规则引擎的架构设计与系统实现
[未完待续中,后续代码实现优先发布到GitHub]
GitHub - failgoddess/rule: 规则引擎
MVP版本完成可以直接下载
业务规则、配置化编程、政策引擎、规则引擎
目录
ruleEngine
1. 背景
2. 方案考察
2.1. 硬编码:
2.2. Drools:
2.3. Urule:
2.4. 自研规则引擎
3. 能力要求
4. 名词解释
5. 概要设计
5.1. 功能模块划分
5.1.1. 公式推理器Calculator:
5.1.2. 指标解析器FormulaExecuter:
5.1.3. 动作执行器ActionExecuter:
5.1.4. 模型执行器RuleModel:
5.1.5. 模型构建器RuleModelBuilder:
5.1.6. 模型加载器RuleModelLoader:
5.1.7. 交互转换器:
5.2. 系统设计
5.2.1. 指标占位符
5.2.2. JSON出参解析
5.2.3. 关系运算符
5.2.4. 技术选型
5.3. 关键技术说明
5.3.1. 逻辑式编程
5.3.2. 分治策略
5.3.3. 决策树
5.3.4. 括号匹配算法
6. 详细设计
6.1. 数据模型
6.1.1. 规则ER-图
6.1.2. 关系数据库表结构
6.2. 执行逻辑图
6.2.1. 规则执行时序图
6.2.2. 指标解析执行流程
6.3. 缓存对象数据结构
6.4. 枚举值配置
1. 背景
在项目步入成熟期,规则类需求几乎占据了业务所有需求的半边天。一方面规则唯一不变的是“多变”,另一方面开发团队对“规则开发”的感受是乏味、疲惫和缺乏技术含量。如何解决规则开发的效率问题,最大化解放开发团队成为一个新的挑战。
规则底层采用规则引擎来实现。规则引擎是一种嵌入在应用程序中的组件,实现了将业务规则从应用程序代码中分离出来,并使用预定义的规则语义来编写业务规则。规则引擎接受数据输入,解释业务规则,并根据规则执行相应的业务逻辑。一个业务规则包含一组条件和在此条件下执行的操作,它们表示业务规则应用程序的一段业务逻辑。我们在业务中设置一个或者多个条件,当满足这些条件时触发相应的操作,规则引擎设计的初衷是可以将复杂多变的规则从硬编码中解放出来,以规则脚本的形式存放在文件或者数据库中,使得规则的变更不需要修改代码即可使用,做到最大程度的灵活。
2. 方案考察
现在市面上在做业务规则的过程中有多种实现方案:
2.1. 硬编码:
优点:
稳定性较佳:语法级别错误不会出现,由编译系统保证。
当规则较少、变动不频繁时,开发效率最高。
缺点:
规则迭代成本高:对规则的少量改动就需要走全流程(开发、测试、部署)。
规则开发和维护门槛高:规则对业务分析人员不可见。业务分析人员有规则变更需求后无法自助完成开发,需要由开发人员介入开发。
2.2. Drools:
优点:
策略规则和执行逻辑解耦方便维护。
缺点:
业务分析师无法独立完成规则配置:由于规则主体DSL是编程语言(支持Java, Groovy, Python),因此仍然需要开发工程师维护。
规则的语法仅适合扁平的规则,对于嵌套条件语义(then里嵌套when...then子句)的规则只能将条件进行笛卡尔积组合以后进行配置,不利于维护。
2.3. Urule:
优点:
可视化操作完善、功能强大
缺点:
不支持回溯:当前分支没有符合条件的之后不支持回溯
不支持动态加载数据:例如门店有等级、店龄、区域等若干属性,业务规则具体是根据店龄不同给出结果还是根据等级,属于规则的业务范畴,调用方并不关心。要是每次需要将所有可能用于规则判断的数据全部由调用方传入,无疑降低了规则的灵活性。
2.4. 自研规则引擎
在学习机器学习中决策树的算法时可以生成决策树的决策流图。决策树整体分为两个阶段:通过算法计算找出规律将规律构建决策模型、传入新数据基于决策流进行新的决策分析。这一点给我带来了很大的思想启发,配置规则的过程作为决策树的构建阶段,新数据决策为决策树的预测过程。出现多个决策路径组合的为最终结果的场景也可以理解决策森林算法的演化。
3. 能力要求
规则引擎的设计主要分为两部分:一部分是规则的维护,包括规则的创建、修改、删除;一部分是规则的执行。规则的维护部分侧重点是页面,我们需要将用户在页面上的操作转换为内置规则并保存到数据库中。在规则执行的过程中调用方只需要选择规则传入相应的数据即可获得决策结果。结合整体需求,规则引擎应该有可扩展、易维护的特点,先将规则引擎的功能需要实现的功能点总结如下:
指标部分(维护指标、计算执行指标)
模型维护(模型即实体,包括模型的创建以及模型属性的维护)
规则维护(包括对规则的增删改查)
条件维护(对规则条件的增删改查)
