Java知识总结
java.util包
list
arraylist
- 初始容量为10,底层(有一个属性)是一个对象数组,
- add元素时,先确保容量足够,不够就扩容,扩容大小为原来的1.5倍。add(index,e)时,先检查越界了没,再看是否要扩容,将index后面的元素整体后移,添加元素
细节: - arraylist的迭代循环,用迭代器迭代的时候,要用迭代器的remove方法,不能用list的remove方法,不然会抛异常;或者用数组索引的方式迭代就可以避免这个问题
linkedlist
- 底层是一个双端链表结构,实现了Deque(双端队列)接口,可以使用LinkedList作为队列和栈的实现
- add直接在链表末尾加节点;add直接在链表末尾加节点,add(index,e)则需要先找到index的位置。查找指定索引的元素时,如果索引在前半部分,则从前完后遍历,在后半部分则从后往前遍历
成员变量有三个:大小、头节点、尾节点

节点是一个双向节点:

Vector
- 与ArrayList一样,也是通过数组实现的,不同的是它是线程安全的,它给需要同步的方法都加上了synchronized关键字,而ArrayList、LinkedList都是线程不安全的
- 扩容时,容量翻倍(ArrayList只增加50%,就有利于节约内存空间)
map
HashMap
-
底层是数组+链表/红黑树

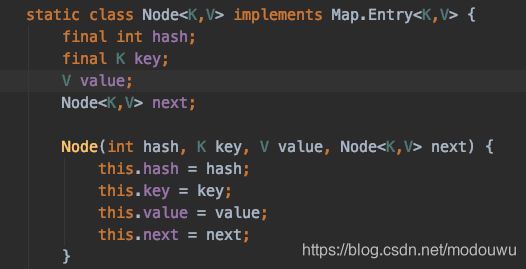


-
链表转化为红黑树的阈值是8,红黑树转化为链表的阈值是6,负载因子0.75
-
树形化最小hash表元素个数是64,即如果桶内元素已经达到转化红黑树阈值,但是表元素总数未达到阈值,则值进行扩容,不进行树形化
-
当hash表元素小于树形化最小hash表元素个数时,但是桶内元素个数大于链表转化为红黑树的阈值时,进行扩容。而当hash中元素个数大于MIN_TREEIFY_CAPACITY时,则进行树形化
-
遍历:结果一定有序,因为是在数组从前往后顺序遍历
get(key)
- 计算key的hash
- 找到在NODE数组中的位置,得到该位置上的NODE
- 如果数组上存的NODE的key就是这个key,那么就找到了返回;不是这个key,说明发生了Hash碰撞
- 否则,如果NODE类型是TreeNode,则在红黑树中查找:先找到节点的root节点,然后比较root节点的hash(这里是hash值,而不是hashCode)和key的hash的大小,小于k的hash,则当前节点置为左孩子;大于kh,置为右孩子,相等则返回该节点;一直循环知道查找到或者返回null
- 否则,遍历链表
hash(Object key)
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
如果key为null,就返回0;否则返回key的hashCode与它的无符号右移16位后的值做异或
put(key,value)
- 根据key得到hash值
- 如果node数组为空或者长度为0则初始化node数组(即node数组延迟到了插入数据时再初始化)
- 根据hash得到数组中对应的桶
- 桶内没有节点,则新建一个node放入数组
- 否则,说明有节点
- 如果该节点的hash相等并且key相等,则找到目标节点,更新节点的值,返回旧value,结束
- 否则,判断桶节点如果是treeNode,就把节点放进红黑树
- 否则,放进链表:循环遍历链表的节点,如果某个节点的hash与key均相等,那么找到更新value并返回旧value;没找到,则新增一个节点放到链表的尾部,同时判断如果链表数量>=8,则转化红黑树:
- 链表转化红黑树:
1)先判断如果node数组为空或者长度<最小红黑树转换长度64,则扩容
2)否则,将node转换为treenode链表,再对treenode链表进行红黑树转化。注意链表转为红黑树之后,链表顺序仍然被保留 - 如果节点有新增,这时map中存储的键值对数量加1,判断节点数量大于最大容量(node数组大小×负载因子),则扩容
- 扩容:
1)新建一个node数组,长度为老的数组的两倍
2)遍历老的node数组,
3)若数组上的桶不为空,判断如果桶的next为空,说明只有单独的Node,把node的hash模新的node数组大小得到在新的node数组的位置,存入
4)桶的next不为空,判断node如果是treeNode,对这棵树重hash到新node数组:
从桶节点开始遍历,根据链表的顺序把树拆分为两条链表,判断如果链表的长度<=6,则把这个链表红黑树转化为链表;>6,如果链表拆分后仍然只有一根链表,那么结构不变,否则把链表转为红黑树。(红黑树拆分为两个链表之后,原来的树结构被打乱,所以需要再转红黑树或者链表)
5)node为链表,遍历链表,构造两个新链表,一个位置为老node数组的位置,一个为老node数组位置+老node数组长度;重新映射后,两条链表中的节点顺序并未发生变化,还是保持了扩容前的顺序
细节
- node数组table是transient的,不会被默认序列化,而是覆盖了readObject/writeObject,自定义了序列化的方式,为何?
有两个问题:1.table有很多桶是空的,序列化未使用的部分部分浪费空间2.同一个键值对在不同的jvm下,所处的桶的位置可能是不同的,在不同jvm序列化可能会产生错误。因为Object的hashcode方法是native的,如果key没有覆盖hashcode方法,那么在不同jvm下hashcode可能不同从而出错

- 当haspmap的元素大小超过数组大小*负载因子0.75时发生扩容
- 在扩容过程中,链表转红黑树要满足两个条件:链表长度大于等于 8;桶数组容量大于等于 64
考察的点:
1)HashMap中的键值可以为Null吗?可以,当计算key的hashcode时,如果为null,直接返回0
2)hashmap的死锁时怎么回事?resize的时候,会transfer元素,一开始1->2,线程1移完之后,变为2->1,线程b移动时,也是移动成2->1,但是由于线程1使2.next=1,导致判断2.next不为空,要继续移1,这样就出现1->2->1的循环链表了
3)红黑树比较的是key的hashcode,哈希碰撞发生条件:两个key的hashcode不一定相同,只要他们的hashcode模上数组得到的数组中的位置相同即可
4)扩容机制要能复述:红黑树扩容后如果数量<=6还是需要转链表的,节点类型会转回node
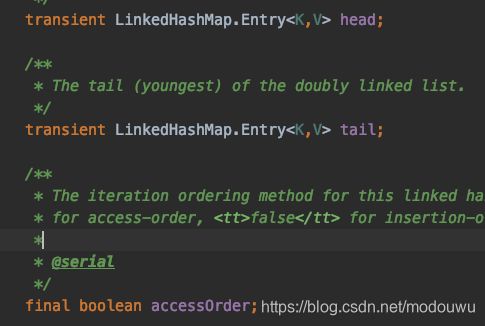
LinkedHashMap
底层;hashmap+双向链表保持插入顺序,内部保存了两个指针head和tail,可以保存插入顺序或者访问顺序

插入
逻辑跟haspmap的插入逻辑大致相同,除了有几点:
1)新建node时,linkedhashmap覆盖了hashmap的newnode方法,增加了把新节点放入双向链表的逻辑:
置tail为当前节点,如果原链表为空,则置头节点为当前节点;否则设置原尾节点的next及该节点的before
2)插入如果是覆盖,会调用查询回调,如果是加了新节点,会调用插入回调
插入回调:即在新增节点时把entry放入双向链表的尾节点,访问方法不会改变顺序;
访问回调:在插入元素和访问元素时,都会把当前元素放入双向链表的末尾。所以其实最后访问或者放入的也是最后遍历
细节
1) map.entry继承体系分析:map.entry->hashMap.node(key value hash next)->linkedHashMap.entry(key value hash next before after保持顺序的双向链表的两个指针)->hashMap.treeNode(key value hash next before after parent left right red颜色 pre这个指针主要是为了在树形变换的时候用的)
可以发现hashmap的treenode继承自linkedhashmap.entry,会浪费两个指针before,after的空间,为啥要浪费呢?源码注释有解释,如果我们的hash算法选用得当并且hashmap够大,则树形结构出现概率是很小的,因此这种浪费是可接受的
2)可以用作LRU缓存
treeMap
底层就是一个红黑树,他的节点entry为 (key,value,left,right,parent,color),保存了一个根节点属性作为红黑树的入口
