多线程,io,网编,反射,xml
代码全部手敲,永远不要相信你看到的结论,自己编码后运行出来的,才是自己的。1111111111111111111111111111111111111111111111
11111111111111111111111111111111111111111111111111111
111111111111111111111111111111111111111111111
11111111111111111111111111111111111111111
多线程概念:难点java多线程的基本使用定义任务、创建和运行线程如下代码 几种定义线程的方式生命周期,礼让and优先级,上下文切换,守护线程,阻塞打断,状态六种线程状态和方法的对应关系线程的相关方法总结同步锁线程安全概念:细节同步锁synchronized概念:基本使用:线程安全的代码ReentrantLock同步锁理解释放锁:死锁线程间通信wait+notifywait 和 sleep的区别?park&unpark实例:生产者消费者模型java内存模型(JMM)可见性有序性原子性volatile(解决可见性、有序性)无锁-casAtomicInteger线程池线程池的介绍线程池的好处线程池的构造方法构造器参数的意义线程池理解线程池的状态线程池的主要流程Execetors创建线程池线程池的关闭线程池的正确使用姿势IO流前言IO流的四点明确(1)明确要操作的数据是数据源还是数据目的(要读还是要写)(2)明确要操作的设备上的数据是字节还是文本(3)明确数据所在的具体设备(4)明确是否需要额外功能IO概念:IO流分类1、输入流与输出流2、字节流与字符流3、节点流和处理流字节流字符流1、(字节流)(缓冲字节流)2、(字符流(转换流不用)(字符流便捷类不能编码)读一行同时读写读取文件创建对象数据、字节、管道(多线程)序列化流(对象流)ObjectOutputStream类ObjectInputStream类两个异常:打印流概念:字节输出打印流PrintStream复制文本文件字符输出打印流PrintWriter复制文本文件Properties属性类Properties概述Properties类IO流对象File类概念,构造,常用方法字节流基类概念:InputStream类的实现子类字符流基类概念:Reader类的实现子类位、字节、字符网络编程一、计算机网络、IP、端口、协议(一)计算机网络(二)IP地址("域名")(协议)InetAddress类(IP)(三)端口InetSocketAddress类(Prot)(四)网络通信协议及接口协议分类概念1.UDP2.TCP(1)三次握手(2)四次挥手二、UDP网络编程和TCP网络编程(一)UDP网络编程1.DatagramSocket2.DatagramPacket3.代码实现案例(多线程)(二)TCP网络编程2.Socket类3.ServerSocket类4.代码实现案例一(回写)案例二(文件)案例三(读取发送接收回写写文件)三、URL(一)概念(二)格式(三)URL类1.构造方法摘要2.常用方法摘要小结反射一、反射的概述二、Class类Class1类加载【理解】2类加载器【理解】类加载器的作用JVM的类加载机制Java中的内置类加载器类加载器ClassLoader三、反射的使用1、获取Class对象的三种方式通过反射获取构造方法Constructor反射的四个步骤创建对象;通过反射获取成员变量Field通过反射获取成员方法Method 运行配置文件内容|反射越过泛型检查反射方法的其它使用之---通过反射运行配置文件内容反射方法的其它使用之---通过反射越过泛型检查3.模块化3.1模块化概述【理解】3.2模块的基本使用【应用】3.3模块服务的基本使用【应用】XML解析1.XML历史4.XML语法4.1.XML语法-文档声明4.2.XML语法-元素(或者叫标记、节点)4.3.XML语法-属性4.4.XML语法-注释4.5.XML语法-CDATA节4.6.XML语法-处理指令4.7XML语法-约束xml文件的解析XML解析技术概述DOM4J:Jsoup:小结什么是xml文件格式XML文件创建格式XML CRUDJAXP使用JAXP进行DOM解析获得JAXP中的DOM解析器DOM编程Node对象DOM方式解析XML文件Dom解析DOM编程练习更新XML文档SAX解析SAX方式解析XML文档SAXSAX解析编程MyContentHandler() MyContentHandler2()TagValueHandler()sax解析案例(javabean封装xml文档数据)DOM4J解析Document对象节点对象节点对象属性 将文档写入XML文件Dom4j在指定位置插入节点字符串与XML的转换Dom4jDOM4J编程*Jsoup解析XPathdom4j参考资料坦克大战Lambda 表达式1.5.9.1 Lambda 表达式入门1.5.9.2 Lambda 表达式与函数式接口1.5.9.3 方法引用与构造器引用1.5.9.4 Lambda 表达式与匿名内部类的联系和区别1.5.9.5 使用 Lambda 表达式调用 Arrays 的类方法
多线程
概念:
进程
是程序的一次动态执行过程,每个进程都有自己独立的内存空间。一个应用程序可以同时启动多个进程
(比如浏览器可以开多个窗口,每个窗口就是一个进程)
多进程操作系统能够运行多个进程,每个进程都能够循环利用所需要的CPU时间片,使的所有进程看上去像在同时运行一样。
程序由指令和数据组成,指令要运行,数据要加载,指令被cpu加载运行,数据被加载到内存,指令运行时可由cpu调度硬盘、网络等设备
线程
线程是进程的一个执行流程,一个进程可以由多个线程组成,
也就是说一个进程可以同时运行多个不同的线程,每个线程完成不同的任务。
开线程就是开个新的栈空间,执行调用者的run方法
一个线程就是一个指令流,cpu调度的最小单位,由cpu一条一条执行指令
线程的并行并发运行:
并发:单核cpu运行多线程时,同一时间段运行,时间片进行很快的切换。线程轮流执行cpu
并行:多核cpu运行 多线程时,真正的在同一时刻运行
线程和进程的关系:
是一个局部和整体的关系,每个进程都由操作系统分配独立的内存地址空间,而同一进程的所有线程都在同一地址空间工作。
作用
程序运行的更快!快!快!充分利用cpu资源,目前几乎没有线上的cpu是单核的,发挥多核cpu强大的能力
难点
-
多线程的执行结果不确定,受到cpu调度的影响
-
多线程的安全问题
-
线程资源宝贵,依赖线程池操作线程,线程池的参数设置问题
-
多线程执行是动态的,同时的,难以追踪过程
-
多线程的底层是操作系统层面的,源码难度大
java多线程的基本使用
新建状态:使用new和某种线程的构造方法来创建线程对象,该线程就会进入新建状态,系统为该线程对象分配内存空间。处于新建状态的线程可以通过调用start()方法进入就绪状态。
就绪状态:此时线程已经具备了运行的条件,进入了线程队列,等待系统分配CPU资源,一旦获得CPU资源,该线程就会进入运行状态。
运行状态:进入运行在状态,线程会执行自己的run()方法中的代码。
阻塞状态:一个正在执行的线程,如果执行了suspend、join或sleep方法,或等待io设备的使用权,那么该线程将会让出自己的CUP控制权并暂时中止自己的执行,进入阻塞状态。
阻塞的线程,不能够进入就绪队列,只有当阻塞原因被消除的时候,线程才能进入就绪状态,重新进入线程队列中排队等待CPU资源,然后继续执行。
死亡状态:一个线程完成了全部工作或者被提前强制性的中止,该线程就处于死亡状态。
定义任务、创建和运行线程
任务: 线程的执行体。也就是我们的核心代码逻辑
继承Thread类 (可以说是 将任务和线程合并在一起)new Thread(){run}
实现Runnable接口 (可以说是 将任务和线程分开了)new Thread(new Runable(){run},name);
实现Callable接口 (利用FutureTask执行任务)ft= new FutureTask(new Callable
Thread实现任务的局限性
Thread(Thread匿名)
任务逻辑写在Thread类的run方法中,有单继承的局限性
创建多线程时,每个任务有成员变量时不共享,必须加static才能做到共享
Runnable和Callable解决了Thread的局限性
Thread(Runable匿名)
但是与Runbale相对Callable来说有以下的局限性
任务没有返回值
任务无法抛异常给调用方
Callable的方法
Thread(FutureTask(Callable匿名))
定义任务
创建线程的方式
通过Thread类直接创建线程
利用线程池内部创建线程
启动线程的方式
调用线程的start()方法
细节:
设置线程名称:
new Thread(,name:"")
如下代码 几种定义线程的方式
@Slf4j
class T extends Thread {
@Override
public void run() {
log.info("我是继承Thread的任务");
}
}
1// 启动继承Thread类的任务
MyThread myThread = new MyThread();
myThread.start();
--------------------------------------------
2// 启动继承Thread匿名内部类的任务 可用lambda优化
Thread t = new Thread(){
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
System.out.println("I Love You~");
}
}
};
t.start();
=====lambda======
Thread t = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
System.out.println("I Love You~");
}
});
t.start();
========================================================================================================================================================================================================================================================
@Slf4j
class MyRunnable implements Runnable {
@Override
public void run() {
log.info("我是实现Runnable的任务");
}
}
1// 启动实现Runnable接口的任务
MyRunable myRunable = new MyRunable();
Thread threadR = new Thread(myRunable);
threadR.start();
---------------------------------------------
2// 启动实现Runnable匿名实现类的任务
Thread tr = new Thread(new Runnable(){
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
System.out.println("I Love You~");
}
}
},name);
tr.start();
========lambda===========
3// 启动实现Runnable的lambda简化后的任务
Thread tr = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
System.out.println("I Love You~");
}
},name);
tr.start();
---------------------------------------------
4//
Thread tr = new Thread(ThreadDemo1::runable);
tr.start();
private static void runable() {
for (int i = 0; i < 1000; i++) {
System.out.println("I Love You~");
}
}
========================================================================================================================================================================================================================================================
@Slf4j
class MyCallable implements Callable {
@Override
public String call() throws ExecutionException, InterruptedException {
log.info("我是实现Callable的任务");
return "success";
}
---------------------------------------------
1// 启动实现了Callable接口的任务 结合FutureTask 可以获取线程执行的结果
FutureTask ft = new FutureTask(new MyCallable());
Thread tf = new Thread(ft);
tf.start();
System.out.println(ft.get());//等主线结束在返回,不然会先执行完子线程
---------------------------------------------
2//启用实现Callable的匿名实现类的任务
FutureTask ft= new FutureTask(new Callable
生命周期,礼让and优先级,上下文切换,守护线程,阻塞打断,状态
线程的生命周期
一个线程的完整生命周期要经历5中状态:新建、就绪、运行、阻塞、死亡
线程的礼让-yield()&线程的优先级
yield()礼让资源不够就会礼让
yield()方法会让运行中的线程切换到就绪状态,重新争抢cpu的时间片,争抢时是否获取到时间片看cpu的分配。
t2线程每次执行时进行了yield(),线程1执行的机会明显比线程2要多。
setPriority(1);优先级 资源不够用才有意义
线程内部用1~10的数来调整线程的优先级,默认的线程优先级为NORM_PRIORITY:5
cpu比较忙时,优先级高的线程获取更多的时间片 cpu比较闲时,优先级设置基本没用上下文切换
多核cpu下,多线程是并行工作的,如果线程数多,单个核又会并发的调度线程,运行时会有上下文切换的概念
cpu执行线程的任务时,会为线程分配时间片,以下几种情况会发生上下文切换。
线程的cpu时间片用完
垃圾回收
线程自己调用了 sleep、yield、wait、join、park、synchronized、lock 等方法
当发生上下文切换时,操作系统会保存当前线程的状态,并恢复另一个线程的状态,jvm中有块内存地址叫程序计数器,用于记录线程执行到哪一行代码,是线程私有的。
idea打断点的时候可以设置为Thread模式,idea的debug模式可以看出栈帧的变化
守护线程thread.setDaemon
概念
默认情况下,java进程需要等待所有线程都运行结束,才会结束,
有一种特殊线程叫守护线程,当所有的非守护线程都结束后,即使它没有执行完,也会强制结束。
细节
默认的线程都是非守护线程。
垃圾回收线程就是典型的守护线程
具体的api。
设为true表示未守护线程,当主线程结束后,守护线程也结束。 默认是false,当主线程结束后,thread继续运行,程序不停止 thread.setDaemon(true);
线程的阻塞,打断
线程的阻塞可以分为好多种,从操作系统层面和java层面阻塞的定义可能不同,但是广义上使得线程阻塞的方式有下面几种
BIO阻塞,即使用了阻塞式的io流
sleep(long time) 让线程休眠进入阻塞状态,当休眠时间结束后重新争抢cpu的时间片继续运行
Thread.sleep(2000);
该方法会抛出 InterruptedException异常 即休眠过程中可被中断,被中断后抛出异常
TimeUnit.SECONDS.sleep(1);
a.join("time") 插队:调用方的线程进入阻塞,等待a线程执行完后恢复运行
time,指定时间内 a线程还未执行完 调用方的线程不继续等待就恢复运行
sychronized或ReentrantLock 造成线程未获得锁进入阻塞状态 (同步锁章节细说)
获得锁之后调用wait()方法 也会让线程进入阻塞状态 (同步锁章节细说)
LockSupport.park() 让线程进入阻塞状态 (同步锁章节细说)
线程的打断-interrupt()
打断标记:
boolean isInterrupted() 获取线程的打断标记 ,调用后不会修改线程的打断标记。线程是否被打断,true表示被打断了,false表示没有
void interrupted() 获取线程的打断标记,调用后清空打断标记 即如果获取为true 调用后打断标记为false (不常用)
中断休眠 打断线程
static boolean interrupt()
可以中断sleep,wait,join等显式的抛出InterruptedException方法的线程,
即中断被休眠阻塞的线程
线程的打断标记还是false
打断正常线程 ,线程不会真正被中断,但是线程的打断标记为true
正在运行的线程会被打断,
线程的打断标记变为true
线程的状态
上面说了一些基本的api的使用,调用上面的方法后都会使得线程有对应的状态。
线程的状态可从 操作系统层面分为五种状态 从java api层面分为六种状态。
五种状态
初始状态:创建线程对象时的状态 可运行状态(就绪状态):调用start()方法后进入就绪状态,也就是准备好被cpu调度执行 运行状态:线程获取到cpu的时间片,执行run()方法的逻辑 阻塞状态: 线程被阻塞,放弃cpu的时间片,等待解除阻塞重新回到就绪状态争抢时间片 终止状态: 线程执行完成或抛出异常后的状态
六种状态
Thread类中的内部枚举State
public enum State { NEW , RUNNABLE , BLOCKED , WAITING , TIMED_WAITING , TERMINATED; }
NEW 线程对象被创建
Runnable 线程调用了start()方法后进入该状态,该状态包含了三种情况
就绪状态 :等待cpu分配时间片
运行状态:进入Runnable方法执行任务
阻塞状态:BIO 执行阻塞式io流时的状态
Blocked 没获取到锁时的阻塞状态(同步锁章节会细说)
WAITING 调用wait()、join()等方法后的状态
TIMED_WAITING 调用 sleep(time)、wait(time)、join(time)等方法后的状态
TERMINATED 线程执行完成或抛出异常后的状态
六种线程状态和方法的对应关系
线程的相关方法总结
主要总结Thread类中的核心方法
| 方法名称 | 是否static | 方法说明 |
|---|---|---|
| start() | 否 | 让线程启动,进入就绪状态,等待cpu分配时间片 |
| run() | 否 | 重写Runnable接口的方法,线程获取到cpu时间片时执行的具体逻辑 |
| yield() | 是 | 线程的礼让,使得获取到cpu时间片的线程进入就绪状态,重新争抢时间片 |
| sleep(time) | 是 | 线程休眠固定时间,进入阻塞状态,休眠时间完成后重新争抢时间片,休眠可被打断 |
| join()/join(time) | 否 | 调用线程对象的join方法,调用者线程进入阻塞,等待线程对象执行完或者到达指定时间才恢复,重新争抢时间片 |
| boolean isInterrupted() | 否 | 获取线程的打断标记,true:被打断,false:没有被打断。调用后不会修改打断标记 |
| interrupt() | 否 | 打断线程,抛出InterruptedException异常的方法均可被打断,但是打断后不会修改打断标记,正常执行的线程被打断后会修改打断标记 |
| interrupted() | 否 | 获取线程的打断标记。调用后会清空打断标记 |
| stop() | 否 | 停止线程运行 不推荐 |
| suspend() | 否 | 挂起线程 不推荐 |
| resume() | 否 | 恢复线程运行 不推荐 |
| currentThread() | 是 | 获取当前线程 |
| setPriority(1); | 是 | 优先级Thread.MIN_PRIORITY||NORM_PRIORITY:5 |
| setDaemon | 是 | 默认为false非守护,true守护线程 |
Object中与线程相关方法
| 方法名称 | 方法说明 |
|---|---|
| wait()/wait(long timeout) | 获取到锁的线程进入阻塞状态 |
| notify() | 随机唤醒被wait()的一个线程 |
| notifyAll(); | 唤醒被wait()的所有线程,重新争抢时间片 |
————————————————
————————————————
同步锁
线程安全
概念:
线程安全(概念)
指的是多线程调用同一个对象的临界区的方法时,对象的属性值一定不会发生错误,这就是保证了线程安全。
产生原因:
多个线程访问共享资源,可能会发生指令交错
临界区:
一段代码如果对共享资源的多线程读写操作,这段代码就被称为临界区。
指令交错(同步锁解决)
指的是 java代码在解析成字节码文件时,java代码的一行代码在字节码中可能有多行,在线程上下文切换时就有可能交错。
细节
线程安全的类一定所有的操作都线程安全吗?(Concurrent、HashMap,)
线程安全指的是类里每一个独立的方法是线程安全的,但是方法的组合就不一定是线程安全的。
成员变量和静态变量是否线程安全?
如果没有多线程共享,则线程安全√
如果存在多线程共享
多线程只有读操作,则线程安全√
多线程存在写操作,写操作的代码又是临界区,则线程不安全×
局部变量是否线程安全?
局部变量是线程安全的√
局部变量引用的对象未必是线程安全的
如果该对象没有逃离该方法的作用范围,则线程安全√
如果该对象逃离了该方法的作用范围,比如:方法的返回值,需要考虑线程安全×
同步锁
synchronized
概念:
同步锁也叫对象锁,是锁在对象上的,不同的对象就是不同的锁。
底层互斥锁 对象锁与互斥锁相联系 任意时刻只能有一个线程访问
该关键字是用于保证线程安全的,是阻塞式的解决方案。
同锁的方法为同步方法,同步代码块
重点:一定要保证是同一对象加锁,多个线程持有同对象锁的钥匙
原理让同一个时刻最多只有一个线程能持有对象锁,其他线程在想获取这个对象锁就会被阻塞,不用担心上下文切换的问题。
注意:时间片切换了,也会执行其他线程,再切换回来会紧接着执行,
只是不会执行到有竞争锁的资源,因为当前线程还未释放锁。
自动释放锁:
当一个线程执行完synchronized的代码块后 会唤醒正在等待的线程
synchronized实际上使用对象锁保证临界区的原子性 临界区的代码是不可分割的 不会因为线程切换所打断
基本使用:
加在方法上 实际是对this对象加锁private synchronized void a() {}
加在静态方法上 实际是对类对象加锁private synchronized static void c() {}
同步代码块 实际是对类对象加锁
private void b{ synchronized (this){} } 同a()
private static void d{ synchronized (类名.class){} } 同c()
创建一个对象进行加锁。
private static Object lock = new Object();
run{ synchronized(lock ){ } }
runnable接口: 不用锁静态对象,同一个任务 能确定是同一个对象 继承Thread类:需要锁静态对象,才能确保是同一个对象
线程安全的代码
private static int count = 0;
private static Object lock = new Object();
private static Object lock2 = new Object();
。。。。。。
synchronized (lock) {
count++;
}
。。。。。。。
。。。。。。。
synchronized (lock) {
count--;
}
。。。。。。
t1.start();t2.start();
// 让t1 t2都执行完
t1.join();t2.join();
System.out.println(count);
}
//===买票=====买票====买票=====买票========买票======买票====买票====买票=====买票====买票======买票======买票======买票====买票====买票====买票====买票=====买票====买票======买票====买票====买票===买票===买票====买票===买票======买票====买票====买票===买票===买票====
public class SellTicket_ {
/*3.使用同步代码块,同步方法,静态的同步方法完成课上火车站卖票案例。
*/
public static void main(String[] args) {
SellTicket st = new SellTicket();
Thread tf1 = new Thread(st,"一");
Thread tf2 = new Thread(st,"二");
Thread tf3 = new Thread(st,"三");
tf1.start();
tf2.start();
tf3.start();
}
}
class SellTicket implements Runnable {
private int tickets = 100;
@Override
public void run() {
while (true) {
if (mothed())
break;
}
}
private synchronized boolean mothed(){
if (tickets>=0){
System.out.println(Thread.currentThread().getName()+"正在买票,还剩"+tickets--);
}else {
return true;
}
return false;
}
}
重点:加锁是加在对象上,一定要保证是同一对象,加锁才能生效
ReentrantLock
可重入锁 : 一个线程获取到对象的锁后,执行方法内部在需要获取锁的时候是可以获取到的。如以下代码
private static final ReentrantLock LOCK = new ReentrantLock();
private static void m() {
LOCK.lock();
try {
log.info("begin");
// 调用m1()
m1();
} finally {
// 注意锁的释放
LOCK.unlock();
}
}
public static void m1() {
LOCK.lock();
try {
log.info("m1");
m2();
} finally {
// 注意锁的释放
LOCK.unlock();
}
}
| ReentrantLock有以下优点 |
|---|
| 支持获取锁的超时时间 |
| 获取锁时可被打断 |
| 可设为公平锁 |
| 可以有不同的条件变量,即有多个waitSet,可以指定唤醒 |
// 默认非公平锁,参数传true 表示未公平锁
ReentrantLock lock = new ReentrantLock(false);
// 尝试获取锁
lock()
// 释放锁 应放在finally块中 必须执行到
unlock()
try {
// 获取锁时可被打断,阻塞中的线程可被打断
LOCK.lockInterruptibly();
} catch (InterruptedException e) {
return;
}
// 尝试获取锁 获取不到就返回false
LOCK.tryLock()
// 支持超时时间 一段时间没获取到就返回false
tryLock(long timeout, TimeUnit unit)
// 指定条件变量 休息室 一个锁可以创建多个休息室
Condition waitSet = ROOM.newCondition();
// 释放锁 进入waitSet等待 释放后其他线程可以抢锁
yanWaitSet.await()
// 唤醒具体休息室的线程 唤醒后 重写竞争锁
yanWaitSet.signal()
同步锁理解
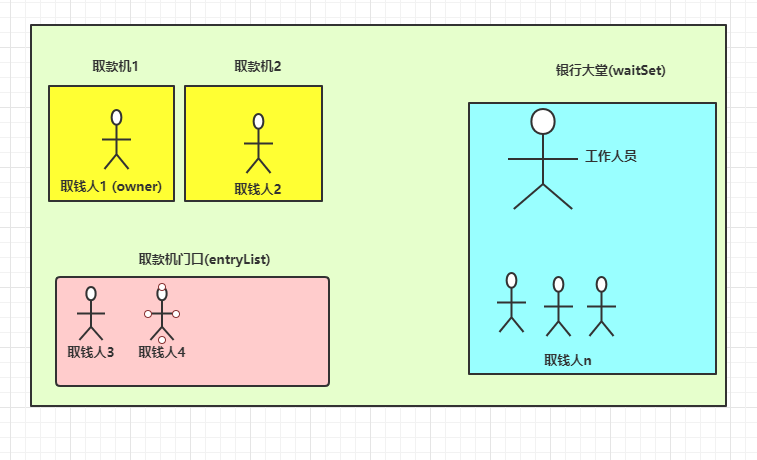
现实中,我们去银行门口的自动取款机取钱,取款机的钱就是共享变量,为了保障安全,不可能两个陌生人同时进入同一个取款机内取钱,所以只能一个人进入取钱,然后锁上取款机的门,其他人只能在取款机门口等待。
取款机有多个,里面的钱互不影响,锁也有多个(多个对象锁),取钱人在多个取款机里同时取钱也没有安全问题。
假如每个取钱的陌生人都是线程,当取钱人进入取款机锁了门后(线程获得锁),取到钱后出门(线程释放锁),下一个人竞争到锁来取钱。
假设工作人员也是一个线程,如果取钱人进入后发现取款机钱不足了,这时通知工作人员来向取款机里加钱(调用notifyAll方法),取钱人暂停取钱,进入银行大堂阻塞等待(调用wait方法)。
银行大堂里的工作人员和取钱人都被唤醒,重新竞争锁,进入后如果是取钱人,由于取款机没钱,还得进入银行大堂等待。
当工作人员获得取款机的锁进入后,加了钱后会通知大厅里的人来取钱(调用notifyAll方法)。自己暂停加钱,进入银行大堂等待唤醒加钱(调用wait方法)。
这时大堂里等待的人都来竞争锁,谁获取到谁进入继续取钱。谁抢到锁谁进去取。
释放锁:
当前线程的同步方法(&代码块)执行完或者遇到break,return,出现未处理异常,导致结束,wait()
死锁
说到死锁,先举个例子,
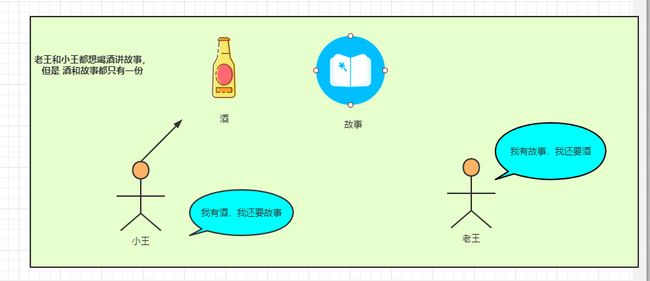
下面是代码实现
static Beer beer = new Beer();
static Story story = new Story();
//一个持有A锁需要B锁开内置代码块
//一个持有B锁需要A锁开内置代码块
public static void main(String[] args) {
new Thread(() ->{
synchronized (beer){
log.info("我有酒,给我故事");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (story){
log.info("小王开始喝酒讲故事");
}
}
},"小王").start();
new Thread(() ->{
synchronized (story){
log.info("我有故事,给我酒");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (beer){
log.info("老王开始喝酒讲故事");
}
}
},"老王").start();
}
class Beer {
}
class Story{
}
死锁导致程序无法正常运行下去
检测工具可以检查到死锁信息
线程间通信
wait+notify
线程间通信可以通过共享变量+wait()¬ify()来实现
wait()将线程进入阻塞状态,
notify()将线程唤醒
当多线程竞争访问对象的同步方法时,锁对象会关联一个底层的Monitor对象(重量级锁的实现)
如下图所示 Thread0,1先竞争到锁执行了代码后,2,3,4,5线程同时来执行临界区的代码,开始竞争锁
Thread-0先获取到对象的锁,关联到monitor的owner,同步代码块内调用了锁对象的wait()方法,调用后会进入waitSet等待,Thread-1同样如此,此时Thread-0的状态为Waitting
Thread2、3、4、5同时竞争,2获取到锁后,关联了monitor的owner,3、4、5只能进入EntryList中等待,此时2线程状态为 Runnable,3、4、5状态为Blocked
2执行后,唤醒entryList中的线程,3、4、5进行竞争锁,获取到的线程即会关联monitor的owner
3、4、5线程在执行过程中,调用了锁对象的notify()或notifyAll()时,会唤醒waitSet的线程,唤醒的线程进入entryList等待重新竞争锁
注意:
Blocked状态和Waitting状态都是阻塞状态
Blocked线程会在owner线程释放锁时唤醒
wait和notify使用场景是必须要有同步,且必须获得对象的锁才能调用,使用锁对象去调用,否则会抛异常
wait() 释放锁 进入 waitSet 可传入时间,如果指定时间内未被唤醒 则自动唤醒
notify()随机唤醒一个waitSet里的线程
notifyAll()唤醒waitSet中所有的线程
static final Object lock = new Object();
new Thread(() -> {
synchronized (lock) {
log.info("开始执行");
try {
// 同步代码内部才能调用
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("继续执行核心逻辑");
}
}, "t1").start();
new Thread(() -> {
synchronized (lock) {
log.info("开始执行");
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("继续执行核心逻辑");
}
}, "t2").start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("开始唤醒");
synchronized (lock) {
// 同步代码内部才能调用
lock.notifyAll();
}
// 执行结果
14:29:47.138 [t1] INFO TestWaitNotify - 开始执行
14:29:47.141 [t2] INFO TestWaitNotify - 开始执行
14:29:49.136 [main] INFO TestWaitNotify - 开始唤醒
14:29:49.136 [t2] INFO TestWaitNotify - 继续执行核心逻辑
14:29:49.136 [t1] INFO TestWaitNotify - 继续执行核心逻辑
wait 和 sleep的区别?
