C++11并发与多线程
C++11并发与多线程
1. 线程是进程中的实际运作单位
-
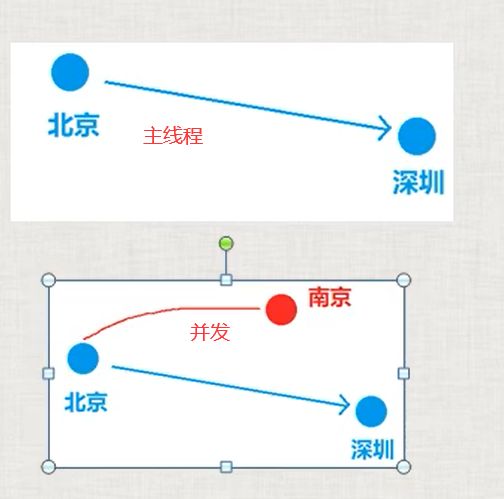
并发:两个或者更多的任务(独立的活动)同时发生(进行):一个程序同时执行多个独立的任务
-
进程:一个可执行程序运行起来了,就叫创建了一个进程。进程就是运行起来的可执行程序
-
线程:进程中的实际运作单位

2. 线程
创建线程
#include
#include // ①
using namespace std; // ②
void hello() { // ③
cout << "Hello World from new thread." << endl;
}
int main() {
thread t(hello); // ④
t.join(); // ⑤
return 0;
}
对于这段代码说明如下:
- 为了使用多线程的接口,我们需要
#include头文件。 - 为了简化声明,本文中的代码都将
using namespace std;。 - 新建线程的入口是一个普通的函数,它并没有什么特别的地方。
- 创建线程的方式就是构造一个
thread对象,并指定入口函数。与普通对象不一样的是,此时编译器便会为我们创建一个新的操作系统线程,并在新的线程中执行我们的入口函数。 - 关于
join函数在下文中讲解。
在linux下编译
g++ 01_hello_thread.cpp -o 01test -pthread
传递参数给入口函数
#include
#include
#include
using namespace std;
void hello(string name){
cout<<"Welcome to "< join和detach
| API | 说明 |
|---|---|
| join | 等待线程完成其执行 |
| detach | 允许线程独立执行 |
-
join:调用此接口时,当前线程会一直阻塞,直到目标线程执行完成。 -
detach:detach是让目标线程成为守护线程(daemon threads)。一旦detach之后,目标线程将独立执行,即便其对应的thread对象销毁也不影响线程的执行。
如果在thread对象销毁的时候我们还没有做决定,则thread对象在析构函数出将调用std::terminate()从而导致我们的进程异常退出。
通过joinable()接口查询是否可以对它们进行join或者detach。
管理当前线程
| API | C++标准 | 说明 |
|---|---|---|
| yield | C++11 | 让出处理器,重新调度各执行线程 |
| get_id | C++11 | 返回当前线程的线程 id |
| sleep_for | C++11 | 使当前线程的执行停止指定的时间段 |
| sleep_until | C++11 | 使当前线程的执行停止直到指定的时间点 |
#include
#include
#include
#include
#include
#include
using namespace std;
void print_time(){
auto now = chrono::system_clock::now();
auto in_time_t = chrono::system_clock::to_time_t(now);
std::stringstream ss;
ss<< put_time(localtime(&in_time_t),"%Y-%m-%d %X");
cout<< "now is: "< 这段代码使用了C++的标准库chrono、ctime、iomanip、iostream、sstream和thread。
函数print_time用于获取当前的系统时间,并以特定的格式打印出来。它使用了C++的chrono库来获取当前时间,并使用localtime函数将时间转换为本地时间,然后使用put_time函数将时间以指定的格式进行格式化输出。
函数sleep_thread用于使当前线程休眠3秒,并在休眠结束后输出一条消息表明线程已经唤醒。它使用了C++的thread库中的sleep_for函数来使当前线程休眠。this_thread::get_id()函数可以获取当前线程的ID。
函数loop_thread用于打印从0到9的整数,并输出打印的线程ID。它在一个循环中打印数值,每次打印后会自动进行下一次迭代。
在main函数中,首先调用print_time函数打印当前时间。然后创建了两个线程t1和t2,分别执行sleep_thread和loop_thread函数。线程t1会调用sleep_thread函数休眠3秒,而线程t2会在循环中执行loop_thread函数。使用t1.join()语句可以等待线程t1执行完毕,而t2.detach()语句则将线程t2与主线程分离,使得线程t2在后台执行而不会影响主线程的运行。最后再次调用print_time函数打印当前时间,并返回0表示程序正常结束。
now is: 2023-09-21 19:22:24
[thread-140221292599040] print: 0
[thread-140221292599040] print: 1
[thread-140221292599040] print: 2
[thread-140221292599040] print: 3
[thread-140221292599040] print: 4
