olap/clickhouse-存储
NSM
DBMS 将单个元组的几乎所有属性连续地存储在一个页面中。
这种存储是 OLTP 工作负载的理想选择,OLTP 的事务倾向于访问单个实体,并且插入工作的负载比较重。
- 使用 tuple-at-a-time 的迭代器处理模型。
NSM 数据库页面大小通常是 4KB 硬件页面的某个恒定倍数。 - 例如: Oracle(4 KB),Postgres(8 KB),MySQL(16 KB)
一个面向磁盘的 NSM 系统将元组的 固定长度 和 可变长度 属性连续地存储在一个有槽 (slot) 的页面中。
元组的 record ID(page#, slot#)是 DBMS 唯一识别一个物理元组的方式。
行存优点
- 快速插入、更新和删除。
- 适合于需要整个元组的查询(OLTP)。
- 可以使用面向索引的物理存储进行聚簇(Clustering)。
行存缺点
- 不适合扫描全表的很大一部分行或者扫描全表的部分列。
- 在访问模式中的内存定位,开销可能非常糟糕。
- 因为在一个页面中存在多个值域,所以不适合压缩。
DSM
将属性和元数据(例如空值)存储在 **固定长度 **的独立数组中。
- 大多数系统使用这些数组的偏移量来识别唯一的物理 tuple。
- 需要处理可变长度的值。
列存优点
- 减少每次查询浪费的 I/O 量,因为 DBMS 只读取它需要的数据。
- 由于增加了局部性和缓存数据重用,查询处理速度更快。
- 更好的数据压缩。
列存缺点
- 由于元组的拆分/拼接/重组,对点查询、插入、更新和删除的速度更慢
DSM案例
C-Store
C-Store 是关系型数据库,它的逻辑表和其他数据库中的并没有什么不同。但是在 C-Store 内部,逻辑表被纵向拆分成 projections,每个 projection 可以包含一个或多个列,甚至可以包含来自其他逻辑表的列(构成索引)。当然,每个列至少会存在于一个 projections 上。
下图的例子中,EMP 表被存储为 3 个 projections,DEPT 被存储为 1 个 projection。每个 projection 按照各自的 sort key 排序,在图中用下划线表示 sort key。

Projection 内是以列式存储的:里面的每个列分别用一个数据结构存放。为了避免列太长引起问题,也支持每个 projection 以 sort key 的值做横向切分。
查询时 C-Store 会先选择一组能覆盖结果中所有列的 projections 集合作为 covering set,然后进行 join 计算重构出原来的行。为了能高效地进行 projections 的 join(即按照另一个 key 重新排序),引入 join index 作为辅助,其中存储了 proj1 到 proj2 的下标映射关系。
Projection 是有冗余性的,常常 1 个列会出现在多个 projection 中,但是它们的顺序也就是 sort key 并不相同,因此 C-Store 在查询时可以选用最优的一组 projections,使得查询执行的代价最小。
巧妙的是,C-Store 的 projection 冗余性还用来实现 K-safe 高可用(容忍最多 K 台机器故障),当部分节点宕机时,只要 C-Store 还能找到某个 covering set 就能执行查询,虽然不一定是最优的 covering set 组合。
从另一个角度看,C-Store 的 Projection 可以看作是一种物化(materialized)的查询结果,即查询结果在查询执行前已经被预先计算好;并且由于每个列至少出现在一个 Projection 当中,没有必要再保存原来的逻辑表。
为任意查询预先计算好结果显然不现实,但是如果物化某些经常用到的中间视图,就能在预计算代价和查询代价之间获得一个平衡。C-Store 物化的正是以某个 sort key 排好序(甚至 JOIN 了其他表)的一组列数据,同时预计算的还有 join index。
Apache ORC
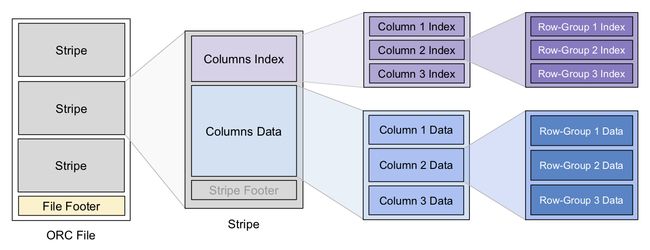
- File Level:即一个 ORC 文件,Footer 中保存了数据的 meta 信息,还有文件数据的索引信息,例如各列数据的最大最小值(范围)、NULL 值分布、布隆过滤器等,这些信息可用来快速确定该文件是否包含要查询的数据。每个 ORC 文件中包含多个 Stripe。
- Stripe Level 对应原表的一个范围分区,里面包含该分区内各列的值。每个 Stripe 也有自己的一个索引放在 footer 里,和 file-level 索引类似。
- Row-Group Level :一列中的每 10000 行数据构成一个 row-group,每个 row-group 拥有自己的 row-level 索引,信息同上。
ORC 里的 Stripe 就像传统数据库的页,它是 ORC 文件批量读写的基本单位。这是由于分布式储存系统的读写延迟较大,一次 IO 操作只有批量读取一定量的数据才划算。这和按页读写磁盘的思路也有共通之处。
像其他很多储存格式一样,ORC 选择将统计数据和 Metadata 放在 File 和 Stripe 的尾部而不是头部。
但 ORC 在 Stripe 的读写上还有一点优化,那就是把分区粒度小于 Stripe 的结构(如 Column 和 Row-Group)的索引统一抽取出来放到 Stripe 的头部。这是因为在批处理计算中一般是把整个 Stripe 读入批量处理的,将这些索引抽取出来可以减少在批处理场景下需要的 IO(批处理读取可以跳过这一部分)。
Apache ORC 提供有限的 ACID 事务支持。受限于分布式文件系统的特点,文件不能随机写,那如何把修改保存下来呢?
