【高光谱一】2022 TGRS Confident Learning-Based Domain Adaptation for Hyperspectral Image Classification
1.motivation
跨域高光谱图像分类是遥感领域面临的主要挑战之一。为了获得更好的统计一致性,现有方法以无监督的方式使用整个未评估的目标数据,这可能会引入噪声并限制神经网络的可判别性。在本文中,提出了基于置信学习的领域自适应(CLDA)从数据操作的新角度来解决这个问题。为此,提出了一种新的框架,将领域自适应与置信学习相结合,前者减少域间差异并为目标实例生成伪标签,后者从中选择高置信度的目标样本。具体来说,置信学习部分根据给定的标签和预测概率对每个伪标记目标样本的置信度进行评估。然后,选择高置信度的目标样本作为训练数据,提高神经网络的判别能力。另外,交替训练领域适应部分和置信学习部分,逐步增加目标领域中高置信标签的比例,从而进一步提高分类的准确率。在4个数据集上的实验结果表明,所提出的CLDA方法优于目前最先进的领域自适应方法。
置信学习(CL)的方法,通过描述和识别数据集中的标签错误来关注标签质量。置信学习方法基于对噪声数据进行剪枝的原理,用概率阈值估计噪声,并对样本进行排序进行置信训练。在置信学习的启发下,根据目标数据的置信度对伪标签进行排序,去除有噪声的伪标签。
2.问题定义
本文采用了双分类器对抗域自适应和置信学习。在域自适应中,双分类器(C1和C2)输出两个概率向量p1和p2 (p1, p2∈RK ×1)来优化损失函数并更新神经网络,其中K为类别数。特征融合分类以双分类器的最后一层特征(在softmax之前)作为输入,选取两个特征之和的最大元素作为伪标签。由此得到所有目标实例的伪标签![]() 。置信学习用于去除标记数据集上的噪声数据,并保留干净的数据用于模型训练。在置信学习中,采用SVM分类器估计预测概率,
。置信学习用于去除标记数据集上的噪声数据,并保留干净的数据用于模型训练。在置信学习中,采用SVM分类器估计预测概率,![]() 。因此,每个目标样本都有一个伪标签和一个预测概率。这样就得到了置信联合矩阵
。因此,每个目标样本都有一个伪标签和一个预测概率。这样就得到了置信联合矩阵![]() ,并对
,并对![]() 进行了归一化,可以得到联合分布矩阵
进行了归一化,可以得到联合分布矩阵![]() 。其中,高置信度的伪标签称为置信标签,
。其中,高置信度的伪标签称为置信标签,![]() ,其中,
,其中,![]() 为置信标签的个数,
为置信标签的个数,![]() 为目标域的置信样本,类权值
为目标域的置信样本,类权值![]() 用于更新神经网络时对实例进行加权。
用于更新神经网络时对实例进行加权。
3.method

从源域(蓝线)和目标域(橙色线),两个高光谱图像patch∈R5×5×ch, ch和5×5表示光谱波段和空间维度,分别输入特征提取器E .然后,特征提取的源和目标域(黑线)被送入两个分类器C1和C2,这两个分类器产生p1和p2,然后利用这些特征预测概率。使用p1和p2来输入损失函数,从而更新E、C1和C2。为了预测目标实例的伪标签Y,取C1和C2的最后一层特征(没有softmax),并通过求和来融合这两个特征。然后,选择融合特征的最大元素对应的类别作为伪标签。置信学习尝试评估伪标签![]() ,并从中选择置信标签
,并从中选择置信标签![]() 。引入支持向量机分类器来获得目标域样本的预测概率
