C++学习笔记—— C++内存管理方式:new和delete操作符进行动态内存管理
系列文章目录
http://t.csdnimg.cn/d0MZH
目录
- 系列文章目录
-
- http://t.csdnimg.cn/d0MZH
- 比喻和理解
-
- a.比喻
-
- C语言开空间
- C++开空间
- b.理解
-
- a、C语言的内存管理的缺点
-
-
- 1、开发效率低(信息传递繁琐)
- 2、可读性低(信息展示混乱)
- 3、稳定性差(开空间可能失败)
- 代码演示
-
- b、C++的内存管理方式的优点
-
-
- 1、开发效率高、稳定
- 2、可读性高(信息集中、整洁)
-
- 一、C++又提出了自己的内存管理方式——通过new和delete操作符进行动态内存管理
-
- 1. 我们在建开辟空间时会发现我们有4个核心需求:
- 2. C++将开辟和释放分别集中在new和delete两个操作符实现:
- 3. new集成:malloc、抛异常、构造函数;delete集成free、抛异常、析构函数
- 4.new和delete内含的功能会根据具体的情况选择性发挥作用
- 二、 operator new与operator delete函数
-
- 1、 operator new与operator delete函数
- 三、内置类型
- 四、自定义类型
-
- 1、new的原理
- 2、delete的原理
- 3、new T[N]的原理
- 4、delete[ ]的原理
- 五、delete[ ]底层原理
- 六、定位new表达式(placement-new)
-
- 使用场景:
比喻和理解
C语言无法方便进行内存管理,C语言有关空间的所有操作都充满了冗余操作;
而C++通过new和delete操作符进行动态内存管理。
简而言之,C++对内存管理的创举主要是让我们输入的信息更高效的被编译器理解。
a.比喻
C语言开空间
打个比方,C语言开辟空间就像是:你要开席,你叫C语言去买10瓶可乐,C语言会做下面这些事:
问无效信息;
它一次只买一瓶,重复十次买一瓶的操作,它每买一瓶都问你去哪家店买、走哪条路;不会思考;
买可乐的预算有多少,购买策略要你全部说清楚,购买时遇到意料之外的情况就打电话问你;轻易放弃,结果不上报;
如果C语言在去的第一家商店购买失败,它就不买了,也不会主动报告购买失败,需要我们专门询问,要是不问C语言就放任错误发生;
C++开空间
而C++就像是:你叫C++去买10瓶可乐,它会问你一些信息,然后再做以下事情:
主动思考
C++会问你给它多少预算,给多少人喝,每人喝几杯,购买现场它根据这些信息自己决定购买策略。灵活多变
如C++在商店购买失败,它会自动换一家商店买。有责任感
换商店会一直换到成功为止,除非彻底买不到才打电话上报。
b.理解
a、C语言的内存管理的缺点
1、开发效率低(信息传递繁琐)
- 内存空间开辟需要显示定义
- 内存空间开辟代码编写繁琐
2、可读性低(信息展示混乱)
- 代码修改检查要反复对比
- 代码开空间显示不整齐
3、稳定性差(开空间可能失败)
- 就算声明了开空间,也不确定有没有开空间
- 开空间失败不自动报警,需要我们设置报警
代码演示
如下代码,我们的计划实现:
- 开一块空间存 int 类型的数据;
- 开辟这块空间并且初始化;
- 在原空间的基础上扩容;
为了实现以上功能,我们要写大量和我们的意图没有任何关系的内容。
代码演示:用C语言的方法开辟空间,可以看到这些代码是非常冗余的:
void Test()
{
int* p1 = (int*)malloc(sizeof(int)); //开辟一个int大小的空间
int* p2 = (int*)calloc(4, sizeof(int)); //开4个int大小的空间并且初始化为0
