Go语言学习笔记:基础语法总结
目录
# 准备工作
#基础类型概览
#Go语言的保留字
#Go语言的内置函数:
#定义变量
## 内建变量类型
##类型转换
## 常量定义
## 枚举类型(特殊的常量)
控制语句:
1.条件语句
2.分支选择语句: switch
3.循环语句
4.goto语句
函数:
不定参函数:
## 指针
##参数传递
数组
#定义数组的方法:
#数组的遍历:
切片 Slice
slice结构:
## Reslice(对底层数组重新切片)
##向Slice添加元素
## Slice的操作
make 与 new
#Map 关联数组/字典/映射
#字符和字符串的处理
结构体:
封装
扩展已有类型
# 准备工作
//1.打开go mod 进行依赖管理
go env -w GO111MODULE=on
//2.设置第三方库的镜像代理
go env -w GOPROXY=https://goproxy.cn,https://goproxy.io,direct
//3. 下载goimports 工具
go get -v golang.org/x/tools/cmd/goimports
//4. 生成go.mod 文件用于模块的依赖管理
go mod init 自定义模块名#基础类型概览
- bool(true,flase)
- int(int/uint,int32/int64/uint32/uint64)
- float32(float32/float64)
- string
- byte(byte/rune): ascii码字符用byte类型,unicode字符用rune类型
- array(array,slice)
- map
- complex
- func
- chan
- interface{} 泛型
Go语言的一个特点:
对于未初始化的变量,会自动初始化为该变量类型的”零值“,
- int的零值是0
- bool的零值是false
- byte的零值是0
- string的零值是""
- floatd的零值为0.00000
#Go语言的保留字
一共5*5 =25个保留字
| break | default | func | interface | select |
| case | defer | go | map | struct |
| chan | else | goto | package | switch |
| const | fallthrough | if | range | type |
| continue | for | import | return | var |
#Go语言的内置函数:
- func append(slice []Type, elems ...Type) []Type
- func cap(v Type) int
- func close(c chan<- Type)
- func complex(r, i FloatType) ComplexType
- func copy(dst, src []Type) int
- func delete(m map[Type]Type1, key Type)
- func imag(c ComplexType) FloatType
- func len(v Type) int
- func make(Type, size IntegerType) Type
- func new(Type) *Type
- func panic(v interface{})
- func real(c ComplexType) FloatType
- func recover() interface{}
- print()
- println()
除了强制类型转换函数,Go语言的内置函数一共这么多
#定义变量
package main
import "fmt"
func variableZeroValue(){
var a int
var s string
fmt.Println(a,s)
fmt.Printf("%d %q\n",a,s)
}
func main(){
fmt.Println("hello world")
variableZeroValue()
}声明变量时如果没有赋值,int型默认为0,string型默认为空串,Println不会打印空串,只能通过Printf打印出来。
%q 即 quotation 引语 语录
定义变量时,可以省略 类型,因为编译器可以自己推断出来
甚至可以省略var ,因为var表示定义变量,我们可以用:= 来表示同样的意义 (只能在函数内使用)
函数外部也可以定义变量,不过必须以 var 关键词 开头(也可以用 var () 这种集中定义变量的写法)
这些变量不是全局变量,而是包内部变量,作用域是整个 package
package main
import "fmt"
var a = 3
var ss = "kk"
// 简便写法
var (
c = 3
b = 12
)
func variableZeroValue(){
var a int
var s string
fmt.Println(a,s)
fmt.Printf("%d %q\n",a,s)
}
func variableInitialValue(){
var a,b int = 3,4;
var s string ="abc";
fmt.Println(a,b,s);
}
func variableTypeDeduction(){
var a,b,s = 3,4,"hello world";
fmt.Println(a,b,s);
}
func variableShorter(){
a,b,c,s := 3,4,5,"hello world";
b = 3;
fmt.Println(a,b,c,s);
}
func main(){
fmt.Println("hello world");
variableZeroValue();
variableInitialValue();
variableTypeDeduction();