。引入支持向量机分类器来获得目标域样本的预测概率![]() 。在此基础上,右上矩阵
。在此基础上,右上矩阵![]() 由
由![]() 和
和![]() 得到。它是一个计数矩阵,用于计算标签错误的样本数量。将
得到。它是一个计数矩阵,用于计算标签错误的样本数量。将![]() 归一化得到
归一化得到![]() 用于求伪标签。通过剪枝操作,将伪标签分为可信标签和不可信标签。然后,选择具有置信度标签的目标样本作为领域自适应部分的训练数据。
用于求伪标签。通过剪枝操作,将伪标签分为可信标签和不可信标签。然后,选择具有置信度标签的目标样本作为领域自适应部分的训练数据。
A.领域自适应
特征提取器通过最小化分类器差异来更新,而双分类器通过最大化差异来优化。受双分类器确定性最大化的启发,使用分类器确定性差异(CDD)来度量分类器的差异。通过这种对抗性学习,双分类器域自适应部分可以对齐源域和目标域的分布。CLDA方法的损失函数定义为
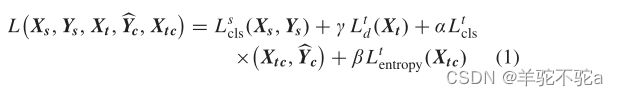
第一项表示标记的源域样本上的分类损失,
第二项表示未标记的目标域样本上的CDD损失,
第三项表示带置信标签的目标域样本上的分类损失,
第四项表示目标域样本上的熵正则化损失。
γ, α, 和β是权衡超参数。在CLDA网络中,特征提取器E和两个分类器(C1和C2)通过以下四个损失进行训练。
1)源分类损失:这是一种交叉熵损失。
将标记好的源域样本送入特征提取器E中提取特征。源特征用于训练分类器C1和C2。通过最小化源分类损失来更新E、C1和C2
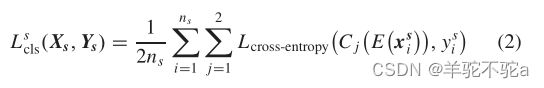
2) CDD损失:
将分类器差异表述为不同目标预测的类相关性;同时,对目标特征的可分辨性进行了隐式约束。具体来说,两个概率矩阵p1和p2由两个分类器(C1和C2)得到。冻结E的参数,并通过最大化两个分类器之间的差异![]() 来更新C1和C2。定义如下:
来更新C1和C2。定义如下:
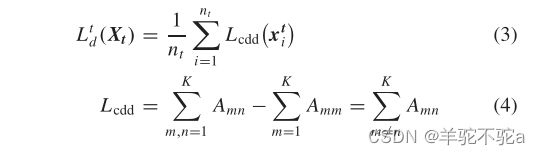
Lcdd为测量分类器差异的CDD损失,m, n∈{1,2,3,…K},A为预测相关性矩阵,用于表示分类器之间的差异。可以定义为![]() ,p1,p2是两个分类器输出的softmax概率,满足
,p1,p2是两个分类器输出的softmax概率,满足![]() 。
。![]() 为C1将样本分类为m类和C2将样本分类为n类的概率乘积。通过对CDD损失进行逆向优化,可以同时增强分类器的确定性和预测多样性。这样,域间差异也减小了。
为C1将样本分类为m类和C2将样本分类为n类的概率乘积。通过对CDD损失进行逆向优化,可以同时增强分类器的确定性和预测多样性。这样,域间差异也减小了。
3) 目标分类损失:
当目标域有置信标签时,使用这些置信标签进一步提高模型的可判别性。设Ltcls为目标域具有置信标签的分类损失,可表示为
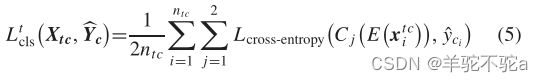
其中,cj (E(x tci))表示预测值。交叉熵损失的权重设置为![]() 。
。
4)熵正则化:
对于目标域,置信学习选择的置信样本的标签可能是不准确的;因此,通过约束目标域样本的预测概率来保证类之间的低密度分离。对于目标域的概率预测结果,期望概率预测输出呈峰值分布(交叉熵值大),而不是平滑分布
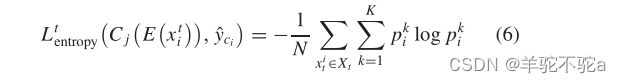
