正则表达式
小序
下午的时光是幸福的,每一步都走的很浪漫
目录
- 小序
- 正文
-
- 元字符使用
-
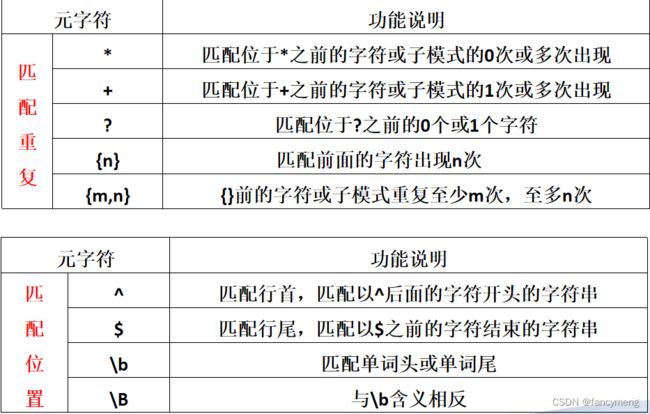
- 元字符 功能
- 贪婪和非贪婪模式
- 正则表达式 re 模块
- 小试牛刀
- 结束语
正文
正则表达式是字符串处理的有力工具,通过普通字符和有特定含义的字符,来组成字符串,用以描述一定的字符串规则,可以快速、准确地完成复杂的查找、替换等处理要求。
正则表达式被广泛用于文本处理,网络爬虫等多种场合中
应熟练掌握元字符的使用与re模块的使用方法
元字符使用
元字符 功能
. 匹配除换行符以外的任意单个字符
[ ] 表示范围,匹配位于[]中的任意一个字符
[-] 在[]之内用来表示范围, 例如[0-9],[a-z],[A-Z]
[ ^字符集 ] 匹配除了字符集以外的任意一个字符
\d 匹配任何数字,相当于[0-9]
\D 与\d含义相反,等效于[ ^0-9 ]
\w 匹配任何字母、数字以及下划线,相当于[a-z A-Z 0-9 _]
\W 与\w含义相反,与“[ ^A-Z a-z 0-9 _ ]”等效
\s 匹配任何空白字符,包括空格、制表符、换页符
\S 与\s含义相反(大部分连续字符都能匹配)
re.findall(‘你.好’,“你很好,你不好,你倒好”)
Out:[‘你很好’, ‘你不好’, ‘你倒好’]
re.findall(‘[aeiou]’,“How are you!”)
Out:[‘o’, ‘a’, ‘e’, ‘o’, ‘u’]
re.findall('[0-5 a-z]',"abc157def")
Out:[‘a’, ‘b’, ‘c’, ‘1’, ‘5’, ‘d’, ‘e’, ‘f’]
re.findall(‘[^0-9]’,“Use 007 port”)
Out: [‘U’, ‘s’, ‘e’, ’ ', ’ ', ‘p’, ‘o’, ‘r’, ‘t’
re.findall(‘\d{1,5}’,“Mysql: 3306, http:80”)
Out: [‘3306’, ‘80’]
re.findall(‘\w’,“server_port = 8888”)
Out:[‘s’, ‘e’, ‘r’, ‘v’, ‘e’, ‘r’, ‘_’, ‘p’, ‘o’, ‘r’, ‘t’, ‘8’, ‘8’, ‘8’, ‘8’]
re.findall(‘\s’,“hello world”)
Out: [‘ ']

re.findall('wo*',"wooooo~~w!")
Out: [‘wooooo’, ‘w’]
re.findall('[A-Z][a-z]+',"Hello World")
Out: [‘Hello’, ‘World’]
re.findall('-?[0-9]+',"Jame,age:18, -26")
Out: [‘18’, ‘-26’]
re.findall(‘1[0-9]{10}’,“Jame:13886495728”)
Out: [‘13886495728’]
re.findall(‘[1-9][0-9]{5,10}’,“Baron:1259296994”)
Out: [‘1259296994’]
re.findall('^Jame',"Jame,hello")
Out: [‘Jame’]
re.findall('Jame$',"Hi,Jame")
Out: [‘Jame’]
re.findall(r'\bis\b',"This is a test.")
Out: [‘is’]
re.findall(r’\Bis\b’,“This is a test.”)