treemap的key需要实现comparator接口,也就是可比较
![]()
hashtable
底层也是一个entry数组,entry为(hash,key,value,next),采用数组+链表
初始容量为11,负载因子为0.75
hashtable的value不允许为空,不然会报空指针。
重hash(扩容):新的容量为旧值的2倍加1
hashtable线程安全,对每个方法都加上了synchronized关键字
java.util.concurrent多线程
线程池ThreadPoolExecutor
- CAS 操作包含三个操作数 – 内存位置、预期数值和新值,是一种cpu级的原子操作
- 线程的排队策略,常见的四种阻塞队列有
SynchronousQueue:同步队列 无界、无缓冲,底层通过大量的自旋、cas操作来实现同步。每个insert线程必须等待一个remove线程,否则就入队等待,同样每个remove线程也必须等待一个insert线程;分为公平模式和非公平模式;入队等待其实是有一个链表式的结构。分为公平模式(先进先出)和非公平模式(后进先出),公平模式内部队列 [参考]
(https://blog.csdn.net/yanyan19880509/article/details/52562039)
底层两种结构:公平策略-队列,非公平策略-栈
这两种结构的节点,都有一个属性thread,他们存的是线程
模式必须是先取再存,消费者线程先进入栈中,park等待,当有生产者线程来放置元素时,会看栈上是否能匹配到消费者线程,能匹配到,则unpark消费者线程,消费者线程取元素成功,则生产者线程put元素成功,返回true,如果未匹配到消费者线程,put元素失败,直接返回false。
SynchronousQueue适合一对一的匹配场景,没有容量,无法缓存
SynchronousQueue一般用于生产、消费的速度大致相当的情况,这样才不会导致系统中过多的线程处于阻塞状态
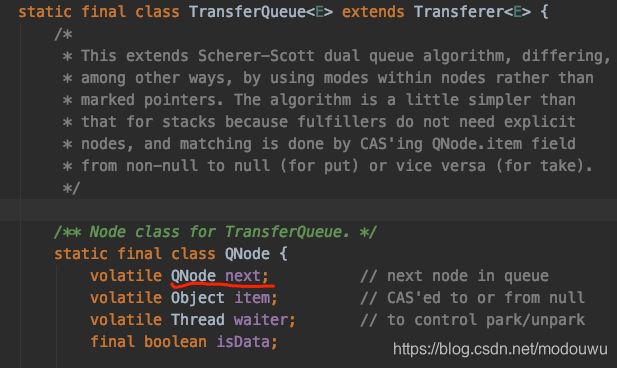
ArrayBlockingQueue:有界队列 基于数组的阻塞队列,按照 FIFO 原则对元素进行排序;底层有一个对象数组Object[] items、一个可重入锁ReentrantLock和两个Condition-notEmpty、notFull;初始化时必须指定容量大小,不需要扩容;有一个生产者指针和一个消费者指针指向数组的某个位置;有公平模式和非公平模式,这里说的是线程的是否公平,比如两个线程都去poll元素,都阻塞,他们俩唤醒是否公平,通过创建ReentrantLock(fair/unfair)来控制,而不是队列里的元素是否公平,队列里的元素是死的,;
缺点:队列长度固定,如果消费速度跟不上入队速度,则会导致提供者线程一直阻塞,且越阻塞越多,非常危险;只使用了一个锁来控制入队出队,效率较低,那是不是可以借助分段的思想把入队出队分裂成两个锁呢
put元素时,先获取lock,判断如果元素个数与数组长度相等,那么notfull等待,否则把元素入队,signal notempty最后解锁。
notfull在放置元素,如果已满,则await;取或清除元素,则signal
notEmpty在防止元素成功,则signal();取元素为空,则await
take元素时,先获取lock,如果元素个数为空,等待
LinkedBlockingQueue:无界队列 基于单链表的阻塞队列,按照 FIFO 原则对元素进行排序;不指定容量,就使用Integer.MAX_VALUE作为容量,因此从底层来说它是有界的;如果初始化不传入初始容量,则使用最大int值,如果出队速度跟不上入队速度,会导致队列特别长,占用大量内存;没有公平非公平模式之分,因为ReentrantLock默认是非公平模式,可以理解只有非公平模式,使用FIFO对元素进行入队出队;
包含一个读reentrantlock和写的reentrantlock,进行了读写分离,有利于并发,这也是linkedBlockingQueue比ArrayBlockingQueue更常用的原因之一
put:获取写锁,如果节点数和容量相等,notfull等待,否则入队,数量+1,如果没有满,唤醒一个notfull线程。
能进行读写分离,是因为读是在表头写是在表尾,他们俩操作的是不同端的数据
LinkedBlockingQueue与ArrayBlockingQueue对比:ArrayBlockingQueue入队出队采用一把锁,导致入队出队相互阻塞,效率低下,而LinkedBlockingQueue入队出队采用两把锁,入队出队互不干扰,效率较高;LinkedBlockingQueue如果初始化不传入初始容量,则使用最大int值,如果出队速度跟不上入队速度,会导致队列特别长,占用大量内存
PriorityBlockingQueue:优先级队列 具有优先级的阻塞队列,集合中的每个元素都有一个权重值,每次出队都弹出优先级最大或最小的元素,使用堆排序实现,底层一个对象数组存储,是;不是全局有序的,只有堆顶存储着最小的元素,是个小顶堆;使用一个锁+一个notEmpty条件控制并发安全;PriorityBlockingQueue是无限增长的队列,元素不够用了会扩容,所以添加元素不会失败;旧容量小于64则翻倍,旧容量大于64则增加一半 - 拒绝策略:
AbortPolicy 丢弃新任务,并抛出 RejectedExecutionException
DiscardPolicy 不做任何操作,直接丢弃新任务
DiscardOldestPolicy 丢弃队列队首的元素,并重新提交新任务(重新走一遍流程)
CallerRunsPolicy 由调用线程执行新任务
默认的拒绝策略是抛出异常 - 添加任务:当添加一个任务,会根据coresize,maxsize等参数,如果不拒绝,就addworker;addworker:新建一个worker,获取ThreadPoolExecutor的对象锁,用来更新对象的状态、添加worker到hashset数组,成功之后,启动加入的这个worker的thread属性,即runworker;runworker:这是一个循环,即获取worker的锁,再运行work中的线程/worker中的线程为空,从阻塞队列中获取task即gettask,然后调用task的run方法(相当于调用普通方法,这样由于之前获取的worker锁,每个worker对应一个task)。在gettask中从阻塞队列获取task的时候,如果超过了线程过期时间,那么减小worker数目,并返回null
- 终止线程池:shutdown:将线程池状态置为shutdown,并且中断所有空闲线程,想中断线程,必须获取worker的锁,在runworker时,是先获取worker的锁然后再执行run的,所以正在运行的worker是不会中断的。SHUTDOWN只是清除一些空闲Worker,并且拒绝新Task加入,对于workQueue中的线程还是继续处理的。
shutdownnow:将线程池状态置为STOP,中断所有worker,并把阻塞队列中的所有task返回 - 流程:创建一个线程池,在还没有任务提交的时候,默认线程池里面是没有线程的。当然,你也可以调用prestartCoreThread方法,来预先创建一个核心线程。
线程池里还没有线程或者线程池里存活的线程数小于核心线程数corePoolSize时,这时对于一个新提交的任务,线程池会创建一个线程去处理提交的任务。当线程池里面存活的线程数小于等于核心线程数corePoolSize时,线程池里面的线程会一直存活着,就算空闲时间超过了keepAliveTime,线程也不会被销毁,而是一直阻塞在那里一直等待任务队列的任务来执行。
当线程池里面存活的线程数已经等于corePoolSize了,这是对于一个新提交的任务,会被放进任务队列workQueue排队等待执行。而之前创建的线程并不会被销毁,而是不断的去拿阻塞队列里面的任务,当任务队列为空时,线程会阻塞,直到有任务被放进任务队列,线程拿到任务后继续执行,执行完了过后会继续去拿任务。这也是为什么线程池队列要是用阻塞队列。
