第三十三学习周报:文献阅读+LSTM变体+RNN
目录
摘要
Abstract
文献阅读:卷积LSTM网络:降水临近预报的机器学习方法
现有问题
提出方法
相关知识
LSTM
FC-LSTM
Conv-LSTM
编码预测结构
研究实验
1. 数据集
2. 评估指标
3. 实验设计
4. 实验结果
研究贡献
Recurrent Neural Network(循环神经网络)
1. RNN的结构
2. RNN的分类
3. RNN的原理
4. RNN can be deep
5. Bidirectional RNN( 双向RNN)
6. RNN的训练
基于Pytorch实现ConvLSTM
摘要
本周阅读的文献中首次提出ConvLSTM,ConvLSTM同时拥有LSTM的时间序列处理能力和CNN的空间特征处理能力,同时它也是FC-LSTM的扩展,解决了FC-LSTM对于空间数据包含太多的冗余的问题。通过叠加多个ConvLSTM层并形成一个编码-预测结构,可用于处理如降雨天气预报等时空序列问题。RNN是一种有记忆力的神经元,它能挖掘数据中的时序信息以及语义信息。通过手动演算RNN的运作过程,认识到它与CNN等结构不同,它同时考虑前一时刻的输入,对前面的内容具有“记忆”功能,因此网络的输入顺序将会影响输出。RNN进行训练时会存在梯度无效和梯度爆炸等问题,而通过LSTM可以很好解决RNN训练时的梯度无效问题。
Abstract
The literature read this week first proposed ConvLSTM, which possesses both the time series processing capability of LSTM and the spatial feature processing capability of CNN. It is also an extension of FC-LSTM, solving the problem of excessive redundancy in spatial data in FC-LSTM. By overlaying multiple ConvLSTM layers and forming an encoding prediction structure, it can be used to handle spatiotemporal sequence problems such as rainfall weather forecasting. RNN is a type of memory neuron that can mine temporal and semantic information in data. By manually calculating the operation process of RNN, it is realized that it is different from CNN and other structures. It simultaneously considers the input of the previous moment and has a "memory" function for the previous content. Therefore, the