variableShorter();
}## 内建变量类型
bool,string
(u)int ,(u)int8,(u)int16,(u)int32,(u)int64,uintptr U表示无符号 int之后可以指定int的bit位,否则跟着操作系统的位数走 uintptr是指针类型
byte,rune byte比特型 一个字节大小 rune 用于unicode字符,大小为32位,占个4字节
float32 float64 complex64 complex128 complex是复数的意思,有实部和虚部,complex64实部和虚部大小同为32,complex128实部和虚部大小同为64
复数类型
package main
import (
"fmt"
"math/cmplx"
)
func main() {
c := 3 + 4i
fmt.Println(cmplx.Abs(c))
}验证欧拉公式

package main
import (
"fmt"
"math/cmplx"
"math"
)
func main() {
fmt.Println(
cmplx.Exp(1i * math.Pi) + 1)
}控制台输出
(0+1.2246467991473515e-16i)为什么不是 0 ?因为complex64 的实部和虚部都是float32
##类型转换
类型转换是强制的,无隐式类型转换
勾股定理
package main
import (
"fmt"
"math"
)
func main() {
var a, b int = 3, 4
fmt.Println(math.Sqrt(float64(a*a + b*b)))
}
控制台输出
5
## 常量定义
func consts(){
//定义常量
const filename = "abc.txt"
const a,b = 3,4
// 集中定义
const (
filename2 = "123";
aa,bb = "123",true;
)
c := int(math.Sqrt(a*a + b*b))
fmt.Println(filename,c)
}const 的值 可以作为任意类型使用,例如math.Sqrt的参数需要float类型,这里const a 就可以作为const使用。
## 枚举类型(特殊的常量)
go语言中没有专门的枚举类型,直接集中定义const常量即可。
func enums(){
const (
cpp = 0;
java = 1;
python =2;
golang = 3;
)
fmt.Println(cpp,java,python,golang);
}
func main(){
enums();
}等价于:元素 iota 表示这组const 是从0开始自增值的
func enums(){
const (
cpp = iota
java
python
golang
)
fmt.Println(cpp,java,python,golang);
}iota 是可以参与运算的
func enums(){
const (
b = 1 << (10*iota) //1 * 2^10*0
kb //1 * 2^(10*1)
mb //1 * 2^ (10*2)
gb
tb
pb
)
fmt.Println(b,kb,mb,gb,tb,pb);
}控制语句:
1.条件语句
if条件中没有括号
package main
import (
"fmt"
"io/ioutil"
)
func main(){
const filename = "abc.txt"
contents,err := ioutil.ReadFile(filename)
if err != nil {
fmt.Println(err)
}else{
fmt.Printf("%s\n",contents)
}
}等价写法:
if 条件中是可以写语句的,语句中变量的作用域是 if语句 语句块作用域{ }
package main
import (
"fmt"
"io/ioutil"
)
func main(){
const filename = "abc.txt"
if contents,err := ioutil.ReadFile(filename); err != nil {
fmt.Println(err)
}else{
fmt.Printf("%s\n",contents)
}
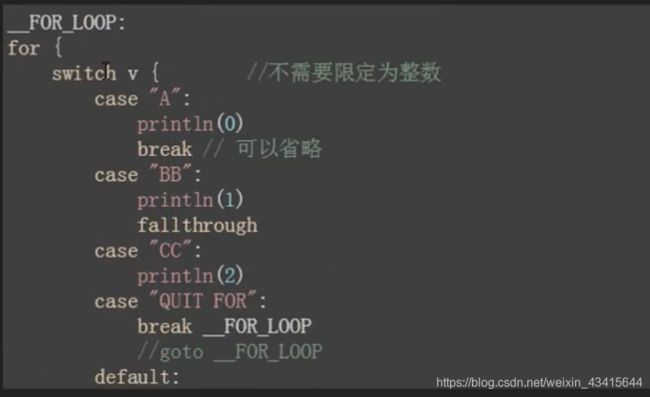
}2.分支选择语句: switch
区别:
- C语言switch(只能是整型),Go语言switch 不限定类型
- case之后自动会添加break,所以可以省略break。 除非使用fallthrough
package main
import (
"fmt"
)
func eval(a,b int,op string) int {
var result int
switch op {
case "+":
result = a+b
case "-":
result = a-b
case "*":
result = a*b
fallthrough
case "/":
result = a/b
default:
panic("unsupport operator:"+op)
}
return result
}
func main(){
result := eval(11,12,"+")
fmt.Println(result)
}panic 中断程序执行 报错
switch之后可以没有表达式 ,在条件中加入表达式即可
func grade(score int) string{
g:= ""
switch {
case score < 60:
g="F"
case score<80:
g="D"
case score<100:
g="A"
default:
panic(fmt.Sprintf("Wrong Score:%d",score))
}
return g
}3.循环语句
for 的条件中不需要有括号
for 的条件中可以省略初始条件,结束条件,递增表达式
