机器学习中的降维算法汇总归纳
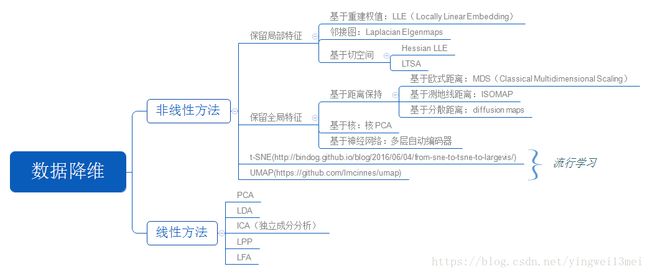
最近看了降维的各类算法,想简单做个回顾和小结,先上图
一、浅谈协方差矩阵
1.1、统计学的基本概念
均值: x ¯ =∑ n i=1 x i n x ¯ = ∑ i = 1 n x i n
方差: var(x)=∑ n i=1 (x i −x ¯ ) 2 n−1 v a r ( x ) = ∑ i = 1 n ( x i − x ¯ ) 2 n − 1
标准差: var(x) − − − − − √ v a r ( x )
均值描述的是样本集合的中间点,它告诉我们的信息是有限的,而标准差给我们描述的是样本集合的各个样本点到均值的距离之平均。
以这两个集合为例,[0, 8, 12, 20]和[8, 9, 11, 12],两个集合的均值都是10,但显然两个集合的差别是很大的,计算两者的标准差,前者是8.3后者是1.8,显然后者较为集中,故其标准差小一些,标准差描述的就是这种“散布度”。之所以除以n-1而不是n,是因为这样能使我们以较小的样本集更好地逼近总体的标准差,即统计上所谓的“无偏估计”。而方差则仅仅是标准差的平方。
1.2、为啥需要协方差
标准差和方差一般是用来描述一维数据的,但现实生活中我们常常会遇到含有多维数据的数据集,最简单的是大家上学时免不了要统计多个学科的考试成绩。面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解更多,比如,一个男孩子的猥琐程度跟他受女孩子的欢迎程度是否存在一些联系。协方差就是这样一种用来度量两个随机变量关系的统计量,我们可以仿照方差的定义: var(x)=∑ n i=1 (x i −x ¯ ) 2 n−1 v a r ( x ) = ∑ i = 1 n ( x i − x ¯ ) 2 n − 1
来度量各个维度偏离其均值的程度,协方差可以这样来定义:
cov(x,y)=∑ n i=1 (x i −x ¯ )(y i −y ¯ )n−1 c o v ( x , y ) = ∑ i = 1 n ( x i − x ¯ ) ( y i − y ¯ ) n − 1
协方差的结果有什么意义呢?如果结果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),也就是说一个人越猥琐越受女孩欢迎。如果结果为负值, 就说明两者是负相关,越猥琐女孩子越讨厌。如果为0,则两者之间没有关系,猥琐不猥琐和女孩子喜不喜欢之间没有关联,就是统计上说的“相互独立”。
从协方差的定义上我们也可以看出一些显而易见的性质,如:
1、 cov(X,X)=var(X) c o v ( X , X ) = v a r ( X )
2、 cov(X,Y)=cov(Y,X) c o v ( X , Y ) = c o v ( Y , X )
1.3、协方差矩阵
前面提到的猥琐和受欢迎的问题是典型的二维问题,而协方差也只能处理二维问题,那维数多了自然就需要计算多个协方差,比如n维的数据集就需要计算 n!(n−2)!∗2 n ! ( n − 2 ) ! ∗ 2 个协方差,那自然而然我们会想到使用矩阵来组织这些数据。给出协方差矩阵的定义:
C n∗n =(c i,j ,c i,j =cov(Dim i ,Dim j )) C n ∗ n = ( c i , j , c i , j = c o v ( D i m i , D i m j ) )
这个定义还是很容易理解的。协方差矩阵是一个对称的矩阵,而且对角线是各个维度的方差。
1.4、小结
理解协方差矩阵的关键就在于牢记它的计算是不同维度之间的协方差,而不是不同样本之间。拿到一个样本矩阵,最先要明确的就是一行是一个样本还是一个维度,心中明确整个计算过程就会顺流而下,这么一来就不会迷茫了。
二、PCA(主成分分析)
本质上讲,PCA就是将高维的数据通过线性变换投影到低维空间上去,但这个投影可不是随便投投,要遵循一个指导思想,那就是:找出最能够代表原始数据的投影方法。这里怎么理解这个思想呢?“最能代表原始数据”希望降维后的数据不能失真,也就是说,被PCA降掉的那些维度只能是那些噪声或是冗余的 数据。这里的噪声和冗余我认为可以这样认识:
- 我们常说“噪音污染”,意思就是“噪声”干扰我们想听到的真正声音。同样,假设样本中某个主要的维度A,它能代表原始数据,是“我们真正想听到的东西”,它本身含有的“能量”(即该维度的方差,为啥?别急,后文该解释的时候就有啦~)本来应该是很大的,但由于它与其他维度有那么一些千丝万缕的相关性,受到这些个相关维度的干扰, 它的能量被削弱了,我们就希望通过PCA处理后,使维度A与其他维度的相关性尽可能减弱,进而恢复维度A应有的能量,让我们“听的更清楚”!