指标维护(对规则指标的增删改查)
结果维护(对规则结果的增删改查)
节点维护(包括静态节点和动态节点部分)
基于规则版本的决策记录(基于历史规则查看判定过程记录)
规则的版本控制
根据技术考察和能力要求对我们的规则引擎提出了更为全面的要求:
l 支持可视化的界面配置
l 支持嵌套条件语义
l 支持组合条件
l 支持动态加载
l 支持决策日志
l 支持规则历史版本
l 支持回溯
l 支持决策森林
4. 名词解释
| 术语及缩略语 | 名词解释 |
|---|---|
| 规则 | 每一个需要用于判定的业务场景就是一套规则,例如:可否邮寄判断;规则通常由每一个决策树的判定结果和操作符构成,例如:区域决策树AND(调整价决策树OR年份决策树);规则的本质是分类问题,由决策树和操作符构建的决策森林 |
| 节点 | 每一个规则内可能影响决策判定流程和结果的一个影响因素(维度) |
| 结果 | 一个规则中所有决策树中可能返回的结果,也就是一个决策树数的叶子结点,例如:可否邮寄判断的结果集合是是和否 |
| 决策树 | 决策树又称为判定树,是规则中的每一条判定路径,这个判定路径是根据不同节点以及条件执行不同分支路径,完整的判定路径分支、节点就是一棵决策树。考虑到不同连接接有同一个下一跳的情况决策树也被称为决策图 |
| 操作符 | 条件运算符 |
| 分支 | 一个分支包含多个连接是一组连接的集合。 |
| 条件 | 条件由被比较值、操作符、比较值构成。名称参考12/6=2 被除数、除数、商 |
| 连接 | 连接表示当前分支中一个节点在一组条件下要进入的下一跳,下一跳可以是另外一个连接也可以是结果。主要是达到执行对象切换的作用。同一个分支中的不同连接指向同过个下一跳逻辑关系为或的关系,同一个连接中不同的条件为且的关系。 |
| 指标 | 是规则流程执行中的元数据。 |
| 判定日志 | 每一次判定结果的日志记录 |
| 判定数据 | 用于规则判定时的入参对象 |
| 历史规则 | 规则的历史版本控制,每一次规则的修改都会引起一个版本变化,同一时间节点一个规则只会有一个生效的版本 |
5. 概要设计
5.1. 功能模块划分
5.1.1. 公式推理器Calculator:
用于计算公式例如((18)/9)9572>1008611计算,是指标解析器的底层实现,公式推理器一部分基于规则引擎实现、一部分基于手写运算符计算器实现
5.1.2. 指标解析器FormulaExecuter:
在公式类指标中用于公式的构建例如:目标库存为公式类指标,计算公式为平均周销*周数,由指标解析器将平均周销和周数替换成指定的数值
在传入类指标中用于将调用方的输入值转化成指标项例如目标库存中周数指标
在配置类指标中用于将配置到系统中的参数解析成指定指标
在动作类指标中用于组件构造动作执行器的执行入参并调用动作执行器。
5.1.3. 动作执行器ActionExecuter:
根据动作的类型传入参执行方法或者发送相应的请求,并负责解析返回值;不变型动作的执行可基于动作执行历史记录;
5.1.4. 模型执行器RuleModel:
负责解析规则模型按照深度优先的规则执行决策树,流程树
5.1.5. 模型构建器RuleModelBuilder:
确定一个规则编码负责从数据表中将于这个规则相关的数据加载到程序中,并组装出可以用于执行的规则模型JSON
5.1.6. 模型加载器RuleModelLoader:
负责加载配置好的模型,规则当前版本的加载优先级为Cache —> Redis —>模型构建器,规则历史版本的模型直接加载历史版本中的模型JSON
5.1.7. 交互转换器:
前端页面本着页面友好的原则会采用多种类型的页面展示和实现,前端数据和后端模型的数据会差异比较大所以在前后交互的过程中采用交互转换器进行数据转换,每种样式的展示方式都会有一个相应的转换器。
5.2. 系统设计
5.2.1. 指标占位符
${123}:调用id为123的指标
@{storeCode}:引用入参storeCode的实际值
%{ now()}:系统内置函数的返回值,这个系统特指规则引擎内部
#{123}:引用id为123的节点
["storeCode","1002"] 向被调用者传入参数storeCode为1002
5.2.2. JSON出参解析
请求型指标会访问一个url发送请求获得非接口返回值是JSON形式的数据,这里采用JsonPath插件对JSON进行解析获取需要的数据。完整语法请参考JsonPath官方文档
Map或对象:$.attr_name
List< Map或对象>$. data[i]. attr_name
i=*或者不配表示 取全部列表每一个item的attr_name逗号隔开