input order of the network will affect the output. When training RNN, there may be problems such as ineffective gradients and exploding gradients, but LSTM can effectively solve the problem of ineffective gradients during RNN training.
文献阅读:卷积LSTM网络:降水临近预报的机器学习方法
title:Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting
文章链接:https://arxiv.org/pdf/1506.04214.pdf
现有问题
1)降水临近预报的目的是预测某一地区在相对较短时间内的未来降雨强度。以前很少有研究从机器学习的角度来研究这个至关重要且具有挑战性的天气预报问题。
2)由于预报分辨率和时间精度要求远高于周平均温度预报等传统预报任务,降水临近预报问题具有相当的挑战性,降水临近预报本质上是一个以过去雷达图序列为输入,以固定数量(通常大于1)的未来雷达图序列为输出的时空序列预报问题然而,这样的学习问题,不管它们的确切应用是什么,首先由于时空序列的高维性,特别是当必须进行多步预测时,除非预测模型很好地捕获了数据的时空结构,否则就不是简单的。此外,由于大气的混沌特性,对雷达回波数据建立有效的预测模型更具挑战性。虽然 FC-LSTM层已被证明在处理时间相关性方面非常强大,但它包含了太多的空间数据冗余
提出方法
1)提出了一种用于降水临近预报的卷积LSTM (ConvLSTM)网络,将降水临近预报描述为一个输入和预测目标都是时空序列的时空序列预报问题。
2)通过扩展全连接LSTM (FC-LSTM),使其在输入到状态和状态到状态的转换中都具有卷积结构,并使用卷积LSTM (ConvLSTM)来构建降水临近预报问题的端到端可训练模型
相关知识
LSTM
对于RNN而言,由于在训练过程中输入的权重W,上层输出的权重U以及偏置b是同一组参数,容易出现梯度爆炸或者梯度消失的情况。为了解决梯度消失和爆炸以及更好的预测分类序列数据等问题,产生了LSTM。相比于普通的RNN,LSTM多了三个控制,分别为输入控制f,输入控制i和输出控制o,同时维持一条记忆线,用来动态的控制哪些更重要的信息需要被保留到下一层,哪些不重要的信息可以被一遗忘,对于每一个门都有自己对应的权重与偏置,在RNN的内部实现了解耦合,避免了梯度消失于梯度爆炸的情况。

FC-LSTM
LSTM的输入是一维的张量,只考虑了时序,没有考虑空间之间的相关性。FC-LSTM的输入可以是多维时间序列数据,例如股票价格、气象数据等,输出也可以是多维数据,例如未来一段时间内的股票价格、气象数据等。FC-LSTM的训练过程可以使用反向传播算法,通过最小化损失函数来优化模型参数。相比于传统的LSTM模型,FC-LSTM可以更好地处理多维时间序列数据,具有更好的预测性能。相比LSTM在FC-LLSTM中加入了窥探机制,每一个门的输入由三部分决定,即本层的输入,上一层的输出以及记忆线C上的信息,同时让原先输入的时间序列向量换成矩阵,以表示空间上的连接关系,矩阵相乘表示着全连接,所以这里叫做full-connection LSTM。

