【微服务】springboot整合kafka-stream使用详解
目录
一、前言
二、kafka stream概述
2.1 什么是kafka stream
2.2 为什么需要kafka stream
2.2.1 对接成本低
2.2.2 节省资源
2.2.3 使用简单
2.3 kafka stream特点
2.4 kafka stream中的一些概念
2.5 Kafka Stream应用场景
三、环境准备
3.1 搭建zk
3.1.1 自定义docker网络
3.1.2 拉取zk镜像
3.1.3 启动zk容器
3.2 搭建kafka
3.2.1 下载kafka并解压
3.2.2 修改配置文件
3.2.3 启动kafka服务
3.3 kafka测试
3.3.1 创建topic
3.3.2 开启kafka生产端控制台
3.3.3 开启kafka消费端控制台
3.4 java客户端集成kafka测试
四、kafka stream 使用
4.1 前置准备
4.2 kafka stream应用开发步骤
4.2.1 步骤1:创建Kafka Streams 实例
4.2.2 步骤2:指定输入与输出topic
4.2.3 步骤3:启动Kafka Streams 实例
4.3 kafka stream操作案例
4.3.1 转换单词大小写
4.3.2 将topic1数据写入到topic2中
4.3.3 统计wordcount
4.4 kafka stream窗口函数使用
4.4.1 需求一,固定时间输出统计结果到另一个topic
4.4.2 需求二,统计topic1中10秒内的wordcount写到topic2
4.5 Kafka Streams使用场景拓展
4.5.1 事件日志监控
4.5.2 事用户行为统计分析
4.5.3 数据聚合与实时计算
4.5.4 实时推荐
4.5.5 实时告警
4.5.6 应用解耦
五、kafka stream整合springboot
5.1 整合过程
5.1.1 导入springboot相关依赖
5.1.2 配置kafka相关信息
5.1.3 添加Kafka Stream配置类
5.1.4 自定义Kafka Stream业务处理监听器
5.1.5 效果测试
六、写在文末
一、前言
随着大数据技术的发展越来越成熟,大数据涉及的领域也越来越多,从以往的T+1到如今的实时处理,得益于底层技术的强大支撑,尤其是流式计算技术的发展让众多的业务场景价值得以深度挖掘,聊到流式计算,涌入入脑海中的Spark Streaming,Flink等,本文接下来将介绍另一种流式计算技术kafka stream。
二、kafka stream概述
2.1 什么是kafka stream
Kafka Stream是一款开源、分布式和水平扩展的流处理平台,其在Apache Kafka之上进行构建,借助其高性能、可伸缩性和容错性,可以实现高效的流处理应用程序。
2.2 为什么需要kafka stream
在处理流式计算的场景中,发展到今天出现了很多成熟的性能高效的技术框架,比如老牌的Apache Storm,大数据处理框架Spark Streaming,Flink等,而且像Spark 与flink都能与SQL紧密结合,集成便捷,功能也很强大,为何还需要kafka stream呢?
