Linux——操作系统与进程的基础概念
操作系统与进程的基础概念
本章思维导图:
注:思维导图对应的.xmind和.png文件都已同步导入至资源
1. 操作系统(OS)

操作系统的基本概念:
操作系统(operator system)简称OS,是一个管理软硬件资源的软件

1.1 为什么要有操作系统
- 如果不借助任何软件,直接管理计算机系统的各种软硬件资源,这显然是十分困难的
- 这时就需要借助操作系统这一软件,来管理好计算机内部的软硬件资源
- 而因为可以很好的管理软硬件资源,操作系统就给用户提供了一个良好稳定的运行环境
总结来说就是:
- 对下,可以将软硬件资源很好的管理组织起来
- 对上,可以给用户提供一个良好的运行环境
1.2 何为管理
上面我我们说,操作系统是管理软硬件资源的软件,那么这个管理具体是怎么管理的呢?
我们可以通过一个现实生活中的例子来进行理解:
毫无疑问,校长是一所学校的正真管理者,校长管理着学校的每一位学生
显然,校长不可能在管理的过程中实际见到每一个学生。那么校长是通过什么方式来有条不紊地管理着学生呢?
众所周知,每一位学生进入校园时,这个学生的所有详细信息都会被记录,作为学校的最高管理着,校长自然也知道这些数据
因此,校长就可以通过这些详细描述每一位学生的数据间接地管理学生(例如,让学号XXX的同学降级)
但是,学校同学恨过,面对如此海量的数据校长不可能不做任何组织地就进行管理
因此,在得到所有描述每一位学生的数据后,校长会先对这些数据进行组织,让这些数据以某种方式有序,再进行管理操作
通过上面的方式,校长得到描述每一位同学的信息,再对这些信息进行组织,就可以很好的管理学校的学生了
具体到操作系统也是如此:
- 作为计算机系统真正的管理者,操作系统并不直接对软硬件资源进行管理
- 而是会先通过得到描述每一种资源的详细属性,并将每一种资源的属性都存入到一个结构体
struct中,再通过利用各种数据结构(例如链表)对这些存储着每一种资源的结构体进行组织 - 这样,操作系统对软硬件资源的管理就转换为了对数据结构对象的操作
即管理的本质其实就是:
先描述,再组织
1.3 用户与操作系统的交互
一旦确定了操作系统为计算机系统真正的管理着,那么所有访问软硬件资源的操作都无法越过操作系统
所以,如果用户想要访问操作系统所管理的软硬件资源,就必须先与操作系统进行交互。
- 但是又因为操作系统直接和各种数据打交道,如果用户直接和操作系统交互会产生风险,因此就产生了系统调用接口
- 通过系统调用接口,用户便可以通过操作系统来访问计算机的软硬件资源
这时,有小伙伴就有疑惑了:
既然和操作系统交互有系统调用接口就足够了,为什么还要有系统库呢?
- 应该清楚,不同系统(如Windows和Linux)提供的系统调用接口肯定是不同的,因此如果是使用系统调用接口的函数,就会导致同一份代码代码只能在一个特定的平台运行,使该程序的可移植性变差
- 而有了库函数,库就会对各种与系统强相关的系统调用接口进行封装,隐蔽不同平台的差异性,这样,使用库函数的同一份代码就可以在不同的平台运行,大大提高了该代码的可移植性
- 例如,
scanf()函数printf()等库函数就对系统调用进行了封装,这也就是为什么这些函数既可以在Windows的编译器使用也可以在Linux的编译器运行
2. 进程(process)基础概念
2.1 何为进程