Conv-LSTM
尽管FC-LSTM层在处理时间相关方面已经被证明是强大的,但它对于空间数据包含太多的冗余。为了解决这个问题,我们提出了FC-LSTM的扩展,连接结构同FC-LSTM,不同的地方在于将中间的全连接换成了卷积,它在输入到状态和状态到状态的转换中都具有卷积结构。可以更好的表示空间中的关系,没有太多的冗余信息。

传统LSTM的 是一维的张量, 而在Conv-LSTM中是3维张量。实际上,传统FC-LSTM的输入、输出和隐藏状态也可以看作是后二维为1的三维张量。从这个意义上说,FC-LSTM实际上是ConvLSTM的一个特例,它的所有特性都位于一个单元上。
是一维的张量, 而在Conv-LSTM中是3维张量。实际上,传统FC-LSTM的输入、输出和隐藏状态也可以看作是后二维为1的三维张量。从这个意义上说,FC-LSTM实际上是ConvLSTM的一个特例,它的所有特性都位于一个单元上。
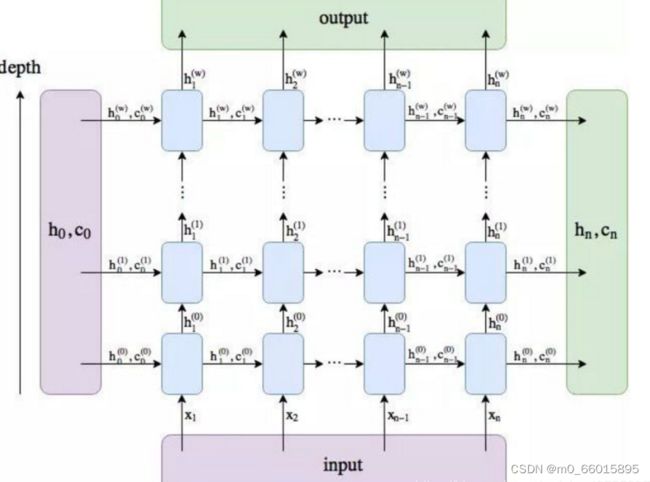
ConvLSTM中的层数就指的是LSTM的层数,每个时间点前后有h和c的传入传出,每层之间的时间点之间有着h的传入和传出。将2D图像转换为3D张量。可以理解为,![]() 以及sequence的每个元素都是三维的tensor,每次我们都是用卷积操作来生成下一个sequence的
以及sequence的每个元素都是三维的tensor,每次我们都是用卷积操作来生成下一个sequence的![]() 。Conv-LSTM通过本地邻居
。Conv-LSTM通过本地邻居 的输入和过去
的输入和过去![]() 状态来确定网格中某个单元格的未来状态。
状态来确定网格中某个单元格的未来状态。
 Conv-LSTM的内部结构
Conv-LSTM的内部结构
编码预测结构
与FC-LSTM一样,Conv-LSTM也可以作为更复杂结构的构建块。对于我们的时空序列预测问题,Conv-LSTM网络由两个网络组成,如图所示的结构,一个编码网络和一个预测网络。预测网络的初始状态和单元输出是从编码网络的最后状态复制的。这两种网络都是通过堆叠多个Conv-LSTM层形成的。由于我们的预测目标与输入具有相同的维数,我们将预测网络中的所有状态连接起来,并将它们馈送到1 × 1的卷积层中以生成最终的预测。编码LSTM将整个输入序列压缩成一个隐藏状态张量,预测LSTM展开这个隐藏状态,给出最终的预测。通过叠加多个ConvLSTM层并形成一个编码-预测结构,我们不仅可以为降水临近预报问题构建网络模型,还可以为更一般的时空序列预测问题构建网络模型。
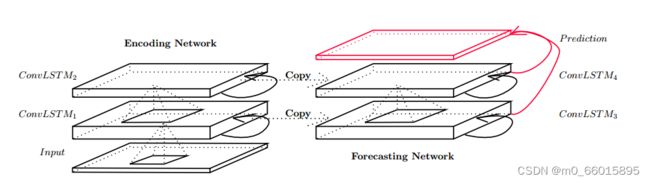 降水临近预报的编码预报ConvLSTM网络
降水临近预报的编码预报ConvLSTM网络
Conv-LSTM就是3D版的传统LSTM,用卷积kernel来解决高维映射的问题。输入和输出元素都是保留所有空间信息的3D张量,由于网络有多个堆叠的Conv-LSTM层,它具有很强的表征能力,这使得它适合在复杂的动力系统中给出预测,比如我们在这里研究的降水临近预报问题。
研究实验
1. 数据集
