Elasticsearch基础入门
一、走进Elasticsearch
1.1 全文检索
1.1.1 为什么要使用全文检索
用户访问我们的首页,一般都会直接搜索来寻找自己想要购买的商品。而商品的数量非常多,而且分类繁杂。如果能正确的显示用户想要的商品,并进行合理的过滤,尽快促成交易,是搜索系统要研究的核心。面对这样复杂的搜索业务和数据量,使用传统数据库搜索就显得力不从心,一般我们都会使用全文检索技术。常见的全文检索技术有Apache Lucene、Solr、Ferret、Elasticsearch等。
1.1.2 理解索引结构
下图是索引结构,下边黑色部分是物理结构,上边蓝色部分是逻辑结构,逻辑结构也是为了更好的去描述工作原理及去使用物理结构中的索引文件。

索引架构图
逻辑结构部分是一个倒排索引列表:
1、将要搜索的文档内容分词,所有不重复的词组成分词列表。
2、将搜索的文档最终以Document方式存储起来。
3、每个词和document都有关联。
如下:

分词
现在,如果我们想搜索quick brown,我们只需要查找包含每个词条的文档:
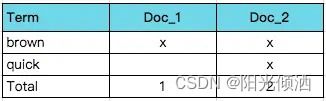
匹配结果
两个文档都匹配,但是第二个文档比第一个匹配度更高。如果我们使用仅计算匹配词条数量的简单相似性算法,那么,我们可以说,对于我们查询的相关性来讲,第二个文档比第一个文档更佳。
1.1.3 倒排索引(Inverted Index)
该索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。Elasticsearch能够实现快速、高效的搜索功能,正是基于倒排索引原理。
我们平时背诗一般是从前往后背,先记诗名、作者,然后背诗的内容。在我们脑子里,大概是这样的:
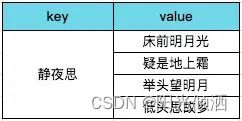
诗句索引
普通的索引,是以诗名作为key,诗的内容作为value。如果有人让你背静夜思你马上能反应过来,因为你从索引直接找到了诗。但如果有人让你说出带”前“字的诗句,由于没有索引,你只能遍历脑海中所有诗词,当你的脑海中诗词量大的时候,就很难在短时间内得到结果了。
如果采用倒排索引(又叫反向索引)的方式来存储就能快速检索出带”前“字的诗句。
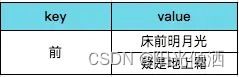
倒排索引
这就是倒排索引,以诗句内容中的一些关键字作为索引,来找到诗句。但这种方式,一句诗就可以建立10个倒排索引,诗句字数越多索引量还要更多,存储会呈现爆炸性地增长。我们可以做”压缩性“存储,既然我们可以通过诗名就想起一首诗,那反向索引就没必要索引到诗句了,只要索引到诗名就行。
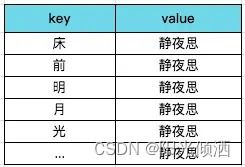
索引到诗名
value不存诗句改存诗题,数据量就会减少很多。这里,诗题可以理解为数据正向索引。
1.1.4 搜索引擎原理
百度、谷歌等这些搜索引擎的原理和我们背诗是一样的,最核心的都是建立倒排索引。搜索引擎三大过程:爬取内容、进行分词、建立反向索引。
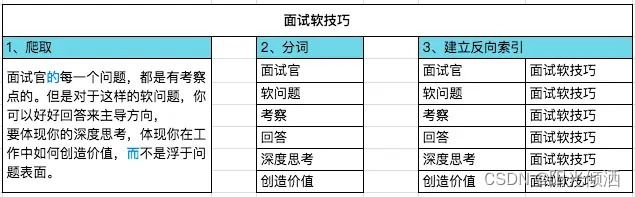
搜索引擎原理
其中标蓝色字体的”的“、”而“由于经过了停顿词过滤,所以不会作为分词。因为停顿词就是没有意义的词,这些词没有必要建立索引。
1.2 Elasticsearch
1.2.1 Elasticsearch简介
Elasticsearch是一个开源的分布式、RESTful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。
Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库——无论是开源还是私有,但它也仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理,因为Lucene 非常复杂。
为了解决Lucene使用时的繁复性,于是Elasticsearch便应运而生。它使用 Java 编写,内部采用 Lucene 做索引与搜索,但是它的目标是使全文检索变得更简单,简单来说,就是对Lucene 做了一层封装,它提供了一套简单一致的 RESTful API 来帮助我们实现存储和检索。
当然,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确地形容:
- 一个分布式的实时文档存储,每个字段可以被索引与搜索;
- 一个分布式实时分析搜索引擎;
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
由于Elasticsearch的功能强大和使用简单,维基百科、卫报、Stack Overflow、GitHub等都纷纷采用它来做搜索。现在,Elasticsearch已成为全文搜索领域的主流软件之一。
1.2.2 Elasticsearch工作原理
当Elasticsearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示:
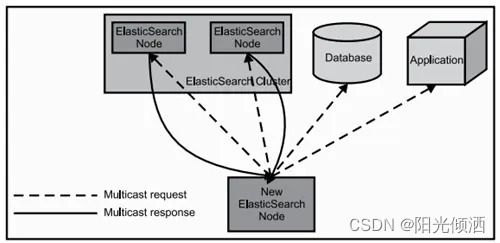
Elasticsearch节点
1.2.3 Elasticsearch核心概念
1、Cluster:集群
Elasticsearch可以作为一个独立的单个搜索服务器,不过,为了处理大型数据集,实现容错和高可用性,Elasticsearch可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2、Node:节点
形成集群的每个服务器称为节点。
3、Shard:分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。 当你查询的索引分布在多个分片上时,Elasticsearch会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
4、Replia:副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。 副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。 当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
5、全文检索
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。 全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
