手把手教你:电影数据分析与可视化系统
系列文章
手把手教你:基于Django的新闻文本分类可视化系统(文本分类由bert实现)
手把手教你:基于python的文本分类(sklearn-决策树和随机森林实现)
手把手教你:岩石样本智能识别系统
一、项目简介
本文主要介绍如何使用python搭建:一个基于Python的电影数据分析与可视化系统
项目功能和可视化展示界面涉及以下功能模块,包括:
- 用户登录界面。
- 爬虫电影数据收集。
- 电影简介界面。根据用户偏好展示TOP10的电影。
- 搜索功能界面。按照电影名、导演、演员,模糊匹配需要搜索的电影,并展示电影详情。
- 电影数据分析可视化界面。用户选择关键词来查看数据和该分类下的数据可视化。
- 数据分析可视化包括:①电影年代、产地、类型的饼状图或柱状体、②关于电影评价的词云图分析。
如各位童鞋需要更换自己的电影数据,完全可以根据源码备注将电影文本数据更换即可直接运行。
- 登录成功后界面
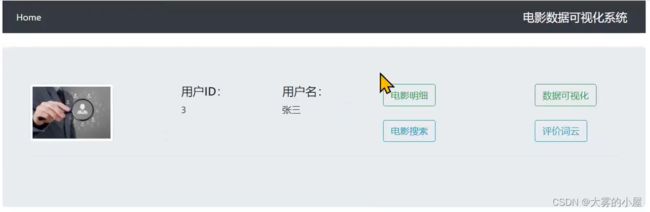
博主也参考过网上电影数据分析的相关文章,但大多是理论大于方法。很多同学肯定对原理不需要过多了解,只需要搭建出一个基于Python的电影数据分析与可视化系统即可。
也正是因为我发现网上大多的帖子只是针对原理进行介绍,功能实现的相对很少。
如果您有以上想法,那就找对地方了!
不多废话,直接进入正题!
二、数据介绍
本数据集采集于豆瓣电影,电影与演员数据、影评数据(用户、评分、评论)收集于2019年9月初,共945万数据,其中包含14万部电影,7万演员,63万用户,416万条电影评分,442万条影评。
数据集共有5个文件: movies.csv、person.csv、users.csv、comments.csv、ratings.csv,关于各个文件的具体内容将在下文介绍:
- Movie数据格式:电影数据共140502部,2019年之前的电影有139129,当前未上映的有1373部,包含21个字段
- Person数据格式:Person文件只包括演员和导演,不包含豆瓣用户数据,共72959个名人数据,包含10个字段
- User数据格式:users.csv数据为豆瓣用户的无脱敏信息,主要是与评论和评分绑定在一起,共获取了639125用户数据,包含4个字段
- Rating数据:评分数据从评论数据中获得,由于豆瓣限制了未登录用户查看的数据量,所以每部电影最多320个评分,最终得到600384个用户的4169420条评分数据,涉及电影68471部,评分值为1-5分(1-很差,2-较差,3-还行,4-推荐,5-力荐),共包含5个字段
- Comment数据格式:评论数据共4428475 条,包含6个字段
2.1 Movie数据
共计21个字段
- MOVIE_ID: 电影ID,对应豆瓣的DOUBAN_ID
- NAME: 电影名称
- ALIAS: 别名
- ACTORS: 主演
- COVER: 封面图片地址
- DIRECTORS: 导演
- GENRES: 类型
- OFFICIAL_SITE: 地址
- REGIONS: 制片国家/地区
- LANGUAGES: 语言
- RELEASE_DATE: 上映日期
- MINS: 片长
- IMDB_ID: IMDbID
- DOUBAN_SCORE: 豆瓣评分
- DOUBAN_VOTES: 豆瓣投票数
- TAGS: 标签
- STORYLINE: 电影描述
- SLUG: 加密的url,可忽略
- YEAR: 年份
- ACTOR_IDS: 演员与PERSON_ID的对应关系,多个演员采用“\|”符号分割,格式“演员A:ID\|演员B:ID”;
- DIRECTOR_IDS: 导演与PERSON_ID的对应关系,多个导演采用“\|”符号分割,格式“导演A:ID\|导演B:ID”;

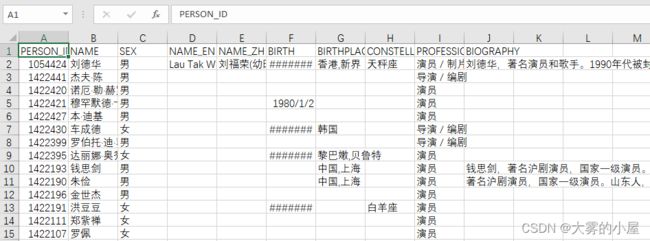
2.2 Person数据
共计10个字段
- PERSON_ID: 名人ID
- NAME: 演员名称
- SEX: 性别
- NAME_EN: 更多英文名
- NAME_ZH: 更多中文名
- BIRTH: 出生日期
- BIRTHPLACE: 出生地
- CONSTELLATORY: 星座
- PROFESSION: 职业
- BIOGRAPHY: 简介
2.3 User数据
共计4个字段
- USER_ID:豆瓣用户ID
- USER_NICKNAME: 评论用户昵称
- USER_AVATAR: 评论用户头像
- USER_URL: 评论用户url
2.4 Rating数据
共计5个字段
- RATING_ID: 评分ID
- USER_ID:豆瓣用户ID
- MOVIE_ID: 电影ID,对应豆瓣的DOUBAN_ID