类似于 LSM-Tree 中的 MVCC 那样,writer 并不是直接修改数据,而是为每个事务生成一个 delta 文件,文件中的修改被叠加在原始数据之上。当 delta 文件越来越多时,通过 minor compaction 把连续多个 delta 文件合成一个;当 delta 变得很大时,再执行 major compaction 将 delta 和原始数据合并。
这种保持基线数据不变、分层叠加 delta 数据的优化方式在列式存储系统中十分常见,是一种通用的解决思路。
别忘了 ORC 的 delta 文件也是写入到分布式储存中的,因此每个 Delta 文件的内容不宜过短。这也解释了 ORC 文件虽然支持事务,但是主要是对批量写入的事务比较友好,不适合频繁且细小的写入事务的原因。
Dremel
Dremel 是 Google 研发的用于大规模只读数据的查询系统,用于进行快速的 ad-hoc 查询,弥补 MapReduce 交互式查询能力的不足。为了避免对数据的二次拷贝,Dremel 的数据就放在原处,通常是 GFS 这样的分布式文件系统,为此需要设计一种通用的文件格式。
Dremel 的系统设计和大多 OLAP 的列式数据库并无太多创新点,但是其精巧的存储格式却变得流行起来,Apache Parquet 就是它的开源复刻版。注意 Parquet 和 ORC 一样都是一种存储格式,而非完整的系统。
嵌套数据模型
Google 内部大量使用 Protobuf 作为跨平台、跨语言的数据序列化格式,相比 JSON 要更紧凑并具有更强的表达能力。Protobuf 不仅允许用户定义必须(required)和可选(optinal)字段,还允许用户定义 repeated 字段,意味着该字段可以出现 0~N 次,类似变长数组。
Dremel 格式的设计目的就是按列来存储 Protobuf 的数据。由于 repeated 字段的存在,这要比按列存储关系型的数据困难一些。一般的思路可能是用终止符表示每个 repeat 结束,但是考虑到数据可能很稀疏,Dremel 引入了一种更为紧凑的格式。
作为例子,下图左半边展示了数据的 schema 和 2 个 Document 的实例,右半边是序列化之后的各个列。序列化之后的列多出了 R、D 两列,分别代表 Repetition Level 和 Definition Level,通过这两个值就能确保唯一地反序列化出原本的数据。

Repetition Level 表示当前值在哪一个级别上重复。对于非 repeated 字段只要填上 trivial 值 0 即可;否则,只要这个字段可能出现重复(无论本身是 repeated 还是外层结构是 repeated),应当为 R 填上当前值在哪一层上 repeat。
举个例子说明:对于 Name.Language.Code 我们一共有三条非 NULL 的记录。
- 第一个是 en-us,出现在第一个 Name 的第一个 Lanuage 的第一个 Code 里面。在此之前,这三个元素是没有重复过的,都是第一次出现。所以其 R=0
- 第二个是 en,出现在下一个 Language 里面。也就是说 Language 是重复的元素。Name.Language.Code 中 Language 排第二个,所以其 R=2
- 第三个是 en-gb,出现在下一个 Name 中,Name 是重复元素,排第一个,所以其 R=1
注意到 en-gb 是属于第 3 个 Name 的而非第 2 个 Name,为了表达这个事实,我们在 en 和 en-gb 中间放了一个 R=1 的 NULL。
Definition Level 是为了说明 NULL 被定义在哪一层,也就宣告那一层的 repeat 到此为止。对于非 NULL 字段只要填上 trivial 值,即数据本身所在的 level 即可。
同样举个例子,对于 Name.Language.Country 列
- us 非 NULL 值填上 Country 字段的 level 即 D=3
- NULL 在 R1 内部,表示当前 Name 之内、后续所有 Language 都不含有 Country 字段。所以 D 为 2。
- NULL 在 R1 内部,表示当前 Document 之内、后续所有 Name 都不含有 Country 字段。所以 D 为 1。
- gb 非 NULL 值填上 Country 字段的 level 即 D=3
- NULL 在 R2 内部,表示后续所有 Document 都不含有 Country 字段。所以 D 为 0。
可以证明,结合 R、D 两个数值一定能唯一构建出原始数据。为了高效编解码,Dremel 在执行时首先构建出状态机,之后利用状态机处理列数据。不仅如此,状态机还会结合查询需求和数据的 structure 直接跳过无关的数据。
Apache Parquet
Parquet 文件格式是自解析的,采用 thrift 格式定义的文件 schema 以及其他元数据信息一起存储在文件的末尾。
文件存储格式示例:
整个文件(表)有 N 个列,划分成了 M 个行组,每个行组都有所有列的一个 Chunk 和其元数据信息。文件的元数据信息存储在数据之后,包含了所有列块元数据信息的起始位置。读取的时候首先从文件末尾读取文件元数据信息,再在其中找到感兴趣的 Column Chunk 信息,并依次读取。文件元数据信息放在文件最后是为了方便数据依序一次性写入。
具体的存储格式展示图:

元数据信息
Parquet 总共有 3 种类型的元数据:文件元数据、列(块)元数据和 page header 元数据。所有元数据都采用 thrift 协议存储。具体信息如下所示:

mergetree
MergeTree 的数据只有一份:*.bin。
MergeTree里面一个分区叫part.