1.2.6 Elasticsearch数据架构的主要概念(与关系数据库Mysql对比)
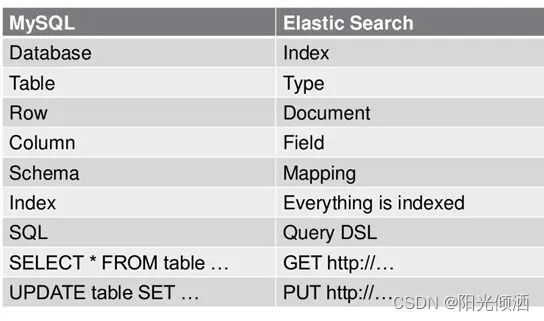
ES数据架构的主要概念
1、关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
2、一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type),
3、一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
4、在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
5、在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET
1.2.6 Elasticsearch特点和优势
1、分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
2、实时分析的分布式搜索引擎。
分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作; 负载再平衡和路由在大多数情况下自动完成。
3、可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上(已测试)
4、支持插件机制,分词插件(IK分词器)、同步插件、Hadoop插件、可视化插件等(Kibana)。
1.3 Elasticsearch国内外使用优秀案例
1、 2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”。
2、维基百科:启动以elasticsearch为基础的核心搜索架构。
3、SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”。
4、百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据。
1.4 ELK
ELK是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。市面上也被成为Elastic Stack。Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/Elasticsearch/kafka等)。Kibana可以将Elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。
二、Elasticsearch映射与数据类型
2.1 动态映射和静态映射
映射(Mapping)相当于数据表的表结构。ElasticSearch中的映射用来定义一个文档,可以定义所包含的字段以及字段的类型、分词器及属性等等。
映射可以分为动态映射和静态映射。
动态映射(dynamic mapping),在关系数据库中,需要事先创建数据库,然后在该数据库实例下创建数据表,然后才能在该数据表中插入数据。而ElasticSearch中不需要事先定义映射(Mapping),文档写入ElasticSearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
静态映射,在ElasticSearch中也可以事先定义好映射,包含文档的各个字段及其类型等,这种方式称之为静态映射。
2.2 静态映射数据类型
2.2.1 字符串类型

字符串类型
2.2.2 整数类型
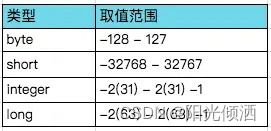
整数类型
2.2.3 浮点类型
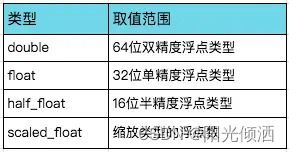
浮点类型
2.2.4 date类型
日期类型表示格式可以是以下几种
1、日期格式的字符串,比如“2020-01-12”或“2020-01-12 12:10:30”
2、long类型的毫秒数(milliseconds-since-the-epoch,epoch就是指UNIX诞生的UTC时间1970年1月1日0时0分0秒)
3、integer的秒数(seconds-since-the-epoch)
2.2.5 boolean类型
逻辑类型(布尔类型)可以接受true/false
2.2.6 binary类型
二进制字段是指用base64来表示索引中存储的二进制数据,可用来存储二进制形式的数据,例如图像。默认情况下,该类型的字段只存储不索引。二进制类型只支持index_name属性。
2.2.7 array类型
在ElasticSearch中,没有专门的数组(Array)数据类型,但是,在默认情况下,任意一个字段都可以包含0或多个值,这个意味着每个字段默认都是数组类型,只不过,数组类型的各个元素值的数据类型必须相同。在ElasticSearch中,数组是开箱即用的(out of box),不需要进行任何配置,就可以直接使用。
在同一个数组中,数组元素的数据类型是相同的,ElasticSearch不支持元素为多个数据类型:[10,"some string"]。
2.2.8 object类型
JSON天生具有层级关系,文档会包含嵌套的对象。
三、安装并运行Elasticsearch
在下载之前你应该确保你的 Java 版本保持在 1.8 及以上,这是 Elasticsearch 的硬性要求,可以自行打开命令行输入 java -version 来查看 Java 的版本
安装完 Java,就可以跟着官方文档安装 Elasticsearch,直接下载压缩包比较简单。我的开发环境是Mac OS,因此我选择的是Mac版本。
官方文档
下载压缩包后对其进行解压,cd进入解压elasticsearch的bin目录
cd /Users/AC/soft/elasticsearch-7.6.2/bin
运行elasticsearch文件启动elasticsearch
./elasticsearch
此时,Elasticsearch运行在本地的9200端口,在浏览器中输入地址http://localhost:9200/ 如果看到以下信息就说明你的电脑已成功安装Elasticsearch
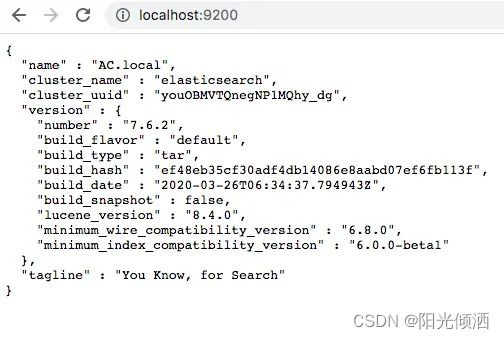
Elasticsearch安装成功
默认情况下,Elasticsearch 只允许本机访问,如果需要远程访问,可以修改 Elastic 安装目录的config/elasticsearch.yml文件,去掉network.host的注释,将它的值改成0.0.0.0,然后重新启动 Elasticsearch。