- RATING: 评分
- RATING_TIME: 评分时间
2.5 Comment数据
共计6个字段
- COMMENT_ID: 评论ID
- USER_ID:用户ID
- MOVIE_ID: 电影ID,对应豆瓣的DOUBAN_ID
- CONTENT: 评论内容
- VOTES: 评论赞同数
- COMMENT_TIME: 评论时间
三、环境要求
- pycharm 22版即可
- anaconda 最新版
- Django 最新版
- Python 3.6
针对环境安装操作博主整理了操作说明,详情可见代码中对应操作文档
四、系统功能及代码示例
4.1 系统架构
本系统采用了Django架构,前端使用的HTML+CSS+bootstrap实现

4.2 数据处理
博主通过对数据进行预处理,对电影年份进行分析,生成词云图。此部分词云图生成代码为独立代码,大家可以借鉴进行修改生成自己的词云图。
from collections import Counter
from os import path
import numpy as np
import pandas as pd
from PIL import Image
from tqdm import tqdm
def create_movies_data():
read_movies = pd.read_csv('./豆瓣电影数据集/movies.csv', encoding='utf-8')
# 删除脏数据
movies = read_movies.dropna(
subset=['NAME', 'MOVIE_ID', 'COVER', 'ACTORS', 'DIRECTORS', 'GENRES',
'REGIONS', 'RELEASE_DATE', 'DOUBAN_SCORE', 'STORYLINE'])
# 删除豆瓣得分为0分的脏数据
movies = movies.loc[movies['DOUBAN_SCORE'] != 0]
movies.to_csv('./data/movies.csv', encoding='utf-8-sig')
return print('创建电影数据成功,文件存放位置:data/movies.csv')
def create_years_data():
"""
获取电影年份
"""
read_movies = pd.read_csv('./data/movies.csv', encoding='utf-8')
movie_years = read_movies['RELEASE_DATE'].to_list()
year_list = []
for i in range(len(movie_years)):
year_list.append(str(movie_years[i]).split('-')[0])
data_year = Counter(year_list)
data_year = sorted(data_year.items(), key=lambda x: x[1], reverse=True)
x_years = []
y_years = []
for k, v in data_year:
x_years.append(k)
y_years.append(v)
def rp_stop_words(data, stop_words):
"""
定义删除停用词函数
"""
if data in stop_words:
data = ''
else:
data = data
return data
def prt_word_cloud(s_num=10000):
"""
如需修改云图样式在此处替换同路径下img.jpg文件
s_num:评论抽样数量
"""
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import re
import jieba
import jieba.analyse as analyse
# 获取评论信息
file_encoding = 'gbk'
# 忽略错误字符
input_fd = open('./豆瓣电影数据集/comments.csv', encoding=file_encoding, errors='ignore')
read_comments = pd.read_csv(input_fd)
text_sap = read_comments.sample(s_num)['CONTENT']
# 合并
text = ' '.join(text_sap.to_list())
# 数据清洗,删除脏字符,保留中文
text_re = re.sub('[^\u4E00-\u9FFF]+', ' ', text)
text_cut = ' '.join(jieba.cut(text_re))