a.bin 是字段 a 的数据,b.bin 是字段 b 的数据,c.bin 是字段 c 的数据,也就是大家熟悉的列存储。
各个 bin 文件以 b.bin排序对齐(b 是排序键),如图:

ClickHouse MergeTree 把 bin 文件根据颗粒度(GRANULARITY)划分为多个颗粒(granule),每个 granule 单独压缩存储。
SETTINGS index_granularity=3 表示每 3 行数据为一个 granule,分区目前只有 7 条数据,所以被划分成 3 个 granule(三个色块):
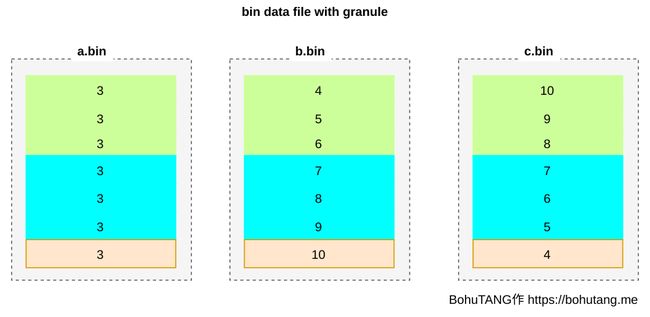
为方便读取某个 granule,使用 *.mrk 文件记录每个 granule 的 offset,每个 granule 的 header 里会记录一些元信息,用于读取解析:

索引
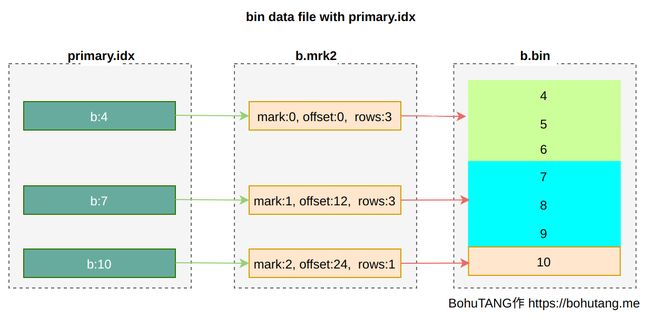
1. primary index
主键索引,可通过[PRIMARY KEY expr]指定,默认是 ORDER BY 字段值。
注意 ClickHouse primary index 跟 MySQL primary key 不是一个概念。
在稀疏点的选择上,取每个 granule 最小值:
- skipping index
普通索引。
INDEXidx_c© TYPE minmax GRANULARITY 1 针对字段 c 创建一个 minmax 模式索引。
GRANULARITY 是稀疏点选择上的 granule 颗粒度,GRANULARITY 1 表示每 1 个 granule 选取一个:

- partition minmax index
针对分区键,MergeTree 还会创建一个 min/max 索引,来加速分区选择。

clickhouse源码
PODArray和ArenaAllocator
PODArray
结构
PodArray是clickhouse设计非常精巧的一个结构。
它不会像vector一样初始化元素,也不会reserve,push_back性能是vector的2.5倍。
它的结构如下:

pad_left优点是可以访问下标-1,arr[-1]是合法的,外部调用在批处理时无需特殊考虑i=0的情况了,比如求差,可以统一写成arr[i]-arr[i-1],删掉了if i==0的那条语句,并且消除了分支。
allocator通过模版而不是构造参数传递,优化了小对象的情况。
移动构造和移动赋值
这里会根据右值是在堆还是栈上分配的,采用不同的赋值逻辑,减少无效拷贝
栈分配的内存在Allocator的
alignas(Alignment) char stack_memory[_initial_bytes];
- swap_stack_heap 栈接管堆,堆重新分配
- 都在栈上,std::swap逐个元素交换
- 都在堆上,交换资源
- 有未分配的PodArray,如果另一方在栈上,先dealloc,再在栈上分配否则执行3
PODArray(PODArray && other) noexcept
{
this->swap(other);
}
PODArray & operator=(PODArray && other) noexcept
{
this->swap(other);
return *this;
}
template <typename... TAllocatorParams>
void swap(PODArray & rhs, TAllocatorParams &&... allocator_params)
{
#ifndef NDEBUG
this->unprotect();
rhs.unprotect();
#endif
/// Swap two PODArray objects, arr1 and arr2, that satisfy the following conditions:
/// - The elements of arr1 are stored on stack.
/// - The elements of arr2 are stored on heap.
auto swap_stack_heap = [&](PODArray & arr1, PODArray & arr2)
{
size_t stack_size = arr1.size();
size_t stack_allocated = arr1.allocated_bytes();
size_t heap_size = arr2.size();
size_t heap_allocated = arr2.allocated_bytes();
/// Keep track of the stack content we have to copy.
char * stack_c_start = arr1.c_start;
/// arr1 takes ownership of the heap memory of arr2.
arr1.c_start = arr2.c_start;
arr1.c_end_of_storage = arr1.c_start + heap_allocated - arr2.pad_right - arr2.pad_left;
arr1.c_end = arr1.c_start + this->byte_size(heap_size);
/// Allocate stack space for arr2.
arr2.alloc(stack_allocated, std::forward<TAllocatorParams>(allocator_params)...);
/// Copy the stack content.
memcpy(arr2.c_start, stack_c_start, this->byte_size(stack_size));
arr2.c_end = arr2.c_start + this->byte_size(stack_size);
};
auto do_move = [&](PODArray & src, PODArray & dest)
{
if (src.isAllocatedFromStack())
{
dest.dealloc();
dest.alloc(src.allocated_bytes(), std::forward<TAllocatorParams>(allocator_params)...);
memcpy(dest.c_start, src.c_start, this->byte_size(src.size()));
dest.c_end = dest.c_start + this->byte_size(src.size());
src.c_start = Base::null;
src.c_end = Base::null;
src.c_end_of_storage = Base::null;
}
else
{
std::swap(dest.c_start, src.c_start);
std::swap(dest.c_end, src.c_end);
std::swap(dest.c_end_of_storage, src.c_end_of_storage);
}
};
if (!this->isInitialized() && !rhs.isInitialized())
{
return;
}
else if (!this->isInitialized() && rhs.isInitialized())
{
do_move(rhs, *this);
return;
}
else if (this->isInitialized() && !rhs.isInitialized())
{
do_move(*this, rhs);
return;
}
if (this->isAllocatedFromStack() && rhs.isAllocatedFromStack())
{
size_t min_size = std::min(this->size(), rhs.size());
size_t max_size = std::max(this->size(), rhs.size());
for (size_t i = 0; i < min_size; ++i)
std::swap(this->operator[](i), rhs[i]);
if (this->size() == max_size)
{
for (size_t i = min_size; i < max_size; ++i)
rhs[i] = this->operator[](i);
}
else
{
for (size_t i = min_size; i < max_size; ++i)
this->operator[](i) = rhs[i];
}
size_t lhs_size = this->size();
size_t lhs_allocated = this->allocated_bytes();
size_t rhs_size = rhs.size();
size_t rhs_allocated = rhs.allocated_bytes();
this->c_end_of_storage = this->c_start + rhs_allocated - Base::pad_right - Base::pad_left;
rhs.c_end_of_storage = rhs.c_start + lhs_allocated - Base::pad_right - Base::pad_left;
this->c_end = this->c_start + this->byte_size(rhs_size);
rhs.c_end = rhs.c_start + this->byte_size(lhs_size);
}
else if (this->isAllocatedFromStack() && !rhs.isAllocatedFromStack())
{
swap_stack_heap(*this, rhs);
}
else if (!this->isAllocatedFromStack() && rhs.isAllocatedFromStack())
{
swap_stack_heap(rhs, *this);
}
else
{
std::swap(this->c_start, rhs.c_start);
std::swap(this->c_end, rhs.c_end);
std::swap(this->c_end_of_storage, rhs.c_end_of_storage);
}
}
push_back
注解中提到,podarray的push_back性能是vector的2.5倍,这是怎么做到的呢?