network.host: 0.0.0.0
上面代码中,设成0.0.0.0让任何人都可以访问。线上服务不要这样设置,要设成具体的 IP。
四、Elasticsearch可视化操作平台Kibana
Kibana 是一个开源的分析和可视化平台,旨在与 Elasticsearch 合作。Kibana 提供搜索、查看和与存储在 Elasticsearch 索引中的数据进行交互的功能。开发者或运维人员可以轻松地执行高级数据分析,并在各种图表、表格和地图中可视化数据。
你可以从 Elasticsearch 的官网获取最新版本的Kibana。解压文档后,cd进kibana的bin目录
cd /Users/AC/soft/kibana-7.6.2/bin
运行kibana文件启动kibana
./kibana
kibana启动后运行在5601端口上,我们可以在浏览器中输入http://localhost:5601 地址来访问kibana。
注意:启动kibana前必须先启动Elasticsearch,否则kibana会启动不成功。
kibana控制台界面
开发中我们一般用得比较多的是Dev Tools工具
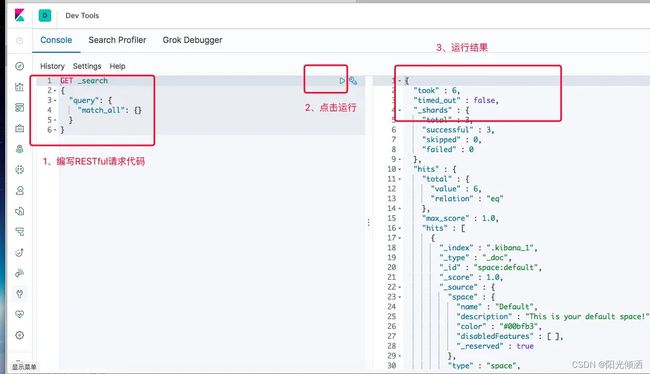
Dev Tools使用
五、Elasticsearch中文分词器-IK分词器
5.1 中文分词
首先我们通过Postman发送GET请求查询分词效果
GET http://localhost:9200/_analyze
{
"text":"我爱你中国"
}
得到如下结果,可以发现ES的默认分词器无法识别中文:我、我爱你、中国这样的词汇,而是简单的将每个字拆完分为一个词,这显然不符合我们的使用要求,所以我们需要安装中文分词器来解决这个问题。
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "",
"position": 0
},
{
"token": "爱",
"start_offset": 1,
"end_offset": 2,
"type": "",
"position": 1
},
{
"token": "你",
"start_offset": 2,
"end_offset": 3,
"type": "",
"position": 2
},
{
"token": "中",
"start_offset": 3,
"end_offset": 4,
"type": "",
"position": 3
},
{
"token": "国",
"start_offset": 4,
"end_offset": 5,
"type": "",
"position": 4
}
]
}
或用kibana请求得到效果(用kibana的话就不用再写IP地址和端口了)
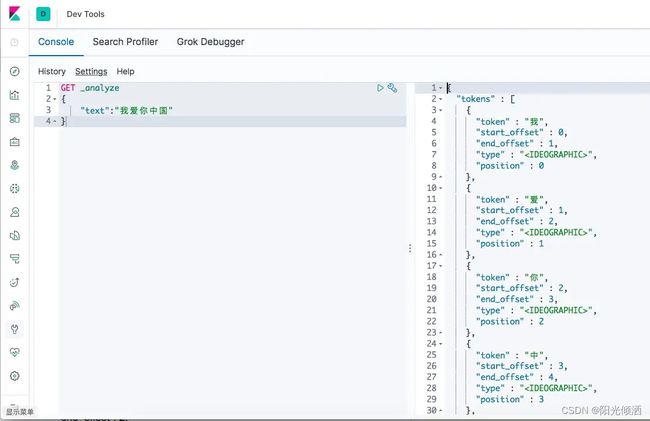
kibana请求
IK分词器是一款国人开发的相对简单的中文分词器。首先我们访问 https://github.com/medcl/elasticsearch-analysis-ik/releases 下载与ES对应版本的中文分词器。将解压后的后的文件夹放入ES根目录下的plugins/ik目录下(ik目录要手动创建),重启ES即可使用。
IK提供了两个分词算法ik_smart和ik_max_word。其中ik_smart为最少切分;ik_max_word为最细粒度划分。
- ik_max_word:会将文本做最细粒度的拆分,例如「我是程序员」会被拆分为「我、是、程序员、程序、员」。
- ik_smart:会将文本做最少切分,例如「我是程序员」会被拆分为「我、是、程序员」
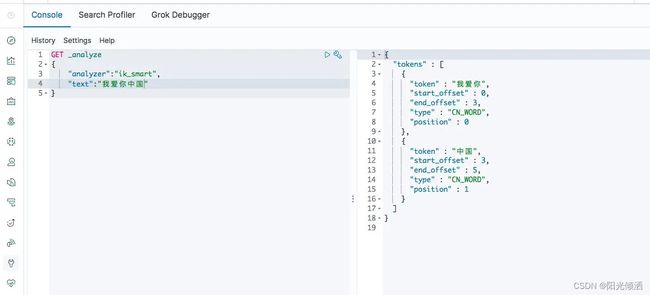 我爱你中国-IK分词器
我爱你中国-IK分词器
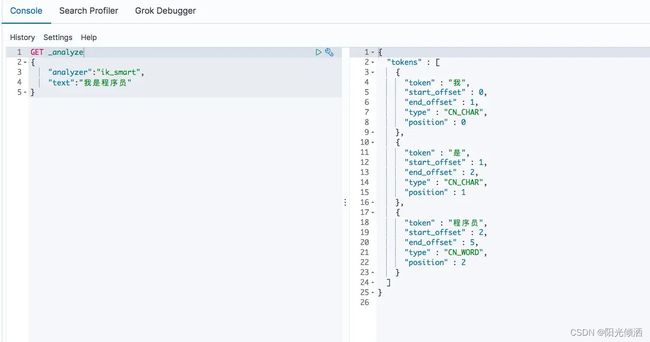
我是程序员-IK分词器
5.2 自定义词库
每年都会涌现一些特殊的流行词,如网红,蓝瘦香菇,喊麦,鬼畜,一般不会在ik的原生词典里。如[蓝瘦香菇]会被拆分成[蓝、瘦、香菇]三个词,而无法识别到[蓝瘦香菇]也是一个词。
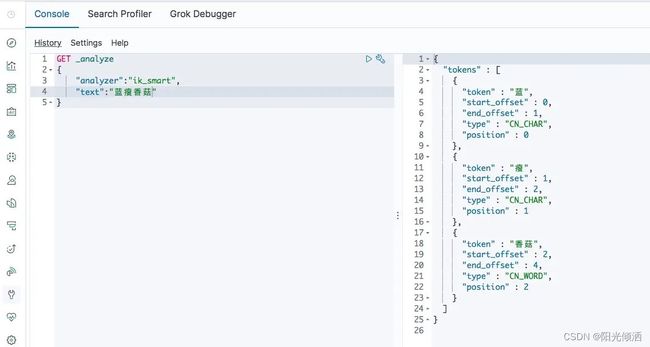
IK无法识别蓝瘦香菇
这时就需要自己补充自己的最新的词语到ik的词库里面去。首先进入ES根目录中的plugins文件夹下的ik文件夹,进入config目录,创建custom.dic文件,写入蓝瘦香菇。同时打开IKAnalyzer.cfg文件,将新建的custom.dic配置其中,重启ES。
IK Analyzer 扩展配置
custom.dic
再次查询发现ES的分词器可以识别到[蓝瘦香菇]词汇
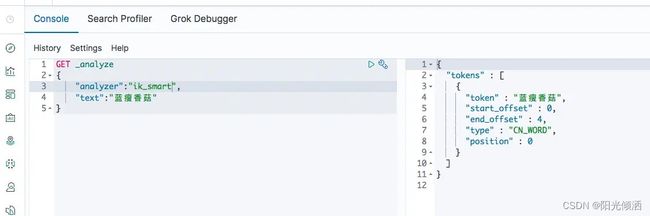
识别到蓝瘦香菇
六、索引操作
6.1 创建索引与映射字段
语法
PUT /索引库名
{
"mappings":{
"类型名称":{
"properties":{
"字段名":{
"type":"类型",
"index":true,
"store":true,
"analyzer":"分词器"
}
}
}
}
}
- 类型名称:就是type的概念,类似于数据库中的不同表。
- 字段名:类似于数据库中的字段名称。
- type:类似于数据库中字段的类型,可以是text、long、short、data、object等。
- index:是否索引,默认为true。如果你需要根据该字段进行查询或排序,则需要将该字段index设置为true,否则设置为false(如图片)。
- store:是否单独存储,默认为false,一般内容比较多的字段设置成true,可以提升查询性能。
- analyzer:分词器,如ik_smart
示例
PUT /sku
{
"mappings": {
"doc":{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_smart"
},
"price":{
"type":"integer"
},
"image":{
"type":"text"
},
"createTime":{
"type":"date"
},
"spuId":{
"type":"text"
},
"categoryName":{
"type":"keyword"
},
"brandName":{
"type":"keyword"
},
"spec":{
"type":"object"
},
"selNum":{
"type":"integer"
},
"commentNum":{
"type":"integer"
}
}
}
}
