从零开始安装并运行YOLOv5
从零开始安装并运行YOLOv5
该文主要实现用YOLOv5的基准检测为自己的视频片段渲染对象检测结果和边界框,本文大部分都是实操,帮助大家快速上手。
什么是YOLOv5?
yolo是一种用于对象检测的最先进的机器学习模型,yolo有不同的版本比如v5v8,如果你提供一个输入,它会给你返回一个输出,那么yolo的输入和输出是什么呢?yolo接受图像或者是一批图像作为其输入,在处理该图像后,它会在图像上放置边界框,它会告诉你在每个边界框中检测到的一个对象,这些边界框就是输出,它还识别每个边界框中的对象是什么,如下图。

图片中有一个红色框标识了person,黄色框标识了backpack,简而言之,yolo就是一台将此类边框放在图片上的机器。但是yolo不会直接将这些边界框绘制或渲染到图像上,而是为每个边界框提供多个值,它为每个边界框提供xmin、xmax、ymin、ymax,标识该边界框的位置,第五个值label代表标签,其中有一个id,例如0标识person,27代表tie(领带)等等
因此,当id为0时,我们知道这里有一个人,然后我们就可以渲染此边界框时写入,最终值是置信度,告诉你整个结果的确定性。

如何使用我们自己的视频在我们自己的计算机上使用YOLO?
正式开始操作!!!
1、环境配置
首先我们需要一个Python环境,这个过程不需要会Python编程,因为代码已经存在,我们只需要运行它即可。这里可以使用一个单独的Python环境或者Anaconda中的环境,本文用的是单独的Python环境,如果你没有Python环境或者有很多个Python环境,请看作者的另一篇文章,pip安装报错?彻底弄清Python软件包安装流程并解决安装错误,文中也会清楚的说明如何把python和pip加入到环境变量中,这也是环境配置中重要的一环。
2、下载YOLOv5
下载网址:GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
点击Download即可下载,下载完成后解压。

此时我们就得到了这样一个文件夹,如下图。

3、安装必要的库
首先我们要安装的库是pytorch,网址:PyTorch,下滑找到下图页面,我用的是Windows所以选择Windows,因为是单独的python环境所以选择pip,有显卡GPU的话可以下载CUDA选择CUDA对应版本(如果只需要训练和简单推理,则无需安装CUDA,如果需要编译、部署等,那么还是需要单独安装CUDA的),这里我选择CPU版本,选择好后,最下方就会出现终端指令,复制在终端运行即可。

终端运行。

在这里我出现了这个错误,这是因为我代理忘记关了,此时可以关闭代理或者让终端也处于代理模式,终端代理指令看这篇文章。
![]()
处理好后再次执行命令,就能安装成功啦,如下图。


4、开始使用
先切换到yolov5所在目录,如下图操作,你的yolov5放在哪你就去哪找,我这里放在e盘。

然后,你可以放一个你想要输入的视频在该文件夹中,如下图。

接着,终端执行以下命令。
python detect.py --source PUBG.mp4
此时提示没有某某模块。

那就使用pip安装一下这个模块就行,如果提示没有别的模块也同理(这里注意如果安装yaml需要把模块名称写成pyyaml)。
![]()
安装好后再次执行。
python detect.py --source PUBG.mp4
可以看到已经在输出了。

最后进入到结果路径文件夹就能找到输出的视频。



其他版本yolo
我们在yolov5主页可以看到还有很多个版本的yolo,如下图,params表示参数量,参数量更大的训练结果更好。

我们可以使用指定版本的yolo,例如指定yolov5s6,使用以下命令。
python detect.py --source PUBG.mp4 --weights yolov5s6.pt
这里可以看到有几个关键的参数,参数放在detect.py文件中的parse_opt()函数中,如下图。

关键参数

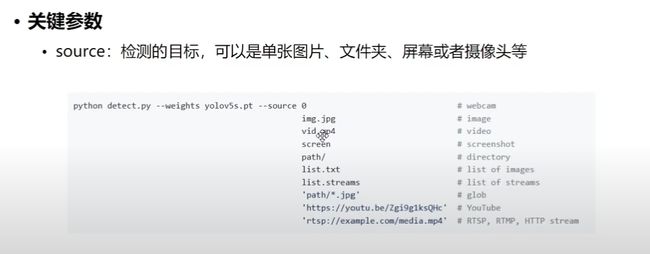
source:
0表示摄像头、path/表示文件夹、screen表示整个屏幕,剩下的如下图所示,一目了然。
conf-thres:

假设我们一开始默认识别出来的效果是上图(左1),经过下述命令将置信度阈值设置为0.8,那么只有检测结果置信度高于0.8才能被成功检测出,如上图(左2)。
python detect.py --weights yolov5s.pt --conf-thres 0.8
iou-thres:

iou-thres用于确定两个边界框被认为是重叠的阈值。当两个边界框的重叠度(IOU)超过这个阈值时,它们被认为是重叠的。
当iou_thres值较低时,意味着两个边界框只有在非常接近完全重叠时才会被认为是重叠的。因此,对于具有较小重叠度的边界框对,它们可能会被视为不重叠,从而导致更少的检测框。
相反,当iou_thres值较高时,意味着即使两个边界框之间的重叠度较小,它们仍然可能被认为是重叠的。这可能导致更多的边界框被检测到。
其他参数
- imgsz表示图像大小,默认是640*640
- max-det表示在一张图片中最大的检测数量
- device就是设备
- view-img就是检测过程中会把检测结果弹出一个框展示
- save开头的参数就是把检测出的某些值存下来,而不仅仅是存一张图片,nosave参数就是与之对应的
- classes是可以指定只检测哪些类别
主要的就这些,剩下的可以自己去了解。

更简单的模型检测

步骤:
1、下载jupyter,下载速度慢的两种解决办法,博客里都有博客1,博客2,命令如下。
pip install jupyterlab
2、pycharm(或别的可视化软件)中新建一个hub_detect.ipynb文件。
3、把代码放入,代码yolo官网也有,这里和官网代码不一样,因为模型不一定非要从torch.hub上进行加载,也可以加载本地的模型(source设置为local,第一个参数填模型所在文件夹路径),如下图就是选择加载本地模型,同样,图片也不一定非要从网上获取,最后的显示用show函数就可以弹出一个展示框。

官网代码:

这里如果提示没有jupyter,可以看这篇文章进行配置:文章。
那么上述代码相对于detect.py文件中的代码来说,明显是比较简洁的,虽然参数没有detect.py文件上那么全,但大部分要求都能满足,并且用这种方式书写代码后续会很好封装。
教程就到这里啦,希望大家能顺利运行。