首先我们知道,vector因为不支持原地扩容而广受诟病:
https://www.zhihu.com/question/384869006
其根本原因在于,realloc可能会分配新的线性地址空间:
 那么podarray是不是解决了这个问题呢?这里我们需要看看clickhouse内存分配器Arena的源码。
那么podarray是不是解决了这个问题呢?这里我们需要看看clickhouse内存分配器Arena的源码。
Arena这个词有没有很熟悉的感觉?没错,glibc的ptmalloc就用了这个概念,我以前写过一篇分析https://www.yuque.com/treblez/qksu6c/yxl59pkvczqot9us?singleDoc# 《ptmalloc:从内存虚拟化说起》
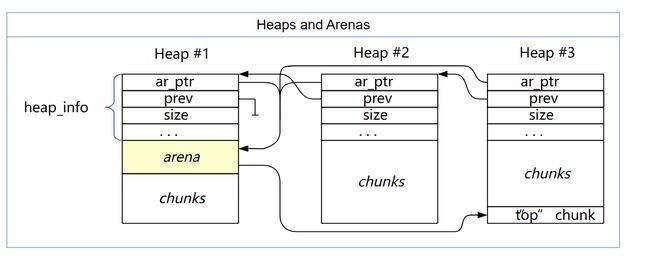
ptmalloc中一个arena用于管理多个heap,heap中有各种各样的bin指向内存管理的最小单位chunk。
在podarray中,reserveForNextSize会进行两倍扩容,然后调用到TAllocator的realloc进行分配:
template <typename U, typename ... TAllocatorParams>
void push_back(U && x, TAllocatorParams &&... allocator_params) /// NOLINT
{
if (unlikely(this->c_end + sizeof(T) > this->c_end_of_storage))
this->reserveForNextSize(std::forward<TAllocatorParams>(allocator_params)...);
// 原地构造,相当于实现了emplace_back的语义
new (t_end()) T(std::forward<U>(x));
this->c_end += sizeof(T);
}
template <typename ... TAllocatorParams>
void reserveForNextSize(TAllocatorParams &&... allocator_params)
{
if (empty())
{
// The allocated memory should be multiplication of ELEMENT_SIZE to hold the element, otherwise,
// memory issue such as corruption could appear in edge case.
realloc(std::max(integerRoundUp(initial_bytes, ELEMENT_SIZE),
minimum_memory_for_elements(1)),
std::forward<TAllocatorParams>(allocator_params)...);
}
else
realloc(allocated_bytes() * 2, std::forward<TAllocatorParams>(allocator_params)...);
}
template <typename ... TAllocatorParams>
void realloc(size_t bytes, TAllocatorParams &&... allocator_params)
{
if (c_start == null)
{
alloc(bytes, std::forward<TAllocatorParams>(allocator_params)...);
return;
}
unprotect();
ptrdiff_t end_diff = c_end - c_start;
char * allocated = reinterpret_cast<char *>(
TAllocator::realloc(c_start - pad_left, allocated_bytes(), bytes, std::forward<TAllocatorParams>(allocator_params)...));
c_start = allocated + pad_left;
c_end = c_start + end_diff;
c_end_of_storage = allocated + bytes - pad_right;
}
稍微大一点的项目都会实现自己的内存分配器,让我们看看clickhouse的ArenaAllocator怎么做的。
ArenaAllocator
MemoryChunk
clickhouse沿用了ptmalloc的chunk的概念,它使用了“空基类优化”,继承自Allocator类,并设置为private,这样就可以使用Allocator类的方法,但是不能直接访问它的数据成员。
ASAN_POISON_MEMORY_REGION 是来自AddressSanitizer (ASan)的一个宏。AddressSanitizer是一种内存错误检测器,它可以检查出C++代码中的内存泄漏、越界等问题。
我们接着看它调用的alloc.
struct alignas(16) MemoryChunk : private Allocator<false> /// empty base optimization
{
char * begin = nullptr;
char * pos = nullptr;
char * end = nullptr; /// does not include padding.
// 只有一个前向指针
std::unique_ptr<MemoryChunk> prev;
MemoryChunk()
{
}
void swap(MemoryChunk & other)
{
std::swap(begin, other.begin);
std::swap(pos, other.pos);
std::swap(end, other.end);
prev.swap(other.prev);
}
MemoryChunk(MemoryChunk && other)
{
*this = std::move(other);
}
MemoryChunk & operator=(MemoryChunk && other)
{
swap(other);
return *this;
}
MemoryChunk(size_t size_)
{
ProfileEvents::increment(ProfileEvents::ArenaAllocChunks);
ProfileEvents::increment(ProfileEvents::ArenaAllocBytes, size_);
begin = reinterpret_cast<char *>(Allocator<false>::alloc(size_));
pos = begin;
end = begin + size_ - pad_right;
ASAN_POISON_MEMORY_REGION(begin, size_);
}
~MemoryChunk()
{
if (empty())
return;
/// We must unpoison the memory before returning to the allocator,
/// because the allocator might not have asan integration, and the
/// memory would stay poisoned forever. If the allocator supports
/// asan, it will correctly poison the memory by itself.