}
如果在6.x上执行,则会正常执行。在elasticsearch7.x上执行会失败,提示信息如下:
{
"error" : {
"root_cause" : [
{
"type" : "mapper_parsing_exception",
"reason" : "Root mapping definition has unsupported parameters: [doc : {properties={commentNum={type=integer}, image={type=text}, brandName={type=keyword}, selNum={type=integer}, createTime={type=date}, price={type=integer}, name={analyzer=ik_smart, type=text}, spuId={type=text}, categoryName={type=keyword}, spec={type=object}}}]"
}
],
"type" : "mapper_parsing_exception",
"reason" : "Failed to parse mapping [_doc]: Root mapping definition has unsupported parameters: [doc : {properties={commentNum={type=integer}, image={type=text}, brandName={type=keyword}, selNum={type=integer}, createTime={type=date}, price={type=integer}, name={analyzer=ik_smart, type=text}, spuId={type=text}, categoryName={type=keyword}, spec={type=object}}}]",
"caused_by" : {
"type" : "mapper_parsing_exception",
"reason" : "Root mapping definition has unsupported parameters: [doc : {properties={commentNum={type=integer}, image={type=text}, brandName={type=keyword}, selNum={type=integer}, createTime={type=date}, price={type=integer}, name={analyzer=ik_smart, type=text}, spuId={type=text}, categoryName={type=keyword}, spec={type=object}}}]"
}
},
"status" : 400
}
出现这个的原因是,elasticsearch7默认不再支持指定索引类型,默认索引类型是_doc。所以在Elasticsearch7中应该这么创建索引
PUT /sku
{
"mappings": {
"properties":{
"name":{
"type":"text",
"analyzer":"ik_smart"
},
"price":{
"type":"integer"
},
"image":{
"type":"text"
},
"createTime":{
"type":"date"
},
"spuId":{
"type":"text"
},
"categoryName":{
"type":"keyword"
},
"brandName":{
"type":"keyword"
},
"spec":{
"type":"object"
},
"selNum":{
"type":"integer"
},
"commentNum":{
"type":"integer"
}
}
}
}
执行成功,返回结果为
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "sku"
}
查看索引字段类型
//查看sku文档
GET sku/_mapping
//查看group文档
GET group/_mapping
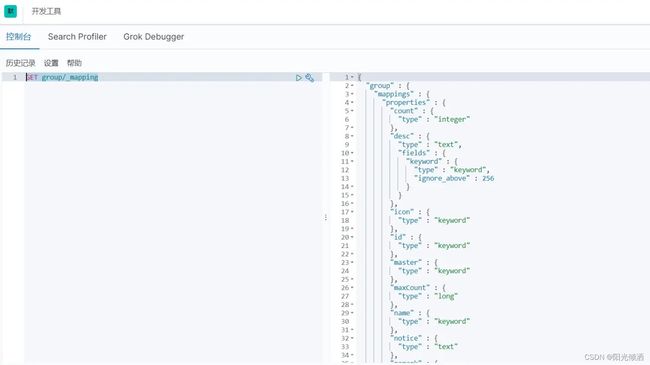
查看索引字段类型
6.2 文档增加与修改
6.2.1 增加文档自动生成ID
通过POST请求,可以向一个已经存在的索引库中添加数据。
语法:
POST 索引库名/类型名
{
"key":"value"
}
示例
POST sku/_doc
{
"name":"小米手机",
"price":200000,
"spuId":101,
"createTime":"2020-05-09",
"brandName":"小米",
"categoryName":"手机",
"saleNum":10012,
"commentNum":323,
"spec":{
"网络制式":"移动4g",
"屏幕尺寸":"4.5"
}
}
执行失败,提示
{
"error" : {
"root_cause" : [
{
"type" : "cluster_block_exception",
"reason" : "index [sku] blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"
}
],
"type" : "cluster_block_exception",
"reason" : "index [sku] blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"
},
"status" : 403
}
解决办法
PUT _settings
{
"index": {
"blocks": {
"read_only_allow_delete": "false"
}
}
}
参考:index [XXX] blocked by: [FORBIDDEN/12/index read-only / allow delete (api)]问题解决
再次执行,执行成功且返回信息如下
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "Ompe7HEBQIJxGG8U13yY",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 2
}
6.2.2 新增文档指定ID
如果我们想要自己新增的时候指定ID,可以这么做:
语法
PUT /索引库名/类型/ID值
{
...