package main
import (
"fmt"
"strconv"
)
func convertToBin(n int) string{
result :=""
for ; n>0;n/=2 {
lsb := n % 2
result = strconv.Itoa(lsb) + result
}
return result
}
func main(){
fmt.Println(convertToBin(100))
}strconv.Itoa() int转字符串,因为只有两个string类型才能拼接
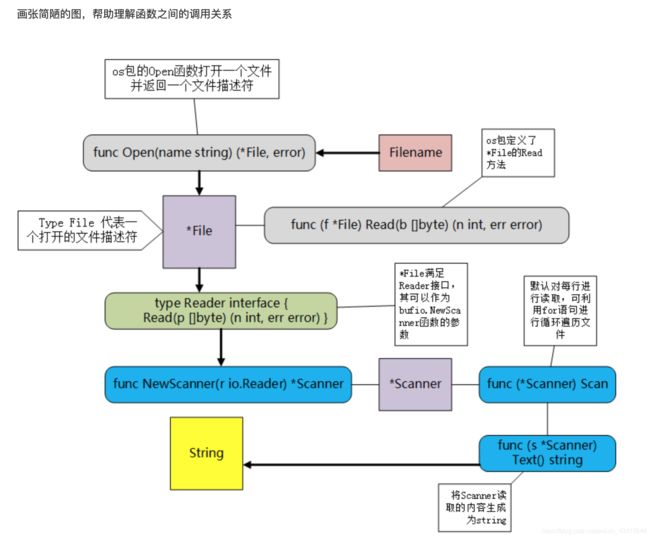
逐行读取文件:
for 省略起始条件 和 递增条件,只有结束条件时,可以直接省略分号。 go中没有while ,for省略起始条件 和递增条件 就是 while
如果起始条件、递增条件都省略了,就是一个死循环。
func printFile(filename string) {
file, err := os.Open(filename)
if err != nil {
panic(err)
}
scanner := bufio.NewScanner(file)
for scanner.Scan() {
fmt.Println(scanner.Text())
}
}
func forever() {
for {
fmt.Println("forever")
}
}
4.goto语句
函数:
函数声明:
go语言的函数可以返回多个值,并且如果多个形参的类型一样 可以集中定义类型 例如 a,b int 表示 a b都是int型
package main
import "fmt"
//带余除法 13/4 = 3 ...1
func div(a, b int) (int, int) {
return a / b, a % b
}
func main() {
fmt.Println(div(13, 4))
}不定参函数:
传入的实际上是参数数组
package main
func add(args ...int) {
var sum int
for _, v := range args {
sum += v
}
println(sum)
}
func main() {
add(1, 2, 3, 4, 5, 6, 7)
}
定义函数时还可以给返回值起名字,这样当调用函数时,编辑器会自动生成 返回值的变量名
并且定义函数时,可以直接return ,编译器自动将定义好的名字的值返回回去
如果接收时只想用其中一个返回值,可以用_来占位另一个返回值
package main
import "fmt"
//带余除法 13/4 = 3 ...1
func div(a, b int) (q, r int) {
q = a / b
r = a % b
return
}
func main() {
q, r := div(123, 11)
fmt.Println(q, r)
}
应用场景:
package main
import (
"fmt"
)
func eval(a, b int, op string) (int, error) {
switch op {
case "+":
return a + b, nil
case "-":
return a - b, nil
case "*":
return a * b, nil
case "/":
return a / b, nil
default:
return 0, fmt.Errorf("unsupport operator:%s", op)
}
}
func main() {
result, err := eval(11, 12, "123")
if err != nil {
fmt.Println(err)
} else {
fmt.Println(result)
}
}
func fmt.Errorf(format string, a ...interface{}) error
返回值是一个error类型的变量
用函数式编程改写:
package main
import (
"fmt"
"math"
)
func apply(op func(int, int) int, a, b int) int {
// p := reflect.ValueOf(op).Pointer()
// opName := runtime.FuncForPC(p).Name()
// fmt.Printf("Calling function %s with args "+"%d,%d\n", opName, a, b)
return op(a, b)
}
func pow(a, b int) int {
return int(math.Pow(float64(a), float64(b)))
}
func main() {
fmt.Println(apply(pow, 2, 3))
}
还可以直接将一个匿名函数定义写在实参的位置
package main
import (
"fmt"
"math"
)
func apply(op func(int, int) int, a, b int) int {
return op(a, b)
}
func main() {
fmt.Println(apply(func(a, b int) int {
return int(math.Pow(float64(a), float64(b)))
}, 2, 3))
}默认参数、可选参数、函数重载 这些花哨的东西,go语言都没有
go语言唯一有的就是一个 可变参数列表
package main
import (
"fmt"
)
func sum(numbers ...int) int {
s := 0
for i := range numbers {
s += numbers[i]
}
return s
}
func main() {
fmt.Println(sum(1, 2, 3, 4, 5))
}
## 指针
go语言的指针不能运算