二者都会让线程进入阻塞状态,有以下区别
wait是Object的方法 sleep是Thread的方法
wait会立即释放锁 sleep不会释放锁
wait后线程的状态是Waiting sleep后线程的状态为 Time_Waiting
park&unpark
LockSupport是juc下的工具类,提供了park和unpark方法,可以实现线程通信
park&unpark wait¬ity park unpark不用获取对象锁 wait 和notify需要获取对象锁 unpark 可以指定唤醒线程 notify随机唤醒 park和unpark的顺序可以先unpark wait和notify的顺序不能颠倒
实例:
一个线程输出a,一个线程输出b,一个线程输出c,abc按照顺序输出,连续输出5次
这个考的就是线程的通信,利用 wait()/notify()和控制变量可以实现,此处使用ReentrantLock即可实现该功能。
public static void main(String[] args) {
AwaitSignal awaitSignal = new AwaitSignal(5);
// 构建三个条件变量
Condition a = awaitSignal.newCondition();
Condition b = awaitSignal.newCondition();
Condition c = awaitSignal.newCondition();
// 开启三个线程
new Thread(() -> {
awaitSignal.print("a", a, b);
}).start();
new Thread(() -> {
awaitSignal.print("b", b, c);
}).start();
new Thread(() -> {
awaitSignal.print("c", c, a);
}).start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
awaitSignal.lock();
try {
// 先唤醒a
a.signal();
} finally {
awaitSignal.unlock();
}
}
}
class AwaitSignal extends ReentrantLock {
// 循环次数
private int loopNumber;
public AwaitSignal(int loopNumber) {
this.loopNumber = loopNumber;
}
/**
* @param print 输出的字符
* @param current 当前条件变量
* @param next 下一个条件变量
*/
public void print(String print, Condition current, Condition next) {
for (int i = 0; i < loopNumber; i++) {
lock();
try {
try {
// 获取锁之后等待
current.await();
System.out.print(print);
} catch (InterruptedException e) {
}
next.signal();
} finally {
unlock();
}
}
}
生产者消费者模型
指的是有生产者来生产数据,消费者来消费数据,
生产者生产满了就不生产了,通知消费者取,等消费了再进行生产。
消费者消费不到了就不消费了,通知生产者生产,生产到了再继续消费。
public static void main(String[] args) throws InterruptedException {
MessageQueue queue = new MessageQueue(2);
// 三个生产者向队列里存值
for (int i = 0; i < 3; i++) {
int id = i;
new Thread(() -> {
queue.put(new Message(id, "值" + id));
}, "生产者" + i).start();
}
Thread.sleep(1000);
// 一个消费者不停的从队列里取值
new Thread(() -> {
while (true) {
queue.take();
}
}, "消费者").start();
}
}
// 消息队列被生产者和消费者持有
class MessageQueue {
private LinkedList list = new LinkedList<>();
// 容量
private int capacity;
public MessageQueue(int capacity) {
this.capacity = capacity;
}
/**
* 生产
*/
public void put(Message message) {
synchronized (list) {
while (list.size() == capacity) {
log.info("队列已满,生产者等待");
try {
list.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
list.addLast(message);
log.info("生产消息:{}", message);
// 生产后通知消费者
list.notifyAll();
}
}
public Message take() {
synchronized (list) {
while (list.isEmpty()) {
log.info("队列已空,消费者等待");
try {
list.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
Message message = list.removeFirst();
log.info("消费消息:{}", message);
// 消费后通知生产者
list.notifyAll();
return message;
}
}
}
// 消息
class Message {
private int id;
private Object value;
}
java内存模型(JMM)
jmm 体现在以下三个方面
-
原子性 保证指令不会受到上下文切换的影响
-
可见性 保证指令不会受到cpu缓存的影响
-
有序性 保证指令不会受并行优化的影响
可见性
停不下来的程序
线程有自己的工作缓存,当主线程修改了变量并同步到主内存时,t线程没有读取到,所以程序停不下来
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
while (run) {
// ....
}
});
t.start();
Thread.sleep(1000);
// 线程t不会如预想的停下来
run = false;
}
如上图所示,线程有自己的工作缓存,当主线程修改了变量并同步到主内存时,t线程没有读取到,所以程序停不下来
有序性
JVM在不影响程序正确性的情况下可能会调整语句的执行顺序,该情况也称为 指令重排序
static int i;
static int j;
// 在某个线程内执行如下赋值操作
i = ...;
j = ...;
有可能将j先赋值
原子性
原子性大家应该比较熟悉,上述同步锁的synchronized代码块就是保证了原子性,
就是一段代码是一个整体,原子性保证了线程安全,不会受到上下文切换的影响。
volatile(解决可见性、有序性)
该关键字解决了可见性和有序性,volatile通过内存屏障来实现的
写屏障
会在对象写操作之后加写屏障,会对写屏障的之前的数据都同步到主存,并且保证写屏障的执行顺序在写屏障之前
读屏障
会在对象读操作之前加读屏障,会在读屏障之后的语句都从主存读,并保证读屏障之后的代码执行在读屏障之后
注意: volatile不能解决原子性,即不能通过该关键字实现线程安全。
volatile应用场景:一个线程读取变量,另外的线程操作变量,加了该关键字后保证写变量后,读变量的线程可以及时感知。
无锁-cas
cas (compare and swap) 比较并交换
为变量赋值时,从内存中读取到的值v,获取到要交换的新值n,执行 compareAndSwap()方法时,比较v和当前内存中的值是否一致,如果一致则将n和v交换,如果不一致,则自旋重试。
cas底层是cpu层面的,即不使用同步锁也可以保证操作的原子性。
无锁的效率是要高于之前的锁的,由于无锁不会涉及线程的上下文切换
cas是乐观锁的思想,sychronized是悲观锁的思想
cas适合很少有线程竞争的场景,如果竞争很强,重试经常发生,反而降低效率
ABA问题
cas存在ABA问题,即比较并交换时,如果原值为A,有其他线程将其修改为B,又在其他线程将其修改为A。
此时实际发生过交换,但是比较和交换由于值没改变可以交换成功
解决方式
AtomicStampedReference/AtomicMarkableReference
上面两个类解决ABA问题,原理就是为对象增加版本号,每次修改时增加版本号,就可以避免ABA问题
或者增加个布尔变量标识,修改后调整布尔变量值,也可以避免ABA问题
private AtomicInteger balance;
// 模拟cas的具体操作
@Override
public void withdraw(Integer amount) {
while (true) {
// 获取当前值
int pre = balance.get();
// 进行操作后得到新值
int next = pre - amount;
// 比较并设置成功 则中断 否则自旋重试
if (balance.compareAndSet(pre, next)) {
break;
}
}
}
juc并发包下包含了实现了cas的原子类
-
AtomicInteger/AtomicBoolean/AtomicLong
-
AtomicIntegerArray/AtomicLongArray/AtomicReferenceArray
-
AtomicReference/AtomicStampedReference/AtomicMarkableReference
AtomicInteger
new AtomicInteger(balance) get() compareAndSet(pre, next) // i.incrementAndGet() ++i // i.decrementAndGet() --i // i.getAndIncrement() i++ // i.getAndDecrement() ++i i.addAndGet() // 传入函数式接口 修改i int getAndUpdate(IntUnaryOperator updateFunction) // cas 的核心方法 compareAndSet(int expect, int update)
线程池
线程池的介绍
线程池是java并发最重要的一个知识点,也是难点,是实际应用最广泛的。
线程的资源很宝贵,不可能无限的创建,必须要有管理线程的工具,线程池就是一种管理线程的工具,java开发中经常有池化的思想,如 数据库连接池、Redis连接池等。
预先创建好一些线程,任务提交时直接执行,既可以节约创建线程的时间,又可以控制线程的数量。
线程池的好处
-
降低资源消耗,通过池化思想,减少创建线程和销毁线程的消耗,控制资源
-
提高响应速度,任务到达时,无需创建线程即可运行
-
提供更多更强大的功能,可扩展性高
线程池的构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
}
构造器参数的意义
| 参数名 | 参数意义 |
|---|---|
| corePoolSize | 核心线程数 |
| maximumPoolSize | 最大线程数 |
| keepAliveTime | 救急线程的空闲时间 |
| unit | 救急线程的空闲时间单位 |
| workQueue | 阻塞队列 |
| threadFactory | 创建线程的工厂,主要定义线程名 |
| handler | 拒绝策略 |
线程池理解
下面 我们通过一个实例来理解线程池的参数以及线程池的接收任务的过程
如上图 银行办理业务。
-
客户到银行时,开启柜台进行办理,柜台相当于线程,客户相当于任务,有两个是常开的柜台,三个是临时柜台。2就是核心线程数,5是最大线程数。即有两个核心线程
-
当柜台开到第二个后,都还在处理业务。客户再来就到排队大厅排队。排队大厅只有三个座位。
-
排队大厅坐满时,再来客户就继续开柜台处理,目前最大有三个临时柜台,也就是三个救急线程
-
此时再来客户,就无法正常为其 提供业务,采用拒绝策略来处理它们
-
当柜台处理完业务,就会从排队大厅取任务,当柜台隔一段空闲时间都取不到任务时,如果当前线程数大于核心线程数时,就会回收线程。即撤销该柜台。
线程池的状态
线程池通过一个int变量的高3位来表示线程池的状态,低29位来存储线程池的数量
| 状态名称 | 高三位 | 接收新任务 | 处理阻塞队列任务 | 说明 |
|---|---|---|---|---|
| Running | 111 | Y | Y | 正常接收任务,正常处理任务 |
| Shutdown | 000 | N | Y | 不会接收任务,会执行完正在执行的任务,也会处理阻塞队列里的任务 |
| stop | 001 | N | N | 不会接收任务,会中断正在执行的任务,会放弃处理阻塞队列里的任务 |
| Tidying | 010 | N | N | 任务全部执行完毕,当前活动线程是0,即将进入终结 |
| Termitted | 011 | N | N | 终结状态 |
// runState is stored in the high-order bits private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;
线程池的主要流程
线程池创建、接收任务、执行任务、回收线程的步骤
-
创建线程池后,线程池的状态是Running,该状态下才能有下面的步骤
-
提交任务时,线程池会创建线程去处理任务
-
当线程池的工作线程数达到corePoolSize时,继续提交任务会进入阻塞队列
-
当阻塞队列装满时,继续提交任务,会创建救急线程来处理
-
当线程池中的工作线程数达到maximumPoolSize时,会执行拒绝策略
-
当线程取任务的时间达到keepAliveTime还没有取到任务,工作线程数大于corePoolSize时,会回收该线程
注意: 不是刚创建的线程是核心线程,后面创建的线程是非核心线程,线程是没有核心非核心的概念的,这是我长期以来的误解。
拒绝策略
-
调用者抛出RejectedExecutionException (默认策略)
-
让调用者运行任务
-
丢弃此次任务
-
丢弃阻塞队列中最早的任务,加入该任务
提交任务的方法
// 执行Runnable
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
// 提交Callable
public Future submit(Callable task) {
if (task == null) throw new NullPointerException();
// 内部构建FutureTask
RunnableFuture ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
// 提交Runnable,指定返回值
public Future submit(Runnable task) {
if (task == null) throw new NullPointerException();
// 内部构建FutureTask
RunnableFuture ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
// 提交Runnable,指定返回值
public Future submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
// 内部构建FutureTask
RunnableFuture ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
protected RunnableFuture newTaskFor(Runnable runnable, T value) {
return new FutureTask(runnable, value);
}
Execetors创建线程池
注意: 下面几种方式都不推荐使用
1.newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
-
核心线程数 = 最大线程数 没有救急线程
-
阻塞队列无界 可能导致oom
2.newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
-
核心线程数是0,最大线程数无限制 ,救急线程60秒回收
-
队列采用 SynchronousQueue 实现 没有容量,即放入队列后没有线程来取就放不进去
-
可能导致线程数过多,cpu负担太大
3.newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
-
核心线程数和最大线程数都是1,没有救急线程,无界队列 可以不停的接收任务
-
将任务串行化 一个个执行, 使用包装类是为了屏蔽修改线程池的一些参数 比如 corePoolSize
-
如果某线程抛出异常了,会重新创建一个线程继续执行
-
可能造成oom
4.newScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
-
任务调度的线程池 可以指定延迟时间调用,可以指定隔一段时间调用
线程池的关闭
shutdown()
会让线程池状态为shutdown,不能接收任务,但是会将工作线程和阻塞队列里的任务执行完 相当于优雅关闭
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(SHUTDOWN);
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
shutdownNow()
会让线程池状态为stop, 不能接收任务,会立即中断执行中的工作线程,并且不会执行阻塞队列里的任务, 会返回阻塞队列的任务列表
public ListshutdownNow() { List tasks; final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { checkShutdownAccess(); advanceRunState(STOP); interruptWorkers(); tasks = drainQueue(); } finally { mainLock.unlock(); } tryTerminate(); return tasks; }
线程池的正确使用姿势
线程池难就难在参数的配置,有一套理论配置参数
cpu密集型 : 指的是程序主要发生cpu的运算
核心线程数: CPU核心数+1
IO密集型: 远程调用RPC,操作数据库等,不需要使用cpu进行大量的运算。 大多数应用的场景
核心线程数=核数*cpu期望利用率 *总时间/cpu运算时间
但是基于以上理论还是很难去配置,因为cpu运算时间不好估算
实际配置大小可参考下表
| cpu密集型 | io密集型 | |
|---|---|---|
| 线程数数量 | 核数<=x<=核数*2 | 核心数*50<=x<=核心数 *100 |
| 队列长度 | y>=100 | 1<=y<=10 |
1.线程池参数通过分布式配置,修改配置无需重启应用
线程池参数是根据线上的请求数变化而变化的,最好的方式是 核心线程数、最大线程数 队列大小都是可配置的
主要配置 corePoolSize maxPoolSize queueSize
java提供了可方法覆盖参数,线程池内部会处理好参数 进行平滑的修改
public void setCorePoolSize(int corePoolSize) {
}
2.增加线程池的监控
3.io密集型可调整为先新增任务到最大线程数后再将任务放到阻塞队列
代码 主要可重写阻塞队列 加入任务的方法
public boolean offer(Runnable runnable) {
if (executor == null) {
throw new RejectedExecutionException("The task queue does not have executor!");
}
final ReentrantLock lock = this.lock;
lock.lock();
try {
int currentPoolThreadSize = executor.getPoolSize();
// 如果提交任务数小于当前创建的线程数, 说明还有空闲线程,
if (executor.getTaskCount() < currentPoolThreadSize) {
// 将任务放入队列中,让线程去处理任务
return super.offer(runnable);
}
// 核心改动
// 如果当前线程数小于最大线程数,则返回 false ,让线程池去创建新的线程
if (currentPoolThreadSize < executor.getMaximumPoolSize()) {
return false;
}
// 否则,就将任务放入队列中
return super.offer(runnable);
} finally {
lock.unlock();
}}
3.拒绝策略 建议使用tomcat的拒绝策略(给一次机会)
// tomcat的源码
@Override
public void execute(Runnable command) {
if ( executor != null ) {
try {
executor.execute(command);
} catch (RejectedExecutionException rx) {
// 捕获到异常后 在从队列获取,相当于重试1取不到任务 在执行拒绝任务
if ( !( (TaskQueue) executor.getQueue()).force(command) ) throw new RejectedExecutionException("Work queue full.");
}
} else throw new IllegalStateException("StandardThreadPool not started.");
}
建议修改从队列取任务的方式: 增加超时时间,超时1分钟取不到在进行返回
public boolean offer(E e, long timeout, TimeUnit unit){}
————————————————
原文链接:万字图解Java多线程_猿小布的博客-CSDN博客_万字图解java多线程
IO流
前言
Java IO流有什么特点? Java IO流分为几种类型? 字节流和字符流的关系与区别? 字符流是否使用了缓冲? 缓冲流的效率一定高吗?为什么? 缓冲流体现了Java中的哪种设计模式思想? 为什么要实现序列化?如何实现序列化? 序列化数据后,再次修改类文件,读取数据会出问题,如何解决呢?
io流用到的地方很多,就比如上传下载,传输,设计模式等…基础打扎实了,才能玩更高端的。
在博主认为真正懂IO流的优秀程序员每次在使用IO流之前都会明确分析如下四点:
(1)明确要操作的数据是数据源还是数据目的(也就是要读还是要写) (2)明确要操作的设备上的数据是字节还是文本 (3)明确数据所在的具体设备 (4)明确是否需要额外功能(比如是否需要转换流、高效流等)
以上四点将会在文章告白IO流的四点明确里面小结一下,如果各位真能熟练以上四点,我觉得这篇文章你就没必要看了,因为你已经把IO玩弄与股掌之中,万物皆可被你盘也就也不再话下了。
IO流的四点明确
(1)明确要操作的数据是数据源还是数据目的(要读还是要写)
源:InputStream Reader 目的:OutputStream Writer
(2)明确要操作的设备上的数据是字节还是文本
源:字节: InputStream文本: Reader
目的:字节: OutputStream文本: Writer
(3)明确数据所在的具体设备
源设备:输入 对应目的设备:输出
硬盘:文件 File开头
内存:数组,字符串
键盘:System.in | 屏幕:System.out
网络:Socket
(4)明确是否需要额外功能
需要转换—— 转换流 InputStreamReader 、OutputStreamWriter
需要高效—— 缓冲流Bufferedxxx
多个源—— 序列流 SequenceInputStream
对象序列化—— ObjectInputStream、ObjectOutputStream
保证数据的输出形式—— 打印流PrintStream 、Printwriter
操作基本数据,保证字节原样性——DataOutputStream、DataInputStream
IO
概念:
IO是什么;流是什么 读取写入数据
IO,即in和out,也就是输入和输出,指应用程序和外部设备之间的数据传递,常见的外部设备包括文件、管道、网络连接。Java 中是通过流处理IO 的。
流(Stream),是一个抽象的概念,是指一连串的数据(字符或字节),是以先进先出的方式发送信息的通道。
当程序需要读取数据的时候,就会开启一个通向数据源的流,这个数据源可以是文件,内存,或是网络连接。类似的,当程序需要写入数据的时候,就会开启一个通向目的地的流。这时候你就可以想象数据好像在这其中“流”动一样。
流的特性
先进先出:最先写入输出流的数据最先被输入流读取到。 顺序存取:可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(RandomAccessFile除外) 只读或只写:每个流只能是输入流或输出流的一种,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
IO流分类
IO流主要的分类方式有以下3种:
按数据流的方向:输入流(Input/Read)、输出流(Output/write)
按处理数据单位:字节流(InputStream、OutputStream)、
字符流(Reader,Writer)(InputStreamReader、OutputStreamWriter)
按功能:节点流、处理流
1、输入流与输出流
输入流 把数据从其他设备上读取到内存中的流。
不会自动识别中文
输出流 把数据从内存 中写出到其他设备上的流。
会自动识别中文(底层有判断)
2、字节流与字符流
字节流和字符流的用法几乎完成全一样,区别在于字节流和字符流所操作的数据单元不同,
字节流操作的单元是数据单元是8位的字节(byte),
字符流操作的是数据单元为16位的字符(char)。
字符流=字节流+编码表
字节流和字符流的其他区别:
字节流一般用来处理图像、视频、音频、PPT、Word等类型的文件。
字符流一般用于处理纯文本类型的文件,如TXT文件等,但不能处理图像视频等非文本文件。
用一句话说就是:字节流可以处理一切文件,而字符流只能处理纯文本文件。
字节流本身没有缓冲区,缓冲字节流相对于字节流,效率提升非常高。
而字符流本身就带有缓冲区,缓冲字符流相对于字符流效率提升就不是那么大了。主要是为了使用里面的方法.