2.2.1 对接成本低
kafka可以说在很多互联网公司都有着广泛的使用,只要维护了kafka的环境,即可集成和使用kafka stream。
2.2.2 节省资源
相比于部署spark,storm等这样的大数据处理框架需要的计算资源,部署kafka占用的服务器资源更少,而且维护起来也相对节省人力。
2.2.3 使用简单
相比与spark和flink这样的大数据框架,kafka在日常的开发中接触和使用会更多,学习和上手成本会低很多。
2.3 kafka stream特点
Kafka Stream是Apache Kafka从0.10版本引入的一个新Feature。它是提供了对存储于Kafka内的数据进行流式处理和分析的功能。具有如下特点:
-
Kafka Stream提供了一个非常简单而轻量的Library,可以方便的嵌入任意Java应用中,也可以任意方式打包和部署;
-
充分利用Kafka分区机制实现水平扩展和顺序性保证;
-
提供记录级的处理能力,从而实现毫秒级的低延迟;
-
支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records),这点与spark和flink中的时间窗口处理机制很像;
-
提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce);
-
通过可容错的state store实现高效的状态操作(如windowed join和aggregation);
-
除了Kafka外,无任何外部依赖,且支持正好一次处理语义;
2.4 kafka stream中的一些概念
在kafka stream中,KStream和KTable是理解kafka stream时非常核心的两个概念。
KStream
KStream是一个数据流,是一段顺序的、可以无限长、不断更新的数据集,可以认为所有的记录都通过Insert only的方式插入进这个数据流中。
KTable
KTable代表一个完整的数据集,可对照mysql理解为数据库中的表。每条记录都有KV键值对,key可理解为数据库中的主键,是唯一的,而value代表一条记录,记录通常是一段可序列化的字符串。可以认为KTable中的数据时通过Update only的方式进入的。如果是相同的key,会覆盖掉原来那条记录。
综上来说:
-
KStream是数据流,即不断传输过来的流式数据记录,以Insert only的方式不断插入;
-
KTable是数据集(逻辑概念),相同key的数据只保留最新的记录,也就是Update only;
2.5 Kafka Stream应用场景
Kafka Streams主要用于以下应用场景:
- 实时数据处理,通过实时流计算,对数据进行快速分析和处理,或者处理之后转交下游应用;
- 流式ETL,将数据从一个数据源抽取到另一个数据源,或将数据进行转换、清洗和聚合操作;
- 流-表格Join:将一条流数据与一个表进行关联查询,实现实时查询和联合分析;
- 行为数据统计分析与推荐,在电商场景中,通过接收用户行为日志数据进行分析计算从而为用户推荐提供数据支撑;
三、环境准备
在开始使用kafka stream之前,先快速搭建起kafka的环境,参照下面的步骤快速部署kafka的环境。
3.1 搭建zk
3.1.1 自定义docker网络
docker network create zk-kafka --driver bridge3.1.2 拉取zk镜像
docker pull zookeeper:3.8.13.1.3 启动zk容器
docker run -d --name zk-server -p 2181:2181 --network zk-kafka -e ALLOW_ANONYMOUS_LOGIN=yes zookeeper:3.8.1 
3.2 搭建kafka
3.2.1 下载kafka并解压
下载地址:Apache Kafka,这里我使用 kafka_2.12-3.1.1.tgz
tar -zxvf kafka_2.12-3.1.1.tgz
cd kafka_2.12-3.1.1
mkdir logs![]()
3.2.2 修改配置文件
进到config目录下,找到server.properties配置文件,主要修改下面几个核心配置即可(覆盖原有的默认的配置参数)
broker.id=0
listeners=PLAINTEXT://云服务器内网IP:9092
zookeeper.connect=内外网均可,如果不对外暴露使用内网IP:2181
log.dirs=/usr/local/kafka/kafka_2.12-3.1.1/logs
advertised.listeners=PLAINTEXT://外网IP:9092
参数说明:
- listeners=PLAINTEXT://云服务器内网ip:9092,如果是云服务器,一定要配置成内网IP;
- advertised.listeners=PLAINTEXT://云服务器公网ip:9092,若要远程访问需配置此项为云服务器的公网ip;
3.2.3 启动kafka服务
在主目录下,使用下面的命令启动kafka服务前台启动
./bin/kafka-server-start.sh ./config/server.properties或者使用下面的命令后台启动
./bin/kafka-server-start.sh -daemon ./config/server.properties
3.3 kafka测试
kafka服务启动之后,接下来创建一个测试用的topic并测试是否能够正常生产和消费消息
3.3.1 创建topic
使用下面的命令创建一个名为zcy的topic
bin/kafka-topics.sh --create --topic zcy --bootstrap-server 公网IP:9092![]()
3.3.2 开启kafka生产端控制台
使用下面的命令,开启一个生产者的控制台窗口,并发送一条消息
bin/kafka-console-producer.sh --broker-list 公网IP:9092 --topic zcy![]()
3.3.3 开启kafka消费端控制台
使用下面的命令,开启一个消费端的控制台窗口,检查是否能够正常消费消息
bin/kafka-console-consumer.sh --bootstrap-server 公网IP:9092 --topic zcy
或者
bin/kafka-console-consumer.sh --bootstrap-server 公网IP:9092 --topic zcy --from-beginning