- 冗余:冗余也就是多余的意思,就是有它没它都一样,放着就是占地方。同样,假如样本中有些个维度,在所有的样本上变化不明显(极端情况:在所有的样本中该维度都等于同一个数),也就是说该维度上的方差接近于零,那么显然它对区分不同的样本丝毫起不到任何作用,这个维度即是冗余的,有它没它一个样,所以PCA应该去掉这些维度。
协方差阵
协方差矩阵度量的是维度与维度之间的关系,而非样本与样本之间。协方差矩阵的主对角线上的元素是各个维度上的方差(即能量),其他元素是两两维度间的协方差(即相关性)。我们要的东西协方差矩阵都有了,先来看“降噪”,让保留下的不同维度间的相关性尽可能小,也就是说让协方差矩阵中非对角线元素都基本为零。达到这个目的的方式自然不用说,线代中讲的很明 确——矩阵对角化。而对角化后得到的矩阵,其对角线上是协方差矩阵的特征值,它还有两个身份:首先,它还是各个维度上的新方差;其次,它是各个维度本身应该拥有的能量(能量的概念伴随特征值而来)。这也就是我们为何在前面称“方差”为“能量”的原因。也许第二点可能存在疑问,但我们应该注意到这个事实,通过对角化后,剩余维度间的相关性已经减到最弱,已经不会再受“噪声”的影响了,故此时拥有的能量应该比先前大了。看完了“降噪”,我们的“去冗余”还没完呢。对角化后的协方差矩阵,对角线上较小的新方差对应的就是那些该去掉的维度。
所以我们只取那些含有较大能量(特征值)的维度,其余的就舍掉即可。PCA的本质其实就是对角化协方差矩阵。
总结一下PCA的算法步骤:
设有m条n维数据。
1)将原始数据按列组成n行m列矩阵X
2)将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3)求出协方差矩阵 C=1m XX T C = 1 m X X T
4)求出协方差矩阵的特征值及对应的特征向量
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
6) Y=PX Y = P X 即为降维到k维后的数据
PCA理解第一层境界:最大方差投影
正如PCA的名字一样, 你要找到主成分所在方向, 那么这个主成分所在方向是如何来的呢?
其实是希望你找到一个垂直的新的坐标系, 然后投影过去, 这里有两个问题。 第一问题: 找这个坐标系的标准或者目标是什么? 第二个问题, 为什么要垂直的, 如果不是垂直的呢?
如果你能理解第一个问题, 那么你就知道为什么PCA主成分是特征值和特征向量了。 如果你能理解第二个问题, 那么你就知道PCA和ICA到底有什么区别了。 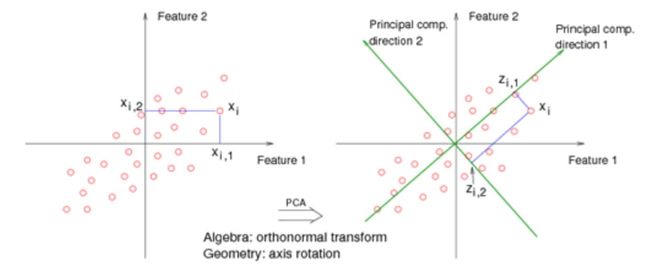
对于第一个问题: 其实是要求解方差最小或者最大。 按照这个目标, 你代入拉格朗日求最值, 你可以解出来, 主成分方向,刚好是S的特征向量和特征值! 是不是很神奇? 伟大的拉格朗日(参考 “一步一步走向锥规划 - QP” “一挑三 FJ vs KKT “)

现在回答了,希望你理解了, PCA是对什么东西求解特征值和特征向量。 也理解为什么是求解的结果就是特征值和特征向量吧!