ASAN_UNPOISON_MEMORY_REGION(begin, size());
Allocator<false>::free(begin, size());
}
bool empty() const { return begin == end;}
size_t size() const { return end + pad_right - begin; }
size_t remaining() const { return end - pos; }
};
下层alloc
这里会一路调用到Allocator::allocNoTrack
MALLOC_MIN_ALIGNMENT默认是8,因为malloc默认会8字节对齐
如果要求的对齐字节数大于8,那么使用posix_memalign(https://man7.org/linux/man-pages/man3/posix_memalign.3.html),分配对齐的字节。
void * allocNoTrack(size_t size, size_t alignment)
{
void * buf;
if (alignment <= MALLOC_MIN_ALIGNMENT)
{
if constexpr (clear_memory)
buf = ::calloc(size, 1);
else
buf = ::malloc(size);
if (nullptr == buf)
DB::throwFromErrno(fmt::format("Allocator: Cannot malloc {}.", ReadableSize(size)), DB::ErrorCodes::CANNOT_ALLOCATE_MEMORY);
}
else
{
buf = nullptr;
int res = posix_memalign(&buf, alignment, size);
if (0 != res)
DB::throwFromErrno(fmt::format("Cannot allocate memory (posix_memalign) {}.", ReadableSize(size)),
DB::ErrorCodes::CANNOT_ALLOCATE_MEMORY, res);
if constexpr (clear_memory)
memset(buf, 0, size);
}
if constexpr (populate)
prefaultPages(buf, size);
return buf;
}
上层alloc
alloc是arena的一个方法,用于不对齐的分配,分配0字节也不会返回nullptr。
unlikely宏定义如下:
define unlikely(x) (__builtin_expect(!!(x), 0))
顺便提一句,clickhouse对于缓存行的使用非常细致,到处都是 [[likely]]和[[unlikely]]
/// Get piece of memory, without alignment.
/// Note: we expect it will return a non-nullptr even if the size is zero.
char * alloc(size_t size)
{
used_bytes += size;
if (unlikely(head.empty() || size > head.remaining()))
addMemoryChunk(size);
char * res = head.pos;
head.pos += size;
ASAN_UNPOISON_MEMORY_REGION(res, size + pad_right);
return res;
}
增长策略如下所示:
可以看到这里有线性增长阈值,小于阈值使用和vector一样的指数增长策略。可以看https://www.zhihu.com/question/36538542/answer/67994276
大于阈值则使用线性增长策略。
/// If MemoryChunks size is less than 'linear_growth_threshold', then use exponential growth, otherwise - linear growth
/// (to not allocate too much excessive memory).
size_t nextSize(size_t min_next_size) const
{
size_t size_after_grow = 0;
if (head.empty())
{
size_after_grow = std::max(min_next_size, initial_size);
}
else if (head.size() < linear_growth_threshold)
{
size_after_grow = std::max(min_next_size, head.size() * growth_factor);
}
else
{
// allocContinue() combined with linear growth results in quadratic
// behavior: we append the data by small amounts, and when it
// doesn't fit, we create a new MemoryChunk and copy all the previous data
// into it. The number of times we do this is directly proportional
// to the total size of data that is going to be serialized. To make
// the copying happen less often, round the next size up to the
// linear_growth_threshold.
size_after_grow = ((min_next_size + linear_growth_threshold - 1)
/ linear_growth_threshold) * linear_growth_threshold;
}
assert(size_after_grow >= min_next_size);
return roundUpToPageSize(size_after_grow, page_size);
}
realloc
前面提到,在podarray中,reserveForNextSize会进行两倍扩容,然后调用到TAllocator的realloc进行分配
/// NOTE Old memory region is wasted.
char * realloc(const char * old_data, size_t old_size, size_t new_size)
{
char * res = alloc(new_size);
if (old_data)
{
memcpy(res, old_data, old_size);
ASAN_POISON_MEMORY_REGION(old_data, old_size);
}
return res;
}
插入
插入的代码在入口在https://github.com/ClickHouse/ClickHouse/blob/0ff216534be190dfc21d0a7f1cb4ed83028641ef/src/Storages/MergeTree/MergeTreeSink.cpp#L58
- 如果正在处理的blcok数量大于0(num_blocks_processed>0) 那么调用delayInsertOrThrowIfNeeded,根据情况sleep一段时间防止part 数量过多
- 如果有动态列,调用convertDynamicColumnsToTuples转换动态列
- 按 Partition By 子句指定的分区,将 block 拆成每个 Partition 一个 Block, block -> []block
- 执行写入writeTempPartImpl
delayInsertOrThrowIfNeeded
在 ClickHouse 的 MergeTree 存储引擎中,“part” 是数据的物理存储单元,它包含了一些行。当我们向表中插入数据时,会生成新的 part。当表中的 part 数量过多时,会消耗大量的系统资源(例如:文件描述符,磁盘 IO,CPU 等),并且可能导致查询性能下降。因此,系统会定期进行后台合并操作,将小的 part 合并成大的 part,以此来降低 part 的数量。
“活跃的 part” 是指当前正在被查询或用于插入操作的 part。“旧的 part” 是指那些已经被标记为要删除,但实际上还没有被删除的 part,它们通常是被新的 part 替换的结果。
当活跃的 part 或旧的 part 数量超过一定阈值时,说明当前的写入速度(插入新 part)或后台合并/删除速度(减少旧 part)太慢,不能有效地控制总的 part 数量。为了防止 part 数量过多,系统会对插入操作进行限流。具体做法就是让插入操作延迟一段时间,给后台合并/删除操作更多的时间来减少 part 数量。这就是活跃的 part 和旧的 part 超过阈值需要延迟一段时间的原因。在 ClickHouse 的 MergeTree 存储引擎中,“part” 是数据的物理存储单元,它包含了一些行。当我们向表中插入数据时,会生成新的 part。当表中的 part 数量过多时,会消耗大量的系统资源(例如:文件描述符,磁盘 IO,CPU 等),并且可能导致查询性能下降。因此,系统会定期进行后台合并操作,将小的 part 合并成大的 part,以此来降低 part 的数量。
“活跃的 part” 是指当前正在被查询或用于插入操作的 part。“旧的 part” 是指那些已经被标记为要删除,但实际上还没有被删除的 part,它们通常是被新的 part 替换的结果。
当活跃的 part 或旧的 part 数量超过一定阈值时,说明当前的写入速度(插入新 part)或后台合并/删除速度(减少旧 part)太慢,不能有效地控制总的 part 数量。为了防止 part 数量过多,系统会对插入操作进行限流。具体做法就是让插入操作延迟一段时间,给后台合并/删除操作更多的时间来减少 part 数量。这就是活跃的 part 和旧的 part 超过阈值需要延迟一段时间的原因。
void MergeTreeData::delayInsertOrThrowIfNeeded(Poco::Event * until, const ContextPtr & query_context, bool allow_throw) const
{
const auto settings = getSettings();
const auto & query_settings = query_context->getSettingsRef();
// 无锁原子操作,注意release和acquire语义
const size_t parts_count_in_total = getActivePartsCount();
/// Check if we have too many parts in total
if (allow_throw && parts_count_in_total >= settings->max_parts_in_total)
{
ProfileEvents::increment(ProfileEvents::RejectedInserts);
throw Exception(
ErrorCodes::TOO_MANY_PARTS,
"Too many parts ({}) in all partitions in total in table '{}'. This indicates wrong choice of partition key. The threshold can be modified "