3.4 java客户端集成kafka测试
引入kafka的客户端依赖
org.apache.kafka
kafka-clients
编写如下的测试代码,向上述kafka的zcy这个topic中发送一条消息
public static void main(String[] args) throws Exception {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "公网IP:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
// 3. 创建 kafka 生产者对象
KafkaProducer kafkaProducer = new KafkaProducer(properties);
System.out.println("开始发送数据");
// 4. 调用 send 方法,发送消息
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("zcy","congge " + i));
}
// 5. 关闭资源
kafkaProducer.close();
} 运行上面的代码,运行成功后,可以看到上面的kafka的消费端的控制台正确接收到了5条消息


四、kafka stream 使用
介绍了kafka stream的相关概念之后,接下来通过一些案例感受下如何使用
4.1 前置准备
创建一个maven工程,引入如下依赖
org.springframework.boot
spring-boot-starter-parent
2.3.4.RELEASE
org.springframework.boot
spring-boot-starter-web
org.springframework.kafka
spring-kafka
org.apache.kafka
kafka-clients
org.apache.kafka
kafka-clients
com.alibaba
fastjson
org.apache.kafka
kafka-streams
connect-json
org.apache.kafka
org.apache.kafka
kafka-clients
再创建另一个topic
bin/kafka-console-consumer.sh --bootstrap-server IP:9092 --topic zcy-out4.2 kafka stream应用开发步骤
使用kafka stream进行应用的业务开发,即相关的API使用,按照下面几步操作:
4.2.1 步骤1:创建Kafka Streams 实例
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "定义本次实例名称,保持全局唯一");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka连接IP地址:9092");
//... 更多其他的属性可以点击到StreamsConfig配置类进行查看
StreamsBuilder builder = new StreamsBuilder();
KafkaStreams streams = new KafkaStreams(builder.build(), props);参数说明:
-
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-stream")指定本次流处理应用的唯一标识符; -
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092")指定连接的 Kafka 集群的地址; -
StreamsBuilder builder = new StreamsBuilder()创建 StreamsBuilder 实例,并用其构建 TOPOLOGY;
4.2.2 步骤2:指定输入与输出topic
final String inputTopic = "topic-input";
final String outputTopic = "topic-output";
KStream inputStream = builder.stream(inputTopic);
//从input-topic中拿到数据进行逻辑处理
KStream outputStream = inputStream.mapValues(value -> value.toUpperCase());
//将处理后的数据输出到其他的topic中
outputStream.to(outputTopic); 4.2.3 步骤3:启动Kafka Streams 实例
streams.start();以上几步可以说是Kafka Streams编程的一种固定的方法模板,需重点关注。
4.3 kafka stream操作案例
4.3.1 转换单词大小写
业务场景如下,从topic1中接收到消息,将消息内容转换为大写之后,输出到topic2
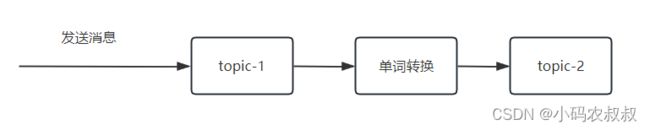
完整的代码如下:
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "stream-convert-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "IP:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream inputStream = builder.stream("zcy");
KStream outputStream = inputStream
.mapValues(value -> value.toUpperCase());
outputStream.to("zcy-out", Produced.with(Serdes.String(), Serdes.String()));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
} 运行代码之前,我们将zcy-out这个topic的消费端的终端打开,便于看到程序中处理之后的结果
![]()
运行上面的程序,通过观察控制台日志可以发现当前处于等待接收消息输入的状态
由于之前zcy这个topic中已经有消息了,可以看到,经过程序的处理,窗口中能够获取到之前的消息,并且已经将消息转为大写了