由这四个类的子类名称基本都是以其父类名作为子类名的后缀。
如:InputStream的子类FileInputStream。 Reader的子类FileReader。
3、节点流和处理流
节点流:直接操作数据读写的流类,比如FileInputStream,
处理流:对一个已存在的流的链接和封装,通过对数据进行处理为程序提供功能强大、灵活的读写功能,例如BufferedInputStream(缓冲字节流)
处理流和节点流应用了Java的装饰者设计模式。
处理流是对节点流的封装,最终的数据处理还是由节点流完成的。
缓冲概念:
在诸多处理流中,有一个非常重要,那就是缓冲流。
我们知道,程序与磁盘的交互相对于内存运算是很慢的,容易成为程序的性能瓶颈。减少程序与磁盘的交互,是提升程序效率一种有效手段。缓冲流,就应用这种思路:普通流每次读写一个字节,而缓冲流在内存中设置一个缓存区,缓冲区先存储足够的待操作数据后,再与内存或磁盘进行交互。这样,在总数据量不变的情况下,通过提高每次交互的数据量,减少了交互次数。
联想一下生活中的例子,我们搬砖的时候,一块一块地往车上装肯定是很低效的。我们可以使用一个小推车,先把砖装到小推车上,再把这小推车推到车前,把砖装到车上。这个例子中,小推车可以视为缓冲区,小推车的存在,减少了我们装车次数,从而提高了效率。
需要注意的是,缓冲流效率一定高吗?不一定,某些情形下,缓冲流效率反而更低,具体请见IO流效率对比。
对文件进行操作:FileInputStream(字节输入流),FileOutputStream(字节输出流),FileReader(字符输入流),FileWriter(字符输出流)
123对管道进行操作:PipedInputStream(字节输入流),PipedOutStream(字节输出流),PipedReader(字符输入流),PipedWriter(字符输出流)
PipedInputStream的一个实例要和PipedOutputStream的一个实例共同使用,共同完成管道的读取写入操作。主要用于线程操作。
Buffered缓冲流::BufferedInputStream,BufferedOutputStream,BufferedReader,BufferedWriter,是带缓冲区的处理流,缓冲区的作用的主要目的是:避免每次和硬盘打交道,提高数据访问的效率。
转化流:InputStreamReader/OutputStreamWriter,把字节转化成字符。
123字节/字符数组:ByteArrayInputStream,ByteArrayOutputStream,CharArrayReader,CharArrayWriter是在内存中开辟了一个字节或字符数组。
123数据流:DataInputStream,DataOutputStream。
因为平时若是我们输出一个8个字节的long类型或4个字节的float类型,那怎么办呢?可以一个字节一个字节输出,也可以把转换成字符串输出,但是这样转换费时间,若是直接输出该多好啊,因此这个数据流就解决了我们输出数据类型的困难。数据流可以直接输出float类型或long类型,提高了数据读写的效率。
打印流:printStream,printWriter,一般是打印到控制台,可以进行控制打印的地方。
对象流:ObjectInputStream,ObjectOutputStream,把封装的对象直接输出,而不是一个个在转换成字符串再输出。
序列化流:SequenceInputStream。
对象序列化:把对象直接转换成二进制,写入介质中。
使用对象流需要实现Serializable接口,否则会报错。而若用transient关键字修饰成员变量,不写入该成员变量,若是引用类型的成员变量为null,值类型的成员变量为0.
字节流字符流
接下来,我们看看如何使用Java IO。
推荐的构造方法:
public FileOutputStream(String name): 根据名称字符串为参数创建对象。
1、调用系统功能去创建文件【输出流对象才会自动创建】 2、创建outputStream对象 3、把fileoutputStream对象指向这个文件
1、(字节流)(缓冲字节流)
FileInputStream、FileOutputStream
字节流的方式效率较低,不建议使用
构造器:FileOutputStream os = new FileOutputStream(file, true);
FileInputStream in = new FileInputStream(file);
BufferedInputStream、BufferedOutputStream
缓冲字节流是为高效率而设计的,真正的读写操作还是靠FileOutputStream和FileInputStream,所以其构造方法入参是这两个类的对象也就不奇怪了。
构造器:BufferedOutputStream bis = new BufferedOutputStream(new FileOutputStream(file, true));
BufferedInputStream fis = new BufferedInputStream(new FileInputStream(file));
字节输入流InputStream主要方法:
read() :从此输入流中读取一个数据字节。
read(byte[] b) :从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。
read(byte[] b, int off, int len) :从此输入流中将最多 len 个字节的数据读入一个 byte 数组中。
底层:String str = new String((char)b); 当拿到b时,做判断 if(b<0) 说明读的是汉字 拿到三个字节,再同时写到项目路径文件中,不会导致乱码
close():关闭此输入流并释放与该流关联的所有系统资源。
字节输出流OutputStream主要方法:
write(byte[] b) :将 b.length 个字节从指定 byte 数组写入此文件输出流中。
write(byte[] b, int off, int len) :将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此文件输出流。(读多少写多少)
write(int b) :将指定字节写入此文件输出流。
close() :关闭此输入流并释放与该流关联的所有系统资源。
"\r\n"手动换行
缓冲流需要刷新flush();
public class IOTest {
public static void main(String[] args) throws IOException {
File file = new File("D:/test.txt");
write(file);
System.out.println(read(file));
}
public static void write(File file) throws IOException {
//OutputStream os = new FileOutputStream(file, true);
// 缓冲字节流,提高了效率
BufferedOutputStream bis = new BufferedOutputStream(new FileOutputStream(file, true));
// 要写入的字符串
String string = "松下问童子,言师采药去。只在此山中,云深不知处。";
// 写入文件
os.write(string.getBytes());
// 刷新关闭流
os.flush():
os.close();
}
public static String read(File file) throws IOException {
//InputStream in = new FileInputStream(file);
// 缓冲字节流,提高了效率
BufferedInputStream fis = new BufferedInputStream(new FileInputStream(file));
// 一次性取多少个字节
byte[] bytes = new byte[1024];
// 用来接收读取的字节数组
StringBuilder sb = new StringBuilder();
// 读取到的字节数组长度,为-1时表示没有数据
int length = 0;
// 循环取数据
while ((length = in.read(bytes)) != -1) {
//fos.write(bytes,0,b);//写入一个字节数组的有效长度。
// 每次读取后,把数组的有效字节部分,变成字符串
sb.append(new String(bytes, 0, length));
}
// 关闭流
in.close();
return sb.toString();
}}
同时读写:
BufferedInputStream fis = new BufferedInputStream(new FileInputStream(file));
//FileOutputStream fos = new FileOutputStream(file, true);
BufferedOutputStream fos = new BufferedOutputStream(new FileOutputStream(file, true));
//定义一个int类型的b 接收每次读取到的一个字节数
int b;
byte[] bytes = new byte[1024];
StringBuilder sb=new StringBuilder();
//循环读写
while ((b = fis.read(bytes)) != -1) {
fos.write(bytes,0,b);//写入一个字节数组的有效长度。
fos.flush();
//底层:String str = new String((char)b);
//当拿到b时,做判断 if(b<0) 说明读的是汉字 拿到三个字节,再同时写到项目路径文件中
//在utf-8的编码环境下,一个中文占3个字节 在GBK的编码环境下,一个中文占2个字节
sb.append(new String(bytes,0,b));
}
2、(字符流(转换流不用)(字符流便捷类不能编码)
(转换流不用)InputStreamReader、OutputStreamWriter
简写:FileReader FileWriter
构造器:OutputStreamWrite osw = new OutputStreamWriter(new FileOutputStream(file, true));
InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "UTF-8");
OutputStreamWriter类其实也是借助FileOutputStream类实现的,吧字节转换为字符,故其构造方法是FileOutputStream的对象
(字符流)FileWriter FileReader
FileWriter等同于OutputStreamWrite
new FileWriter等同于new OutputStreamWriter(new FileOutputStream(file, true));
构造器:FileWriter osw = new FileWriter(file,true);
FileReader isr = new FileReader(file);(不能指定编码)
(缓冲字符流)BufferedReader、BufferedWriter
构造器:BufferedWriter bw = new BufferedWriter(new FileWriter(file, true));
BufferedReader br = new BufferedReader(new FileReader(file));
可见字符缓冲流效率上并没有明显提高,我们更多的是要使用它的readLine()和newLine()方法
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
字符输入流Reader主要方法:
read():读取单个字符。
read(char[] cbuf) :将字符读入数组。
从此输入流中将最多cbuf.length 个字节的数据读入一个 char数组中。
read(char[] cbuf, int off, int len) : 将字符读入数组的某一部分。
read(CharBuffer target) :试图将字符读入指定的字符缓冲区。
close() :关闭此流,输入关闭时自动刷新。
字符输出流Writer主要方法:
write(char[] cbuf) :写入字符数组。
write(char[] cbuf, int off, int len) :写入字符数组的某一部分。(读多少写多少)
write(int c) :写入单个字符。
write(String str) :写入字符串。
write(String str, int off, int len) :写入字符串的某一部分。
writeUTF("读字符串")writeChars()writeBytes()
flush() :刷新该流的缓冲。
close() :关闭此流,但要先刷新它。
字符缓冲流还有两个独特的方法:
BufferedReader类readLine() :读取一个文本行。
BufferedWriter类newLine() :写入一个行分隔符(换行)。这个方法会自动适配所在系统的行分隔符。
public class IOTest {
public static void write(File file) throws IOException {
//OutputStreamWriter可以显示指定字符集,否则使用默认字符集
//OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(file, true), "UTF-8");
FileWriter osw = new FileWriter(file,true);
// 要写入的字符串
String string = "松下问童子,言师采药去。只在此山中,云深不知处。";
osw.write(string);
osw.close();
}
public static String read(File file) throws IOException {
//InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "UTF-8");
FileReader isr = new FileReader(file);
// 字符数组:一次读取多少个字符
char[] chars = new char[1024];
// 每次读取的字符数组先append到StringBuilder中
StringBuilder sb = new StringBuilder();
// 读取到的字符数组长度,为-1时表示没有数据
int length;
// 循环取数据
while ((length = isr.read(chars)) != -1) {
// 每次读取后,把数组的有效字符部分,变成字符串
sb.append(chars, 0, length);
//写osw.write(length);
}
// 关闭流
isr.close();
return sb.toString()
}}
缓冲字符流 BufferedReader、BufferedWriter
读一行
public static void main(String[] args) throws IOException {
BufferedWriter bw = new BufferedWriter(new FileWriter("day02z-code\\src\\com\\hongpeng\\d21\\file_\\bufferedWriter_Reader.txt"));
//new OutputStreamWriter(new FileOutputStream(file, true), "UTF-8");
//new fileWriter
BufferedReader br = new BufferedReader(new FileReader("day02z-code\\src\\com\\hongpeng\\d21\\file_\\StreamWriter_Reader.txt"));
writeread(bw,br);
}
public static void writeread(BufferedWriter bw,BufferedReader br)throws IOException{
// InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "UTF-8");
// 用来接收读取的字节数组
StringBuilder sb = new StringBuilder();
// 按行读数据
String line;
// 循环取数据
while ((line = br.readLine()) != null) {
// 将读取的内容转换成字符串
sb.append(line);
bw.write(line);
bw.newline();//换行
bw.flush();
}
// 关闭流
bw.close();
br.close();
System.out.println(sb.toString());
}
同时读写
public static void main(String[] args) throws IOException {
FileWriter osw = new FileWriter("day02z-code\\src\\com\\hongpeng\\d21\\file_\\StreamWriter_Reader.txt");
FileReader isr = new FileReader("day02z-code\\src\\com\\hongpeng\\d21\\file_\\bufferedWriter_Reader.txt");
writeread(osw,isr);
}
public static void writeread(FileWriter osw,FileReader isr)throws IOException{
// InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "UTF-8");
// 字符数组:一次读取多少个字符
char[] chars = new char[1024];
// 每次读取的字符数组先append到StringBuilder中
StringBuilder sb = new StringBuilder();
// 读取到的字符数组长度,为-1时表示没有数据
int length;
// 循环取数据
while ((length = isr.read(chars)) != -1) {
// 将读取的内容转换成字符串
sb.append(chars, 0, length);
osw.write(chars,0,length);
osw.flush();
}
// 关闭流
osw.close();
isr.close();
System.out.println(sb.toString());
}
读取文件创建对象
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new FileReader("E:\\itcast\\蔡徐坤.txt"));
//储存读取一行数据
String line;
//创建ArrayList集合
ArrayList als = new ArrayList<>();
//循环读取
while ((line = br.readLine())!=null){
//分割
String[] str = line.split("-");
//创对象
Student s = new Student(str[0],Integer.parseInt(str[1]),str[2]);
//添加到集合
als.add(s);
//
}
for (Student student:als) {
System.out.println(student);
}
br.close();
}
private String name;
private int age;
private String neppy;
数据、字节、管道(多线程)
DataInputStream,DataOutputStream
ByteArrayInputStream,ByteArrayOutputStream,CharArrayReader,CharArrayWriter
PipedInputStream(字节输入流),PipedOutStream(字节输出流),PipedReader(字符输入流),PipedWriter(字符输出流)
序列化流(对象流)
File -> Settings -> Inspections -> Serialization issues -> S UID S UID s long
概念:
序列化是指将Java对象转换为字节序列的过程,
Java 提供了一种对象序列化的机制。用一个字节序列可以表示一个对象,该字节序列包含该对象的数据、对象的类型和对象中存储的属性等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
而反序列化则是将字节序列转换为Java对象的过程。
反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。看图理解序列化:
序列化流【理解】
什么时候序列化?
当你想把的内存中的对象状态保存到一个文件中或者数据库中时候。
当你想用套接字在网络上传送对象的时候。
当你想通过RMI传输对象的时候。
如何实现序列化?
实现了Serializable接口
什么是反序列化?
该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化
优点
可以把对象写入文本文件或者在网络中传输
实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘上(如:存储在文件里),实现永久保存对象。
利用序列化实现远程通信,即:能够在网络上传输对象。
注意事项细节 1、当一个父类实现序列化,子类就会自动实现序列化,不需要显式实现Serializable接口。
2、当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化。
如果一个对象的成员变量是一个对象,那么这个对象的数据成员也会被保存!这是能用序列化解决深拷贝的重要原因。
3、并非所有的对象都可以进行序列化,比如:
安全方面的原因,比如一个对象拥有private,public等成员变量,对于一个要传输的对象,比如写到文件,或者进行RMI传输等等,在序列化进行传输的过程中,这个对象的private等域是不受保护的;
资源分配方面的原因,比如socket,thread类,如果可以序列化,进行传输或者保存,也无法对他们进行重新的资源分配,而且,也是没有必要这样实现。
4、声明为static和transient类型的成员变量不能被序列化。因为static代表类的状态,transient代表对象的临时数据。
5、serialVersionUID (类名AIT ENTER)
序列化运行时会使用一个称为 serialVersionUID 的版本号,并与每个可序列化的类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。
如果接收者加载的该对象的类的 serialVersionUID 与对应的发送者的类的版本号不同,则反序列化将会导致 InvalidClassException。
可序列化类可以通过声明名为 "serialVersionUID" 的字段(该字段必须是静态 (static)、最终 (final) 的 long 型字段)显式声明其自己的 serialVersionUID。
如果序列化的类未显式的声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值,如“Java(TM) 对象序列化规范”中所述。不过,强烈建议 所有可序列化类都显式声明 serialVersionUID 值,原因是计算默认的 serialVersionUID 对类的详细信息具有较高的敏感性,根据编译器实现的不同可能千差万别,这样在反序列化过程中可能会导致意外的 InvalidClassException。
因此,为保证 serialVersionUID 值跨不同 java 编译器实现的一致性,序列化类必须声明一个明确的 serialVersionUID 值。
还强烈建议使用 private 修饰符显示声明 serialVersionUID(如果可能),原因是这种声明仅应用于直接声明类 -- serialVersionUID 字段作为继承成员没有用处。数组类不能声明一个明确的 serialVersionUID,因此它们总是具有默认的计算值,但是数组类没有匹配 serialVersionUID 值的要求。
6、Java有很多基础类已经实现了serializable接口,比如String,Vector等。但是也有一些没有实现serializable接口的。
有了上面关于序列化和反序列化的详细介绍,现在你对平时所用的序列化和反序列化是如何实现的,什么场景下会使用它,是不是更加深刻了吧
ObjectOutputStream类ObjectInputStream类
java.io.ObjectOutputStream 类,将Java对象的原始数据类型写出到文件,实现对象的持久存储。
构造代码如下: ObjectOutputStream out = new ObjectOutputStream( new FileOutputStream("aa.txt"));
ArrayList al = new ArrayList();保存对象
list.add(new Employee("周淑怡","长了张嘴",24));
out.writeObject(list);
void writeObject() 写一个al集合对象
ObjectInputStream反序列化流,将之前使用ObjectOutputStream序列化的原始数据恢复为对象。
构造代码如下: ObjectInputStream in = new ObjectIntputStream( new FileIntputStream("aa.txt"));
ArrayList arrayList = (ArrayList) in.readObject();
for (Object o:arrayList) { System.out.println(o);
}
Object readObject() 读一个集合对象
public static void main(String [] args) {
output();
}
private static void output() {
try {
// 创建序列化流对象
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("day02z-code\\src\\com\\hongpeng\\d21\\file_\\employee.txt"));
// 写出对象
ArrayList list = new ArrayList();
list.add(new Employee("周淑怡","长了张嘴",24));
out.writeObject(list);
// 释放资源
out.close();
System.out.println("Serialized data is saved"); // 姓名,地址被序列化,年龄没有被序列化。
} catch(IOException i) {
i.printStackTrace();
}
}
@Test
public void input(){
try {
// 创建反序列化流
ObjectInputStream in = new ObjectInputStream(new FileInputStream("D:\\ideajava\\U1-code\\day02z-code\\src\\com\\hongpeng\\d21\\file_\\employee.txt"));
ArrayList arrayList = (ArrayList) in.readObject();
for (Object o:arrayList) {
System.out.println(o);
}
// 释放资源
in.close();
}catch(IOException i) {
// 捕获其他异常
i.printStackTrace();
return;
}catch(ClassNotFoundException c) {
// 捕获类找不到异常
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
}
}
class Employee{
标准JavaBean八个步骤
1. 私有成员变量: 保护
2. 无参构造:快速创建对象
全参构造:在创建对象的时候给属性赋值
getter and setter:提供公共属性访问方式
equals and hashcode:
重写equals: 比较对象的时候比较是对象的属性值而不是地址值
重写hashCode: HashSet集合去重 (对象的Hash值 && (对象的地址值 || 对象的equals方法))
toString: 输出对象看到的是对象的属性值
实现Serializable接口: 能被序列化流和反序列化流操作的标记
自动生成serialVersionUID: 给类身份证,保证我在反序列化的时候能够识别文件中的对象
}
两个异常:
对于JVM可以反序列化对象,它必须是能够找到class文件的类。如果找不到该类的class文件,则抛出一个 ClassNotFoundException 异常。
另外,当JVM反序列化对象时,能找到class文件,但是class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个InvalidClassException异常。发生这个异常的原因如下:
1、该类的序列版本号与从流中读取的类描述符的版本号不匹配 2、该类包含未知数据类型 2、该类没有可访问的无参数构造方法
Serializable 接口给需要序列化的类,提供了一个序列版本号。serialVersionUID 该版本号的目的在于验证序列化的对象和对应类是否版本匹配。
打印流
概念:
java.io.PrintStream类
字节打印流PrintStream,字符打印流PrintWriter
// System.in 编译类型 InputStream // System.in 运行类型 BufferedInputStream BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); BufferedInputStream bis = new BufferedInputStream(new InflaterInputStream(System.in)); // 表示的是标准输入 键盘 //2. 编译类型 PrintStream //3. 运行类型 PrintStream // 表示的是标准输入 显示器打印流特点:
A:只操作目的地,不操作数据源 B:可以操作任意类型的数据 C:如果启用了自动刷新,在调用println()方法的时候,能够换行并刷新 D:可以直接操作文件
如果该流的构造方法能够同时接收File和String类型的参数,一般都是可以直接操作文件的!