*int 指向 int类型的指针
package main
import (
"fmt"
)
func main() {
var a int = 2
var pa *int = &a
*pa = 3
fmt.Println(a)
}##参数传递
值传递:形参是实参的副本
引用传递:形参是实参的别名
go语言只有值传递一种方式,go语言通过指针的值传递 来实现 引用传递的效果
func swap(a, b *int) {
*a, *b = *b, *a
}
func main() {
a := 3
b := 4
swap(&a, &b)
fmt.Println(a, b)
}
另一种实现方式
func swap(a, b int) (int, int) {
return b, a
}
func main() {
a := 3
b := 4
a, b = swap(a, b)
fmt.Println(a, b)
}数组
#定义数组的方法:
func main() {
var arr1 [5]int
arr2 := [3]int{1, 3, 5}
arr3 := [...]int{2, 4, 5, 12312, 32131, 32}
fmt.Println(arr1, arr2, arr3)
var grid [4][5]int
fmt.Println(grid)
}数量写在类型的前面
[3]int 指明有3个int
[...]int 表示让编译器替我们数有多少个int
[4][5]int 表示4个长度为5的int数组
#数组的遍历:
键值循环:
range 关键字可以 获取到 数组元素的索引 和 值,可以通过_ 来省略变量
func main() {
arr3 := [...]int{2, 4, 5, 12312, 32131, 32}
for i := 0; i < len(arr3); i++ {
fmt.Println(arr3[i])
}
for i, v := range arr3 {
fmt.Println(arr3[i], v)
}
}数组是值类型
调用 func f(arr [10]int ) 会拷贝数组
func printArr(arr [5]int) {
arr[0] = 100
for i, v := range arr {
fmt.Println(i, v)
}
}
func main() {
arr3 := [...]int{2, 4, 5, 12312, 32131}
printArr(arr3)
fmt.Println(arr3)
}指向数组的指针
func printArr(arr *[5]int) {
arr[0] = 100
for i, v := range arr {
fmt.Println(i, v)
}
}
func main() {
arr3 := [...]int{2, 4, 5, 12312, 32131}
printArr(&arr3)
fmt.Println(arr3)
}go语言一般不直接使用数组,更常用的是切片
切片 Slice
slice 本身是没有数据的,是对底层array 的一个view (视图),本质上是个结构体
注意:
数组和切片形式上的区别:数组 [有数字或者点]类型 ,切片 []类型 方括号中没有数字就表示
如果函数的形参是array类型,那么实际传给函数的只是实参的拷贝值。所以在函数中修改该数组的副本并不会修改函数外的原数组
但是如果函数的形参是slice 类型,那么传递给函数的也只是slice的拷贝值,不过即便是拷贝值,这个拷贝值中数组指针仍然指向原数组,所以在函数中改变slice中元素的值,对应array中元素的值也会改变,array的其他slice视图中该元素的值也会改变。
slice结构:
type slice struct {
array unsafe.Pointer //数组指针
len int
cap int
}- len 是用来限制 切片索引的,例如 s 是一个切片,len 是6 ,那么s[i] ,i 不能超过 len
- cap 是切片中数组指针指向的底层数组的大小,
- append(s,xxx) 每向切片中追加一个值,其实是在向底层数组中追加值,切片的成员变量len会++
- 当len > cap 时,就会重新开一个容量更大的数组,将原来的数组拷贝过去,并更新切片的cap值
编程实践:
func updateSlice(s []int) { //s 是切片类型而不是数组类型
s[0] = 100
}
func main() {
arr := [...]int{0, 1, 2, 3, 4, 5, 6, 7} //数组
//前闭后开区间 [2 3 4 5]
fmt.Println(arr[2:6]) //切片
fmt.Println(arr[:6])
fmt.Println(arr[2:])
s2 := arr[:3] //切片
s1 := arr[:] //切片
fmt.Println(s1)
updateSlice(s1)
fmt.Println(s1)
fmt.Println(arr)
fmt.Println(s2)
}运行结果:
[2 3 4 5]
[0 1 2 3 4 5]
[2 3 4 5 6 7]
[0 1 2 3 4 5 6 7]
[100 1 2 3 4 5 6 7]
[100 1 2 3 4 5 6 7]
[100 1 2]## Reslice(对底层数组重新切片)
reslice:对切片再进行切片。本质就是对底层数组进行重新切片。
因为切片本质上是一个结构体,里面存了底层数组的指针,切片长度,底层数组的大小。所以将一个切片再进行切片,其实就是将底层数组的指针和cap拷贝了一份,将len改了改,改了改对底层数组的起始和结束,并且切片的起始和结束 在范围上不能超过底层数组的范围。
例如:
func main() {
arr := [...]int{0, 1, 2, 3, 4, 5, 6, 7}
s2 := arr[:3]
s1 := s2[2:5]
fmt.Println(s2)
fmt.Println(s1)
}[0 1 2]
