机器学习之金融风控
机器学习之金融风控
- 一、评分卡
-
- 1.1 评分卡原理
- 1.2 评分卡优缺点
- 1.3 评分卡模型搭建步骤
- 1.4 IV值和WOE值详解
- 1.5 评分卡转换
- 二、实现
-
- 2.1 数据导入与预处理
- 2.2 可视化分析
- 2.3 数据分箱-计算IV值和WOE值
- 2.4 baseline模型搭建与评估
- 2.5 评分卡转换
- 2.6 验证评分卡效果
- 2.7 总结
- 三、参考网址
一、评分卡
1.1 评分卡原理
- 根据风控时间点的”前中后”,一般风评分卡可以分为下面三类:
1)A卡(Application score card):目的在于预测申请时(申请信用卡、申请贷款)对申请人进行量化评估;
2)B卡(Behavior score card):目的在于预测使用时点(获得贷款、信用卡的使用期间)未来一定时间内逾期的概率;
3)C卡(Collection score card):目的在于预测已经逾期并进入催收阶段后未来一定时间内还款的概率。
1.2 评分卡优缺点
- 优点:
1)易于使用。业务人员在操作时,只需要按照评分卡每样打分然后算个总分就能操作,不需要接受太多专业训练;
2)直观透明。客户和审核人员都能知道看到结果,以及结果是如何产生的;
3)应用范围广。如支付宝的芝麻信用分,或者知乎盐值。 - 缺点:
1)当信息维度高时,评分卡建模会变得非常困难;
1.3 评分卡模型搭建步骤
- 0.数据探究。研究数据都包含哪些信息;
- 1.样本选取。选取一定时间周期内该平台上的信贷样本数据,划分训练集和测试集;
- 2.变量选取。也就是特征筛选。需要一定的业务理解。一般这部分费时较久;
- 3.逻辑回归。根据筛选后的特征,构建逻辑回归模型;
- 4.评分卡转换。根据一定的公式转换;
- 5.验证并上线。验证评分卡效果,并上线持续监测。
1.4 IV值和WOE值详解
-
WOE:Weight of Evidence,即证据权重。WOE是对原始自变量的一种编码形式。
1)对变量进行WOE编码时,首先需要对变量进行分组处理(即离散化、分箱等操作),分组后,对于第 i i i组,WOE的计算公式为:
W O E i = l n ( p y i p n i ) = l n ( y i y T n i n T ) (1) WOE_i=ln(\frac{py_i}{pn_i})=ln(\frac{\frac{y_i}{y_T}}{\frac{n_i}{n_T}})\tag{1} WOEi=ln(pnipyi)=ln(nTniyTyi)(1)
2)其中 p y i py_i pyi是组中响应的客户数( y i y_i yi,在风险模型中,对应违约的客户,即label=1的客户)占所有样本中所有响应客户( y T y_T yT)的比例; p n i pn_i pni是组中未响应的客户( n i n_i ni,在风险模型中,对应未违约的客户,即label=0的客户)占所有样本中所有未响应客户( n T n_T nT)的比例。
3)WOE越大,组中响应的客户比例和未响应客户比例之间的比值差异越大,则在这个分组里的样本响应的可能性就越大,WOE越小,差异越小,这个分组里的样本响应的可能性就越小。 -
IV:Information Value,即信息值或信息量。判断特征对结果的重要程度。
1)IV的计算公式为:
I V i = ( p y i − p n i ) ∗ W O E i = ( p y i − p n i ) ∗ l n ( p y i p n i ) = ( p y i − p n i ) ∗ l n ( y i y T n i n T ) (2) \begin{aligned} IV_i&=(py_i-pn_i)*WOE_i\\ &=(py_i-pn_i)*ln(\frac{py_i}{pn_i})\\ &=(py_i-pn_i)*ln(\frac{\frac{y_i}{y_T}}{\frac{n_i}{n_T}})\tag{2} \end{aligned} IVi=(pyi−pni)∗WOEi=(pyi−pni)∗ln(pnipyi)=(pyi−pni)∗ln(nTniyTyi)(2)
有了一个变量的各个分组的 I V i IV_i IVi值,我们可以计算整个变量的IV值,如下所示:
I V = ∑ i n I V i (3) IV=\sum_i^n IV_i\tag{3} IV=i∑nIVi(3)
其中 n n n为变量分组的个数。 -
IV值缺点:不能自动处理变量的分组中出现响应比例为0或100%的情况。那么,遇到响应比例为0或者100%的情况,我们应该怎么做呢?建议如下:
(1)如果可能,直接把这个分组做成一个规则,作为模型的前置条件或补充条件;
(2)重新对变量进行离散化或分组,使每个分组的响应比例都不为0且不为100%,尤其是当一个分组个体数很小时(比如小于100个),强烈建议这样做,因为本身把一个分组个体数弄得很小就不是太合理。
(3)如果上面两种方法都无法使用,建议人工把该分组的响应数和非响应的数量进行一定的调整。如果响应数原本为0,可以人工调整响应数为1,如果非响应数原本为0,可以人工调整非响应数为1。
1.5 评分卡转换
- 评分卡模型中不直接采用客户违约概率p,而是采用违约概率与正常概率之间的比值,称为odds,即
o d d s = p 1 − p (4) odds=\frac{p}{1-p}\tag{4} odds=1−pp(4)
p = o d d s 1 + o d d s (5) p=\frac{odds}{1+odds}\tag{5} p=1+oddsodds(5) - 为什么不直接采用p,而是采用odds呢?