text_cut_list = text_cut.split(' ')
# 去停用词
# 加载停用词表,如需修改停用词,替换原文件“stopwords.txt”
txt_stop = './data/stopwords.txt'
# 将停用词库读入列表
stop_words = []
with open(txt_stop, encoding='utf-8') as fin:
for line in fin.readlines():
stop_words.append(str(line.replace(' \n', '')))
# 形成最终结果
text_last_list = []
# 去停用词
for word in text_cut_list:
f_word = rp_stop_words(word, stop_words)
if len(f_word) >= 2:
text_last_list.append(f_word)
text_last = ' '.join(text_last_list)
# 文本分词,提取Tfi-Df模型中权重Top200的单词
keywords_count_list = analyse.extract_tags(text_last, topK=500, withWeight=True)
keywords_all = ' '.join([ite[0] for ite in keywords_count_list])
# 读取词云背景图
# background_image = plt.imread('./static/img/background_img.jpg')
background_image = np.array(Image.open("./static/img/background_img.jpg"))
# 词云实现
wc = WordCloud(background_color='white', # 设置背景颜色
max_words=200, # 设置最大现实的字数
mask=background_image, # 设置背景图片
stopwords=STOPWORDS, # 设置停用词
font_path='simfang.ttf', # 设置字体格式,如不设置显示不了中文
max_font_size=200, # 设置字体最大值
random_state=9, # 设置有多少种随机生成状态,即有多少种配色方案
)
wc.generate(keywords_all)
image_colors = ImageColorGenerator(background_image)
wc.recolor(color_func=image_colors)
plt.figure(figsize=(10, 10))
plt.imshow(wc)
plt.axis('off')
plt.savefig('./static/img/WordCloud_img.jpg')
# plt.show()
return print('创建评论词云图成功,文件存放位置:/static/img/WordCloud_img.jpg')
if __name__ == '__main__':
create_movies_data()
prt_word_cloud()
4.3 系统登录功能

doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css"
integrity="sha384-B0vP5xmATw1+K9KRQjQERJvTumQW0nPEzvF6L/Z6nronJ3oUOFUFpCjEUQouq2+l" crossorigin="anonymous">
{% load static %}
<link rel="stylesheet" href="{% static 'css/mycss.css' %}" type="text/css">
<title>电影数据可视化系统title>
head>
<body>
<div class="container">
<nav class="navbar navbar-expand-lg navbar-dark bg-dark">
<button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarSupportedContent"
aria-controls="navbarSupportedContent" aria-expanded="false" aria-label="Toggle navigation">
<span class="navbar-toggler-icon">span>
button>
<div class="collapse navbar-collapse" id="navbarSupportedContent">
