numpy学习笔记
numpy
创建数组array
一维数组的创建与修改
import numpy as py
a = np.array([1, 2, 3, 4, 5])
b = np.array(range(1, 6)) # range:范围
c = np.arange(1, 6)
# 以上三种方法生成的数组内容相同,均为[1 2 3 4 5],尽管与列表list外表相似,但差别很大,且列表有‘,’隔开
# arange()使用方法 : np.arange([start,] stop[, step], dtype=None)
# arange()方法类似于range(),可以指定起始值(可省略·包含)、终止值(不可省略·不包含)、步长(可省略)
# eg,np.arange(1, 7, 2) >>>[1 3 5]
# 不同的是,arange()方法可以通过dtype参数指定数组中的数据类型,eg,dtype=bool,布尔类型(True,False),(默认类型可能存在小数取整问题,要注意)
# 也可以对数据类型进行修改
f = arange(0, 6, 2)
print(f)
f1 = f.astype('bool')
print(f1)
# >>>[0 2 4]
# [Flase True True]
# 使用astype()方法不会修改原来的数据类型(下面的shape、reshape类似),而是将修改后的数据类型进行返回,可以使用一个变量来接收新的数据类型
二维数组的创建与修改
import numpy as py
a2 = np.array([[1, 3, 6],
[4, 2, 7]])
# 注意二维数组创建时,'[]'的数量,同时可以使用shape()方法输出维数,reshape()方法进行不同维数数组间的转换
# shape()方法
print(a2.shape)
# >>>(2, 3)
# reshape()方法
arr1 = np.array([1, 2, 3, 4, 5, 6])
arr2 = np.array([[1, 2, 3],
[4, 5, 6]])
# 一维转二维(reshape()传入参数最好为一个元组,但不是元组也可以执行)
arr1_2 = arr1.reshape((2, 3))
print(arr1_2)
# >>>[[1 2 3]
# [4 5 6]]
# 二维转一维(reshape()其中几个数据,就为几维)
# 方法一
arr2_1 = arr2.reshape((6,))
print(arr2_1)
# >>>[1 2 3 4 5 6]
#方法二(faltten()方法默认按行降维,可以通过指定参数使其按列降维)
arr3 = arr2.flatten()
arr4 = arr2.flatten('F')
print(arr3)
print(arr4)
# [1 2 3 4 5 6]
# [1 4 2 5 3 6]
特殊数组的创建(全0、全1、对角)
import numpy as np
# 生成2*5的全1数组,元素类型为bool类型
arr = np.ones((2, 5), dtype=bool)
print(arr)
# 生成1*5的全0数组,元素类型不指定
arr3 = np.zeros((1, 5))
print(arr3)
# 生成5*5的对角数组(主对角线为1,其余为0,该方法貌似没有dtype参数)
# 若要改变类型,可以使用astype()方法,
# eg,arr2 = np.eye(5).astype(bool)
arr2 = np.eye(5)
print(arr2)
数组的计算
数组和数的计算(起作用于数组每个元素)
import numpy as np
# 生成一个3*4的数组
a = np.array(range(12))
text_arr = a.reshape((3, 4))
print(text_arr)
# >>>[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
# 加法
print(text_arr+2)
# >>>[[ 2 3 4 5]
# [ 6 7 8 9]
# [10 11 12 13]]
# 除法
print(text_arr/2)
# >>>[[0. 0.5 1. 1.5]
# [2. 2.5 3. 3.5]
# [4. 4.5 5. 5.5]]
数组和数组的计算
类型相同(计算的两个数组)(如均为3*4数组),对应位置元素之间进行运算
import numpy as py
# 创建两个类型相同的数组(3*4)
arr1 = np.arange(12).reshape((3, 4))
arr2 = np.arange(10, 22).reshape((3, 4))
print(arr1)
print(arr2)
# arr1 >>>[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
# ------------------------------------
# arr2 >>>[[10 11 12 13]
# [14 15 16 17]
# [18 19 20 21]]
# 加法
print(arr1+arr2)
# arr1+arr2 >>> [[10 12 14 16]
# [18 20 22 24]
# [26 28 30 32]]
# 乘法
print(arr1*arr2)
