浅谈师范双非普本工科专业的秋招历程
本人普通师范院校通信工程专业,于秋招历程之中四处碰壁,迫于家庭等各种因素考虑,最终选择移动的偏远县城岗位的OFFER!本人秋招历程之中,屡屡碰壁,也算得上“收获满满”!我简单给各位浅谈一下我的个人求职历程。
本人的秋招最先开始是在8月份投递了第一份国企C++的岗位,奈何笔试没有通过。在后续的几个月中,通过努力,有了一份上市公司的实习经历,实习结束后,简历的内容也丰富起来,我也开始陆陆续续的在网上进行简历投递,也慢慢都有了一些面试机会!
面试的过程中,本来以为有实习经历和项目的我应该可以找到一份较好的offer,奈何在学校的环境中,自己的想法还是太理想化了!记住,校园很理想,社会很现实,社会很现实,社会很现实!
求职路上第一道拦路虎就是学历,在我的求职经历中,很多企业默认的第一学历只有 985/211 、双一流以及其他!有的岗位甚至明写着985/211学历不限制专业,非92只允许几个专业可以投递。所以,很多好的岗位本人是没有资格投递的!其次,就是所谓的“降维打击”!为什么要用降维打击一词来形容呢,因为在求职过程中你的对手可能不只有本科生,还有研究生甚至是博士生!比如我面试的广东华阳,虽然写着本科生也可以招收,但是最后招收的基本全是研究生甚至博士生,原因也无他,太多研究生报名了!在现在这个大环境下,我感觉我所投递的岗位本科生真的多如牛毛,甚至你会发现研究生也一抓一大把。要想在这种环境下拿到好的offer入场券,对于普通人来说学历和技术,你必须得有一个过硬的吧!很是可惜,当时我并不具备这样的条件。
求职路上第二道拦路虎就是专业,就像张雪峰所强调的专业壁垒!我是通信工程专业,想投计算机岗位的话就会有一些碰壁!尤其是国企央企这种,好的都是专业限定得比较死!不能投递。这个得大家自行体会,我个人感觉这个是对我影响比较少的!
求职路上第三道拦路虎就是技术。如果你有过硬的技术,那么在秋招的历程中,你会发现机会非常的多!那么如何判断自己的技术行不行呢?我个人觉得,由市场来判断是最客观的!比如我去联通的外包实习,实习工资是3k多,这就是我的市场价值。当然技术也有很多分类,比如你的沟通能力或者你的口语表达能力特别强的话,你也会收到一份好的OFFER!比如我投递的几家IT公司,要求会日语,如果没有的话会在公司入职的6个月内全职学日语,考证,考证通过后才上技术岗。又或者我面试的银行岗位,面试官是留洋回来的,面试的几位同学除了我是师范类的剩下的也基本是武大,重邮,墨尔本大学的本科生,面试官叫我们自我介绍都是英文自我介绍,有的还是全程英文交流,他们一口流利的英文让我感到人和人的差别之大,深感无奈。英语瘸腿的我,结果当然是没有通过。
假如说各位和我一样都有这些劣势甚至负面Buff叠满,那么该如何减小这些劣势呢!以我个人的经历来说,有人内推可以最大程度的降低学历之间的劣势甚至增加入职概率。我们可以查查我们想投递的公司,对比一下上届和上上届师兄师姐有没有入职的,有的话就找辅导员询问他们的联系方式,向他们了解企业的情况以及入职成功的心得体会!
在然后就是打铁还需自身硬,各位如果想找互联网方面或者通信相关的工作,不要死磕八股文,要联系实际,最好自己认真的实操一遍流程并仔细分析,总结遇到的相关问题和解决方案。不要再被面试官询问项目遇到的最大问题时,回答各种查询最后发现是版本兼容问题这种答案。B站上有很多的好课,大家可以选择性的查缺补漏。如果当时我没有自己在阿里云服务器部署过项目,广州海颐的面试我是不可能通过面试并获得offer的。
最后也是非常重要的一点,信息差。我们年级群时常会发出一些企业推荐,但是大多是非常迟了才发在群里,比如今天年级群推荐的嵌入式工程师岗位,是11月17号开始招聘的,没准现在都招满了,投递了也基本没有后续。大家可以多去Boos直聘、前程无忧、智联招聘、国聘(这个流程比较慢)去查查最新的岗位和工作机会,这样面试的概率大大提高.
