epoll的底层实现原理
一、内核从网卡接收网络数据的处理过程:
计算机由CPU、内存、网卡等设备硬件设备组成。
计算机接收网络数据的处理过程是:
- 网卡收到网线传来的数据,经过DMA传输、IO通路选择等处理后,将收到的数据写入内存;
- 网卡将接收到的网络数据写入内存后,网卡向CPU发出一个中断信号,CPU能够捕获这个信号,然后执行相应的中断处理程序(对应IRQ请求的处理程序);
此时的中断程序主要有两项功能:
① 先将网络数据写入到对应socket的接收缓冲区中;
② 唤醒此socket阻塞队列上的进程,将其重新放入到工作队列中;
1.1 硬中断、软中断、信号的区别:
硬中断:
外部设备(磁盘、网卡、键盘等)对CPU的中断;
软中断:
中断服务程序对内核的中断;
软中断是Linux中断机制的“下半部分”(bottom-half),在软件上模拟硬件中断,达到异步调用下半部分服务函数的功能。
信号:
内核(或其他进程)对某个进程的中断。
软件上模拟硬件中断,中断某个用户进程的运行,转而去处理相应的“中断”。这一系列动作包含:
信号产生—>信号响应—>信号处理—>信号返回。
1.2 socket对象上的等待队列:
当进程创建一个socket套接字时,操作系统会相应的创建出一个由文件系统管理的socket对象,这个socket对象中包含:
发送缓冲区、接收缓冲区、等待队列、 等成员。
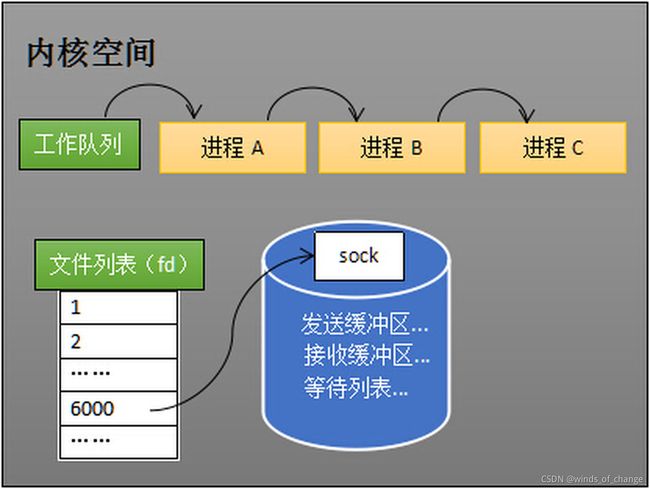
其中,等待队列是非常重要的成员。
操作系统会将调动recv阻塞的进程挂在对应socket的等待队列中(只是进程的引用,不是进程本身),此时进程进入阻塞态,不会占用CPU资源。
当socket上收到数据后,操作系统会将该socket从等待队列中重新放回到工作队列,继续执行。
1.3 操作系统如何知道网卡上收到的数据属于哪个socket:
每个socket对应的是一个网络连接(TCP或UDP),即一个socket对应一组IP地址和端口号,而网络数据中包含了IP地址和端口号信息,操作系统会维护端口号到socket的索引结构,根据收到的网络数据中的端口号信息就可以快速找到对应的socket套接字。
二、如何同时监视多个socket的数据:
2.1 单进程单socket的弊端:
服务端需要管理多个客户端连接,而 recv() 系统调用只能监视单个socket。
这种情况下,如果要管理多个客户端连接,就需要多开进程或线程,每个进程维护一个socket套接字,没有网络数据时进程阻塞在recv()系统调用上,当网络数据到达时,操作系统环境对应socket等待队列上的进程。
此时面临的问题是维护进程或线程带来的系统开销(每个线程的栈空间8M,由于系统的内存资源有限,1K个线程就已经需要消耗8G内存,不可能无限制的多开线程,且进程、线程间的频繁切换也会带来较大的开销)。
2.2 select的设计思想:
这种矛盾下,人们开始寻找监视多个socket的方法。
最先想到的办法是使用一个进程监视多个socket,预先传入一个socket列表,如果列表中的socket都没有数据,则进程继续挂起;直到有一个或以上的socket接收到网络数据,再唤醒进程。
这种方法很直接,这也是select的设计思想。
2.2.1 select的执行流程是:
如下图,假设进程A同时监听 sock1、sock2、sock3(通过fd_set传入),那么,在调用select之后,操作系统会把进程A分别加入到这三个socket的等待队列中: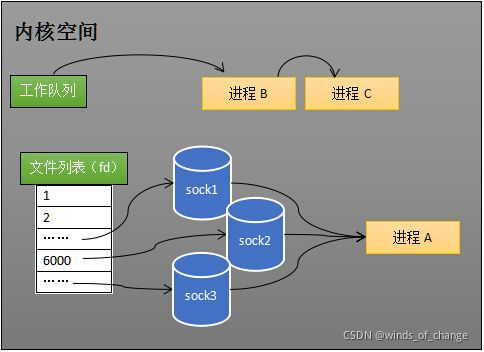
当任何一个socket上收到数据时,中断程序将唤起进程。
所谓唤起进程,就是将其从所有的socket对象的等待队列中移除,并插入到就绪队列中。
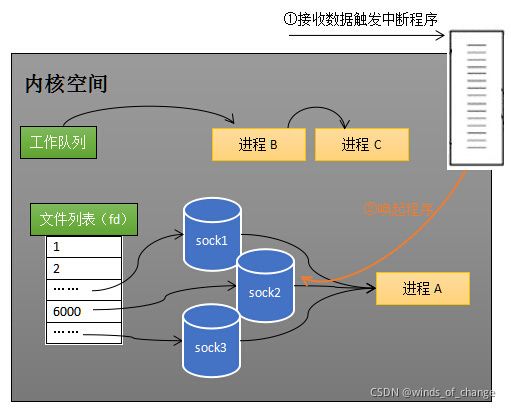
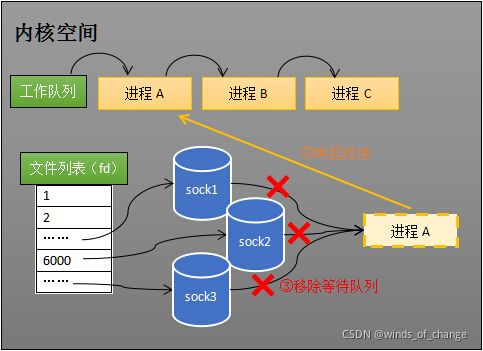
经过这两步之后,当进程A被唤醒时,它知道它所检测的socket列表中至少有个socket已经接收到数据了。此时程序遍历一遍socket列表,就可以得到就绪的socket。
2.2.2 select的缺点是:
- 每次调用select都需要将进程加入到所有socket对象的等待队列中,每次唤醒进程又要将进程从所有socket对象的等待队列中移除。这里涉及到对socket列表的两次遍历,而且每次都要将整个fds列表传递给内核,有一定的开销。正因为遍历操作开销大,出于效率的考量,才会规定select的最大监视数量,默认只能监视1024个socket(强行修改也是可以的);