采用Moving-MNIST合成数据集,数据集中的所有数据实例都是20帧长(10帧用于输入,10帧用于预测),并且包含两个在64 × 64patch中移动的手写数字。移动的数字是从MNIST数据集中的500个数字的子集中随机选择的,起始位置和速度方向均匀随机选择,随机选择速度幅值。这个生成过程重复15000次,得到一个包含10000个训练序列、2000个验证序列和3000个测试序列的数据集。
2. 评估指标
所有的模型的均采用cross-entropy交叉熵作为损失函数,在MovingMNIST数据集对比FC-LSTM以及不同架构Conv-LSTM的交叉熵结果。
3. 实验设计
在一个合成的MovingMNIST数据集上比较我们的ConvLSTM网络和FC-LSTM网络,以获得对我们模型行为的一些基本理解。以不同的层数和内核大小运行我们的模型,并研究了一些“域外”的情况。
对于FC-LSTM网络,我们使用具有两个2048节点的LSTM层。对于ConvLSTM网络,我们将patch大小设置为4 × 4,以便每个64 × 64帧由16 × 16 × 16张量表示。我们用不同的层数测试了模型的三种变体,1层网络包含一个包含256个隐藏状态的ConvLSTM层,2层网络包含两个包含128个隐藏状态的ConvLSTM层,3层网络的三个ConvLSTM层中分别包含128个、64个和64个隐藏状态。所有的输入到状态核和状态到状态核的大小都是5 × 5,此外还尝试了其他网络配置,将2层和3层网络的状态对状态核和输入对状态核分别更改为1 × 1和9 × 9。
4. 实验结果
各算法在测试集上的平均交叉熵损失(每个序列的)如表所示,从交叉熵损失结果来看,不同层次的ConvLSTM的的交叉熵都均小于FC-LSTM网络的交叉熵,说明网络的性能始终优于FC-LSTM网络。此外,尽管在2层和3层网络之间的改进不是那么显著,但可以看出更深的模型可以给出更好的结果。
ConvLSTM网络与FC-LSTM网络在Moving-MNIST数据集上的比较 -5x5 和-1x1表示相应的状态到状态内核大小,即5×5或1×1。' 256 ', ' 128 ', ' 64 '表示ConvLSTM层中隐藏状态的数量。 (5x5) 和(9x9)表示输入到状态的内核大小。
虽然新的两层网络的参数数量接近于原始网络,但由于仅通过1×1状态到状态的转换难以捕获时空运动模式,因此结果变得更差。同时,新的3层网络比新的2层网络性能更好,因为更高层可以看到更宽的输入范围。然而,它的性能不如具有更大状态到状态内核大小的网络。这提供了更大的状态到状态核更适合捕获时空相关性的证据。可以得出结论,使状态到状态卷积核的大小大于1对于捕获时空运动模式至关重要,更深入的模型可以用更少的参数产生更好的结果,Conv-LSTM网络的性能始终优于FC-LSTM网络。
研究贡献
1)将降水临近预报表述为一个时空序列预测问题,并提出了LSTM的一个新的扩展,称为ConvLSTM来解决这个问题。ConvLSTM层不仅保留了FC-LSTM的优点,而且由于其固有的卷积结构也适用于时空数据。
2)通过将ConvLSTM融入到编码预测结构中,建立了降水临近预报的端到端可训练模型。
Recurrent Neural Network(循环神经网络)
1. RNN的结构