i=5 代表取索引为5 的attr_name
5.2.3. 关系运算符
系统内置操作符用于经销规则的逻辑判断,系统内置的每一条指令都有一个操作符,它表示该指令应进行什么性质的操作。不同的指令用操作符这个字段的不同编码来表示,每一种编码代表一种指令。
| 操作符 | 布尔 | 不区分字符串 | 字符串 | 数值 | 时间 | 列表 | |
|---|---|---|---|---|---|---|---|
| be | 介于(闭区间) | √ | √ | ||||
| bed | 介于(开区间) | √ | √ | ||||
| nbe | 不介于(闭区间) | √ | √ | ||||
| nbed | 不介于(开区间) | √ | √ | ||||
| cn | 包含 | √ | |||||
| ncn | 不包含 | √ | |||||
| en | 为空 | √ | √ | √ | √ | √ | √ |
| nn | 不为空 | √ | √ | √ | √ | √ | √ |
| eq | 等于 | √ | √ | √ | √ | √ | √ |
| eqd | 等于(不区分) | √ | √ | ||||
| neq | 不等于 | √ | √ | √ | √ | √ | √ |
| neqd | 不等于(不区分) | √ | √ | ||||
| ge | 大于等于 | √ | √ | ||||
| gt | 大于 | √ | √ | ||||
| in | 在集合 | √ | |||||
| nin | 不在集合 | √ | |||||
| le | 小于等于 | √ | √ | ||||
| lt | 小于 | √ | √ | ||||
| nre | 不正则 | √ | √ | ||||
| re | 正则 | √ | √ | ||||
| and | 并且 | √ | √ | √ | |||
| or | 或 | √ | √ | √ | |||
| not | 非 | √ | √ | √ | |||
| xor | 异或 | √ | √ | √ | |||
| lp | 左括号 | ||||||
| rp | 右括号 | ||||||
| add | 加 | √ | √ | ||||
| sub | 减 | √ | √ | ||||
| mul | 乘 | √ | |||||
| div | 除 | √ | |||||
| acm | 取余 | √ |
5.2.4. 技术选型
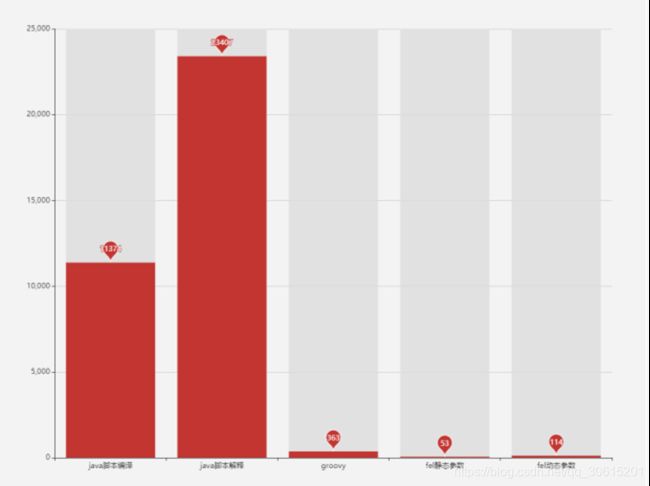
技术选型目前规则引擎领域开源的主要有Drools、IKExpression、Aviator、QLExpress、SimpleEL、Groovy、Fel等,鉴于Fel表达式求值语法简洁。同时其优异的性能表现,规则中心选型Fel。执行100 万次表达式求值的性能表现对比如下图:
5.3. 关键技术说明
本系统会用到:依赖性任务排序的算法(用于指标依赖执行顺序的执行顺序)、决策树算法、分治策略、括号匹配、策略模式、逻辑式编程、JSONPath、DFS算法、Cache、Fel。
5.3.1. 逻辑式编程
算法+数据结构=程序这是Pascal设计者Niklaus Wirth的一本著作的书名,它刻画了过程式尤其是结构化编程的思想。后来Robert Kowalski进一步提出:算法=逻辑+控制。其中逻辑是算法的核心,控制主要用于改进算法的效率。在逻辑式编程中,程序员只需表达逻辑,而控制交给编程语言的解释器或编译器去管理。
本规则引擎采用逻辑式编程的思想,由业务人员提供业务规则,开发负责将业务规则整理转义成解释器可解释执行的配置文件,在交由解释器和编译器解析执行。则可以做到业务只考虑规则构建、开发需表达逻辑、而执行交给解释器或编译器去管理,当调用方选择规则模型传入初始化数据后有加载器加载指定模型、执行器用相关的决策路径来控制执行返回规则结果达到一部分业务流程可配置的目的。
5.3.2. 分治策略
经销规则模块执行器采用分治策略实现深度遍历的决策树。分治策略是对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。
分治法的基本步骤 分治法在每一层递归上都有三个步骤:
分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题;
解决:若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题;
合并:将各个子问题的解合并为原问题的解。
5.3.3. 决策树