当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列也满了,这里假设maximumPoolSize>corePoolSize(如果等于的话,就直接拒绝了),这时如果再来新的任务,线程池就会继续创建新的线程来处理新的任务,知道线程数达到maximumPoolSize,就不会再创建了。这些新创建的线程执行完了当前任务过后,在任务队列里面还有任务的时候也不会销毁,而是去任务队列拿任务出来执行。在当前线程数大于corePoolSize过后,线程执行完当前任务,会有一个判断当前线程是否需要销毁的逻辑:如果能从任务队列中拿到任务,那么继续执行,如果拿任务时阻塞(说明队列中没有任务),那超过keepAliveTime时间就直接返回null并且销毁当前线程,直到线程池里面的线程数等于corePoolSize之后才不会进行线程销毁。
如果当前的线程数达到了maximumPoolSize,并且任务队列也满了,这种情况下还有新的任务过来,那就直接采用拒绝的处理器进行处理。默认的处理器逻辑是抛出一个RejectedExecutionException异常。你也就可以指定其他的处理器,或者自定义一个拒绝处理器来实现拒绝逻辑的处理(比如讲这些任务存储起来)。JDK提供了四种拒绝策略处理类:AbortPolicy(抛出一个异常,默认的),DiscardPolicy(直接丢弃任务),DiscardOldestPolicy(丢弃队列里最老的任务,将当前这个任务继续提交给线程池),CallerRunsPolicy(交给线程池调用所在的线程进行处理)
AQS抽象队列同步器
- 底层,包含一个volatile的state(代表共享资源),包含一个内部类node,node属性(pre,next,thread),底层是一个FIFO的NODE双链表队列。定义了一套多线程访问共享资源的同步器框架,具体的资源获取的由继承类来实现
- acquire获取资源:调用继承类的获取资源方法,如果获取成功,返回;获取失败,就要加入到node队列末尾,然后自旋直到前驱节点是head节点,则调用继承类的获取资源的方法,如果获取到了资源,把当前节点设置为head节点,把前驱节点置为空方便gc,循环过程中,前驱节点不为head节点或者获取资源失败,判断node的前驱是不是被取消,被取消则由node顶替它的位置直到找到一个不是被取消的节点,把前驱节点置为singal(这个是告诉前驱节点获取资源之后通知自己)。然后park这个节点,节点进入等待状态
- release释放资源:调用继承类的释放资源方法,若成功,找到下一个需要唤醒的节点,uppark
- 共享式的acquireshared:
Reentrantlock
可重入锁
内部类Sync继承了AQS,NonfairSync和FairSync继承了Sync.
acquire方法:如果锁状态是0,cas加锁;否则判断锁的拥有者是否是当前线程,是的话就重入。剩余逻辑参照AQSDACQUIRE
aqs无所谓公平模式和非公平模式,它只是让两个等待的节点组成了双向队列。
公平模式,线程acquire资源时,会判断队列必须没有前驱阶段,也就是必须(aqs的双向链表队列的头节点)是head节点才会抢锁,fifo的顺序
非公平模式则不会有这个判断,只要acquire就会抢
同步关键字
volatile
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义
(1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的
(2)禁止进行指令重排序
底层原理
观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令,lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
(1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
(2)它会强制将对缓存的修改操作立即写入主存;
(3)如果是写操作,它会导致其他CPU中对应的缓存行无效
使用的场景
运算的结果并不依赖于变量的当前值,或者能够确保只有单一的线程修改变量的值
synchronized
底层原理
在Java中,每一个对象都拥有一个锁标记(monitor),也称为监视器,多线程同时访问某个对象时,线程只有获取了该对象的锁才能访问;另外,每个类也会有一个锁,它可以用来控制对static数据成员的并发访问
(1)同步语句块:实现使用的是monitorenter 和 monitorexit 指令,其中monitorenter指令指向同步代码块的开始位置,monitorexit指令则指明同步代码块的结束位置,当执行monitorenter指令时,当前线程将试图获取 objectref(即对象锁) 所对应的 monitor 的持有权,当 objectref 的 monitor 的进入计数器为 0,那线程可以成功取得 monitor,并将计数器值设置为 1,取锁成功。如果当前线程已经拥有 objectref 的 monitor 的持有权,那它可以重入这个 monitor (关于重入性稍后会分析),重入时计数器的值也会加 1。倘若其他线程已经拥有 objectref 的 monitor 的所有权,那当前线程将被阻塞,直到正在执行线程执行完毕,即monitorexit指令被执行,执行线程将释放 monitor(锁)并设置计数器值为0 ,其他线程将有机会持有 monitor 。值得注意的是编译器将会确保无论方法通过何种方式完成,方法中调用过的每条 monitorenter 指令都有执行其对应 monitorexit 指令,而无论这个方法是正常结束还是异常结束
(2)方法:synchronized修饰的方法并没有monitorenter指令和monitorexit指令,取得代之的确实是从方法常量池中的方法表结构(method_info Structure) 中的 ACC_SYNCHRONIZED 访问标志区分一个方法是否同步方法,该标识指明了该方法是一个同步方法,如果设置了,执行线程将先持有monitor(虚拟机规范中用的是管程一词), 然后再执行方法,最后再方法完成(无论是正常完成还是非正常完成)时释放monitor
有两种锁,对象锁和类锁;每个对象有一个监视器锁(monitor)
(3)l静态方法:一个类只有一个class对象,Class对象其实也仅仅是1个java对象,因为每一个java对象都有1个互斥锁,而类的静态方法是须要Class对象。因此所谓的类锁,只不过是Class对象的锁而已
等待唤醒机制与synchronized
notify/notifyAll和wait方法必须处于synchronized代码块或者synchronized方法中,这是因为调用这几个方法前必须拿到当前对象的监视器monitor对象,也就是说notify/notifyAll和wait方法依赖于monitor对象,synchronized关键字可以获取 monitor ,这也就是为什么notify/notifyAll和wait方法必须在synchronized代码块或者synchronized方法调用的原因。
需要特别理解的一点是,与sleep方法不同的是wait方法调用完成后,线程将被阻塞,但wait方法将会释放当前持有的监视器锁(monitor),直到有线程调用notify/notifyAll方法后方能继续执行,而sleep方法只让线程休眠并不释放锁。同时notify/notifyAll方法调用后,并不会马上释放监视器锁,而是在相应的synchronized(){}/synchronized方法执行结束后才自动释放锁
申请内存之后内存不能回收叫内存泄漏,申请内存时内存不够叫内存溢出
锁升级
自旋锁
自适应自旋锁
轻量级锁
偏向锁
重量级锁
上述这三种机制的切换是根据竞争激烈程度进行的:
在几乎无竞争的条件下, 会使用偏向锁
在轻度竞争的条件下, 会由偏向锁升级为轻量级锁
在重度竞争的情况下, 会由轻量级锁升级为重量级锁
线程安全容器
ConcurrentHashMap
底层原理
旧版本:
- 总体结构是一个分段锁数组segments,segment内部是一个可重入锁+hashentry数组+链表(因为是1.7,所以是没有红黑树的,hashMap也是1.8才有红黑树)
segment(threshold,loadfactor,hashentry[]),并且继承了ReentrantLock,因此包含一把锁;这个segment数组个数是怎么得到的呢?在构造ConcurrentHashMap时需要传入一个并发度参数,初始segment数组大小为1,并且segment数组大小也代表了并发度,然后如果并发度<设定的并发度,那么segment数组大小左移1位变为2倍,才比较此时的segment数组大小和兵法度,直到并发度>=设定的并发度,则得到segments数组大小