操作系统这门学科对进程给出了这样的定义:
是正在运行的程序的实例,是操作系统对程序执行的基本单元
但显然,如果只对进程有这样的了解,仅仅是不够的,接下来,我们将对什么是进程这一问题进行更深的分析:
应该清楚,一个程序要被执行,那么它就一定会被加载到内存中,变成进程
内存作为一种资源,自然要被操作系统管理,从而进程也会被操作系统管理
如何管理,前面已经分析过:先描述,再组织
- 描述进程的各种属性信息都被封装到了一个结构体
struct中,这个数据结构对象在操作系统学科上,称为PCB(process control block)——进程控制块,具体到Linux,称为task_struct- Linux操作系统会以链表等数据结构的形式对
tast_struct进行组织这样,操作系统对进程的控制就变成了对
PCB的组织管理,以及各种数据结构的增删查改,而不会直接对进程的可执行程序进行操作
所以,我们可以对何为进程做一个进一步的总结:
进程 =
PCB(内核数据结构)+ 可执行程序
2.1.1 task_struct的内容
task_struct存放着描述一个进程各种属性的详细信息,其包含这些内容:
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
- I/ O状态信息: 包括显示的I/O请求,分配给进程的I/ O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
注:本篇,将会对进程的标识符、状态、优先级做详细讲解,其余部分之后再涉及。
2.2 查看进程

命令:
ps axj
- 查看当前运行的所有进程

-
PPID和PID都是标识符。其中PID为本进程的标识符,PPID则是父进程的标识符 -
STAT则为该进程的进程状态
其实,所有的进程信息都放在了目录/proc目录下,如果我们想查看当前所有进程的PID也可以用命令:
ls /proc