[2 3 4]demo2:
s1 := s2[2:5]
fmt.Printf("s1=%v,len(s1)=%d,cap(s1)=%d\n", s1, len(s1), cap(s1))s1=[2 3 4],len(s1)=3,cap(s1)=6##向Slice添加元素
- append(s,xxx) 每向切片中追加一个值,本质上是在向底层数组中追加值,切片的成员变量len会++
- 当len > cap 时,就会重新开一个容量更大的数组,将原来的数组拷贝过去,并更新切片的cap值
func main() {
arr := [...]int{0, 1, 2, 3, 4}
s1 := arr[:3]
fmt.Printf("s1=%v,len(s1)=%d,cap(s1)=%d\n", s1, len(s1), cap(s1))
s3 := append(s1, 10)
s4 := append(s3, 11)
s5 := append(s4, 12)
fmt.Printf("s3=%v s4=%v s5=%v", s3, s4, s5)
fmt.Println(arr)
}结果:
s1=[0 1 2],len(s1)=3,cap(s1)=5
s3=[0 1 2 10] s4=[0 1 2 10 11] s5=[0 1 2 10 11 12][0 1 2 10 11]## Slice的操作
#创建slice的三种方法
#拷贝slice:copy(切片1,切片2)
将切片2 中的数据 赋值到 切片1中去。常用于切片1的底层数组比较大,切片2的底层数组比较小,将切片的2中数据拷贝到切片1的底层数组中。
package main
import (
"fmt"
)
//1.不同类型的切片无法复制
//2.如果s1的长度大于s2的长度,将s2中对应位置上的值替换s1中对应位置的值
//3.如果s1的长度小于s2的长度,多余的将不做替换
func main() {
s1 := []int{1, 2, 3}
s2 := []int{4, 5}
s3 := []int{6, 7, 8, 9}
copy(s1, s2)
fmt.Println(s1) //[4 5 3]
copy(s2, s3)
fmt.Println(s2) //[6 7]
}#删除切片中元素
#对切片进行 头pop
#对切片进行 尾pop
package main
import (
"fmt"
)
func printSlice(s []int) {
fmt.Printf("%v len=%d,cap=%d\n", s, len(s), cap(s))
}
func main() {
//创建方法1 向其中追加数据时,会自动调整 len 和 cap
var s []int //Zero value for slice is nil
for i := 0; i < 100; i++ {
printSlice(s)
s = append(s, 2*i+1)
}
fmt.Println(s)
//创建方法2
s1 := []int{2, 4, 6, 8}
printSlice(s1)
//创建方法3 指定 len 和 cap
s2 := make([]int, 16)
s3 := make([]int, 10, 32)
printSlice(s2)
printSlice(s3)
//Copying Slice
copy(s2, s1)
printSlice(s2) //[2 4 6 8 0 0 0 0 0 0 0 0 0 0 0 0]
fmt.Println("Deleting elements from slice")
s2 = append(s2[:3], s2[4:]...) //...表示展开
printSlice(s2)
fmt.Println("Popping from front")
front := s2[0]
s2 = s2[1:]
fmt.Println(front, s2)
fmt.Println("Popping from back")
tail := s2[len(s2)-1]
s2 = s2[:len(s2)-1]
fmt.Println(s2, tail)
}
#将一个切片追加到另一个切片
内置函数 append() 也是一个可变参数的函数。这意味着可以在一次调用中传递多个值。如果使用 … 运算符,可以将一个切片的所有元素追加到另一个切片里:
// 创建两个切片,并分别用两个整数进行初始化
num1 := []int{1, 2}
num2 := []int{3, 4}
// 将两个切片追加在一起,并显示结果
fmt.Printf("%v\n", append(num1, num2...))输出的结果为:
[1 2 3 4]
在返回的新的切片中,切片 num2 里的所有值都追加到了切片 num1 中的元素后面。
make 与 new
首先,make和new 都是在开堆内存
new(类型) 在堆上开辟相应大小的内存,然后返回该实例的指针
make(类型[,...]) 在堆上开辟相应大小的内存,直接返回该实例, 专用于给map、slice、channel类型 开辟堆内存
用法实例:
var slice_ []int = make([]int,5,10)
fmt.Println(slice_)
var slice_1 []int = make([]int,5)
fmt.Println(slice_1)
var m_ map[string]int = make(map[string]int)以下两种写法等价:
make([]int, 50, 100)
new([100]int)[0:50]make给slice开内存时,底层数组的长度可以省略
例如:make([][]int,5) 这样的二维数组,我们需要分两次指定开内存。
先告诉编译器我们需要多少行
然后告诉编译器每行需要多少个元素,
让编译器自己去算需要开多大空间
maze := make([][]int, row) //第二个参数指定view的长度,第三个长度指定底层数组的长度(可省略)
for i := range maze {