HashEntry(key,hash,value,next) - get/put():首先从segments数组中定位segment,然后加锁,定位hashentry数组,再查链表。两次hash定位
- size():需要在多个segment中运行,size操作就是遍历了两次Segment,每次记录Segment的modCount值,然后将两次的modCount进行比较,如果相同,则表示期间没有发生过写入操作,就将原先遍历的结果返回,如果不相同,则把这个过程再重复做一次,如果再不相同,则就需要将所有的Segment都锁住,然后一个一个遍历
1.8版本
- 底层和hashmap基本一样(也就是有空黑树),自旋锁+同步原理synchronized+大量volatile变量+CAS;调整为对每个桶加锁(Node)
- put():如果node数组没有初始化就初始化,计算在node数组中的位置,如果桶上没有元素,通过cas的方式放置元素;如果发现桶的节点正在扩容,则当前线程也去帮忙扩容;否则通过synchronized方式对桶加锁,再分别进行覆盖值,链表和红黑树的操作。省略扩容以及转红黑树判断
- 扩容:关键就是通过CAS设置sizeCtl与transferIndex变量,协调多个线程对table数组中的node进行迁移
- size():获取所有段的元素个数;不加锁
参考:1.7和1.8的区别总结
总结
ConcurrentHashMap是HashMap的线程安全版本;
查询操作是不会加锁的,所以ConcurrentHashMap不是强一致性的;
CopyOnWriteArrayList
写时复制,是ArrayList的线程安全版本,适用于读多写少
每次对数组的修改都完全拷贝一份新的数组来修改,修改完了再替换掉老数组,这样保证了只阻塞写操作,不阻塞读操作,实现读写分离。
底层包含一个volatile数组和一个reentrantlock,新增修改删除需要加锁,然后拷贝一份新的数组来修改,修改完再替换老数组,解锁;读的时候直接读数组不需要加锁;这样保证了只阻塞写操作,不阻塞读操作,实现读写分离。如果这时候有多个线程正在修改数据,则读取的是旧的数据。
缺点:内存占用,在写操作的时候,内存里会同时存在两个对象的内存;只能保证数据的最终一致性,不能保证实时一致性
CopyOnWriteArraySet
底层是一个CopyOnWriteArrayList,只是不允许元素重复,调用的是CopyOnWriteArrayList的方法,如果元素已存在则不添加,元素不存在则添加
通过调用CopyOnWriteArrayList的addIfAbsent()方法来保证元素不重复
CountDownLatch
计数器 只能使用一次,利用它可以实现类似计数器的功能
内部类Sync继承了AQS
await():内部会调用方法tryAcquireShared(1),逻辑就是如果state=0,就返回成功,否则等待。
countDown();自旋并使state-1,如果state=0,那么通过循环唤醒AQS上面的等待队列
CountDownLatch初始化时会传入共享资源state的值,线程A调用await(),则会等待state=0这个条件;而线程B1、B2、B3使state自减,当state=0时,会唤醒等待的线程A
CountDownLatch与Thread.join()有何不同?Thread.join()是在主线程中调用的,它只能等待被调用的线程结束了才会通知主线程,而CountDownLatch则不同,它的countDown()方法可以在线程执行的任意时刻调用,灵活性更大
semaphore[ˈsɛməˌfɔr]
信号量 Semaphore可以控同时访问的线程个数即限流量,通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可
内部类Sync继承了AQS,NonfairSync和FairSync分别提供非公平和公平策略。volatile state保存了当前资源状态
acquire方法:还是走AQS的框架,如果获取到锁,返回,获取不到,排队。获取锁的逻辑由具体的实现类来实现;即先获取剩余资源,如果资源数-需求数>0,成功返回,并且cas设置state,否则不停的循环
cyclicbarrier [ˈsaɪklɪkˈbæriɚ]
循环栅栏 可以重复使用,通过它可以实现让一组线程等待至某个状态之后再全部同时执行
内部有一个可重入锁reentrantlock,它保存了一个count,每次有线程await,都会自减,直到为0就通知signalall
CyclicBarrier基于ReentrantLock及其Condition实现整个同步逻辑
await():获取可重入锁,如果当前线程是最后一个线程,那么在这个线程中执行传入的runnable方法,并重置屏障使其可以循环使用,同时调用condition.singalall方法唤醒所有等待线程;若不是最后一个线程,则调用条件对象condition.await让它等待。最后解锁。
CyclicBarrier与CountDownLatch的对比?
前者是最后一个线程到达时自动唤醒,后者是通过显式地调用countDown()实现;
前者是通过重入锁及其条件锁实现的,后者是直接基于AQS实现的;
前者具有“代”的概念,可以重复使用,后者只能使用一次;
Exchanger
交换器
线程间交换数据,一般用于两个线程之间交换或者偶数个线程之间交换、互相消费。
v exchange(v):交换出去v类型数据,并返回v类型数据
Condition
在reentrantlock中使用condition时,存在两类同步队列,一个归属于reentrantlock(在aqs里,用来争用reentrantlock),一类归属于condition(用来等待条件)
- 该接口的唯一实现是AQS的内部类ConditionObject,这个类底层是一个node类型的单链表.一个锁对象reentrantlock可同时创建多个 ConditionObject 对象、即对应多个单链表,这意味着多个竞争同一独占锁的线程可在不同的条件队列中进行等待。在唤醒时,可唤醒指定条件队列中的线程
- await():先把node加到条件队列/单链表的末尾,并把所有cancel状态的node从单链表移除,释放这个锁,并唤醒 AQS队列中一个线程,节点如果不是条件等待状态,即节点在AQS队列上,则park线程让线程等待。当线程被唤醒,就尝试在AQS队列中获取锁,并进行后续操作
- signal():将条件队列中的头结点转移到同步队列中,先检查线程是否获取了独占锁,没获取就抛出异常。将头结点转移到同步队列中,并且把头结点从条件队列中移除,如果转移失败,则继续转移下一个节点,直到转移成功
- 总结一下 Condition 执行 await 和 signal 的过程吧
首先,线程如果想执行 await 方法,必须拿到锁,在 AQS 里面,抢到锁的一般都是 head,然后 head 失效,从队列中删除。在当前线程(也就是 AQS 的 head)拿到锁后,调用了 await 方法,第一步创建一个 Node 节点,放到 Condition 自己的队列尾部,并唤醒 AQS 队列中的某个(head)节点,然后阻塞自己,等待被 signal 唤醒。
当有其他线程调用了 signal 方法,就会唤醒 Condition 队列中的 first 节点,然后将这个节点放进 AQS 队列的尾部。阻塞在 await 方法的线程苏醒后,他已经从 Condition 队列总转移到 AQS 队列中了,这个时候,他就是一个正常的 AQS 节点,就会尝试抢锁。并清除 Condition 队列中无效的节点
线程
线程的生命周期:
NEW 新建状态,线程还未开始
RUNNABLE 可运行状态,正在运行或者在等待系统资源
BLOCKED 阻塞状态,在等待一个监视器锁(也就是我们常说的synchronized)
WAITING 等待状态
TIMED_WAITING 超时等待状态,在调用了以下方法后会进入超时等待状态,如Thread.sleep() Object.wait(timeout)
TERMINATED 终止状态
RPC框架中异步调用是怎么实现的?