1)根据逻辑斯蒂回归原理:
p = 1 1 + e − θ T x (6) p=\frac{1}{1+e^{-\theta^Tx}}\tag{6} p=1+e−θTx1(6)
经过变换可得:
l n ( p 1 − p ) = θ T x (7) ln(\frac{p}{1-p})=\theta^Tx\tag{7} ln(1−pp)=θTx(7)
2)有了逻辑斯蒂的原理,我们可得:
l n ( o d d s ) = θ T x (8) ln(odds)=\theta^Tx\tag{8} ln(odds)=θTx(8) - 评分卡逻辑的背后是odds的变动与评分变动之间的映射(把odds映射为评分),可以设计一个公式:
S c o r e = A − B ∗ l n ( o d d s ) (9) Score=A-B*ln(odds)\tag{9} Score=A−B∗ln(odds)(9)
其中A、B是出常数,B前面取负号的原因在于:违约率越低,得分越高。 - 计算A、B的方法如下,首先包含2个假设:
1)基准分:当 θ 0 \theta_0 θ0为某个比率时的得分 P 0 P_0 P0,业界风控策略基准分都设置为500/600/650,基准分 P 0 P_0 P0为:
P 0 = A − B ∗ l n ( θ 0 ) (10) P_0=A-B*ln(\theta_0)\tag{10} P0=A−B∗ln(θ0)(10)
2)PDO(point of double):比率翻倍时分数的变动值,我们这里假设当odds翻倍时,分值减少50,则有:
P 0 − P D O = A − B ∗ l n ( 2 θ 0 ) (11) P_0-PDO=A-B*ln(2\theta_0)\tag{11} P0−PDO=A−B∗ln(2θ0)(11)
由公式(9)、(10)可得A、B的值为:
B = P D O l n 2 (12) B=\frac{PDO}{ln2}\tag{12} B=ln2PDO(12)
A = P 0 + B ∗ l n ( θ 0 ) (13) A=P_0+B*ln(\theta_0)\tag{13} A=P0+B∗ln(θ0)(13) - 评分卡里每一个变量的每一个分箱有一个对应分值:
S c o r e = A − B { θ 0 + θ 1 x 1 + θ n x n } (14) Score=A-B\{\theta_0+\theta_1x_1+\theta_nx_n\}\tag{14} Score=A−B{θ0+θ1x1+θnxn}(14)
其中变量 x 1 , x 2 x_1, x_2 x1,x2都是最终模型的输入变量。由于所有输入变量都进行了WOE编码,所以这些变量可以写为 ( θ i w i j ) δ i j (\theta_i w_{ij})\delta_{ij} (θiwij)δij的形式,其中 w i j w_{ij} wij为第 i i i个特征的第 j j j个分箱的WOE值, δ i j \delta_{ij} δij是取值为0,1的变量,当 δ i j = 1 \delta_{ij}=1 δij=1时,表示特征 i i i取第 j j j个分箱值, δ i j = 0 \delta_{ij}=0 δij=0时,表示特征 i i i不取第 j j j个分箱值,最终得到评分卡模型为:
S c o r e = A − B { θ 0 + ( θ 1 w 11 ) δ 11 + ( θ 1 w 12 ) δ 12 + . . . . . . . . . + ( θ n w n 1 ) δ n 1 + ( θ n w n 2 ) δ n 2 + . . . } (15) Score=A-B\begin{Bmatrix} \theta_0\\ +(\theta_1 w_{11})\delta_{11}+(\theta_1 w_{12})\delta_{12}+...\\ ......\\ +(\theta_n w_{n1})\delta_{n1}+(\theta_n w_{n2})\delta_{n2}+... \end{Bmatrix}\tag{15} Score=A−B⎩⎪⎪⎨⎪⎪⎧θ0+(θ1w11)δ11+(θ1w12)δ12+.........+(θnwn1)δn1+(θnwn2)δn2+...⎭⎪⎪⎬⎪⎪⎫(15)
二、实现
2.1 数据导入与预处理
#导入所需要的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
import seaborn as sns
import math
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE
from sklearn.linear_model import LogisticRegression
import sklearn.metrics as metrics
#数据读取与展示