Out: [‘is’] This
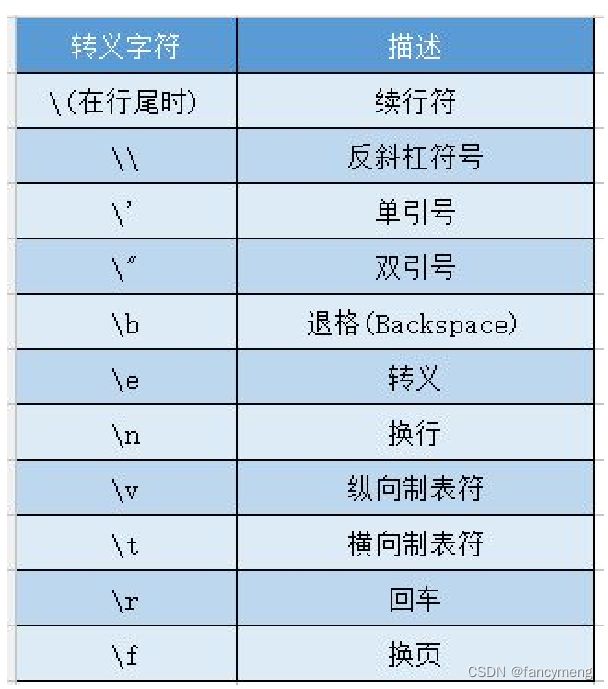
如果使用正则表达式匹配特殊字符则需要加 \ 表示转义
. + ^ $ [ ] ( ) { } | \
re.findall('-?\d+\.?\d*',"123,-123,1.23,-1.23")
Out: [‘123’, ‘-123’, ‘1.23’, ‘-1.23’]
如果以“\”开头的元字符与转义字符相同,则需要使用“\”在元字符前,或者使用原始字符串。
在字符串前加上字符r或R之后表示原始字符串
贪婪和非贪婪模式
贪婪模式: 默认情况下,匹配重复的元字符总是尽可能多的向后匹配内容
非贪婪模式: 让匹配重复的元字符尽可能少的向后匹配内容
贪婪模式转换为非贪婪模式:在匹配重复元字符(*、+、?、{n}、 {n,m})后加 ‘?’ 号即可
re.findall(r'\(.+?\)',"(abcd)efgh(higk)")
Out: [‘(abcd)’, ‘(higk)’]
re.findall(r'\(.+\)',"(abcd)efgh(higk)")
Out:[‘(abcd)efgh(higk)’]
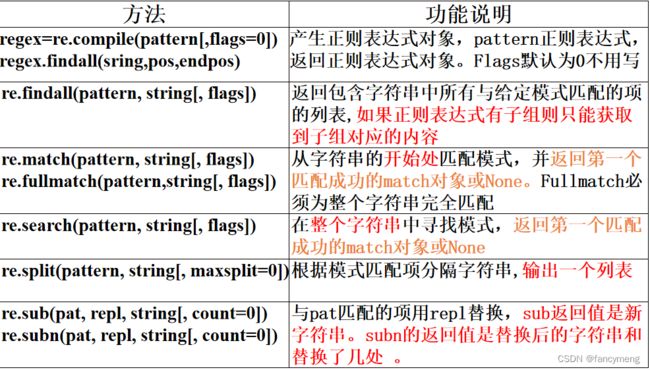
正则表达式 re 模块
import re
s = "Levi:1994,Sunny:1993"
pattern = r"(\w+):(\d+)"
l = re.findall(pattern, s)
print(l)
# OUT: [('Levi', '1994'), ('Sunny', '1993')]
regex = re.compile(pattern)
l = regex.findall(s)
print(l)
# OUT: [('Levi', '1994'), ('Sunny', '1993')]
regex = re.compile(pattern)
l = regex.findall(s,0,12)
print(l)
# OUT: [('Levi', '1994')]
match对象的主要方法有:
group():返回匹配的一个或多个子模式内容
groups():返回一个包含匹配的所有子模式内容的元组
groupdict():返回包含匹配的所有命名子模式内容的字典
start():返回指定子模式内容的起始位置
end():返回指定子模式内容的结束位置的前一个位置
span():返回一个包含指定子模式内容起始位置和结束位置前一个位置的元组
import re
example = 'Beautiful is better than ugly.'