如果想要查看一个进程更为详细的信息,可以直接使用命令:
ls /proc/PID
- 查看进程对应的标识符目录
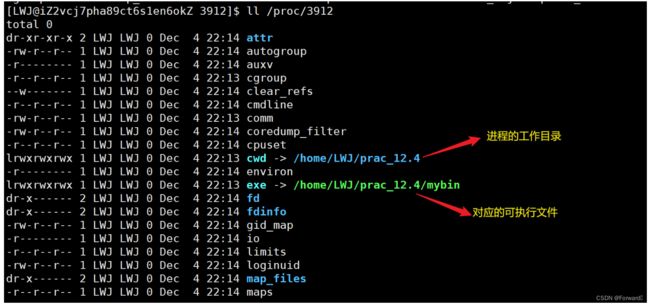
2.3 获取进程标识符
在Linux上编写程序的过程中,我们也可以通过对应的系统调用来获取本进程和父进程的进程标识符
注意:
由于不同系统的系统调用不同,因此本方法只适用于Linux操作系统
头文件:
系统调用接口:
pid_t getpid(); //获取子进程pid
pid_t getppid(); //获取父进程pid
//返回值为一个无符号整数
演示:
示例代码:
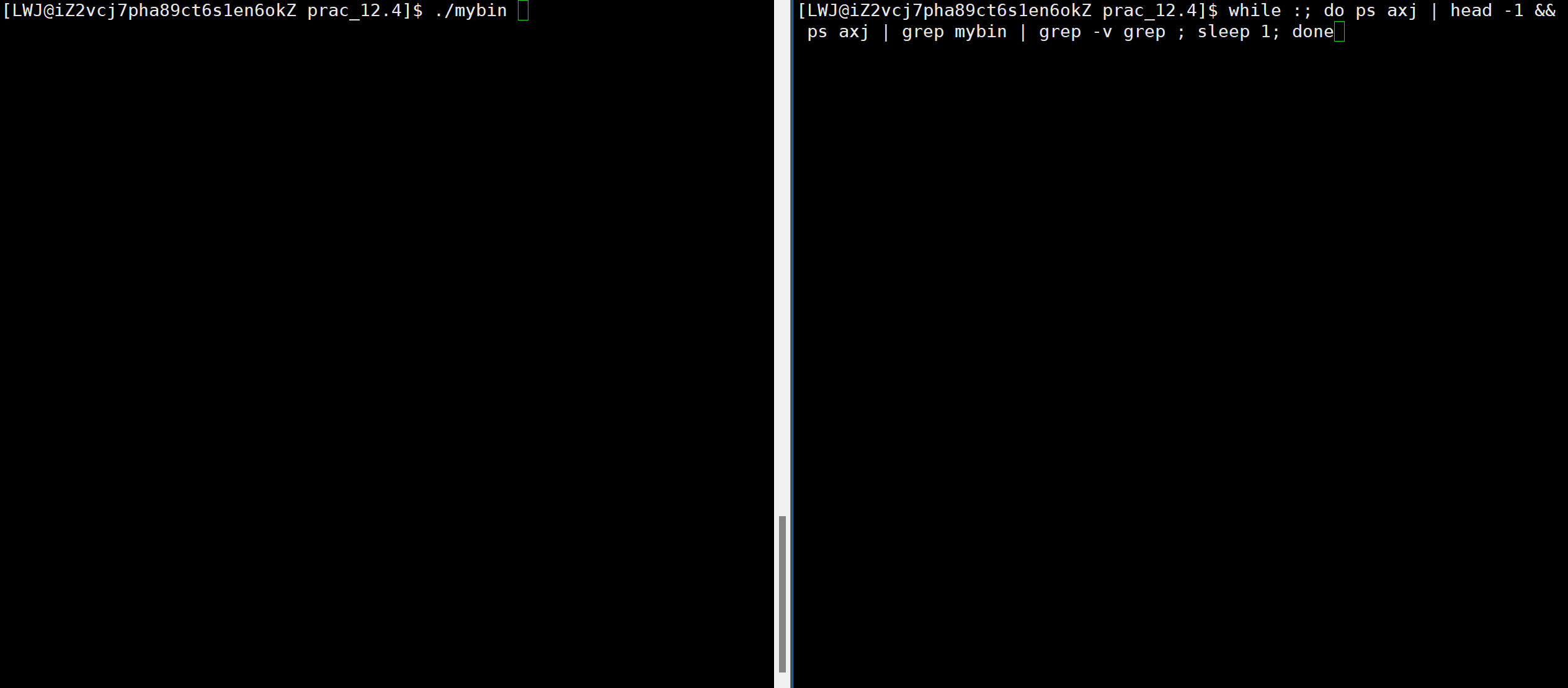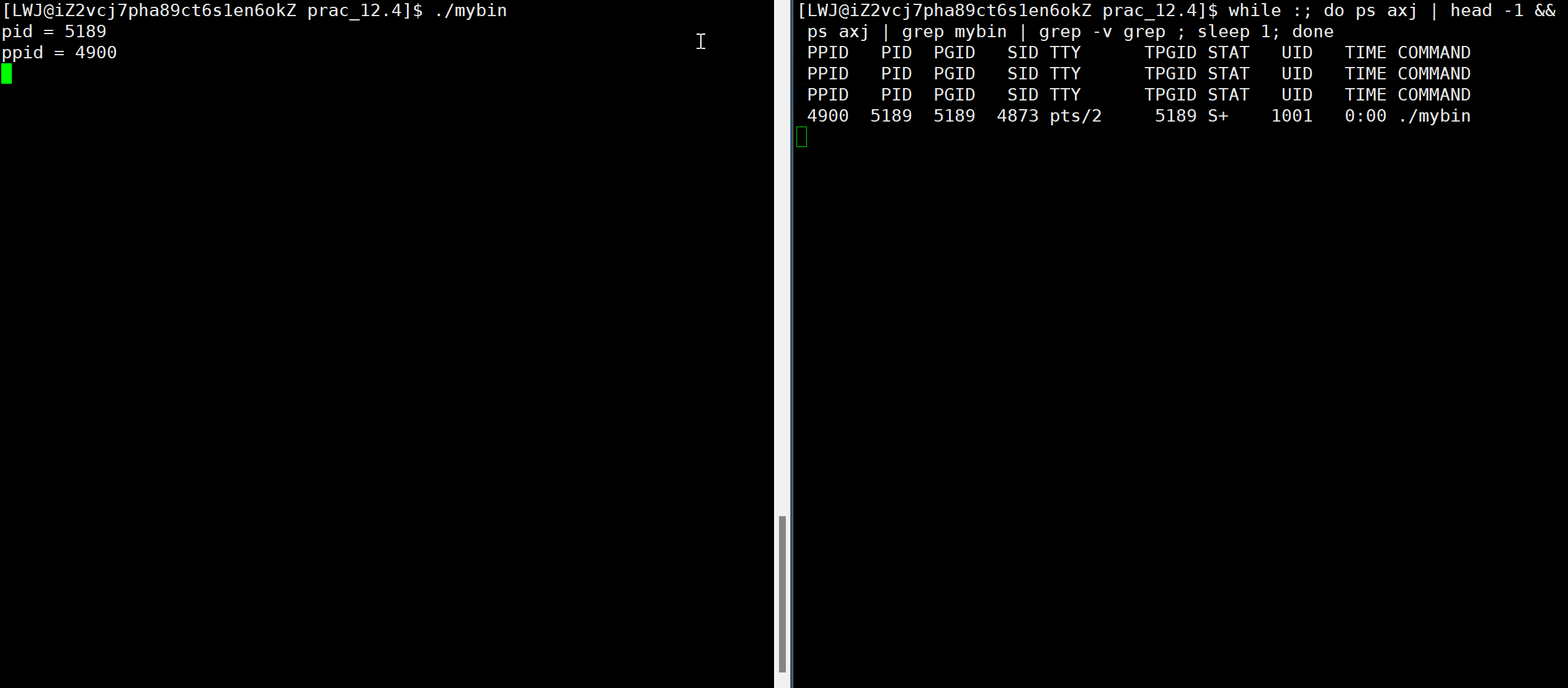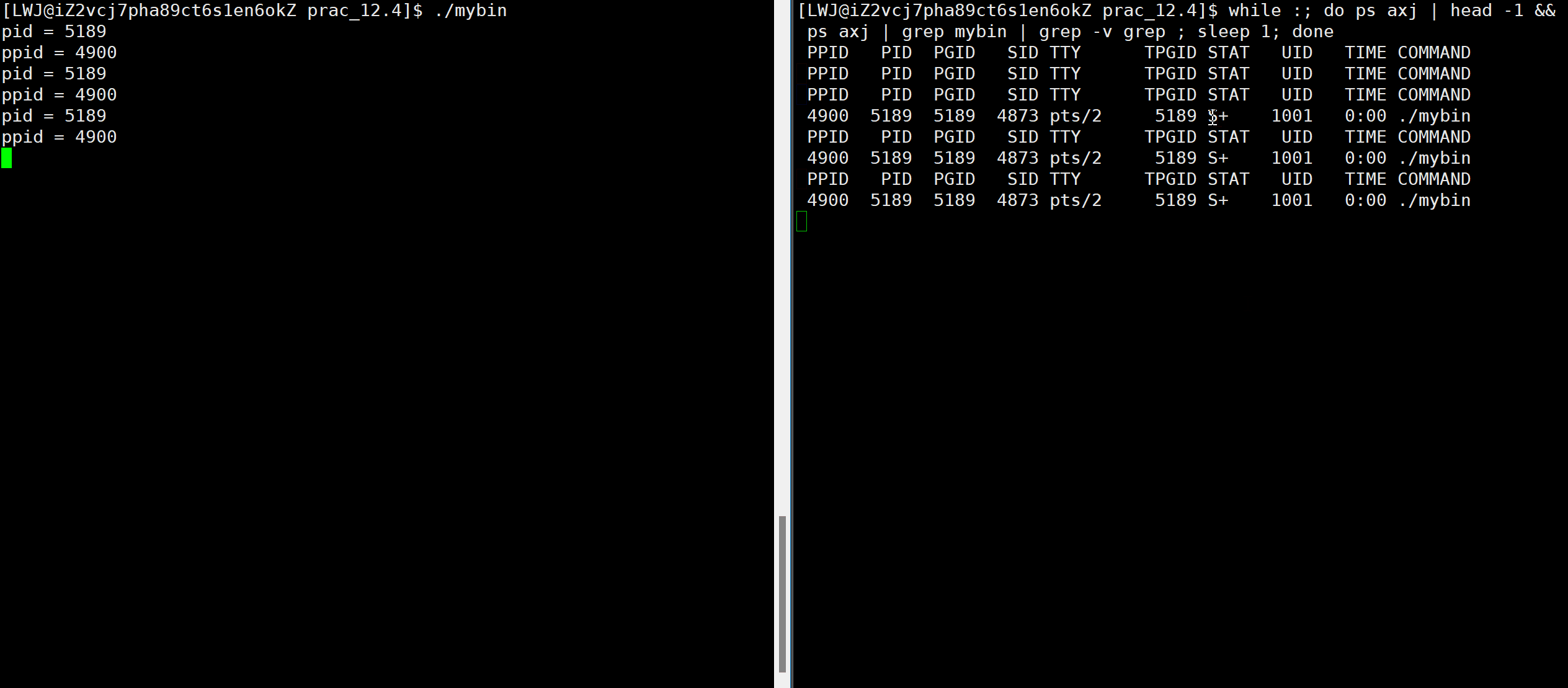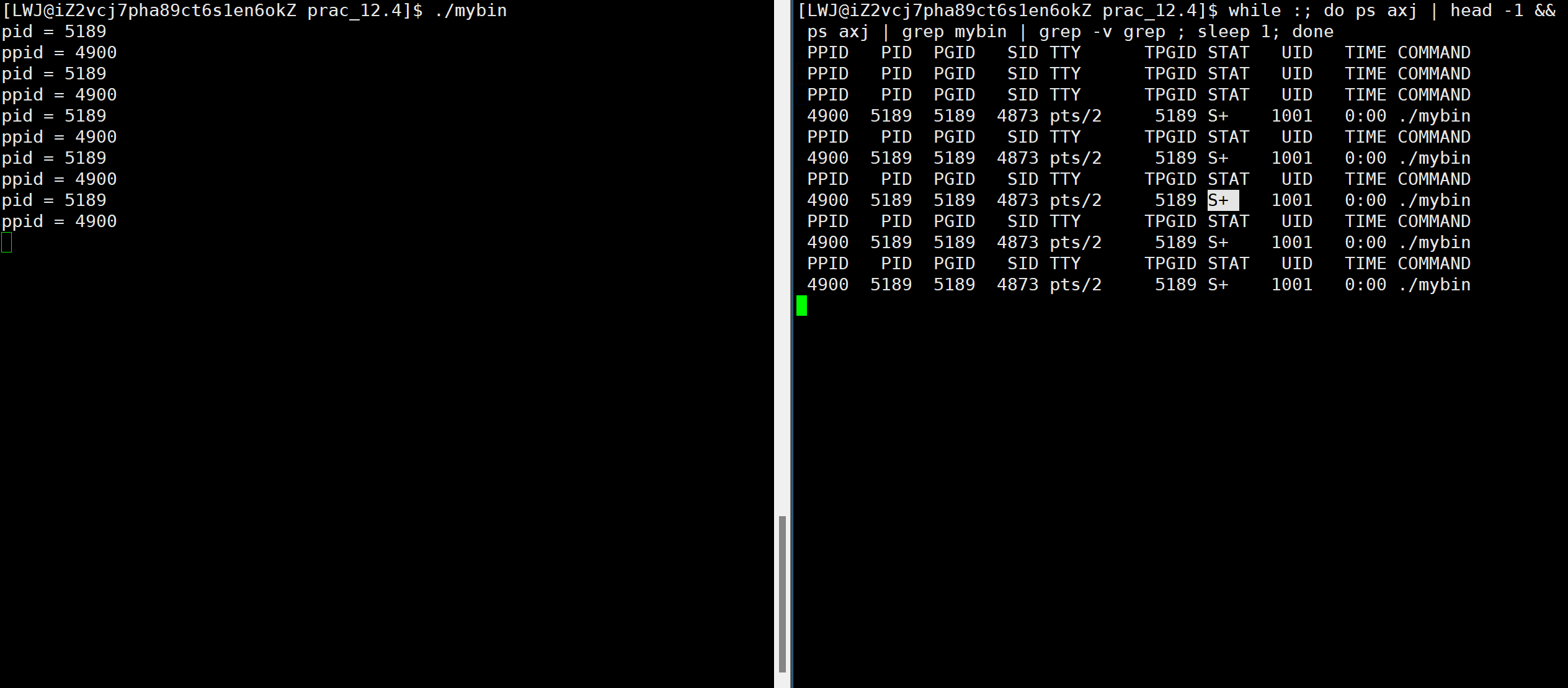
#include#include #include int main() { while (1) { std::cout << "pid = " << getpid() << std::endl; std::cout << "ppid = " << getppid() << std::endl; sleep(1); } return 0; } 操作:
./mybin #mybin是上面代码生成的可执行程序 while :; do ps axj | head -1 && ps axj | grep mybin | grep -v grep; sleep 1; done # 每隔一秒,循环打印本进程和父进程的进程标识符效果:

2.4 进程状态
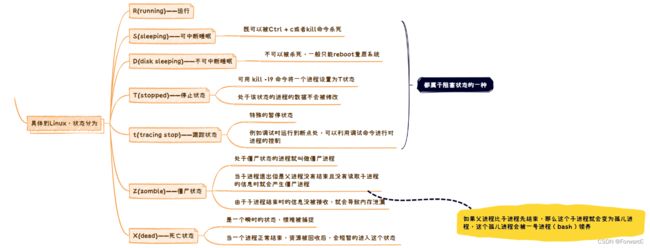
2.4.1 从操作系统学科上来说

从操作系统学科上来说,进程状态分为:运行、阻塞、挂起三种
2.4.1.1 运行
每个CPU都会维护一个运行(调度)队列(每个CPU有且只有一个调度队列)
- 无论一个进程有没有被CPU调度,凡是在调度队列的进程都处于运行状态
- 说明,进程的处于运行状态说明了它准备好了随时被调度
需要注意:
一个进程不可能没有限制的运行下去。现代操作系统,都是基于时间片进行轮转的(实时操作系统除外)
为了确保CPU资源的合理分配,CPU规定了每个进程的最长运行时间,这个时间也被称为时间片(1ms)。
如果一个进程在时间片到了还没有执行完,那么操作系统会直接中断该进程并让CPU执行下一个进程
2.4.1.2 阻塞
-
当一个进程正在等待某种资源的时候,它就会被操作系统控制,离开调度队列,进入等待队列,从而进入阻塞状态
-
只有获得所需要的资源的时候,才会重新进入调度队列,等待CPU调度执行
-
例如,当函数
scanf()函数被执行时,程序就会等待从缓冲区读取信息,这个时候对应的进程就处于阻塞状态
2.4.1.3 挂起
挂起状态十分罕见,因此我们这里只分析挂起状态的一种——阻塞挂起
- 一个进程会被操作系统设置为挂起状态必须有一个前提——内存资源已经十分吃紧
- 阻塞挂起——当一个进程被设置为阻塞状态时,内存资源吃紧,为了不使系统崩溃,操作系统会将这个进程移出内存,转入硬盘空间,这时这个进程的状态就变为了阻塞挂起
应该清楚:
- 操作系统对进程的操作,一直操作的是进程的
task_struct- 进程状态的变迁,就是操作系统将进程对应的**
task_struct迁移到不同队列的过程**(例如,运行状态到阻塞状态就是task_struct从调度队列迁移到等待队列)
2.4.2 具体到Linux操作系统
我们可以看看Linux内核源代码对进程是如何定义的:
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};
接下来,我们就对这些状态进行简单的了解:
2.4.2.1 R(running)
运行状态
和操作系统学科的运行状态一样,凡是在CPU维护的调度队列上的进程都处于运行状态
但是,这个运行状态可能和大家所想的运行状态可能会有出入:
我们在
Linux上运行下面代码:#include#include #include int main() { while (1) { std::cout << "pid = " << getpid() << std::endl; std::cout << "ppid = " << getppid() << std::endl; sleep(1); } return 0; } 利用命令查看进程状态:
while :; do ps axj | head -1 &&ps axj | grep mybin | grep -v grep ; sleep 1; done # mybin为上述代码生成的可执行文件结果如下:
可以看到,当我们查看进程时,竟然不是运行状态,这是为何,这个程序难道不是一直在运行吗?
我们修改代码:
#includeint main() { while (1) { ; } return 0; } 再重复上述步骤,结果如下:
可以看到,这一次的进程确实是运行状态(R)
为什么会形成这种差别?
- 可以发现,第一份代码在死循环中有向屏幕打印信息的操作,而第二份代码没有和其他硬件资源交互
- 正是因为第一份代码会向屏幕输出信息,也就是和硬件设备进行交互,那么总会有时刻他会进行资源的等待,从而退出调度队列,也就不是阻塞状态了。
- 而第二份代码没有和硬件资源交互,自然也就不存在资源等待,也就会一直处于运行状态了