总结起来,找工作看得是整体综合实力的强弱,不单单只看学历和技术,但是必定看学历和技术,如果有时间各位一定要努力提升一下自己的硬实力和软实力,综合实力强才是真的强!也顺带说一下我秋招所获得的offer. 主要有以下:
北京天源迪科-运维工程师offer
广州海颐-全栈开发工程师
新点软件-交付工程师
杭州新中大-二次开发岗
中国移动-边境县城岗(职位不确定)
东宝信息-实施顾问
卓望数码-网络工程师(面试中)
朗国电子-技术支持(面试中)
华勤技术-IT运维工程师-(面试中)
江苏海隆软件-对日开发(得学日语)
湖北银行-总行科技人员(已通过线上面试,太远了放弃线下面试)
接下来就是开始分享一些我个人总结的八股文!
1、oracle去除重复的记录并保留序号最小的记录,设计sql语句
select min(id) from 表 group by id ;
2、mybatis怎么使用
mybatis属于ORM框架,封装了jdbc。可以通过注解或xml配置文件两种方式来使用。mybatis拥有一级缓存和二级缓存。
3、前端如何传数据到后端。在spring mvc中如何实现
前后端数据的互通是通过Ajax+Json技术实现的。springmvc框架封装了原生mvc,视图层向业务层传递数据时需经过控制层。
4、单线程和多线程的区别
多线程即同时存在多个线程运行,比只有一个线程运行效率要高。多线程可能产生并发问题,可以使用同步技术加以控制。
5、ajax怎么传数据
可以在ajax请求的url后追加请求参数或通过ajax技术中data属性。
6、get和post有什么区别,get为什么比post快
1、get把请求的数据放在url上,其格式为 以?分割URL和传输数据,参数之间以&相连;post把请求的数据放在HTTP的包体内
2、get提交的数据最大是2k,post理论上没有限制
3、get请求会被浏览器主动cache,而post不会(除非手动设置)
4、get请求只能进行url编码,而post支持多种编码方式
5、get请求参数会被完整保留在浏览器历史记录里,而post中的参数不会被保留
6、get只接受ascii字符的参数的数据类型,而post没有限制
7、get产生的url地址可以被bookmark,而post不可以
8、get效率高
9、c3p0和jdbc怎么联系起来的
在jdbc获取连接对象的时候,通过c3p0的工具类来实现
步骤:
导入C3P0库, 配置C3P0连接池, 使用JDBC连接, 关闭连接
10、Jsp和servlet的区别。
jsp一般属于视图层,servlet属于控制层。jsp最终编译时会转换成servlet。每个servlet均有对应的资源名称
11、springmvc的工作原理
(1)、 用户发送请求至前端控制器DispatcherServlet。
(2)、 DispatcherServlet收到请求调用HandlerMapping处理器映射器。
(3)、 处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
(4)、 DispatcherServlet调用HandlerAdapter处理器适配器。
(5)、 HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
(6)、 Controller执行完成返回ModelAndView。
(7)、 HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
(8)、 DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
(9)、 ViewReslover解析后返回具体View。
(10)、DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
(11)、 DispatcherServlet响应用户。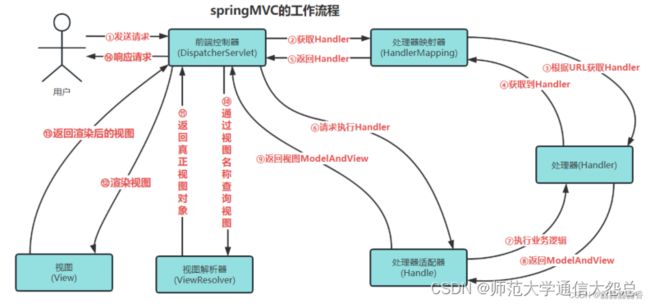
12、MVC框架的理解
mvc框架包含View视图,Controller控制器,Model模型三部分。视图用于渲染数据,模型用于处理业务,控制器起纽带作用:把视图和模型联系在一起
工作流程:
1.浏览器通过视图向控制器发出请求;
2.控制器接收到请求后对数据进行封装,选择模型进行业务逻辑处理;
3.随后控制器将模型处理结果转发到视图或下一个控制器;