其中![]() 是两个分类器在目标域中预测的概率的平均值。熵正则化损失在经过置信学习部分的数据清洗后,利用目标实例来保证特征的可判别性。
是两个分类器在目标域中预测的概率的平均值。熵正则化损失在经过置信学习部分的数据清洗后,利用目标实例来保证特征的可判别性。
B.置信学习
置信学习有两个输入:带噪声的伪标签![]() 和预测概率
和预测概率![]() 。计算C1和C2的最后一层特征向量的和,并选择最大概率对应类别作为该样本的伪标签。另一方面,采用SVM分类器估计目标样本的预测概率
。计算C1和C2的最后一层特征向量的和,并选择最大概率对应类别作为该样本的伪标签。另一方面,采用SVM分类器估计目标样本的预测概率![]() ,使用源域数据训练SVM分类器,使得根据
,使用源域数据训练SVM分类器,使得根据![]() 进行的分类与
进行的分类与![]() 不同。E提取的源特征被输入到SVM中,相关的标签在这个训练阶段只用于更新SVM分类器的参数,而不用于更新特征提取器E的参数。
不同。E提取的源特征被输入到SVM中,相关的标签在这个训练阶段只用于更新SVM分类器的参数,而不用于更新特征提取器E的参数。
因此,每个目标样本![]() 可以评估其属于一个类别
可以评估其属于一个类别 的置信度,可表示为
的置信度,可表示为![]() 或
或![]() 。由于目标域样本不存在真值标签
。由于目标域样本不存在真值标签 ,因此本文认为SVM预测的结果可信且接近真值标签。
,因此本文认为SVM预测的结果可信且接近真值标签。
置信学习的过程可以分为两个步骤:
1)估计伪标签![]() 和真标签(由
和真标签(由![]() 估计)的联合分布矩阵
估计)的联合分布矩阵![]() ,以得到伪标签的置信度;
,以得到伪标签的置信度;
2)根据其置信度找到不可信的标签并进行剪枝。
首先,由![]() 和
和![]() 得到一个置信的联合矩阵
得到一个置信的联合矩阵![]() 来划分和计数标签误差。对于目标域,
来划分和计数标签误差。对于目标域,![]() 表示带有伪标记
表示带有伪标记 的样本
的样本 ,实际上具有真正的标签。也就是说,对于伪标签为i的样本输入到SVM中,得到标签为j的概率大于等于阈值
,实际上具有真正的标签。也就是说,对于伪标签为i的样本输入到SVM中,得到标签为j的概率大于等于阈值![]() (即SVM中属于类j的概率均值)的样本,即伪标签≠预测标签,即标签错误,计入
(即SVM中属于类j的概率均值)的样本,即伪标签≠预测标签,即标签错误,计入![]() 中。自动阈值方法使置信学习对类不平衡和异构类概率分布具有鲁棒性。因此,置信联合矩阵可定义为:
中。自动阈值方法使置信学习对类不平衡和异构类概率分布具有鲁棒性。因此,置信联合矩阵可定义为:
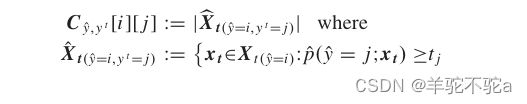
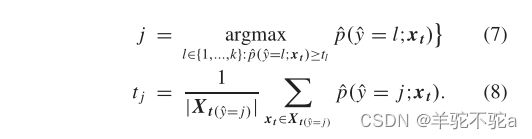
对![]() 进行归一化,得到联合分布矩阵
进行归一化,得到联合分布矩阵![]() 的估计
的估计

对![]() 进行估计后,采用PBC (prune by class按类修剪)方法对目标伪标签进行清理。对于每一类,首先根据置信
进行估计后,采用PBC (prune by class按类修剪)方法对目标伪标签进行清理。对于每一类,首先根据置信![]() 对(带伪标签i)的样本进行排序,然后选择最低置信
对(带伪标签i)的样本进行排序,然后选择最低置信![]() 的