PrintStream是OutputStream的子类,PrintWriter是Writer的子类,两者处于对等的位置上,所以它们的API是非常相似的。无非一个是字节打印流,一个是字符打印流。
PrintStream out = System.out;
//输出到控制台
out.print("john, hello");
//因为print底层使用的是write , 所以我们可以直接调用write进行打印/输出
out.write("韩顺平,你好".getBytes());
out.close();
//更改输出位置
System.setOut(new PrintStream("e:\\f1.txt"));
System.out.println("hello, 韩顺平教育~");
字节输出打印流PrintStream复制文本文件
字符输出打印流PrintWriter复制文本文件
public static void main(String[] args) throws IOException {
BufferedReader br=new BufferedReader(new FileReader("day02z-code\\src\\com\\hongpeng\\d21\\file_\\床前明月光.txt"));
//PrintWriter ps = new PrintWriter("")
PrintStream ps=new PrintStream("day02z-code\\src\\com\\hongpeng\\d21\\file_\\PrintStream.txt");
String line;
while((line=br.readLine())!=null) {
ps.println(line);
}
br.close();
ps.close();
}
####
Properties属性类
我想各位对这个Properties类多多少少也接触过了,首先Properties类并不在IO包下,那为啥要和IO流一起讲呢?原因很简单因为properties类经常和io流的联合一起使用。
(1)是一个集合类,Hashtable的子类
Properties properties = new Properties();
(2)特有功能 A:public Object setProperty(String key,String value)//保存一对属性。 B:public String getProperty(String key)使用此属性列表中//指定的键搜索属性值。 C:public Set stringPropertyNames()//所有键的名称的集合。 (3)和IO流结合的方法 把键值对形式的文本文件内容加载到集合中 public void load(Reader reader) public void load(InputStream inStream) 把集合中的数据存储到文本文件中 public void store(FileWriter writer,String comments) public void store(FileOutputStream out,String comments)
Properties概述
java.util.Properties 继承于Hashtable ,来表示一个持久的属性集。它使用键值结构存储数据,每个键及其对应值都是一个字符串。该类也被许多Java类使用,比如获取系统属性时,System.getProperties 方法就是返回一个Properties对象。
Properties类
构造方法 public Properties() :创建一个空的属性列表。
基本的存储方法 public Object setProperty(String key, String value) : 保存一对属性。 public String getProperty(String key) :使用此属性列表中指定的键搜索属性值。 public Set
stringPropertyNames() :所有键的名称的集合。
public class ProDemo {
public static void main(String[] args) throws FileNotFoundException {
// 创建属性集对象
Properties properties = new Properties();
// 添加键值对元素
properties.setProperty("filename", "a.txt");
properties.setProperty("length", "209385038");
properties.setProperty("location", "D:\\a.txt");
// 打印属性集对象
System.out.println(properties);
// 通过键,获取属性值
System.out.println(properties.getProperty("filename"));
System.out.println(properties.getProperty("length"));
System.out.println(properties.getProperty("location"));
// 遍历属性集,获取所有键的集合
Set strings = properties.stringPropertyNames();
// 打印键值对
for (String key : strings ) {
System.out.println(key+" -- "+properties.getProperty(key));
}
}
}
输出结果:
{filename=a.txt, length=209385038, location=D:\a.txt}
a.txt
209385038
D:\a.txt
filename -- a.txt
length -- 209385038
location -- D:\a.txt
与流相关的方法 public void load(InputStream inStream): 从字节输入流中读取键值对。
参数中使用了字节输入流,通过流对象,可以关联到某文件上,这样就能够加载文本中的数据了。现在文本数据格式如下:
filename=Properties.txt length=123 location=C:\Properties.txt
加载代码演示:
public class ProDemo {
public static void main(String[] args) throws FileNotFoundException {
// 创建属性集对象
Properties pro = new Properties();
// 加载文本中信息到属性集
pro.load(new FileInputStream("Properties.txt"));
// 遍历集合并打印
Set strings = pro.stringPropertyNames();
for (String key : strings ) {
System.out.println(key+" -- "+pro.getProperty(key));
}
}
}
输出结果:
filename -- Properties.txt
length -- 123
location -- C:\Properties.txt
文本中的数据,必须是键值对形式,可以使用空格、等号、冒号等符号分隔。
怎么说呢,io流的基础回顾就先告一段落了,浅尝辄止。循序渐进,实践中慢慢总结!更何况我还很low,依旧任重而道远。
现在jdk已经出到13了,io流也有了许多的变化。有时间会从头整理一下,一定会有机会的! ————————————————
IO流对象
第一节中,我们大致了解了IO,并完成了几个案例,但对IO还缺乏更详细的认知,那么接下来我们就对Java IO细细分解,梳理出完整的知识体系来。
Java种提供了40多个类,我们只需要详细了解一下其中比较重要的就可以满足日常应用了。
File类
概念,构造,常用方法
File类是用来操作文件的类,但它不能操作文件中的数据。
public class File extends Object implements Serializable, Comparable
File类实现了Serializable、 Comparable
,说明它是支持序列化和排序的。 File类的构造方法
File(File parent, String child) 根据父 parent 抽象路径名和 child 路径名字符串创建一个新 File 实例。 File(String pathname) 通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例。 File(String parent, String child) 根据父 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。
String parent = "F:\aaa";
String child = "bbb.txt"
File(URI uri) 通过将给定的 file: URI 转换为一个抽象路径名来创建一个新的 File 实例。
File类的注意点:
一个File对象代表硬盘中实际存在的一个文件或者目录。
File类构造方法不会给你检验这个文件或文件夹是否真实存在,因此无论该路径下是否存在文件或者目录,都不影响File对象的创建。
常用方法
createNewFile() 文件不存在,创建一个新的空文件并返回
true,文件存在,不创建文件并返回。
delete() 删除此抽象路径名表示的文件或目录。
exists() 测试此抽象路径名表示的文件或目录是否存在。
boolean isDirectory() :此File表示的是否为目录。
public boolean isFile() :此File表示的是否为文件。
getAbsoluteFile() 返回此抽象路径名的绝对路径名形式。
getAbsolutePath() 返回此抽象路径名的绝对路径名字符串。
length() 返回由此抽象路径名表示的文件的长度。
mkdirs() 创建此抽象路径名指定的(多级)目录。包括任何必需但不存在的父目录。
返回一个String数组,表示该File目录中的所有子文件或目录。
public String[] list();
public File[] listFiles()
指定的目录必须存在
指定的必须是目录。
public class FileTest {
public static void main(String[] args) throws IOException {
File file = new File("C:/Mu/fileTest.txt");
// 判断文件是否存在
if (!file.exists()) {
// 不存在则创建
file.createNewFile();
}
System.out.println("文件的绝对路径:" + file.getAbsolutePath());
System.out.println("文件的大小:" + file.length());
//获取当前目录下的文件以及文件夹的名称。
String[] names = file.list();
for(String name : names){
System.out.println(name);
}
————————————————
// 刪除文件
file.delete();
}}
递归遍历文件夹下所有文件以及子文件
public static void main(String[] args) {
File file=new File("D:\\java专属IO测试");
Recursion(file);
}
public static void Recursion(File file){
//1、判断传入的是否是目录
if(!file.isDirectory()){
//不是目录直接退出
return;
}
//已经确保了传入的file是目录
File[] files = file.listFiles();
//遍历files
for (File f: files) {
//如果该目录下文件还是个文件夹就再进行递归遍历其子目录
if(f.isDirectory()){
//递归
Recursion(f);
}else {
//如果该目录下文件是个文件,则打印对应的名字
System.out.println(f.getName());
}
}
}
字节流基类
概念:
InputStream与OutputStream是两个抽象类,是字节流的基类。
以InputStream为例,它继承了Object,实现了Closeable
public abstract class InputStream extends Object implements Closeable
InputStream类的实现子类
InputStream:InputStream是所有字节输入流的抽象基类,前面说过抽象类不能被实例化,实际上是作为模板而存在的,为所有实现类定义了处理输入流的方法。
FileInputSream:文件输入流,一个非常重要的字节输入流,用于对文件进行读取操作。
PipedInputStream:管道字节输入流,能实现多线程间的管道通信。
ByteArrayInputStream:字节数组输入流,从字节数组(byte[])中进行以字节为单位的读取,也就是将资源文件都以字节的形式存入到该类中的字节数组中去。
FilterInputStream:装饰者类,具体的装饰者继承该类,这些类都是处理类,作用是对节点类进行封装,实现一些特殊功能。
DataInputStream:数据输入流,它是用来装饰其它输入流,作用是“允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型”。
BufferedInputStream(封装):缓冲流,对节点流进行装饰,内部会有一个缓存区,用来存放字节,每次都是将缓存区存满然后发送,而不是一个字节或两个字节这样发送,效率更高。
ObjectInputStream:对象输入流,用来提供对基本数据或对象的持久存储。通俗点说,也就是能直接传输对象,通常应用在反序列化中。它也是一种处理流,构造器的入参是一个InputStream的实例对象。
OutputStream类继承关系图:
OutputStream类继承关系与InputStream类似,需要注意的是多了PrintStream.
字符流基类
概念:
与字节流类似,字符流也有两个抽象基类,分别是Reader和Writer。其他的字符流实现类都是继承了这两个类。
Reader类的实现子类
InputStreamReader:从字节流到字符流的桥梁(InputStreamReader构造器入参是FileInputStream的实例对象),它读取字节并使用指定的字符集将其解码为字符。它使用的字符集可以通过名称指定,也可以显式给定,或者可以接受平台的默认字符集。
BufferedReader:从字符输入流中读取文本,设置一个缓冲区来提高效率。BufferedReader是对InputStreamReader的封装,前者构造器的入参就是后者的一个实例对象。
FileReader:用于读取字符文件的便利类,new FileReader(File file)等同于new InputStreamReader(new FileInputStream(file, true),"UTF-8"),但FileReader不能指定字符编码和默认字节缓冲区大小。
PipedReader :管道字符输入流。实现多线程间的管道通信。
CharArrayReader:从Char数组中读取数据的介质流。
StringReader :从String中读取数据的介质流。
Writer与Reader结构类似,方向相反,不再赘述。唯一有区别的是,Writer的子类多了PrintWriter。
位、字节、字符
字节(Byte)是计量单位,表示数据量多少,是计算机信息技术用于计量存储容量的一种计量单位,通常情况下一字节等于八位。
字符(Character)计算机中使用的字母、数字、字和符号,比如’A’、‘B’、’$’、’&'等。
一般在英文状态下一个字母或字符占用一个字节,一个汉字用两个字节表示。
字节与字符:
ASCII 码中,一个英文字母(不分大小写)为一个字节,一个中文汉字为两个字节。 UTF-8 编码中,一个英文字为一个字节,一个中文为三个字节。 Unicode 编码中,一个英文为一个字节,一个中文为两个字节。 符号:英文标点为一个字节,中文标点为两个字节。例如:英文句号 . 占1个字节的大小,中文句号 。占2个字节的大小。 UTF-16 编码中,一个英文字母字符或一个汉字字符存储都需要 2 个字节(Unicode 扩展区的一些汉字存储需要 4 个字节)。 UTF-32 编码中,世界上任何字符的存储都需要 4 个字节。 ———————————————— :【Java基础-3】吃透Java IO:字节流、字符流、缓冲流_云深不知处-CSDN博客 ———————————————— :史上最骚最全最详细的IO流教程,小白都能看懂!_宜春-CSDN博客
网络编程
首先理清一个概念:网络编程不等于网站编程,网络编程即使用套接字来达到进程间通信,现在一般称为TCP/IP编程。
一、计算机网络、IP、端口、协议
(一)计算机网络
概念:
计算机网络是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路连接起来,在网络操作系统,网络管理软件及网络通信协议的管理和协调下,实现资源共享和信息传递的计算机系统。
主要功能
资源共享 信息传输与集中处理 均衡负荷与分布处理 综合信息服务(www / 综合业务数字网络 ISDN)
计算机网络三高问题
高并发,高性能,高可用。
计算机网络分类
局域网 城域网 广域网 互联网 等等… (Local Area Network;LAN) 通常我们常见的“LAN”就是指局域网,这是我们最常见、应用最广的一种网络
(二)IP地址("域名")(协议)
概念
IP协议:网络互连协议ipconfig ping
计算机在网络中的唯一标识
每个人的电脑都有一个独一无二的IP地址,这样互相通信时就不会传错信息了。
192.168.157.1
无连接数据报传送,数据报路由选择和差错控制
分类
IP地址根据版本可以分类为:IPv4和IPv6
IPv4 IPv6 地址长度 IPv4协议具有32位(4字节)地址长度 IPv6协议具有128位(16字节)地址长度 格式 IPv4 地址的文本格式为 nnn.nnn.nnn.nnn,其中 0<=nnn<=255,而每个 n 都是十进制数。可省略前导零。192.168.157.1||192.168.60.1 IPv6 地址的文本格式为xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx,其中每个 x 都是十六进制数可省略前导零。fe80::2556:7879:6797:fe25%6||fe80::e58e:f072:a29a:4bd%10 数量 共有43亿,30亿在北美,4亿在亚洲,2011年就已经用尽 多到每一粒沙子都可以分配一个IPv6地址
IPv4又可以分为五类:
A类:在IP地址的四段号码中,第一段号码为网络号码,剩下的三段号码为本地计算机的号码;A类IP地址中网络的标识长度为8位,主机标识的长度为24位,A类网络地址数量较少,有126个网络,每个网络可以容纳主机数达1600多万(256的三次方-2)台。
B类:在IP地址的四段号码中,前两段号码为网络号码。B类IP地址中网络的标识长度为16位,主机标识的长度为16位,B类网络地址适用于中等规模的网络,有16384个网络,每个网络所能容纳的计算机数为6万多(256的二次方-2)台
C类:在IP地址的四段号码中,前三段号码为网络号码,剩下的一段号码为本地计算机的号码;此类地址中网络的标识长度为24位,主机标识的长度为8位,C类网络地址数量较多,有209万余个网络。适用于小规模的局域网络,每个网络最多只能包含254(256-2)台计算机
D类:此类IP地址在历史上被叫做多播地址(multicast address),即组播地址;在以太网中,多播地址命名了一组应该在这个网络中应用接收到一个分组的站点;多播地址的最高位必须是“1110”,范围从224.0.0.0到239.255.255.255
E类: 此类地址也不分网络地址和主机地址,它的第1个字节的前五位固定为“11110”,为将来使用保留,地址范围从240.0.0.1到255.255.255.254
InetAddress类(IP)
说到IP地址,就要引入一个类:InetAddress 此类表示互联网协议 (IP) 地址。
InetAddress类无构造方法
.getByName("localhost");得到ip地址
1.常用方法摘要
方法名 用法 作用 static InetAddress getLocalHost() InetAddress ip = InetAddress.getLocalHost(); 返回本地主机名和IP。 static InetAddress getByName(String host) InetAddress.getByName("localhost"); 给定主机名,返回主机名和IP。 String getHostName() ip.getHostName(); 返回 IP 地址的主机名。 String getHostAddress() ip.getHostAddress(); 返回 IP 地址的字符串。(文本表示形式) byte[] getAddress() Arrays.toString(ip.getAddress()) 返回此 InetAddress 对象的原始 IP 地址。 127.0.0.1:本机地址,主要用于测试。别名:Localhost
192.168.157.1
获取百度地址
InetAddress inetAddress = InetAddress.getByName("www.baidu.com"); // 获取此 IP 地址的主机名。 System.out.println(inetAddress.getHostName()); //返回 IP 地址字符串(以文本表现形式)。 System.out.println(inetAddress.getHostAddress()); }
(三)端口
概念,细节
IP地址用来标识一台计算机,端口号是用来区分一台机器上不同的应用程序的。 我们使用IP地址加端口号,就可以保证数据准确无误地发送到对方计算机的指定软件上了。
端口是虚拟的概念,是一个逻辑端口。 当我们使用网络软件一打开,那么操作系统就会为网络软件分配一个随机的端口号,或者打开的时候向系统要指定的端口号。 通过端口,可以在一个主机上运行多个网络应用程序。端口的表示是一个16位的二进制整数,2个字节,对应十进制的0~65535。char
端口号在计算机内部是占2个字节。一台机器上最多有65536个端口号。一个应用程序可以占用多个端口号。端口号如果被一个应用程序占用了,那么其他的应用程序就无法再使用这个端口号了。
记住一点,我们编写的程序要占用端口号的话
占用1024以上的端口号,1024以下的端口号不要去占用,因为系统有可能会随时征用。端口号本身又分为TCP端口和UDP端口,TCP的8888端口和UDP的8888端口是完全不同的两个端口。TCP端口和UDP端口都有65536个
分类
公有端口:0~1023
HTTP:80 HTTPS:443 FTP:21 Telnet:23
程序注册端口(分配给用户或者程序):1024~49151
Tomcat:8080 MySQL:3306 Oracle:1521
动态、私有端口:49152~65535
DOS命令查看端口
查看所有端口:netstat -ano
查看指定端口:netstat -ano|findstr "端口号"
查看指定端口的进程:tasklist|findstr "端口号"
InetSocketAddress类(Prot)
说到端口,则要引入一个类:InetSocketAddress
此类实现 IP 套接字地址(IP 地址 + 端口号)。
构造方法摘要
InetSocketAddress(InetAddress addr, int port) 根据 IP 地址和端口号创建套接字地址。
InetSocketAddress(int port) 创建套接字地址,其中 IP 地址为通配符地址,端口号为指定值。
InetSocketAddress(String hostname, int port) 根据主机名和端口号创建套接字地址。
常用方法摘要
InetAddress getAddress() 获取 InetAddress。 String getHostName() 获取 hostname。 int getPort() 获取端口号。
案例演示
import java.net.InetAddress;
import java.net.InetSocketAddress;
public class TestPort {
public static void main(String[] args) {
InetSocketAddress inetSocketAddress = new InetSocketAddress("127.0.0.1",8082);
System.out.println(inetSocketAddress);
//返回主机名
System.out.println(inetSocketAddress.getHostName());
//获得InetSocketAddress的端口
System.out.println(inetSocketAddress.getPort());
//返回一个InetAddress对象(IP对象)
InetAddress address = inetSocketAddress.getAddress();
System.out.println(address);
}
}
(四)网络通信协议及接口
网络通信协议
计算机网络中用户连接和通讯的规则称为协议
计算机网络中实现通信必须有一些约定,即通信协议;包括对速率,传输代码,代码结构,传输控制步骤,出错控制等制定的标准。常见的网络通信协议有:TCP/IP协议、IPX/SPX协议、NetBEUI协议等。
TCP/IP协议:传输控制协议/因特网互联协议(Transmission Control Protocol/Internet Protocal),是Internet最基本、最广泛的协议。
它定义了计算机如何连入因特网,以及数据如何在它们之间传输的标准。
它的内部包含一系列的用于处理数据通信的协议,并采用了4层的分层模型,每一层都呼叫它的下一层所提供的协议来完成自己的需求。
网络通信接口
为了使两个节点之间能进行对话,必须在他们之间建立通信工具(即接口),使彼此之间,能进行信息交换。接口包括两部分:
硬件装置:实现结点之间的信息传送 软件装置:规定双方进行通信的约定协议
通信协议分层思想
为什么要分层
由于结点之间联系很复杂,在制定协议时,把复杂成份分解成一些简单的成份,再将它们复合起来。最常用的复合方式就是层次方式,及同层间可以通信,上一层可以调用下一层,而与再下一层不发生关系。各层互不影响,利于系统的开发和扩展。
通信协议的分层规定
把用户应用程序作为最高层,把物理通信线路作为最底层,将其间的协议处理分为若干层,规定每层处理的任务,也规定每层的接口标准。
参考模型
上图中,TCP/IP协议中的四层分别是应用层、传输层、网络层和链路层,每层分别负责不同的通信功能。
应用层:主要负责应用程序的协议,例如HTTP协议、FTP协议等。 传输层:主要使网络程序进行通信,在进行网络通信时,可以采用TCP协议,也可以采用UDP协议。 网络层:网络层是整个TCP/IP协议的核心,它主要用于将传输的数据进行分组,将分组数据发送到目标计算机或者网络。 数据链路层:链路层是用于定义物理传输通道,通常是对某些网络连接设备的驱动协议,例如针对光纤、网线提供的驱动。 我们编写的程序位于应用层,因此我们的程序是和TCP/UDP打交道的
协议分类概念
概念:
通信的协议还是比较复杂的,java.net包中包含的类和接口,它们提供低层次的通信细节,我们可以直接使用这些类和接口,来专注于网络程序开发,而不用考虑通信的细节。 java.net包中提供了两种常见的网络协议的支持:TCP和UDP
TCP是可靠的连接,TCP就像打电话,需要先打通对方电话,等待对方有回应后才会跟对方继续说话,也就是一定要确认可以发信息以后才会把信息发出去。
TCP上传任何东西都是可靠的,只要两台机器上建立起了连接,在本机上发送的数据就一定能传到对方的机器上。
TCP传送数据可靠,但传送得比较慢;
UDP就好比发电报,发出去就完事了,对方有没有接收到它都不管,所以UDP是不可靠的。
UDP传送数据不可靠,但是传送得快。
1.UDP
用户数据报协议(User Datagram Protocol)。
UDP是无连接通信协议,即在数据传输时,数据的发送端和接收端不建立逻辑连接。简单来说,当一台计算机向另外一台计算机发送数据时,发送端不会确认接收端是否存在,就会发出数据,同样接收端在收到数据时,也不会向发送端反馈是否收到数据。
由于使用UDP协议消耗资源小,通信效率高,所以通常都会用于音频、视频和普通数据的传输
例如视频会议都使用UDP协议,因为这种情况即使偶尔丢失一两个数据包,也不会对接收结果产生太大影响。
但是在使用UDP协议传送数据时,由于UDP的面向无连接性,不能保证数据的完整性,因此在传输重要数据时,不建议使用UDP协议。
特点:数据被限制在64kb以内,超出这个范围就不能发送了。
数据报(Datagram):网络传输的基本单位
2.TCP
传输控制协议(Transmission Control Protocol)。TCP协议是面向连接的通信协议,即传输数据之前,在发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输。
在TCP连接中必须要明确客户端与服务器端,由客户端向服务端发出连接请求,每次连接的创建都需要经过“三次握手”。
(1)三次握手
TCP协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可靠。
第一次握手,客户端发送SYN(SEQ=x)报文给服务器端,进入SYN_SEND状态。 (客户端向服务器端发出连接请求,等待服务器确认。) 第二次握手,服务器端收到SYN报文,回应一个SYN (SEQ=y)ACK(ACK=x+1)报文,进入SYN_RECV状态。(服务器端向客户端回送一个响应,通知客户端收到了连接请求。) 第三次握手,客户端收到服务器端的SYN报文,回应一个ACK(ACK=y+1)报文,进入Established状态。(客户端再次向服务器端发送确认信息,确认连接。) 三次握手完成,TCP客户端和服务器端成功地建立连接,可以开始传输数据了。整个交互过程如下图所示。
(2)四次挥手
其次,TCP的客户端和服务端断开连接,需要四次挥手
客户端打算关闭连接,此时会发送一个 TCP 首部 FIN 标志位被置为 1 的报文,也即 FIN 报文,之后客户端进入 FIN_WAIT_1 状态。 服务端收到该报文后,就向客户端发送 ACK 应答报文,接着服务端进入 CLOSED_WAIT 状态。 客户端收到服务端的 ACK 应答报文后,之后进入 FIN_WAIT_2 状态。 等待服务端处理完数据后,也向客户端发送 FIN 报文,之后服务端进入 LAST_ACK 状态。 客户端收到服务端的 FIN 报文后,回一个 ACK 应答报文,之后进入 TIME_WAIT 状态 服务器收到了 ACK 应答报文后,就进入了 CLOSE 状态,至此服务端已经完成连接的关闭。 客户端在经过 2MSL 一段时间后,自动进入 CLOSE 状态,至此客户端也完成连接的关闭。 你可以看到,每个方向都需要一个 FIN 和一个 ACK,因此通常被称为四次挥手。这里一点需要注意是:主动关闭连接的,才有 TIME_WAIT 状态。
为什么挥手需要四次? 关闭连接时,客户端向服务端发送 FIN 时,仅仅表示客户端不再发送数据了但是还能接收数据。服务器收到客户端的 FIN 报文时,先回一个 ACK 应答报文,而服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送 FIN 报文给客户端来表示同意现在关闭连接。从上面过程可知,服务端通常需要等待完成数据的发送和处理,所以服务端的 ACK 和 FIN 一般都会分开发送,从而比三次握手导致多了一次。参考
通俗理解 三次握手A:我要过来了!B:我知道你要过来了!A:我现在过来! 四次挥手A:我们分手吧!B:真的分手吗?B:真的真的要分手吗?A:是的! 由此,可以可靠地进行连接和断开。
二、UDP网络编程和TCP网络编程
网络编程也叫做Socket编程,即套接字编程。套接字指的是两台设备之间通讯的端点。
(一)UDP网络编程
从技术意义上来讲,只有TCP才会分Server和Client。
对于UDP来说,从严格意义上来讲,并没有所谓的Server(服务端)和Client(客户端)。
java.net包给我们提供了两个类DatagramSocket(此类表示用于发送和接收数据报的套接字)和DatagramPacket(该类表示数据报的数据包。 打包)
1.DatagramSocket
此类表示用于发送和接收数据报的套接字
(1)构造方法摘要 protected DatagramSocket()构造数据报套接字并将其绑定到本地主机上的任何可用端口。发送 protected DatagramSocket(int port)构造数据报套接字并将其接收绑定到本地主机上的指定端口。 protected DatagramSocket(int port, InetAddress laddr)创建一个数据报套接字,绑定到指定的本地地址。
socket.send(packet);//发送
socket.receive(packet);阻塞式接收
2.DatagramPacket
该类表示数据报的数据包。 打包
(1)构造方法摘要 DatagramPacket(byte[] buf, int offset, int length)构造一个 DatagramPacket用于接收指定长度的数据报包到缓冲区中。 DatagramPacket(byte[] buf, int offset, int length, InetAddress address, int port)构造用于发送指定长度的数据报包到指定主机的指定端口号上。
byte[] buf:发送的数据、int offset:起始位置、int length:字节数组长度、
InetAddress address:ip地址对象InetAddress.getByName("ip")、int port:端口号
(2)常用方法摘要
byte[] getData() 返回数据报包中的数据。
int getLength() 返回要发送的数据的长度或接收到的数据的长度。
InetAddress getAddress() 返回该数据报发送或接收数据报的计算机的IP地址。
getSocketAddress();返回该数据报发送或接收数据报的计算机的IP地址和端口号
3.代码实现
发送方
public class UDPSender {
public static void main(String[] args) throws IOException {
//1、创建一个socket
DatagramSocket socket = new DatagramSocket();
//2、ip
InetAddress inet = InetAddress.getLocalHost();
//3、数据
String msg="你好,很高兴认识你!";
byte[] buffer = msg.getBytes();
///4、创建一个包(要发送给谁)
DatagramPacket packet = new DatagramPacket(buffer,0,buffer.length,inet,9090);
//5、发送包
socket.send(packet);
//6、释放资源
socket.close();
}
}
socket 数据 ip packet打包 发送 释放
//IO流发送数据
//1、创建一个socket
DatagramSocket socket = new DatagramSocket();
Scanner sc = new Scanner(System.in);
String line;
//流对象
BufferedReader br = new BufferedReader(new FileReader("day02z-code\\src\\com\\hongpeng\\d21\\file_\\床前明月光.txt"));
//循环输入
while ((line = br.readLine())!=null){
//2、数据
byte[] bytes = line.getBytes();
//3、ip
InetAddress ip = InetAddress.getByName("192.168.157.1");
//4、打包
DatagramPacket packet = new DatagramPacket(bytes, 0, bytes.length,ip,9090);
//5、发送包
socket.send(packet);
}
//6、释放资源
socket.close();
接收方
public class UDPReceiver {
public static void main(String[] args) throws IOException {
//1、创建一个socket,开放端口
DatagramSocket socket = new DatagramSocket(9090);
byte[] buffer = new byte[1024];
//2、创建一个包接收数据
DatagramPacket packet = new DatagramPacket(buffer, 0, buffer.length);
//3、接收数据
socket.receive(packet);//阻塞式接收
//将数据包转换为字符串输出
String msg = new String(packet.getData(), 0, packet.getLength());
System.out.println(msg);
System.out.println(packet.getAddress());
//4、释放资源
socket.close();
}
}
socket 数组(数据) 打包 接收 (打印) 释放
//循环接收
//1、创建一个socket,开放端口
DatagramSocket socket = new DatagramSocket(9090);
while (true) {
byte[] buffer = new byte[1024];
//2、创建一个包接收数据
DatagramPacket packet = new DatagramPacket(buffer, 0, buffer.length);
//3、接收数据
socket.receive(packet);//阻塞式接收
//将数据包转换为字符串输出
String msg = new String(packet.getData(), 0, packet.getLength());
System.out.println(msg);
}
注意: 如果是TCP中先启动客户端会报错:
而如果是UDP中先启动发送方不会报错,但会正常退出。
案例(多线程)
完成在线咨询功能,学生和老师在线一对一交流(多线程)
发送方
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetAddress;
import java.net.SocketException;
public class UDPSender implements Runnable{
//创建一个socket
DatagramSocket socket=null;
//创建一个流 用于录入键盘的数据
BufferedReader bfr=null;
//发送数据目的地的IP