4.在视图层合并数据和界面模板生成HTML并做出最终响应。
14、String字符串比较相等,为什么不用==
equals方法,==比较两个字符串的内存地址是否相同
当比较两个字符串是否相等时,应该使用.equals()方法而不是==运算符。==比较的是两个字符串对象的引用地址,而.equals()比较的是两个字符串对象的内容。
15、说说你对面向对象的理解
面向对象是一种程序设计思想,整个程序都是由若干个对象构成,对象与对象之间存在多种关系。使用该思想开发项目时,通常需要把项目中使用的对象进行抽象。
比起面向过程,面向对象更注重有哪些参与者(对象)、及各自需要做什么,将其拆解为一个个模块和对象,这样的好处是易于维护和拓展。
16、连接两个string字符串,使用“+”有什么影响
(1)+号,每当连接一次均会在内存上新建一个空间分配给连接后的字符串
(2)concat方法
concat 是一个常用的方法,用于将两个或多个对象(例如数组、字符串等)连接起来形成一个新的对象。需要注意的是,concat 方法不会改变原始的数组或字符串,而是返回一个新的合并后的对象。
(3)append方法
在 Java 中,append() 是用于字符串拼接的方法之一,通常是在 StringBuilder 或 StringBuffer 对象上使用。
StringBuilder 和 StringBuffer 类提供了可变的字符串操作,其中都包含了 append() 方法。
需要注意的是,与直接使用字符串连接操作符(+)相比,使用 StringBuilder 或 StringBuffer 的 append() 方法可以提升性能并减少内存开销,尤其当需要在循环中拼接大量字符串时。
17、stringbuffer和stringbuilder的区别
- String类型的字符串对象是不可变的,一旦String对象创建后,包含在这个对象中的字符序列是不可以改变的,直到这个对象被销毁。
- StringBuilder和StringBuffer类型的字符串是可变的,不同的是StringBuffer类型的是线程安全的,而StringBuilder不是线程安全的
3、如果是多线程环境下涉及到共享变量的插入和删除操作,StringBuffer则是首选。如果是非多线程操作并且有大量的字符串拼接,插入,删除操作则StringBuilder是首选。
StringBuffer是同步的,StringBuilder不是。
18、sql优化
(1)避免使用*
(2)避免复杂的多表连接
(3)建立有效索引
(4)读写分离
19、SSM框架的理解
SSM即Spring+SpringMVC+Mybatis三个框架,SpringMVC主要作用在MVC层。Mybatis作用在持久层,提供一、二级缓存。Spring框架通过依赖注入把MVC和持久层联系起来并且Spring框架通过AOP实现事务管理
老师更新:
ssm指spring、springmvc和mybatis三个框架。springmvc属于spring框架的组件,实现了mvc模型,提供前端路由映射、视图解析等功能。spring框架提供了AOP的编程思想,来管理事务。同时通过IoC实现各层的依赖注入。myabtis集成到spring框架,主要作用在持久层,封装了jdbc,提供了一、二 级缓存。
20、简单谈谈Redis
Redis是一种非关系型数据库,存储数据使用K-V形式,有时redis作为缓存来用,搭建redis缓存集群。
Redis的基本数据类型:字符串(String),列表(List),集合(Set),
有序集合(Sorted Set),哈希表(Hash)
21、svn用过吧,那么你们怎么解决冲突问题的
svn属于团队协作版本控制工具,为了避免冲突问题,通常提交代码前先更新。有些冲突产生后需要和团队成员讨论需要保留那些代码片段。
- 更新代码:使用"svn update"命令从仓库中获取最新的代码。
- 理解冲突:查看冲突标记("<<<<<<<", "=======", ">>>>>>> "),找到冲突部分。
- 手动解决冲突:根据需要修改冲突部分的代码。
- 标记冲突已解决:使用"svn resolved"命令或"svn resolved
"将冲突标记为已解决。 - 提交变更:使用"svn commit"命令提交解决冲突后的代码。
重要的是与团队成员沟通,并在解决冲突后进行全面测试和验证。
23、session和cookie的区别,怎么消除session,session怎么用。