2.4.2.2 S(sleeping)
该状态称为可中断睡眠
- S状态如果归类到操作系统学科的状态,也属于阻塞状态的一种
- S状态可以被
CTRL + c中断,也可以被kill -9 PID命令杀死 - 当程序在等待硬件资源时(例如
scanf(),printf()),对应的进程就处于S状态
2.4.2.3 D(disk sleep)
该状态称为不可中断睡眠
- 其也属于阻塞状态的一种
- 如果一个进程处于D状态,那么就不可以被
CTRL + c或者kill命令终止 - 一般只能
reboot重启系统来终止该进程
2.4.2.4 T(stopped)
该状态成为暂停状态
- 其也属于阻塞状态的一种
- 可以利用命令
kill -19 PID来让PID对应的进程处于T状态(利用此命令会让该进程处于后台)
例如:

2.4.2.5 t(tracing stop)
该状态称为跟踪状态
- 其也属于阻塞状态的一种
- 当使用
gdb调试工具,运行到断点处时,进程就会处于t状态
例如:
2.4.2.6 Z(zombie)
该状态称为僵尸状态
何为僵尸状态?
-
现有一个子进程和它的父进程,如果父进程没终止,而子进程终止,但是父进程没有读取子进程遗留的数据,此时该子进程就会处于僵尸状态
-
处于僵尸状态的进程就称为僵尸进程
例如:
#include 注意:
fork()函数为创建子进程函数- 给子进程返回0,给父进程返回子进程的
PID - 具体细节以后再讲
演示结果如下:

僵尸进程的危害性:
很容易想到,一个进程之所以会被创建,是因为用户想要这个进程帮其完成特定的任务
因此,当子进程结束时,必定会有结果数据,并存储到其
task_struct中,并等待其父进程接收如果父进程在子进程结束后不进行等待接收,那么子进程
task_struct就会一直存在,一直占用着内存资源最终,就导致了内存泄漏
和僵尸进程对应,还有一种特殊的进程叫做孤儿进程:
- 一个子进程和对应的父进程,如果父进程比子进程先结束,那么这个子进程就会变为孤儿进程
- 为了避免孤儿进程的资源不被接收,变成僵尸进程导致内存泄露,所有的孤儿进程会被
1号进程init领养,init为所有进程的父进程
2.4.2.7 X(dead)
该状态称为死亡状态
- 当一个进程正常结束,并且其资源得到回收后,就会进入这个状态
- X状态是一个瞬时状态,难以捕捉
2.4.3 前台进程和后台进程
可能大家已经注意到,我们之前看到的进程状态后面都有一个符号+
- 符号
+就表示这个进程为前台进程 - 前台进程可以被
CTRL + c终止
如果要要将一个可执行文件改为后台进程,可以用命令:
./file.ext &
- 当一个进程变为后台进程后,可以在程序执行的过程中继续执行shell命令
- 如果一个进程为后台进程,那就不可以用
CTRL + c终止,只能用kill -9杀死
例如:
2.5 进程优先级

进程的优先级决定了CPU分配资源的顺序
2.5.1 查看进程优先级
命令:
ps -al

其中:
-
PRI就是进程的优先级PRI的范围为[60, 99],注意是闭区间,因此PRI有40个取值PRI的值越小,表示优先级越高
-
NI为进程的nice值,为进程的修正数据NI的范围为[-20,19],注意是闭区间
2.5.2 修改进程的优先级
一般来说,不建议人为修改进程的优先级
如果要修改进程的优先级,不能直接修改PRI,而只能间接地修改NI即nice值
规则如下:
PRI(new) = PRI(old) + NI,即新的优先级等于旧的优先级加上nice值- 每一次修改进程的优先级,
PRI(old)都会被置为80 - 这样,当
nice值为负值,进程的优先级就会变高;nice为正值,进程的优先级就会变低
修改进程优先级的命令为:
topr指定进程的PID指定进程的nice值
2.6 进程的几个特性
竞争性:
系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级
独立性:
多进程运行,需要独享各种资源,多进程运行期间互不干扰
并行:
多个进程在多个CPU下分别,同时进行运行,这称之为并行
并发:
多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
2.7 进程的调度与切换