private String toIP;
//发送数据目的地的端口
private int toPort;
public UDPSender(String toIP, int toPort) {
this.toIP = toIP;
this.toPort = toPort;
try {
socket=new DatagramSocket();//创建一个socket
} catch (SocketException e) {
e.printStackTrace();
}
bfr=new BufferedReader(new InputStreamReader(System.in));//从键盘录入数据到流中
}
@Override
public void run() {
while (true){//循环发送数据
try {
String msg = bfr.readLine();//从流中读取数据
byte[] buffer = msg.getBytes();
InetAddress inet = InetAddress.getByName(toIP);
DatagramPacket packet = new DatagramPacket(buffer, 0, buffer.length, inet, toPort);
socket.send(packet);
//如果发送了拜拜,则退出发送
if(msg.equals("拜拜")){
break;
}
} catch (IOException e) {
e.printStackTrace();
}
}
//释放资源
if(socket!=null){
socket.close();
}
if (bfr!=null){
try {
bfr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
接收方
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.SocketException;
public class UDPReceiver implements Runnable{
//创建一个socket
DatagramSocket socket=null;
//接收方自己所在的端口
private int fromPort;
//数据发送者的姓名
private String msgFrom;
public UDPReceiver(int fromPort,String msgFrom) {
this.fromPort = fromPort;
this.msgFrom=msgFrom;
try {
socket=new DatagramSocket(fromPort);//创建一个socket
} catch (SocketException e) {
e.printStackTrace();
}
}
@Override
public void run() {
while(true){//循环接收
try {
byte[] buffer = new byte[1024 * 8];
DatagramPacket packet = new DatagramPacket(buffer, 0, buffer.length);
socket.receive(packet);
String msg = new String(packet.getData(), 0, packet.getLength());
System.out.println(msgFrom+":"+msg);
if (msg.equals("拜拜")){//如果接收到的数据为拜拜,则退出接收
break;
}
} catch (IOException e) {
e.printStackTrace();
}
}
//释放资源
socket.close();
}
}
学生线程
public class Student {
public static void main(String[] args) {
new Thread(new UDPSender("127.0.0.1",8888)).start();
new Thread(new UDPReceiver(7777,"老师")).start();
}
}
老师线程
public class Teacher {
public static void main(String[] args) {
new Thread(new UDPSender("127.0.0.1",7777)).start();
new Thread(new UDPReceiver(8888,"学生")).start();
}
}
(二)TCP网络编程
概述
TCP通信能实现两台计算机之间的数据交互,通信的两端,要严格区分为客户端(Client)与服务端(Server)。
两端通信时步骤:
服务端程序,需要事先启动,等待客户端的连接。 客户端主动连接服务器端,连接成功才能通信。服务端不可以主动连接客户端。
在Java中,提供了两个类用于实现TCP通信程序:
客户端:java.net.Socket 类表示。创建Socket对象,向服务端发出连接请求,服务端响应请求,两者建立连接开始通信。 服务端:java.net.ServerSocket 类表示。创建ServerSocket对象,相当于开启一个服务,并等待客户端的连接。
2.Socket类
Socket 类:该类实现客户端套接字,套接字指的是两台设备之间通讯的端点。
构造方法摘要 public Socket(String host, int port) :创建套接字对象并将其连接到指定主机上的指定端口号。
Socket client = new Socket("127.0.0.1", 6666);
如果指定的host是null ,则相当于指定地址为回送地址。
回送地址(127.x.x.x) 是本机回送地址(Loopback Address),
主要用于网络软件测试以及本地机进程间通信,
无论什么程序,一旦使用回送地址发送数据,立即返回,不进行任何网络传输。
常用方法摘要
方法 作用 细节 public InputStream getInputStream() : 返回此套接字的输入流。 如果此Scoket具有相关联的通道,则生成的InputStream 的所有操作也关联该通道。关闭生成的InputStream也将关闭相关的Socket。 public OutputStream getOutputStream() : 返回此套接字的输出流。 如果此Scoket具有相关联的通道,则生成的OutputStream 的所有操作也关联该通道。关闭生成的OutputStream也将关闭相关的Socket。 BufferedWriter bw = new BufferedWriter(new OutputStreamWrtier(os)); 把套接字的字节流转换为字符流 插入换行符表示内容结束,但是接收方需要用readLine来读取文件 public void close() : 关闭此套接字。 一旦一个socket被关闭,它不可再使用。关闭此socket也将关闭相关的InputStream和OutputStream 。 public void shutdownOutput() : 禁用此套接字的输出流。 任何先前写出的数据将被发送,随后终止输出流。
3.ServerSocket类
ServerSocket类:这个类实现了服务器套接字,该对象等待通过网络的请求。
构造方法摘要 public ServerSocket(int port) :
使用该构造方法在创建ServerSocket对象时,就可以将其绑定到一个指定的端口号上,参数port就是端口号。
ServerSocket server = new ServerSocket(6666);
常用方法摘要 public Socket accept() :侦听并接受连接,返回一个新的Socket对象,用于和客户端实现通信。该方法会一直阻塞直到建立连接。
有了Socket对象实现通讯。Socket 类功能
4.代码实现
客户端
import java.io.IOException;
import java.io.OutputStream;
import java.net.InetAddress;
import java.net.Socket;
public class TCPClient {
public static void main(String[] args){
Socket socket = null;
OutputStream os = null;
try {
//1、创建Socket对象,它的第一个参数需要的是服务端的IP,第二个参数是服务端的端口
InetAddress inet = InetAddress.getByName("127.0.0.1");
socket = new Socket(inet,8090);
//2、获取一个输出流,用于写出要发送的数据
os = socket.getOutputStream();
//3、写出数据
os.write("你好,我是客户端!".getBytes());
} catch (IOException e) {
e.printStackTrace();
} finally {//4、释放资源
if(socket!=null){
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(os!=null){
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
服务端
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class TCPServer {
public static void main(String[] args) {
ServerSocket serverSocket = null;
Socket socket = null;
InputStream is = null;
ByteArrayOutputStream baos = null;
try {
//1、创建服务端的ServerSocket,指明自己的端口号
serverSocket = new ServerSocket(8090);
//2、调用accept接收到来自于客户端的socket
socket = serverSocket.accept();//阻塞式监听,会一直等待客户端的接入
//3、获取socket的输入流
is = socket.getInputStream();
// 不建议这样写:因为如果我们发送的数据有汉字,用String的方式输出可能会截取汉字,产生乱码
// int len=0;
// byte[] buffer = new byte[1024];
// while ((len=is.read(buffer))!=-1){
// String str = new String(buffer, 0, len);
// System.out.println(str);
// }
//4、读取输入流中的数据
//ByteArrayOutputStream的好处是它可以根据数据的大小自动扩充
baos = new ByteArrayOutputStream();
int len=0;
byte[] buffer = new byte[1024];
while ((len=is.read(buffer))!=-1){
baos.write(buffer,0,len);
}
System.out.println("收到了来自于客户端"+socket.getInetAddress().getHostName()
+"的消息:"+baos.toString());
} catch (IOException e) {
e.printStackTrace();
} finally {//5、关闭资源
if(serverSocket!=null){
try {
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(socket!=null){
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(is!=null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(baos!=null){
try {
baos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
服务器是没有IO流的,服务器可以获取到请求的客户端对象socket 使用每个客户端socket中提供的IO流和客户端进行交互 服务器使用客户端的字节输入流读取客户端发送的数据 服务器使用客户端的字节输出流给客户端回写数据
案例一(回写)
服务端向客户端回写数据
客户端
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.InetAddress;
import java.net.Socket;
public class TCPClient {
public static void main(String[] args){
Socket socket = null;
OutputStream os = null;
ByteArrayOutputStream baos=null;
InputStream is=null;
try {
//1、创建Socket对象,它的第一个参数需要的是服务端的IP,第二个参数是服务端的端口
InetAddress inet = InetAddress.getByName("127.0.0.1");
socket = new Socket(inet,8888);
//2、获取一个输出流,用于写出要发送的数据
os = socket.getOutputStream();
//3、写出数据
os.write("你好,我是客户端!".getBytes());
//==========================解析回复==================================
//4、首先必须通知服务器,我已经输出完毕了,不然服务端不知道什么时候输出完毕
//服务端的while循环会一直执行,会阻塞
socket.shutdownOutput();
///5、获取输入流,用于读取服务端回复的数据
is = socket.getInputStream();
baos = new ByteArrayOutputStream();
int len=0;
byte[] buffer = new byte[1024];
while ((len=is.read(buffer))!=-1){
baos.write(buffer,0,len);
}
System.out.println("收到了来自服务端的消息:"+baos.toString());
} catch (IOException e) {
e.printStackTrace();
} finally {//6、释放资源
if(socket!=null){
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(os!=null){
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(is!=null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (baos!=null){
try {
baos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
服务端
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class TCPServer {
public static void main(String[] args) {
ServerSocket serverSocket = null;
Socket socket = null;
InputStream is = null;
ByteArrayOutputStream baos = null;
OutputStream os=null;
try {
//1、创建服务端的ServerSocket,指明自己的端口号
serverSocket = new ServerSocket(8888);
//2、调用accept接收到来自于客户端的socket
socket = serverSocket.accept();//阻塞式监听,会一直等待客户端接入
//3、获取socket的输入流
is = socket.getInputStream();
// 不建议这样写:因为如果我们发送的数据有汉字,用String的方式输出可能会截取汉字,产生乱码
// int len=0;
// byte[] buffer = new byte[1024];
// while ((len=is.read(buffer))!=-1){
// String str = new String(buffer, 0, len);
// System.out.println(str);
// }
//4、读取输入流中的数据
//ByteArrayOutputStream的好处是它可以根据数据的大小自动扩充
baos = new ByteArrayOutputStream();
int len=0;
byte[] buffer = new byte[1024];
while ((len=is.read(buffer))!=-1){
baos.write(buffer,0,len);
}
System.out.println("收到了来自于客户端"+socket.getInetAddress().getHostName()
+"的消息:"+baos.toString());
//===========================回复==========================================
//5、获取一个输出流,写出回复给客户端
os = socket.getOutputStream();
//6、写出数据
os.write("你好,我是服务端".getBytes());
} catch (IOException e) {
e.printStackTrace();
} finally {//7、关闭资源
if(serverSocket!=null){
try {
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(socket!=null){
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(is!=null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(baos!=null){
try {
baos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(os!=null){
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
案例二(文件)
上传文件:客户端发送文件给服务端,服务端将文件保存在本地
客户端
import java.io.FileInputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.InetAddress;
import java.net.Socket;
public class TCPClient {
public static void main(String[] args) {
Socket socket = null;
FileInputStream fis = null;
OutputStream os = null;
try {
//1、创建Socket对象,它的第一个参数需要的是服务端的IP,第二个参数是服务端的端口
InetAddress inet = InetAddress.getByName("127.0.0.1");
socket = new Socket(inet, 8888);
//2、创建一个文件输入流,读取要上传的文件
fis = new FileInputStream("D:/test/touxiang.jpg");
//3、获取一个输出流,用于写出要发送的数据
os = socket.getOutputStream();
byte[] buffer = new byte[1024];
int len=0;
while((len=fis.read(buffer))!=-1){
//4、写出数据
os.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {//5、释放资源
if(socket!=null){
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fis!=null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(os!=null){
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
服务端
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class TCPServer {
public static void main(String[] args) {
ServerSocket serverSocket = null;
Socket socket = null;
FileOutputStream fos = null;
InputStream is = null;
try {
//1、创建服务端的ServerSocket,指明自己的端口号
serverSocket = new ServerSocket(8888);
//2、调用accept接收到来自于客户端的socket
socket = serverSocket.accept();//阻塞式监听,会一直等待客户端的接入
//3、创建一个文件输出流,用于将读取到的客户端上传的文件输出
fos = new FileOutputStream("touxiang.jpg");
//4、获取socket的输入流
is = socket.getInputStream();
byte[] buffer = new byte[1024];
int len=0;
while((len=is.read(buffer))!=-1){
fos.write(buffer,0,len);//5、写出文件
}
} catch (IOException e) {
e.printStackTrace();
} finally {//6、释放资源
if(serverSocket!=null){
try {
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(socket!=null){
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fos!=null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(is!=null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
假设大海里有许多岛屿,客户端和服务端相当于其中的两座岛屿,“客户端”岛屿生产了一种农作物要运到“服务端”岛屿,所以“客户端”要知道“服务端”确切的地址(IP),不然就运错地方了,socket就相当于运输的船只,port就相当于“服务端”岛屿的某个港口。
案例三(读取发送接收回写写文件)
客户端
package com.hongpeng.d23.ktal;
import java.io.*;
import java.net.Socket;
public class TCPc_ {
public static void main(String[] args) throws IOException {
//
Socket client = new Socket("127.0.0.1",8080);
//读取(输入流)
BufferedInputStream br = new BufferedInputStream(new FileInputStream("E:\\itcast\\出师表.txt"));
//发送接收(网络编程)
OutputStream os = client.getOutputStream();
InputStream is = client.getInputStream();
//容器
byte[] bytes = new byte[1024];
StringBuilder sb = new StringBuilder();
int len;
//读取 发送
while ((len=br.read(bytes))!=-1){
sb.append(new String(bytes,0,len));
//发送
os.write(bytes, 0, len);
os.flush();
}
System.out.println(sb.toString());
//4、首先必须通知服务器,我已经输出完毕了,不然服务端不知道什么时候输出完毕
//服务端的while循环会一直执行,会阻塞
client.shutdownOutput();
//接收
while ((len = is.read(bytes))!=-1){
// sbs.append(new String(bytes,0,len));
System.out.println(new String(bytes,0,len));
}
client.close();
br.close();
os.close();
is.close();
}
}
服务端
package com.hongpeng.d23.ktal;
import javax.annotation.processing.Filer;
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
public class TCPs_ {
public static void main(String[] args) throws IOException {
ServerSocket server = new ServerSocket(8080);
Socket socket = server.accept();
//读取(输入流)
BufferedInputStream br = new BufferedInputStream(new FileInputStream("E:\\itcast\\出师表.txt"));
//写入(输出流)
BufferedOutputStream bw = new BufferedOutputStream( new FileOutputStream("E:\\itcast\\出师表(FBI).txt"));
//接收发送(网络传输)
OutputStream os = socket.getOutputStream();
InputStream is = socket.getInputStream();
//容器
byte[] bytes = new byte[1024];
StringBuilder sb = new StringBuilder();
int len;
//接收 写文件
while ((len=is.read(bytes))!=-1){
System.out.println(new String(bytes,0,len));
bw.write(bytes,0,len);
bw.flush();
}
System.out.println(sb.toString());
//读取 发送
while ((len = br.read(bytes))!=-1){
sb.append(new String(bytes,0,len));
os.write(bytes, 0, len);
os.flush();
}
server.close();
br.close();
os.close();
is.close();
}
}
字符
客户端
package com.hongpeng.d23.ktal;
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
public class TCPRerder_ {
public static void main(String[] args) throws IOException {
ServerSocket server = new ServerSocket(8080);
Socket socket = server.accept();
//接收
InputStream is = socket.getInputStream();
BufferedReader bris = new BufferedReader(new InputStreamReader(is));
//写入
// BufferedOutputStream bw = new BufferedOutputStream( new FileOutputStream("E:\\itcast\\出师表(FBI).txt"));
BufferedWriter bw = new BufferedWriter( new FileWriter("E:\\itcast\\出师表(FBI).txt"));
//读取
// BufferedInputStream br = new BufferedInputStream(new FileInputStream("E:\\itcast\\出师表.txt"));
BufferedReader br = new BufferedReader(new FileReader("E:\\itcast\\出师表.txt"));
//发送
OutputStream os = socket.getOutputStream();
BufferedWriter bwos = new BufferedWriter(new OutputStreamWriter(os));
//容器
char[] chars = new char[1024];
StringBuilder sb = new StringBuilder();
int len;
//接收 写文件
while ((len=bris.read(chars))!=-1){
System.out.println(new String(chars,0,len));
bw.write(chars,0,len);
bw.flush();
}
System.out.println(sb.toString());
//4、首先必须通知服务器,我已经输出完毕了,不然服务端不知道什么时候输出完毕
//服务端的while循环会一直执行,会阻塞
client.shutdownOutput();
//读取 发送
while ((len = br.read(chars))!=-1){
sb.append(new String(chars,0,len));
bwos.write(chars, 0, len);
bwos.flush();
}
socket.shutdownInput();
socket.close();
server.close();
br.close();
bwos.close();
bris.close();
}
}
服务端
package com.hongpeng.d23.ktal;
import java.io.*;
import java.net.Socket;
public class TCPWriter_ {
public static void main(String[] args) throws IOException {
//
Socket client = new Socket("127.0.0.1",8080);
//读取文件
// BufferedInputStream br = new BufferedInputStream(new FileInputStream("E:\\itcast\\出师表.txt"));
BufferedReader br = new BufferedReader(new FileReader("E:\\itcast\\出师表.txt"));
//发送接收
OutputStream os = client.getOutputStream();
BufferedWriter bwos = new BufferedWriter(new OutputStreamWriter(os));
InputStream is = client.getInputStream();
BufferedReader bris = new BufferedReader(new InputStreamReader(is));
//容器
char[] chars = new char[1024];
StringBuilder sb = new StringBuilder();
int len;
//读取 发送
while ((len=br.read(chars))!=-1){
sb.append(new String(chars,0,len));
//发送
bwos.write(chars, 0, len);
bwos.flush();
}
System.out.println(sb.toString());
//接收
while ((len = bris.read(chars))!=-1){
// sbs.append(new String(bytes,0,len));
System.out.println(new String(chars,0,len));
}
client.shutdownInput();
client.close();
br.close();
bwos.close();
bris.close();
}
}
三、URL
(一)概念
URL(Uniform Resource Locator):统一资源定位符,它表示Internet上某一资源的地址。 通过URL我们可以访问Internet上的各种网络资源,比如最常见的www,ftp站点。浏览器通过解析给定的URL可以在网络上查找相应的文件或其他资源。
URI=URL+URN
URI:Uniform Resource Identifier ,统一资源标志符。 URL:Uniform Resource Locator,统一资源定位符。 URN:Uniform Resource Name,统一资源命名。 网络三大基石:HTML,HTTP,URL
(二)格式
URL的基本结构由5部分组成: <传输协议>://<主机名>:<端口号>/<文件名>#片段名?参数列表
片段名:即锚点,例如看小说,直接定位到章节 参数列表格式:参数名=参数值&参数名=参数值...... 例如: http://localhost:8080/index.jsp#a?username=Tom&password=123456
(三)URL类
java.net包下
1.构造方法摘要
URL(String spec)根据 String 表示形式创建 URL 对象。 URL(String protocol, String host, int port, String file) 根据指定协议名、主机名、端口号和文件名创建 URL 对象。 URL(String protocol, String host, String file) 根据指定的协议名、主机名和文件名创建 URL。
2.常用方法摘要
String getProtocol()获取此 URL的协议名称。 String getHost() 获取此 URL 的主机名。 int getPort() 获取此 URL 的端口号。 String getPath() 获取此 URL 的文件路径。 String getFile()获取此 URL 的文件名。 String getQuery()获取此 URL的查询部分。 URLConnection openConnection() 返回一个URLConnection实例,表示与URL引用的远程对象的URL 。
URLConnection类中又有一个方法: InputStream getInputStream() 返回从此打开的连接读取的输入流。 案例演示1
import java.net.MalformedURLException;
import java.net.URL;
public class Test {
public static void main(String[] args) throws MalformedURLException {
URL url = new URL("http://localhost:8080/index.jsp?username=Tom&password=123456");
System.out.println(url.getProtocol());//获取协议名
System.out.println(url.getHost());//获取主机名
System.out.println(url.getPort());//获取端口号
System.out.println(url.getPath());//获取文件路径
System.out.println(url.getFile());//获取文件名
System.out.println(url.getQuery());//获取查询名
}
}
案例演示2 URL下载网络资源
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class Test {
public static void main(String[] args) throws IOException {
//下载地址
URL url = new URL("https://img.t.sinajs.cn/t6/style/images/global_nav/WB_logo.png?id=1404211047727");
//连接到这个资源 HTTP
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStream is = urlConnection.getInputStream();
FileOutputStream fos = new FileOutputStream("weibo.jpg");
byte[] buffer = new byte[1024];
int len=0;
while ((len=is.read(buffer))!=-1){
fos.write(buffer,0,len);
}
//释放资源
urlConnection.disconnect();//断开连接
is.close();
fos.close();
}
}
小结
———————————————— 版权声明:本文为CSDN博主「ZaynFox」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:Java 网络编程_ZaynFox的博客-CSDN博客_java网络编程
反射
反射是框架设计的灵魂 (使用的前提条件:必须先得到代表的字节码的Class,Class类用于表示.class文件(字节码))
框架 在学习Java的路上,相信你一定使用过各种各样的框架。所谓的框架就是一个半成品软件,已经对基础的代码进行了封装并提供相应的API。在框架的基础上进行软件开发,可以简化编码。学习使用框架并不需要了解反射,但是如果想要自己写一个框架,那么就需要对反射机制有很深入的了解。
一、反射的概述
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;
这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
要想解剖一个类,必须先要获取到该类的字节码文件对象。而解剖使用的就是Class类中的方法.所以先要获取到每一个字节码文件对应的Class类型的对象.