下图所示的一个全连接的神经网络,假设权值都是1,没有bias,所有激活函数均为线性函数。对于每一层的神经元都能保存当前输入通过计算得到的值,也就是输出给下一层神经元的值,当下一次输入的时候,每层神经元已经记住了上一层神经元的输出,而上一个词汇(如果不是第一个词汇的话)又具有上上个词汇的信息,以此类推,当前词汇就具有了上文所有词汇的信息,因此这时的神经元要同时考虑输入和上一层的输出。

2. RNN的分类
Elman Network是将hide layer 的输出存入memory,Jordan Network是将整个network的输出存入memory。
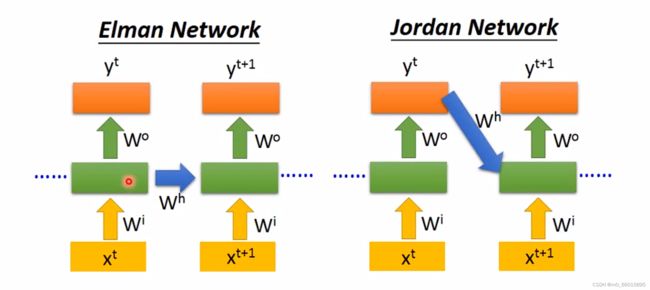
Q:在现实应用中Jordan Network表现得比Elman Network更好,为什么Jordan Network可以得到更好的效果?
A:因为hide layer的W是没有target的,所以很难控制它学到的东西,因此放入memory的信息是不可控的,但是整个y是有target的,可以比较清楚放在memory里面的信息。最后的输出比中间层的输出具有更具体完备的特征,即信息更有用。
3. RNN的原理
假设现在有三个输入序列: 、、
、、![]() ,对于第一次和第二次的序列是相同的但是它们的的output却是不一样的,因为第一次输入的时候,神经元保存的是初始值0,但是第二次输入神经元的值是第一次计算的值,也就是
,对于第一次和第二次的序列是相同的但是它们的的output却是不一样的,因为第一次输入的时候,神经元保存的是初始值0,但是第二次输入神经元的值是第一次计算的值,也就是![]() ,所以即使是相同的输入,也会得到不同的结果。
,所以即使是相同的输入,也会得到不同的结果。
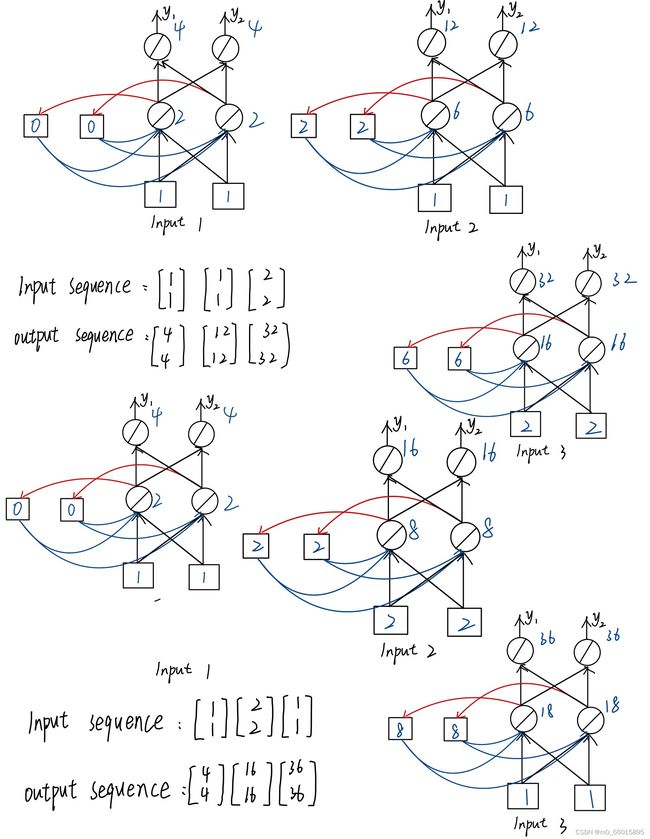
RNN是会考虑输入的顺序的,可以发现如果调换输入的顺序,那么output序列也会改变
图中的网络中并不是3个RNN,而是同一个RNN在不同的时间点,使用3次。
两个“Taipei”前面的输入向量不一样,因此x1通过neuron的输出是不一样的,所以存到memory的内容不一样,所以两个“Taipei”的输出是不一样的。
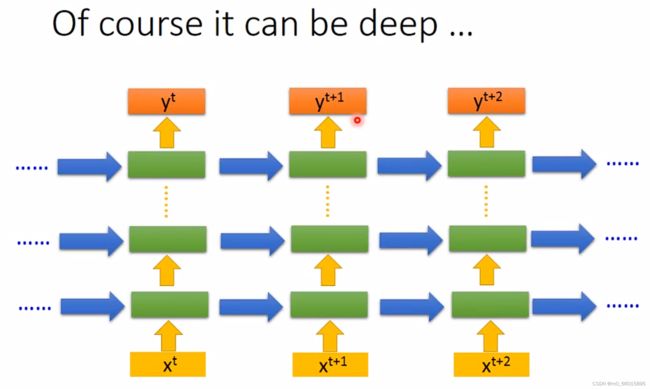
4. RNN can be deep
RNN可以有有多层,输入一个向量可以经过很多个hide layer 得到输出,每一个hide layer的output都会被存在memory里面,在下一个时间点的hide layer会把上一个时间点存的值读入,一直持续下去。
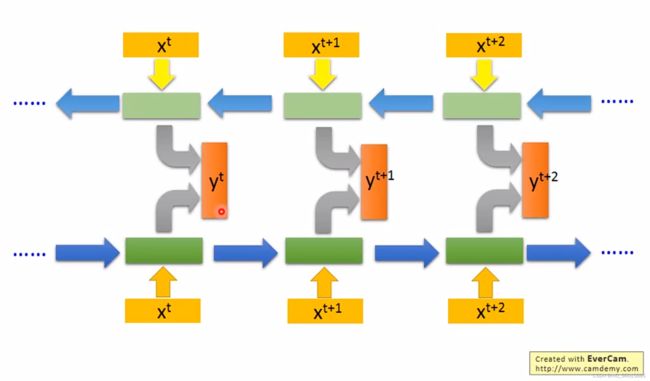
5. Bidirectional RNN( 双向RNN)
单向的RNN可以考虑前面的输入,但无法考虑后面的输入。双向的RNN弥补了这个缺陷,如果只有正向network,那么在产生y的时候,只能考虑x之前输入的信息,而双向的RNN不仅可以考虑前面的input,同时也可以考虑后面的input,相当于考虑了全部的input。
6. RNN的训练
RNN的训练采用gradient descend方法,然而基于RNN的网络的训练是很困难的,在很幸运的情况可能训练成功降低了loss值,可是在有的时候会出现“起起伏伏”无法训练下去的情况。

Q:为什么RNN的training有问题?