[thread-140221292599040] print: 5
[thread-140221292599040] print: 6
[thread-140221292599040] print: 7
[thread-140221292599040] print: 8
[thread-140221292599040] print: 9
[thread-140221300991744] is waking up
now is: 2023-09-21 19:22:27
一次调用
| API | C++标准 | 说明 |
|---|---|---|
| call_once | C++11 | 即便在多线程环境下,也能保证只调用某个函数一次 |
| once_flag | C++11 | 与call_once配合使用 |
有些任务需要执行一次,并且我们只希望它执行一次,例如资源的初始化任务。
#include
#include
#include
using namespace std;
void init(){
cout<< "Initialing..."< Initialing...
无法确定具体是哪一个线程会执行init
3. 并发
#include
#include
#include
#include
#include
using namespace std;
static const int MAX = 10e8;
static double sum = 0;
void worker(int min,int max){
for(int i = min; i<=max; i++){
sum += sqrt(i);
}
}
void serial_task(int min,int max){
auto start_time = chrono::steady_clock::now();
sum = 0;
worker(0,MAX);
auto end_time = chrono::steady_clock::now();
auto ms = chrono::duration_cast(end_time-start_time).count();
cout << "Serail task finish, " << ms << " ms consumed, Result: " << sum << endl;
}
void concurrent_task(int min, int max){
auto start_time = chrono::steady_clock::now();
unsigned concurrent_count = thread::hardware_concurrency();
cout << "hardware_concurrency: " << concurrent_count << endl;
vector threads;
min = 0;
sum = 0;
for(int t = 0; t < concurrent_count; t++){
int range = max / concurrent_count * (t + 1);
threads.push_back(thread(worker,min,range));
min = range + 1;
}
for(int i = 0; i < threads.size(); i++){
threads[i].join();
}
auto end_time = chrono::steady_clock::now();
auto ms = chrono::duration_cast(end_time-start_time).count();
cout << "Concurrent task finish, " << ms << " ms consumed, Result: " << sum << endl;
}
int main(){
serial_task(0, MAX);
concurrent_task(0, MAX);
return 0;
}
定义了一个串行任务函数serial_task,它接受两个参数min和max。在这个函数中,首先记录任务开始的时间,然后将sum重置为0,接着调用worker函数来进行计算,计算的范围是从0到MAX。接着记录任务结束的时间,计算任务执行时间,并输出计算结果。
接着定义了一个并行任务函数concurrent_task,它也接受两个参数min和max。在这个函数中,首先记录任务开始的时间,然后通过thread::hardware_concurrency()函数获取系统的并发线程数,并输出到控制台。接着定义一个线程数组threads,并用循环创建多个线程来执行worker函数,每个线程计算一个范围内的数的平方根并累加到sum变量中。最后,等待所有线程执行完毕,记录任务结束的时间,计算任务执行时间,并输出计算结果。
Serail task finish, 6655 ms consumed, Result: 2.10819e+13
hardware_concurrency: 8
Concurrent task finish, 5232 ms consumed, Result: 2.88206e+12
#在这里并行的速度并没有比串行快多少,而且计算的结果还是错的
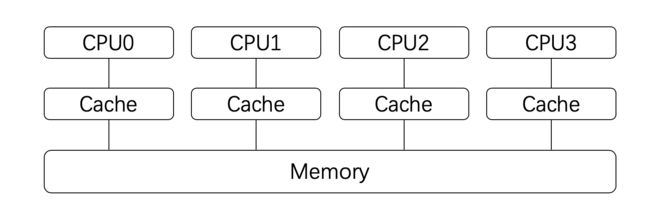