这仅仅是PCA的本意! 我们也经常看到PCA用在图像处理里面, 希望用最早的主成分重建图像:

这是怎么做到的呢?
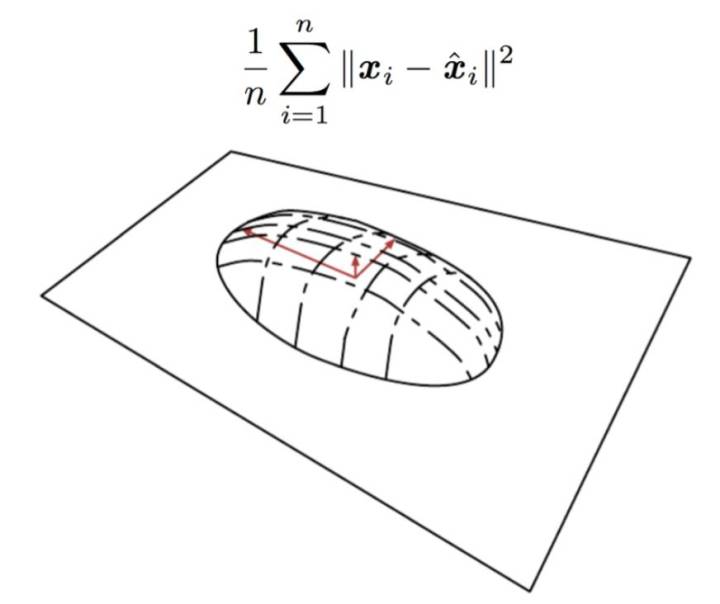
PCA理解第二层境界:最小重建误差
什么是重建, 那么就是找个新的基坐标, 然后减少一维或者多维自由度。 然后重建整个数据。 好比你找到一个新的视角去看这个问题, 但是希望自由度小一维或者几维。

那么目标就是要最小重建误差,同样我们可以根据最小重建误差推导出类似的目标形式。

虽然在第二层境界里面, 也可以直观的看成忽略了最小特征值对应的特征向量所在的维度。 但是你能体会到和第一层境界的差别么? 一个是找主成分, 一个是维度缩减。 所以在这个层次上,才是把PCA看成降维工具的最佳视角。
PCA理解第三层境界:高斯先验误差
在第二层的基础上, 如果引入最小二乘法和带高斯先验的最大似然估计的等价性。(参考”一步一步走向锥规划 - LS” “最小二乘法的4种求解” ) 那么就到了理解的第三层境界了。

所以, 重最小重建误差, 我们知道求解最小二乘法, 从最小二乘法, 我们可以得到高斯先验误差。

有了高斯先验误差的认识,我们对PCA的理解, 进入了概率分布的层次了。 而正是基于这个概率分布层次的理解, 才能走到Hinton的理解境界。
PCA理解第四层境界(Hinton境界):线性流形对齐
如果我们把高斯先验的认识, 到到数据联合分布, 但是如果把数据概率值看成是空间。 那么我们可以直接到达一个新的空间认知。
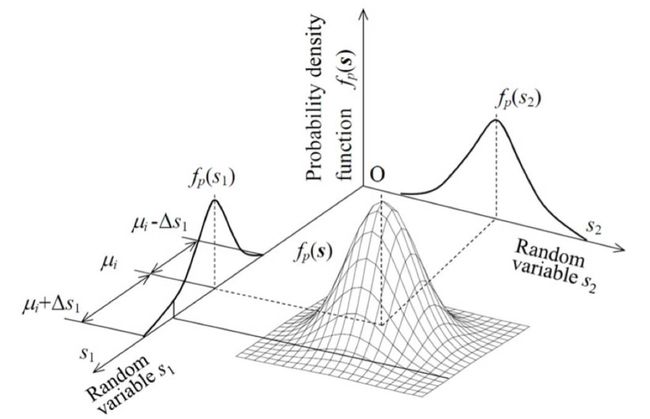
这就是“Deep Learning”书里面写的, 烙饼空间(Pancake), 而在烙饼空间里面找一个线性流行,就是PCA要干的事情。 我们看到目标函数形式和最小重建误差完全一致。 但是认知完全不在一个层次了。
小结
这里罗列理解PCA的4种境界,试图通过解释Hinton如何理解PCA的, 来强调PCA的重要程度。 尤其崇拜Hinton对简单问题的高深认知。不仅仅是PCA,尤其是他对EM算法的再认识, 诞生了VBEM算法, 让VB算法完全从物理界过渡到了机器学习界(参考 “变の贝叶斯”)。 有机会可以看我对EM算法的回答,理解EM算法的9种境界。
三、SVD(奇异值分解)
http://www.cnblogs.com/peizhe123/p/5113357.html
https://www.cnblogs.com/pinard/p/6251584.html
https://blog.csdn.net/u010099080/article/details/68060274
从Andrew的课来看:SVD相当于an implementation of PCA 1.现在的计算机计算SVD已经很成熟了,Andrew本人将其视作平方运算这样的计算。 2.用SVD来实现PCA,避免了高维sigma矩阵(设计矩阵/协方差矩阵)的计算。
回顾下特征值和特征向量的定义如下: Ax=λx A x = λ x
其中A是一个 n×n n × n 的矩阵,x 是一个n维向量,则我们说 λ λ 是矩阵A的一个特征值,而x是矩阵A的特征值λ所对应的特征向量。
求出特征值和特征向量有什么好处呢? 就是我们可以将矩阵A特征分解。如果我们求出了矩阵A的n 个特征值 λ 1 ≤λ 2 ≤...≤λ n λ 1 ≤ λ 2 ≤ . . . ≤ λ n ,以及这n n 个特征值所对应的特征向量 w 1 ,w 2 ,...w n w 1 , w 2 , . . . w n ,如果这n个特征向量线性无关,那么矩阵A就可以用下式的特征分解表示:
A=WΣW −1 A = W Σ W − 1
其中W是这n个特征向量所张成的 n×n n × n 维矩阵,而 ∑ ∑ 为这n个特征值为主对角线的 n×n n × n 维矩阵。
一般我们会把W的这n个特征向量标准化,即满足 ||w i || 2 =1 | | w i | | 2 = 1 , 或者说 w T i w i =1 w i T w i = 1 , 此时W的n个特征向量为标准正交基,满足 W T W=I W T W = I , 即 W T =W −1 W T = W − 1 , 也就是说W为酉矩阵。