答:RPC框架常用的调用方式有同步调用、异步调用,其实它们本质上都是异步调用,它们就是用FutureTask的方式来实现的。
一般地,通过一个线程(我们叫作远程线程)去调用远程接口,如果是同步调用,则直接让调用者线程阻塞着等待远程线程调用的结果,待结果返回了再返回;如果是异步调用,则先返回一个未来可以获取到远程结果的东西FutureXxx,当然,如果这个FutureXxx在远程结果返回之前调用了get()方法一样会阻塞着调用者线程。
有兴趣的同学可以先去预习一下dubbo的异步调用(它是把Future扔到RpcContext中的)
mybatis
加载过程
springmvc
配置文件解析:首先根据工具类resources加载配置文件,得到输入流,根据输入流生成配置文件解析器,调用各个节点解析方法,把解析到的属性和值设置到configuration。其中,解析mapper节点会定位到mapper.xml文件,然后解析mapper文件,并存到configuration,这样映射文件就解析完了
springboot
在启动时会加载所有spring.facotrys中指定的类;扫描所有mapper,并得到bean定义的集合;重置了beanClass为代理类 MapperFactoryBean,个mapper都变成了MapperFactoryBean,为了区分他们,MapperFactoryBean的构造函数参数,传入了mapper接口的名字;
sql的执行过程
第一步判断configiration的mapper集合中必须包含目标目标Mapper,然后通过jdk的动态代理创建mapper对象,调用代理对象的sql方法就可以操作数据库了。动态代理具体添加了什么操作呢?如果方法是object对象方法,那么直接通过反射调用,如果是sql方法,先从缓存map里获取mappermethod对象,然后调用它的execute方法获取返回结果(底层也是调用statement执行sql)。execute方法:判断方法类型,根据不同的方法类型执行不同的方法
mysql数据库
聚簇(集)索引和非聚簇(集)索引
聚簇索引,索引存储的结构与数据存储的物理结构是一样的,因为物理顺序结构只有一种,那么一个表的聚簇索引也只有一个,通常是主键,设置主键系统默认就给你加上了聚簇索引。
非聚簇索引,记录的物理顺序与逻辑顺序没有必然的联系,与数据的存储物理结构没有关系;一个表对应的非聚簇索引可以有多条,根据不同列的约束可以建立不同要求的非聚簇索引
单列索引和联合索引(复合索引)
单列索引,包含主键索引,唯一索引
联合索引,包含多个字段,遵循最左前缀原则,只有在使用左边字段查询时才会被使用。
当创建(a,b,c)联合索引时,相当于创建了(a)单列索引,(a,b)联合索引以及(a,b,c)联合索引
想要索引生效的话,只能使用 a和a,b和a,b,c三种组合;当然,我们上面测试过,a,c组合也可以,但实际上只用到了a的索引,c并没有用到
b树,b+树索引
数据库查询数据时,需要将需要查询的页数据加载到内存,每次加载需要一次磁盘io,磁盘io的速度很慢,如果使用平衡二叉树,最坏io的次数是树的高度,io频繁。因此将瘦高的树变矮胖,两点:每个节点存储更多元素,采用多叉树
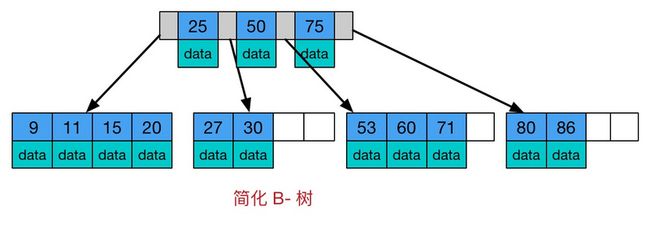

b树和b+树区别
1)B+树叶子节点保存索引和数据,非叶子节点保存索引,查询时间复杂度固定为 log n;b树的内节点和叶子节点都保存索引和数据,查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)
2)B+树叶子节点是有序链表,大大增加区间访问性,可使用范围查询等,而B-树每个节点 key 和 data 在一起,则无法范围查找;
3)由于B+树的叶子节点的数据都是使用链表连接起来的,而且他们在磁盘里是顺序存储的,所以当读到某个值的时候,磁盘预读原理就会提前把这些数据都读进内存,使得范围查询和排序都很快
b+树特征:
- 复合索引和单列索引的结构类似,只是key是多列并有序而已
- Innodb的聚集索引也是主键索引,索引的key就是表的主键,叶子节点包含完整的数据记录,因此主键索引的索引和数据在一个文件;非主键索引的叶子存的是主键而不是地址,因此innoBB的非主键索引最终还是要依赖主键索引来实现。有一种特殊的索引叫覆盖索引,比如我们建立了复合索引(uage,uname),select uage,uname from user where uage=12;这条语句会使用索引而且能直接返回数据而不需要再通过主键索引了,那么这个复合索引可以称为覆盖索引
- MyISAM的主键索引,索引文件和数据是分开的,索引叶子存储的是数据的地址;辅助索引和主键索引结构一样,索引叶子也存储了数据的地址,只是key可以重复不唯一
myisam和innodb区别
- InnoDB支持事务,MyISAM不支持
- InnoDB支持外键,而MyISAM不支持
- InnoDB的B+树主键索引的叶子节点就是数据文件,辅助索引的叶子节点是主键的值;而MyISAM的B+树主键索引和辅助索引的叶子节点都是数据文件的地址指针
- InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快(注意不能加有任何WHERE条件)
- InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
- InnoDB表必须有唯一索引(如主键),Myisam可以没有
事务的隔离级别
读未提交,读已提交(解决脏读),可重复读(解决不可重复读),可串行化(解决幻读)
不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
锁
- innodb支持事务,支持行锁和表锁,myisam不支持事务,只支持表锁
- 共享锁和排他锁都是行锁,意向锁都是表锁,应用中我们只会使用到共享锁和排他锁,意向锁是mysql内部使用的,不需要用户干预。因此我们使用innodb时只会接触行锁
共享锁:select xxx from xxx in share mode,共享锁在多个事务可以共享
排他锁:select xxx from xxx for update,排他锁获取之前必须等其他事务的共享锁释放
- 对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁,对于普通SELECT语句,InnoDB不会加任何锁
- MyISAM在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行更新操作(UPDATE、DELETE、INSERT等)前,会自动给涉及的表加写锁
- 可重复读的隔离级别下使用了MVCC机制,select操作不会更新版本号,是快照读(历史版本);insert、update和delete会更新版本号,是当前读(当前版本)
间隙锁
- 目的是为了防止幻读,使用情况为范围查询
- innodb自动使用间隙锁条件:一、必须在RR级别下,二、检索条件必须有索引(没有索引的话,mysql会全表扫描,那样会锁定整张表所有的记录,包括不存在的记录,此时其他事务不能修改不能删除不能添加)
- 间隙的位置判定,先判断索引大小,再判断其他元素如主键的大小来判断是否在间隙内
- 间隙锁与间隙锁之间不互斥,因此容易造成死锁
- 可以参考 间隙锁
记录锁(行锁)
- 事务隔离级别为读提交时,写数据只会锁住相应的行;为可重复读时则是next-key
- 情况:如果where条件不走索引,那么会进行全表扫描,锁定整张表的所有记录(既不是加表锁,也不是在满足条件的记录上加行锁,而是所有记录都加行锁)
注:在实际的实现中,MySQL有一些改进,在MySQL Server过滤条件,发现不满足后,会调用unlock_row方法,把不满足条件的记录放锁 (违背了2PL的约束)。这样做,保证了最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的
next-key锁(当前读)
select * from table where ? lock in share mode;
select * from table where ? for update;
insert into table values (…);
update table set ? where ?;
delete from table where ?;
- 所有以上的语句,都属于当前读,读取记录的最新版本。并且,读取之后,还需要保证其他并发事务不能修改当前记录,对读取记录加锁。其中,除了第一条语句,对读取记录加S锁 (共享锁)外,其他的操作,都加的是X锁 (排它锁)