(1)session由服务器端创建,由服务端保存信息,打开新的浏览器,就会开始一次新的会话cookie由服务器发送给客户端的片段信息,存储在客户端浏览器的内存中或硬盘上。由客户端保存信息,在cookie有效期间内,多个浏览器可访问同一个cookie对象
(2)通常session在浏览器中会有默认的有效期,过期即失效
session与Cookie的区别:
1.session存储数据在服务器端,Cookie在客户端;
2.session没有数据大小限制,Cookie有数据大小限制;
3.session数据安全,Cookie相对于不安全。
4.过期时间:Cookie可以设置过期时间,可以长期保存在客户端。Session通常在浏览器关闭后自动过期,也可以设置有效期。
1.cookie数据存放在客户的浏览器上,session数据放在服务器上。
2.cookie数据只能是字符串类型。session数据是object类型(**session可以存储任意Java对象**)
3.一个cookie存储的数据一般不超过4K。session存储在服务器上可以任意存储数据。当 session存储数据太多时,服务器可选择进行清理。
4.cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session。
5.两者都是以“k-v”形式存数据,都可以设置数据有有效期。
- 如何消除Session:
- 服务器端:可以在服务器端删除或清除Session数据。
- 客户端:在客户端无法直接删除Session,但可以通过让Session过期或重启浏览器来间接删除。
如何使用Session
创建Session->存储Session数据->检索Session数据->更新Session数据->销毁Session
25、ajax的具体实现流程
- 创建一个异步调用对象。
- 创建一个http请求,并指定该请求的方法,url及验证信息。
- 设置http请求状态变化时的响应函数。
- 发送http请求。
第五,获取异步调用返回的数据。第六,使用js或dom实现局部刷新。
26、线程有几种创建方式
(1)继承Thread父类
(2)实现runnable接口
(3)使用线程池技术
(4)使用Callable实现有返回值的线程
27. sleep() 和 wait() 有什么区别?
类的不同:sleep() 来自 Thread类,wait() 来自 Object类。
释放锁:sleep() 不释放锁;wait() 释放锁。
使用的范围是不同的:wait:只能在同步代码块中使用;sleep:可以在任何地方使用
用法不同:sleep() 时间到会自动恢复;wait() 可以使用 notify()/notifyAll()直接唤醒。
28.线程的 run() 和 start() 有什么区别?
start() 方法用于启动线程,run() 方法用于执行线程的运行时代码。
run() 可以重复调用,而 start() 只能调用一次。
第二次调用start() 必然会抛出运行时异常
29.在 Java 程序中怎么保证多线程的运行安全?
- 使用安全类,比如 Java. util. concurrent 下的类。
- 使用自动锁 synchronized。
- 使用手动锁 Lock。
30、使用过触发器吗?
触发器属于数据库中的对象,通常绑定在某个表上,封装一定的功能,当对该表记录进行增删改操作时,触发器会自动触发并执行其封装的功能
31、ioc,aop原理
ioc即控制反转,依赖对象的创建及维护是由外部容器负责的。
aop即面向切面编程,是一种设计思想。从系统中分离出方面,然后集中实现。从而可以独立编写业务逻辑代码和方面代码,在系统运行时,再将方面代码“织入”到系统中。
32、使用static修饰和不使用static的区别
static修饰的属性和方法属于类,供所有类的对象共享
static访问特点:
非静态成员方法
1.能够访问静态的成员变量;
2.能够访问非静态的成员变量;
3.能够访问静态的成员方法;
4.能够访问非静态的成员方法;
静态的成员方法
1.能够访问静态成员变量,但是不能够直接访问非静态成员变量
2.能够访问静态的成员方法,但是不能够直接访问非静态成员方法
33、jdbc的使用过程
(1)加载驱动
(2)获取连接对象
(3)通过操作对象实现curd
(4)关闭连接
34、登录怎么实现的,密码加密了嘛?使用明文还是暗文,知道怎么加密嘛?