re.findall('\\bb.+?\\b', example) #以字母b开头的完整单词
# 此处问号?表示非贪心模式
# OUT: ['better']
re.findall('\\bb.+\\b', example) #贪心模式的匹配结果
# OUT: ['better than ugly']
re.findall('\\Bh.+?\\b', example) #不以h开头且含有h字母的单词剩余部分
# OUT: ['han']
print(re.match('done|quit', 'done!')) #匹配成功,返回match对象
# OUT: , 'ddone'))
#匹配不成功
# OUT: None
m = re.match(r'[A-Z]\w*',"Hello World")
print(m.group())
# OUT: Hello
下一个例子:
import re
m = re.fullmatch(r'\d+',"hello-1973")
print(m.group())
OUT: AttributeError: ‘NoneType’ object has no attribute ‘group’
# 完全匹配
m = re.fullmatch(r'[0-9a-z-A-Z]+',"hello-1973")
print(m.group())
# OUT: hello-1973
print(re.search('done|quit', 'done!')) #匹配成功
# OUT: , 'd!one!done')) #匹配成功
# OUT:
# 按空格切
re.split(r' ',line)
# OUT: ['abc', 'aa;bb,cc', '|', 'dd(xx).xxx', '12.12\txxxx']
# 加将空格放可选框内[]内
re.split(r'[ ]',line)
# OUT: ['abc', 'aa;bb,cc', '|', 'dd(xx).xxx', '12.12\txxxx']
# 多字符匹配
re.split(r'[;,]',line)
# OUT: ['abc aa', 'bb', 'cc | dd(xx).xxx 12.12\txxxx']
# 使用括号捕获分组,默认保留分割符
re.split(‘([;])',line)
# OUT: ['abc aa', ';', 'bb,cc | dd(xx).xxx 12.12\txxxx']
pat = '{name}'
text = 'Dear {name}...'
re.sub(pat, 'Mr.Dong', text) #字符串替换
# OUT: 'Dear Mr.Dong...’
s = 'a s d'
re.sub('a|s|d', 'good', s) #字符串替换
# OUT: 'good good good’
s = "时间: 2019/10/12"
ns = re.subn(r'\d+','00',s)
print(ns)
# OUT: ('时间: 00/00/00', 3)
正则表达式对象的 match 方法和 search 方法匹配成功后返回match对象。
match对象的属性变量有:
pos 匹配的目标字符串开始位置
endpos 匹配的目标字符串结束位置
re 正则表达式
string 目标字符串
lastgroup 最后一组的名称
lastindex 最后一组的序号
import re
pattern = r"(ab)cd(?Pef)" #(?Pef)用pig代表ef
regex = re.compile(pattern)
obj = regex.search("abcdefghi",pos=0,endpos=7)
print(obj.pos) # 目标字符串开头位置
print(obj.endpos) # 目标字符串结束位置
print(obj.re) # 正则
print(obj.string) # 目标字符串
print(obj.lastgroup) # 最后一组名称
print(obj.lastindex) # 最后一组序号ef
# 输出如下顺序
0
7
re.compile('(ab)cd(?Pef)' )
abcdefghi
pig
2
match对象的属性方法有:
span() 获取匹配内容的起止位置
start() 获取匹配内容的开始位置
end() 获取匹配内容的结束位置
groupdict() 获取捕获组字典,组名为键,对应内容为值
groups() 获取子组对应内容
group(n = 0)默认为0表示获取整个match对象内容
其中函数参数“flags”的值可以是下面几个的不同组合(使用“|”进行组合):
re.I(IGNORECASE 表示忽略大小写)
re.A(ASCII 元字符只能匹配ascii码 )
re.M(MULTILINE 多行匹配模式, 影响 ^ 和 $)
re.S(DOTALL 使元字符“.”匹配任意字符,包括换行符)
import re
s = """Hello world
你好,北京"""
regex=re.compile(r‘\w+’)
l=regex.findall(s)
print(l)
# OUT: ['Hello', 'world', '你好', '北京']
# 只能匹配ASCII码字符
regex = re.compile(r‘\w+’,flags = re.A)
l=regex.findall(s)
print(l)
# OUT: ['Hello', 'world']
# 忽略字母大小写
regex = re.compile(r'[a-z]+',flags = re.I)
l=regex.findall(s)
print(l)
# OUT: ['Hello', 'world']
小试牛刀
1、匹配网址
有一批网址:
http://www.interoem.com/messageinfo.asp?id=35
http://3995503.com/class/class09/news_show.asp?id=14
http://lib.wzmc.edu.cn/news/onews.asp?id=769
http://www.zy-ls.com/alfx.asp?newsid=377&id=6http://www.fincm.com/newslist.asp?id=415
需要正则后为:
http://www.interoem.com/
http://3995503.com/
http://lib.wzmc.edu.cn/
http://www.zy-ls.com/
http://www.fincm.com/
2、匹配合法的ip地址
3、匹配所有合法的电子邮件地址(格式如上)
4、打开test.txt文本,将里边得文本使用正则表达式筛选出数字,再存入test1.txt文件中。
答案见文章绑定的资源中(注:资源中还有其他的练习)
结束语
尝试着去适应和改变,
尝试着去探索和发现,
生活的美好就在平凡的每一天,每一秒。