test=pd.read_csv('./data/give me some credit/cs-test.csv')
del test['Unnamed: 0'] #删除无用的列
train=pd.read_csv('./data/give me some credit/cs-train.csv')
del train['Unnamed: 0']
train.head()


变量SeriousDlqin2yrs是模型的label。其中1为坏,0为好。这个变量是意思是Serious Delinquent in 2 year,也就是2年内发生严重逾期,其中”严重“定义为逾期超过90天。例如你2019年4月1号是你的还款日,然后你在7月1号前都没还钱,那这时候逾期就超过90天了,你的数据标签就为1。
#查看数据是否缺失
train.info()
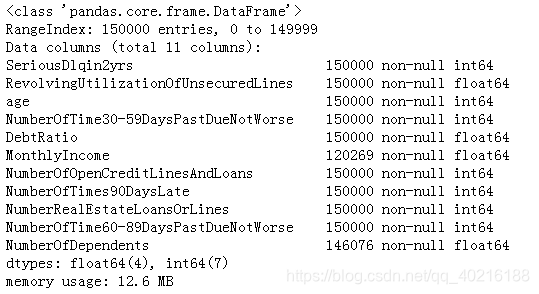
#数据描述性统计
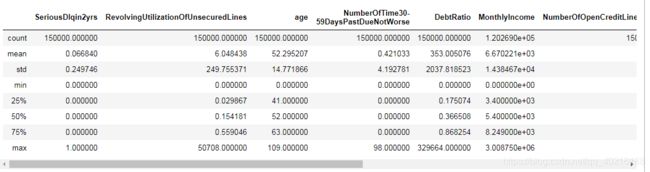
train.describe()
#定义函数,计算缺失值及缺失比例
def cal_miss_value(df):
null_val_sum=df.isnull().sum()
null_df=pd.DataFrame({'Columns':null_val_sum.index,
'Number of null values':null_val_sum.values,
'Proportion':null_val_sum.values/len(df)})
null_df['Proportion']=null_df['Proportion'].apply(lambda x:format(x, '.2%'))
return null_df
train_null_df=cal_miss_value(train)
train_null_df

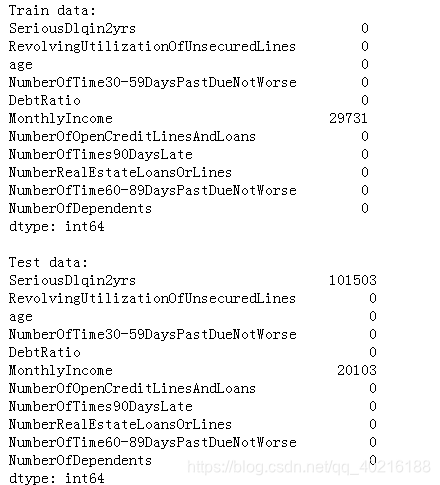
#缺失值处理-中位数填充
train['NumberOfDependents']=train['NumberOfDependents'].fillna(train['NumberOfDependents'].median())
print('Train data:')
print(train.isnull().sum())
test['NumberOfDependents']=test['NumberOfDependents'].fillna(test['NumberOfDependents'].median())
print('\nTest data:')
print(test.isnull().sum())
#使用随机森林对收入NumberOfDependents进行预测,来填充缺失值
names=list(train.columns)
names.remove('NumberOfDependents')
def rf_fill_nan(df, null_col):
#分成已知该特征和未知该特征2部分
known=df[df[null_col].notnull()]
unknown=df[df[null_col].isnull()]
#指定X和y
X=known.drop([null_col], axis=1)
y=known[null_col]
model=RandomForestRegressor(random_state=0, n_jobs=-1).fit(X, y)
pred=model.predict(unknown.drop([null_col], axis=1)).round(0) #四舍五入取整
df.loc[df[null_col].isnull(), null_col]=pred #缺失值进行填充
return df
train=rf_fill_nan(train, 'MonthlyIncome')
#异常值处理--剔除age等于0的数据
train=train.loc[train['age']>0]
2.2 可视化分析
#可视化分析
sns.countplot(x='SeriousDlqin2yrs', data=train)
print('Default rate=%.4f'%(train['SeriousDlqin2yrs'].sum()/len(train)))
#结果
Default rate=0.0668

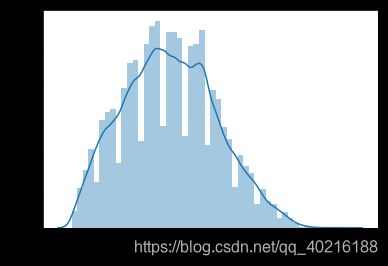
#客户年龄分布
sns.distplot(train['age'])
2.3 数据分箱-计算IV值和WOE值
#数据分箱
'''
需要 qcut的: 等频分箱,每个箱包含的样本数是相同的
RevolvingUtilizationOfUnsecuredLines
DebtRatio
MonthlyIncome
NumberOfOpenCreditLinesAndLoans