<ul class="navbar-nav mr-auto">
<li class="nav-item">
<a class="nav-link active" href="{% url 'start' %}">Home <span class="sr-only">(current)span>a>
li>
ul>
<div class="text-center">
<span class="navbar-brand mb-0 h1">电影数据可视化系统span>
div>
div>
nav>
div>
<br>
<div class="container">
<div class="jumbotron">
<div id="serch">
<h3 class="display-8 text-center">请登录
h3>
<br>
<div class="row align-items-center col-auto">
<div class="col-sm-12">
<form class="form-outline" method="post" action="{% url 'get_ans' %}">
{% csrf_token %}
<div>
<h5 class="display-10 text-danger">用户名: h5>
<input class="form-control mr-sm-2" type="search" placeholder="name" aria-label="Search"
name="user_name">
div>
<br>
<div>
<h5 class="display-10 text-danger">密码: h5>
<input class="form-control mr-sm-2" type="search" placeholder="password" aria-label="Search"
name="password">
div>
<br>
<button class="btn btn-outline-success my-2 my-sm-0" type="submit">登录button>
form>
div>
div>
div>
<div id="answer" class="col-auto">
<hr class="my-4">
{% block content %}
{% endblock %}
div>
div>
div>
<br>
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/jquery.slim.min.js"
integrity="sha384-DfXdz2htPH0lsSSs5nCTpuj/zy4C+OGpamoFVy38MVBnE+IbbVYUew+OrCXaRkfj"
crossorigin="anonymous">script>
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.bundle.min.js"
integrity="sha384-Piv4xVNRyMGpqkS2by6br4gNJ7DXjqk09RmUpJ8jgGtD7zP9yug3goQfGII0yAns"
crossorigin="anonymous">script>
body>
html>
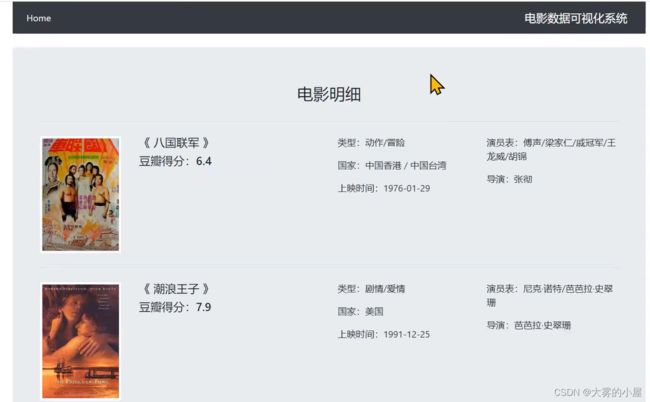
4.4 电影简介
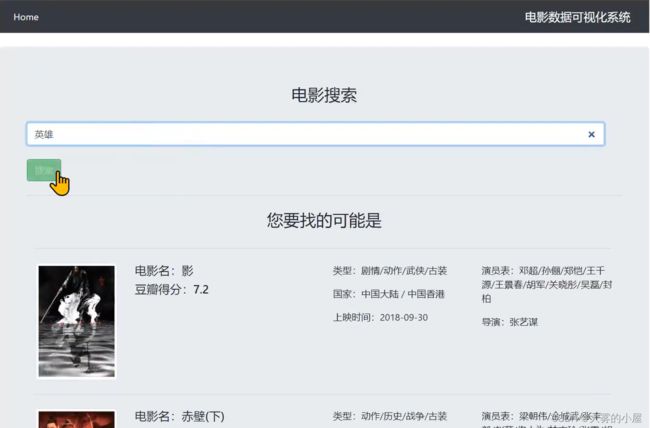
4.5 电影搜索界面
def get_one_movie(text):
"""
获取电影搜索数据
"""
read_movies = pd.read_csv('./data/movies.csv', encoding='utf-8')
# 正则表达式匹配电影名、演员、导演
movies = read_movies.loc[read_movies['NAME'].str.contains(r'.*?' + text + '.*') |
read_movies['ACTORS'].str.contains(r'.*?' + text + '.*') |
read_movies['DIRECTORS'].str.contains(r'.*?' + text + '.*')
]
movies_name = movies['NAME'].to_list()
movies_id = movies['MOVIE_ID'].to_list()
movies_cover = movies['COVER'].to_list()
movies_actors = movies['ACTORS'].to_list()