- 记录所+行锁,是Innodb默认的加锁方式,只是rc只有行锁,rr才是两者都有
- 特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁
mvcc(快照读,默认)
- 简单的select操作,属于快照读,不加锁
- 多版本并发控制,通过创建版本号和删除版本号来实现多事务并发,用于RR,RC级别,支持行锁
- MVCC在RR和RC隔离级别下的区别,在RR隔离级别下,一个事务只能读取到事务开始的那个时刻的数据快照,即,别的事务修改并提交的数据在自身没有提交之前一般读取不到(加for update语句的select除外,因为这个语句要对数据加X锁必须读取最新的数据快照),在RC隔离级别下,事务总是读取数据行的最新快照,即会产生不可重复读的问题
RR下查出的记录满足两个条件:(1)删除版本号未指定或者大于当前事务版本号 (2)创建版本号 小于或者等于 当前事务版本号
幻读的解决
对于快照读,依赖mvcc机制;对于当前读,依赖于间隙锁
RR隔离级别已经解决了幻读,依靠(1)MVCC(2)间隙锁,(高性能mysql中已经提及了)
RR和RC加锁情况总结
主键为id,普通索引year
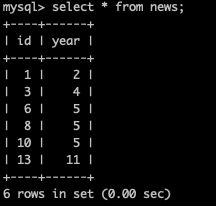
非唯一索引
单一查询:
事务一:
select * from news where year=4 for update
要想锁定year为4的记录,那么不仅需要锁定当前year=4的记录,还需要锁定year=4前后的间隙。试想如果仅仅锁定(3,4),那么如果再插入一条(2,4)的纪录,就出现幻读了
事务二:
insert into news values(0,2);//成功
insert into news values(2,4);//阻塞
insert into news values(2,2);//阻塞
insert into news values(4,5);//阻塞
insert into news values(7,5);//成功
update news set id=4 where id=10;//阻塞
update news set id=12 where id=6;//成功!!!
间隙锁锁定的区域:
根据检索条件向左寻找最靠近检索条件的记录值A,作为左区间,向右寻找最靠近检索条件的记录值B作为右区间,即锁定的间隙为(A,B)。where year=4的话,那么间隙锁的区间范围为(1,2)到(6,5),这两个节点还不包含的
间隙锁的目的是为了防止幻读,其主要通过两个方面实现这个目的:
(1)防止间隙内有新数据被插入
(2)防止已存在的数据,更新成间隙内的数据(例如防止numer=3的记录通过update变成number=5)
范围查询:
事务一:
select * from news where year>4 for update
根据条件向左取4,向右为无穷大,因此间隙锁的范围为(3,4)到无穷大
事务二:
update news set id=4 where year=4;//阻塞
insert into news values(4,4);//阻塞
update news set id=3 where year=4;//成功!!说明是开区间
唯一索引
单一查询:
事务一:
select * from news where id=6 for update;
事务二:
insert into news values(5,5);//成功
insert into news values(7,5);//成功
select * from news where year=5 for update;//阻塞
select * from news where year=5 for update;//阻塞
可以看到单一查询,唯一索引只锁定行,不锁定间隙
范围查询:

事务一:
select * from news where id>5 for update
唯一索引的范围查询,锁定行和间隙。根据条件向左取3,向右取无穷大,因此区间为3到无穷大
事务二:
insert into news values(6,1);//阻塞
insert into news values(4,1);//阻塞!!!!
空查询:
select * from news where id>4 and id<7 for update;此时会对表中第一个不满足条件的项上加上gap锁,防止后续插入满足条件的记录。此时加锁的范围是((3,4),(8,5)]
对于如上的两个限定范围的查询,mysql只会将id>4这个正向扫描的条件下降到mysql的引擎层,因此innoDb看到的索引条件是id>4,读出的第一条记录是id=8,给(8,5)加上next key锁,然后返回给mysql server层进行id<7的判断
gap锁之间是不冲突的,但是两个事务同时执行上述sql会冲突,就是因为加了next key锁即行锁的缘故
数据库常见的优化策略
1.选取最适用的字段属性
如邮政编码char(6)就不要写成vchar(255)
not null能加就加,这样可以省去是否等于null的判断
2.使用join代替子查询
因为使用子查询的话,mysql需要在内存中创建临时表来存这个子查询的结果
3.使用联合(UNION)来代替手动创建的临时表
4.使用外键
5.使用索引
索引常见的优化策略
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by涉及的列上建立索引
2.尽量避免在 where 子句中使用 !=或<> 操作符,否则将引擎放弃使用索引而进行全表扫描
3.尽量避免在 where 子句中对字段进行 null 值 判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
5.对于 like ‘…%’ (不以 % 开头)
6.尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
select id from t where num/2=100
7.在使用索引字段作为条件时,如果该索引是【复合索引】,那么必须使用到该索引中的【第一个字段】作为条件时才能保证系统使用该索引,否则该索引将不会被使用。并且应【尽可能】的让字段顺序与索引顺序相一致
ICP(Index Condition Pushdown)索引条件下推
mysql查询分为引擎层和server层,
- 不使用ICP时,storage层将满足索引条件的的对应的整行记录取出,返回给server层,server层再使用后面的where条件(非索引条件)过滤,筛选出满足的数据
- 使用ICP时,storage层首先将index key条件满足的索引记录区间确定,然后在索引上使用index filter进行过滤,筛选满足所有索引条件的索引记录,然后回表取出对应的整行记录返回给server层,server层再使用后面的where条件(非索引条件)过滤,筛选出满足的数据


ICP的使用限制
ICP的优化在引擎层就能够过滤掉大量的数据,这样无疑能够减少了对base table和mysql server的访问次数,提升了性能
- ICP只能用于二级索引,不能用于主索引
- 并非全部where条件都可以用ICP筛选。如果where条件的字段不在索引列中,还是要读取整表的记录到server端做where过滤
- ICP的加速效果取决于在存储引擎内通过ICP筛选掉的数据的比例
- 当sql 使用覆盖索引时,不支持ICP 优化方法
ICP与锁
在RR隔离级别下,针对一个复杂的SQL,首先需要提取其where条件。Index Key确定的范围,需要加上GAP锁;Index Filter过滤条件,视MySQL版本是否支持ICP,若支持ICP,则不满足Index Filter的记录,不加X锁,否则需要X锁;Table Filter过滤条件,无论是否满足,都需要加X锁
Spring
bean的生命周期
参考:spring bean的生命周期

第4步,BeanPostProcessor前置处理,指的是调用Object postProcessBeforeInitialization(Object bean, String beanName)
第7步,BeanPostProcessor后置处理,指的是调用Object postProcessAfterInitialization(Object bean, String beanName)
第8步,Destruction指的是销毁时调用的回调方法
循环依赖
第2步中,设置对象的属性,如果是一个Bean对象依赖于另一个Bean对象,则Spring容器首先要先去实例化 bean 依赖的对象,实例化好后才能设置到当前 bean 中。如果是循环依赖,spring怎么初始化的呢?
