微服务架构<1>
我们为什么要做微服务的架构,将单一的服务进行拆分,我服务间通信采用轻量级http,比如说在springcloud中使用openFiegn发起调用
也可以使用一些rpc框架来实现通信,比如说dubbo, grpc之类的都可以实现微服务的通信的
微服务的架构,我们要从单体架构进行拆成一个个微服务
涉及到我们为什么要拆,怎么去拆,我们进行拆分的时候要考虑一些什么样的原则和策略,我一个单体架构,我运行的好好的,我为什么要拆分.
我们单体架构,当我们的流量起来的时候,我此时单体架构就扛不住并发了,此时只能用垂直架构的方式来进行扩展
我部署多台节点但是这种架构方式,他的问题就是
1>我去改一个小小的功能的时候,比如说我去改order服务的时候,其他服务可能会受到影响,去迭代的时候不好迭代
2>第二点就是浪费我资源机器,我要把整个架构进行部署,会浪费我的机器资源,如果我此时拆分了微服务的话,我扩容的时候,只需要对我某个微服务进行扩容就可以了
3>而且单体项目 如果项目很大的话,部署会很耗时,如果我拆分成微服务的话就会很方便,当进行服务拆分后,我专门的服务由专门的人来管理,当我进行服务迭代的时候,我只需要对某个服务进行迭代,我其他服务是不需要动的
我扩容的时候i只需要对某个服务进行扩容 我其他服务不用动
4>单体服务如果发生宕机了 你服务整体就宕机了,我某个微服务挂了的话,不会影响其他微服务的正常运行
当然你微服务拆分后,整体的运维部署就会麻烦一些
微服务的拆分的策略,如果你服务业务简单的话我们可以采用自下而上的拆分策略,我们可以基于数据库来拆分
从数据库的角度就划分清楚了,因为此时数据库的表的命名是不一样的pms,cms,oms, 我从数据库上升到我应用层面
如果业务比较复杂的话,我可以用DDD来做服务的拆分,我可以先规划好我的领域,自上而下的进行服务拆分,当业务比较复杂的时候采用DDD来做会比较好一些
我们从单体架构来做微服务的拆分,我首先要做的就是前后端分离,其次要做一些公共服务的拆分, 比如说授权 分布式id
再把功能性的服务给拆出来 这个就是我们拆分的策略
先把通用性的服务给独立出来 比如说分布式id,认证授权这些 因为每个模块都需要
对性能要求比较高的服务要单独拆出来 比如说秒杀,方便后面的扩容
为什么要把秒杀从订单系统中独立出来,因为秒杀并发量高,
我们可以把性能要求比较高的服务独立出来
我们还要把核心服务和可靠性低的非核心的服务分开,然后重点保护这些核心服务的高可用

我们可以进行异构 比如说Python可以做数据分析,go语言适合做高并发场景 这些我们都可以做服务的独立抽取
我们可以作为独立的服务进行拆分 我们通过这些策略实现微服务的拆分 我们项目是怎么拆分的

微服务的拆分,同时我们的数据库也做了拆分,做了独立的库以及独立的表

关于我们微服务拆分的一些原则和策略,比如说电商项目 我们此时拆分了很多模块,非业务的和业务的
通用性的功能模块(统一认证,全局唯一id),以及我们做了一些服务的拆分
我们微服务拆分之后我们要做一些i技术选型
我们使用springcloud/Alibaba
我们做了服务拆分之后下一步要去做技术选型
服务注册和发现,以及服务配置的问题 nacos eureka zk apolo这些技术我们该怎么去选择
我们还要考虑springcloud以及springboot的版本问题 兼容性的问题
我们可以借助于springCloudAlbiaba 帮助我们更快的介入微服务的开发。
接下来我们要接入微服务组件,让他实现我们的微服务之间的调用
微服务的调用,首先实现的是服务的注册和发现,nacos注册中心的作用是服务的注册和发现
我们微服务启动的时候会给这个注册中心注册自己的信息
当服务下线了,他会有一个心跳机制来感知我的服务已经下线,超过多少ms,就会去做剔除(服务的续约)
这样当我order--->user的时候 我就可以感知你服务已经下线了,剔除调这个不可用的服务
同样注册中心提供一个服务发现的接口,这就是注册中心的架构
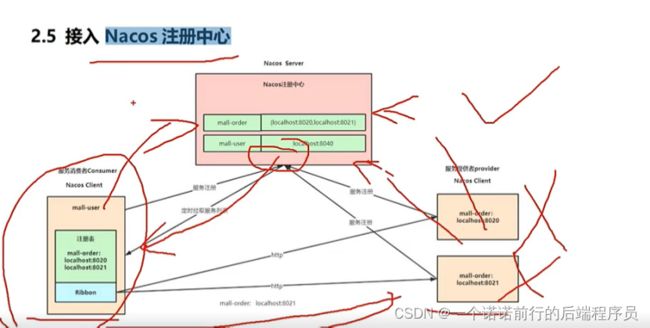
我们微服务首先要实现服务注册和发现,这是一个核心需求第一步肯定接入注册中心
注册中心选型 我们 使用nacos
我们第一步加pom文件 第二步加上对应微服务中添加nacos的配置