maze[i] = make([]int, col)
}#Map 关联数组/字典/映射
map的声明方式:
第一种:开栈内存 map[xxx]xxx = {"xxx":"xxx","xxx":"xxxx"}的形式
第二种:开堆内存 xxx := make(map[xxx]xxx)
注:
- 方括号中写key的类型,后面写value的类型
- 因为map 本身是无序的,所以遍历map不能保证顺序,如果需要顺序,需要手动对key排序
/*
* @Author: your name
* @Date: 2020-10-11 23:09:31
* @LastEditTime: 2020-10-11 23:54:07
* @LastEditors: Please set LastEditors
* @Description: In User Settings Edit
* @FilePath: /learngo/map.go
*/
package main
import "fmt"
func main() {
//定义方式1
m := map[string]string{
"name": "shang",
"course": "mooc",
}
fmt.Println(m)
//定义方式2
m2 := map[string]int{} //m2 == empty map
//定义方式3
var m3 map[string]int //m3 == nil go语言中的nil不同于其他语言中的null go中nil是可以参与运算的
fmt.Println(m2)
fmt.Println(m3)
fmt.Println("遍历map")
for k, v := range m {
fmt.Println(k, v) //输出结果是无序的
}
//map的操作
//查询元素
fmt.Println("Getting values")
username := m["name"]
course := m["courseeeee"] //当去取map中的一个不存在的键值时,还是可以取到值的,只不过这个值是一个空串
fmt.Println(username, course)
password, ok := m["password"] //当key存在时,ok为true,不存在时,ok为false
username, okk := m["name"]
fmt.Println(username, okk)
fmt.Println(password, ok)
if password, ok = m["password"]; ok {
fmt.Println(password, ok)
} else {
fmt.Println("key does not exist")
}
//删除元素
fmt.Println("Deleting values")
delete(m, "name")
fmt.Println(m)
}
map中的key :
map使用哈希表,key必须可以比较相等
除了slice、map、function 之外的内建类型都可以作为key
struct 类型中只要不包含 slice/map/function 也可以作为key
判断key是否存在:
package main
func main() {
user := map[string]string{
"username": "xiaoming",
"password": "123456",
// "token": "1dsafaQEWDAadad",
}
token, exist := user["token"]
if exist {
println(token)
} else {
println("非法用户")
}
}
例题:寻找最长的不含有重复字符的子串 pwwwke->wke
/*
* @Author: your name
* @Date: 2020-10-12 08:13:05
* @LastEditTime: 2020-10-12 08:46:18
* @LastEditors: Please set LastEditors
* @Description: In User Settings Edit
* @FilePath: /learngo/search.go
*/
package main
import "fmt"
// 对于同一个字母x,我们让start始终指向目前不含重复字母的串的首位置,然后寻找lastOccurredp[x]
// lastOccurred[x]不存在,或者小于start , 无需操作
// lastOccurred[x]>=start,则更新start,指向lastOccurred+1 这个位置
// 更新lastOccurred[x] 更新maxLength
func lengthOfNonRepeatingSubStr(s string) int {
lastOccurred := make(map[byte]int)
start := 0
maxLength := 0
for i, ch := range []byte(s) {
//当该字符串出现过 => 重复出现了 且如果 以前出现的下标 比 start 大时,start后移一位
if lastI, ok := lastOccurred[ch]; ok && lastI >= start {
start = lastI + 1
}
if i-start+1 > maxLength {
maxLength = i - start + 1
}
lastOccurred[ch] = i
}
return maxLength
}
func main() {
fmt.Println(lengthOfNonRepeatingSubStr("aaaabcccc"))
fmt.Println(lengthOfNonRepeatingSubStr("bbbbb"))
fmt.Println(lengthOfNonRepeatingSubStr("pwwkew"))
}
但是现在还不能处理中文,如何才能支持多语言呢?
