Hadoop入门学习笔记——四、MapReduce的框架配置和YARN的部署
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7
课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd=5ay8
Hadoop入门学习笔记(汇总)
目录
- 四、MapReduce的框架配置和YARN的部署
-
- 4.1. 配置MapReduce和YARN
- 4.2. YARN集群启停脚本
-
- 4.2.1. 一键启停脚本
- 4.2.2. 单独进程启停
- 4.3. 提交MapReduce示例程序到YARN运行
-
- 4.3.1. 提交wordcount(单词统计)示例程序
- 4.3.2. 提交根据Monte Carlo蒙特卡罗算法求圆周率的示例程序
四、MapReduce的框架配置和YARN的部署
本次YARN的部署结构如下图所示:

当前,共有三台服务器(虚拟机)构成集群,集群规划如下所示:
| 主机 | 部署的服务 |
|---|---|
| node1 | ResourceManager、NodeManager、ProxyServer、JobHistoryServer |
| node2 | NodeManager |
| node3 | NodeManager |
MapReduce是运行在YARN上的,所以MapReduce只需要配置,YARN需要部署并启动。
4.1. 配置MapReduce和YARN
1、在node1节点,修改mapred-env.sh文件:
# 进入hadoop配置文件目录
cd /export/server/hadoop-3.3.4/etc/hadoop/
# 打开mapred-env.sh文件
vim mapred-env.sh
打开后,在文件中加入以下内容:
# 设置JDK路径
export JAVA_HOME=/export/server/jdk
# 设置JobHistoryServer进程的内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
# 设置日志级别为INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
2、再修改同目录下的mapred-site.xml配置文件,在其configuration标签内增加以下内容:
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<description>description>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node1:10020value>
<description>description>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node1:19888value>
<description>description>
property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dirname>
<value>/data/mr-history/tmpvalue>
<description>description>
property>
<property>
<name>mapreduce.jobhistory.done-dirname>
<value>/data/mr-history/donevalue>
<description>description>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOMEvalue>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOMEvalue>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOMEvalue>
property>
其中,
mapreduce.framework.name 表示MapReduce的运行框架,这里设置为Yarn;
mapreduce.jobhistory.address 表示历史服务器通讯地址和端口号,这里为node1:10020;
mapreduce.jobhistory.webapp.address 表示历史服务器Web端地址和端口号,这里为node1:19888;
mapreduce.jobhistory.intermediate-done-dir 表示历史信息在HDFS的记录临时路径,这里是/data/mr-history/tmp;
mapreduce.jobhistory.done-dir 表示历史信息在HDFS的记录路径,这里是/data/mr-history/done;
yarn.app.mapreduce.am.env 表示MapReduce HOME的路径,这里设置为HADOOP_HOME相同路径;
mapreduce.map.env 表示Map HOME的路径,这里设置为HADOOP_HOME相同路径;
mapreduce.reduce.env 表示Reduce HOME的路径,这里设置为HADOOP_HOME相同路径;
至此,MapReduce的配置完成。
3、接下来,配置YARN。在node1节点,修改yarn-env.sh文件:
# 进入hadoop配置文件目录
cd /export/server/hadoop-3.3.4/etc/hadoop/
# 打开yarn-env.sh文件
vim yarn-env.sh
在文件中添加以下内容:
# 设置JDK路径的环境变量
export JAVA_HOME=/export/server/jdk
# 设置HADOOP_HOME的环境变量
export HADOOP_HOME=/export/server/hadoop
# 设置配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# 设置日志文件路径的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
4、修改同目录下的yarn-site.xml配置文件,在其configuration节点中添加以下内容:
<property>
<name>yarn.log.server.urlname>
<value>http://node1:19888/jobhistory/logsvalue>
<description>description>
property>
<property>
<name>yarn.web-proxy.addressname>
<value>node1:8089value>