此时通过生产端的控制台发送一条消息,然后再在zcy-out消息控制台中就能近乎实时看到被转换后的消息了

注意:如果实际业务中想适当节省计算资源,即不需要实时计算,而是间隔计算之后提交结果,可以通过设置下面的这个参数,即3秒提交一次结果
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,3000); //提交时间设置为3秒4.3.2 将topic1数据写入到topic2中
业务场景如下,topic1接收外部消息,然后转发到topic2中
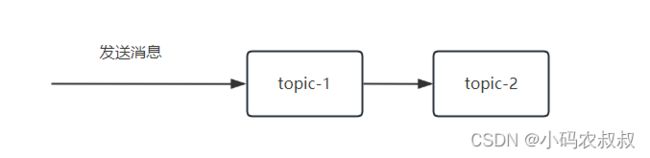
实际开发中,可能需要将原始的消息经过简单的处理之后发到另一个topic中,以供后面的业务使用,可以考虑使用下面这种方式
public class StreamCopy {
public static void main(String[] args) {
Properties prop =new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"copy-stream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"IP:9092");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,3000);
StreamsBuilder builder = new StreamsBuilder();
KStream inputStream = builder.stream("zcy");
inputStream.to("zcy-out", Produced.with(Serdes.String(), Serdes.String()));
KafkaStreams streams = new KafkaStreams(builder.build(), prop);
streams.start();
}
} 运行代码之后,仍然采用上面的方式做测试,在zcy的生产者窗口发送一条消息,可以看到zcy-out
中接收到相同的消息

4.3.3 统计wordcount
需求场景如下,通过kafka stream将第一个topic中接收到的消息经过计算之后输出到topic2中
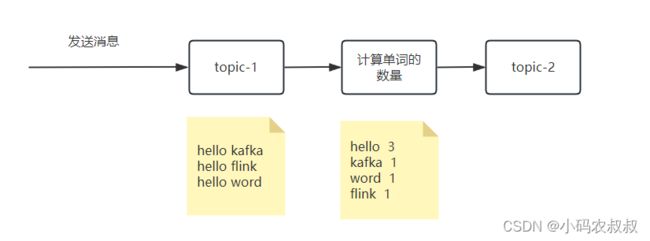
完整代码如下
public class KafkaStreamWordCount {
public static void main(String[] args) {
//kafka的配置
Properties prop = new Properties();
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "IP:9092");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-count");
StreamsBuilder streamsBuilder = new StreamsBuilder();
KStream stream = streamsBuilder.stream("zcy");
stream.flatMapValues(new ValueMapper>() {
@Override
public Iterable apply(String value) {
return Arrays.asList(value.split(" "));
}
})
//按照value进行聚合处理
.groupBy((key, value) -> value)
//时间窗口
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
//统计单词的个数
.count()
//转换为kStream
.toStream()
.map((key, value) -> {
System.out.println("key:" + key + " ,vlaue:" + value);
return new KeyValue<>(key.key().toString(), value.toString());
})
//发送消息
.to("zcy-out");
KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(), prop);
kafkaStreams.start();
}
} 4.4 kafka stream窗口函数使用
窗口函数在很多技术框架中都有着广泛的使用,比如spark,flink,hive,甚至在mysql8也开始支持窗口函数了,利用窗口函数可以对某个时间窗口内的数据进行统计、聚合和计算,接下来通过几个案例展示下在kafka stream中窗口函数的使用。
4.4.1 需求一,固定时间输出统计结果到另一个topic
这里每隔3秒输出一次从topic1中过去10秒的数据到topic2中
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.*;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class WindowStream1 {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG, "WindowCountStream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "IP:9092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 3000);
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream source = builder.stream("zcy");
KTable, Long> countTable = source
.flatMapValues(value -> Arrays.asList(value.toString().split("\\s+")))
.map((x, y) -> {
return new KeyValue(y, "1");
}).groupByKey()
//加10秒窗口,按步长3秒滑动
.windowedBy(TimeWindows.of(Duration.ofSeconds(10).toMillis()).advanceBy(Duration.ofSeconds(3).toMillis()))