}
示例
PUT sku/_doc/1
{
"name":"小米电视",
"price":100000,
"spuId":10110,
"createTime":"2020-05-09",
"brandName":"小米",
"categoryName":"电视",
"saleNum":10012,
"commentNum":323,
"spec":{
"网络制式":"移动4g",
"屏幕尺寸":"39"
}
}
可以通过查询命令查看刚才新增的数据
GET sku/_search
6.2.3 修改索引文档
我们可以继续通过 PUT /索引库名/类型/ID值 的方式来更改刚才插入的数据
PUT sku/_doc/1
{
"name":"华为电视",
"price":100000,
"spuId":10110,
"createTime":"2020-05-09",
"brandName":"华为",
"categoryName":"电视",
"saleNum":10012,
"commentNum":323,
"spec":{
"网络制式":"移动4g",
"屏幕尺寸":"39"
}
}
6.2.4 通过ID删除索引文档
DELETE /sku/_doc/z8qEEHIBZBLFtWo4JEtR
6.3 索引查询
基本语法
GET /索引库名/_search
{
"query":{
"查询类型":{
"查询条件":"查询条件值"
}
}
}
这里的query代表一个查询对象,里面可以有不同的查询属性
- 查询类型:例如match_all,match,term,range等等。
- 查询条件:查询条件会根据类型的不同,写法也有差异。
6.3.1 查询所有数据(match_all)
示例:
GET /sku/_search
{
"query": {
"match_all": {}
}
}
query:代表查询对象
match_all:代表查询所有
上面可以简写成:
GET sku/_search
6.3.2 匹配查询(match)
示例:查询名称包含手机的记录
GET /sku/_search
{
"query": {
"match": {
"name": "手机"
}
}
}
结果结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 0.44183272,
"hits" : [
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "Ompe7HEBQIJxGG8U13yY",
"_score" : 0.44183272,
"_source" : {
"name" : "小米手机",
"price" : 200000,
"spuId" : 101,
"createTime" : "2020-05-09",
"brandName" : "小米",
"categoryName" : "手机",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "移动4g",
"屏幕尺寸" : "4.5"
}
}
},
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.44183272,
"_source" : {
"name" : "苹果手机",
"price" : 100000,
"spuId" : 10112,
"createTime" : "2020-05-01",
"brandName" : "苹果",
"categoryName" : "手机",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "全网",
"屏幕尺寸" : "56"
}
}
},
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.44183272,
"_source" : {
"name" : "vivo手机",
"price" : 200000,
"spuId" : 10118,
"createTime" : "2020-05-01",
"brandName" : "vivo",
"categoryName" : "手机",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "全网",
"屏幕尺寸" : "56"
}
}
},
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "gAWw_nEBqh6AXa2lyxIz",
"_score" : 0.44183272,
"_source" : {
"name" : "三星手机",
"price" : 200000,
"spuId" : 104,
"createTime" : "2020-05-09",
"brandName" : "三星",
"categoryName" : "手机",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "移动4g",
"屏幕尺寸" : "4.5"
}
}
}
]
}
}
如果我们查询“小米电视”会有几条记录被查询出来呢?你可以能说会有一条,但我们测试一下会看到结果为:小米电视、小米手机、三星电视三条结果,这是为什么呢?这是因为在查询时,会先搜索关键字进行分词,对分词后的字符串进行查询(分成小米、电视两个词),只要是包含这些字符串的都是要被查询出来的,多个词之间是or的关系。
但注意,查询结果的匹配分值_score 是不一样的,分值高的排在前面。
搜索:小米电视
GET /sku/_search
{
"query": {
"match": {
"name": "小米电视"
}
}
}
查询结果:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 2.059239,
"hits" : [
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "2",
"_score" : 2.059239,
"_source" : {
"name" : "小米电视",
"price" : 100000,
"spuId" : 10111,
"createTime" : "2020-05-01",
"brandName" : "小米",
"categoryName" : "电视",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "全网",
"屏幕尺寸" : "56"
}
}
},
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "Ompe7HEBQIJxGG8U13yY",
"_score" : 1.0296195,
"_source" : {
"name" : "小米手机",
"price" : 200000,
"spuId" : 101,
"createTime" : "2020-05-09",
"brandName" : "小米",
"categoryName" : "手机",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "移动4g",
"屏幕尺寸" : "4.5"
}
}
},
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0296195,
"_source" : {
"name" : "三星电视",
"price" : 100000,
"spuId" : 10111,
"createTime" : "2020-05-01",
"brandName" : "三星",
"categoryName" : "电视",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "全网",
"屏幕尺寸" : "56"
}
}
}
]
}
}
如果我们想要进行精确查询,想要的是查询“小米电视”这一条记录,怎么办呢?我们可以这样写:
GET /sku/_search
{
"query": {
"match": {
"name": {
"query": "小米电视",
"operator": "and"
}
}
}
}
查询结果只有小米电视一条记录了:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.059239,
"hits" : [
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "2",
"_score" : 2.059239,
"_source" : {
"name" : "小米电视",
"price" : 100000,
"spuId" : 10111,
"createTime" : "2020-05-01",
"brandName" : "小米",
"categoryName" : "电视",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "全网",
"屏幕尺寸" : "56"
}
}
}
]
}
}
operator 指定为and,不指定时默认为or。
Java关键代码
SearchRequest request = new SearchRequest(index);
MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery(pageSearchVO.getField(), keyword);
//精确查询(关键字不分词查询)
queryBuilder.operator(Operator.AND);
builder.query(queryBuilder);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
控制精度
在 所有 与 任意 间二选一有点过于非黑即白。如果用户给定 5 个查询词项,想查找只包含其中 4 个的文档,该如何处理?将 operator 操作符参数设置成 and 只会将此文档排除。
有时候这正是我们期望的,但在全文搜索的大多数应用场景下,我们既想包含那些可能相关的文档,同时又排除那些不太相关的。换句话说,我们想要处于中间某种结果。
match 查询支持 minimum_should_match 最小匹配参数,这让我们可以指定必须匹配的词项数用来表示一个文档是否相关。我们可以将其设置为某个具体数字,更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量:
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": {
"query": "quick brown dog",
"minimum_should_match": "75%"
}
}
}
}
6.3.3 多字段查询(multi_match)
multi_match与match类似,不同的是它可以在多个字段中查询
GET /sku/_search
{
"query": {
"multi_match": {
"query": "小米",
"fields": ["name","brandName","categoryName"]
}
}
}
查询结果
{
"took" : 14,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0296195,
"hits" : [
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "Ompe7HEBQIJxGG8U13yY",
"_score" : 1.0296195,
"_source" : {
"name" : "小米手机",
"price" : 200000,
"spuId" : 101,
"createTime" : "2020-05-09",
"brandName" : "小米",
"categoryName" : "手机",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "移动4g",
"屏幕尺寸" : "4.5"
}
}
},