2.7.1 进程的切换
我们知道,LInux是基于时间片轮转的操作系统,如果一个进程的时间片到了,那么CPU就会终止这个进程,并调度下一个进程。
那么问题来了:
当这个被强制终止的进程再一次被CPU调度时,CPU怎么知道上一次运行的位置呢?
- CPU中存在大量的寄存器,当一个进程被CPU调度运行的时候,会产生大量的临时数据,这些临时数据会保存到某个寄存器中
- 这些临时数据就被称为硬件上下文。可以认为硬件上下文同时也会拷贝到进程的
task_struct中(实际上这种说法并不完全对) - 当一个进程没有运行结束而被强行终止时,操作系统就会对该进程进行保护上下文的操作,以确认进程运行的位置
- 当进程第二次(三次、四次……)被CPU调度时,就会进行恢复上下文的操作,从而可以继续上一次的位置运行
一次保护上下文和恢复上下文的过程就是一次进程的切换
需要注意:
一个CPU只有一套寄存器,但是一套寄存器可以有多套进程的数据
2.7.2 进程的调度
众所周知,CPU是靠调度队列来实现进程的调度的
这一节,我们要探讨Linux内核实现进程调度的O(1)算法:
一个好的调度算法,应该综合考虑优先级、饥饿问题、时间复杂度这三部分
我们先来看看涉及这一算法的调度队列的内核数据结构:
红色部分和蓝色部分是完全相同的两部分,其中:
queue[140]实际上是一个task_struct*数组,即每一个下标都可以跟一个进程task_struct的队列。同时下标[0, 99]不做分析,我们只看[100, 139]的部分(实际上就对应着40个优先级),如图:
这样,我们就可以通过从低位到高位(下标小的优先级更高)遍历这140个位置,按优先级高低的顺序依次调度进程
但是,并不一定每个下标对应的队列都有进程在排队,总会有空队列,因此一股脑地遍历140个是不合理的,我们应该尽可能的少遍历一些位置,以提高效率
这时,数组
bitmap[5]就起了作用,这是一个整型数组,一共5个整形数据,那么就会有5 * 32个比特位,那么我们就可以用这160个比特位分别代表queue[]140每个队列的情况:如果对应的比特位为0,就说明是空队列,否则说明有进程在排队这样,遍历
queue[140]就转换成了位图操作:
- 我么可以遍历
bitmap的每个整数,如果为0,就说明这个整数对应的32个比特位为0,那就对应着queue有32个位置为空队列;而如果某个整数不为0,那也可以通过位运算找到第一个1,即优先级最高的队列,从而进行进程的调度而
nr_active为一个整形变量,表示queue有多少个可调度的进程从而,这样的进程调度算法在复杂度上基本上就是
O(1)了,并且也很好的考虑了优先级的问题但显然,饥饿问题还没有解决:
有进程被调度就肯定有进程会加入运行队列,如果新加入的进程优先级一直较高,那么那些优先级较低的进程一直不被调度怎么办?
之前提到的和红色部分一摸一样的蓝色部分就是为了解决这个问题
- 我们称红色部分的
queue[140]为活跃队列,而蓝色部分的queue[140]为过期队列,如图:
- Linux规定,CPU只会调度活跃队列的进程,而新加入运行队列的进程则会进入过期队列,而不会进入活跃队列
- 我们可以将红色和蓝色这两个内容完全相同的部分看成是一个数组:
prio_arry[2]- 绿色部分为两个指针,
*active为活跃指针,*expired为过期指针,其分别指向数组的两个元素:&prio_arry[0],&prio_arry[1](一开始下标为0的为活跃队列,下标为1的为过期队列)- 这样,CPU在执行进程调度时,就会通过活跃指针
active找到活跃队列,从而进行调度- 而将活跃队列的所有进程调度完后,就会执行
swap(&active, &expired)操作,交换活跃指针和过期指针的内容,让活跃指针指向新的活跃队列(当旧的活跃队列被调度完后,过期队列就成了新的活跃队列),开始新一轮调度- 如此循环
需要注意:CPU只会通过活跃指针
active进行调度



以上就是O(1)调度算法的完整过程。