命名空间是做环境隔离的,启动nacos,nacos启动后,我们的服务就要去注册
在控制台就可以看到有没有注册成功(nacos的注册信息)

这就是我们关注的nacos(做注册中心),
我们也可以配置cluster-name 上海 ,可以实现同集群优先调用
基于集群名字的改变我负载均衡的算法,优先调用同集群下的微服务
我们也可以基于版本做灰度

关于注册中心的配置就可以了,第一步引入依赖 第二步指定注册中心地址
接下来我们讲配置的统一管理
我们会引入nacos的配置中心,微服务中有个配置中心
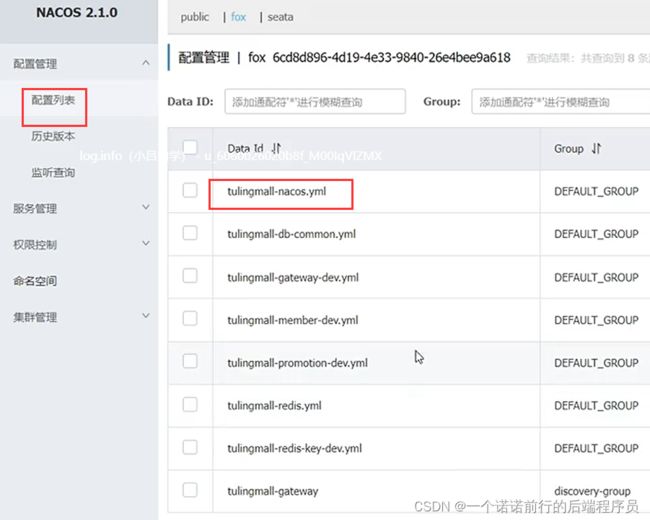
微服务的配置我们可以在这里配置,这里的配置分公共配置抽离和自己的配置。
比如说nacos注册中心的地址配置,属于通用配置,每个微服务都要进行服务的注册
然后各个微服务的数据库连接,redis这些我们就可以单独抽取出来
这样我们就把我们的配置用nacos管理起来了,这就是我们的配置中心的配置。他是怎么去用的
同样是2步,第一步引入配置中心的依赖

配置中心的yaml配置
我们服务的调用 user--->order的调用 我们现在2个服务都是独立的springboot应用,我们的postman是可以访问的
现在我要发起一个请求 通过user调用到order上, 这个时候我们就需要服务间的远程调用信息,比如说openFeign
我们也的要引入openFeign的依赖
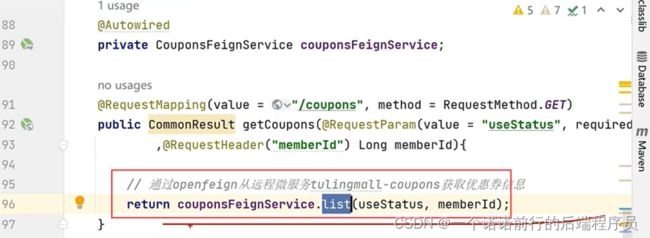
我通过feignClient 就可以发起请求调用
这是关于我们openFeign的作用,调我们远程方法像调用我们本地方法一样 属于一种RPC 框架
基于openFeing 实现我们微服务的调用