#字符和字符串的处理
/*
* @Author: your name
* @Date: 2020-10-12 09:04:49
* @LastEditTime: 2020-10-12 10:00:44
* @LastEditors: Please set LastEditors
* @Description: In User Settings Edit
* @FilePath: /learngo/string.go
*/
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "Yes我爱西电!" //go 语言用3个字节表示一个中文(utf-8编码) 英文一个字节,即utf-8采用可变长编码,英文和中文的字节数是不同的
fmt.Println(len(s)) //16
fmt.Println([]byte(s))
for _, b := range []byte(s) {
fmt.Printf("0x%X ", b)
}
fmt.Println()
for i, ch := range s { //ch is a rune 其实就是int32的别名
fmt.Printf("(%d %X)", i, ch)
}
fmt.Println()
//获取真正的的字符数量得用utf8.RuneCountInString,len获得的只是字节数量
fmt.Println("Rune count:",
utf8.RuneCountInString(s))
//获取所有的字节
bytes := []byte(s)
for len(bytes) > 0 {
ch, size := utf8.DecodeRune(bytes)
bytes = bytes[size:]
fmt.Printf("%c ", ch)
}
fmt.Println()
for i, ch := range []rune(s) {
fmt.Printf("(%d %c) ", i, ch)
}
fmt.Println()
}
国际版
/*
* @Author: your name
* @Date: 2020-10-12 08:13:05
* @LastEditTime: 2020-10-12 10:04:20
* @LastEditors: Please set LastEditors
* @Description: In User Settings Edit
* @FilePath: /learngo/search.go
*/
package main
import "fmt"
// 对于同一个字母x,我们让start始终指向目前不含重复字母的串的首位置,然后寻找lastOccurredp[x]
// lastOccurred[x]不存在,或者小于start , 无需操作
// lastOccurred[x]>=start,则更新start,指向lastOccurred+1 这个位置
// 更新lastOccurred[x] 更新maxLength
func lengthOfNonRepeatingSubStr(s string) int {
lastOccurred := make(map[rune]int)
start := 0
maxLength := 0
for i, ch := range []rune(s) {
//当该字符串出现过 => 重复出现了 且如果 以前出现的下标 比 start 大时,start后移一位
if lastI, ok := lastOccurred[ch]; ok && lastI >= start {
start = lastI + 1
}
if i-start+1 > maxLength {
maxLength = i - start + 1
}
lastOccurred[ch] = i
}
return maxLength
}
func main() {
fmt.Println(lengthOfNonRepeatingSubStr("aaaabcccc"))
fmt.Println(lengthOfNonRepeatingSubStr("bbbbb"))
fmt.Println(lengthOfNonRepeatingSubStr("pwwkew"))
fmt.Println(lengthOfNonRepeatingSubStr("小小明123"))
}
结构体:
go语言的面向对象仅支持封装,不支持继承和多态。我们不需要继承和多态,继承和多态所做的工作 go用接口来做
不论是 指针 还是 结构的实例 ,一律用 . 来访问成员
package main
import "fmt"
type treeNode struct {
value int
left, right *treeNode
}
//结构的成员函数 是写在结构外边的。且函数名前 有一个接受者 来指明这个方法 属于 谁,接受者实际上和普通的参数没有本质上的区别,只是写在了前面而已
func (node treeNode) print() {
fmt.Println(node.value)
}
//(值接受者) 注意 go语言所有的传递都是 值传递,所以下面这种方法并不能修改掉value
func (node treeNode) fakeSetValue(value int) {
node.value = value
}
//(指针接受者) 使用指针来作为接受者 node的值可以为nil
func (node *treeNode) setValue(value int) {
if node == nil {
fmt.Println("setting value to nil")
return
}
node.value = value
}
// 小结:值接受者是go特有的,值/指针接受者 均可接受值或者指针,并不能限制调用的人如何调用
//中序遍历该树 左中右
func (node *treeNode) traverse() {
if node == nil {
return
}
node.left.traverse() //众所周知 C++ 中 如果node.left == null 是不能 node.left->traverse的,但是go语言中却可以
node.print()
node.right.traverse()
}
//自定义工厂函数
func createNode(value int) *treeNode {
return &treeNode{value: value} //这里返回了局部变量的地址给外边,这种做法在C++会崩掉,但是在go语言中却是正确的
/*
这是因为C++中局部变量 是和其所在函数一起被分配在栈上的,当函数结束的时候,函数出栈,函数的局部变量也就被销毁了
所以想要在函数体中传递有效的变量地址给外边,必须在堆上new出来一块内存。
go 语言中的 局部变量 到底是分配在 栈上还是堆上呢?其实都有可能,当编译器看到 一个局部变量的地址被返回的时候,就会在堆上分配内存(然后参与垃圾回收)
如果没有返回,就会在栈上分配内存
*/
}
func main() {
var root treeNode
fmt.Println(root) //{0 }
root = treeNode{value: 3}
root.left = &treeNode{}
root.right = &treeNode{5, nil, nil}
root.right.left = new(treeNode) //new是一个内建函数,返回treeNode的地址
nodes := []treeNode{
{value: 3},
{},
{6, nil, nil},
}
fmt.Println(nodes)
root.right.right = createNode(100)
root.fakeSetValue(11)
root.print()