NumberRealEstateLoansOrLines
需要 cut的: 等间隔分箱或者自定义分箱边界
age
NumberOfDependents
NumberOfTime30-59DaysPastDueNotWorse
NumberOfTimes90DaysLate
NumberOfTime60-89DaysPastDueNotWorse
'''
age_bins = [-math.inf, 25, 40, 50, 60, 70, math.inf]
train['bin_age'] = pd.cut(train['age'],bins=age_bins).astype(str)
dependent_bin = [-math.inf,2,4,6,8,10,math.inf]
train['bin_NumberOfDependents'] = pd.cut(train['NumberOfDependents'],bins=dependent_bin).astype(str)
dpd_bins = [-math.inf,1,2,3,4,5,6,7,8,9,math.inf]
train['bin_NumberOfTimes90DaysLate'] = pd.cut(train['NumberOfTimes90DaysLate'],bins=dpd_bins)
train['bin_NumberOfTime30-59DaysPastDueNotWorse'] = pd.cut(train['NumberOfTime30-59DaysPastDueNotWorse'], bins=dpd_bins)
train['bin_NumberOfTime60-89DaysPastDueNotWorse'] = pd.cut(train['NumberOfTime60-89DaysPastDueNotWorse'], bins=dpd_bins)
train['bin_RevolvingUtilizationOfUnsecuredLines'] = pd.qcut(train['RevolvingUtilizationOfUnsecuredLines'],q=5,duplicates='drop').astype(str)#q为分箱数,当有重复的边界时,会报错,将报错drop掉
train['bin_DebtRatio'] = pd.qcut(train['DebtRatio'],q=5,duplicates='drop').astype(str)
train['bin_MonthlyIncome'] = pd.qcut(train['MonthlyIncome'],q=5,duplicates='drop').astype(str)
train['bin_NumberOfOpenCreditLinesAndLoans'] = pd.qcut(train['NumberOfOpenCreditLinesAndLoans'],q=5,duplicates='drop').astype(str)
train['bin_NumberRealEstateLoansOrLines'] = pd.qcut(train['NumberRealEstateLoansOrLines'],q=5,duplicates='drop').astype(str)
#写一个计算IV的函数
def cal_IV(df, feature, target):
lst=[]
for i in df[feature].unique():
lst.append([feature,
i,
len(df.loc[df[feature]==i]),
len(df.loc[(df[feature]==i)&(df[target]==1)])])
data=pd.DataFrame(lst, columns=['特征', '特征取值', '该特征取值下样本数', '该特征取值下bad样本数'])
data=data.loc[data['该特征取值下bad样本数']>0] #如果该取值下没有bad样本,则无法计算woe值
data['woe的分子']=data['该特征取值下bad样本数']/len(df.loc[df[target]==1])
data['woe的分母']=(data['该特征取值下样本数']-data['该特征取值下bad样本数'])/len(df.loc[df[target]==0])
data['woe']=np.log(data['woe的分子']/data['woe的分母'])
data['iv']=(data['woe']*(data['woe的分子']-data['woe的分母'])).sum()
return data
lst=[]
for j in train.columns:
if j.startswith('bin_'): #判断字符串以bin_开头,endswith是判断结尾