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0296195,
"_source" : {
"name" : "小米电视",
"price" : 100000,
"spuId" : 10111,
"createTime" : "2020-05-01",
"brandName" : "小米",
"categoryName" : "电视",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "全网",
"屏幕尺寸" : "56"
}
}
}
]
}
}
查询字段的模糊匹配
字段名称可以用模糊匹配的方式给出:任何与模糊模式正则匹配的字段都会被包括在搜索条件中,例如可以使用以下方式同时匹配 book_title 、 chapter_title 和 section_title (书名、章名、节名)这三个字段:
{
"multi_match": {
"query": "Quick brown fox",
"fields": "*_title"
}
}
提升单个字段的权重
可以使用 ^ 字符语法为单个字段提升权重,在字段名称的末尾添加 ^boost ,其中 boost 是一个浮点数:
{
"multi_match": {
"query": "Quick brown fox",
"fields": [ "*_title", "chapter_title^2" ]
}
}
chapter_title 这个字段的 boost 值为 2 ,而其他两个字段 book_title 和 section_title 字段的默认 boost 值为 1 。
6.3.4 词条查询(term)
term查询被用于精确匹配,这些精确值可能是数字、时间、布尔或者那些未分词的字符串。
GET /sku/_search
{
"query": {
"term": {
"price": 200000
}
}
}
6.3.5 多词条查询(terms)
terms查询和term查询一样,但它允许你指定多值进行匹配。如果这个词段包含了指定中的任何一个值,那么这个文档满足条件(类似于mysql中的in)。
GET /sku/_search
{
"query": {
"terms": {
"price": [200000,100000]
}
}
}
6.3.6 布尔组合(bool)
bool把各种其他查询通过must(与)、must_not(非)、should(或)的方式进行组合。
示例:查询名称包含手机的,并且品牌为小米的记录
GET /sku/_search
{
"query": {
"bool": {
"must": [
{"match": {
"name": "手机"
}},
{
"term": {
"brandName": {
"value": "小米"
}
}
}
]
}
}
}
示例:查询名称包含手机的,或者品牌为小米的记录
GET /sku/_search
{
"query": {
"bool": {
"should": [
{"match": {
"name": "手机"
}},
{
"term": {
"brandName": {
"value": "小米"
}
}
}
]
}
}
}
6.3.7 过滤查询
过滤是针对搜索的结果进行过滤,过滤器主要判断的是文档是否匹配,不去计算和判断文档的匹配度得分,所以过滤器性能比查询要高,且方便缓存,推荐尽量使用过滤器去实现查询或者过滤器和查询共同使用。
示例:过滤品牌为小米的记录
GET /sku/_search
{
"query": {
"bool": {
"filter": [
{"match":{
"brandName":"小米"
}}
]
}
}
}
查询结果(注意_score为0)
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "Ompe7HEBQIJxGG8U13yY",
"_score" : 0.0,
"_source" : {
"name" : "小米手机",
"price" : 200000,
"spuId" : 101,
"createTime" : "2020-05-09",
"brandName" : "小米",
"categoryName" : "手机",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "移动4g",
"屏幕尺寸" : "4.5"
}
}
},
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.0,
"_source" : {
"name" : "小米电视",
"price" : 100000,
"spuId" : 10111,
"createTime" : "2020-05-01",
"brandName" : "小米",
"categoryName" : "电视",
"saleNum" : 10012,
"commentNum" : 323,
"spec" : {
"网络制式" : "全网",
"屏幕尺寸" : "56"
}
}
}
]
}
}
6.3.8 分组查询
示例:按分组名称聚合查询,统计每个分组的数量。类似mysql中的group by
GET /sku/_search
{
"size": 0,
"aggs": {
"sku_category": {
"terms": {
"field": "categoryName"
}
}
}
}
size为0 不会将数据查询出来,目的是让查询更快。查询结果如下:
GET /sku/_search
{
"size": 0,
"aggs": {
"sku_category": {
"terms": {
"field": "categoryName"
}
}
}
}
我们可以同时查询多个分组,如下:
GET /sku/_search
{
"size": 0,
"aggs": {
"sku_category": {
"terms": {
"field": "categoryName"
}
},
"sku_brand": {
"terms": {
"field": "brandName"
}
}
}
}
6.3.9 范围
在 SQL 中,范围查询可以表示为:
SELECT document
FROM products
WHERE price BETWEEN 20 AND 40
Elasticsearch 有 range 查询,不出所料地,可以用它来查找处于某个范围内的文档:
"range" : {
"price" : {
"gte" : 20,
"lte" : 40
}
}
range 查询可同时提供包含(inclusive)和不包含(exclusive)这两种范围表达式,可供组合的选项如下:
- gt: > 大于(greater than)
- lt: < 小于(less than)
- gte: >= 大于或等于(greater than or equal to)
- lte: <= 小于或等于(less than or equal to)
下面是一个范围查询的例子
GET /my_store/products/_search
{
"query" : {
"constant_score" : {
"filter" : {
"range" : {
"price" : {
"gte" : 20,
"lt" : 40
}
}
}
}
}
}
如果想要范围无界(比方说 >20 ),只须省略其中一边的限制:
"range" : {
"price" : {
"gt" : 20
}
}
日期范围
range 查询同样可以应用在日期字段上:
"range" : {
"timestamp" : {
"gt" : "2014-01-01 00:00:00",
"lt" : "2014-01-07 00:00:00"
}
}
当使用它处理日期字段时, range 查询支持对 日期计算(date math) 进行操作,比方说,如果我们想查找时间戳在过去一小时内的所有文档:
"range" : {
"timestamp" : {
"gt" : "now-1h"
}
}
日期计算还可以被应用到某个具体的时间,并非只能是一个像 now 这样的占位符。只要在某个日期后加上一个双管符号 (||) 并紧跟一个日期数学表达式就能做到:
"range" : {
"timestamp" : {
"gt" : "2014-01-01 00:00:00",
"lt" : "2014-01-01 00:00:00||+1M"
}
}
早于 2014 年 1 月 1 日加 1 月(2014 年 2 月 1 日 零时)
6.3.10 处理Null值
参考 处理Null值
存在查询 exists
POST /my_index/posts/_bulk
{ "index": { "_id": "1" }}
{ "tags" : ["search"] }
{ "index": { "_id": "2" }}
{ "tags" : ["search", "open_source"] }
{ "index": { "_id": "3" }}
{ "other_field" : "some data" }
{ "index": { "_id": "4" }}
{ "tags" : null }
{ "index": { "_id": "5" }}
{ "tags" : ["search", null] }
'
1、tags 字段有 1 个值。
2、tags 字段有 2 个值。
3、tags 字段缺失。
4、tags 字段被置为 null 。
5、tags 字段有 1 个值和 1 个 null 。
我们的目标是找到那些被设置过标签字段的文档,并不关心标签的具体内容。只要它存在于文档中即可,用 SQL 的话就是用 IS NOT NULL 非空进行查询:
SELECT tags
FROM posts
WHERE tags IS NOT NULL
在 Elasticsearch 中,使用 exists 查询的方式如下:
GET /my_index/posts/_search
{
"query" : {
"constant_score" : {
"filter" : {
"exists" : { "field" : "tags" }
}
}
}
}
这个查询返回 3 个文档:
"hits" : [
{
"_id" : "1",
"_score" : 1.0,
"_source" : { "tags" : ["search"] }
},
{
"_id" : "5",
"_score" : 1.0,
"_source" : { "tags" : ["search", null] }
},
{
"_id" : "2",
"_score" : 1.0,
"_source" : { "tags" : ["search", "open source"] }
}
]
尽管文档 5 有 null 值,但它仍会被命中返回。字段之所以存在,是因为标签有实际值( search )可以被索引,所以 null 对过滤不会产生任何影响。
显而易见,只要 tags 字段存在项(term)的文档都会命中并作为结果返回,只有 3 和 4 两个文档被排除。
缺失查询 missing
这个 missing 查询本质上与 exists 恰好相反:它返回某个特定 无 值字段的文档,与以下 SQL 表达的意思类似:
SELECT tags
FROM posts
WHERE tags IS NULL
我们将前面例子中 exists 查询换成 missing 查询:
GET /my_index/posts/_search
{
"query" : {
"constant_score" : {
"filter": {
"missing" : { "field" : "tags" }
}
}
}
}
按照期望的那样,我们得到 3 和 4 两个文档(这两个文档的 tags 字段没有实际值):
"hits" : [
{
"_id" : "3",
"_score" : 1.0,
"_source" : { "other_field" : "some data" }
},
{
"_id" : "4",
"_score" : 1.0,
"_source" : { "tags" : null }
}
]
6.3.11 最佳字段 dis_max
参考 最佳字段
假设有个网站允许用户搜索博客的内容,以下面两篇博客内容文档为例:
PUT /my_index/my_type/1
{
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
PUT /my_index/my_type/2
{
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
用户输入词组 “Brown fox” 然后点击搜索按钮。事先,我们并不知道用户的搜索项是会在 title 还是在 body 字段中被找到,但是,用户很有可能是想搜索相关的词组。用肉眼判断,文档 2 的匹配度更高,因为它同时包括要查找的两个词:
现在运行以下 bool 查询:
{
"query": {
"bool": {
"should": [
{ "match": { "title": "Brown fox" }},
{ "match": { "body": "Brown fox" }}
]
}
}
}
但是我们发现查询的结果是文档 1 的评分更高:
{
"hits": [
{
"_id": "1",
"_score": 0.14809652,
"_source": {
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
},
{
"_id": "2",
"_score": 0.09256032,
"_source": {
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
}
]
}
为了理解导致这样的原因,需要回想一下 bool 是如何计算评分的:
1、它会执行 should 语句中的两个查询。
2、加和两个查询的评分。
3、乘以匹配语句的总数。
4、除以所有语句总数(这里为:2)。
文档 1 的两个字段都包含 brown 这个词,所以两个 match 语句都能成功匹配并且有一个评分。文档 2 的 body 字段同时包含 brown 和 fox 这两个词,但 title 字段没有包含任何词。这样, body 查询结果中的高分,加上 title 查询中的 0 分,然后乘以二分之一,就得到比文档 1 更低的整体评分。
在本例中, title 和 body 字段是相互竞争的关系,所以就需要找到单个 最佳匹配 的字段。
如果不是简单将每个字段的评分结果加在一起,而是将 最佳匹配 字段的评分作为查询的整体评分,结果会怎样?这样返回的结果可能是: 同时 包含 brown 和 fox 的单个字段比反复出现相同词语的多个不同字段有更高的相关度。
dis_max 查询
不使用 bool 查询,可以使用 dis_max 即分离 最大化查询(Disjunction Max Query) 。分离(Disjunction)的意思是 或(or) ,这与可以把结合(conjunction)理解成 与(and) 相对应。分离最大化查询(Disjunction Max Query)指的是: 将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回 :
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Brown fox" }},
{ "match": { "body": "Brown fox" }}
]
}
}
}
得到我们想要的结果为:
{
"hits": [
{
"_id": "2",
"_score": 0.21509302,
"_source": {
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
},
{
"_id": "1",
"_score": 0.12713557,
"_source": {
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
}
]
}
最佳字段调优
当用户搜索 “quick pets” 时会发生什么呢?在前面的例子中,两个文档都包含词 quick ,但是只有文档 2 包含词 pets ,两个文档中都不具有同时包含 两个词 的 相同字段 。如下,一个简单的 dis_max 查询会采用单个最佳匹配字段,而忽略其他的匹配:
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Quick pets" }},
{ "match": { "body": "Quick pets" }}
]
}
}
}
{
"hits": [
{
"_id": "1",
"_score": 0.12713557,
"_source": {
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
},
{
"_id": "2",
"_score": 0.12713557,
"_source": {
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
}
]
}
注意两个评分是完全相同的。
我们可能期望同时匹配 title 和 body 字段的文档比只与一个字段匹配的文档的相关度更高,但事实并非如此,因为 dis_max 查询只会简单地使用 单个 最佳匹配语句的评分 _score 作为整体评分。
tie_breaker参数
可以通过指定 tie_breaker 这个参数将其他匹配语句的评分也考虑其中:
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Quick pets" }},
{ "match": { "body": "Quick pets" }}
],
"tie_breaker": 0.3
}
}
}
结果:文档 2 的相关度比文档 1 略高。
tie_breaker 参数提供了一种 dis_max 和 bool 之间的折中选择,它的评分方式如下:
- 获得最佳匹配语句的评分 _score 。
- 将其他匹配语句的评分结果与 tie_breaker 相乘。
- 对以上评分求和并规范化。
tie_breaker 可以是 0 到 1 之间的浮点数,其中 0 代表使用 dis_max 最佳匹配语句的普通逻辑, 1 表示所有匹配语句同等重要。最佳的精确值需要根据数据与查询调试得出,但是合理值应该与零接近(处于 0.1 - 0.4 之间),这样就不会颠覆 dis_max 最佳匹配性质的根本。
七、JavaRest高级客户端
7.1 JavaRest高级客户端简介
Elasticsearch 存在三种Java客户端
1、Transport Client
2、Java Low Level Rest Client (低级rest客户端)
3、Java High Level Rest Client (高级rest客户端)
这三者的区别是:
1、Transport Client 没有使用RESTful风格的接口,而是二进制的方式传输数据。
2、Elasticsearch 官方推出了Java Low Level Rest Client,它支持RESTful。但是缺点是Transport Client的使用者把代码迁移到Java Low Level Rest Client的工作量比较大。
3、Elasticsearch 官方推出Java High Level Rest Client ,它是基于Java Low Level Rest Client的封装,并且API接收参数和返回值和Transport Client是一样的,使得代码迁移变得容易并且支持了RESTful的风格,兼容了这两种客户端的优点。强烈建议ES 5 及其以后的版本使用Java High Level Rest Client。
7.2 正式使用Java High Level Rest Client
准备工作,新建工程,引入依赖
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.6.2
7.3 新增和修改数据
7.3.1 插入单条数据
HttpHost:url地址封装
RestClientBuilder:rest客户端构建器
RestHighLevelClient:rest高级客户端
IndexRequest:新增或修改请求
IndexResponse:新增或修改的响应结果
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
/**
* @description 新增/修改 数据
*/
public class Client {
public static void main(String[] args) throws IOException {
// 1、连接rest接口
HttpHost http = new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder restClientBuilder = RestClient.builder(http);
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 2、封装请求对象
//如果id不存在则是新增,如果存在则是修改
IndexRequest indexRequest = new IndexRequest("sku").id("1000");
Map skuMap = new HashMap();
skuMap.put("name","华为P30 Pro 新增");
skuMap.put("brandName","华为");
skuMap.put("categoryName","手机");
skuMap.put("price",1010222);
skuMap.put("createTime","2019-05-01");
skuMap.put("saleNum",101022);
skuMap.put("commentNum",1010223);
Map spec = new HashMap();
spec.put("网络制式","移动4G");
spec.put("屏幕尺寸","5");
skuMap.put("spec",spec);
indexRequest.source(skuMap);
// 3、获取执行结果
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
int status = indexResponse.status().getStatus();
System.out.println(status);
restHighLevelClient.close();
}
}
如果id不存在则是新增,如果存在则是修改。
新增时控制台打印的status 为201,修改status 为200,在Kibana查询我们刚才插入的数据,显示结果如下:

数据查询
7.3.2 批处理请求
BulkRequest:批量请求(用于增删改操作)
BulkResponse:批量响应(用于增删改操作)
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
/**
* @description 批处理请求
*/
public class Client2 {
public static void main(String[] args) throws IOException {
// 1、连接rest接口
HttpHost http = new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder restClientBuilder = RestClient.builder(http);
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 2、封装请求对象
BulkRequest bulkRequest = new BulkRequest();
IndexRequest indexRequest = new IndexRequest("sku").id("1001");
Map skuMap = new HashMap();
skuMap.put("name","华为Mete20 Pro");
skuMap.put("brandName","华为");
skuMap.put("categoryName","手机");
skuMap.put("price",1010222);