决策树机器学习预测方法,主要用于对离散型数据的分类。一个值经过相应的节点测验会跳过假分支进入真分支,所以一组值经过决策树以后,就会形成从树跟到结果节点的一条唯一路径。所以它除了可以对输入进行分类之外,还能给出如此分类的解释。算法实现分为:特征选择、决策树的训练构建决策模型、模型对新数据测预测;
规则引擎的数据维度抽取参考特征选择,也是在硬编码中用于if判断的数据字段;决策树模型的构建采用业务人员在实际工作中的经验规则;传入数据由模型执行类比对模型预测的阶段;
5.3.4. 括号匹配算法
指标的公式是可以嵌套的所以需要来解析公式需要用到括号匹配算法:
123 门店平均销量指标 入参门店编码 sku编码 天数
456 门店可用库存指标 入参门店编码 sku编码
789 门店需求量指标公式为:门店10天的sku需求量=10天门店最近30天平均该sku销量-门店前库存;可表示为 10${123(storeCode:@{storeCode},skuCode:@{skuCode},dayNumber:30)}-${345(storeCode:@{storeCode},skuCode:@{skuCode})}
这个解析的过程是一个采用分治策略的递归解析过程;用到括号匹配算法来解析公式;
原括号匹配算法只是在结构出判断堆栈是否为空用于判断是否成对出现,这里需要做一个改造每一次堆栈为空的时候表示这是一个最大单元也就是整个公式最多可以分为几段 门店需求量就可以分为两段 ${123(storeCode:@{storeCode},skuCode:@{skuCode},dayNumber:30)}和${345(storeCode:@{storeCode},skuCode:@{skuCode})}
在利用分治递归的思想将每一段分别处理

6. 详细设计
6.1. 数据模型
6.1.1. 规则ER-图

6.1.2. 关系数据库表结构
节点表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| Id | int8 | 64 | 节点表 |
| rule_id | int8 | 64 | 所属规则ID |
| Name | varchar | 64 | 节点标题 |
| note_type | int4 | 32 | 节点数据来源类型:10传入20指标值 |
| note_category | int4 | 32 | 节点类型:1可变、0不可变 |
| Attribute | varchar | 128 | 判定数据对象的字段 |
| note_category | int4 | 32 | 节点类型:1可变、0不可变 |
| value_type | int4 | 32 | 10数字20时间30字符串35不区分字符串40列表 |
| parameter | varchar | 255 | 参数用json表示,节点调用指标的参数只能是配置好的固定值或者传入节点的数据值 |
| quota_id | int8 | 64 | 指标id |
| Remark | varchar | 512 | 备注 |
结果表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| Id | int8 | 64 | 结果表 |
| rule_id | int8 | 64 | 所属规则ID |
| Name | varchar | 64 | 结果标题 |
| Data | varchar | 128 | 结果数据 |
| result_type | int4 | 32 | 结果类型10固定值20节点值30指标值 |
| node_id | int8 | 64 | 节点ID |
| quota_id | int8 | 64 | 指标ID |
| parameter | varchar | 255 | 参数用json表示 |
| Remark | varchar | 512 | 备注 |
规则表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| Id | int8 | 64 | 规则表 |
| Name | varchar | 64 | 规则名称 |
| Code | varchar | 64 | 规则编码 |
| Content | varchar | 32 | 规则内容 |
| data_type | varchar | 32 | 结果数据的类型 |
| node_info | varchar | 32 | 支持的对象节点的描述 |
| node_attribute | varchar | 32 | 支持的对象节点的属性 |