lst.append([j, cal_IV(train, j, 'SeriousDlqin2yrs')['iv'][0]])
data_iv=pd.DataFrame(lst, columns=['feature', 'iv'])
data_iv=data_iv.sort_values(by='iv', ascending=False).reset_index(drop=True) #按IV值进行降序排列
data_iv


我们选择IV值之大于0.1的特征进行预测。
used_cols=data_iv.loc[data_iv['iv']>0.1]['feature'].tolist()
used_cols
#结果
['bin_RevolvingUtilizationOfUnsecuredLines',
'bin_NumberOfTime30-59DaysPastDueNotWorse',
'bin_NumberOfTimes90DaysLate',
'bin_NumberOfTime60-89DaysPastDueNotWorse',
'bin_age']
#定义一个函数cal_WOE,用以把分箱转成WOE值
def cal_WOE(df, features, target):
df_new=df
for f in features:
df_woe=df_new.groupby(f).agg({target:['sum', 'count']})
df_woe.columns = list(map(''.join, df_woe.columns))
df_woe = df_woe.reset_index()
df_woe = df_woe.rename(columns = {target+'sum':'bad'})
df_woe = df_woe.rename(columns = {target+'count':'all'})
df_woe['good']=df_woe['all']-df_woe['bad']
df_woe['bad_rate']=df_woe['bad']/df_woe['bad'].sum()
df_woe['good_rate']=df_woe['good']/df_woe['good'].sum()
df_woe['woe'] = df_woe['bad_rate'].divide(df_woe['good_rate'],fill_value=1)#分母为0时,用1填充
#此woe值未取对数,对数转换后可能造成出现无穷小
df_woe.columns = [c if c==f else c+'_'+f for c in list(df_woe.columns)]
df_new=df_new.merge(df_woe, on=f, how='left')
return df_new
df_woe = cal_WOE(train,used_cols,'SeriousDlqin2yrs')
woe_cols = [c for c in list(df_woe.columns) if 'woe' in c]
df_woe[woe_cols]

d=pd.DataFrame()
for j in train.columns:
if j.startswith('bin_'): #判断字符串以bin_开头,endswith是判断结尾
d=d.append(cal_IV(train, j, 'SeriousDlqin2yrs'))
d
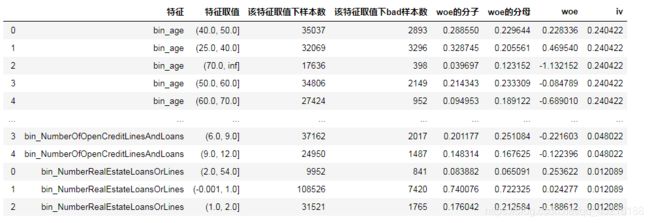
2.4 baseline模型搭建与评估
#建立逻辑斯蒂回归-取出20%的数据作为验证集
X_train, X_validation, y_train, y_validation=train_test_split(df_woe[woe_cols], df_woe['SeriousDlqin2yrs'], test_size=0.2, random_state=42)
print("train set's bad rate is: %.4f"% (y_train.sum()/y_train.count()))
print("validation set's bad rate is: %.4f"% (y_validation.sum()/y_validation.count()))
#结果
train set's bad rate is: 0.0672
validation set's bad rate is: 0.0653
print(np.isinf(X_train).any()) #判断是否为无穷大
print(np.isfinite(X_train).any()) #判断是否为有限的数字
print(np.isnan(X_train).any()) #判断是否存在缺失值

#采用SMOTE进行数据平衡,效果不好,所以未采用
