Redis应用-缓存
目录
什么是缓存
使用redis作为缓存
缓存的更新策略
通用的淘汰策略
redis内置的淘汰策略
缓存预热
缓存穿透
缓存雪崩
缓存击穿
什么是缓存
缓存(cache)是计算机中一个经典的概念,在很多的场景中都会涉及到.
核心思路就是把一些常用的数据放到触手可及(访问速度更快)的地方,方便随时读取.
对于计算机来说,往往访问速度越快的设备,成本越高,存储空间越小.
因此,缓存是更快了,但是空间上往往是不足的.所以大部分的时候,缓存只存放一些热点数据(频繁访问的数据).
二八定律:20%的热点数据能够应对80%的访问场景,因此只需要把这少量的热点数据缓存起来,就可以应对大多数的场景,从而整体上有明显的性能提升.
使用redis作为缓存
我们通常使用redis来作为数据库(mysql)等的缓存.
数据库是非常重要的组件,在绝大部分商业项目中都会使用到,并且mysql的速度又比较慢,所以就可以使用redis来作为mysql的缓存.

因为mysql等数据库的效率比较低,所以承担的并发量有限,一旦请求的数量多了,数据库的压力就会很大,甚至很容易宕机.
如何让数据库承担更大的并发量,核心思路有两个:开源和节流.
开源:引入更多的机器,部署更多的数据库实例,构成数据库集群.
节流:引入缓存,使用其他的方式保存经常访问的热点数据,从而降低直接访问数据库的请求数量.
redis就是一个用来作为数据库缓存的常见方案,redis的访问速度比mysql快很多,或者说处理同一个访问请求,redis消耗的系统资源比mysql少很多,因此redis能支持的并发量更大.
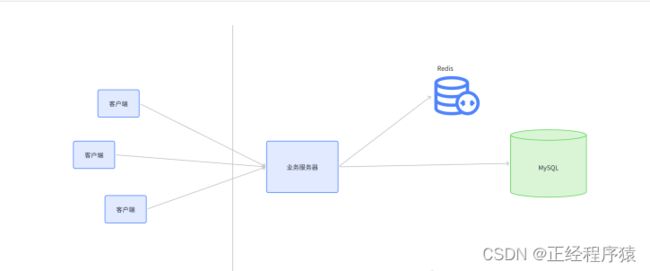
redis就像是一个护盾一样,保护着mysql.
客户端访问业务服务器,发起查询请求,业务服务器会先查询redis,查看想要的数据是否在redis中存在,如果在redis中存在了,就直接返回,此时就不必访问mysql了;如果在redis中不存在,在去查询mysql.
根据二八定律,只需要在redis中存放20%的热点数据,就可以使80%的请求不在真正的查询mysql,从而大大提高整体的访问效率,降低数据库的压力.
需要注意的是:缓存是用来加快读操作的速度的,如果写操作,还是要写进数据库,此时缓存并不能提高性能.
缓存的更新策略
如何知道redis中应该存储哪些数据,如何知道哪些数据是热点数据呢?
1.定期生成
每隔一定的周期(比如一天/一周/一个月),对于访问的数据频次进行统计,挑选出访问频次最高的前N%的数据.
优点:实现起来比较简单,过程更加可控,方便排查问题.
缺点:实时性不够,如果出现一些突发性事件,有一些本来不是热点的数据变成了热点数据,那么新的热点数据可能会给数据库带来较大的压力.
2.实时生成
先给缓存设定容量上限(可以通过redis配置文件的maxmemory参数设定).
接下来用户的每次查询,如果在redis中查到了,就直接返回,如果redis中不存在,就从数据库查,同时把查到的结果也写入redis.
如果缓存满了,就会触发内存淘汰策略,把一些相对不那么热门的数据淘汰掉.
按照上述过程,持续一段事件之后,redis内部的数据自然就是热门数据了.
通用的淘汰策略
FIFO(first in first out)
先进先出,把缓存中存在时间最久的,也就是先来的数据,淘汰掉.
LRU(least recently used)
淘汰最久未使用的,记录每个key的最近访问时间,把最近访问时间最老的key淘汰掉.
LFU(least frequently used)
淘汰访问次数最少的,记录每个key最近一段时间的访问次数,把访问次数最少的淘汰掉.
Random
随机淘汰,从所有的key中随机抽取淘汰掉.
上述的淘汰策略,可以自己实现,redis也提供了内置的淘汰策略,供我们直接使用.
redis内置的淘汰策略
缓存预热
缓存穿透
缓存穿透产生的原因:
缓存雪崩
短时间内大量的key在缓存上失效,导致数据库压力骤增,设置直接宕机.
产生原因
大规模的key失效,可能性主要有两种.
1.redis直接挂了.redis宕机或者redis集群模式下大量节点宕机.
2.redis上大量的key同时过期.很可能之前短时间内设置了很多key给redis,并且设置的过期时间是相同的.
解决方法
1.加强监控报警,加强redis集群可用性的保证.
2.不给key设置过期时间,或者在设置过期时间的时候添加随机因子,避免同一时间过期.
缓存击穿
cache breakdown,也可以叫做缓存瘫痪/崩溃.
相当于缓存雪崩的特殊情况,针对热点key,突然过期了,导致大量的请求直接访问到数据库上,甚至引起数据库宕机.
如何解决
1.基于统计的方式发现热点key,并设置永不过期.
2.进行必要的服务降级,例如访问数据库的时候使用分布式锁,限制同时请求数据库的并发数.
服务降级:在特定的情况下,适当的关闭一些不重要的功能,只保留核心的功能.