"with 'max_parts_in_total' setting in element in config.xml or with per-table setting." ,
parts_count_in_total, getLogName());
}
size_t outdated_parts_over_threshold = 0;
{
size_t outdated_parts_count_in_partition = 0;
if (settings->inactive_parts_to_throw_insert > 0 || settings->inactive_parts_to_delay_insert > 0)
outdated_parts_count_in_partition = getMaxOutdatedPartsCountForPartition();
if (allow_throw && settings->inactive_parts_to_throw_insert > 0 && outdated_parts_count_in_partition >= settings->inactive_parts_to_throw_insert)
{
ProfileEvents::increment(ProfileEvents::RejectedInserts);
throw Exception(
ErrorCodes::TOO_MANY_PARTS,
"Too many inactive parts ({}) in table '{}'. Parts cleaning are processing significantly slower than inserts",
outdated_parts_count_in_partition, getLogName());
}
// 如果超过了限制并且设置了允许抛出异常,那么就抛出异常。如果超过了允许延迟插入的阈值,那么就会计算出超过阈值的 part 数量
if (settings->inactive_parts_to_delay_insert > 0 && outdated_parts_count_in_partition >= settings->inactive_parts_to_delay_insert)
outdated_parts_over_threshold = outdated_parts_count_in_partition - settings->inactive_parts_to_delay_insert + 1;
}
auto [parts_count_in_partition, size_of_partition] = getMaxPartsCountAndSizeForPartition();
size_t average_part_size = parts_count_in_partition ? size_of_partition / parts_count_in_partition : 0;
const auto active_parts_to_delay_insert
= query_settings.parts_to_delay_insert ? query_settings.parts_to_delay_insert : settings->parts_to_delay_insert;
const auto active_parts_to_throw_insert
= query_settings.parts_to_throw_insert ? query_settings.parts_to_throw_insert : settings->parts_to_throw_insert;
size_t active_parts_over_threshold = 0;
{
bool parts_are_large_enough_in_average
= settings->max_avg_part_size_for_too_many_parts && average_part_size > settings->max_avg_part_size_for_too_many_parts;
if (allow_throw && parts_count_in_partition >= active_parts_to_throw_insert && !parts_are_large_enough_in_average)
{
ProfileEvents::increment(ProfileEvents::RejectedInserts);
throw Exception(
ErrorCodes::TOO_MANY_PARTS,
"Too many parts ({} with average size of {}) in table '{}'. Merges are processing significantly slower than inserts",
parts_count_in_partition,
ReadableSize(average_part_size),
getLogName());
}
if (active_parts_to_delay_insert > 0 && parts_count_in_partition >= active_parts_to_delay_insert
&& !parts_are_large_enough_in_average)
/// if parts_count == parts_to_delay_insert -> we're 1 part over threshold
active_parts_over_threshold = parts_count_in_partition - active_parts_to_delay_insert + 1;
}
/// no need for delay
if (!active_parts_over_threshold && !outdated_parts_over_threshold)
return;
UInt64 delay_milliseconds = 0;
{
size_t parts_over_threshold = 0;
size_t allowed_parts_over_threshold = 1;
const bool use_active_parts_threshold = (active_parts_over_threshold >= outdated_parts_over_threshold);
if (use_active_parts_threshold)
{
parts_over_threshold = active_parts_over_threshold;
allowed_parts_over_threshold = active_parts_to_throw_insert - active_parts_to_delay_insert;
}
else
{
parts_over_threshold = outdated_parts_over_threshold;
allowed_parts_over_threshold = outdated_parts_over_threshold; /// if throw threshold is not set, will use max delay
if (settings->inactive_parts_to_throw_insert > 0)
allowed_parts_over_threshold = settings->inactive_parts_to_throw_insert - settings->inactive_parts_to_delay_insert;
}
const UInt64 max_delay_milliseconds = (settings->max_delay_to_insert > 0 ? settings->max_delay_to_insert * 1000 : 1000);
if (allowed_parts_over_threshold == 0 || parts_over_threshold > allowed_parts_over_threshold)
{
delay_milliseconds = max_delay_milliseconds;
}
else
{
double delay_factor = static_cast<double>(parts_over_threshold) / allowed_parts_over_threshold;
const UInt64 min_delay_milliseconds = settings->min_delay_to_insert_ms;
delay_milliseconds = std::max(min_delay_milliseconds, static_cast<UInt64>(max_delay_milliseconds * delay_factor));
}
}
ProfileEvents::increment(ProfileEvents::DelayedInserts);
ProfileEvents::increment(ProfileEvents::DelayedInsertsMilliseconds, delay_milliseconds);
CurrentMetrics::Increment metric_increment(CurrentMetrics::DelayedInserts);
LOG_INFO(log, "Delaying inserting block by {} ms. because there are {} parts and their average size is {}",
delay_milliseconds, parts_count_in_partition, ReadableSize(average_part_size));
if (until)
until->tryWait(delay_milliseconds);
else
std::this_thread::sleep_for(std::chrono::milliseconds(static_cast<size_t>(delay_milliseconds)));
}
convertDynamicColumnsToTuples
核心在于recursivlyConvertDynamicColumnToTuple,它会将每一列Finalized化(转换为稀疏或稠密格式),并且铺平。
void convertDynamicColumnsToTuples(Block & block, const StorageSnapshotPtr & storage_snapshot)
{
for (auto & column : block)
{
if (!column.type->hasDynamicSubcolumns())
continue;
std::tie(column.column, column.type)
= recursivlyConvertDynamicColumnToTuple(column.column, column.type);
GetColumnsOptions options(GetColumnsOptions::AllPhysical);
auto storage_column = storage_snapshot->tryGetColumn(options, column.name);
if (!storage_column)
throw Exception(ErrorCodes::LOGICAL_ERROR, "Column '{}' not found in storage", column.name);
auto storage_column_concrete = storage_snapshot->getColumn(options.withExtendedObjects(), column.name);
/// Check that constructed Tuple type and type in storage are compatible.