| Remark | varchar | 255 | 备注 |
决策树表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| Id | int8 | 64 | 经销商商品授权表 |
| rule_id | int8 | 64 | 规则ID |
| code | varchar | 64 | 决策树编码 |
| first_branch_id | int8 | 64 | 第一跳ID(分支) |
| name | varchar | 64 | 决策树标题 |
| remark | varchar | 255 | 备注 |
运算符表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| id | int8 | 64 | 运算符表 |
| code | varchar | 64 | 编码 |
| operation_type | int4 | 32 | 类型:1关系运算符2逻辑运算符3优先级运算符4算数运算符 |
| name | varchar | 128 | 运算符标题 |
| remark | varchar | 255 | 备注 |
分支表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| id | int8 | 64 | 分支表 |
| node_id | int8 | 64 | 节点ID |
| node_type | int8 | 64 | 节点数据类型 |
| name | varchar | 64 | 条件名称 |
| operation_id | int8 | 64 | 操作符ID |
| threshold | varchar | 32 | 阀值 |
| rule_id | int8 | 64 | 规则ID |
| tree_id | int8 | 64 | 决策树ID |
| remark | varchar | 512 | 备注 |
条件表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| id | int8 | 64 | 条件表 |
| link_id | int8 | 64 | 连接ID |
| priority | Int4 | 64 | 优先级 |
| name | varchar | 64 | 条件名称 |
| operation_id | int8 | 64 | 操作符ID |
| threshold | varchar | 32 | 阀值 |
| rule_id | int8 | 64 | 规则ID |
| branch_id | int8 | 64 | 分支ID |
| threshold_type | Int4 | 32 | 阀值类型10固定值20节点值 |
| note_id | int8 | 64 | 节点ID |
| remark | varchar | 512 | 备注 |
连接表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| id | int8 | 64 | 连接表 |
| name | varchar | 64 | 连接名称 |
| priority | int4 | 64 | 优先级 |
| tree_id | int8 | 64 | 决策树ID |
| branch_id | int8 | 64 | 所属分支ID |
| next_branch_id | int8 | 64 | 下一跳分支ID |
| next_type | int4 | 32 | 下一跳类型 |
| next_result_id | int8 | 64 | 下一跳结果ID |
| rule_id | int8 | 64 | 规则ID |
| remark | varchar | 512 | 备注 |
判定数据表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| id | int8 | 64 | 判定数据表 |
| rule_id | int8 | 64 | 规则ID |
| rule_version | varchar | 128 | 规则版本号 |
| data | varchar | 128 | 判定数据 |
| result | varchar | 64 | 结果(不一定来源于结果) |
| result_id | int8 | 64 | 结果ID(为空则表示规则结果为和合成结果) |
| history_id | int8 | 64 | 历史ID |