如果依赖靠构造器的方式注入,则会报循环依赖异常;
如果是setter设置属性模式,并且是范围是单例,通过实例化后加缓存解决
如BeanA和BeanB循环依赖,A实例化后,将自己提前曝光加入到缓存中;此时开始设置属性,就开始创建B,实例化B后,设置B的属性,发现B依赖了A,就从提前曝光的缓存中拿到了A,顺利完成了属性设置,并顺利完成了后续的bean创建步骤,返回给A,接着A再继续自己的bean创建即可
Spring启动流程
入口是SpringApplication.run(Application.class, args)
1】new SpringApplication,并设置属性:从spring.factories配置文件中读取所有ApplicationContextInitializer,ApplicationListener的实现类并设置、设置mainApplicationClass等
2】开始执行run方法:
①加载spring.factories,发布application启动事件:读取并加载所有SpringApplicationRunListener(都是在spring.factories文件里定义的),并start它们,同时发布ApplicationStartingEvent事件,之前加载的ApplicationListener收到这个事件就会做出对应的操作,如设置log系统、配置environment、配置profile等。后续的发布的其他一些事件,也会执行监听器对应的方法,如环境准备好事件、application准备好事件、application启动失败事件等等
②环境准备:创建StandardEnvironment,发布环境准备事件。这里会加载一些系统环境变量、properties、yml文件配置等等
③创建容器ApplicationContext(简称Context,继承了beanFactory):通过反射的方式Class来newInstance容器
④准备容器Context:设置之前的Environment环境给Context、执行容器后置处理postProcessApplicationContext()、执行第一步加载的ApplicationContextInitializer中的初始化方法、发布Context准备事件等等,这里,springboot的容器就准备好了
⑤刷新容器【核心】:
a.初始化BeanFactory,并准备:如设置ClassLoader、设置Bean表达式解析器、Property解析器等准备工作
b.调用invokeBeanFactoryPostProcessors即BeanFactory后置处理方法
b1)从BeanFactory中获取实现了BeanFactoryPostProcessor接口的类,得到了ConfigurationClassPostProcessor类,然后触发它的方法postProcessBeanDefinitionRegistry(bean定义初始化后置处理方法):
b1a):遍历BeanFactory中的所有BeanDefinition,得到被@configuration注解的
BeanDefinition列表
b1b):对每个BeanDefinition解析,逻辑为:第一步解析成员,有的@configuration注解的类下面还有@Configuration子类,第二步,处理@PropertySources注解,将配置文件解析后存入(Stand)environment,如配置为redis.properties文件,第三步处理@ComponentScan注解,扫描路径下的所有class,判断这个类有@component注解【注意:@Configuration、@Service注解内部是包含@Component的】,得到Beandefition集合,对每个beandefinition,解析一下它的配置如scope、dependens on等等设置回beandefinition,并把beandefinition注册到BeanFactory(这里只是进行了注册,真正生成bean放在了d),第四步处理@Import注解,拿到注解上的引入类,设置到BeanDefinition中,第五步,处理@ImportResource注解,得到location信息设置到BeanDefinition中,第六步,处理@Bean注解,得到类中被@Bean修饰的所有方法集合,并设置到BeanDefinition中,第七步,处理接口的默认方法,有的话就设置到BeanDefinition中,第八步,如果就父类就把父类设置到BeanDefinition中,解析完成,所有设置好的BeanDefinition都保存到了解析类中
b2:[#aop1]调用invokeBeanDefinitionRegistryPostProcessors提供一个修改beanDefinition的机会
c.从BeanFactory中获取所有实现beanPostProcessors接口的类,并注册到BeanFactory中
d.调用finishBeanFactoryInitialization(),实例化所有已注册但还没创建bean的BeanDefinition,通常我们自己写的service、component都是在此注入到容器:
d1:循环处理BeanFactory(也就是容器Context)中的每一个BeanDefinition,检查是否实现了FactoryBean接口,如果是则将BeanName前面加上&,进行处理;否则先从缓存中获取对象,缓存中没有,把beanName放进alreadyCreated的set集合中,开始创建
d2:检查是否有DependsOn(控制bean加载顺序),有则对每一个依赖项,进行处理:先检查是否有循环依赖,然后注册依赖关系,然后创建依赖的bean
d3:处理lookup-method
d4:调用实例化前置方法resolveBeforeInstantiation,提供短路操作:遍历所有实现InstantiationAwareBeanPostProcessor接口的类,调用实例化前置方法postProcessBeforeInstantiation;如果得到了一个不为null的bean,则调用BeanPostProcessor.postProcessAfterInitialization初始化后置方法;最终得到的bean如果不为null,那么bean创建成功,直接返回d2
d5:创建一个BeanWrapper:此时实例化,通过反射创建一个实例,放进BeanWrapper
d6:判断bean是单例并且beanfactory允许循环依赖并且当前bean正在创建,那么就需要提早暴露这个单例bean,把它加入到注册单例set中
d7:填充属性:循环调用实例化后置方法InstantiationAwareBeanPostProcessor.postProcessAfterInstantiation,接着循环调用InstantiationAwareBeanPostProcessor.postProcessProperties属性填充后置方法(通过反射对@Autowire、@Resource、@Value进行设置)和InstantiationAwareBeanPostProcessor.postProcessPropertyValues,接着从beanDefinition中获取所有属性值,注入到bean中
d8:开始初始化
d81:对实现Aware接口的类设置属性
d82:调用BeanPostProcessor.postProcessBeforeInitialization初始化前置方法。@PostConstruct是通过扩展这个方法来实现初始化动作
d83:如果实现了InitializingBean接口,那么执行它的afterPropertiesSet方法;
如果配置了自定义的InitMethod,就调用自定义的初始化方法
d84:调用BeanPostProcessor.postProcessAfterInitialization初始化后置方法。至此,bean创建结束
d9:把bean添加到beanFactory
⑥:创建一个TomcatServer并启动
aop流程
@aspect的类都会加上@component注解注入spring,有这个注解就要创建bean.
