C/C++知识补充
1.在C++11标准里面,auto能从声明的初始化表达式中推导出变量的类型,如auto a = 100;和int a = 100;等价
2.long long 才是64位,long和int是等价的,都是32位。至于为什么还会有个所谓的长整型的存在呢?这个和编码的历史有关,这里就不展开了。
这里借用一下其它博主的图
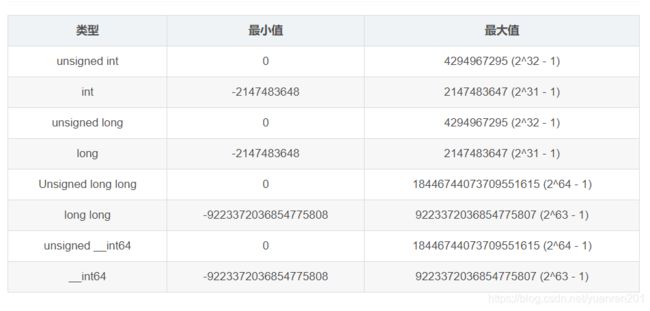
原链接在这:https://blog.csdn.net/chao2016/article/details/73359271
3.最大的无符号整数是4294967295;最大的有符号整数是2147483647
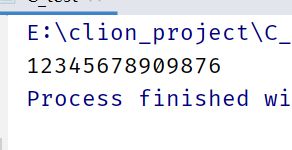
4.string装long long:
//借用sstream头文件中的stringstream
string a="12345678909876";
stringstream ss(a);
long long ll=0;
ss>>ll;
cout<<ll;
运行结果:
5.INT_MAX和INT_MIN的头文件是limits.h
6.用条件运算符?:实现按条件输出:
#include 运行结果:
7.引用(reference)就是一个变量的别名,例子如下:
int i = 0;
int & iRef = i;
iRef++; // i = iRef = 1
更多说明请点击这里
8.用条件运算符实现按条件返回:
// std::nullopt can be used to create any (empty) std::optional
auto create2(bool b) {
return b ? std::optional<std::string>{"Godzilla"} : std::nullopt;
}
9.pair的构造
一共有3种,这里我只提一种,另外两种可浏览C++ pair用法
std::pair <string,double> p1;
p1 = std::make_pair("shoes",20.0);
10.获得stringstream的长度:
stringstream.str().length();
11.判断一个字符串是否在枚举类型里:
我暂时没找到C/C++能实现的,但是Java中是有的,类似于用.valueOf()把字符串转成枚举类型,然后就可以直接switch case了
java的实现在这:https://blog.csdn.net/Fighting_Boss/article/details/80929166
12.string类的头文件是string,命名空间是std,注意,它的首字母是小写
13.strcmp比较两个字符串,如果相同,则返回0.原型为int strcmp(const char *a, const char *b)
14.比较两个字符串是否相同时,可以用"==",也可以用strcmp函数(头文件是cstring,相同则返回0).例子如下:
#include 运行结果:

15.C++中string类型转成char*型:
string.c_str();
16.声明数组:type arrayname[arraysize],如int y[100]
Java声明数组:type[] arrayname = new type[size],如double[] y = new double[100]
python声明数组,就有点麻烦了,可以看看这篇博客
17.几个预处理指令:
1)#if 如果给定条件为真,则编译下面代码
2)#ifdef 如果宏已经定义,则编译下面代码
3)#ifndef 如果宏没有定义,则编译下面代码
4)#endif 结束一个#if …#else条件编译块
18.关于指针
1)函数指针与指针函数:
int *func(),int (*func)(),(int *)func()中的func含义的区别:
int *func()和(int *)func()是等价的,在这两种情况中,func都是普通的函数名,不过这个函数的返回值是一个指针。而且从这里也可以看出,*是优先和左边的符号结合,所以如果出现int *a,b这样的代码,那就是定义了一个指针变量a,一个整型变量b;
int (*func)()中,func是一个指向参数为空,返回值为int的函数的指针,使用如下:
#include 运行结果:

2)数组指针与指针数组:
char *p[4]和(char *)p[4]是等价的,都是一个包含4个char指针的数组,所以是指针的数组;char (*p)[4]则是一个指向有4个char的指针,是一个数组的指针
3)二维指针:
来品一下这个数组:
char *language[]={"fortran", "basic","pascal","java","c"};
这个language是一个元素为char*的数组,所以它的第一个元素是一个指针,而不是字符串
- language是这个指针数组的地址,也就是指向
fortran这个字符串的指针的地址 - *language是从第一个元素的地址所提取出来的第一个指针的值,也就是
fortran这个字符串的地址。如果要修改这个指针的指向,就这样修改:*language=... - **language是从
fortran这个字符串的地址中进一步提值,也就是f这个字母 - 所以,变量的地址和变量的值是不一样的
- *language==*(language+0)==laguage[0],即中括号同时起到地址偏移和取值的作用
- *language+2相当于取第一个字符串的地址,然后跳两个char,最后的输出是rtran
- *(language+2)则是往后跳取两个元素,也就是指向’pascal’这个指针,然后取这个指针的值,也就是字符串的地址
- 最后来总结一下
- language+x(x=0,1,2,3,4,下同)就是取这5个字符串指针的地址,也就是存放指针的地址,这时候如果用printf(“language+1=%s”,language+1)会输出乱码
- *(language+x)就是从地址中取出指针的值,也就是开始读取字符串的内容了 ,用printf("*(language+1)=%s",*(language+1))可以输出字符串
- *(*(language+x)+y)指的是第x+1个字符串的第y+1个字符
- 示例程序如下(x=1,y=2):
#include 运行结果:

4)这是我们课件的说明:

5)指针的运算符有两个:
i)&:取地址运算符,用来取数组或变量地址的运算符
ii)*:用来取某地址中的内容的运算符
下面是一个实例:

6)如果要把指针作为函数的参数传到函数里,然后修改指针的指向,如果不想用return的话,那么需要用到二级指针。因为所谓指针的指向,就是指针的值,修改一个变量的值,自然需要利用它的地址。而一级指针的地址就只能用二级指针来存。如下:
#include 7)给字符串指针数组(比如char *tmp[10])赋值时,不能用strcpy,直接用赋值符号就可以了;这点和字符二维数组刚好是反过来的。
但是指针数组虽然在赋值上面比较方便,但是由于它是和内存打交道的,比如有一个字符串指针数组char *a[100],和一个字符数组char name[100],如果我在第 i步执行a[i]=name,那么往后我想修改name的值,然后把这个值赋给a[j]时,由于指向name的这块内存的内容发生了变化,所以a[i]的值也会相应发生变化,最后就会导致a[i]和a[j]指向同一块内存,从而使这俩的内容一样
总之就是,指针数组就是垃圾,不要用它
8)指针的*号在声明和使用时的意义是不一样的,声明时的意义是表明它是指针变量,使用时是取值
9)说一下什么叫字符型指针和字符型指针数组
根据我们PPT的定义,字符型指针的定义如下:
char *p;//指向字符型的指针
所以字符型指针数组就是一个元素为字符型指针的数组,也就是字符串指针数组:
char *p[];
19.strcmp函数的头文件是string.h
20.二级指针相当于一个指针数组,即这个指针指向的是一个数组,这个数组的元素全都是指针
21.以下两种情况中的Te的意义:
typedef struct T{...} Te:是T结构体的新名称
struct T{...} Te:是T结构体类型的变量
22.我们有以下的一个二维指针:
struct Test **p,那么
1)**p就是一个Test结构体
2)*p就是指向第一个结构体的指针
3)p就是指向这个结构体指针数组的指针
23.给指针赋值:
int *a;
int x=1+1;
a=&x;
24.C++输出string:好像只能用str.c_str()把string转成char*,然后才能用printf("%s",string)输出
25.double fabs(double x):返回x的绝对值,这个x是double型
float fabsf(float x):返回float型x的绝对值
int abs(int x):返回int型x的绝对值
26.isspace():C的库函数,它检查所传字符是否是以下的空白字符:
’ ’ (0x20) space (SPC) 空格符
‘\t’ (0x09) horizontal tab (TAB) 水平制表符
‘\n’ (0x0a) newline (LF) 换行符
‘\v’ (0x0b) vertical tab (VT) 垂直制表符
‘\f’ (0x0c) feed (FF) 换页符
‘\r’ (0x0d) carriage return (CR) 回车符
27.获取数据变量的类型:typeid(obj).name(),示例如下:
#include 运行结果:

关于typeid().name()
28.另外如果不在定义变量时就声明字符串的类型为string,那就会默认是char数组,比如这段代码:
#include 运行结果:

29.C++申请空间直接用new就可以了
struct INT{
int value;
string name;
}
INT *a = new INT;
30.遍历vector的方式:
1)正序遍历
//auto关键字
for(auto it = _identifiers.begin();it!=_identifiers.end();it++){
//do something
}
这样,*it就是这个vector中的元素
2)逆序遍历
#include 运行结果:

31.char*转string:这个很直接,直接赋值就可以了,甚至都不需要调用接口:
#include 运行结果:

32.make_pair是一个函数,当然得用括号把两个参数括起来,而不能是像声明时的那样用尖括号括起来,即:
声明:![]()
make_pair:
![]()
33.修改vector中结构体的属性值好像没有相关接口,我是直接遍历找到需要修改的元素,然后直接给它的相应元素赋新值的
34.C语言中的switch语句后的表达式只能接short,char,int,long这些整型和枚举类型,float、double、Boolean这些都是不可以的。
35.数字0~9的ASCII码是48~57;大写字母A~Z的ASCII码值是65~90;小写字母a~z的ASCII码值是97~122。
36.给字符数组赋值的方法:
- 定义时直接赋值,char a[10]=“123”;
- 逐个字符赋值,char a[10]={‘1’,‘2’,‘3’};
- 用strcpy,strcpy(a,“123”);
最后要注意的是,不能在声明结束后再给字符串数组赋整个字符串,比如char a[10]; a="123"。因为这时候a是一个数组名,而数组名属于常指针,是个产量;a="123"相当于改变这个常指针的指向,从指向这个数组的地址变成指向123这个字符串常量所在的地址。
37.关于strlen()
1)函数原型:size_t strlen(const char *str),功能是计算字符串str的长度,直到结束符\0,但不包括结束符
2)sizeof是计算这个数据结构所占的总字节数,所以会把字符串末尾的\0给加进去
3)像这样的字符数组:char a[100]={'1','2','3'};,用strlen计算出来的长度也是3
38.用scanf输入一堆,然后以回车键结束:
char c;
while(scanf("%c",&c)!=EOF){
printf("%c",c);
}
在命令行中运行时,先按回车,然后CTRL+z即可结束输入(在Linux中式CTRL+d)
39.数组可以作为参数传递给函数,这实际上传递的是数组的首地址,即第一个元素的地址。因为作为参数的数组名,它的值就是个地址,把这个值传给函数时,实际上就是把地址传给了函数
40.fscanf(file pointer, "%s", char s[100])如果读到了空格就会停止读入
41.scanf()函数接收输入数据时,遇到空格、回车、跳格等空白符会结束一个数据的输入,但是如果是以空白符结束输入,那就需要再输入一个非空白符+回车才能结束输入。关于scanf更详细的说明可见由scanf说起之1:scanf函数和回车、空格 及其返回值
42.一个比较容易出错的例子如下:
int *p;
int i=0;
*p=i;
这个p指向的地址是随机的,不知道会把i的值赋给哪块重要的地址,可能造成意想不到的错误
43.malloc函数原型:void *malloc(size_t size)
44.两个指向同一数组成员的指针可以进行相减,其结果为两指针间相差元素的个数,比如p指向数组第一个元素,q指向数组最后一个元素则q-p+1表示数组长度;但是要注意,指针是不能相加的
45.y=*p++,这里面需要分成两步去分析:
1)取出p指针指向的地址里面的数赋给y
2)p指针+1,指向下一个元素
*p++等效于*(p++),这个看起来好像和先用了再加有点矛盾,但其实是不矛盾的,因为还是先取p指向的地址,然后取值,用了这个指针指向的地址,再对其进行运算
46.各种判断输入结束:
1)判断标准输入的输入结束:
while(gets(s)!=NULL){...}
如果是fgets也是NULL
fgets的使用格式:
fgets(char *s,int size,FILE *stream)
2)读入文件时判断读入是否结束:
while((c=fgetc(in))!=EOF){...}
3)用fscanf读入文件
while(fscanf(fileptr,"%...",...)!=EOF){...}
结束标志:
| 函数 | 结束标志 |
|---|---|
| gets/fgets | NULL |
| fgetc /getc | EOF |
| fscanf/scanf | EOF |
所以就是,只有gets和fgets是以NULL结尾的;
另外说一下,fgetc和getc的用法是一样的,都是从文件流中读取内容
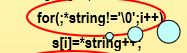
47.把一个字符串复制到另一个字符串中:
i=0;
while((s[i]=t[i])!='\0')
i++;
其中s[i]=t[i]这个表达式的值是t[i]。而且这样写的好处是可以把反斜杠0也写到s数组里面。要是用类似这样的写法,就不能写进去:
48.char *gets(char s[])从标准输入中读入一行到数组S中,但换行符不读入,数组以’\0’结束,如果是输入结束或发生错误则返回NULL
49.分析以下两个swap函数:
1)