处理器在进行计算的时候,高速缓存会参与其中,例如数据的读和写。而高速缓存和系统主存(Memory)是有可能存在不一致的。即:某个结果计算后保存在处理器的高速缓存中了,但是没有同步到主存中,此时这个值对于其他处理器就是不可见的。
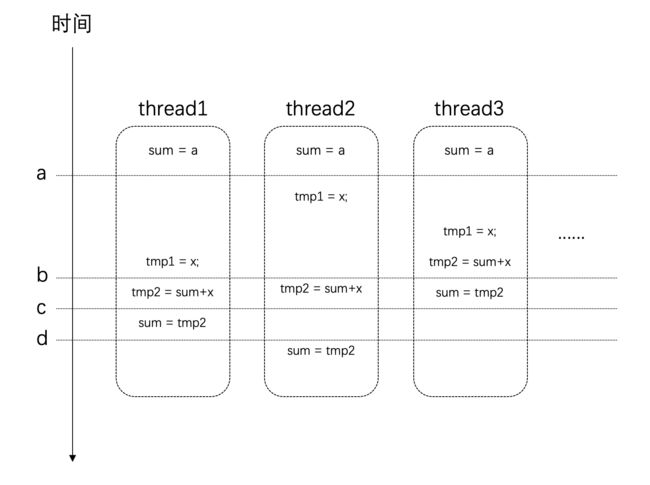
事情还远不止这么简单。我们对于全局变量值的修改:sum += sqrt(i);这条语句,它并非是原子的。它其实是很多条指令的组合才能完成。假设在某个设备上,这条语句通过下面这几个步骤来完成。它们的时序可能如下所示:
竞争条件与临界区
当多个进程或者线程同时访问共享数据时,只要有一个任务会修改数据,那么就可能会发生问题。此时结果依赖于这些任务执行的相对时间,这种场景称为竞争条件(race condition)。
访问共享数据的代码片段称之为临界区(critical section)。具体到上面这个示例,临界区就是读写sum变量的地方。
4. 互斥和锁
mutex
开发并发系统的目的主要是为了提升性能:将任务分散到多个线程,然后在不同的处理器上同时执行。这些分散开来的线程通常会包含两类任务:
- 独立的对于划分给自己的数据的处理
- 对于处理结果的汇总
其中第1项任务因为每个线程是独立的,不存在竞争条件的问题。而第2项任务,由于所有线程都可能往总结果(例如上面的sum变量)汇总,这就需要做保护了。在某一个具体的时刻,只应当有一个线程更新总结果,即:保证每个线程对于共享数据的访问是“互斥”的。mutex 就提供了这样的功能。
| API | C++标准 | 说明 |
|---|---|---|
| mutex | C++11 | 提供基本互斥设施 |
| timed_mutex | C++11 | 提供互斥设施,带有超时功能 |
| recursive_mutex | C++11 | 提供能被同一线程递归锁定的互斥设施 |
| recursive_timed_mutex | C++11 | 提供能被同一线程递归锁定的互斥设施,带有超时功能 |
| shared_timed_mutex | C++14 | 提供共享互斥设施并带有超时功能 |
| shared_mutex | C++17 | 提供共享互斥设施 |
| 方法 | 说明 |
|---|---|
| lock | 锁定互斥体,如果不可用,则阻塞 |
| try_lock | 尝试锁定互斥体,如果不可用,直接返回 |
| unlock | 解锁互斥体 |
这三个方法提供了基础的锁定和解除锁定的功能。使用lock意味着有很强的意愿一定要获取到互斥体,而使用try_lock则是进行一次尝试。这意味着如果失败了,你通常还有其他的路径可以走。
在这些基础功能之上,其他的类分别在下面三个方面进行了扩展:
- 超时:
timed_mutex,recursive_timed_mutex,shared_timed_mutex的名称都带有timed,这意味着它们都支持超时功能。它们都提供了try_lock_for和try_lock_until方法,这两个方法分别可以指定超时的时间长度和时间点。如果在超时的时间范围内没有能获取到锁,则直接返回,不再继续等待。 - 可重入:
recursive_mutex和recursive_timed_mutex的名称都带有recursive。可重入或者叫做可递归,是指在同一个线程中,同一把锁可以锁定多次。这就避免了一些不必要的死锁。 - 共享:
shared_timed_mutex和shared_mutex提供了共享功能。对于这类互斥体,实际上是提供了两把锁:一把是共享锁,一把是互斥锁。一旦某个线程获取了互斥锁,任何其他线程都无法再获取互斥锁和共享锁;但是如果有某个线程获取到了共享锁,其他线程无法再获取到互斥锁,但是还有获取到共享锁。这里互斥锁的使用和其他的互斥体接口和功能一样。而共享锁可以同时被多个线程同时获取到(使用共享锁的接口见下面的表格)。共享锁通常用在读者写者模型上。
使用共享锁的接口如下:
| 方法 | 说明 |
|---|---|
| lock_shared | 获取互斥体的共享锁,如果无法获取则阻塞 |
| try_lock_shared | 尝试获取共享锁,如果不可用,直接返回 |
| unlock_shared | 解锁共享锁 |
- 在访问共享数据之前加锁
- 访问完成之后解锁
- 在多线程中使用带锁的版本
#include
#include
#include
#include
#include
#include
using namespace std;
static const int MAX = 10e8;
static double sum = 0;
static mutex exclusive;
void concurrent_worker(int min, int max) {
for (int i = min; i <= max; i++) {
exclusive.lock();
sum += sqrt(i);
exclusive.unlock();
}
}
void worker(int min, int max) {
for (int i = min; i <= max; i++) {
double sqrt_i = sqrt(i);
// 使用互斥锁保护对 sum 的访问
lock_guard lock(sum_mutex);
sum += sqrt_i;
}
}
void concurrent_task(int min, int max) {
auto start_time = chrono::steady_clock::now();