getLeastCommonTypeForDynamicColumns(
storage_column->type, {column.type, storage_column_concrete.type}, true);
}
}
splitBlockIntoParts
整个过程主要分为以下步骤:
检查输入block是否为空,或者block是否没有数据(行数为0)。如果是,就直接返回空结果。
调用metadata_snapshot->check(block, true)进行一些元数据的检查。
检查metadata_snapshot是否没有设定分区键(即表是否是非分区表)。如果没有分区键,就创建一个BlockWithPartition对象,该对象包含原始的block和一个空的Row,并返回。
如果有分区键,会创建一个block的副本,然后执行分区表达式,将计算结果作为新的分区键列添加到副本block中。
利用新添加的分区键列,构造一个scatter selector(分散选择器),这个selector实际上是一个映射,可以根据行id映射到对应的分区id。
利用selector,将原始block分散到多个block中,并将每个新的block和对应的分区键封装成一个BlockWithPartition对象,最后返回所有的BlockWithPartition对象。
需要注意的是,为了提高效率,如果只需要分成一个分区(即所有行的分区键都相同),那么代码会直接复制原始block和分区键,而不会进行实际的分散操作。这段代码是对MergeTree表插入的数据进行分区的过程。在ClickHouse中,数据插入MergeTree类型的表前,会先将数据按照Partiton表达式分区,然后写入到对应的分区中。
BlocksWithPartition MergeTreeDataWriter::splitBlockIntoParts(
const Block & block, size_t max_parts, const StorageMetadataPtr & metadata_snapshot, ContextPtr context, AsyncInsertInfoPtr async_insert_info)
{
BlocksWithPartition result;
if (!block || !block.rows())
return result;
metadata_snapshot->check(block, true);
if (!metadata_snapshot->hasPartitionKey()) /// Table is not partitioned.
{
result.emplace_back(Block(block), Row{});
if (async_insert_info != nullptr)
{
result[0].offsets = std::move(async_insert_info->offsets);
result[0].tokens = std::move(async_insert_info->tokens);
}
return result;
}
Block block_copy = block;
// executePartitionByExpression 对 Block 执行 MergeTree Partition By 子句, 并且将新增的 key 字段添加到 block_copy 中
// partition_key_names_and_types 仅包含分区相关字段
/// After expression execution partition key columns will be added to block_copy with names regarding partition function.
auto partition_key_names_and_types = MergeTreePartition::executePartitionByExpression(metadata_snapshot, block_copy, context);
// 分区列
ColumnRawPtrs partition_columns;
partition_columns.reserve(partition_key_names_and_types.size());
for (const auto & element : partition_key_names_and_types)
partition_columns.emplace_back(block_copy.getByName(element.name).column.get());
// buildScatterSelector 建立了 row_id -> partition_id 之间的映射
// selector 等价于 []int 类型, selector[row_id] = partition_id
PODArray<size_t> partition_num_to_first_row;
IColumn::Selector selector;
buildScatterSelector(partition_columns, partition_num_to_first_row, selector, max_parts, context);
auto async_insert_info_with_partition = scatterAsyncInsertInfoBySelector(async_insert_info, selector, partition_num_to_first_row.size());
size_t partitions_count = partition_num_to_first_row.size();
result.reserve(partitions_count);
auto get_partition = [&](size_t num)
{
Row partition(partition_columns.size());
for (size_t i = 0; i < partition_columns.size(); ++i)
partition[i] = (*partition_columns[i])[partition_num_to_first_row[num]];
return partition;
};
if (partitions_count == 1)
{
/// A typical case is when there is one partition (you do not need to split anything).
/// NOTE: returning a copy of the original block so that calculated partition key columns
/// do not interfere with possible calculated primary key columns of the same name.
result.emplace_back(Block(block), get_partition(0));
if (!async_insert_info_with_partition.empty())
{
result[0].offsets = std::move(async_insert_info_with_partition[0]->offsets);
result[0].tokens = std::move(async_insert_info_with_partition[0]->tokens);
}
return result;
}
for (size_t i = 0; i < partitions_count; ++i)
result.emplace_back(block.cloneEmpty(), get_partition(i));
// IColumn::scatter 算子可以将一个 Column 一拆多
// 对每个 Column 一拆多后,组合为多个 Block
for (size_t col = 0; col < block.columns(); ++col)
{
MutableColumns scattered = block.getByPosition(col).column->scatter(partitions_count, selector);
for (size_t i = 0; i < partitions_count; ++i)
result[i].block.getByPosition(col).column = std::move(scattered[i]);
}
for (size_t i = 0; i < async_insert_info_with_partition.size(); ++i)
{
result[i].offsets = std::move(async_insert_info_with_partition[i]->offsets);
result[i].tokens = std::move(async_insert_info_with_partition[i]->tokens);
}
return result;
}
writeTempPartImpl
这段三百行的代码用于写入分区后的block
这里part存储有三种格式:MergeTreeDataPartWide、MergeTreeDataPartCompact和MergeTreeDataPartInMemory
- MergeTreeDataPartWide类代表了MergeTree存储系统中的一部分数据,其中数据按广义格式存储,即每一列的数据被存储在一个或多个(对于复杂类型)文件(bins)中。每个数据文件后面都跟着一个marks文件。该类可以在具有自适应和非自适应granularity的表中使用。这是MergeTree的常规部分格式,适用于大部分,因为它最有效率。如果数据部分的未压缩大小(字节)或行数超过了min_bytes_for_wide_part和min_rows_for_wide_part的阈值,则数据部分将以广义格式创建。
- MergeTreeDataPartCompact 用于将数据以紧凑的格式(compact format)存储,每个列都存储在一个文件(data.bin)中。数据被划分为多个粒度(granules),并且每个粒度中的列被顺序化。每个粒度被依次写入数据文件。标记(marks)也存储在一个单独的文件(data.mrk3)中。
- WAL会写为MergeTreeDataPartInMemory , 其余情况都不会走到MergeTreeDataPartInMemory
sync_guard会记录fd,在析构的时候执行fcntl(fd, F_FULLFSYNC, 0)进行刷盘.