以上的总结就是什么是反射 反射就是把java类中的各种成分映射成一个个的Java对象
例如:一个类有:成员变量、方法、构造方法、包等等信息,利用反射技术可以对一个类进行解剖,把个个组成部分映射成一个个对象。 (其实:一个类中这些成员方法、构造方法、在加入类中都有一个类来描述)
反射的优点 可以在程序运行过程中,操作这些对象; 可以解耦,提高程序的可扩展性。
在学习反射以前,我们先来了解一下Java代码在计算机中所经历的三个阶段:
Source源代码阶段:.java被编译成*.class字节码文件。 Class类对象阶段:.class字节码文件被类加载器加载进内存,并将其封装成Class对象(用于在内存中描述字节码文件),Class对象将原字节码文件中的成 员变量抽取出来封装成数组Field[],将原字节码文件中的构造函数抽取出来封装成数组Construction[],将成员方法封装成数组Method[]。当然Class类内 不止这三个,还封装了很多,我们常用的就这三个。 RunTime运行时阶段:使用new创建对象的过程。
如图是类的正常加载过程:反射的原理在与class对象。 熟悉一下加载的时候:Class对象的由来是将class文件读入内存,并为之创建一个Class对象。
其中这个Class对象很特殊。我们先了解一下这个Class类
二、Class类
Class
Class 类的实例表示正在运行的 Java 应用程序中的类和接口。也就是jvm中有N多的实例每个类都有该Class对象。(包括基本数据类型) Class 没有公共构造方法。Class 对象是在加载类时由 Java 虚拟机 以及 通过调用类加载器中的defineClass 方法 自动构造的。也就是这不需要我们自己去处理创建,JVM已经帮我们创建好了。
方法共有64个太多了。
有Class对象的类:Constructor|Field|Method
构造方法
Constructor con = c.getDeclaredConstructor(String.class,int.class,String.class);属性
Field f = c.getDeclaredField("name");方法
Method method1OBJ = c.getDeclaredMethod("method2", String.class, int.class);setAccessible
1类加载【理解】
类加载的描述
当程序要使用某个类时,如果该类还未被加载到内存中,则系统会通过类的加载,类的连接,类的初始化这三个步骤来对类进行初始化。如果不出现意外情况,JVM将会连续完成这三个步骤,所以有时也把这三个步骤统称为类加载或者类初始化:5个阶段
-
1.类的加载
-
就是指将class文件读入内存,并为之创建一个 java.lang.Class 对象
-
任何类被使用时,系统都会为之建立一个 java.lang.Class 对象
-
静态加载:Dog dog = new Dog();
-
动态加载:Class c = dog.class
Object con = c.getConstructor().newInstance();
-
-
类的连接
-
2.验证阶段:用于检验被加载的类是否有正确的内部结构,并和其他类协调一致
-
3.准备阶段:负责为类的类变量分配内存,并设置默认初始化值
-
4.解析阶段:将类的二进制数据中的符号引用替换为直接引用
-
-
5.类的初始化
-
在该阶段,主要就是对类变量进行初始化
-
Initialization(初始化)
-
*
()是由编译器按语句在源文件中出现的顺序,依次自动收集类中所有静态变量的赋值动作和静态代码块中的语句,并进行合并。(线程安全)
-
-
类的初始化步骤
-
假如类还未被加载和连接,则程序先加载并连接该类
-
假如该类的直接父类还未被初始化,则先初始化其直接父类
-
假如类中有初始化语句,则系统依次执行这些初始化语句
-
注意:在执行第2个步骤的时候,系统对直接父类的初始化步骤也遵循初始化步骤1-3
-
-
类的初始化时机
-
创建类的实例
-
调用类的类方法
-
访问类或者接口的类变量,或者为该类变量赋值
-
使用反射方式来强制创建某个类或接口对应的java.lang.Class对象
-
初始化某个类的子类
-
直接使用java.exe命令来运行某个主类
-
2类加载器【理解】
类加载器的作用
-
负责将.class文件加载到内存中,并为之生成对应的 java.lang.Class 对象。虽然我们不用过分关心类加载机制,但是了解这个机制我们就能更好的理解程序的运行!
JVM的类加载机制
-
全盘负责:就是当一个类加载器负责加载某个Class时,该Class所依赖的和引用的其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入
-
父类委托:就是当一个类加载器负责加载某个Class时,先让父类加载器试图加载该Class,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类
-
缓存机制:保证所有加载过的Class都会被缓存,当程序需要使用某个Class对象时,类加载器先从缓存区中搜索该Class,只有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存储到缓存区
Java中的内置类加载器
-
Bootstrap class loader:它是虚拟机的内置类加载器,通常表示为null ,并且没有父null
-
Platform class loader:平台类加载器可以看到所有平台类 ,平台类包括由平台类加载器或其祖先定义的Java SE平台API,其实现类和JDK特定的运行时类
-
System class loader:它也被称为应用程序类加载器 ,与平台类加载器不同。 系统类加载器通常用于定义应用程序类路径,模块路径和JDK特定工具上的类
-
类加载器的继承关系:System的父加载器为Platform,而Platform的父加载器为Bootstrap
类加载器ClassLoader
//static ClassLoader getSystemClassLoader()返回用于委派的系统类加载器 ClassLoader c = ClassLoader.getSystemClassLoader(); //AppClassLoader 属于System class loader:系统类加载器 System.out.println(c); //ClassLoader getParent()返回父类加载器进行委派 ClassLoader cp = c.getParent(); //ExtClassLoader 属于PlatForm class loader:平台类加载器 System.out.println(cp); //内置类加载器 ClassLoader pp = cp.getParent(); //null 属于Bootstrap class loader:内置类加载器 System.out.println(pp);
三、反射的使用
先写一个Student类。
1、获取Class对象的三种方式
import java.lang.Class;
(一般不用)Object ——> getClass(); |||||对象都有了还要反射干什么。
Student stu1 = new Student();//这一new 产生一个Student对象,一个Class对象。 Class c= stu1.getClass();//获取Class对象
Object类中的getClass方法、因为所有类都继承Object类。从而调用Object类来获取
(安全可靠)任何数据类型(包括基本数据类型)都有一个“静态”的class属性 ||||||需要导入类的包,依赖太强,不导包就抛编译错误。
Class c= Student.class;
(常用)通过Class类的静态方法:forName(String className) |||||一个字符串可以传入也可写在配置文件中等多种方法。
Class c= Class.forName("包名.类名");
注意此字符串必须是真实路径,就是带包名的类路径,包名.类名
实例对象 T newInstance():
Object obj = c.newInstance();
注意:在运行期间,一个类,只有一个Class对象产生
通过反射获取构造方法Constructor
import java.lang.reflect.Constructor;
-
概念:
Constructor(管理构造函数的类)
-
方法:
setAccessible(true);//暴力反射(忽略掉访问修饰符)
可以适当优化速度
获取构造方法:
返回的是描述这个(?)参构造函数的类对象。
批量的方法:
public Constructor[] getConstructors():所有"公有的"构造方法
public Constructor[] getDeclaredConstructors():获取所有的构造方法(包括私有、受保护、默认、公有)
Constructor[] conArray = c.getDeclaredConstructors();
遍历:for(Constructor1 c : conArray){System.out.println(c);}
单个的方法,并调用:
public Constructor getConstructor(Class... parameterTypes):获取单个"公有的"构造方法:
public Constructor getDeclaredConstructor(Class... parameterTypes):获取"某个构造方法"可以是私有的,或受保护、默认、公有;
Constructor con = c.getDeclaredConstructor(String.class);
参数:参数类型.class
实例对象T newInstance(Object... initargs)
作用:
它的返回值是T类型,所以newInstance是创建了一个构造方法的声明类的新实例对象。并为之调用
参数:对应参数类型的数值
Object obj = con3.newInstance("张三",18,"男");
Object obj = class.newInstance());//默认无参的构造器创造的对象
//构造器 Constructor con = c.getDeclaredConstructor(String.class,int.class,String.class); //调用构造方法 //暴力访问(忽略掉访问修饰符) con.setAccessible(true); Object obj = con3.newInstance("张三",18,"男"); Student stu1 = (Student)obj;暴力访问(忽略掉构造方法的访问修饰符)
con.setAccessible(true);忽略构造方法的访问修饰符
反射的四个步骤创建对象;
1、获取Class对象
Class c = Class.forName("包名.类名");
2、获取构造方法
Constructor con = c.getDeclaredConstructor(String.class,int.class,String.class);
3、暴力反射
con.setAccessible(true);//暴力访问(忽略掉访问修饰符)
4、传入参数
Object obj = con.newInstance("张三","18","男"); Student stu1 = (Student)obj;
通过反射获取成员变量Field
import java.lang.reflect.Field;
无参构造创建对象 obj0
获取成员变量并调用:
批量的
Field[] getFields():获取所有的"公有字段"
Field[] getDeclaredFields():获取所有字段,包括:私有、受保护、默认、公有;
Field[] fieldArray = c.getDeclaredFields();
遍历:for(Field f : fieldArray){System.out.println(f);}
获取单个的:
public Field getField(String fieldName):获取某个"公有的"字段;
public Field getDeclaredField(String fieldName):获取某个字段(可以是私有的)
Field f = c.getDeclaredField("phoneNum");
参数:字段名
设置字段的值:void set(Object obj,Object value)
作用:给属性赋值,或更改值
参数说明:要传入设置的对象,要传入实参//单个属性
f.set(obj, "18888889999");
(静态的属性属于类可以为null,”“)
获取值 get(Object obj)
//获得属性 Field f = c.getDeclaredField("phoneNum"); //暴力反射,解除私有限定 f.setAccessible(true); //获取一个对象 Constructor con = c.getConstructor(); c.newInstance();默认无参构造器创造出来的对象 Object obj = con.newInstance();//产生Student对象--》Student stu = new Student(); //为字段设置值 f.set(obj, "18888889999"); Student stu2 = (Student) obj; System.out.println("验证电话:" + stu);
通过反射获取成员方法Method
import java.lang.reflect.Method;
无参构造创建对象 obj
获取成员方法并调用:
批量的:
public Method[] getMethods():获取所有"公有方法";(包含了父类的方法也包含Object类)
public Method[] getDeclaredMethods():获取所有的成员方法,包括私有的(不包括继承的)
methodArray = c.getDeclaredMethods();
遍历:for(Method m : methodArray){System.out.println(m);}
.获取单个的
public Method getMethod(String name,Class... parameterTypes):
public Method getDeclaredMethod(String name,Class... parameterTypes):
Method m = c.getDeclaredMethod("show4", int.class);
参数:name : 方法名;Class ... : 形参的Class类型对象
调用方法:Object invoke(Object obj,Object... args):
作用:调用方法
参数说明:obj : 要调用方法的对象;args:调用方式时所传递的实参;
m.invoke(obj, 20);
(静态的方法属于类可以为null,”“)
//获得方法 Method m = c.getDeclaredMethod("show4", int.class); //解除私有限定 m.setAccessible(true); //实例化一个Student对象 Constructor con = c.getConstructor() c.newInstance();默认无参构造器创造出来的对象 Object obj = con.newInstance(); //调用 Object result = m.invoke(obj, 20);//需要两个参数,一个是要调用的对象(获取有反射),一个是实参 System.out.println("返回值:" + result);m.setAccessible(true);//解除私有限定
其实这里的成员方法:在模型中有属性一词,就是那些setter()方法和getter()方法。还有字段组成,这些内容在内省中详解
反射main方法
获取Student类的main方法、不要与当前的main方法搞混了
Method methodMain = c.getMethod("main", String[].class);//第一个参数:方法名称,第二个参数:方法形参的类型,
用invoke
methodMain.invoke(null, new String[]{"a","b","c"}); //第一个参数,对象类型,因为方法是static静态的,所以为null可以,第二个参数是String数组,这里要注意在jdk1.4时是数组,jdk1.5之后是可变参数 //这里拆的时候将 new String[]{"a","b","c"} 拆成3个对象。。。所以需要将它强转。 methodMain.invoke(null, (Object)new String[]{"a","b","c"});//方式一 methodMain.invoke(null, new Object[]{new String[]{"a","b","c"}});//方式二
运行配置文件内容|反射越过泛型检查
反射方法的其它使用之---通过反射运行配置文件内容
配置文件以txt文件为例子(pro.txt): className = cn.fanshe.Student methodName = show
测试类:
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.Method;
import java.util.Properties;
/*
* 我们利用反射和配置文件,可以使:应用程序更新时,对源码无需进行任何修改
* 我们只需要将新类发送给客户端,并修改配置文件即可
*/
public class Demo {
public static void main(String[] args) throws Exception {
//通过反射获取Class对象
Class stuClass = Class.forName(getValue("className"));//"cn.fanshe.Student"
//2获取show()方法
Method m = stuClass.getMethod(getValue("methodName"));//show
//3.调用show()方法
m.invoke(stuClass.getConstructor().newInstance());
}
//此方法接收一个key,在配置文件中获取相应的value
public static String getValue(String key) throws IOException{
Properties pro = new Properties();//获取配置文件的对象
FileReader in = new FileReader("pro.txt");//获取输入流
pro.load(in);//将流加载到配置文件对象中
in.close();
return pro.getProperty(key);//返回根据key获取的value值
}
}
控制台输出: is show()
需求: 当我们升级这个系统时,不要Student类,而需要新写一个Student2的类时,这时只需要更改pro.txt的文件内容就可以了。代码就一点不用改动
要替换的student2类:
public class Student2 {
public void show2(){
System.out.println("is show2()");
}
}
配置文件更改为: className = cn.fanshe.Student2 methodName = show2 控制台输出: is show2();
反射方法的其它使用之---通过反射越过泛型检查
泛型用在编译期,编译过后泛型擦除(消失掉)。所以是可以通过反射越过泛型检查的 测试类:
import java.lang.reflect.Method;
import java.util.ArrayList;
/*
* 通过反射越过泛型检查
* 例如:有一个String泛型的集合,怎样能向这个集合中添加一个Integer类型的值?
*/
public class Demo {
public static void main(String[] args) throws Exception{
ArrayList strList = new ArrayList<>();
strList.add("aaa");
strList.add("bbb");
// strList.add(100);
//获取ArrayList的Class对象,反向的调用add()方法,添加数据
Class listClass = strList.getClass(); //得到 strList 对象的字节码 对象
//获取add()方法
Method m = listClass.getMethod("add", Object.class);
//调用add()方法
m.invoke(strList, 100);
//遍历集合
for(Object obj : strList){
System.out.println(obj);
}
}
}
3.模块化
3.1模块化概述【理解】
Java语言随着这些年的发展已经成为了一门影响深远的编程语言,无数平台,系统都采用Java语言编写。但是,伴随着发展,Java也越来越庞大,逐渐发展成为一门“臃肿” 的语言。而且,无论是运行一个大型的软件系统,还是运行一个小的程序,即使程序只需要使用Java的部分核心功能, JVM也要加载整个JRE环境。 为了给Java“瘦身”,让Java实现轻量化,Java 9正式的推出了模块化系统。Java被拆分为N多个模块,并允许Java程序可以根据需要选择加载程序必须的Java模块,这样就可以让Java以轻量化的方式来运行
其实,Java 7的时候已经提出了模块化的概念,但由于其过于复杂,Java 7,Java 8都一直未能真正推出,直到Java 9才真正成熟起来。对于Java语言来说,模块化系统是一次真正的自我革新,这种革新使得“古老而庞大”的Java语言重新焕发年轻的活力
3.2模块的基本使用【应用】
-
在项目中创建两个模块。一个是myOne,一个是myTwo
-
在myOne模块中创建以下包和以下类,并在类中添加方法
-
在myTwo模块中创建以下包和以下类,并在类中创建对象并使用
-
在myOne模块中src目录下,创建module-info.java,并写入以下内容
-
在myTwo模块中src目录下,创建module-info.java,并写入以下内容
3.3模块服务的基本使用【应用】
-
在myOne模块中新建一个包,提供一个接口和两个实现类
-
在myOne模块中修改module-info.java文件,添加以下内容
-
在myTwo模块中新建一个测试类
-
在myTwo模块中修改module-info.java文件,添加以下内容
XML解析
1.XML历史
gml(1969)->sgml(1985)->html(1993)->xml(1998)
-
1969 gml(通用标记语言),主要目的是要在不同的机器之间进行通信的数据规范
-
1985 sgml(标准通用标记语言)
-
1993 html(超文本标记语言,www网)
html语言本身是有一些缺陷的 (1)不能自定义标签 (2)html本身缺少含义 (3)html没有真正的国际化
有一个中间过渡语言,xhtml: html->xhtml->xml
-
1998 xml extensiable markup language 可扩展标记语言
XML解析技术概述
XML解析方式分为两种:dom和sax dom:(Document Object Model, 即文档对象模型) 是 W3C 组织推荐的处理 XML 的一种方式。 sax: (Simple API for XML) 不是官方标准,但它是 XML 社区事实上的标准,几乎所有的 XML 解析器都支持它。 XML解析器 Crimson、Xerces 、Aelfred2
XML解析开发包 Jaxp、sax、Jdom、dom4j
2.为什么需要XML
1.需求1 两个程序间进行数据通信? 2.需求2 给一台服务器,做一个配置文件,当服务器程序启动时,去读取它应当监听的端口号,还有连接数据库的用户名和密码?
在XML语言中,它允许用户自定义标签。一个标签用于描述一段数据;一个标签可以分为开始标签和结束标签,在开始标签和结束标签之间,又可以使用其他标签描述其他数据,以此来实现数据关系的描述。
3.XML常见应用
1.XML的出现解决了程序间数据传输的问题: 比如QQ之间的数据传送,用XML格式来传送数据,具有良好的可读性,可维护性
2.XML可以做配置文件 XML文件做配置文件可以说非常普遍,比如我们的服务器的server.xml,web.xml。再比如我们的structs中的structs-config.xml文件,和hibernate的hibernate.cfg.xml等等。
3.XML可以充当小型的数据库 XML文件可以做小型数据库,也是不错的选择,我们程序中可能用到一些经常要人工配置的数据,如果放在数据库中读取不合适(因为这会增加维护数据库的工作),则可以考虑直接用XML来做小型数据库。这种方式直接读取文件显然要比读数据库快。比如msn中保存用户聊天记录就是用XML文件。
入门案例:用XML来记录一个班级信息。
杨过 男 20 小龙女 女 21 我们可以用浏览器打开:
那么我们的XML能不能像html那样显示在网页上呢?也是可以的,它也可以用css来修饰,但我们不用,我们只需要使用XML来存储数据。
在这个例子中,如果我们把第一行的编码改为utf-8,再用浏览器打开会报错,这是为什么呢?
因为xml文件的默认编码是ANSI,即美国国家标准协会制定的编码,它根据不同的国家和地区制定了不同的标准,那么在中国就是GB2312,所以我们用GB2312编码不会出错,而用UTF-8会报错。
解决办法就是将该XML文件更改为UTF-8的编码模式即可。
4.XML语法
一个XML文件分为如下几部分内容: 1.文档声明 2.元素 3.属性 4.注释 5.CDATA区、特殊字符 6.处理指令(processing instruction)
-
xml文档的后缀名 .xml
-
xml第一行必须定义为文档声明
-
xml文档中有且仅有一个根标签
-
属性值必须使用引号(单双都可)引起来
-
标签必须正确关闭
-
xml标签名称区分大小写
4.1.XML语法-文档声明
-
XML声明放在XML文档的第一行
XML声明由以下几个部分组成:
version –文档符合XML1.0规范,我们学习1.0 encoding –文档字符编码,比如”GB2312”或者”UTF-8” standalone –文档定义是否独立使用 standalone=”no”为默认值。yes代表是独立使用,而no代表不是独立使用
4.2.XML语法-元素(或者叫标记、节点)
(1)每个XML文档必须有且只有一个根元素
-
根元素是一个完全包括文档中其他所有元素的元素
-
根元素的起始标记要放在所有其他元素的起始标记之前
-
跟元素的结束标记要放在所有其他元素的结束标记之后
(2)XML元素指的是XML文件中出现的标签,一个标签分为开始标签和结束标签,一个标签有如下几种书写方式,例如
-
包含标签体:
www.sohu.com
-
不含标签体的:
,简写为:
-
(3)一个标签中也可以嵌套若干子标签。但所有标签必须合理地嵌套,绝对不允许交叉嵌套,例如
welcome to www.sohu.com
-
这种情况肯定是要报错的。
(4)对于XML标签中出现的所有空格和换行,XML解析程序都会当做标签内容进行处理。例如下面两段内容的意义是不一样的。
xiaoming
-
和如下:
xiaoming
(5)由于在XML中,空格和换行都作为原始内容被处理,所以,在编写XML文件时,要特别注意。
(6)命名规范:一个XML元素可以包含字母、数字以及其它一些可见字符,但必须遵守以下规范:
-
区分大小写,例如,元素P和元素p是两个不同的元素
-
不能以数字或下划线”_”开头
-
元素内不能包含空格
-
名称中间不能包含冒号(:)
-
可以使用中文,但一般不这么用
4.3.XML语法-属性
Tom
(1)属性值用双引号(”)或单引号(’)分隔,如果属性值中有单引号,则用双引号分隔;如果有双引号,则用单引号分隔。那么如果属性值中既有单引号还有双引号怎么办?这种要使用实体(转义字符,类似于html中的空格符),XML有5个预定义的实体字符,如下:

(2)一个元素可以有多个属性,它的基本格式为:
<元素名 属性名1="属性值1" 属性名2="属性值2">
-
(3)特定的属性名称在同一个元素标记中只能出现一次
(4)属性值不能包括<,>,&,如果一定要包含,也要使用实体
4.4.XML语法-注释
XML的注释类似于HTML中的注释:
-
(1)注释内容不要出现
--
(2)不要把注释放在标记中间; (3)注释不能嵌套 (4)可以在除标记以外的任何地方放注释
4.5.XML语法-CDATA节
假如有这么一个需求,需要通过XML文件传递一幅图片,怎么做呢?其实我们看到的电脑上的所有文件,本质上都是字符串,不过它们都是特殊的二进制字符串。我们可以通过XML文件将一幅图片的二进制字符串传递过去,然后再解析成一幅图片。那么这个字符串就会包含大量的<,>,&或者“等一些特殊的不合法的字符。这时候解析引擎是会报错的。
所以,有些内容可能不想让解析引擎解析执行,而是当做原始内容处理,用于把整段文本解释为纯字符数据而不是标记。这就要用到CDATA节。
语法如下:
CDATA节中可以输入任意字符(除]]>外),但是不能嵌套!