的![]() 个样本作为不可信的标签并修剪它们。这样,得到置信标签
个样本作为不可信的标签并修剪它们。这样,得到置信标签![]() 。
。
由于不可信的标签被类智能地过滤掉,因此类别之间可信标签的数量可能不同。为了平衡类分布,计算类权重![]()

结果,将置信标签和样本![]() 输入特征提取器E,替换所有目标域样本
输入特征提取器E,替换所有目标域样本 ,并使用类权值
,并使用类权值![]() 重新加权每个类中的目标监督损失函数。
重新加权每个类中的目标监督损失函数。
这样,这些目标样本和它们的置信标签![]() 就可以像标记的源数据一样更新领域自适应部分的神经网络。
就可以像标记的源数据一样更新领域自适应部分的神经网络。
C.实现细节
为了充分利用目标域的置信样本,提高目标域的分类性能,CLDA方法的训练过程包括域适应和置信学习两个部分。在训练的早期阶段,目标领域中没有置信标签。
因此,首先使用标记的源数据Xs, Ys和未标记的目标数据训练特征提取器E和双分类器。在5个TRAIN_NUM epoch之后,分类器能够为目标样本提供伪标签。通过置信学习,选择置信标签及其相关样本![]() ,而不是整个目标数据,加入模型训练。一旦获得目标域的置信标签,就可以在训练域适应和置信学习之间迭代交替。整个训练过程详见算法1。
,而不是整个目标数据,加入模型训练。一旦获得目标域的置信标签,就可以在训练域适应和置信学习之间迭代交替。整个训练过程详见算法1。

一方面,将领域适应的对抗性训练过程分为三个步骤。
首先,利用标记的源域样本对特征提取器(E)和两个分类器(C1和C2)进行更新,提高了网络对源域样本的可分辨性;
当目标域有置信标签时,加入交叉熵损失和熵正则化损失,使网络对目标域样本更具判别性。它可以表示为
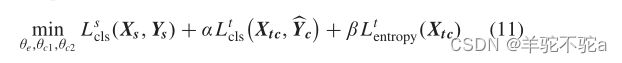
其中,θe, θc1, θc2为特征提取器和两个分类器的参数,置信学习开始前α = β = 0。
其次,利用目标域样本更新分类器并保持源域样本的准确率,公式为
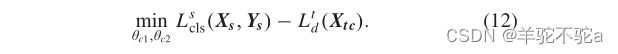
第三,使用未标记的目标域样本更新特征提取器,可以表示为:
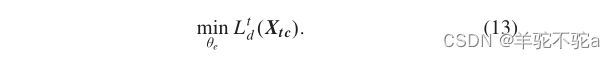
值得注意的是,特征融合分类结果![]() 不参与梯度反向传播。另一方面,利用置信学习寻找更精确的目标域样本,并使用置信标签,进一步监督分类器的训练,提高模型的可转移性。通过C1和C2的末层特征预测所有目标域样本得到伪标签
不参与梯度反向传播。另一方面,利用置信学习寻找更精确的目标域样本,并使用置信标签,进一步监督分类器的训练,提高模型的可转移性。通过C1和C2的末层特征预测所有目标域样本得到伪标签![]() 。
。
然后,利用源域特征对SVM分类器进行训练,对目标样本进行预测,得到预测概率![]() 。用
。用![]() 和
和![]() 对每个类别的样本数进行计数,得到矩阵
对每个类别的样本数进行计数,得到矩阵![]() 。将
。将![]() 归一化得到联合分布矩阵
归一化得到联合分布矩阵![]() 。
。![]() 可以计算出类权值,过滤掉不可信的标签,得到下一阶段训练的可信标签。
可以计算出类权值,过滤掉不可信的标签,得到下一阶段训练的可信标签。
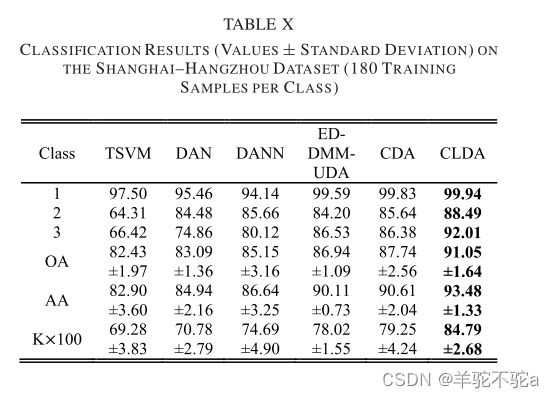
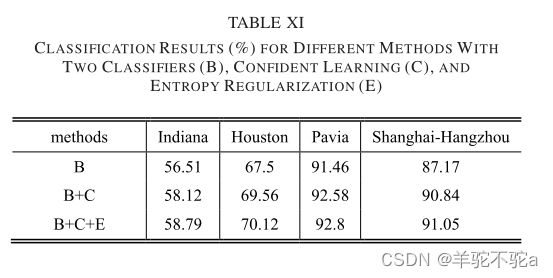
4.实验