我们可以打开openFeign的日志
整个微服务的组件必须要有有一个服务网关,微服务的入口,我要接入服务的网关springcloudgateway
在网关中我可以对服务进行鉴权,校验登录 都可以在网关中去做
网关还有路由功能,基于网关做路由转发到对应的微服务中,就可以完成服务的路由
网关是个很重要的组件


gateway的yaml和pom的配置
路由信息
断言中基于nacos拉取服务
我们就可以基于网关去调用对应微服务了
第一步引入依赖,第二步配置yaml ,网关底层是基于webFlex 所以要排查对应的mvc 依赖
关于我们微服务拆分前期必须介入的组件,配置中心,注册中心以及openFeign 网关
现在我们网关也有了,微服务也拆分了,微服务间间通过openFeing也可以调用通
但是还有一个统一认证我们还没有去做
我们之前已经讲解了微服务的拆分原则,策略,以及我们项目中是怎么做拆分的,包括我们也接入了配置中心以及注册中心
openFeign实现了服务的调用,最后我们也搭建了一个服务网关
基于这个网关服务,我们除了做路由转发,我们还要做一个统一认证服务

------------------<<<<<<<<<<<<<<<<统一认证服务
搭建完毕微服务后 还有一个日志体系方便我们快速排查问题.
落地整个微服务的时候,因为此时你的应用是分散在不同的机器上的,可能查询一个日志需要在很多个服务器上去排查才可以排查到
有一定的日志分析体系,我们今天会从一个nginx访问日志入手分析,分析我们电商项目的pv和uv
nginx作为统一入口,他就是我微服务的流量入口,我们可以基于nginx做pv,uv的统计。
我们今天就会从nginx的访问日志场景来分析pv和uv
我们的技术还是最常规的elk日志体系,因为elk在微服务收集中比较成熟

logstash作为分布式日志处理的中心,由他来收集应用的各种各样的日志,收集之后进行处理,处理之后变成json
日志存储在es中,我们基于kibana 就可以查到了
filebeat负责对日志的采集(elk中专门做日志采集用的)
logstash 本身也可以收集日志,但是他的应用比较重,占用的系统资源比较多
启动以及反应会比较慢一些,所以通常不适合和我们的应用单独部署在一台机器上,这样会影响性能
我们通常会搭建一个中间的服务,用更简单的filebeat来负责做日志的采集
elk的版本以及集群架构的部署规划

简单一个示例 验证了我们logstash服务搭建可以的
nginx--->filebeat--->logstash--->es--->kibana
logstash从filebeat收集,输出到es 中,logstash可以对日志进行格式的处理
将nginx 日志解析为json 格式的数据 存储在es

这个就是nginx log的日志 每一个ngixn请求都会打印这一条日志,基于这个日志进行拆分,会将这一行文本解析成为json格式
接下来我们要搭建filebeat,filebeat来采集我服务器的日志,我自然会将filebeat和我的应用(nginx)部署在一起
filebeat 我要采集那些日志,filebeat采集的是一行一行的日志.他不具备对日志的过滤,格式化的能力所以我们要通过logstash 对日志进行处理
nginx---->filebeat--->logstash--->es
filebeat采集nginx 日志 ,采集到的ngixn日志发送到logstash
logstash会对日志进行格式化,格式化处理之后发送到es
我们通过kibana就可以看到es中的日志数据

我们就可以在kibana中看到日志,我们访问前端页面,就产生了ngixn的log日志,产生日志经过filebeat和logstash的采集和处理,就可以在kibana中看到对应的数据
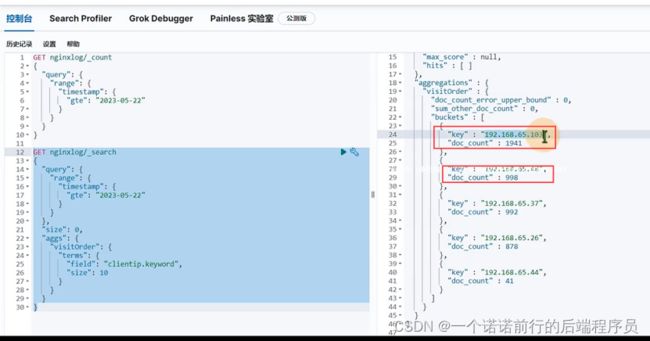
我们有了这些日志数据,可以分析很多东西,比如说统计pv,访问一次页面就有一个log日志
我就可以统计出当天有多少条日志,我就可以简单的认为有多少pv