# X_train_smote, y_train_smote = SMOTE(random_state=42).fit_resample(X_train, y_train)
# print("After SMOTE, train set's bad rate is: %.4f"% (y_train_smote.sum()/y_train_smote.count()))
#Logistic Regression作为baseline模型,常用于风控领域
#model_smote=LogisticRegression(random_state=42).fit(X_train_smote, y_train_smote)
model=LogisticRegression(random_state=42).fit(X_train, y_train)
print("Model's parameters:", model.coef_)
prob=model.predict_proba(X_validation)[:,1] #返回2列数据,第0列是0类别的概率,第1列是1类别的概率
fpr,tpr, threshold=metrics.roc_curve(y_validation, prob)
roc_auc=metrics.auc(fpr,tpr)
#绘制ROC曲线
plt.plot(fpr,tpr,'b',label="AUC=%.2f"%roc_auc)
plt.title('ROC Curve')
plt.legend(loc='best')
plt.plot([0,1],[0,1],'r--')
plt.xlim([0,1])
plt.ylim([0,1])
plt.xlabel('fpr')
plt.ylabel('tpr')
plt.show()
#计算混淆矩阵
y_pred=model.predict(X_validation)
print('Confusion_matrix:\n',metrics.confusion_matrix(y_validation, y_pred))
#计算分类指标
print('\nAccuracy:\n %.4f'%metrics.accuracy_score(y_validation, y_pred))
target_names = ['label=0','label=1']
print('\nPrecision_recall_f1-score:\n',metrics.classification_report(y_validation,y_pred,target_names = target_names))

2.5 评分卡转换
#评分卡转换
#设置基础分P0为650,PDO为50,我们定义theta_0为1:1(表示p/1-p=1:1),也可以采用其他值
B=50/np.log(2)
A=650+B*np.log(1/1)
def generate_scorecard(model_coef, bin_df, features, B):
lst=[]
cols=['Variable','Binning','Score']
coef=model_coef[0]
for i in range(len(features)):
f=features[i]
df=bin_df[bin_df['特征']==f]
for index, row in df.iterrows():
lst.append([f, row['特征取值'], int(-coef[i]*row['woe']*B)])
data=pd.DataFrame(lst, columns=cols)
return data
score_card = generate_scorecard(model.coef_, d, used_cols, B)
score_card
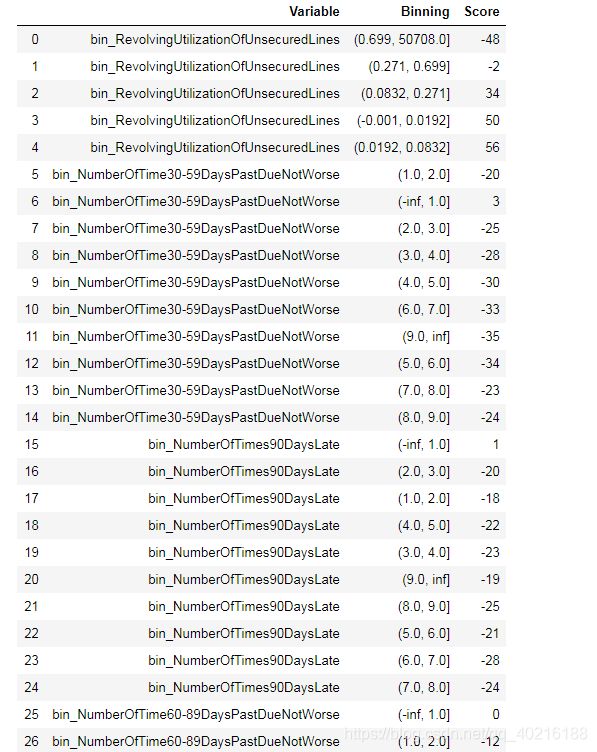
#进行排序
sort_scorecard=score_card.groupby(by='Variable').apply(lambda x:x.sort_values('Score', ascending=False))
sort_scorecard
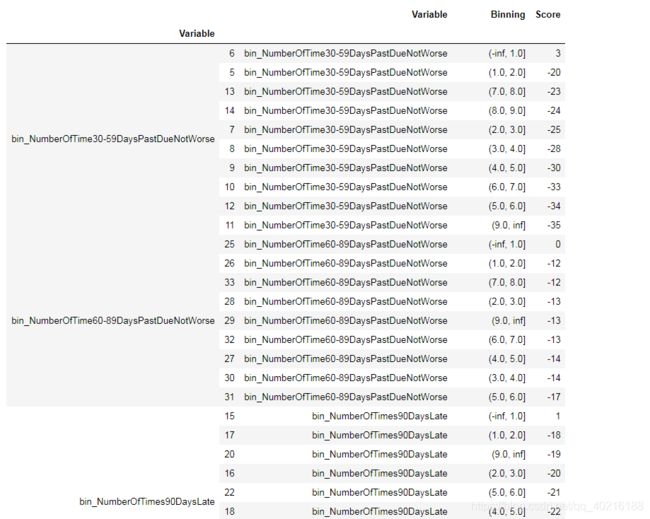
总体来说评分符合预期。
2.6 验证评分卡效果
#为了验证评分卡的效果,我们各选五个SeriousDlqin2yrs == 0和SeriousDlqin2yrs == 1
#并固定一个random state。
def str_to_int(s):
if s == '-inf':
return -999999999.0
elif s=='inf':
return 999999999.0
else:
return float(s)
def map_value_to_bin(feature_value, feature_to_bin):