这样我们的特征分解表达式可以写成 A=W∑W T A = W ∑ W T
注意到要进行特征分解,矩阵A必须为方阵。那么如果A不是方阵,即行和列不相同时,我们还可以对矩阵进行分解吗?答案是可以,此时我们的SVD登场了。
假设有 m×n m × n 的矩阵 A, 那么 SVD 就是要找到如下式的这么一个分解,将 A分解为 3 个矩阵的乘积: A m×n =U m×m Σ m×n V T n×n A m × n = U m × m Σ m × n V n × n T
其中,U 和 V都是正交矩阵 (Orthogonal Matrix),在复数域内的话就是酉矩阵(Unitary Matrix),即 U T U=E m×m U T U = E m × m , V T V=E n×n V T V = E n × n 换句话说,就是说 U的转置等于 U的逆,V 的转置等于 V 的逆。而 ∑ ∑ 就是一个非负实对角矩阵。
求解
U U 和V V 的列分别叫做 A的 左奇异向量(left-singular vectors)和 右奇异向量(right-singular vectors), ∑ ∑ 的对角线上的值叫做 A的奇异值(singular values)。
其实整个求解 SVD 的过程就是求解这 3 个矩阵的过程,而求解这 3 个矩阵的过程就是求解特征值和特征向量的过程,问题就在于 求谁的特征值和特征向量。
- U U 的列由 AA T A A T 的单位化过的特征向量构成
- V V 的列由 A T A A T A 的单位化过的特征向量构成
- ∑ ∑ 的对角元素来源于 AA T A A T 或 A T A A T A 的特征值的平方根,并且是按从大到小的顺序排列的
那么求解 SVD 的步骤就显而易见了:
- 求 AA T A A T 的特征值和特征向量,用单位化的特征向量构成 U U
- 求 A T A A T A 的特征值和特征向量,用单位化的特征向量构成 V V
- 将AA T A A T 或者 A T A A T A 的特征值求平方根,然后构成 ∑ ∑
四、FA(因子分析)
https://blog.csdn.net/yujianmin1990/article/details/49247307
https://blog.csdn.net/sinat_37965706/article/details/71330979
因子分析其实就是认为高维样本点实际上是由低维样本点经过高斯分布、线性变换、误差扰动生成的,因此高维数据可以使用低维来表示(本质上就是一种降维算法)。因子分析(factor analysis)是一种数据简化的技术。它通过研究众多变量之间的内部依赖关系,探求观测数据中的基本结构,并用少数几个假想变量来表示其基本的数据结构。这几个假想变量能够反映原来众多变量的主要信息。原始的变量是可观测的显在变量,而假想变量是不可观测的潜在变量,称为因子。
因子分析,实际上应该叫做公共因子分析,看其定义:
X=AF+ϵ X = A F + ϵ
X X 表示原始数据, F F 表示公共因子,ϵ ϵ 是特殊因子
因子分析的原理是假设原始的数据是由公共因子(公共维度)与误差因子(非公共维度)构成的,如上式所写。(但因子分析更关心公共因子,对特殊因子不甚关心)
那么,如何找到公共因子呢? 我们先尝试对上式变形运算:
X T X=(AF+ϵ) T (AF+ϵ) X T X = ( A F + ϵ ) T ( A F + ϵ )
先看右侧,我们将非公共部分去掉,得到:
X T X≈(AF) T (AF) X T X ≈ ( A F ) T ( A F )
注意此处的约等于不是抽取公共因子(用少量公共因子)之后造成的约等,而是因为去掉了特殊因子造成的约等。
X T X=VΛV T X T X = V Λ V T 实对称矩阵的特征值分解,此处不做单位化处理。