skuMap.put("createTime","2019-05-01");
skuMap.put("saleNum",101022);
skuMap.put("commentNum",1010223);
Map spec = new HashMap();
spec.put("网络制式","移动4G");
spec.put("屏幕尺寸","5");
skuMap.put("spec",spec);
indexRequest.source(skuMap);
bulkRequest.add(indexRequest);
// 3、获取执行结果
// IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
int status = bulkResponse.status().getStatus();
System.out.println(status);
restHighLevelClient.close();
}
}
7.4 匹配查询
SearchRequest:查询请求对象
SearchResponse:查询响应对象
SearchSourceBuilder:查询源构造器
MatchQueryBuilder:匹配查询构建器
示例:查询商品名称包含手机的记录
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.io.IOException;
/**
* @description 匹配查询
*/
public class Client3 {
public static void main(String[] args) throws IOException {
// 1、连接rest接口
HttpHost http = new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder restClientBuilder = RestClient.builder(http);
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 2、封装请求对象
/**
* GET /sku/_search
* {
* "query": {
* "match": {
* "name": "手机"
* }
* }
* }
*/
SearchRequest searchRequest = new SearchRequest("sku");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name","手机");
searchSourceBuilder.query(matchQueryBuilder);
searchRequest.source(searchSourceBuilder);
// 3、获取执行结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
long totalHits = searchHits.getTotalHits().value;
System.out.println("记录数:"+totalHits);
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
restHighLevelClient.close();
}
}
查询结果如下:
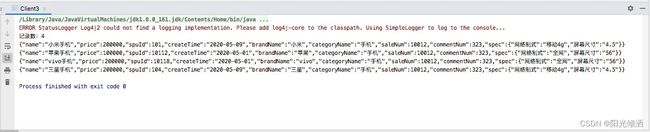
匹配查询结果
7.5 布尔与词条查询
BoolQueryBuilder:布尔查询构建器
TermQueryBuilder:词条查询构建器
QueryBuilders:查询构建器工厂
示例:查询名称包含手机,并且品牌为小米的记录
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.io.IOException;
/**
* @description 布尔与词条查询
*/
public class Client4 {
public static void main(String[] args) throws IOException {
// 1、连接rest接口
HttpHost http = new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder restClientBuilder = RestClient.builder(http);
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 2、封装请求对象
/**
* GET /sku/_search
* {
* "query": {
* "bool": {
* "must": [
* {"match": {
* "name": "手机"
* }},
* {
* "term": {
* "brandName": {
* "value": "小米"
* }
* }
* }
* ]
* }
* }
* }
*/
SearchRequest searchRequest = new SearchRequest("sku");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name","手机");
boolQueryBuilder.must(matchQueryBuilder);
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("brandName","小米");
boolQueryBuilder.must(termQueryBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
// 3、获取执行结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
long totalHits = searchHits.getTotalHits().value;
System.out.println("记录数:"+totalHits);
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
restHighLevelClient.close();
}
}
查询结果:
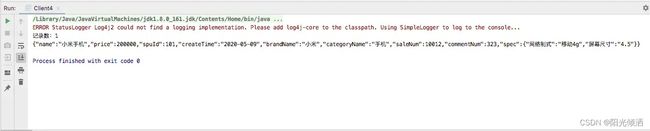
7.6 过滤查询
示例:筛选品牌为小米的记录
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.io.IOException;
/**
* @description 过滤查询
*/
public class Client5 {
public static void main(String[] args) throws IOException {
// 1、连接rest接口
HttpHost http = new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder restClientBuilder = RestClient.builder(http);
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 2、封装请求对象
/**
* GET /sku/_search
* {
* "query": {
* "bool": {
* "filter": [
* {"match":{
* "brandName":"小米"
* }}
* ]
* }
* }
* }
*/
SearchRequest searchRequest = new SearchRequest("sku");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("brandName","小米");
boolQueryBuilder.filter(termQueryBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
// 3、获取执行结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
long totalHits = searchHits.getTotalHits().value;
System.out.println("记录数:"+totalHits);
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
restHighLevelClient.close();
}
}
查询结果:

7.7 分组(聚合)查询
AggregationBuilders:聚合构建器工厂
TermsAggregationBuilder:词条聚合构建器
Aggregations:分组结果封装
Terms.Bucket:桶
示例:按商品分类分组查询,求出每个分类的文档数
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.search.aggregations.Aggregation;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.io.IOException;
import java.util.List;
import java.util.Map;
/**
* @description 分组(聚合)查询
*/
public class Client6 {
public static void main(String[] args) throws IOException {
// 1、连接rest接口
HttpHost http = new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder restClientBuilder = RestClient.builder(http);
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
// 2、封装请求对象
/**
* GET /sku/_search
* {
* "size": 0,
* "aggs": {
* "sku_category": {
* "terms": {
* "field": "categoryName"
* }
* }
* }
* }
*/
SearchRequest searchRequest = new SearchRequest("sku");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("sku_category").field("categoryName");
searchSourceBuilder.aggregation(termsAggregationBuilder);
searchSourceBuilder.size(0);
searchRequest.source(searchSourceBuilder);
// 3、获取执行结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
Map aggregationMap = aggregations.getAsMap();
Terms terms = (Terms) aggregationMap.get("sku_category");
List buckets = terms.getBuckets();
for(Terms.Bucket bucket : buckets){
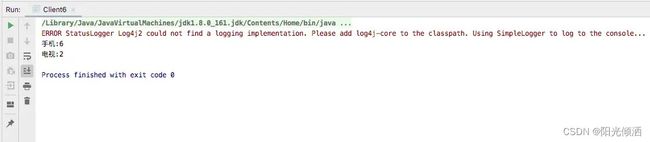
System.out.println(bucket.getKeyAsString()+":"+bucket.getDocCount());
}
restHighLevelClient.close();
}
}
查询结果:
八、ES文档 & 驱动
https://www.elastic.co/cn/downloads/past-releases/jdbc-client-7-6-2
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html