<description>proxy server hostname and portdescription>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
<description>Configuration to enable or disable log aggregationdescription>
property>
<property>
<name>yarn.nodemanager.remote-app-log-dirname>
<value>/tmp/logsvalue>
<description>Configuration to enable or disable log aggregationdescription>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>node1value>
<description>description>
property>
<property>
<name>yarn.resourcemanager.scheduler.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairSchedulervalue>
<description>description>
property>
<property>
<name>yarn.nodemanager.local-dirsname>
<value>/data/nm-localvalue>
<description>Comma-separated list of paths on the local filesystem where intermediate data is written.description>
property>
<property>
<name>yarn.nodemanager.log-dirsname>
<value>/data/nm-logvalue>
<description>Comma-separated list of paths on the local filesystem where logs are written.description>
property>
<property>
<name>yarn.nodemanager.log.retain-secondsname>
<value>10800value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.description>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
<description>Shuffle service that needs to be set for Map Reduce applications.description>
property>
其中,核心配置如下:
yarn.resourcemanager.hostname 表示ResourceManager设置在哪个节点,这里是node1节点;
yarn.nodemanager.local-dirs 表示NodeManager中间数据Linux系统本地存储的路径;
yarn.nodemanager.log-dirs 表示NodeManager数据Linux系统日志本地存储的路径;
yarn.nodemanager.aux-services 表示为MapReduce程序开启Shuffle服务;
额外配置如下:
yarn.log.server.url 表示历史服务器的URL;
yarn.web-proxy.address 表示代理服务器的主机和端口号;
yarn.log-aggregation-enable 表示是否开启日志聚合;
yarn.nodemanager.remote-app-log-dir 表示程序日志在HDFS中的存放路径;
yarn.resourcemanager.scheduler.class 表示选择Yarn使用的调度器,这里选的是公平调度器;
5、完成上述配置后,需要将MapReduce和YARN的配置文件分发到node2和node3服务器相同位置中,使用hadoop用户身份执行以下命令
# 将mapred-env.sh、mapred-site.xml、yarn-env.sh、yarn-site.xml四个配置文件,复制到node2的相同路径下
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/
# 将mapred-env.sh、mapred-site.xml、yarn-env.sh、yarn-site.xml四个配置文件,复制到node3的相同路径下
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/
4.2. YARN集群启停脚本
在启动YARN集群前,需要确保HDFS集群已经启动。同样,启停YARN集群也必须使用hadoop用户身份。
4.2.1. 一键启停脚本
$HADOOP_HOME/sbin/start-yarn.sh或start-yarn.sh一键启动YARN集群
- 会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager;
- 会基于workers文件配置的主机启动NodeManager;
- 在当前机器启动ProxyServer(代理服务器)。
命令执行效果如下图所示:

此时通过jps命令查看进程,可以看到如下效果:

此时,可以看到ResourceManager、NodeManager和WebAppProxyServer都已经启动,还需要启动HistoryServer,可以通过后续章节介绍的mapred --daemon start historyserver命令启动。
至此,整个YARN集群启动完成。
此时,可以通过访问http://node1:8088/ 即可看到YARN集群的监控页面(即ResourceManager的WebUI)
$HADOOP_HOME/sbin/stop-yarn.sh或stop-yarn.sh一键关闭YARN集群。- 配置部署好YARN集群后,可以关闭YARN集群、关闭JobHistoryServer、关闭HDFS集群、关闭虚拟机之后,对虚拟机创建快照,保存好当前环境。
4.2.2. 单独进程启停
- 在每一台机器,单独启动或停止进程,可以通过如下命令执行:
$HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager|proxyserver
start和stop决定启动和停止;