A:因为RNN在进行gradient descend的时候error surface不是太平坦就是太陡峭,在更新参数的时候,可能恰好跳过悬崖发生loss暴增。而在很平坦的区域learning rate会慢慢的调大,如果在更新过程中不下心走到了悬崖处,即橙色点处,那么很大的gradient再乘上很大的learning rate就是大幅度更新,参数就飞出了范围。
一个很直观判断参数gradient大小的方法就是将该参数做微小的变化,看对它输出影响有多大。以一个简单的RNN为例,输入门和输出门的权重都是1,从forget gate到输入的权重是w,第一个时间点输入1,其他的时间点输入都是0。将1输进去时候一直乘以w,到第1000个时间的输出值为![]() ,在w=1附近可以看出来当w的值发生微小变化时,对输出值的影响却很大,因此w在等于1处有很大的的gradient,learning rate的值就需要设置得小一些,而在w在0.99处的gradient又很小,需要大一点的learning rate。
,在w=1附近可以看出来当w的值发生微小变化时,对输出值的影响却很大,因此w在等于1处有很大的的gradient,learning rate的值就需要设置得小一些,而在w在0.99处的gradient又很小,需要大一点的learning rate。

因此可以发现在很小的区域内,gradient就会有很大的变化,这就是为什么RNN在训练的时候存在问题,这是因为RNN把同样的东西在transform的时候重复用在了每一个时间节点上,因此参数w只要发生变化就是发生两种情况,一个是没有造成任何影响,一个是造成非常大的影响,产生蝴蝶效应。
如今解决RNN训练难的问题方法就是LSTM,所以我们将RNN换成了LSTM,在普通的RNN架构中,每一个时间点的memory里面的值都会被覆盖,就不会再产生影响,但LSTM是将原本memory里面的值乘上一个权重再加到input,如果权重不为0,那么一旦有一个值被存入memory造成了影响,那么这个影响将会一直存在,除非forget gate把memory清空了,因此不会存在gradient vanishing问题,让error surface不那么崎岖,可以做到将比较平坦的地方拿掉,解决梯度消失的问题,但是不能解决梯度爆炸的问题,所以在训练的时候需要使用较小的learning rate。
基于Pytorch实现ConvLSTM
import numpy as np
from torch.utils.data import Dataset,DataLoader
import torch
import torch.nn as nn
"""
定义ConvLSTM每一层的、每个时间点的模型单元,及其计算。
"""
class ConvLSTMCell(nn.Module):
def __init__(self, input_dim, hidden_dim, kernel_size, bias):
"""
单元输入参数如下:
input_dim: 输入张量对应的通道数,对于彩图为3,灰图为1。
hidden_dim: 隐藏状态的神经单元个数,也就是隐藏层的节点数,应该可以按计算需要“随意”设置。
kernel_size: (int, int),卷积核,并且卷积核通常都需要为奇数。
bias: bool,单元计算时,是否加偏置,通常都要加,也就是True。
"""
super(ConvLSTMCell, self).__init__() #self:实例化对象,__init__()定义时该函数就自动运行,
#super()是实例self把ConvLSTMCell的父类nn.Modele的__init__()里的东西传到自己的__init__()里
#总之,这句是搭建神经网络结构必不可少的。
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.kernel_size = kernel_size
self.padding = kernel_size[0] // 2, kernel_size[1] // 2 #//表示除法后取整数,为使池化后图片依然对称,故这样操作。
self.bias = bias
"""
nn.Conv2D(in_channels,out_channels,kernel_size,stride,padding,dilation=1,groups=1,bias)
二维的卷积神经网络
"""
self.conv = nn.Conv2d(in_channels=self.input_dim + self.hidden_dim, #每个单元的输入为上个单元的h和这个单元的x,
#所以h和x要连接在一起,在x的通道数上与h的维度上相连。
out_channels=4 * self.hidden_dim, #输入门,遗忘门,输出门,激活门是LSTM的体现,
#每个门的维度和隐藏层维度一样,这样才便于进行+和*的操作
#输出了四个门,连接在一起,后面会想办法把门的输出单独分开,只要想要的。
kernel_size=self.kernel_size,
padding=self.padding,
bias=self.bias)
def forward(self, input_tensor, cur_state):
"""
input_tensor:此时还是四维张量,还未考虑len_seq,[batch_size,channels,h,w],[b,c,h,w]。
cur_state:每个时间点单元内,包含两个状态张量:h和c。
"""
h_cur, c_cur = cur_state #h_cur的size为[batch_size,hidden_dim,height,width],c_cur的size相同,也就是h和c的size与input_tensor相同
combined = torch.cat([input_tensor, h_cur], dim=1) #把input_tensor与状态张量h,沿input_tensor通道维度(h的节点个数),串联。