使用jdk自带的工具类通过MD5加密算法加密。
登录功能的密码加密一般使用哈希算法,比如MD5、SHA-1、SHA-256等。在注册时,用户输入的密码经过哈希算法加密后存储到数据库中。在登录时,用户输入的密码再次经过相同的哈希算法加密,与数据库中存储的加密密码进行比较验证。这样可以确保密码不以明文形式存储,增加了安全性。
35、git有几个仓库,冲突之后怎么解决
git属于团队协作的版本控制技术,支持分布式。通常由本地库和远程库构成。同21
先将本地修改的代码缓存起来,git stash,然后是git pull,然后还原暂存的内容git stash pop,git status查看哪些文件冲突了,就vim打开冲突的文件,把文件里面的冲突标识符删掉,然后再git add,git commit即可。
36、聊聊gc垃圾回收机制
gc垃圾回收机制是一个系统级的线程,它自动跟踪每块被分配出去的内存空间,自动释放被定义成垃圾的内存。程序员不能精确的控制和干预
37、接口和抽象类的区别;
(1)抽象类中可以包含抽象方法和普通方法,而接口中只可以包含抽象方法,且abstract可省略
(2)接口是公开的,里面不能有私有的方法或变量,而抽象类是可以有私有方法或私有变量的
(3)实现接口时一定要实现接口里定义的所有方法,而继承抽象类可以有选择地重写需要用到的方法
(4)接口可以实现多重继承,而一个类只能继承一个父类
38、springboot打包部署
通常使用maven工具进行项目打包成war或jar包
39、请解释一下继承和多态
(1)继承属于类与类之间的一种关系,通过继承可以实现代码重用,在java中子类extends父类
(2)多态通常用于提高代码通用性,即把不同的子类对象都当作父类来看,可以屏蔽不同子类对象之间的差异,举个具体例子。
继承建立了类之间的层次关系,并提供了代码的复用性;而多态性则允许我们以统一的方式对待不同的对象,从而提升代码的可扩展性和可复用性。
41、说一下快速排序怎么实现
(1). 在数组中选一个基准数(通常为数组第一个;
(2). 将数组中小于基准数的数据移到基准数左边,大于基准数的移到右边;
(3). 对于基准数左、右两边的数组,不断重复以上两个过程,直到每个子集只有一个元素,即为全部有序。
快速排序的时间复杂度为O(nlogn),是一种常用且高效的排序算法。
42、说一下线程池中使用的类
(1).newCachedThreadPool
(2).newFixedThreadPool
(3).newSingleThreadExecutor
(4).newScheduleThreadPool
43、对象的创建方式
(1)使用new关键字
(2)使用Class类的newInstance方法
(3)使用Constructor类的newInstance方法
(4)使用Clone的方法
(5)使用反序列化
浅拷贝和深拷贝的区别
1.浅拷贝会直接进行值传递,也就是将该属性值复制一份给新的对象。 简而言之,需要复用现有对象的基本类型的成员变量数据时,浅拷贝即可。
2.复制整个对象(复制前后两个对象完全一样)。 深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。深拷贝相比于浅拷贝速度较慢并且花销较大。
第一点,深拷贝和浅拷贝的解释
深拷贝:复制整个依赖的变量
浅拷贝:复制过程中只复制一层变量,不会复制深层变量所绑定的变量
第二点,深拷贝和浅拷贝的区别
深拷贝生成的新的列表和原列表没有关系
浅拷贝生成的列表如果修改的不是第一层变量,复制的列表会随之改变,但是如果改变的是第一层的变量,新列表不会修改
两个问题
哪里不同?
都是浅拷贝,但实现方式不同。ArrayList基于System.arraycopy,LinkedList主要依靠自己的循环遍历。
为何不同?