可控制resourcemanager、nodemanager、webappproxyserver三种进程。
例如:
# 在node1启动ResourceManager
yarn --daemon start resourcemanager
# 在node1、node2、node3分别启动NodeManager
yarn --daemon start nodemanager
# 在node1启动WebProxyServer
yarn --daemon start proxyserver
- 历史服务器(JobHistoryServer)的启动和停止
$HADOOP_HOME/bin/mapred --daemon start|stop historyserver
用法:
# 启动JobHistoryServer
mapred --daemon start historyserver
# 停止JobHistoryServer
mapred --daemon stop historyserver
4.3. 提交MapReduce示例程序到YARN运行
YARN作为资源调度管控框架,其本身提供资供许多程序运行,常见的有:
- MapReduce程序
- Spark程序
- Flink程序
Hadoop官方提供了一些预置的MapReduce程序代码,存放于$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar文件内。
上述程序可使用hadoop har命令提交至YARN运行,其命令语法为:
hadoop jar 程序文件 java类名 [程序参数] ... [程序参数]
4.3.1. 提交wordcount(单词统计)示例程序
1、程序内容
- 给定数据输入的路径(HDFS)、给定结果输出的路径(HDFS)
- 将输入路径内的数据中的单词进行计数,将结果写到输出路径
2、准备一份待统计的数据文件并上传至HDFS中
使用vim words.txt命令,在Linux本地创建words.txt文件,其内容如下:
itheima itcast itheima itcast
hadoop hdfs hadoop hdfs
hadoop mapreduce hadoop yarn
itheima hadoop itcast hadoop
itheima itcast hadoop yarn mapreduce
使用命令hdfs dfs -mkdir -p /input在HDFS根目录创建input文件夹(用于存储待统计的文件),使用hdfs dfs -mkdir -p /output命令在HDFS根目录创建output文件夹(用于存储统计结果),使用hdfs dfs -put words.txt /input命令将本地的words.txt文件上传至HDFS系统中。
3、提交MapReduce程序
使用如下命令:
hadoop jar /export/server/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount hdfs://node1:8020/input/ hdfs://8020/output/wc
其中,
hadoop jar 表示向YARN提交一个Java程序;
/export/server/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar 表示所要提交的程序路径;
wordcount 表示要运行的java类名;
hdfs://node1:8020/input/ 表示参数1,在本程序中是待统计的文件夹,这里写了hdfs协议头,指明了是HDFS文件系统的路径(经测试,不写也可以,默认读取HDFS文件系统路径);
hdfs://8020/output/wc 表示参数2,在本程序中是统计结果输出的文件夹,这里写明了hdfs协议头,指明了是HDFS文件系统的路径(经测试,不写也可以,默认读取HDFS文件系统路径),这里需要确保该文件夹不存在,否则会报错。
运行日志如下所示:
[hadoop@node1 ~]$ hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount hdfs://node1:8020/input hdfs://node1:8020/output/wc
2023-12-14 15:31:53,988 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at node1/192.168.88.101:8032
2023-12-14 15:31:55,818 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1702538855741_0001
2023-12-14 15:31:56,752 INFO input.FileInputFormat: Total input files to process : 1
2023-12-14 15:31:57,040 INFO mapreduce.JobSubmitter: number of splits:1
2023-12-14 15:31:57,607 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1702538855741_0001
2023-12-14 15:31:57,607 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-12-14 15:31:58,167 INFO conf.Configuration: resource-types.xml not found
2023-12-14 15:31:58,170 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-12-14 15:31:59,119 INFO impl.YarnClientImpl: Submitted application application_1702538855741_0001
2023-12-14 15:31:59,406 INFO mapreduce.Job: The url to track the job: http://node1:8089/proxy/application_1702538855741_0001/
2023-12-14 15:31:59,407 INFO mapreduce.Job: Running job: job_1702538855741_0001
2023-12-14 15:32:23,043 INFO mapreduce.Job: Job job_1702538855741_0001 running in uber mode : false