unsigned concurrent_count = thread::hardware_concurrency();
cout << "hardware_concurrency: " << concurrent_count << endl;
vector threads;
min = 0;
sum = 0;
for (int t = 0; t < concurrent_count; t++) {
int range = max / concurrent_count * (t + 1);
threads.push_back(thread(concurrent_worker, min, range));
min = range + 1;
}
for (int i = 0; i < threads.size(); i++) {
threads[i].join();
}
auto end_time = chrono::steady_clock::now();
auto ms = chrono::duration_cast(end_time - start_time).count();
cout << "Concurrent task finish, " << ms << " ms consumed, Result: " << sum << endl;
}
int main() {
concurrent_task(0, MAX);
return 0;
}
Serail task finish, 26665 ms consumed, Result: 2.10819e+13
(1)
hardware_concurrency: 8
Concurrent task finish, 156722 ms consumed, Result: 2.10819e+13
(2)
hardware_concurrency: 8
Concurrent task finish, 167880 ms consumed, Result: 2.10819e+13
结果是对了,但是我们却发现这个版本比原先单线程的版本性能还要差很多。这是因为加锁和解锁是有代价的,这里计算最耗时的地方在锁里面,每次只能有一个线程串行执行,相比于单线程模型,它不但是串行的,还增加了锁的负担,因此就更慢了。
于是我们改造concurrent_worker,像下面这样:
// 08_improved_mutex_lock.cpp
void concurrent_worker(int min, int max) {
double tmp_sum = 0;
for (int i = min; i <= max; i++) {
tmp_sum += sqrt(i); // ①
}
exclusive.lock(); // ②
sum += tmp_sum;
exclusive.unlock();
}
这段代码的改变在于两处:
- 通过一个局部变量保存当前线程的处理结果
- 在汇总总结过的时候进行锁保护
hardware_concurrency: 8
Concurrent task finish, 1304 ms consumed, Result: 2.10819e+13
用锁的粒度(granularity)来描述锁的范围。细粒度(fine-grained)是指锁保护较小的范围,粗粒度(coarse-grained)是指锁保护较大的范围。出于性能的考虑,我们应该保证锁的粒度尽可能的细。并且,不应该在获取锁的范围内执行耗时的操作,例如执行IO。如果是耗时的运算,也应该尽可能的移到锁的外面。
死锁
#include
#include
#include
#include
using namespace std;
class Account {
public:
Account(string name, double money): mName(name), mMoney(money) {};
public:
void changeMoney(double amount) {
mMoney += amount;
}
string getName() {
return mName;
}
double getMoney() {
return mMoney;
}
mutex* getLock() {
return &mMoneyLock;
}
private:
string mName;
double mMoney;
mutex mMoneyLock;
};
class Bank {
public:
void addAccount(Account* account) {
mAccounts.insert(account);
}
bool transferMoney(Account* accountA, Account* accountB, double amount) {
lock_guard guardA(*accountA->getLock());
lock_guard guardB(*accountB->getLock());
if (amount > accountA->getMoney()) {
return false;
}
accountA->changeMoney(-amount);
accountB->changeMoney(amount);
return true;
}
double totalMoney() const {
double sum = 0;