- P2.1, minmax_idx->update(…) 对 Partition 涉及的字段统计 min-max 值,作为额外的谓词下推索引
- P2.2, stableGetPermutation() 对 Block 数据按照 Order By 字段排序,这里有两个细节
- 会预先检查是否排序,因此如果数据已经排过序再写入,事实上写入速度会有提升
- stableGetPermutation 为稳定排序, 底层实现为 std::stable_sort,时间复杂度为 O(N((logN)^2))
- P2.3, updateTTL(…) 是为支持 TTL 数据生命周期管理做的数据 min-max 索引,用于快速判断一个 Part 是否命中 TTL
- P2.4, MergeTreeData::createPart 创建 Part 实例
- 注意 choosePartType() 会按照 Block 大小和行数决定是否使用 Compact/Memory 存储方式,默认为 Wide 方式存储
- 本文重点讨论 Wide (即列式) 存储方式
- P2.5, MergedBlockOutputStream::writeWithPermutation, 实现 Block 数据的写入
- 后文详细介绍这一部分
- P2.6, MergedBlockOutputStream::writeSuffixAndFinalizePart, 进行一系列的收尾工作
- 统计各个文件的 checksum,写入到 checksums.txt,所有文件的 checksum 记录到一个文件
- 写入 TTL info 信息,写入到 ttl.txt
- 写入 Part 总行数写入到 count.txt
writeImpl
void MergedBlockOutputStream::writeImpl(const Block & block, const IColumn::Permutation * permutation)
{
block.checkNumberOfRows();
size_t rows = block.rows();
if (!rows)
return;
writer->write(block, permutation);
if (reset_columns)
new_serialization_infos.add(block);
rows_count += rows;
}
- checkNumberOfRows() 做了保底检查,确保各个 Column 的行数是相同的
- writer->write(block, permutation) 调用之前 data.createPart() 决定的 Writer 实例
- 可能是 MergeTreeDataPartWriterWide、MergeTreeDataPartWriterCompact、MergeTreeDataPartWriterInMemory 中的一个
- 细节见 MergeTreeData::choosePartType, src/Storages/MergeTree/MergeTreeData.cpp
- 后文以 MergeTreeDataPartWriterWide 举例
write
void MergeTreeDataPartWriterWide::write(const Block & block, const IColumn::Permutation * permutation)
{
/// Fill index granularity for this block
/// if it's unknown (in case of insert data or horizontal merge,
/// but not in case of vertical part of vertical merge)
// ClickHouse 默认每 8192(8K) 行数据,为主键字段创建一行索引数据 就是index_granularity
if (compute_granularity)
{
size_t index_granularity_for_block = computeIndexGranularity(block);
if (rows_written_in_last_mark > 0)
{
size_t rows_left_in_last_mark = index_granularity.getMarkRows(getCurrentMark()) - rows_written_in_last_mark;
/// Previous granularity was much bigger than our new block's
/// granularity let's adjust it, because we want add new
/// heavy-weight blocks into small old granule.
if (rows_left_in_last_mark > index_granularity_for_block)
{
/// We have already written more rows than granularity of our block.
/// adjust last mark rows and flush to disk.
if (rows_written_in_last_mark >= index_granularity_for_block)
adjustLastMarkIfNeedAndFlushToDisk(rows_written_in_last_mark);
else /// We still can write some rows from new block into previous granule. So the granule size will be block granularity size.
adjustLastMarkIfNeedAndFlushToDisk(index_granularity_for_block);
}
}
fillIndexGranularity(index_granularity_for_block, block.rows());
}
Block block_to_write = block;
auto granules_to_write = getGranulesToWrite(index_granularity, block_to_write.rows(), getCurrentMark(), rows_written_in_last_mark);
auto offset_columns = written_offset_columns ? *written_offset_columns : WrittenOffsetColumns{};
Block primary_key_block;
if (settings.rewrite_primary_key)
primary_key_block = getBlockAndPermute(block, metadata_snapshot->getPrimaryKeyColumns(), permutation);
Block skip_indexes_block = getBlockAndPermute(block, getSkipIndicesColumns(), permutation);
auto it = columns_list.begin();
for (size_t i = 0; i < columns_list.size(); ++i, ++it)
{
auto & column = block_to_write.getByName(it->name);
if (data_part->getSerialization(it->name)->getKind() != ISerialization::Kind::SPARSE)
column.column = recursiveRemoveSparse(column.column);
if (permutation)
{
if (primary_key_block.has(it->name))
{
const auto & primary_column = *primary_key_block.getByName(it->name).column;
writeColumn(*it, primary_column, offset_columns, granules_to_write);
}
else if (skip_indexes_block.has(it->name))
{
const auto & index_column = *skip_indexes_block.getByName(it->name).column;
writeColumn(*it, index_column, offset_columns, granules_to_write);
}
else
{
/// We rearrange the columns that are not included in the primary key here; Then the result is released - to save RAM.
ColumnPtr permuted_column = column.column->permute(*permutation, 0);
writeColumn(*it, *permuted_column, offset_columns, granules_to_write);
}
}
else
{
writeColumn(*it, *column.column, offset_columns, granules_to_write);
}
}
if (settings.rewrite_primary_key)
calculateAndSerializePrimaryIndex(primary_key_block, granules_to_write);
calculateAndSerializeSkipIndices(skip_indexes_block, granules_to_write);
calculateAndSerializeStatistics(block);
shiftCurrentMark(granules_to_write);
}
该函数应是对列存储的数据库的一个部分(称为part)进行写入操作。以下是代码的主要逻辑:
- 首先,如果需要计算块的粒度(granularity),就会调用computeIndexGranularity函数来进行计算。粒度描述了一个块中的行数。在某些情况下,如果上一个块的粒度大于当前块的粒度,会进行调整,并可能会刷新磁盘。
- 然后,确定需要写入的块的粒度,并获取这些粒度。
- 接着,对于块中的每一列,进行一些处理和调整,然后通过调用writeColumn函数将每一列写入part。
- 对于特定的列,如主键列和跳过索引列,会进行额外的处理。如果有必要,还会对非主键列进行重新排序,以节省RAM。
- 如果设置了rewrite_primary_key,那么就会计算并序列化主索引。
- 同样,会计算并序列化跳过索引,并计算并序列化统计信息。
- 最后,根据写入的粒度,调整当前标记。