2023-12-14 15:32:23,045 INFO mapreduce.Job: map 0% reduce 0%
2023-12-14 15:32:37,767 INFO mapreduce.Job: map 100% reduce 0%
2023-12-14 15:32:50,191 INFO mapreduce.Job: map 100% reduce 100%
2023-12-14 15:32:51,220 INFO mapreduce.Job: Job job_1702538855741_0001 completed successfully
2023-12-14 15:32:51,431 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=84
FILE: Number of bytes written=553527
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=248
HDFS: Number of bytes written=54
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=11593
Total time spent by all reduces in occupied slots (ms)=9650
Total time spent by all map tasks (ms)=11593
Total time spent by all reduce tasks (ms)=9650
Total vcore-milliseconds taken by all map tasks=11593
Total vcore-milliseconds taken by all reduce tasks=9650
Total megabyte-milliseconds taken by all map tasks=11871232
Total megabyte-milliseconds taken by all reduce tasks=9881600
Map-Reduce Framework
Map input records=6
Map output records=21
Map output bytes=233
Map output materialized bytes=84
Input split bytes=98
Combine input records=21
Combine output records=6
Reduce input groups=6
Reduce shuffle bytes=84
Reduce input records=6
Reduce output records=6
Spilled Records=12
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=300
CPU time spent (ms)=2910
Physical memory (bytes) snapshot=353423360
Virtual memory (bytes) snapshot=5477199872
Total committed heap usage (bytes)=196218880
Peak Map Physical memory (bytes)=228843520
Peak Map Virtual memory (bytes)=2734153728
Peak Reduce Physical memory (bytes)=124579840
Peak Reduce Virtual memory (bytes)=2743046144
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=150
File Output Format Counters
Bytes Written=54
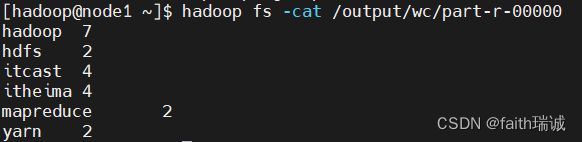
4、查看运行结果
运行完毕后,使用hadoop fs -ls /output/wc可以看到运行结果输出的文件

使用hadoop fs -cat /output/wc/part-r-00000命令,可以看到程序运行的结果
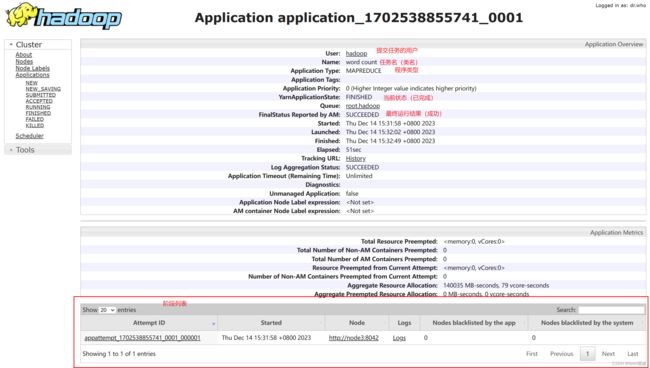
除此之外,在YARN集群的监控页面http://node1:8088/ 点击左侧的Applications菜单,可以看到刚才运行过的任务

再点击任务的ID,可以进入任务详情页面
再点击某一个阶段的Logs链接,可以看到对应阶段的运行的客户端日志(在配置yarn-site.xml文件时,配置了开启日志聚合),这个页面本质上是JobHistoryServer提供的页面(19888端口)

在任务详情页面点击History链接,可以看到任务的历史运行状态,在其中可以看到其Map任务和Reduce任务,也可以继续点进Map和Reduce任务查看相关的日志等信息,对于程序出错时的排查很有帮助。

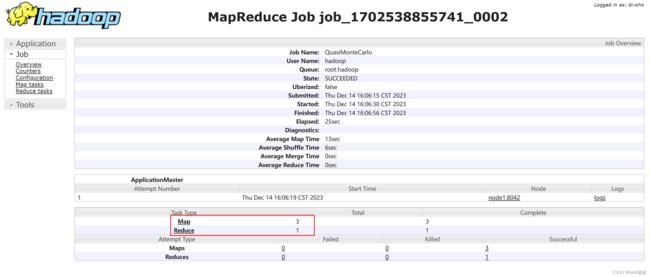
4.3.2. 提交根据Monte Carlo蒙特卡罗算法求圆周率的示例程序
1、提交程序
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar pi 3 1000
hadoop jar 表示向YARN提交一个Java程序;
/export/server/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar 表示所要提交的程序路径;
pi 表示运行的Java类名;
3 表示使用3个Map任务;
1000 表示样本数为1000,样本数越多,求得的圆周率越准确,但是程序运行时长越长。
运行日志如下所示:
[hadoop@node1 ~]$ hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar pi 3 1000
Number of Maps = 3
Samples per Map = 1000
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Starting Job
2023-12-14 16:06:12,042 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at node1/192.168.88.101:8032
2023-12-14 16:06:13,550 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1702538855741_0002
