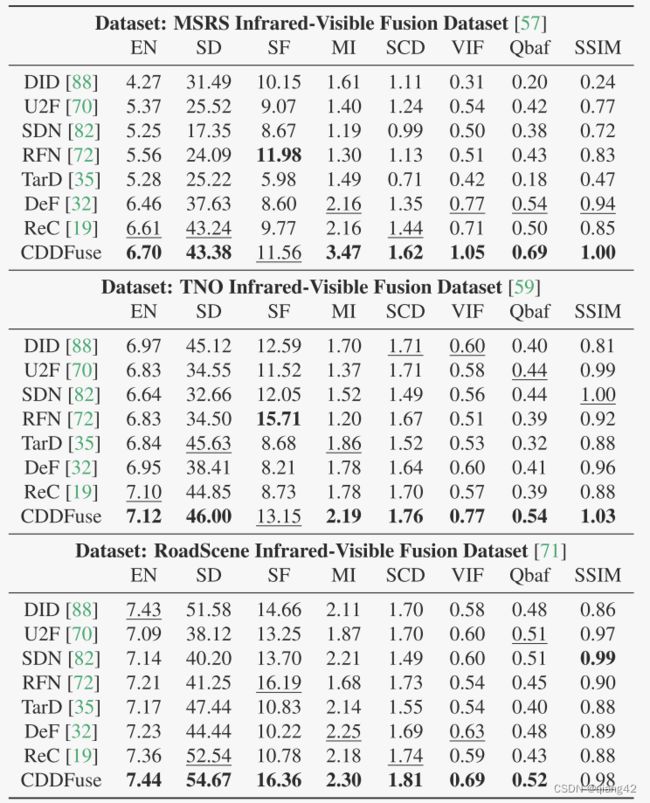
图3和4展示了定性比较。本文方法更好的融合了红外图像的热辐射信息和可见光图像的细节纹理。黑暗中的物体被清晰的高亮出来,因此前景目标可以很容易的从背景中区分出来。
因为低光照导致难以识别的背景细节,具有清晰的边缘和充足的轮廓信息。
③quantitative comparison
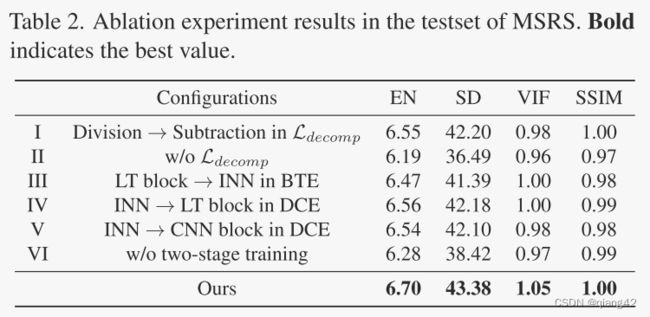
4.3 Ablation studies
4.4 下游VIF应用
4.4.1 目标检测

4.4.2 语义分割

5. 医学图像融合


6. 结论
①主题:提出了一种用于多模态图像融合的双分支TransformerCNN架构。
②贡献:借助Restormer、Lite Transformer和可逆神经网络模块,更好地提取了模态特定特征和模态共享特征,并通过提出的相关性驱动分解损失对模态特定特征和模态共享特征进行了更直观有效的分解。
③实验:实验证明了CDDFuse的融合效果,并提高了下游多模态模式识别任务的准确率。
传送门
图像融合相关论文阅读笔记
[FusionGAN: A generative adversarial network for infrared and visible image fusion]
[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
[Visible and Infrared Image Fusion Using Deep Learning]
[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
[U2Fusion: A Unified Unsupervised Image Fusion Network]
图像融合论文baseline总结
[图像融合论文baseline及其网络模型]
其他论文
[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
其他总结
[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]
如有疑问可联系:[email protected];
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~