- 进程被唤醒后,程序并不知道socket列表中的那些socket上收到数据,因此在用户空间内需要对socket列表再做一次遍历。
2.3 epoll的设计思想:
2.3.1 epoll的实现原理和流程:
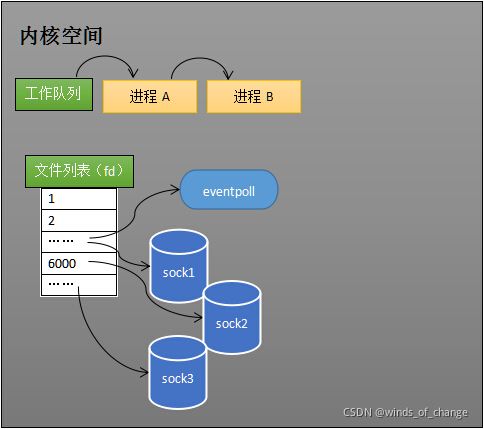
1. 创建epoll对象:
当进程调用 epoll_create 方法时,内核会创建一个 eventpoll 对象,也就是应用程序中的 epfd 所代表的对象。
eventpoll 对象也是文件系统中的一员(Linux中一切设备皆文件),和socket一样也拥有一个“等待队列”。
内核创建eventpoll对象:
2. 维护监视列表:
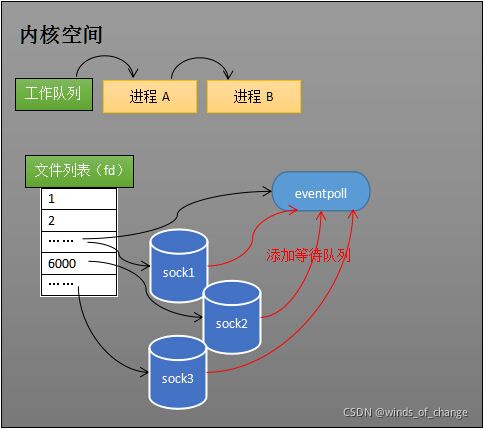
创建epoll对象 eventpoll 之后,可以使用 epoll_ctl 添加或者删除所要监听的socket。
以添加socket为例,如果要对sock1、sock2、sock3进行监视,内核会将eventpoll添加到这三个socket的等待队列中。
当socket收到数据后,中断回调程序会操作eventpoll对象,而不是直接操作进程。
3. 接收数据:
select的低效原因之一在于应用程序不知道哪些socket收到数据,只能一个个的遍历。如果内核维护一个“就绪列表”,在就绪列表中引用收到数据的socket,就能避免遍历。
在 eventpoll 对象中就实现了这样的一个“就绪列表” ---- rdlist。
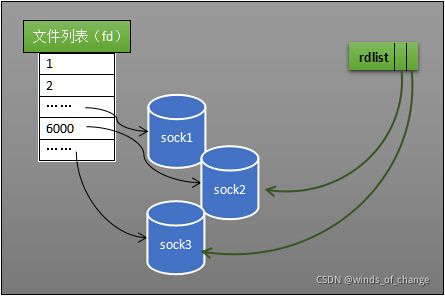
当socket收到数据,中断回调程序会给eventpoll的“就绪列表”添加socket的引用,如下图所示:

eventpoll对象相当于是socket和进程之间的中介,socket的数据接收并不直接影响进程,而是通过改变eventpoll的就绪列表来改变进程状态。
epoll_wait的返回条件也是根据rdlist的状态进行判断:
如果rdlist已经引用了socket,那么epoll_wait直接返回;