1)[#aop1]这里会创建一个beanDefinition(InfrastructureAdvisorAutoProxyCreator)到beanfactory。它实现了BeanPostProcessor,在其他bean初始化后会调用它的postProcessAfterInitialization
2)会获取beanfactory中的所有的beanNames,根据beanname获取class,判断class上如果有aspect注解,那么解析这个class,获取所有没有被@pointcut注解的方法,循环解析这些方法,解析到aspectJAnnotation表达式,则包装成一个AspectJExpressionPointcut切点表达式切入点对象(即包含execution表达式的对象),最后再和当前class包装成Advisor对象.这样通过解析class的aspect方法得到了一个advisor的list集合.最后得到了所有的通知器advisors,并放入缓存。这样就完成了@aspect的类的解析和通知器的设置
上面并不会通过捷径创建代理类,对aop来说只是解析,还是要走正常的创建bean的流程。
3)在初始化bean的最后一步,会调用BeanPostProcessor.postProcessAfterInitialization初始化后置处理方法,这时会进入AbstractAutoProxyCreator.postProcessAfterInitialization方法内,对所有的bean判断,先获取所有advisor,(如果缓存有则拿缓存,没有则进入2)),如果bean中有方法能匹配到通知器advisors中的表达式[#springboot事物],那么开始创建代理类
4)先创建代理工厂AopProxy,此时会选择使用cglib还是jdk。
①是否启用优化optimize。由于 cglib的动态代理创建类比较慢,但是执行代码比较快,jdk动态代理相反,创建比较快,执行比较慢。如果配置了optimize=true,那么目标类实现了接口就使用jdk代理,否则就用cglib。默认是false。
②proxyTargetClass 是否强制使用cglib实现代理。默认是false
③目标接口是否是SpringProxy的子接口
上面三个条件如果都为false,则直接走jdk,否则需要判断,目标类是接口类或者目标类是SpringProxy的子接口,那么走jdk,否则走cglib。
5)创建完成开始获取代理类,然后注入到beanFactory中
jdk的getProxy:生成的代理类CglibAopProxy
cglib的getProxy:生成的代理类JdkDynamicAopProxy
springAop的调用逻辑:
当调用目标类的方法时,如果是cglib代理,代理类CglibAopProxy调用内部类DynamicAdvisedInterceptor的intercept代理方法,如果是jdk代理,代理类执行invoke代理方法
cglib的代理方法intercept():
①首先根据目标方法,获取匹配到的拦截器:
获取目标类相关的所有通知器,判断类和方法均能匹配上的话,就生成一个拦截器集合[#springboot事物调用][这里如果有事务也会获取到事务拦截器],这里spring事物的拦截器也是在这里获得
②如果拦截器数组是空并且方法是public,直接通过反射调用该方法;
否则,调用MethodInterceptor的proceed方法
③proceed方法:这里会取出拦截器数组的所有MethodInterceptor,然后执行他们的invoke方法[#springboot事物调用]
比如@AfterThrowing在调用结果异常时执行,逻辑就是try继续执行proceed方法向下传递,但是catch里回去异常然后反射调用业务方法.见AspectJAfterThrowingAdvice
@AfterReturning逻辑是先执行proceed方法,然后执行AfterReturn的业务逻辑,所以如果proceed抛异常,AfterReturn的业务逻辑不会执行
@After逻辑是try proceed方法,finnally里执行after逻辑。不管正常还是异常都会执行逻辑
@Around逻辑是生成一个JoinPoint对象,然后进行参数绑定JoinPoint,然后反射调用around逻辑,around逻辑里可以直接返回数据,也可以继续传递调用proceed方法
@before逻辑先绑定JoinPoint通过反射执行before逻辑,然后继续执行proceed
最后一次执行proceed方法时会发现拦截器链已执行完毕,就通过代理方法反射调用目标方法
所以业务逻辑先后顺序是@Around->@before->目标方法->@after->@afterreturn->@afterthrowing,其中@around提供了JoinPoint.proceed()方法让它自己选择是否继续proceed(),其他方法都只是单纯的业务方法,如果@around不执行proceed()自己返回一个对象,那么@Around->@after->@afterreturn->@afterthrowing,原因是拦截器链生成的时候是有序的,按照@afterthrowing->@afterreturn->@after->@Around->@before的调用顺序,如果@around不proceed,那么before和目标方法当然不执行
spring aop
Spring中的事务
[#springboot事物调用]
这里spring事务,则执行事务拦截器的TransactionInterceptor.invoke(),具体逻辑invokeWithinTransaction
1)首先获取事务的各种配置属性:解析方法上面的@transactional注解,因为注解上可以附带很多属性,就在这里解析,这样就得到了TransactionAttribute 对象
2)根据配置属性获取事务管理器,如果不配置会有一个default事务管理器
创建一个事务信息对象TransactionInfo,保存所有相关信息
3)开启事务,
4)通过反射调用目标方法(有人说这个地方和@around类似),
5)如果抛出异常,则catch 然后回滚事务,throw这个异常;
如何回滚completeTransactionAfterThrowing:
判断异常如果是 RuntimeException 类型异常或者 是 Error 类型的,就回滚。这就是默认的回滚策略。
为true,就执行事务管理器的rollback,首先关闭sqlsession对象,从数据库连接持有对象中获取数据库连接Connection,调用connection.rollback方法完成回滚。后面的sql底层。
6)finally释放事务相关资源
7)如果没有异常,提交事务,返回返回值
事务回滚提交,其实都是事务管理器里保存有jdbc的connection,通过这个connection来执行提交或回滚。
如何提交commitTransactionAfterReturning:从数据库连接持有对象中获取数据库连接Connection,调用connection.commit方法完成提交
springboot事务和aop基本一样
织入点:跟springaop一样,@transactional相当于@Around
调用:跟springaop一样
DispatcherServlet请求流转过程
请求的入口是一个Thread的run(),最终会经过DispatcherServlet来处理。流程为
1)给request设置属性,最主要的是WebApplicationContext
2)获取HandlerExecutionChain拦截执行链:
a.循环处理所有的HandlerMapping,匹配上最佳的HandlerMapping。因为通过web请求,匹配上的是RequestMappingHandlerMapping,经过它的处理,返回了一个封装的handlerMethod对象,包含了调用的是哪个controller、哪个方法、参数等信息
b.对RequestMappingHandlerMapping里的Interceptor列表循环匹配得到的handlerMethod,匹配的上得到一个Interceptor链
3)匹配HandlerAdapter:DispatcherServlet中的HandlerAdapter循环匹配,最终匹配到RequestMappingHandlerAdapter
4)执行执行链的applyPreHandle():循环执行Interceptor链
的每个Interceptor的preHandle(),如果有一个返回false,就循环执行每一个Interceptor的afterCompletion(),退出;否则preHandle()执行完全
5)开始执行
a.解析参数
b.通过反射调用真实方法即controller的方法得到ModeleAndView
6)循环执行Interceptor链的PostHandle
7)执行Interceptor链的triggerAfterCompletion
结论:afterCompletion一定会执行,PreHandler不一定会执行完全
执行顺序:Filter->Interceptor.preHandle->Handler->Interceptor.postHandle->Interceptor.afterCompletion->Filter

设计模式
六大原则
开闭原则:对扩展开放,对修改关闭
里氏代换原则:任何基类可以出现的地方,子类一定可以出现。抽象化
依赖倒转原则:针对接口编程,依赖于抽象而不依赖于具体
接口隔离原则:使用多个隔离的接口,比使用单个接口要好。它还有另外一个意思是:降低类之间的耦合度
迪米特法则,又称最少知道原则:一个实体应当尽量少地与其他实体之间发生相互作用,使得系统功能模块相对独立
合成复用原则:尽量使用合成/聚合的方式,而不是使用继承