.count();
countTable.toStream().foreach((key, val) -> {
System.out.println("key: " + key + " val: " + val);
});
countTable.toStream().map((key, val) -> {
return new KeyValue(key.toString(), val.toString());
}).to("zcy-out");
final Topology topo = builder.build();
final KafkaStreams streams = new KafkaStreams(topo, prop);
streams.start();
}
} 运行代码,按照上述相同的方式测试,然后再在控制台可以看到统计到的时间窗口内的单词数

4.4.2 需求二,统计topic1中10秒内的wordcount写到topic2
一个典型的场景就是,通过session会话的时间窗口统计用户访问网站的时长,对某个特定的用户来说,用户从登录开始,即该用户的窗口开始,直到发生退出或者会话超时,窗口期结束,可以统计在窗口期间发生的各种动作,比如点击某些按钮,浏览某个页面的时长等行为。
public class WindowStream2 {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG, "WindowCountStream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "IP:9092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 2000);
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream source = builder.stream("zcy");
KTable, Long> countTable = source.flatMapValues(value -> Arrays.asList(value.toString().split("\\s+")))
.map((x, y) -> {
return new KeyValue<>(y, "1");
}).groupByKey()
.windowedBy(SessionWindows.with(Duration.ofSeconds(15).toMillis()))
.count();
countTable.toStream().foreach((key, val) -> {
System.out.println("key: " + key + " val: " + val);
});
countTable
.toStream()
.map((key, val) -> {
return new KeyValue(key.toString(), val.toString());
})
.to("zcy-out");
KafkaStreams streams = new KafkaStreams(builder.build(), prop);
streams.start();
}
} 4.5 Kafka Streams使用场景拓展
4.5.1 事件日志监控
假如现在需要对某系统中实时上报到topic-1的错误或告警日志进行转换,并输出到下游的topic-2中做大屏监控,如下为原始的从topic-1中获取到的日志数据格式
{
"timestamp" : "2023-12-11 23:25:13",
"method": "GET",
"endpoint": "http://10.1.63.112:9098/fox/message/get",
"status_code": 500,
"source_ip":"192.168.9.138",
"request_params":"type=5&status=3",
"operation_user":"6613"
}假如下游的应用需要实时可视化用户请求日志,需要的数据格式如下:
{
"ope_time": "2023-12-11 23:25:13",
"ope_user": [
{"user_id": "6613", "source_ip": "192.168.9.138","endpoint":"http://10.1.63.112:9098/fox/message/get"}
]
}如果使用Kafka Stream来处理,可以考虑下面的思路
-
根据业务需求对原始日志进行聚合和转换,重新组装结果的格式,并将结果写到下游的topic中;
-
下游应用从topic中获取处理的结果,按照大屏的数据格式再次组装数据,最后展示到大屏;
4.5.2 事用户行为统计分析
比如某电商网站或app的后台需要统计用户某些指标的数据,从而分析用户的消费习惯为后续做促销提供数据决策依据,现在从原始的topic中可以拿到下面几类指标信息
{
"enter_type": app,
"online_time": 16m,
"user_type": "level_1" ,
"buy_time_in_month":2,
"user_id":1003
}有了这些信息,就可以计算某种类型的用户,在过去一年内产生在app或网站来浏览的时长,购买的总次数,如果需要汇聚更多的信息,可以要求上游的topic中传入更详细的参数。
4.5.3 数据聚合与实时计算
kafka stream可以作为简单的实时计算框架,对数据进行准实时的聚合统计,快速汇总计算数据按业务维度进行数据分发,承载一部分大数据实时计算的功能。
4.5.4 实时推荐
基于现有的数据模型进行相关的指标计算,预测某些指标的行为,进一步指导业务决策,比如上面统计电商网站中用户的网站浏览动作。
4.5.5 实时告警
检测系统异常指标,通过准实时计算汇聚结果,将异常行为进行上报。
4.5.6 应用解耦
这个与消息中间件的作用类似,为了减少源系统的计算压力,可以通过kafka stream进行解耦,所有的计算动作在kafka stream中进行,然后再将计算结果推送到下游的topic进行后续的使用。
五、kafka stream整合springboot
有了上面对kafka stream的了解和使用,接下来演示下如何在springboot中整合kafka stream
5.1 整合过程
5.1.1 导入springboot相关依赖
在上述已经导入的依赖的基础上补充下面几个依赖