很简单,造成ArrayList和LinkedList各种差异的原因,最终都是由于其底层数据结构不同造成的,前者是数组,后者是链表。
2022-9-15:新中大面试
(总结:技术问题均从简历和项目发问,大家好好总结项目所涉及的技术)
Q1:如何实现模糊查询,查询功能如何实现,列举查询语句
A:可参考(用通配符 字段名.1ike ‘%xx% ’or用占位符)
Q2:前后端分离中前端是如何部署,后端是如何部署
(1)后端项目部署是通过Maven打包成jar包部署到服务器上
(2)前端项目部署是通过Vue框架的脚手架和Node.js工具把项目部署到Nginx服务器上
(3)前后端数据的互通是通过Ajax+Json技术实现的
2022-9-19(第一场):国泰新点面试
数据库基础知识较多
Q1:string类型比较大小用equals还是==,为什么,总结equals和==是什么时候需要用
使用equals,若使用==则比较的是地址。
==号的作用
- 比较基本数据类型:比较的是具体的值
- 比较引用数据类型:比较的是对象地址值
equals的作用:
- 用于判断两个变量是否是对同一个对象的引用,即堆中的内容是否相同,返回值为布尔类型
Q2:字符串使用什么拼接,为什么不使用“+”,stringbuffer VS stringbuilder
编译器每次碰到"+"的时候,会new- 个StringBuilder,接着调用append方法,再调用toString方法,生成新字符串。若代码中有很多"+",就会每个"+"生成一次StringBuilder, 这种方式对内存是一种浪费, 效率很不好。由于这样子拼接字符串的低效,我们才需要使用StringBuilder和StringBuffer来拼接。
StringBuffer和StringBuilder二者的区别主要就是StringBuffer是线程安全的,而StringBuilder是线程不安全的。
Q3:MySQL分组关键字,去重关键字;主键,外键,约束,视图,索引,接口,实现,查询联合主键(了解英文和概念)
SELECT:用于从数据库中检索数据。
INSERT INTO:用于将新数据插入到数据库表中。
UPDATE:用于修改数据库表中的数据。
DELETE FROM:用于从数据库表中删除数据。
DISTINCT: 可以去除重复的数据
CREATE TABLE:用于创建新的数据库表。
ALTER TABLE:用于修改数据库表结构。
DROP TABLE:用于删除数据库中的表。
INDEX:用于创建索引,优化数据库性能。
JOIN:用于将两个或多个表中的数据相关联。
UNION:用于将两个或多个查询结果集合并。
GROUP BY:用于对查询结果进行分组。
HAVING:用于对分组后的数据进行筛选。
ORDER BY:用于对查询结果进行排序。
LIMIT:用于限制查询结果的数量。
主键是一种用于唯一标识表中每一行数据的标识符。在Mysql中,主键可以是一个或多个列的组合,但是必须满足以下条件:
- 主键列的值必须唯一,不能重复。
- 主键列的值不能为空,不能为NULL。
- 一个表只能有一个主键。
外键是一个表中的一列或多列,其值必须匹配另一个表中的主键值或唯一值
约束:约束是对表中数据进行限制的规则。约束可以是列级别或表级别。列级别约束只对单个列起作用,而表级别约束则对整个表起作用。
NOT NULL约束
UNIQUE约束
CHECK约束
DEFAULT约束
索引:索引是一种特殊的数据结构,它提供了快速访问表中特定行的方法。索引可以在单个列上创建,也可以在多个列上创建。
PRIMARY KEY索引
UNIQUE索引
INDEX索引
FULLTEXT索引
视图:视图是一个虚拟表,其内容由查询定义。与实际表不同,视图并不包含任何数据。视图只包含使用时动态检索数据的查询。
联合主键:多张表进行关联,通过第三张表来维护多张表的主键,第三张表的自身主键为联合主键
复合主键:自身表中有多个字段同时作为主键,单个不能称为主键
接口:接口是用于访问数据库的程序代码集合。
实现:实现是指将接口转换为可执行代码的过程。
查询联合主键:联合主键是由两个或多个列组成的主键。
Q4:MySQL常用的引擎(英文)
- InnoDB存储引擎
- MyISAM存储引擎
- Memory存储引擎
- CSV存储引擎
- Archive
Q6:MySQL子查询关键字
any,all,exist,in
in关键字主要用于查找属性值是否属于指定的集合,属于比较常用的一个
any关键字用来表示父查询满足子查询结果的任意一个值,可以和比较运算符进行
all关键字用来表示父查询满足子查询结果的所有值,可以和比较运算符进行
关键字exists用来判断子查询是否返回结果集
Q7:MySQL模糊查询,%对查询的影响
在MySQL中,可以使用LIKE和通配符%来进行模糊查询。通配符%用于表示任意字符序列,可以在查询中灵活匹配符合特定模式的数据。
%通配符在MySQL中的使用可以帮助我们实现基于模糊匹配的灵活查询,但需要注意对性能的影响,并谨慎使用以避免不必要的查询开销。