如下例,这种情况它不会报错,而如果不包含在CDATA节中,就会报错:
杨过 男 20
4.6.XML语法-处理指令
处理指令,简称PI(processing instruction)。处理指令用来指示解析引擎如何解析XML文件,看下面一个例子:
比如我们也可以使用css样式表来修饰XML文件,
我们在xml文件中使用处理指令引入这个css文件,如下:
杨过 男 20 小龙女 女 21
这时候我们再用浏览器打开这个xml文件,会发现浏览器解析出一个带样式的视图,而不再是单纯的目录树了:
但是XML的处理指令不要求掌握,因为用到的很少。
4.7XML语法-约束
-
分类: 1. DTD:一种简单的约束技术 2.Schema:一种复杂的约束技术
* DTD: * 引入dtd文档到xml文档中 * 内部dtd:将约束规则定义在xml文档中 * 外部dtd:将约束的规则定义在外部的dtd文件中 * 本地: * 网络:
* Schema: * 引入: 1.填写xml文档的根元素 2.引入xsi前缀. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 3.引入xsd文件命名空间. xsi:schemaLocation="http://www.itcast.cn/xml student.xsd" 4.为每一个xsd约束声明一个前缀,作为标识 xmlns="http://www.itcast.cn/xml"
xml文件的解析
XML解析技术概述
操作xml文档
解析(读取):将文档中的数据读取到内存中 2. 写入:将内存中的数据保存到xml文档中。持久化的存储
解析xml的方式:
DOM:(Document Object Model, 即文档对象模型) 是 W3C 组织推荐的处理 XML 的一种方式。(占内存)将标记语言文档一次性加载进内存
SAX: (Simple API for XML) 不是官方标准,但它是 XML 社区事实上的标准,几乎所有的 XML 解析器都支持它。(不能增删改) 逐行读取,基于事件驱动的。
XML解析器
Crimson、Xerces 、Aelfred2
xml常见的解析器:
JAXP:sun公司提供的解析器,支持dom和sax两种思想
DOM4J:一款非常优秀的解析器
Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
PULL:Android操作系统内置的解析器,sax方式的。
XML解析开发包 Jaxp、sax、Jdom、dom4j、Jsoup
DOM4J:
package com.xinsi.qi.utils;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
public class Dom4jXml {
public void test(){
try {
File inputFile = new File("F:\\J2EE学习资料\\demoLes03\\web\\WEB-INF\\test.xml");
//获取解析器
SAXReader reader = new SAXReader();
//通过解析器的read方法将配置文件读取到内存,生成一个Document【org.dom4j】对象树
Document document = reader.read(inputFile);
//获取根节点root
Element classElement = document.getRootElement();
List nodes = document.selectNodes("/class/part[@id='02']");
//定位到该元素属性的位置,定位到id为02的元素属性
System.out.println("--------------------");
for (Node node:nodes){
System.out.println("标签名=:"+node.getName());
System.out.println("姓名:"+node.selectSingleNode("name").getText());
System.out.println("年龄:"+node.selectSingleNode("age").getText());
System.out.println("性别:"+node.selectSingleNode("sex").getText());
}
} catch (Exception e1) {
e1.printStackTrace();
}
}
}
案例:遍历全部
try {
//创建解析器
SAXReader reader = new SAXReader();
//通过解析器的read方法将配置文件读取到内存,生成一个Document【org.dom4j】对象树
Document document = reader.read("week1-code\\src\\com\\hpit10\\DomJ_\\book3.xml");
//获取根节点
Element root = document.getRootElement();
//遍历
for (Iterator rootIter = root.elementIterator();rootIter.hasNext();){
Element bookElt = rootIter.next();
for (Iterator innerIter = bookElt.elementIterator();innerIter.hasNext();){
Element innerElt = innerIter.next();
String innerValue = innerElt.getStringValue();
System.out.println(innerValue);
}
}catch (Exception e){
e.printStackTrace();
}
Jsoup:
//2.1获取student.xml的path
String path = JsoupDemo1.class.getClassLoader().getResource("com/hpit01/Jsoup01/student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
Document document = Jsoup.parse(new File(path), "utf-8");
//3.获取元素对象 Element
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
//3.1获取第一个name的Element对象
Element element = elements.get(0);
//3.2获取数据
String name = element.text();
System.out.println(name);
案例:
public class Jsoup_Demo4 {
public static void main(String[] args) throws IOException {
//根据文件路径获取document对象
String path = Jsoup_Demo4.class.getClassLoader().getResource("com/hpit01/Jsoup01/student.xml").getPath();
Document document = Jsoup.parse(new File(path), "utf-8");
//通过document对象根据标签名称获取标签元素对象们
Elements names = document.getElementsByTag("name");
System.out.println(names.size());
System.out.println("---------------------------");
System.out.println(names.html());
//通过元素对象获取具有number属性的子元素对象
Element student = document.getElementsByTag("student").get(0);
Elements number = student.getElementsByAttribute("number");
System.out.println(number.size());
System.out.println("---------------------------");
//通过元素对象获取该元素中namber属性的值
String value = student.attr("number");
System.out.println(value);
System.out.println("---------------------------");
//获取name元素对象中的纯文本内容
Elements name_ele = student.getElementsByTag("name");
String text = name_ele.text();
System.out.println(text);
System.out.println("---------------------------");
//获取name元素对象中的带有标签的内容
String html = name_ele.html();
System.out.println(html);
}
}
小结
语法规范:
1.XML声明语句 2.必须有一个根元素 3.标记大小写敏感 4.属性值用引号 5.标记成对 6.空标记关闭 7.元素正确嵌套
from:xml文件基本格式与解析(一)_SixSixSix_Six的博客-CSDN博客_xmf是什么格式
什么是xml文件格式
-
我们要给对方传输一段数据,数据内容是“too young,too simple,sometimes naive”,要将这段话按照属性拆分为三个数据的话,就是,年龄too young,阅历too simple,结果sometimes naive。我们都知道程序不像人,可以体会字面意思,并自动拆分出数据,因此,我们需要帮助程序做拆分,因此出现了各种各样的数据格式以及拆分方式。比如,可以是这样的数据为“too young,too simple,sometimes naive”然后按照逗号拆分,第一部分为年龄,第二部分为阅历,第三部分为结果。
-
也可以是这样的数据为“too_young* too_simple*sometimes_naive”从数据开头开始截取前面十一个字符,去掉号并把下划线替换为空格作为第一部分,再截取接下来的十一个字符同样去掉并替换下划线为空格作为第二部分,最后把剩下的字符同样去号体会空格作为第三部分。
-
这两种方式都可以用来容纳数据并能够被解析,但是不直观,通用性也不好,而且如果出现超过限定字数的字符串就容纳不了,也可能出现数据本身就下划线字符导致需要做转义。基于这种情况,出现了xml这种数据格式, 上面的数据用XML表示的话可以是这样
也可以是这样
两种方式都是xml,都很直观,附带了对数据的说明,并且具备通用的格式规范可以让程序做解析。如果用json格式来表示的话,就是下面这样看出来没,其实数据都是一样的,不同的只是数据的格式而已,同样的数据,我用xml格式传给你,你用xml格式解析出三个数据,用json格式传给你,你就用json格式解析出三个数据,还可以我本地保存的是xml格式的数据,我自己先解析出三个数据,然后构造成json格式传给你,你解析json格式,获得三个数据,再自己构造成xml格式保存起来,说白了,不管是xml还是json,都只是包装数据的不同格式而已,重要的是其中含有的数据,而不是包装的格式。
XML文件创建格式
-
例:
我是徐茅山 今年20岁 男 我是李逍遥 今年22岁 男
-
开始的
XML CRUD
U2-code\week1-code\hpit10\
JAXP
JAXP 开发包是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包组成 在 javax.xml.parsers 包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的 DOM 或 SAX 的解析器对象。
使用JAXP进行DOM解析
javax.xml.parsers 包中的DocumentBuilderFactory用于创建DOM模式的解析器对象 , DocumentBuilderFactory是一个抽象工厂类,它不能直接实例化,但该类提供了一个newInstance方法 ,这个方法会根据本地平台默认安装的解析器,自动创建一个工厂的对象并返回。
获得JAXP中的DOM解析器
调用 DocumentBuilderFactory.newInstance() 方法得到创建 DOM 解析器的工厂。 调用工厂对象的 newDocumentBuilder方法得到 DOM 解析器对象。 调用 DOM 解析器对象的 parse() 方法解析 XML 文档,得到代表整个文档的 Document 对象,进行可以利用DOM特性对整个XML文档进行操作了。
DOM编程
DOM模型(document object model) DOM解析器在解析XML文档时,会把文档中的所有元素,按照其出现的层次关系,解析成一个个Node对象(节点)。 在dom中,节点之间关系如下: 位于一个节点之上的节点是该节点的父节点(parent) 一个节点之下的节点是该节点的子节点(children) 同一层次,具有相同父节点的节点是兄弟节点(sibling) 一个节点的下一个层次的节点集合是节点后代(descendant) 父、祖父节点及所有位于节点上面的,都是节点的祖先(ancestor)
Node对象
Node对象提供了一系列常量来代表结点的类型,当开发人员获得某个Node类型后,就可以把Node节点转换成相应的节点对象(Node的子类对象),以便于调用其特有的方法。(查看API文档) Node对象提供了相应的方法去获得它的父结点或子结点。编程人员通过这些方法就可以读取整个XML文档的内容、或添加、修改、删除XML文档的内容了。
DOM方式解析XML文件
DOM解析编程 遍历所有节点 查找某一个节点 删除结点 更新结点 添加节点
Dom解析
//1.获取工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//2.产生解析器
DocumentBuilder builder = factory.newDocumentBuilder();
//3.解析xml文档,得到代表文档的document
Document document = builder.parse(new File("week1-code\\src\\com\\hpit10\\book.xml"));
//遍历
list(document);
//遍历
public static void list(Node node) {
if (node.getNodeType() == Node.ELEMENT_NODE) {
System.out.println(node.getNodeName());
}
NodeList list = node.getChildNodes();
for (int i = 0; i < list.getLength(); i++) {
Node child = list.item(i);
list(child);
}
}
DOM编程练习
book1.xml
<书架>
<书 name="yyyyyyy">
<售价>109
<售价>39元
<书名>Java就业培训教程
<作者>张孝祥
<书>
<书名>JavaScript网页开发
<作者>张孝祥
<售价>28.00元
遍历所有节点
public class Demo1 {
/**使用jaxp操作xml文档
* @param args
* @throws ParserConfigurationException
* @throws IOException
* @throws SAXException
*/
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//1.获取工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//2.产生解析器
DocumentBuilder builder = factory.newDocumentBuilder();
//3.解析xml文档,得到代表文档的document
Document document = builder.parse(new File("src/book1.xml"));
//遍历
list(document);
}
//遍历
public static void list(Node node){
if(node.getNodeType()==Node.ELEMENT_NODE){
System.out.println(node.getNodeName());
}
NodeList list = node.getChildNodes();
for(int i=0;i
查找某一个节点
//得到售价结点的值
@Test
public void read() throws Exception{
//1.获取工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book.xml"));
NodeList list = document.getElementsByTagName("售价");
Node price = list.item(0);
String value = price.getTextContent();
System.out.println(value);
}
添加节点
//向指定节点中增加孩子节点(售价节点)
@Test
public void add() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
//创建需要增加的节点
Node price = document.createElement("售价");
price.setTextContent("59元");
//得到需要增加的节点的父亲
Node parent = document.getElementsByTagName("书").item(0);
//把需要增加的节点挂到父结点上
parent.appendChild(price);
//把内存中的document写到xml文档
TransformerFactory tf = TransformerFactory.newInstance();
//得到转换器
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
//向指定位置上插入售价节点
@Test
public void add2() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
Node node = document.createElement("售价");
node.setTextContent("39元");
Node parent = document.getElementsByTagName("书").item(0);
parent.insertBefore(node, document.getElementsByTagName("书名").item(0));
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
更新结点
//修改结点的值:<售价>109改为111
@Test
public void update() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
Node price = document.getElementsByTagName("售价").item(0);
price.setTextContent("111");
//把内存中的document写到xml文档
TransformerFactory tf = TransformerFactory.newInstance();
//得到转换器
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
删除结点
//删除xml文档的售价结点
@Test
public void delete() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
Node node = document.getElementsByTagName("售价").item(2);
node.getParentNode().removeChild(node);
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
执行后
操作xml文档属性
//操作xml文档属性
@Test
public void updateAttribute() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
//操作xml文档的元素时,一般都把元素当作node对象,但是程序员如果发现node不好使时,就应把node强转成相应类型
Node node = document.getElementsByTagName("书").item(0);
Element book = null;
if(node.getNodeType()==Node.ELEMENT_NODE){ //在作结点转换之前,最好先判断结点类型
book = (Element)node;
}
book.setAttribute("name", "yyyyyyy");
book.setAttribute("password", "123");
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
//移除xml文档属性
@Test
public void updateAttribute() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
//操作xml文档的元素时,一般都把元素当作node对象,但是程序员如果发现node不好使时,就应把node强转成相应类型
Node node = document.getElementsByTagName("书").item(0);
Element book = null;
if(node.getNodeType()==Node.ELEMENT_NODE){ //在作结点转换之前,最好先判断结点类型
book = (Element)node;
}
// book.setAttribute("name", "yyyyyyy");
// book.setAttribute("password", "123");
book.removeAttribute("password");
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
删除整个XML文档
//删除整个xml文档
@Test
public void delete2() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
//得到要删除的结点
Element e = (Element) document.getElementsByTagName("售价").item(0);
e.getParentNode().getParentNode().getParentNode().removeChild(e.getParentNode().getParentNode());
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
更新XML文档
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写入到一个XML文件中。 Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象, 用javax.xml.transform.stream.StreamResult 对象来表示数据的目的地。 Transformer对象通过TransformerFactory获得。
SAX解析
在使用 DOM 解析 XML 文档时,需要读取整个 XML 文档,在内存中构架代表整个 DOM 树的Doucment对象,从而再对XML文档进行操作。此种情况下,如果 XML 文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出。 SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会文档进行操作。 SAX采用事件处理的方式解析XML文件,利用 SAX 解析 XML 文档,涉及两个部分:解析器和事件处理器: 解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。 解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。 事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理。
阅读ContentHandler API文档,常用方法:startElement、endElement、characters
SAX方式解析XML文档
使用SAXParserFactory创建SAX解析工厂 SAXParserFactory spf = SAXParserFactory.newInstance();
通过SAX解析工厂得到解析器对象 SAXParser sp = spf.newSAXParser();
通过解析器对象得到一个XML的读取器 XMLReader xmlReader = sp.getXMLReader();
设置读取器的事件处理器 xmlReader.setContentHandler(new BookParserHandler());
解析xml文件 xmlReader.parse("book.xml");
SAX
MyContentHandler
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//1.创建工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//2.用工厂创建解析器
SAXParser sp = factory.newSAXParser();
//3.利用解析器得到reader
XMLReader reader = sp.getXMLReader();
//4、在解析xml文档之前,设置好事件处理器
reader.setContentHandler(new MyContentHandler());
//4.利用reader读取 xml文档
reader.parse("week1-code\\src\\com\\hpit10\\SAX_\\book1.xml");
}
class MyContentHandler implements ContentHandler{
public void startElement(String uri, String localName, String name,
Attributes atts) throws SAXException {
System.out.println("当前解析到了:" + name + ",这个标签是开始标签");
for(int i=0;i
SAX解析编程
book.xml
<书架>
<书 name="yyyyyyy">
<售价>209元
<售价>19元
<书名>Java就业培训教程
<作者>张孝祥
<售价>19元
<售价>19元
<书>
<书名>JavaScript网页开发
<作者>张孝祥
<售价>28.00元
MyContentHandler()
public class Demo1 {
/**
*sax方式解析book1.xml文件
* @throws SAXException
* @throws ParserConfigurationException
* @throws IOException
*/
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//1.创建工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//2.用工厂创建解析器
SAXParser sp = factory.newSAXParser();
//3.利用解析器得到reader
XMLReader reader = sp.getXMLReader();
//4、在解析xml文档之前,设置好事件处理器
reader.setContentHandler(new MyContentHandler());
//4.利用reader读取 xml文档
reader.parse("src/book1.xml");
}
}
//得到xml文档内容的事件处理器
class MyContentHandler implements ContentHandler{
public void startElement(String uri, String localName, String name,
Attributes atts) throws SAXException {
System.out.println("当前解析到了:" + name + ",这个标签是开始标签");
for(int i=0;i
MyContentHandler2()
public class Demo1 {
/**
*sax方式解析book1.xml文件
* @throws SAXException
* @throws ParserConfigurationException
* @throws IOException
*/
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//1.创建工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//2.用工厂创建解析器
SAXParser sp = factory.newSAXParser();
//3.利用解析器得到reader
XMLReader reader = sp.getXMLReader();
//4、在解析xml文档之前,设置好事件处理器
reader.setContentHandler(new MyContentHandler2());
//4.利用reader读取 xml文档
reader.parse("src/book1.xml");
}
}
//用于获取第一个售价节点的值:<售价>109
class MyContentHandler2 extends DefaultHandler{
private boolean isOk = false;
private int index = 1;
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if(isOk==true && index==1){
System.out.println(new String(ch,start,length));
}
}
@Override
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
if(name.equals("售价")){
isOk = true;
}
}
@Override
public void endElement(String uri, String localName, String name)
throws SAXException {
if(name.equals("售价")){
isOk = false;
index++;
}
}
}
修改book.xml
<书架>
<书 name="yyyyyyy">
<售价>209元
<售价>19元
<书名>Java就业培训教程
<作者>张孝祥
<售价>19元
<售价>19元
<书>
<书名>JavaScript网页开发
<作者>黎活明
<售价>28.00元
TagValueHandler()
public class Demo1 {
/**
*sax方式解析book1.xml文件
* @throws SAXException
* @throws ParserConfigurationException
* @throws IOException
*/
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//1.创建工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//2.用工厂创建解析器
SAXParser sp = factory.newSAXParser();
//3.利用解析器得到reader
XMLReader reader = sp.getXMLReader();
//4、在解析xml文档之前,设置好事件处理器
reader.setContentHandler(new TagValueHandler());
//4.利用reader读取 xml文档
reader.parse("src/book1.xml");
}
}
//获取指定标签的值
class TagValueHandler extends DefaultHandler{
private String currentTag; //记住当前生命标签
private int needNumber = 2; //记住想要获取第几个标签
private int currentNumber; //当前解析到的是第几个标签
@Override
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
currentTag = name;
if(currentTag.equals("作者")){
currentNumber ++;
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if("作者".equals(currentTag) && currentNumber == needNumber){
System.out.println(new String(ch,start,length));
}
}
@Override
public void endElement(String uri, String localName, String name)
throws SAXException {
currentTag = null;
}
sax解析案例(javabean封装xml文档数据)
<书架> <书 name="yyyyyyy"> <书名>Java就业培训教程 <作者>张孝祥 <售价>19元 <书> <书名>JavaScript网页开发 <作者>黎活明 <售价>28.00元
创建一个book类
public class Book {
private String name;
private String author;
private String price;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
@Override
public String toString() {
return "Book [name=" + name + ", author=" + author + ", price=" + price + "]";
}
}
public class Demo2 {
/**
*sax方式解析book1.xml文件
* @throws SAXException
* @throws ParserConfigurationException
* @throws IOException
*/
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//1.创建工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//2.用工厂创建解析器
SAXParser sp = factory.newSAXParser();
//3.利用解析器得到reader
XMLReader reader = sp.getXMLReader();
//4、在解析xml文档之前,设置好事件处理器
BeanListHandler handler = new BeanListHandler();
reader.setContentHandler(handler);
//4.利用reader读取 xml文档
reader.parse("src/book1.xml");
List list = handler.getList();
for(Book book : list){
System.out.println(book);
}
}
}
//把xml文档中的每一本书封装到一个book对象,并把对个book对象放在一个list集合中返回
class BeanListHandler extends DefaultHandler{
private List list = new ArrayList();
private String currentTag;
private Book book;
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// TODO Auto-generated method stub
currentTag = qName;
if("书".equals(currentTag)){
book = new Book();
}
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
// TODO Auto-generated method stub
if("书名".equals(currentTag)){
String name = new String(ch,start,length);
book.setName(name);
}
if("作者".equals(currentTag)){
String author = new String(ch,start,length);
book.setAuthor(author);
}
if("售价".equals(currentTag)){
String price = new String(ch, start, length);
book.setPrice(price);
}
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
// TODO Auto-generated method stub
if(qName.equals("书")){
list.add(book);
book = null;
}
currentTag = null;//不加上会报java.lang.NullPointerException
}
public List getList() {
return list;
}
}
DOM4J解析
Dom4j是一个简单、灵活的开放源代码的库。Dom4j是由早期开发JDOM的人分离出来而后独立开发的。与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j的API相对要复杂一些,但它提供了比JDOM更好的灵活性。
Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的Dom4j,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j。
使用Dom4j开发,需下载dom4j相应的jar文件。
Document对象
DOM4j中,获得Document对象的方式有三种:
1.读取XML文件,获得document对象
SAXReader reader = new SAXReader(); Document document = reader.read(new File("input.xml"));
2.解析XML形式的文本,得到document对象.
String text = "
3.主动创建document对象.
Document document = DocumentHelper.createDocument(); //创建根节点 Element root = document.addElement("members");
节点对象
1.获取文档的根节点.
Element root = document.getRootElement();
2.取得某个节点的子节点.
Element element=node.element("书名");
3.取得节点的文字
String text=node.getText();
4.取得某节点下所有名为“member”的子节点,并进行遍历.
List nodes = rootElm.elements("member") for (Iterator it = nodes.iterator(); it.hasNext();) { Element elm = (Element) it.next(); // do something
String innerValue = innerElt.getStringValue(); System.out.println(innerValue);
}
5.对某节点下的所有子节点进行遍历.
for(Iterator it=root.elementIterator();it.hasNext();){ Element element = (Element) it.next(); // do something }
6.在某节点下添加子节点.
Element ageElm = newMemberElm.addElement("age");
7.设置节点文字.
element.setText("29");
8.删除某节点.
//childElm是待删除的节点,parentElm是其父节点 parentElm.remove(childElm);
9.添加一个CDATA节点.