root.setValue(12)
root.print()
//证明 nil 同样可以调用成员函数
var pRoot *treeNode
pRoot.setValue(123)
//中序遍历该树
fmt.Println("中序遍历", root)
root.traverse()
}
封装
名字一般用CamelCase
首字母大写 表示 public,首字母小写表示private
public 和private是针对包来说的
每个目录下只能有一个包,main包包含了可执行入口
为结构定义的方法必须放在同一个包内
可以是不同的文件
除此之外,在文件包含的时候,一个包的中的大写字母开头的函数和变量是包级别的公有变量
而小写字母开头的函数和变量是包级别的私有变量
实例:将之前的treeNode 封装
目录结构:

entry/entry.go
/*
* @Author: your name
* @Date: 2020-10-12 15:25:08
* @LastEditTime: 2020-10-12 18:32:31
* @LastEditors: Please set LastEditors
* @Description: In User Settings Edit
* @FilePath: /learngo/tree/entry/entry.go
*/
package main
import (
"fmt"
"learngo/tree"
)
func main() {
var root tree.TreeNode
fmt.Println(root) //{0 }
root = tree.TreeNode{Value: 3}
root.Left = &tree.TreeNode{}
root.Right = &tree.TreeNode{5, nil, nil}
root.Right.Left = new(tree.TreeNode) //new是一个内建函数,返回TreeNode的地址
nodes := []tree.TreeNode{
{Value: 3},
{},
{6, nil, nil},
}
fmt.Println(nodes)
root.Right.Right = tree.CreateNode(100)
root.FakeSetValue(11)
root.Print()
root.SetValue(12)
root.Print()
//证明 nil 同样可以调用成员函数
var pRoot *tree.TreeNode
pRoot.SetValue(123)
//中序遍历该树
fmt.Println("中序遍历", root)
root.Traverse()
}
tree/node.go
/*
* @Author: your name
* @Date: 2020-10-12 10:19:28
* @LastEditTime: 2020-10-12 18:28:55
* @LastEditors: Please set LastEditors
* @Description: In User Settings Edit
* @FilePath: /learngo/tree/node.go
*/
package tree
import "fmt"
type TreeNode struct {
Value int
Left, Right *TreeNode
}
//结构的成员函数 是写在结构外边的。且函数名前 有一个接受者 来指明这个方法 属于 谁,接受者实际上和普通的参数没有本质上的区别,只是写在了前面而已
func (node TreeNode) Print() {
fmt.Println(node.Value)
}
//(值接受者) 注意 go语言所有的传递都是 值传递,所以下面这种方法并不能修改掉value
func (node TreeNode) FakeSetValue(value int) {
node.Value = value
}
//(指针接受者) 使用指针来作为接受者 node的值可以为nil
func (node *TreeNode) SetValue(value int) {
if node == nil {
fmt.Println("setting value to nil")
return
}
node.Value = value
}
// 小结:值接受者是go特有的,值/指针接受者 均可接受值或者指针,并不能限制调用的人如何调用
//自定义工厂函数
func CreateNode(value int) *TreeNode {
return &TreeNode{Value: value} //这里返回了局部变量的地址给外边,这种做法在C++会崩掉,但是在go语言中却是正确的
/*
这是因为C++中局部变量 是和其所在函数一起被分配在栈上的,当函数结束的时候,函数出栈,函数的局部变量也就被销毁了
所以想要在函数体中传递有效的变量地址给外边,必须在堆上new出来一块内存。
go 语言中的 局部变量 到底是分配在 栈上还是堆上呢?其实都有可能,当编译器看到 一个局部变量的地址被返回的时候,就会在堆上分配内存(然后参与垃圾回收)
如果没有返回,就会在栈上分配内存
*/
}
tree/traversal.go
/*
* @Author: your name
* @Date: 2020-10-12 18:41:41
* @LastEditTime: 2020-10-12 18:43:53
* @LastEditors: Please set LastEditors
* @Description: In User Settings Edit
* @FilePath: /learngo/tree/traversal.go
*/
package tree
//一个结构不同的方法可以分散在不同的文件中
//中序遍历该树 左中右
func (node *TreeNode) Traverse() {
if node == nil {
return
}
node.Left.Traverse() //众所周知 C++ 中 如果node.left == null 是不能 node.left->Traverse的,但是go语言中却可以
node.Print()
node.Right.Traverse()
}
扩展已有类型
为结构定义的方法 可以放在不同的 文件之中,但是必须放在 同一个包内, 即文件开头的 package xxx 必须相同
如何扩充系统类型 或者 别人的类型:
定义别名

queue/queue.go 扩展系统类型
package queue
type Queue []int
//不论是不是结构体类型,都可以有成员函数,这就是个写法问题,func (参数)函数名 ,参数写写在前面
//就用 参数.函数名 调用函数,参数写在 函数名后面 func 函数名(参数) ,就通过 函数名(参数)调用
func (q *Queue) Push(v int) {
*q = append(*q, v)
}
func (q *Queue) Pop() int {
head := (*q)[0]
*q = (*q)[1:]
return head
}
func (q *Queue) IsEmpty() bool {
return len(*q) == 0
}
entry/entry.go
package main
import (
"fmt"
"learngo/queue"
)
func main() {
q := queue.Queue{1}
q.Push(123)
q.Push(23)
fmt.Println(q.Pop())
fmt.Println(q.Pop())
fmt.Println(q.IsEmpty())
fmt.Println(q.Pop())
fmt.Println(q.IsEmpty())
}