# arr1*arr2 >>> [[ 0 11 24 39]
# [ 56 75 96 119]
# [144 171 200 231]]
类型不同(计算的两个数组),会按照维度相同的行或列进行运算(至少有一个为向量(行数组或列数组))
import numpy as py
# 创建数组(3*4)
arr = np.arange(12).reshape((3, 4))
# arr >>>[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
# 按行运算
arr1 = np.array([0, 1, 2, 3])
print(arr-arr1)
# arr1 >>>[[0 0 0 0]
# [4 4 4 4]
# [8 8 8 8]]
# 也可以使用‘小数组’-‘大数组’,结果为上述结果的‘负数’(所有元素加负号)
#按列运算
arr2 = np.arange(3).reshape((3, 1))
print(arr2)
print(arr-arr2)
# arr2 >>> [[0]
# [1]
# [2]]
# ----------------------
# arr-arr2 >>> [[0 1 2 3]
# [3 4 5 6]
# [6 7 8 9]]
索引与切片
一般元素的选取
创建数组
import numpy as np
# 创建数组(7*8)
arr = np.arange(56).reshape((7, 8))
print(arr)
# >>> [[ 0 1 2 3 4 5 6 7]
# [ 8 9 10 11 12 13 14 15]
# [16 17 18 19 20 21 22 23]
# [24 25 26 27 28 29 30 31]
# [32 33 34 35 36 37 38 39]
# [40 41 42 43 44 45 46 47]
# [48 49 50 51 52 53 54 55]]
取行
print(arr[2]) # h3
print(arr[4, :]) # h5
# h3-h5(注意索引'a:b'包含a,不包含b)
print(arr[2:5])
print(arr[2:5, :])
print(arr[[2, 4]]) # 取不连续多行h2、h5(注意'[]'数量)
取列
print(arr[:, 2]) # l3
print(arr[:, 2:5]) # l3-l5(连续多列)
print(arr[:, [1, 3, 5]]) # l2、l4、l6(不连续多列)
取元素
print(arr[1, 2]) # 取单个元素
print(arr[[1, 0, 3], [2, 7, 1]]) # 取多个元素(第一个[]储存x,第二个[]储存y)
注意:类型不同
a1 = arr[1, 2] # 取单个元素
a2 = arr[[1, 0, 3], [2, 7, 1]] # 取多个元素(第一个[]储存x,第二个[]储存y)
print(a1)
print(type(a1))
print(a2)
print(type(a2))
# a1 >>> 10
#
# a2 >>> [10 7 25]
#
有条件的选取
import numpy as np
# 创建数组(7*8)
arr = np.arange(56).reshape((7, 8))
print(arr)
# >>> [[ 0 1 2 3 4 5 6 7]
# [ 8 9 10 11 12 13 14 15]
# [16 17 18 19 20 21 22 23]
# [24 25 26 27 28 29 30 31]
# [32 33 34 35 36 37 38 39]
# [40 41 42 43 44 45 46 47]
# [48 49 50 51 52 53 54 55]]
# 选取上述数组中大于等于10的元素
print(arr[arr >= 10])
# 选取数组中等于30的元素
print(arr[arr == 30])
# 选取大于10,小于20的元素
# 1、生成两个条件的bool数组;2、bool相加表示并集、bool相乘表示交集
a = arr > 10 # a 为'大于10'的bool数组
b = arr <= 20 # b 为'小于20'的bool数组
print(arr[a*b]) # a*b为'大于10小于20'的bool数组
# 若要替换数组中的元素,选中后赋值即可
# 如将上述'大于10,小于20的元素'修改为100
arr[a*b] = 100
numpy常用统计函数
常用的函数如下, 请注意函数在使用时需要指定 axis 轴的方向,若不指定,默认统计整个数组。
arr.sum(axis=), 返回求和
arr.mean(axis=), 返回均值
arr.max(axis=), 返回最大值
arr.min(axis=), 返回最小值
np.median(arr, axis=),返回中值
arr.ptp(axis=), 极差,最大值与最小值的差
arr.std(axis=), 返回标准偏差(standard deviation)
arr.var(axis=), 返回方差(variance)
arr.cumsum(axis=), 返回累加值
arr.cumprod(axis=), 返回累乘积值
例一:mean()方法
'''arr
[[4 5 1 2 4]