#combined:[batch_size,input_dim+hidden_dim,height,weight]
combined_conv = self.conv(combined) #Conv2d的输入,[batch_size,channels,height,width]
#Conv2d的输出,[batch_size,output_dim,height,width],这里output_dim=input_dim+hidden_dim
cc_i, cc_f, cc_o, cc_g = torch.split(combined_conv, self.hidden_dim, dim=1) #将conv的输出combined_conv([batch_size,output_dim,height,width])
#分成output_dim这个维度去分块,每个块包含hidden_dim个节点信息
#四个块分别对于i,f,o,g四道门,每道门的size为[b,hidden_dim,h,w]
i = torch.sigmoid(cc_i) # 输入门
f = torch.sigmoid(cc_f) # 遗忘门
o = torch.sigmoid(cc_o) # 输出门
g = torch.tanh(cc_g) #激活门
c_next = f * c_cur + i * g #主线,遗忘门选择遗忘的+被激活一次的输入,更新长期记忆。
h_next = o * torch.tanh(c_next) #短期记忆,通过主线的激活和输出门后,更新短期记忆(即每个单元的输出)。
return h_next, c_next #输出当前时间点输出给下一个单元的,两个状态张量。
def init_hidden(self, batch_size, image_size):
"""
初始状态张量的定义,也就是说定义还未开始时输入给单元的h和c。
"""
height, width = image_size
init_h = torch.zeros(batch_size, self.hidden_dim, height, width, device=self.conv.weight.device) #初始输入0张量
init_c = torch.zeros(batch_size, self.hidden_dim, height, width, device=self.conv.weight.device) #[b,hidden_dim,h,w]
#self.conv.weight.device表示创建tensor存放的设备
#和conv2d进行的设备相同
return (init_h,init_c)
"""
定义整个ConvLSTM按序列和按层数的结构和计算。
输入介绍:
五维数据,[batch_size,len_seq,channels,height,width] or [l,b,c,h,w]。
输出介绍:
输出两个列表:layer_output_list和last_state_list。
列表0:layer_output_list--单层列表,每个元素表示一层LSTM层的输出h状态,每个元素的size=[b,l,hidden_dim,h,w]。
列表1:last_state_list--双层列表,每个元素是一个二元列表[h,c],表示每一层的最后一个时间单元的输出状态[h,c],
h.size=c.size=[b,hidden_dim,h,w]
使用示例:
>> x = torch.rand((64, 20, 1, 64, 64))
>> convlstm = ConvLSTM(1, 30, (3,3), 1, True, True, False)
>> _,last_states = convlstm(x)
>> h = last_states[0][0] #第一个0表示要第1层的列表,第二个0表示要h的张量。
"""
class ConvLSTM(nn.Module):
"""
输入参数如下:
input_dim:输入张量对应的通道数,对于彩图为3,灰图为1。
hidden_dim:h,c两个状态张量的节点数,当多层的时候,可以是一个列表,表示每一层中状态张量的节点数。
kernel_size:卷积核的尺寸,默认所有层的卷积核尺寸都是一样的,也可以设定不同的lstm层的卷积核尺寸不同。
num_layers:lstm的层数,需要与len(hidden_dim)相等。
batch_first:dimension 0位置是否是batch,是则True。
bias:是否加偏置,通常都要加,也就是True。
return_all_layers:是否返回所有lstm层的h状态。
"""
def __init__(self, input_dim, hidden_dim, kernel_size, num_layers,
batch_first=True, bias=True, return_all_layers=False):
super(ConvLSTM, self).__init__()
self._check_kernel_size_consistency(kernel_size) #后面def了的,检查卷积核是不是列表或元组。
kernel_size = self._extend_for_multilayer(kernel_size, num_layers) # 如果为多层,将卷积核以列表的形式分入多层,每层卷积核相同。
hidden_dim = self._extend_for_multilayer(hidden_dim, num_layers) # 如果为多层,将隐藏节点数以列表的形式分入多层,每层卷积核相同。
if not len(kernel_size) == len(hidden_dim) == num_layers: # 判断卷积层数和LSTM层数的一致性,若不同,则报错。
raise ValueError('Inconsistent list length.')