| factor | varchar | 128 | 决定因素 |
| remark | varchar | 512 | 备注 |
判定日志表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| id | int8 | 64 | 判定数据表 |
| rule_id | int8 | 64 | 规则ID |
| rule_version | varchar | 128 | 规则版本号 |
| judge_data_id | int8 | 64 | 判定数据ID |
| flag | bool | 0 | 是否符合 |
| history_id | int8 | 64 | 历史ID |
| node_id | int8 | 64 | 节点ID |
| link_id | int8 | 64 | 连接ID |
| condition_id | int8 | 64 | 条件ID |
| branch_id | int8 | 64 | 分支ID |
| remark | varchar | 512 | 备注 |
历史规则表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| id | int8 | 64 | 历史规则表 |
| rule_id | int8 | 64 | 规则ID |
| rule_version | varchar | 128 | 规则版本号 |
| start_time | timestamp | 64 | 开始时间 |
| end_time | timestamp | 64 | 结束时间 |
| remark | varchar | 512 | 备注 |
指标表
| 字段 | 数据类型 | 长度 | 说明 |
|---|---|---|---|
| id | int8 | 64 | 配置表 |
| quota_type | int4 | 32 | 指标类型10方法类20请求类30公式类40配置类 |
| name | varchar | 255 | 指标名称 |
| value_type | int4 | 32 | 数据值类型10数字20时间30字符串35不区分字符串40列表 |
| java_method | varchar | 255 | 10方法类所配置的方法 |
| request_url | varchar | 255 | 20请求类请求路径 |
| request_method | Varchar | 255 | 20请求类请求方法,目前只支持get、post |
| formula | Varchar | 255 | 30公式类计算公式 |
| deploy | Varchar | 255 | 40配置类配置 |
| parameter | Varchar | 255 | 参数用json表示 |
| feedback_rule | Varchar | 255 | 返回值取值规则 |
| necessary | varchar | 255 | 必须的入参也就是调用者必传的字段 |
| cache_ime | varchar | 255 | 请求型缓存时间 |
| remark | varchar | 512 | 备注 |
6.2. 执行逻辑图
6.2.1. 规则执行时序图
6.2.2. 指标解析执行流程
6.2.2.1. 公式型指标
10*${123(attr1:12,attr2:${456})}+2
10*
${123(attr1:12,attr2:${456})}
123 的指标
解析123指标需要的入参
attr1=12
attr2=${456}
${456}
456 的指标
456 的指标 执行
123入参构建完成
123 的指标 执行
+2
6.2.2.2. 请求型指标
6.3. 缓存对象数据结构
6.4. 枚举值配置
| 枚举类型 | 枚举值 | 枚举描述 |
|---|---|---|
| 节点数据来源类型 | 10 | 传入值 |
| 20 | 指标值 | |
| 指标类型 | 10 | 方法类 |
| 20 | 请求类 | |
| 30 | 公式类 | |
| 40 | 配置类 | |
| 结果类型 | 10 | 固定值 |
| 20 | 节点值 | |
| 30 | 指标值 | |
| 下一跳类型 | 1 | 分支 |
| 2 | 结果 | |
| 阀值类型 | 10 | 固定值 |
| 20 | 节点值 | |
| 数据值类型 | 10 | 数值 |
| 20 | 时间 | |
| 30 | 字符串 | |
| 35 | 不区分大小字符串 | |
| 40 | 列表 |