[1 1 2 5 5]]
'''
# 使用mean()方法求每行的均值
arr1 = arr.mean(axis=1)
print(arr1)
'''
[3.2 2.8]
'''
例二:cumsum()方法
arr2 = arr.cumsum(axis=1)
print(arr2)
'''
[[ 4 9 10 12 16]
[ 1 2 4 9 14]]
'''
其他操作(转置、拼接、交换)
转置
# 以下两张转置方法均不会改变原有数组的类型,而是将转置后的新的数组类型作为返回值返回,需要变量接收
# arr >>> [[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# 方法一(T)
arr1 = arr.T
print(arr1)
# >>> [[0 5]
# [1 6]
# [2 7]
# [3 8]
# [4 9]]
# 方法二(transpose()) ,transpose:转置
arr2 = arr.transpose()
print(arr2)
# >>> [[0 5]
# [1 6]
# [2 7]
# [3 8]
# [4 9]]
拼接
# arr1 >>> [[0 1 2 3]
# [4 5 6 7]]
# arr2 >>> [[100 101 102 103]
# [104 105 106 107]]
# 竖向拼接(vertical:垂直的, stack:堆n&v)
v_arr = np.vstack((arr1, arr2))
print(v_arr)
# v_arr >>> [[ 0 1 2 3]
# [ 4 5 6 7]
# [100 101 102 103]
# [104 105 106 107]]
# 横向拼接(horizontal:水平的)
h_arr = np.hstack((arr2, arr1))
print(h_arr)
# h_arr >>> [[100 101 102 103 0 1 2 3]
# [104 105 106 107 4 5 6 7]]
交换(行/列)
# arr >>> [[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
# 行交换(交换第3行与第4行)
arr[[2, 3], :] = arr[[3, 2], :] # ', :'也可以不要,因为数组默认组成元素为整行
print(arr)
# >>> [[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [15 16 17 18 19]
# [10 11 12 13 14]]
# 列交换(交换第4列与第5列)
arr[:, [3, 4]] = arr[:, [4, 3]]
print(arr)
# >>> [[ 0 1 2 4 3]
# [ 5 6 7 9 8]
# [10 11 12 14 13]
# [15 16 17 19 18]]
numpy中的nan
常见特性
# nan(not a number)
# 1、nan与inf都是float类型
# 2、两个nan不相等(nan!=nan >>> True)
# 3、nan与任何值运算,结果都是nan
常见用法
# 特性1,注意不能将int类型的数组元素替换为nan,可以在原数组后面使用.astype('float')
# 可以通过特性2来统计数组中nan的个数,如下所示
# np.count_nonzero(arr),用于统计数组arr中非0元素的个数(nan也是非0元素),传入的arr数据可以是bool类型(0为False,1为True)
''' arr
[[3.08511002 4.60162247 1.00057187 2.51166286 1.73377945]
[1.46169297 1.93130106 nan 2.98383737 nan]]
'''
t1 = np.count_nonzero(arr != arr)
print(t1)
# >>> 2
# 也可以用np.isnan(arr)方法,该方法返回值为bool类型的数组
t2 = np.count_nonzero(np.isnan(arr))
print(t2)
# >>> 2
练习:将nan替换为每一列的均值
'''arr
[[ 4. 5. 1. 2. 4. 1. 1.]
[ 2. 5. nan 2. nan 5. 3.]
[ 5. 4. 5. 3. nan 3. 5.]
[ 2. 2. nan 2. 2. 2. 2.]]
'''
# 将nan替换为每一列的均值
for i in range(arr.shape[1]):
temp_col = arr[:, i] # 取每一列元素,存于数组temp_col
if np.count_nonzero(temp_col != temp_col) != 0: # 如果该列存在nan,即nan个数不为0
no_nan = temp_col[temp_col == temp_col] # 先将其余元素提取出来
temp_col[temp_col != temp_col] = no_nan.mean() # 求其均值,并将其赋予该列nan
'''
[[4. 5. 1. 2. 4. 1. 1.]
[2. 5. 3. 2. 3. 5. 3.]
[5. 4. 5. 3. 3. 3. 5.]
[2. 2. 3. 2. 2. 2. 2.]]