for (auto a : mAccounts) {
sum += a->getMoney();
}
return sum;
}
private:
set mAccounts;
};
void randomTransfer(Bank* bank, Account* accountA, Account* accountB) {
while(true) {
double randomMoney = ((double)rand() / RAND_MAX) * 100;
if (bank->transferMoney(accountA, accountB, randomMoney)) {
cout << "Transfer " << randomMoney << " from " << accountA->getName()
<< " to " << accountB->getName()
<< ", Bank totalMoney: " << bank->totalMoney() << endl;
} else {
cout << "Transfer failed, "
<< accountA->getName() << " has only $" << accountA->getMoney() << ", but "
<< randomMoney << " required" << endl;
}
}
}
int main() {
Account a("Paul", 100);
Account b("Moira", 100);
Bank aBank;
aBank.addAccount(&a);
aBank.addAccount(&b);
thread t1(randomTransfer, &aBank, &a, &b);
thread t2(randomTransfer, &aBank, &b, &a);
t1.join();
t2.join();
return 0;
}
这两个线程可能会同时获取其中一个账号的锁,然后又想获取另外一个账号的锁,此时就发生了死锁。如下图所示:
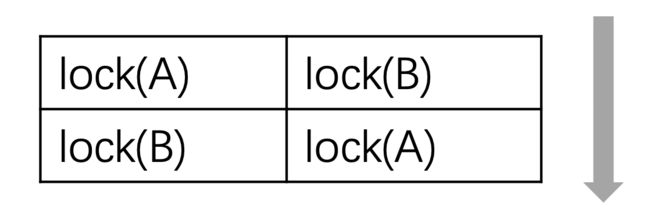
当然,发生死锁的原因远不止上面这一种情况。如果两个线程互相join就可能发生死锁。还有在一个线程中对一个不可重入的互斥体(例如mutex而非recursive_mutex)多次加锁也会死锁。
修改
#include
#include
#include
#include
using namespace std;
class Account {
public:
Account(string name, double money): mName(name), mMoney(money) {};
public:
void changeMoney(double amount) {
mMoney += amount;
}
string getName() {
return mName;
}
double getMoney() {
return mMoney;
}
mutex* getLock() {
return &mMoneyLock;
}
private:
string mName;
double mMoney;
mutex mMoneyLock;
};
class Bank {
public:
void addAccount(Account* account) {
mAccounts.insert(account);
}
bool transferMoney(Account* accountA, Account* accountB, double amount) {
// lock(*accountA->getLock(), *accountB->getLock());
// lock_guard lockA(*accountA->getLock(), adopt_lock);
// lock_guard lockB(*accountB->getLock(), adopt_lock);
scoped_lock lockAll(*accountA->getLock(), *accountB->getLock());
if (amount > accountA->getMoney()) {
return false;
}
accountA->changeMoney(-amount);
accountB->changeMoney(amount);
return true;
}
double totalMoney() const {
double sum = 0;
for (auto a : mAccounts) {
sum += a->getMoney();
}
return sum;
}
private:
set mAccounts;
};
mutex sCoutLock;
void randomTransfer(Bank* bank, Account* accountA, Account* accountB) {
while(true) {
double randomMoney = ((double)rand() / RAND_MAX) * 100;
if (bank->transferMoney(accountA, accountB, randomMoney)) {
sCoutLock.lock();
cout << "Transfer " << randomMoney << " from " << accountA->getName()