for idx, row in feature_to_bin.iterrows():
bins=str(row['Binning'])
left_open=bins[0]=='('
right_open=bins[-1]==')'
binnings=bins[1:-1].split(',')
in_range=True
# check left bound
if left_open:
if feature_value<=str_to_int(binnings[0]):
in_range=False
else:
if feature_value<str_to_int(binnings[0]):
in_range=False
#check right bound
if right_open:
if feature_value>= str_to_int(binnings[1]):
in_range = False
else:
if feature_value> str_to_int(binnings[1]):
in_range = False
if in_range: #in_range==True时
return row['Binning']
return null
def map_to_score(df, score_card):
scored_columns=list(i.split('_')[1] for i in score_card['Variable'].unique())
score=0
for col in scored_columns:
bin_col='bin_'+col
feature_to_bin=score_card[score_card['Variable']==bin_col]
feature_value=df[col]
selected_bin=map_value_to_bin(feature_value, feature_to_bin)
selected_record_in_scorecard=feature_to_bin[feature_to_bin['Binning'] == selected_bin]
score+=selected_record_in_scorecard['Score'].iloc[0]
return score
def calculate_score_with_card(df, score_card, A):
df['score']=df.apply(map_to_score, args=(score_card,), axis=1)
df['score']=df['score']+A
df['score']=df['score'].astype(int)
return df
#生成样本
row_cols=[i.split('_')[1] for i in used_cols]#取出未转换为分箱的原始5个特征
pred_cols=row_cols+used_cols
good_sample=train[train['SeriousDlqin2yrs']==0].sample(5, random_state=1)[pred_cols]
bad_sample=train[train['SeriousDlqin2yrs']==1].sample(5, random_state=1)[pred_cols]
#开始计算评分--好客户
calculate_score_with_card(good_sample, score_card, A)
calculate_score_with_card(good_sample, score_card, A)
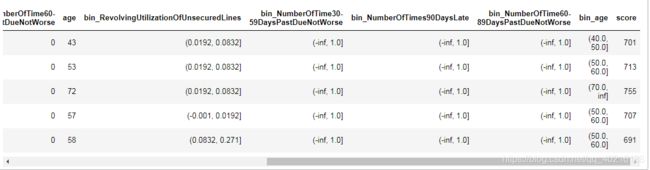
#开始计算评分--坏客户
calculate_score_with_card(bad_sample, score_card, A)
calculate_score_with_card(bad_sample, score_card, A)
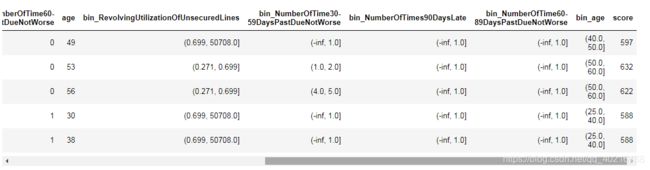
可以看到,好样本分数评分都比坏样本分数高,说明了评分卡的有效性。
2.7 总结
- 由于测试集label信息未知,所以无法计算IV值和WOE值;
- 分箱可以进行优化,可以才测试集上使用分箱结果;
三、参考网址
- https://mp.weixin.qq.com/s/5BPb-wDauPvDZkTc2euROQ
- https://mp.weixin.qq.com/s/5cJ5Yix_3up2sAixJd79Zw
- https://mp.weixin.qq.com/s/eGjgCkgtupolyT4BccAANQ
- https://www.kaggle.com/orange90/credit-scorecard-example/notebook
- https://zhuanlan.zhihu.com/p/148102950