2023-12-14 16:06:13,888 INFO input.FileInputFormat: Total input files to process : 3
2023-12-14 16:06:14,149 INFO mapreduce.JobSubmitter: number of splits:3
2023-12-14 16:06:14,658 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1702538855741_0002
2023-12-14 16:06:14,659 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-12-14 16:06:15,065 INFO conf.Configuration: resource-types.xml not found
2023-12-14 16:06:15,065 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-12-14 16:06:15,256 INFO impl.YarnClientImpl: Submitted application application_1702538855741_0002
2023-12-14 16:06:15,403 INFO mapreduce.Job: The url to track the job: http://node1:8089/proxy/application_1702538855741_0002/
2023-12-14 16:06:15,404 INFO mapreduce.Job: Running job: job_1702538855741_0002
2023-12-14 16:06:32,155 INFO mapreduce.Job: Job job_1702538855741_0002 running in uber mode : false
2023-12-14 16:06:32,156 INFO mapreduce.Job: map 0% reduce 0%
2023-12-14 16:06:47,156 INFO mapreduce.Job: map 67% reduce 0%
2023-12-14 16:06:50,188 INFO mapreduce.Job: map 100% reduce 0%
2023-12-14 16:06:57,275 INFO mapreduce.Job: map 100% reduce 100%
2023-12-14 16:06:58,328 INFO mapreduce.Job: Job job_1702538855741_0002 completed successfully
2023-12-14 16:06:58,589 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=72
FILE: Number of bytes written=1108329
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=786
HDFS: Number of bytes written=215
HDFS: Number of read operations=17
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=3
Launched reduce tasks=1
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=39354
Total time spent by all reduces in occupied slots (ms)=7761
Total time spent by all map tasks (ms)=39354
Total time spent by all reduce tasks (ms)=7761
Total vcore-milliseconds taken by all map tasks=39354
Total vcore-milliseconds taken by all reduce tasks=7761
Total megabyte-milliseconds taken by all map tasks=40298496
Total megabyte-milliseconds taken by all reduce tasks=7947264
Map-Reduce Framework
Map input records=3
Map output records=6
Map output bytes=54
Map output materialized bytes=84
Input split bytes=432
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=84
Reduce input records=6
Reduce output records=0
Spilled Records=12
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=699
CPU time spent (ms)=11980
Physical memory (bytes) snapshot=775233536
Virtual memory (bytes) snapshot=10945183744
Total committed heap usage (bytes)=466890752
Peak Map Physical memory (bytes)=227717120
Peak Map Virtual memory (bytes)=2734153728
Peak Reduce Physical memory (bytes)=113000448
Peak Reduce Virtual memory (bytes)=2742722560
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=354
File Output Format Counters
Bytes Written=97
Job Finished in 46.895 seconds
Estimated value of Pi is 3.14133333333333333333
2、查看运行情况
在在YARN集群的监控页面,可以查看对应任务的History信息,可以看到当前任务使用了3个Map任务和1个Reduce任务,同时,也可以查看相应的运行日志信息。