Linux Centos7 安装NVIDIA 驱动
cat /etc/redhat-release 查看系统版本
| 服务器IP |
系统版本 |
内核 |
GPU |
内存和硬盘 |
后期扩容 |
| 10.0.2.125 |
CentOS Linux release 7.9.2009 |
5.3.10-1.el7.elrepo.x86_64 |
4 张 Tesla T4(16G) |
376G + 1.5T |
物理机 |
| 10.0.2.130 |
CentOS Linux release 7.9.2009 |
3.10.0-1160.el7.x86_64 |
2 张 Tesla T4(16G) |
251G + 3T |
物理机 |
| 10.0.2.131 |
CentOS Linux release 7.9.2009 |
3.10.0-1160.el7.x86_64 |
1 张 Tesla T4(16G) |
251G + 3T |
物理机 |
部分文档说:注意: 安装nvidia-docker2前要先安装 驱动及CUDA、CUDNN安装
部分文档说:提示: 宿主机没必要安装cuda和cudnn的包,build的时候不能使用`--runtime=nvidia`,要构建镜像的时候使用`nvidia`
在131测试(一块显卡)
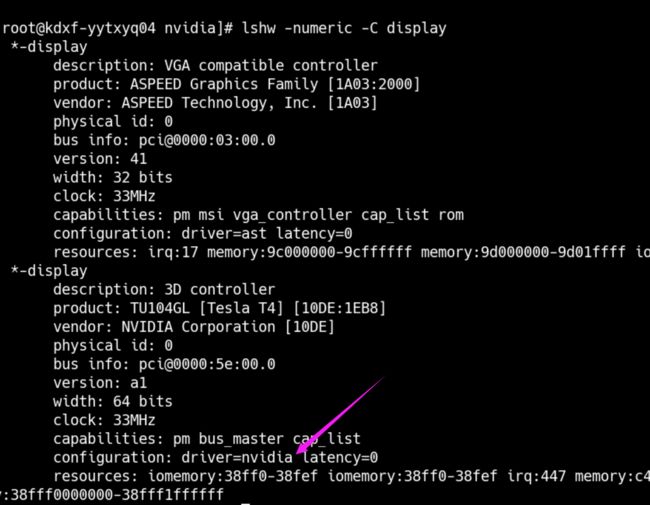
lshw -numeric -C display 检查硬件
lspci | grep -i nvidia
5e:00.0 3D controller: NVIDIA Corporation TU104GL [Tesla T4] (rev a1)
说明此刻用的是开源版本的nouveau显卡驱动,在后文,如果安装完毕nvidia的驱动后,这行会变为configuration: driver=nvidia:
安装步骤
更新kernel
其中dkms是可选的,但是有了它,可以确保以后内核更新后,内核更新事件会触发Nvidia的内核驱动跟着自动编译安装更新。实际上,你在安装驱动的过程中,会有专门的提示框弹出来让你选择。
yum install -y --downloadonly --downloaddir=/root/ epel-release
yum install -y --downloadonly --downloaddir=/root/ kernel-headers kernel-devel dkms
rpm -ivh kernel-devel-3.10.0-1160.el7.x86_64.rpm
yum -y install gcc kernel-devel
安装 gcc、kernel
gcc -v
禁用 nouveau
检查模块是否仍旧在加载(安装nvidia显卡驱动前需要禁用nouveau,不然会碰到冲突的问题,导致无法安装nvidia显卡驱动)
查看命令:
lsmod | grep nouveau
修改dist-blacklist.conf文件:
vim /lib/modprobe.d/dist-blacklist.conf
将nvidiafb注释掉:
#blacklist nvidiafb
然后添加以下语句:
blacklist nouveau
options nouveau modeset=0重建initramfs image
#备份一份成bak文件
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
#重启镜像
dracut /boot/initramfs-$(uname -r).img $(uname -r)
#修改运行级别为文本模式
systemctl set-default multi-user.target
reboot
lsmod | grep nouveau安装NVIDIA驱动
# 驱动下载地址官方驱动 | NVIDIA
# 请选择自己需要的版本号 # 需要加上权限
chmod +x NVIDIA-Linux-x86_64-410.129-diagnostic.run
# 不使用命令,直接复制上面地址也可以在浏览器直接下载
./NVIDIA-Linux-x86_64-410.129-diagnostic.run --kernel-source-path=/usr/src/kernels/3.10.0-1160.el7.x86_64 -k $(uname -r)





lshw -numeric -C display
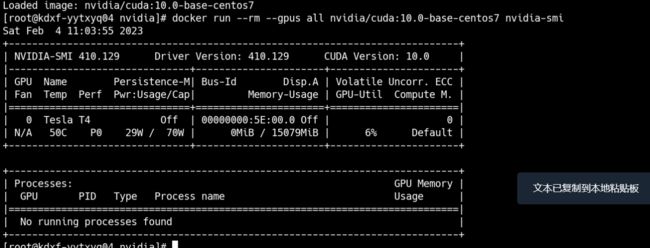
nvidia-smi

安装nvidia-docker2
准备文件,需要和系统版本对应
在已安装docker的机器上
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
url -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
yum install --downloadonly nvidia-docker2 --downloaddir=/tmp/nvidia
得到这些

rpm -Uvh *.rpm --nodeps --force
安装nvidia docker2以后,修改docker 默认runtime。重启docker,这样就能在docker或者k8s中使用gpu了。
cat /etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}# 热启动docker
systemctl daemon-reload && sudo kill -SIGHUP $(pidof dockerd)
不行再systemctl restart dockerdocker run --rm --gpus all nvidia/cuda:10.0-base-centos7 nvidia-smi
docker run --rm --gpus all nvidia/cuda:11.4.3-base-centos7 nvidia-smi
卸载更换
yum install -y nvidia-docker2 --downloadonly --downloaddir=/root/nvidia-new
yum install -y nvidia-container-toolkit --downloadonly --downloaddir=/root/nvidia-new
rpm -Uvh *.rpm --nodeps --force
sudo /usr/bin/nvidia-uninstall
chmod a+x NVIDIA-Linux-x86_64-440.33.01.run #(对应老驱动版本)
./NVIDIA-Linux-x86_64-440.33.01.run --uninstall
卸载nvidia-docker
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
reboot
安装
./NVIDIA-Linux-x86_64-440.118.02.run --kernel-source-path=/usr/src/kernels/3.10.0-1160.el7.x86_64 -k $(uname -r)
./NVIDIA-Linux-x86_64-535.104.12----12.2.run --kernel-source-path=/usr/src/kernels/3.10.0-1160.102.1.el7.x86_64 -k $(uname -r)
docker run --rm --gpus all nvidia/cuda:10.0-base-centos7 nvidia-smi 测试
docker run --rm --gpus all nvidia/cuda:11.4.3-base-centos7 nvidia-smi
报错 Error opening terminal: xterm.
1.rpm -qa | grep ncurses
2.sudo yum install ncurses.x86_64 ncurses-devel.x86_64
3.export TERMINFO=/usr/share/terminfo