org.springframework.boot
spring-boot-autoconfigure
org.projectlombok
lombok
org.springframework.boot
spring-boot-starter-web
5.1.2 配置kafka相关信息
在配置文件中添加如下配置信息
server:
port: 8088
spring:
application:
name: kafka-sream-app
kafka:
bootstrap-servers: kafka连接IP:9092
producer:
retries: 5
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: ${spring.application.name}-test
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
kafka:
hosts: kafka连接IP:9092
group: ${spring.application.name}5.1.3 添加Kafka Stream配置类
@Setter
@Getter
@Configuration
@EnableKafkaStreams
@ConfigurationProperties(prefix="kafka")
public class KafkaStreamConfig {
private static final int MAX_MESSAGE_SIZE = 16 * 1024 * 1024;
private String hosts;
private String group;
@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)
public KafkaStreamsConfiguration defaultKafkaStreamsConfig() {
Map props = new HashMap<>();
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);
props.put(StreamsConfig.APPLICATION_ID_CONFIG, this.getGroup()+"_stream_aid");
props.put(StreamsConfig.CLIENT_ID_CONFIG, this.getGroup()+"_stream_id");
props.put(StreamsConfig.RETRIES_CONFIG, 5);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
return new KafkaStreamsConfiguration(props);
}
} 5.1.4 自定义Kafka Stream业务处理监听器
还记得在编写消息中间件客户端程序的时候添加的那些监听器吗,原理类似,这里自定义一个监听器处理类,接收上游的topic消息进行处理之后再发送到下一个topic中,相当于是把上面的代码搬过来放到spring的ioc容器中
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.TimeWindows;
import org.apache.kafka.streams.kstream.ValueMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.time.Duration;
import java.util.Arrays;
@Configuration
public class StreamCountListener {
@Bean
public KStream kStream(StreamsBuilder streamsBuilder) {
KStream stream = streamsBuilder.stream("zcy");
stream.flatMapValues(new ValueMapper>() {
@Override
public Iterable apply(String value) {
return Arrays.asList(value.split(" "));
}
})
//按照value进行聚合处理
.groupBy((key, value) -> value)
//时间窗口
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
//统计单词的个数
.count()
//转换为kStream
.toStream()
.map((key, value) -> {
System.out.println("key:" + key + " ,vlaue:" + value);
return new KeyValue<>(key.key().toString(), value.toString());
})
//发送消息
.to("zcy-out");
return stream;
}
} 5.1.5 效果测试
运行项目,运行之后,使用下面的代码,往zcy这个topic中发送一些消息
public static void main(String[] args) throws Exception {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "IP:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
// 3. 创建 kafka 生产者对象
KafkaProducer kafkaProducer = new KafkaProducer(properties);
System.out.println("开始发送数据");
// 4. 调用 send 方法,发送消息
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("zcy","congge_" + i));
}
// 5. 关闭资源
kafkaProducer.close();
} 发送成功后,在控制台中可以看到经过上面的监听类处理得到的结果输出信息

六、写在文末
本篇通过较大得篇幅详细分享了kafka stream的使用,流式计算可以说是当下非常火热的技术之一,对于非大数据场景下的业务处理,kafka stream提供了一种很好的解决思路,希望对看到的同学有所帮助,本篇到此介绍,感谢观看。