2)

只有1才能实现值交换的目的,是通过修改地址中的内容实现的,2只是换了两个指针的指向
50.数组名和指针是有区别的,前者是常量,后者是变量
51.错误分析
#include 错误原因是返回的是临时变量s,而临时变量在函数结束时这个函数所用的栈都会销毁,所以返回一个临时变量是没有意义的,可以对insert函数修改如下:

图中绿框框起来的那段,用malloc申请了内存后,只要不free,这块内存都会一直存在,不管是不是在函数里面,这样返回这个局部变量就有意义了。
52.指针声明时可以不用初始化,但是使用前一定要初始化,即明确它指向哪块内存
53.定义在函数内部的变量就是本地变量
54.结构类型我觉得应该是从struct开始,一直到那个结构类型名那里,即struct node这样子
55.来说一下C语言中简单赋值运算符=:
1)首先,它的优先级是低于==,!=这两个的
2)它的运算顺序是从右到左,所以a=b=c这个等式的结果是,a的值是c,b的值也是c
3)最后说一下,一个把字符串t拼接到字符串s后面的函数:

就是填空那里,我本来填的是*t!=’\0’,这个原来的答案暴露了好几个问题:
1)赋值运算符的优先级低于不等号
2)赋值运算符的运算顺序是从右到左
3)按原来的答案,*(s+n)的值是*t!=’\0’这个不等式的正误,即0表示错,1表示对
56.一个典型的错误
#include 这样会导致程序运行崩溃,具体原因是*a=‘1’,*(a+1)=‘2’,*(a+2)=‘3’,*(a+3)=’\0’,这块内存是不能变的,而在sstrcat函数里,在第一步循环里面就试图通过*(s+n)=*t来修改它*(a+3)的内容,所以会出错
57.结构体如果以这样的形式void fun(struct node a)作为参数,那么其实是函数自己创建了一个新的结构体,作为实参的结构体中的值被复制到新的结构体中,然后在这个函数中进行的所有操作都是只针对这个结构体副本进行的操作而已。所以,结构体变量我感觉也是和普通变量一样,而不是相数组名那样表示一个地址。
58.今天发现指针的一个特别巧的用法,那就是通过指针的偏移来截取字符串,比如
char *s="-20";
printf("%d",atoi(s+1));//不要负号,只要后面的“20”
运行结果:

另外,关于string类的截取,可以用string.substr()方法:
1)s.substr(pos,n):截取s中从pos开始到末尾的n个字符的子串并返回
2)s.substr(pos):截取s中从pos开始到末尾的所有字符的子串,并返回
59.fread函数解析:
1)原型:size_t fread( void *buffer, size_t size, size_t count, FILE *stream )
2)工作原理:从给定输入流stream中读取cout个对象(对象大小为size个字节),并把它们替换到buffer缓冲区指定的数组,返回值是读取的对象的数量(即成功读取的字节数/size)
参考:fread函数详解
60.ungetc函数的作用是把废弃的数据退回到流里面去,比如下面这种用法:
ungetc(c,stdin)
61.圆括号英文:Parentheses
中括号:bracket
花括号:curly(卷曲的)
62.所谓的有序序列,就是能确定顺序的序列,它的顺序应当是有意义的,而我们根据同样的规则可以得到同样的序列;而有序性就是指线性关系,有相对应的前驱和后继
63.~是按位取反,!表示判断式的值取反
64.用一个数组来表示各个对象的布尔属性,用char flag[n]={0}就可以直接在函数内部一句话搞定初始化,而且占的空间还小
65.要修改一个已存在的文件,只能用“r+”,用“w+”打开一个已存在的文件的话,会导致原文件丢失,这也是这两种读写模式的区别
66.fgets在读入的字符串后面加换行符,而gets不加;
fputs不在输出的字符串后面加换行符,而puts会加换行符
67.计算x的y次方:
double pow(double x,double y);
头文件是math.h
68.atoi函数的头文件是stdlib.h
69.结构体自引用只能引用指针,不然相当于递归调用,没有调用结束的时刻
下面关于线性表的说法错误的是:ABC
A. 可以对线性表进行插入和删除操作,因此,采用数组的方式来定义线性顺序表时候,不能限定数组的长度。
B.对线性表的操作中,可能需要在线性表的第i个位置插入一个新的元素,或者需要删除线性表的第i个位置元素,在指定操作位置i时,一定要保证i是一个合适的值,即1≤i≤n(其中n为线性表当前元素个数)。
C. 对有序顺序表操作的时间效率比无序顺序表操作的时间效率要高。
D.线性表中的所有元素必须具有相同的类型,即线性表元素具有同一性。
解析:
B的错误原因是i应该是从0~n-1;
C的意思是所有操作,而插入和删除的话,两者的效率显然是一样的;
最后补充一下,线性表有3大特点:
1)同一性:同一数据类型
2)有穷性:有限个数据元素
3)有序性:相邻元素间有前后顺序关系
71.isalpha,isdigit这些函数的头文件是ctype.h
72.今天看到个新写法:
struct Node{
int key;
int val;
//这个构造函数的意思相当于函数体内部的key=k,val=v
Node(int k=0,int v=0):key(k),val(v){}
}
这种写法叫做参数初始化表,在效率上没有区别,仅仅是书写方便,尤其是成员变量较多时。
73.迭代器:迭代器是一种检查容器内元素并遍历元素的数据类型,可以代替下标访问容器内对象的元素。每种容器类型都定义了自己的迭代器类型,比如vector的迭代器定义如下:
vector<int>::iterator iter;
这句话定义了一个名为iter,它的数据类型是vector
可以简单理解为指针
74.关于容器的end()方法,容易以为返回的是容器的最后一个元素,其实指向的是最后一个元素的下一个
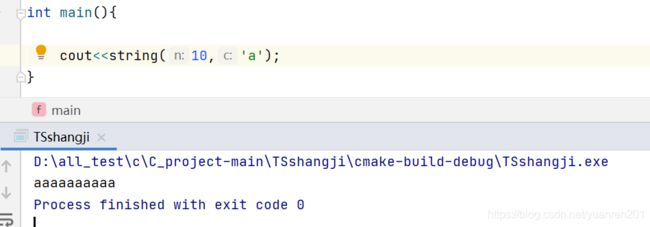
75.string(int num,char c)解析:
这句代码的意思是返回一个字符串,这个字符串是由num个字符c组成的:
76.string声明后默认是个空字符串