int* p3 = (int*)realloc(p2, sizeof(int) * 10); //扩容,把大小扩大到10个int,并且转移空间地址到p31
}
糟糕的是上面三行代码如果开空间失败不会自动报警
b、C++的内存管理方式的优点
在实践时可以发现,我们编码时思维聚焦于开辟空间的用途;
同时也发现,实现功能时会反复使用同样的空间大小和变量类型。
1、开发效率高、稳定
如下代码,我们要修改开辟的空间属性,只需要在开空间的代码上微调即可;
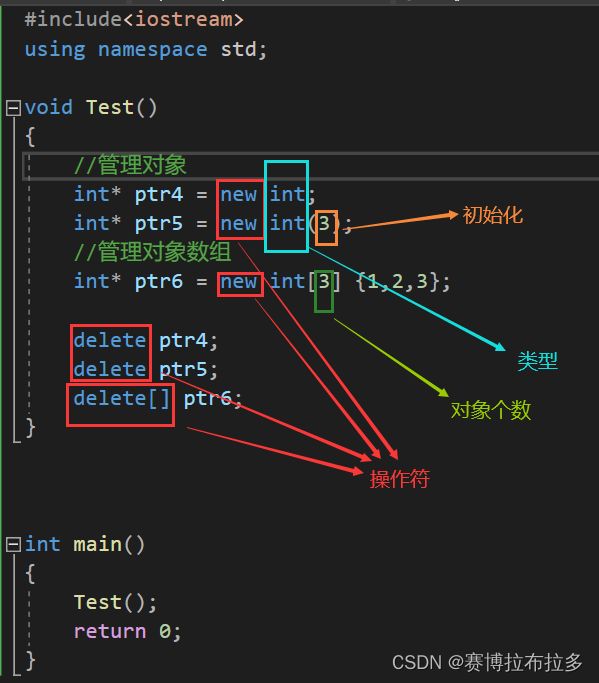
void Test()
{
// 动态申请一个int类型的空间
int* ptr4 = new int;
// 动态申请一个int类型的空间并初始化为10
int* ptr5 = new int(10);
// 动态申请5个int类型的空间,并初始化为0
int* ptr6 = new int[5];
// 动态申请5个int类型的空间并初始化前3个空间,后面2个空间默认为0
int* ptr7 = new int[5]={1,2,3};
delete ptr4;
delete ptr5;
delete[] ptr6;
delete[] ptr7;
}
简而言之,开辟一个空间,进行一番操作初始化它,就是我们的常做的操作;
由此,通过自定义类型就可以实现:通过一个类我们可以在开辟一个空间的同时启动一个构造函数对这个空间进行操作;
如下代码:
我们定义了一个自定义类型A,当我们使用new来开辟空间时,会自动启动A的构造函数;
#include2、可读性高(信息集中、整洁)
一、C++又提出了自己的内存管理方式——通过new和delete操作符进行动态内存管理
1. 我们在建开辟空间时会发现我们有4个核心需求:
开辟空间(1、2),释放空间(3、4):
- 开辟空间;
- 初始化空间;
- 释放空间;
- 指针置空
2. C++将开辟和释放分别集中在new和delete两个操作符实现:
new实现:
1.开辟空间、2.初始化空间;
delete实现:
3.释放空间、4.指针置空;
在申请自定义类型的空间时,new会自动调用operator new和构造函数,delete会自动调用operator delete 和 析构函数。
3. new集成:malloc、抛异常、构造函数;delete集成free、抛异常、析构函数
- new 是operator new 和构造函数的结合, delete 是oprator delete 和析构函数的结合;
- perator new 是malloc和抛异常的结合,oprator delete 是free和抛异常的结合。
4.new和delete内含的功能会根据具体的情况选择性发挥作用
- 在new 起作用的过程中,固定发挥malloc、抛异常、构造函数初始化空间;
- 在delete 起作用的过程中,固定发挥free、抛异常的作用,根据情况来判断是否调用析构函数 释放空间;
如果开空间时没有malloc开辟空间,则当我们要释放空间时,我们可以去使用free或delete释放空间,因为此时delete只有free可以发挥作用,没有调用析构函数的必要;
如下代码:对p1象占用了int类型的空间,我们使用free就可以释放这个空间;
相同情况下,p2使用delete也是可以的;
同理,p3的int【10】也是free、delete皆可。
#include二、 operator new与operator delete函数
1、 operator new与operator delete函数
new和delete是用户进行动态内存申请和释放的操作符,operator new 和operator delete是系统提供的全局函数,new在底层调用operator new全局函数来申请空间,delete在底层通过operator delete全局函数来释放空间。