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.kernel_size = kernel_size
self.num_layers = num_layers
self.batch_first = batch_first
self.bias = bias
self.return_all_layers = return_all_layers #一般都为False。
cell_list = [] #每个ConvLSTMCell会存入该列表中。
for i in range(0, self.num_layers): # 当LSTM为多层,每一层的单元输入。
if i==0:
cur_input_dim = self.input_dim #一层的时候,单元输入就为input_dim,多层的时候,单元第一层输入为input_dim。
else:
cur_input_dim = self.hidden_dim[i - 1] #多层的时候,单元输入为对应的,前一层的隐藏层节点情况。
cell_list.append(ConvLSTMCell(input_dim=cur_input_dim,
hidden_dim=self.hidden_dim[i],
kernel_size=self.kernel_size[i],
bias=self.bias))
self.cell_list = nn.ModuleList(cell_list) # 把定义的多个LSTM层串联成网络模型,ModuleList中模型可以自动更新参数。
def forward(self, input_tensor, hidden_state=None):
"""
input_tensor: 5D张量,[l, b, c, h, w] 或者 [b, l, c, h, w]
hidden_state: 第一次输入为None,
Returns:last_state_list, layer_output
"""
if not self.batch_first:
input_tensor = input_tensor.permute(1, 0, 2, 3, 4) # (t, b, c, h, w) -> (b, t, c, h, w)
if hidden_state is not None:
raise NotImplementedError()
else:
b, _, _, h, w = input_tensor.size() # 自动获取 b,h,w信息。
hidden_state = self._init_hidden(batch_size=b,image_size=(h, w))
layer_output_list = []
last_state_list = []
seq_len = input_tensor.size(1) #根据输入张量获取lstm的长度。
cur_layer_input = input_tensor #主线记忆的第一次输入为input_tensor。
for layer_idx in range(self.num_layers): #逐层计算。
h, c = hidden_state[layer_idx] #获取每一层的短期和主线记忆。
output_inner = []
for t in range(seq_len): #序列里逐个计算,然后更新。
h, c = self.cell_list[layer_idx](input_tensor=cur_layer_input[:, t, :, :, :],cur_state=[h, c])
output_inner.append(h) #第layer_idx层的第t个stamp的输出状态。
layer_output = torch.stack(output_inner, dim=1) #将第layer_idx层的所有stamp的输出状态串联起来。
cur_layer_input = layer_output #准备第layer_idx+1层的输入张量,其实就是上一层的所有stamp的输出状态。
layer_output_list.append(layer_output) #当前层(第layer_idx层)的所有timestamp的h状态的串联后,分层存入列表中。
last_state_list.append([h, c]) #当前层(第layer_idx层)的最后一个stamp的输出状态的[h,c],存入列表中。
if not self.return_all_layers: #当不返回所有层时
layer_output_list = layer_output_list[-1:] #只取最后一层的所有timestamp的h状态。
last_state_list = last_state_list[-1:] #只取最后一层的最后的stamp的输出状态[h,c]。
return layer_output_list, last_state_list
def _init_hidden(self, batch_size, image_size):
"""
所有lstm层的第一个时间点单元的输入状态。
"""
init_states = []
for i in range(self.num_layers):
init_states.append(self.cell_list[i].init_hidden(batch_size, image_size)) #每层初始单元,输入h和c,存为1个列表。
return init_states
@staticmethod #静态方法,不需要访问任何实例和属性,纯粹地通过传入参数并返回数据的功能性方法。
def _check_kernel_size_consistency(kernel_size):
"""
检测输入的kernel_size是否符合要求,要求kernel_size的格式是list或tuple
"""
if not (isinstance(kernel_size, tuple) or
(isinstance(kernel_size, list) and all([isinstance(elem, tuple) for elem in kernel_size]))):
raise ValueError('`kernel_size` must be tuple or list of tuples')
@staticmethod
def _extend_for_multilayer(param, num_layers):
"""
扩展到LSTM多层的情况
"""
if not isinstance(param, list):
param = [param] * num_layers
return param
x = torch.rand((64, 20, 1, 64, 64))
convlstm = ConvLSTM(1, 30, (3,3), 1, True, True, False)
_, last_states = convlstm(x)
h = last_states[0][0] # 第一个0表示要第一层的列表,第二个0表示要列表里第一个位置的h输出。设定ConvLSTM为1层,每层隐藏单元节点数为30,卷积核(3,3),这个程序运行后可以发现,输入x的size为[64,20,1,64,64],输出的第一层h的size为[64,30,64,64],符合预期。