今天的日志采集情况uv 代表一个独立访客,比如说当前一个人我不管访问多少页面 我的uv 始终算一个 ,区分不同的客户,可以根据客户的ip来做区分

有多少个ip地址就有多少个访客,这个我们的uv 就是5,可以看到有5个独立的访客户
这样我们就搭建了一个简单的日志过滤收集体系,现在我们基于nginx日志做了一个简单的数据过滤收集的体系
我们基于nginx做了一个简单的日志采集,如果后续对接报表数据我们可以快速做一些报表数据
我们基于nginx的日志可以这样采集,我们对于我们的应用服务日志也可以这样采集,也是通过filebeat采集
然后我可以定制,日志格式log日志我们也可以定制格式
比如说结合aop,针对于openfein的请求,在微服务的调用的时候我们可以吧日志收集起来
我专门记录feign请求的日志,我就可以知道从原始服务调用到某个具体的服务,这个就是链路追踪
skywalking 直接在服务调用层面快速实现实现对链路的收集,这就是后面搭建的体系
关于nginx访问日志收集和实战,我们采用的是elk的方案进行收集
在微服务中我们还要收链路追踪日志,比如说下单环节,这么多微服务的调用,出现问题之后我们该怎么去排查和定位
或者说我们发现下单链路长,比较耗时,怎么定位是那个微服务的耗时长
接入skywalking 去实现这个链路追踪,我们采用skywalking
我们结合我们项目去实现 看下怎么去使用我们的skywalking
第一步搭建skywalking服务
第二步只需要 我对应的微服务启动的时候需要配置这个skywalking 地址和我们的微服务的名字
我们微服务通过agent的方式来接入这个skywalking
接入这个skywalking后 当我们访问postman的时候 我们就可以在skywalking 的ui界面获取到对应的链路信息以及耗时


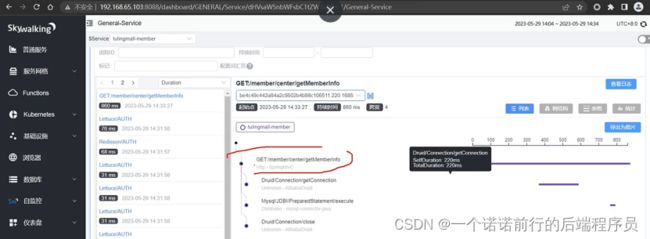
我们通过trace就可以查询到他的链路,我们可以看经过那些微服务, 这是我们的skywalking
我们这些链路追踪数据可以收集到es中去,比方说我们生成日志文件,我通过这个文件收集到es中去
如果我们想要收集我们的微服务日志,他就会有个traceId的

我们在微服务中的日志框架需要做整合 在log.xml文件中加入配置 就可以实现我们的traceId了

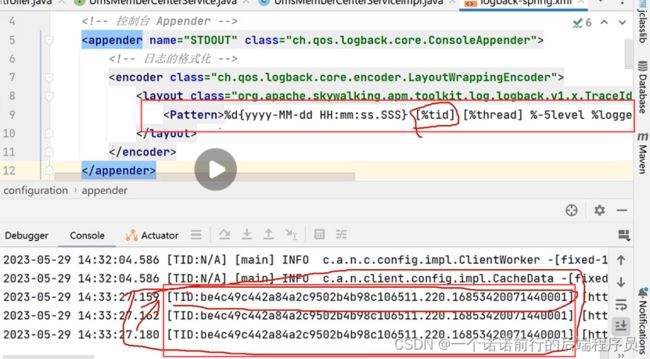
利用tid 我就可以知道和我这次链路相关的日志 这些数据可以收集到es中的
,此时我们也可以通过skywalking 来观察到哪一个请求会比较慢,我们之前讲了 我们接入skywalking 是实现我们的链路追踪,同时我们也整合日志框架 让我们的日志产生一个traceid
接下来我们可以通过收集这个traceId的日志 来做日志分析,有异常的话 我们可以做分析

我们利用elk 来收集我们服务的链路日志,elk收集日志的架构是,我们都可以利用filebeat来做日志收集
logback整合logstash插件,我logback的日志信息可以直接上报到logstash中
### 做日志收集 logbach+skywalking+logstash+es+kibana

只要我们微服务产生日志 就可以给logshash 传输,同时会输出到es中

当我们通过postman访问的时候,我们就会logstash收集到这些日志,这些日志就会上报到我es中
es可以辅助kibana中查看
当然我们也可以通过fliebeat来搜集 微服务的日志,基于es我们可以很方便的做日志排查

我们吧这种链路日志收集起来 在es中可以快速定位为题