operator new:该函数实际通过malloc来申请空间,当malloc申请空间成功时直接返回;申请空间失败,尝试执行空间不足应对措施,如果改应对措施用户设置了,则继续申请,否则抛异常。
如下代码我们尝试通过new来创建一个对象
#include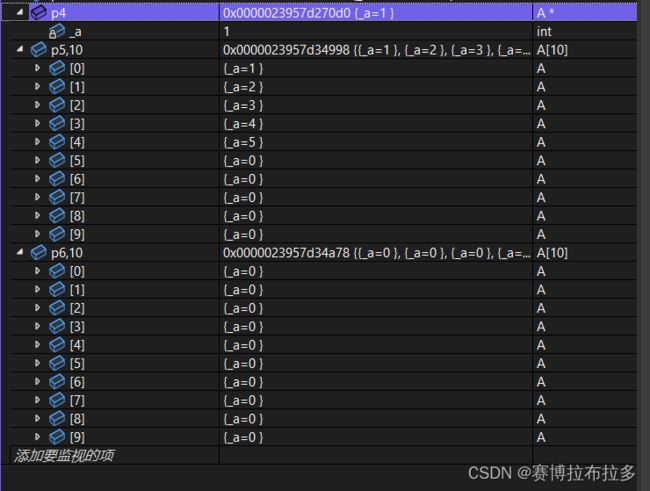
三、内置类型
如果申请的是内置类型的空间,new和malloc,delete和free基本类似,不同的地方是:
- new/delete申请和释放的是单个元素的空间;
- new[ ]和delete[ ]申请的是连续空间,而且new在申请空间失败时会抛异常,malloc会返回NULL。
四、自定义类型
1、new的原理
- 调用operator new函数申请空间
- 在申请的空间上执行构造函数,完成对象的构造
A* p1 = new A(1);
2、delete的原理
- 在空间上执行析构函数,完成对象中资源的清理工作
- 调用operator delete函数释放对象的空间
delete p1;
3、new T[N]的原理
- 调用operator new[]函数,在operator new[]中实际调用operator new函数完成N个对象空间的申请
- 在申请的空间上执行N次构造函数
- 返回开辟空间的地址
A* p2 = new A[10];
4、delete[ ]的原理
- 在释放的对象空间上执行N次析构函数,完成N个对象中资源的清理
- 调用operator delete[]释放空间,实际在operator delete[]中调用数个operator delete来释放空间
delete[] p2;
五、delete[ ]底层原理
delete[]被设计用来释放多个连续的同构造空间,那么它需要获取两个信息:
- 被释放空间的位置——在delete[]后接的地址p2;
- 调用几次析构函数——在我们使用new[]的时候,会自动在存储信息的空间前面开一个空间用来记录该空间存储了多少个对象。
如下代码:
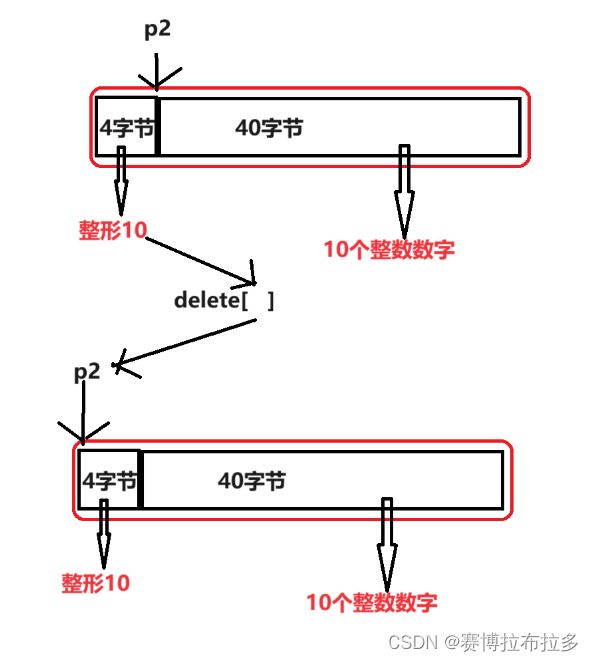
A* p2 = new A[10];
delete[] p2;
我们使用了new A[10]开辟了十个存储int数据的空间,我们的指针p2也指向了这个空间的第一个元素的地址;
而当我们调用delete[]来释放该空间时,delete[ ]空着的[ ]就会把p2前面四个字节的内容作为整形装到[]里面,于是在编译器看来 delete[] p2 就变成了 “ delete[10] p2” ;
由此编译器知道了需要调用十次析构函数释放该空间,同时p2也被修改指向了该空间真正的起始地址,最后释放空间时会把开头的4个字节和后面的40个字节一起释放掉,然后p2被置空。至此new A[10]所占用的空间被全部释放;
六、定位new表达式(placement-new)
定位new表达式是在已分配的原始内存空间中调用构造函数初始化一个对象。
使用格式:
new (place_address) type
或者
new (place_address) type(initializer-list)
place_address必须是一个指针,initializer-list是类型的初始化列表
使用场景:
定位new表达式在实际中一般是配合内存池使用。因为内存池分配出的内存没有初始化,所以如果是自定义类型的对象,需要使用new的定义表达式进行显示调构造函数进行初始化。
即,有些情况下编译器会使用内存池来优化运行效率,而这时我们要开辟空间时就会出现空间开辟到内存池上而不是堆上,如此一来开辟空间就相当于失败了,因为内存池不能像堆一样一直保存信息;
所以有了placement-new的概念,专门在那些使用内存池的编译器上发挥作用,特别地要求开辟空间要在堆上开辟而不是内存池上。