'''
random(随机数常用方法介绍)
.rand()(不常使用)
# 创建均匀分布的随机数组,浮点数,范围为[0, 1)
arr1 = np.random.rand(2, 5)
print(arr1)
'''
[[0.62740707 0.44553463 0.50733307 0.58543158 0.26384939]
[0.57921636 0.09801639 0.75462551 0.48890316 0.86963899]]
'''
.randn()
# 创建标准正态分布的随机数组,浮点数,均值为0,方差为1
arr2 = np.random.randn(2, 5)
print(arr2)
print('-'*100)
# 创建均值为10,方差为1.5的正态分布的随机数组
arr2 = 1.5 * np.random.randn(2, 5) + 10
print(arr2)
'''
[[-1.21917188 -0.31588127 0.63634746 1.49401394 -0.60690165]
[ 0.02646661 0.12754377 1.01771709 -1.12258059 -0.01021243]]
-----------------------------------------------------------------
[[10.11841524 10.60079869 11.1896106 9.80760455 8.81258389]
[11.28906315 9.59767769 10.67918961 11.28440804 9.28527924]]
'''
.randint()
# 从给定上下限选取随机整数创建数组(np.random.randint(min, max-1, size=None))
arr3 = np.random.randint(0, 5, size=(2, 5))
print(arr3)
'''
[[4 1 3 0 4]
[0 2 1 0 0]]
'''
.uniform()
# 从指定范围产生随机分布的浮点数数组,uniform(min=0.0, max=1.0, size=None)
arr4 = np.random.uniform(0, 0.1, size=5)
print(arr4)
'''
[0.02503829 0.00511872 0.06617172 0.0856498 0.03822023]
'''
.seed()
# 随机数种子(seed)
# 在seed()中传入相同的数字使得接下来生成的随机数序列是相同的,仅对最近的随机数生成语句生效,且会对相同函数产生影响
np.random.seed(1)
arr5 = np.random.randint(0, 5, size=4)
print(arr5)
np.random.seed(1)
arr6 = np.random.uniform(0, 5, size=4)
print(arr6)
np.random.seed(1)
arr7 = np.random.randint(0, 5, size=4)
print(arr7)
'''
[3 4 0 1]
[2.08511002e+00 3.60162247e+00 5.71874087e-04 1.51166286e+00]
[3 4 0 1]
'''
# 观察上面输出结果可以发现,虽然arr6前也使用了seed()方法,但并未和arr5结果一致
.seed()补充
多次运行发现,只要使用了一次np.random.seed(),那么接下来所有产生随机数语句的结果均与上一次相同,不会改变(但不一定相同),如下代码所示
np.random.seed(1)
arr5 = np.random.randint(0, 5, size=4)
print(arr5)
# np.random.seed(1)
arr6 = np.random.uniform(0, 5, size=4)
print(arr6)
# np.random.seed(1)
arr7 = np.random.randint(0, 5, size=4)
print(arr7)
'''
[3 4 0 1]
[1.51166286 0.73377945 0.46169297 0.93130106]
[4 1 2 4]
'''
# 我们将第5行与第9行的seed()代码注释掉,仅保留第1行的seed()代码,多次运行,结果未发生改变
np.loadtxt()用法
# arr = np.loadtxt('text.txt', delimiter=',', skiprows=, dtype=)
# delimiter:指定数据分隔符
# skiprows:跳过的行数,skiprows=1说明跳过首行
# dtype:指定数据类型
# 如果加载的数据中存在中文,则dtype=str, encoding='utf-8'(或者gbk,如果存在中文乱码的情况)
轴(axis)的补充
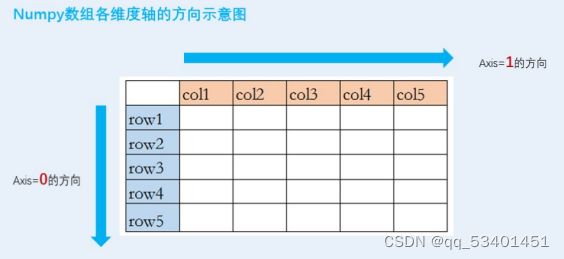
指定的轴(axis)的方向,即为数组运算的方向
生成试验用的数组
import numpy as np
arr = np.random.randint(1, 6, (2, 5))
print(arr)
'''
[[4 5 1 2 4]
[1 1 2 5 5]]
'''
例一:使用mean()方法
# 若想求每一行的平均值,期望输出[a b]
# 即数组元素的运算方向为'横向',此时我们需要指定'axis=1'即可
arr1 = np.mean(arr, axis=1)
print(arr1)
'''
[3.2 2.8]
'''
例二:使用max()方法
# 若想求每一列的最大值,期望输出[a b c d e]
# 即数组元素的运算方向为'纵向',此时需要指定'axis=0'
arr2 = np.max(arr, axis=0)
print(arr2)
'''
[4 5 2 5 5]
'''
例三:使用cumsum()方法,返回累加值
# 若想求在行方向上累加的数组
# 即数组元素的运算方向为'横向',此时需要指定'axis=1'
arr3 = np.cumsum(arr, axis=1)
print(arr3)
'''
[[ 4 9 10 12 16]
[ 1 2 4 9 14]]
'''
以上内容为本人学习笔记,
发现问题,望您指出
谢谢!