canal 学习笔记
一、canal是什么
canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到canal发送过来的dump请求,开始推送binary log给canal,然后canal解析binary log,再发送到存储目的地。
二、binLog日志
它记录了所有的DDL DML等语句,以事件的方式记录 ,也可以用来做数据恢复,包含两类文件:
- 类是索引文件 .index 结尾用于记录所有的二进制文件。
- 进制文件(以.0000为后缀) 记录数据库所有的DDL和DML。
binlog的分类:
- statement:语句级别 会记录每一次执行写操作的语句,相对row模式节省空间 可能产生不一致性。
- row: 行级 记录每次操作后每行记录的变化 会保持数据的一致性 但是占用空间较大。
- mixed: 混合以上两种。
三、canal的链接模式
首先需要下载canal,并删除startUp.bat的如下内容,否则会启动报错。
-Dlogback.configurationFile="%logback_configurationFile%”然后双击startUp.bat 就能正常启动了。并在工程中引入canal 的maven
com.alibaba.otter
canal.client
1.1.4
还需要对mysql的binlog日志进行开启,并设置为行级(row)模式。
TCP模式:
首先canal.properties 文件修改模式为TCP
canal.serverMode = tcp修改实例的配置文件,需要提前为canal创建账户并赋予权限。
canal.instance.mysql.slaveId=0 # 这个slaveid需要保持全局唯一
# username/password
canal.instance.dbUsername=canal # 用户名
canal.instance.dbPassword=root # 用密码
canal.instance.connectionCharset = UTF-8 # 字符集接下来就需要写监听的代码:
public class CanalMain {
public static void main(String[] args) throws InterruptedException, InvalidProtocolBufferException {
// 单机下的canal 链接 destination 指定的是canal的监听对象,用户名和密码一般不用填写
CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress("localhost", 11111),
"example", "", "");
// 死循环监听链接
while (true){
canalConnector.connect(); // 获取链接
canalConnector.subscribe("canaltest.*"); // 设置订阅的数据,这里是订阅了canaltest数据库下的所有表
Message message = canalConnector.get(100); // get指定每次获取的数量 如果没有到达目标数量也不会阻塞
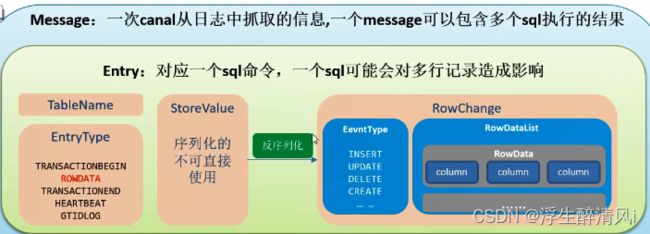
List entries = message.getEntries(); // entry 里面包含sql信息
if(!entries.isEmpty()){
for(CanalEntry.Entry entry: entries){
String tableName = entry.getHeader().getTableName(); // 获取表名
CanalEntry.EntryType entryType = entry.getEntryType(); // 获取类型
ByteString storeValue = entry.getStoreValue(); // storeValue就是真正数据的存放地方
if(CanalEntry.EntryType.ROWDATA.equals(entryType)){
// 解析一行数据
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
CanalEntry.EventType eventType = rowChange.getEventType(); // 事件的类型
// 一条sql的到来能获得 修改前的数据 和 修改后的数据
// 删除只有修改前没有修改后 插入只有修改后没有修改前
List rowDatasList = rowChange.getRowDatasList();
for(CanalEntry.RowData data: rowDatasList){
JSONObject before = new JSONObject();
for(CanalEntry.Column befData: data.getBeforeColumnsList()){
before.put(befData.getName(), befData.getValue());
}
JSONObject after = new JSONObject();
for(CanalEntry.Column AftData: data.getAfterColumnsList()){
after.put(AftData.getName(), AftData.getValue());
}
}
}
}
}
}
}
} message的数据结构如下图:
 kafka模式:
kafka模式:
首先需要开启zookeeper 和 kafka。修改canal的模式 改成kafka。
canal.serverMode = kafka并修改MQ相关配置指定kafka地址
##################################################
######### MQ #############
##################################################
canal.mq.servers = 127.0.0.1:9092 # kafka地址 多个逗号间隔
canal.mq.retries = 0 # 重试次数
canal.mq.batchSize = 16384 # 批size
canal.mq.maxRequestSize = 1048576 # 最大请求size修改监听对象配置文件的 kafka topic 并能对多个进行修改。
# mq config
canal.mq.topic=canal_example # 监听哪个实例对象
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0 # 具体的分区
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
启动kafka消费者 指定topic,修改数据库的信息,kafka就能监听到了。