X T X=[β 1 ,β 2 ,...,β n ]⎡ ⎣ ⎢ ⎢ ⎢ λ 1 λ 2 ... λ n ⎤ ⎦ ⎥ ⎥ ⎥ ⎡ ⎣ ⎢ ⎢ ⎢ β 1 β 2 ...β n ⎤ ⎦ ⎥ ⎥ ⎥ X T X = [ β 1 , β 2 , . . . , β n ] [ λ 1 λ 2 . . . λ n ] [ β 1 β 2 . . . β n ]
X T X=[λ 1 − − √ β 1 ,λ 2 − − √ β 2 ,...,λ n − − √ β n ]⎡ ⎣ ⎢ ⎢ ⎢ ⎢ λ 1 − − √ β 1 λ 2 − − √ β 2 ...λ n − − √ β n ⎤ ⎦ ⎥ ⎥ ⎥ ⎥ X T X = [ λ 1 β 1 , λ 2 β 2 , . . . , λ n β n ] [ λ 1 β 1 λ 2 β 2 . . . λ n β n ]
对比上式: X T X≈(AF) T (AF) X T X ≈ ( A F ) T ( A F ) 看着形式是一样的,并且符合了定义的公共因子的样子。
如果从 [λ 1 − − √ β 1 ,λ 2 − − √ β 2 ,...,λ n − − √ β n ] [ λ 1 β 1 , λ 2 β 2 , . . . , λ n β n ] 抽取几个 β β 作为公共因子,岂不是个很好的想法。于是,就有了公共因子。
此处的左侧 X T X X T X ,怎么看着这么眼熟,是不是跟前面提到的协方差矩阵很像。哈哈,是的,很像。但是请注意:
这里可以不用去中心化,因为没有严格的去研究维度之间的相关性,而是单纯的做了转置再乘以自身(当然也可以去中心化),这种变形运算是为了凑出右侧乘的形式,以便于跟定义的公共因子的样子相近。
至此,公共因子的抽取也就结束了,至于公共因子旋转之类的操作,是为了使得公共因子更具有可解释性,暂时还不做解释了。
还有如何利用公共因子去分析原始维度的重要性,这里也不做赘述了,大家自己上网搜索了解吧。
公共因子的形式可以有很多种,都能凑出定义的形式来,那么也就有很多因子分析方法了。
小结 PCA和FA是很常用的因素分析方法,他们之间既有联系又各不相同。
- 主成分分析,是分析维度属性的主要成分表示。
- 因子分析,是分析属性们的公共部分的表示。
from sklearn import datasets
from matplotlib import pyplot as plt
iris = datasets.load_iris()
from sklearn.decomposition import FactorAnalysis
fa = FactorAnalysis(n_components=2)
iris_two_dim = fa.fit_transform(iris.data)
iris_two_dim[:5]
f = plt.figure(figsize=(5, 5))
ax = f.add_subplot(111)
ax.scatter(iris_two_dim[:,0], iris_two_dim[:, 1], c=iris.target)
ax.set_title("Factor Analysis 2 Components")
五、独立成分分析(ICA)
https://blog.csdn.net/shenziheng1/article/details/53637907
https://blog.csdn.net/cai2016/article/details/52983473
动机源自于cocktail party problem(鸡尾酒会问题),ICA与被称为盲源分离(Blind Source Separation,BSS)或盲信号分离的方法具有非常密切的关系。“源”在此处的意思是指原始信号,即独立成分,如鸡尾酒会中的说话者;而“盲”表示我们对于混合矩阵所知甚少,仅仅对源信号做非常弱的假定。ICA是实现盲源分离的其中一种,但也许是被最广泛使用的方法。
推荐电子工业出版社的一本中译本教材《独立成分分析》,稍稍一读感觉之前到处搜罗资料的时间真是浪费了,很多时候确实是外国的月亮更圆啊。
以鸡尾酒会声音辨别为例,将每个声音区分出来,这样人大脑就可以很快集中听需要注意的声音。以下以三个独立源为例,三个接收端,每个接收端都含有三个声音源的线性叠加。下图是示例图:

对模型参数的解释
A=[a11,a12,a12;a21,a22,a23;a31,a32,a32]作为一个混合矩阵,这里的每一个元素可以表示鸡尾酒舞会问题中物理意义为距离,X为观测信号,S为独立源也就是声音信号。以上模型中假设每个独立源噪声干扰很小,忽略影响。实际上在ICA信号盲源分离中可以将噪声信号单独一种独立源处理较好,一些文献对于ICA噪声就是采用这种方案进行处理。
半盲源分离信号分离
在混合矩阵A已知的前提下,反解出独立源就很简单。ICA常用的情形是混合矩阵和独立源都不明确的条件下一种估计算法。真正实现信号的盲源分离。
ICA盲源分离流程

上述流程图中,由独立源线性组合成的观测信号X,只需要对S进行求解即可。S=B*X,其中B为A的逆,通过迭代对A进行逼近,当达到设置的精度时即可分离出混合矩阵的近似。盲源分离的目的是求得源信号的最佳估计。
ICA假设的三个条件
独立成分被假设是统计独立。对于这一条可以从概率密度以及其他算法可以判断。我们说随机变量 y 1 ,y 2 ..y n y 1 , y 2 . . y n 独立,是指在i≠j时,有关 y i y i 的取值情况对于 y j y j 如何取值没有提供任何信息。
独立成分具有非高斯分布。如果观测到的变量具有高斯分布,那么ICA在本质上是不可能实现的。假定S经过混合矩阵A后,他们的联合概率密度仍然不变化,因此我们没有办法在混合中的得到混合矩阵的信息。
假设混合矩阵是方阵。这个条件是为了后续ICA算法求解的便利。当混合矩阵A是方阵时就意味着独立源的个数和监测信号的个数数目是一致。
ICA算法步骤
观测信号构成一个混合矩阵,通过数学算法进行对混合矩阵A的逆进行近似求解分为三个步骤:
1) 去均值。去均值也就是中心化,实质是使信号X均值是零。
2) 白化。白化就是去相关性。
3) 构建正交系统。在常用的ICA算法基础上已经有了一些改进,形成了fastICA算法。fastICA实际上是一种寻找 w T z(即Y=w T z) w T z ( 即 Y = w T z ) 的非高斯最大的不动点迭代方案。
以上有较多的数学推导,这里就省略了,下面给出fastICA的算法流程:
1 观测数据的中心化
2 数据白化
3 选择需要估计的分量个数m,设置迭代次数和范围
4 随机选择初始权重
5 选择非线性函数
6 迭代
7 判断收敛,是下一步,否则返回步骤6
8 返回近似混合矩阵的逆矩阵六、LDA(linear discriminant analysis)
https://www.cnblogs.com/pinard/p/6244265.html
6.1 LDA 思想
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。什么意思呢? 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
我们先看看最简单的情况。假设我们有两类数据 分别为红色和蓝色,如下图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。

上图中国提供了两种投影方式,哪一种能更好的满足我们的标准呢?从直观上可以看出,右图要比左图的投影效果好,因为右图的黑色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。以上就是LDA的主要思想了,当然在实际应用中,我们的数据是多个类别的,我们的原始数据一般也是超过二维的,投影后的也一般不是直线,而是一个低维的超平面。
6.2 算法流程
现在我们对LDA降维的流程做一个总结。
输入:数据集 D={(x 1 ,y 1 ),(x 2 ,y 2 ),...,((x m ,y m ))} D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( ( x m , y m ) ) } ,其中任意样本 x i x i 为n维向量, y i ∈{C 1 ,C 2 ,...,C k } y i ∈ { C 1 , C 2 , . . . , C k } , 降维到的维度d。