如果rdlist为空,阻塞进程。
4. 阻塞和唤醒进程:
如下图,假设当进程A运行到epoll_wait()时,操作系统会将进程A放入到eventpoll对象的等待队列中,阻塞进程。
(对于epoll,操作系统只需要将进程A放入eventpoll这一个对象的等待队列中;而对于select,操作系统则需要将进程A放入到socket列表中的所有socket对象的等待队列中。)
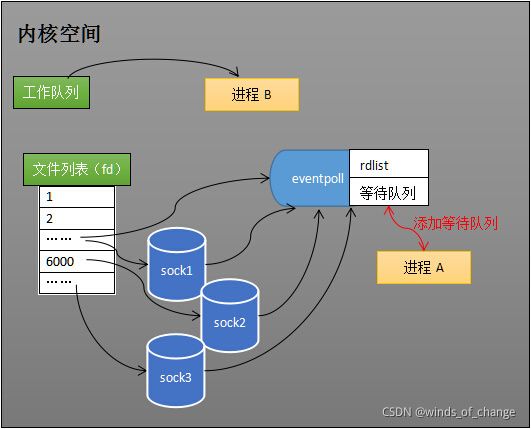
当socket接收到数据时,中断回调程序一方面修改rdlist“就绪列表”,另一方面唤醒eventpoll等待队列中的进程A。
也因为rdlist就绪列表的存在,进程A可以在重新进入运行态后准确知道哪些socket上发生了变化。

2.3.2 epoll高效的原因:
相较于select,epoll实现高效主要基于以下两点:
- 功能分离;
- 就绪列表。
select低效的原因之一是将“维护等待队列”和“阻塞进程”两个步骤合二为一。
每次调用select都需要这两步操作,然而大多数应用场景中,需要监视的socket相对固定,并不需要每次修改。
epoll将这两个操作分开,先用 epoll_ctl 维护等待队列,再调用 epoll_wait 阻塞进程,以此来提高效率。
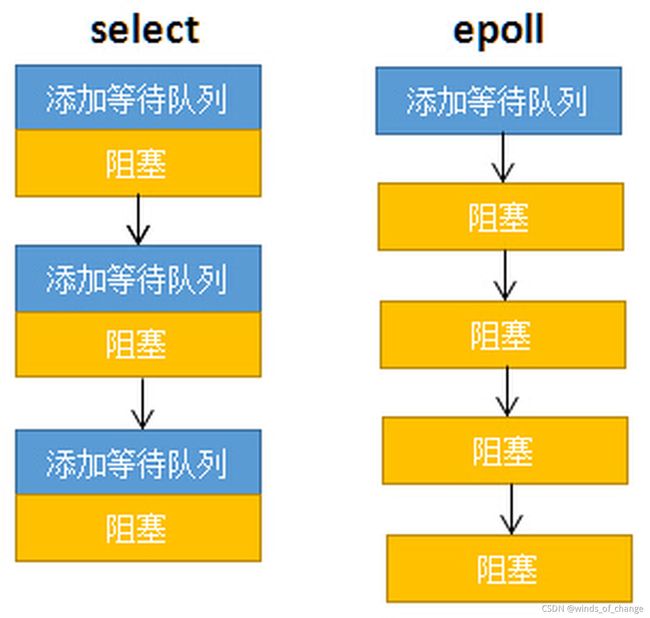
select低效的另一个原因在于程序不知道哪些socket收到数据,只能一个一个的遍历。如果内核维护一个“就绪列表”,引用收到的数据的socket,就能避免遍历。
2.3.3 epoll的实现细节:
1. eventpoll对象的数据结构:
eventpoll对象包含了:lock、mtx、wq(等待队列)、rdlist 等成员。
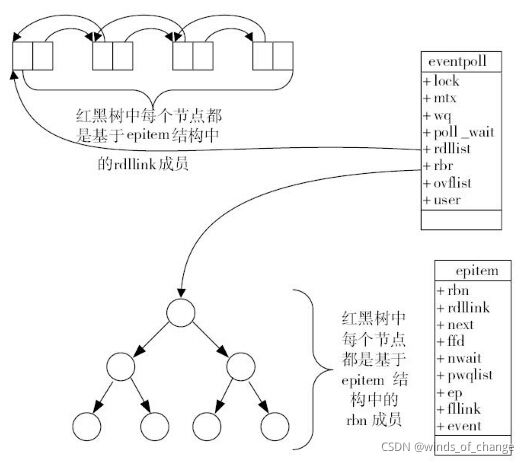
2. rdlist就绪队列的数据结构:
epoll使用双向链表来实现就绪队列rdlist。
3. 索引结构:
epoll使用红黑树作为索引结构,以便于快速的插入和删除要监视的socket套接字。
红黑树时一种自平衡的二叉查找树,搜索、插入、删除的时间复杂度都是O(logN)。
参考内容:
添加链接描述