Transformer中的position encoding
参考 Transformer中的position encoding(位置编码一)_zuoyou-HPU的博客-CSDN博客
正余弦编码
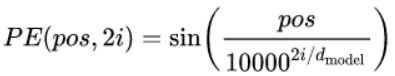

公式解读:
1.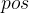 :假设我们有一个输入的句子,token切分之后有250个token,则表示的是第几个token;
:假设我们有一个输入的句子,token切分之后有250个token,则表示的是第几个token;
2. :对应embedding size, 表示的是embedding向量中的第 个元素,例如某一个token被token embedding嵌入为 [0.1,0.15,0.12,0.03],则
:对应embedding size, 表示的是embedding向量中的第 个元素,例如某一个token被token embedding嵌入为 [0.1,0.15,0.12,0.03],则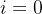 对应0.1的位置,
对应0.1的位置,![]() 对应0.15的位置;
对应0.15的位置;
3.由于transformer的论文中使用了2i和2i+1用于划分embedding 矩阵的奇数列和偶数列,因此 最大等于embedding_size//2,例如embedding size=4,则 最大为2;
4. : 指的就是embedding size
: 指的就是embedding size
实现步骤
1.创建mask
假设mask为4×4大小,输入图像大小为3×3。
下图为mask生成的4*4维度的矩阵,根据对应与输入图像大小3*3生成以下的mask编码tensor,下右图为反mask编码tensor,这一步就得到了图像的大小及对应与mask下的位置。

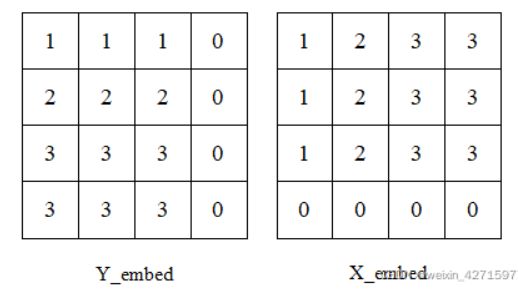
2.生成Y_embed和X_embed的tensor
y_embed = not_mask.cumsum(1, dtype=torch.float32) #在行方向累加#(b , h , w)
x_embed = not_mask.cumsum(2, dtype=torch.float32) #在列方向累加#(b , h , w)Y_embed对为mask编码True的进行行方向累加1,X_embed对为mask编码True的进行列方向累加1。如图:
3. 对position进行编码
# 假设词嵌入生成10维向量
num_pos_feats = 10
dim_t = torch.arange(num_pos_feats, dtype=torch.float32) #生成10维数
dim_t = 10000 ** (2 * (dim_t // 2) / num_pos_feats) #对应公式中的分母4.生成pos_x以及pos_y
# x_embed[:, :, None]维度为(4,4,1),dim_t维度为(10,1)
# 相当于把x_embed[:, :, None]复制10次摞在一起,再每个数字除以dim_t
pos_x = x_embed[:, :, None] / dim_t
pos_y = y_embed[:, :, None] / dim_t
直观效果如图:

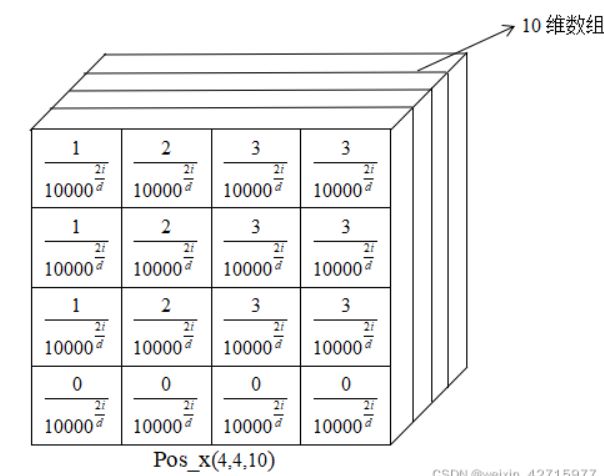
其中i对应的是10维position的不同维度的数,d代表的是position编码维度。
# pos_x[:, :, 0::2]维度为(4,4,5),相当于取出0、2、4、6、8层
# pos_x[:, :, 1::2]维度为(4,4,5),相当于取出1、3、5、7、9层
# 对偶数层取sin,奇数层取cos
# dim=3,是对最低维度进行拼接,
# 拿出pos_x第0层的第一个数的sin值,和pos_x第1层的第一个数的cos值,进行拼接。以此类推。
# 拼接后维度为(4,4,5,2)
# flatten(2),在第二个维度展平,结果维度为(4,4,10)
pos_x = torch.stack((pos_x[:, :, 0::2].sin(), pos_x[:, :, 1::2].cos()), dim=3).flatten(2)
pos_y = torch.stack((pos_y[:, :, 0::2].sin(), pos_y[:, :, 1::2].cos()), dim=3).flatten(2)以上步骤实现的直观图如下:(建议放大看)

5.组合Pos_x和Pos_y
因为上述位置编码的生成是行列方向分开的,这一步需要进行组合。
# pos_y和pos_x维度均为(4,4,10)
# dim=2,结果的维度为(4,4,20)
pos = torch.cat((pos_y, pos_x), dim=2)