Element contentElm = infoElm.addElement("content"); contentElm.addCDATA(diary.getContent());
节点对象属性
1.取得某节点下的某属性
Element root=document.getRootElement(); //属性名name Attribute attribute=root.attribute("size");
2.取得属性的文字
String text=attribute.getText();
3.删除某属性
Attribute attribute=root.attribute("size"); root.remove(attribute);
4.遍历某节点的所有属性
Element root=document.getRootElement(); for(Iterator it=root.attributeIterator();it.hasNext();){ Attribute attribute = (Attribute) it.next(); String text=attribute.getText(); System.out.println(text); }
5.设置某节点的属性和文字.
newMemberElm.addAttribute("name", "sitinspring");
6.设置属性的文字
Attribute attribute=root.attribute("name"); attribute.setText("sitinspring");
将文档写入XML文件
1.文档中全为英文,不设置编码,直接写入的形式.
XMLWriter writer = new XMLWriter(new FileWriter("output.xml")); writer.write(document); writer.close();
2.文档中含有中文,设置编码格式写入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();// 指定XML编码 format.setEncoding("GBK"); XMLWriter writer = new XMLWriter(newFileWriter("output.xml"),format); writer.write(document); writer.close();
Dom4j在指定位置插入节点
1.得到插入位置的节点列表(list) 2.调用list.add(index,elemnent),由index决定element的插入位置。 Element元素可以通过DocumentHelper对象得到。示例代码 Element aaa = DocumentHelper.createElement("aaa"); aaa.setText("aaa");
List list = root.element("书").elements(); list.add(1, aaa);
//更新document
字符串与XML的转换
1.将字符串转化为XML String text = " sitinspring "; Document document = DocumentHelper.parseText(text);
2.将文档或节点的XML转化为字符串. SAXReader reader = new SAXReader(); Document document = reader.read(new File("input.xml")); Element root=document.getRootElement(); String docXmlText=document.asXML(); String rootXmlText=root.asXML(); Element memberElm=root.element("member"); String memberXmlText=memberElm.asXML();
Dom4j
try {
//创建解析器
SAXReader reader = new SAXReader();
//通过解析器的read方法将配置文件读取到内存,生成一个Document【org.dom4j】对象树
Document document = reader.read("week1-code\\src\\com\\hpit10\\DomJ_\\book3.xml");
//获取根节点
Element root = document.getRootElement();
//遍历
for (Iterator rootIter = root.elementIterator();rootIter.hasNext();){
Element bookElt = rootIter.next();
for (Iterator innerIter = bookElt.elementIterator();innerIter.hasNext();){
Element innerElt = innerIter.next();
String innerValue = innerElt.getStringValue();
System.out.println(innerValue);
}
}catch (Exception e){
e.printStackTrace();
}
DOM4J编程
读取xml
//读取xml文档数据:<书名>Java就业培训教程
@Test
public void read() throws Exception{
//获取解析器
SAXReader reader = new SAXReader();
//通过解析器的read方法将配置文件读取到内存,生成一个Document【org.dom4j】对象树
Document document = reader.read(new File("src/book1.xml"));
//获取根节点
Element root = document.getRootElement();
Element bookname = root.element("书").element("书名");
System.out.println(bookname.getText());
}
读取xml属性
//<书 name="yyyyyyy">
@Test
public void readAttr() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element root = document.getRootElement();
String value = root.element("书").attributeValue("name");
System.out.println(value);
}
向xml中添加元素
//向xml文档中添加<售价>19元
@Test
public void add() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element price = DocumentHelper.createElement("售价");
price.setText("19元");
document.getRootElement().element("书").add(price);
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book1.xml"),format);//FileOutputStream 查格式输入器format的码表"UTF-8"
writer.write(document); //utf-8
writer.close();
}
dom4j保存数据的乱码问题
//向xml文档中添加<售价>19元
@Test
public void add() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element price = DocumentHelper.createElement("售价");
price.setText("19元");
document.getRootElement().element("书").add(price);
//编码
// format.setEncoding("gb2312");
//
XMLWriter writer = new XMLWriter(new FileWriter("src/book1.xml"));//默认查gb2312码表
writer.write(document);
writer.close();
}
//向xml文档中添加<售价>19元
@Test
public void add() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element price = DocumentHelper.createElement("售价");
price.setText("19元");
document.getRootElement().element("书").add(price);
XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream("src/book1.xml"),"UTF-8"));
writer.write(document); //默认UTF-8
writer.close();
}
修改xml元素
//修改:<售价>19元 为209元
@Test
public void update() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element price = (Element) document.getRootElement().element("书").elements("售价").get(0);
price.setText("209元");
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book1.xml"),format);
writer.write(document); //utf-8
writer.close();
}
删除xml元素
//删除:<售价>209
@Test
public void delete() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element price = (Element) document.getRootElement().element("书").elements("售价").get(0);
price.getParent().remove(price);
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book1.xml"),format);
writer.write(document); //utf-8
writer.close();
}
向指定位置增加售价结点
//向指定位置增加售价结点
@Test
public void add2() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element price = DocumentHelper.createElement("售价");
price.setText("19元");
List list = document.getRootElement().element("书").elements();
list.add(1, price);
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book1.xml"),format);
writer.write(document); //utf-8
writer.close();
}
XPath提取xml文档数据
@Test
public void findWithXpath() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element e = (Element) document.selectNodes("//书名").get(1);
System.out.println(e.getText());
}
user.xml
@Test
public void findUser() throws Exception{
String username = "aaa";
String password = "1233";
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/users.xml"));
Element e = (Element) document.selectSingleNode("//user[@username='"+username+"' and @password='"+password+"']");
if(e!=null){
System.out.println("让用户登陆成功!!");
}else{
System.out.println("用户名和密码不正确!!");
}
}
}
*Jsoup解析
* Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
* 快速入门:
* 步骤:
1. 导入jar包
2. 获取Document对象
3. 获取对应的标签Element对象
4. 获取数据
* 代码:
//2.1获取student.xml的path
String path = JsoupDemo1.class.getClassLoader().getResource("com/hpit01/Jsoup01/student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
Document document = Jsoup.parse(new File(path), "utf-8");
//3.获取元素对象 Element extends ArrrayList集合
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
//3.1获取第一个name的Element对象
Element element = elements.get(0);
//3.2获取数据
String name = element.text();
System.out.println(name);
* 对象的使用:
1. Jsoup:工具类,可以解析html或xml文档,返回Document
* parse:解析html或xml文档,返回Document
* parse(File in, String charsetName):解析xml或html文件的。
* parse(String html):解析xml或html字符串
* parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象
2. Document:文档对象。代表内存中的dom树
* 获取Element对象
* getElementById(String id):根据id属性值获取唯一的element对象
* getElementsByTag(String tagName):根据标签名称获取元素对象集合
* getElementsByAttribute(String key):根据属性名称获取元素对象集合
* getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
3. Elements:元素Element对象的集合。可以当做 ArrayList来使用
4. Element:元素对象
1. 获取子元素对象
* getElementById(String id):根据id属性值获取唯一的element对象
* getElementsByTag(String tagName):根据标签名称获取元素对象集合
* getElementsByAttribute(String key):根据属性名称获取元素对象集合
* getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
2. 获取属性值
* String attr(String key):根据属性名称获取属性值
3. 获取文本内容
* String text():获取文本内容
* String html():获取标签体的所有内容(包括字标签的字符串内容)
5. Node:节点对象
* 是Document和Element的父类
案例:
public class Jsoup_Demo4 {
public static void main(String[] args) throws IOException {
//根据文件路径获取document对象
String path = Jsoup_Demo4.class.getClassLoader().getResource("com/hpit01/Jsoup01/student.xml").getPath();
Document document = Jsoup.parse(new File(path), "utf-8");
//通过document对象根据标签名称获取标签元素对象们
Elements names = document.getElementsByTag("name");
System.out.println(names.size());
System.out.println("---------------------------");
//通过元素对象获取具有number属性的子元素对象
Element student = document.getElementsByTag("student").get(0);
Elements number = student.getElementsByAttribute("number");
System.out.println(number.size());
System.out.println("---------------------------");
//通过元素对象获取该元素中namber属性的值
String value = student.attr("number");
System.out.println(value);
System.out.println("---------------------------");
//获取name元素对象中的纯文本内容
Elements name_ele = student.getElementsByTag("name");
String text = name_ele.text();
System.out.println(text);
System.out.println("---------------------------");
//获取name元素对象中的带有标签的内容
String html = name_ele.html();
System.out.println(html);
}
}
XPath
详情参考:XPath 教程
1. selector:选择器
* 使用的方法:Elements select(String cssQuery)
* 语法:参考Selector类中定义的语法
//获取name标签
Elements els = document.select("name");
System.out.println(els);
System.out.println("---------------------------");
//获取id为#beida的标签
Elements select = document.select("#beida");
System.out.println(select);
System.out.println("---------------------------");
//获取student标签,并且number属性值为s001的age子标签
Elements age = document.select("student[number=\"s001\"] age");
System.out.println(age);
2. XPath:XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言
* 使用Jsoup的Xpath需要额外导入jar包。
* 查询w3cshool参考手册,使用xpath的语法完成查询
package com.hpit01.Jsoup01;
import cn.wanghaomiao.xpath.exception.XpathSyntaxErrorException;
import cn.wanghaomiao.xpath.model.JXDocument;
import cn.wanghaomiao.xpath.model.JXNode;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Jsoup_Demo6 {
public static void main(String[] args) throws IOException, XpathSyntaxErrorException {
//根据文件路径获取document对象
String path = Jsoup_Demo6.class.getClassLoader().getResource("com/hpit01/Jsoup01/student.xml").getPath();
Document document = Jsoup.parse(new File(path), "utf-8");
//将document包装成JXDocument
JXDocument jkd=new JXDocument(document);
//查询所有的student标签
List jxNodes = jkd.selN("//student");
for (JXNode jxNode : jxNodes) {
System.out.println(jxNode);
}
System.out.println("--------------------------------");
//查询所有的student标签下的name标签
List jxNodes2 = jkd.selN("//student/name");
for (JXNode jxNode : jxNodes2) {
System.out.println(jxNode);
}
System.out.println("--------------------------------");
//查询所有的student标签下带有id属性的name标签
List jxNodes3 = jkd.selN("//student/name[@id]");
for (JXNode jxNode : jxNodes3) {
System.out.println(jxNode);
}
System.out.println("--------------------------------");
//查询所有的student标签下id属性值为hpit01的name标签
List jxNodes4 = jkd.selN("//student/name[@id='hpit01']");
for (JXNode jxNode : jxNodes4) {
System.out.println(jxNode);
}
}
}
dom4j参考资料
dom4j ———————————————— 版权声明:本文为CSDN博主「c.」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:XML编程(CRUD)_C.-CSDN博客_xml编程
-
坦克大战
Lambda 表达式
Lambda 表达式支持将代码块作为方法参数, Lambda 表达式允许使用更简洁的代码来创建只有一个抽象方法的接口(这 种接口被称为函数式接口)的实例 。
1.5.9.1 Lambda 表达式入门
先使用匿名内部类实现:
public interface Command { // 接口里定义的process()方法用于封装“处理行为” void process(int[] target); }
public class ProcessArray { public void process(int[] target , Command cmd) { cmd.process(target); } }
public class CommandTest { public static void main(String[] args) { ProcessArray pa = new ProcessArray(); int[] array = {3, -4, 6, 4}; // 处理数组,具体处理行为取决于匿名内部类 pa.process(array , new Command() { public void process(int[] target) { int sum = 0; for (int tmp : target ) { sum += tmp; } System.out.println("数组元素的总和是:" + sum); } }); } }
Lambda 表达式完全可用于简化创建匿名内部类对象:
public class CommandTest2 { public static void main(String[] args) { ProcessArray pa = new ProcessArray(); int[] array = {3, -4, 6, 4}; // 处理数组,具体处理行为取决于匿名内部类 pa.process(array , (int[] target)->{ int sum = 0; for (int tmp : target ) { sum += tmp; } System.out.println("数组元素的总和是:" + sum); }); } }
与创建匿名内部类时需要实现的 process(int[] target)方法完全相同,lambda 表达式只是不需要 new Xx(){} 这种烦琐的代码,不需要指出重写的方法名字,也不需要给出重写的方法的返回值类型一一只要给出重写的方法括号以及括号里的形参列表即可。
当使用 Lambda 表达式代替匿名内部类创建对象时, Lambda 表达式的代码块将会代替实现抽象方法的方法体, Lambda 表达式就相当 一个匿名方法。
Lambda 表达式的主要作用就是代替匿名内部类的烦琐语法。它由三部分组成:
形参列表 。形参列表允许省略形参类型 。如果形参列表中只有一个参数,甚至连形参列表的圆括号也可以省略 。 箭头(-> )。必须通过英文中画线和大于符号组成。 代码块。如果代码块只包含一条语句 , Lambda 表达式允许省略代码块的花括号 ,那么这条语句 就不要用花括号表示语句结束 。 Lambda 代码块只有一条 return 语句,甚至可以省略 return 关键 字。 Lambda 表达式需要返回值,而它的代码块中仅有一条省略了 retum 的语句 , Lambda 表达式会自动返回这条语句的值。 Lambda 表达式的几种简化写法。
interface Eatable { void taste(); } interface Flyable { void fly(String weather); } interface Addable { int add(int a , int b); } public class LambdaQs { // 调用该方法需要Eatable对象 public void eat(Eatable e) { System.out.println(e); e.taste(); } // 调用该方法需要Flyable对象 public void drive(Flyable f) { System.out.println("我正在驾驶:" + f); f.fly("【碧空如洗的晴日】"); } // 调用该方法需要Addable对象 public void test(Addable add) { System.out.println("5与3的和为:" + add.add(5, 3)); } public static void main(String[] args) { LambdaQs lq = new LambdaQs(); // Lambda表达式的代码块只有一条语句,可以省略花括号。 lq.eat(()-> System.out.println("苹果的味道不错!")); // Lambda表达式的形参列表只有一个形参,省略圆括号 lq.drive(weather -> { System.out.println("今天天气是:" + weather); System.out.println("直升机飞行平稳"); }); // Lambda表达式的代码块只有一条语句,省略花括号 // 代码块中只有一条语句,即使该表达式需要返回值,也可以省略return关键字。 lq.test((a , b)->a + b); } }
第一段粗体字代码使用 Lambda 表达式相当于不带形参的匿名方法,由于该 Lambda 表达式的代码块只有一行代码 , 因此可以省略代码块的花括号;
第二段粗体字代码使用 Lambda 表达式相当于只带一个形参的医名方法 ,由于该 Lambda 表达式的形参列表只有一个形参,因此省略了形参列表的圆括号;
第三段粗体字代码的 Lambda 表达式 的代码块中只有一行语句,这行语句的返回值将作为该代码块的返回值 。
1.5.9.2 Lambda 表达式与函数式接口
Lambda 表达式的类型,也被称为"目标类型( target type) " , Lambda 表达式的目标类型必须是"函数式接口( functional interface ) " 。函数式接口代表只包含一个抽象方法的接口。函数式接口可以包含多个默认方法、类方法,但只能声明一个抽象方法 。
如果采用匿名内部类语法来创建函数式接口的实例,则只需要实现一个抽象方法,在这种情况下即可采用 Lambda 表达式来创建对象,该表达式创建出来的对象的目标类型就是这个函数式接口。 查询 Java 8 的 API 文档,可以发现大量的函数式接口,例如: Runnable、 ActionListener 等接口都是函数式接口 。
Java 8 专门为函数式接口提供了 @FunctionalInterface 注解,该注解通常放在接口定义前面,该注解对程序功能没有任何作用,它用于告诉编译器执行更严格检查一一检查该接口必须是函数式接口,否则编译器就会报错 。
@FunctionalInterface interface FkTest { void run(); }
public class LambdaTest { public static void main(String[] args) { // Runnable接口中只包含一个无参数的方法 // Lambda表达式代表的匿名方法实现了Runnable接口中唯一的、无参数的方法 // 因此下面的Lambda表达式创建了一个Runnable对象 Runnable r = () -> { for(int i = 0 ; i < 100 ; i ++) { System.out.println(); } }; // // 下面代码报错: 不兼容的类型: Object不是函数接口 // Object obj = () -> { // for(int i = 0 ; i < 100 ; i ++) // { // System.out.println(); // } // };
Object obj1 = (Runnable)() -> {
for(int i = 0 ; i < 100 ; i ++)
{
System.out.println();
}
};
// 同样的Lambda表达式可以被当成不同的目标类型,唯一的要求是:
// Lambda表达式的形参列表与函数式接口中唯一的抽象方法的形参列表相同
Object obj2 = (FkTest)() -> {
for(int i = 0 ; i < 100 ; i ++)
{
System.out.println();
}
};
}
}
Lambda 表达式实现的是匿名方法 – 因此它只能实现特定函数式接口中的唯一方法。这意味着 Lambda 表达式有如下两个限制 。
Lambda 表达式的目标类型必须是明确的函数式接口 。 Lambda 表达式只能为函数式接口创建对象 。 Lambda 表达式只能实现一个方法 ,只有一个抽象方法的接口(函数式接口〉创建对象 。 Lambda 表达式的目标类型必须是明确的函数式接口。
为了保证 Lambda 表达式的目标类型是一个明确的函数式接口,可以有如下三种常见方式 。
将 Lambda 表达式赋值给函数式接口类型的变量。 将 Lambda 表达式作为函数式接口类型的参数传给某个方法。 使用函数式接口对 Lambda 表达式进行强制类型转换。 Java 8 在 java.util.function 包下预定义了大量函数式接口,典型地包含如下 4 类接口 。
XxxFunction: 这类接口中通常包含一个 applyO抽象方法,该方法对参数进行处理、转换 CapplyO 方法的处理逻辑由 Lambda 表达式来实现),然后返回 一个新的值 。 该函数式接口通常用于对指定数据进行转换处理 。
XxxConsumer: 这类接口中通常包含一个 acceptO抽象方法,该方法与 XxxFunction 接口中的 applyO方法基本相似,也负责对参数进行处理,只是该方法不会返回处理结果 。
XxxxPredicate: 这类接口中通常包含一个 testO抽象方法,该方法通常用来对参数进行某种判断 (testO方法的判断逻辑由 Lambda 表达式来实现),然后返回 一个 boolean 值 。 该接口通常用于判 断参数是否满足特定条件,经常用于进行筛滤数据 。
XxxSupplier: 这类接口中通常包含一个 getAsXxxO抽象方法,该力法不需要输入参数,该力法 会按某种逻辑算法 (getAsXxx 0方法的逻辑算法由 Lambda 表达式来实现)返回 一个数据。
综上所述,不难发现 Lambda 表达式的本质很简单,就是使用简洁的语法来创建函数式接口的实例 – 这种语法避免了匿名内部类的烦琐 。
1.5.9.3 方法引用与构造器引用
如果 Lambda 表达式的代码块只有一条代码,程序就可以省略 Lambda 表达式中代码块的花括号 。 不仅如此,如果 Lambda 表达式的代码块只有一条代码,还可以在代码块中使用方法引用和构造器引用 。
方法引用和构造器引用可以让 Lambda 表达式的代码块更加简洁 。 方法引用和构造器引用都需要使 用两个英文冒号 。
种类 示例 说明 对应Lambda表达式 引用类方法 类名:类方法 函数式接口中被实现方法的全部参数传给 该类方法作为参数 (a, b,…) ->类名.类方法(a, b,…) 引用特定对象的实 例 方法 特定对象实例方法 函数式接口中被 实 现方法的全部参数传给 该方法作为参数 (a, b,…)->特定对象.实例方法(a, b,…) 引用某类对象的实例方法 类名实例方法 函数式接口中被实现方法的第 一 个参数作为调用 者 ,后面的参数全部传给该方法作为参数 (a, b,…) ->a 实例方法(b,…) 引用构造器 类名::new 函数式接口中被实现方法的全部参数传给 该构造器作为参数 (a, b,…) ->new 类名 (a, b,…)
import javax.swing.*;
@FunctionalInterface interface Converter { Integer convert(String from); } @FunctionalInterface interface MyTest { String test(String a , int b , int c); } @FunctionalInterface interface YourTest { JFrame win(String title); } public class MethodRefer { public static void main(String[] args) { // 下面代码使用Lambda表达式创建Converter对象 Converter converter1 = from -> Integer.valueOf(from); // 方法引用代替Lambda表达式:引用类方法。 // 函数式接口中被实现方法的全部参数传给该类方法作为参数。 Converter converter1 = Integer::valueOf; Integer val = converter1.convert("99"); System.out.println(val); // 输出整数99
// 下面代码使用Lambda表达式创建Converter对象
Converter converter2 = from -> "fkit.org".indexOf(from);
// 方法引用代替Lambda表达式:引用特定对象的实例方法。
// 函数式接口中被实现方法的全部参数传给该方法作为参数。
Converter converter2 = "fkit.org"::indexOf;
Integer value = converter2.convert("it");
System.out.println(value); // 输出2
// 下面代码使用Lambda表达式创建MyTest对象
MyTest mt = (a , b , c) -> a.substring(b , c);
// 方法引用代替Lambda表达式:引用某类对象的实例方法。
// 函数式接口中被实现方法的第一个参数作为调用者,
// 后面的参数全部传给该方法作为参数。
MyTest mt = String::substring;
String str = mt.test("Java I Love you" , 2 , 9);
System.out.println(str); // 输出:va I Lo
// 下面代码使用Lambda表达式创建YourTest对象
YourTest yt = (String a) -> new JFrame(a);
// 构造器引用代替Lambda表达式。
// 函数式接口中被实现方法的全部参数传给该构造器作为参数。
YourTest yt = JFrame::new;
JFrame jf = yt.win("我的窗口");
System.out.println(jf);
}
}
1.5.9.4 Lambda 表达式与匿名内部类的联系和区别
Lambda 表达式与匿名 内 部类存在如下相同点:
Lambda 表达式与匿名内部类一样 , 都可以直接访问 “effectively final” 的局部变量,以及外部 类的成员变量(包括实例变量和类变量〉 。 Lambda 表达式创建的对象与匿名内部类生成的对象一样 , 都可 以直接调用从接口中继承的默认方法 。 Lambda 表达式与匿名内部类主要存在如下区别:
匿名内部类可以为任意接口创建实例一一不管接口包含多少个抽象方法,只要匿名内部类实现 所有的抽象方法即可;但 Lambda 表达式只能为函数式接口创建实例 。 匿名内部类可以为抽象类甚至普通类创建实例;但 Lambda 表达式只能为函数式接口创建实例 。 匿名内部类实现的抽象方法的方法体允许调用接口中定义的默认方法;但 Lambda 表达式的代 码块不允许调用接口中定义的默认方法 。
1.5.9.5 使用 Lambda 表达式调用 Arrays 的类方法
Arrays 类的有些方法需要 Comparator 、XxxOperator 、XxxFunction 等接口的实例,这些接口都是函数式接口,因此可以使用 Lambda 表达式来调用 Arrays 的方法 。
import java.util.Arrays;
public class LambdaArrays { public static void main(String[] args) { String[] arr1 = new String[]{"java" , "fkava" , "fkit", "ios" , "android"}; Arrays.parallelSort(arr1, (o1, o2) -> o1.length() - o2.length()); System.out.println(Arrays.toString(arr1)); int[] arr2 = new int[]{3, -4 , 25, 16, 30, 18}; // left代表数组中前一个所索引处的元素,计算第一个元素时,left为1 // right代表数组中当前索引处的元素 Arrays.parallelPrefix(arr2, (left, right)-> left * right); System.out.println(Arrays.toString(arr2)); long[] arr3 = new long[5]; // operand代表正在计算的元素索引 Arrays.parallelSetAll(arr3 , operand -> operand * 5); System.out.println(Arrays.toString(arr3)); } }