输出:降维后的样本集 D' D ′
1) 计算类内散度矩阵 S w S w
2) 计算类间散度矩阵 S b S b
3) 计算矩阵 S −1 w S b S w − 1 S b
4)计算 S −1 w S b S w − 1 S b 的最大的d个特征值和对应的d个特征向量 (w 1 ,w 2 ,...w d ) ( w 1 , w 2 , . . . w d ) ,得到投影矩阵
5) 对样本集中的每一个样本特征 x i x i , 转化为新的样本 z i =W T x i z i = W T x i
6) 得到输出样本集 D'={(z 1 ,y 1 ),(z 2 ,y 2 ),...,(z m ,y m )} D ′ = { ( z 1 , y 1 ) , ( z 2 , y 2 ) , . . . , ( z m , y m ) }
以上就是使用LDA进行降维的算法流程。实际上LDA除了可以用于降维以外,还可以用于分类。一个常见的LDA分类基本思想是假设各个类别的样本数据符合高斯分布,这样利用LDA进行投影后,可以利用极大似然估计计算各个类别投影数据的均值和方差,进而得到该类别高斯分布的概率密度函数。当一个新的样本到来后,我们可以将它投影,然后将投影后的样本特征分别带入各个类别的高斯分布概率密度函数,计算它属于这个类别的概率,最大的概率对应的类别即为预测类别。
6.3 LDA vs PCA
LDA用于降维,和PCA有很多相同,也有很多不同的地方,因此值得好好的比较一下两者的降维异同点。
首先我们看看相同点:
1)两者均可以对数据进行降维。
2)两者在降维时均使用了矩阵特征分解的思想。
3)两者都假设数据符合高斯分布。
我们接着看看不同点:
1)LDA是有监督的降维方法,而PCA是无监督的降维方法
2)LDA降维最多降到类别数k-1的维数,而PCA没有这个限制。
3)LDA除了可以用于降维,还可以用于分类。
4)LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。
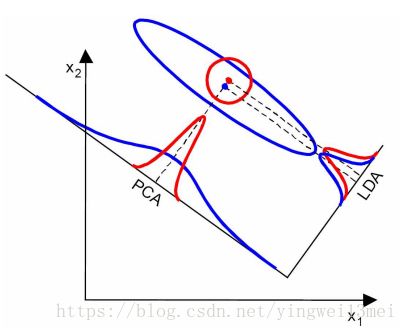
这点可以从下图形象的看出,在某些数据分布下LDA比PCA降维较优。

当然,某些某些数据分布下PCA比LDA降维较优,如下图所示:
6.4. 小结
LDA算法既可以用来降维,又可以用来分类,但是目前来说,主要还是用于降维。在我们进行图像识别图像识别相关的数据分析时,LDA是一个有力的工具。下面总结下LDA算法的优缺点。
LDA算法的主要优点有:
1)在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
2)LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
LDA算法的主要缺点有:
1)LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
2)LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
3)LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
4)LDA可能过度拟合数据。
七、t-SNE(t-distributed Stochastic Neighbor Embedding)
http://bindog.github.io/blog/2016/06/04/from-sne-to-tsne-to-largevis/
http://www.datakit.cn/blog/2017/02/05/t_sne_full.html
t-SNE(TSNE)将数据点之间的相似度转换为概率。原始空间中的相似度由高斯联合概率表示,嵌入空间的相似度由“t分布”表示。
7.1 SNE基本原理
SNE是通过仿射(affinitie)变换将数据点映射到概率分布上,主要包括两个步骤:
- SNE构建一个高维对象之间的概率分布,使得相似的对象有更高的概率被选择,而不相似的对象有较低的概率被选择。
- SNE在低维空间里在构建这些点的概率分布,使得这两个概率分布之间尽可能的相似。
我们看到t-SNE模型是非监督的降维,他跟kmeans等不同,他不能通过训练得到一些东西之后再用于其它数据(比如kmeans可以通过训练得到k个点,再用于其它数据集,而t-SNE只能单独的对数据做操作,也就是说他只有fit_transform,而没有fit操作)
7.2 t-SNE
尽管SNE提供了很好的可视化方法,但是他很难优化,而且存在”crowding problem”(拥挤问题)。后续中,Hinton等人又提出了t-SNE的方法。与SNE不同,主要如下:
- 使用对称版的SNE,简化梯度公式
- 低维空间下,使用t分布替代高斯分布表达两点之间的相似度
7.3 不足
主要不足有四个:
- 主要用于可视化,很难用于其他目的。比如测试集合降维,因为他没有显式的预估部分,不能在测试集合直接降维;比如降维到10维,因为t分布偏重长尾,1个自由度的t分布很难保存好局部特征,可能需要设置成更高的自由度。
- t-SNE倾向于保存局部特征,对于本征维数(intrinsic dimensionality)本身就很高的数据集,是不可能完整的映射到2-3维的空间
- t-SNE没有唯一最优解,且没有预估部分。如果想要做预估,可以考虑降维之后,再构建一个回归方程之类的模型去做。但是要注意,t-sne中距离本身是没有意义,都是概率分布问题。
- 训练太慢。有很多基于树的算法在t-sne上做一些改进
7.4 变种
- multiple maps of t-SNE
- parametric t-SNE
- Visualizing Large-scale and High-dimensional Data
八、UMAP(Uniform Manifold Approximation and Projection)
https://github.com/lmcinnes/umap
https://umap-learn.readthedocs.io/en/latest/
https://arxiv.org/abs/1802.03426
是一种类似t-SNE的降维可视化技术,用于非线性降维。算法是基于以下3个数据假设前提。
- The data is uniformly distributed on Riemannian manifold;
- The Riemannian metric is locally constant (or can be approximated as such);
- The manifold is locally connected.
九、Isomap
参考:https://blog.csdn.net/zhangweiguo_717/article/details/69802312
Isomap算法是在MDS算法的基础上衍生出的一种算法,MDS算法是保持降维后的样本间距离不变,Isomap算法引进了邻域图,样本只与其相邻的样本连接,他们之间的距离可直接计算,较远的点可通过最小路径算出距离,在此基础上进行降维保距。
计算流程如下:
- 设定邻域点个数,计算邻接距离矩阵,不在邻域之外的距离设为无穷大;
- 求每对点之间的最小路径,将邻接矩阵矩阵转为最小路径矩阵;
- 输入MDS算法,得出结果,即为Isomap算法的结果。
最小路径这里采用Floyd算法:输入邻接矩阵,邻接矩阵中,除了邻域点之外,其余距离都是无穷大,输出完整的距离矩阵。
参考:
https://www.zhihu.com/question/36348219/answer/275378672
https://mp.weixin.qq.com/s/G6ryJ0iLQ0dvMZbUj-71mw
https://blog.csdn.net/qiusuoxiaozi/article/details/50810521
https://wenku.baidu.com/view/ce7ee04bcc175527072208ca.html