<< " to " << accountB->getName()
<< ", Bank totalMoney: " << bank->totalMoney() << endl;
sCoutLock.unlock();
} else {
sCoutLock.lock();
cout << "Transfer failed, "
<< accountA->getName() << " has only " << accountA->getMoney() << ", but "
<< randomMoney << " required" << endl;
sCoutLock.unlock();
}
}
}
int main() {
Account a("Paul", 100);
Account b("Moira", 100);
Bank aBank;
aBank.addAccount(&a);
aBank.addAccount(&b);
thread t1(randomTransfer, &aBank, &a, &b);
thread t2(randomTransfer, &aBank, &b, &a);
t1.join();
t2.join();
return 0;
}
C++17 或更早版本的标准,并且编译器不支持 C++17 的 scoped_lock,所以要指定g++以c++17标准编译
g++ -std=c++17 10_improved_bank_transfer.cpp -o 10test -pthread
通用锁定算法
| API | C++标准 | 说明 |
|---|---|---|
| lock | C++11 | 锁定指定的互斥体,若任何一个不可用则阻塞 |
| try_lock | C++11 | 试图通过重复调用 try_lock 获得互斥体的所有权 |
RAII
std::mutex 是 C++11 中最基本的 mutex 类,通过实例化 std::mutex 可以创建互斥量, 而通过其成员函数 lock() 可以进行上锁,unlock() 可以进行解锁。 但是在实际编写代码的过程中,最好不去直接调用成员函数, 因为调用成员函数就需要在每个临界区的出口处调用 unlock(),当然,还包括异常。 这时候 C++11 还为互斥量提供了一个 RAII 语法的模板类 std::lock_guard。 RAII 在不失代码简洁性的同时,很好的保证了代码的异常安全性。
在 RAII 用法下,对于临界区的互斥量的创建只需要在作用域的开始部分,例如:
#include
#include
#include
int v = 1;
void critical_section(int change_v) {
static std::mutex mtx;
std::lock_guard lock(mtx);
// 执行竞争操作
v = change_v;
// 离开此作用域后 mtx 会被释放
}
int main() {
std::thread t1(critical_section, 2), t2(critical_section, 3);
t1.join();
t2.join();
std::cout << v << std::endl;
return 0;
}
情况1(不加锁):
23
3
情况2:
2
3
3
情况3:
3
2
3
由于 C++ 保证了所有栈对象在生命周期结束时会被销毁,所以这样的代码也是异常安全的。 无论 critical_section() 正常返回、还是在中途抛出异常,都会引发堆栈回退,也就自动调用了 unlock()。
而 std::unique_lock 则是相对于 std::lock_guard 出现的,std::unique_lock 更加灵活, std::unique_lock 的对象会以独占所有权(没有其他的 unique_lock 对象同时拥有某个 mutex 对象的所有权) 的方式管理 mutex 对象上的上锁和解锁的操作。所以在并发编程中,推荐使用 std::unique_lock。
std::lock_guard 不能显式的调用 lock 和 unlock, 而 std::unique_lock 可以在声明后的任意位置调用, 可以缩小锁的作用范围,提供更高的并发度。
如果你用到了条件变量 std::condition_variable::wait 则必须使用 std::unique_lock 作为参数。
例如:
#include
#include
#include
using namespace std;
int v = 1;
void critical_section(int change_v){
static mutex mtx;
unique_lock lock(mtx);
v = change_v;
cout<<"1:"<< v << endl;
//释放锁
lock.unlock();
// 在此期间,任何人都可以抢夺 v 的持有权
// 开始另一组竞争操作,再次加锁
lock.lock();
v += 1;
cout<<"2:"<< v << endl;
}
int main(){
thread t1(critical_section,2),t2(critical_section,3);
t1.join();
t2.join();
return 0;
}
情况1
1:3
2:4
1:2
2:3
情况2
1:2
2:3
1:3
2:4