movies_directors = movies['DIRECTORS'].to_list()
movies_genres = movies['GENRES'].to_list()
movies_regions = movies['REGIONS'].to_list()
movies_date = movies['RELEASE_DATE'].to_list()
movies_score = movies['DOUBAN_SCORE'].to_list()
movies_list = []
for i in range(len(movies)):
movies_data = {
"movies_name": movies_name[i],
"movies_id": movies_id[i],
"movies_cover": movies_cover[i],
"movies_actors": movies_actors[i],
"movies_directors": movies_directors[i],
"movies_genres": movies_genres[i],
"movies_regions": movies_regions[i],
"movies_date": movies_date[i],
"movies_score": movies_score[i]
}
movies_list.append(movies_data)
return movies_list
def get_all_movie():
"""
获取所有电影数据
"""
# 此处设置电影明细中展示的电影数量。
get_movie_number = 100
read_movies = pd.read_csv('./data/movies.csv', encoding='utf-8')
movies = read_movies.sample(get_movie_number)
movies_name = movies['NAME'].to_list()
movies_id = movies['MOVIE_ID'].to_list()
movies_cover = movies['COVER'].to_list()
movies_actors = movies['ACTORS'].to_list()
movies_directors = movies['DIRECTORS'].to_list()
movies_genres = movies['GENRES'].to_list()
movies_regions = movies['REGIONS'].to_list()
movies_date = movies['RELEASE_DATE'].to_list()
movies_score = movies['DOUBAN_SCORE'].to_list()
movies_list = []
for i in range(len(movies)):
movies_data = {
"movies_name": movies_name[i],
"movies_id": movies_id[i],
"movies_cover": movies_cover[i],
"movies_actors": movies_actors[i],
"movies_directors": movies_directors[i],
"movies_genres": movies_genres[i],
"movies_regions": movies_regions[i],
"movies_date": movies_date[i],
"movies_score": movies_score[i]
}
movies_list.append(movies_data)
return movies_list
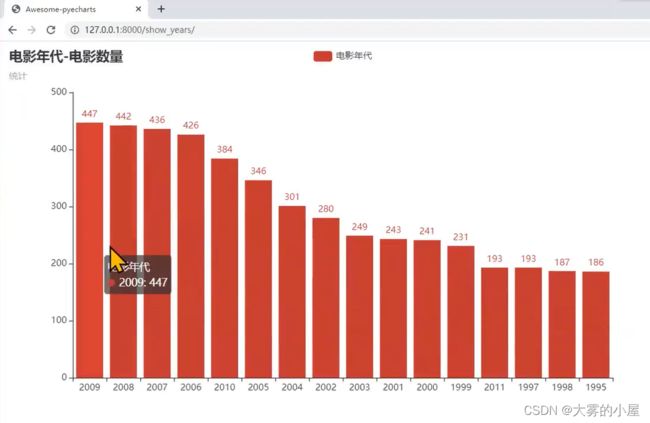
4.6 数据可视化-电影年代分析
4.7 数据可视化-电影产地分析
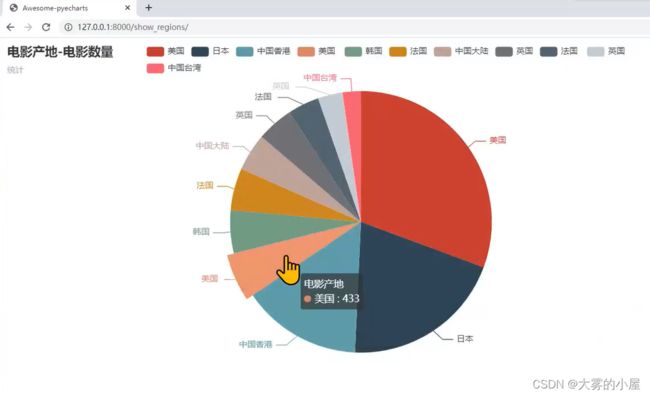
def show_year(number=15):
from pyecharts.charts import Bar
from pyecharts import options as opts
"""
获取电影年代展示功能实现
"""
read_movies = pd.read_csv('./data/movies.csv', encoding='utf-8')
movie_years = read_movies['RELEASE_DATE'].to_list()
year_list = []
# 处理日期格式
for i in range(len(movie_years)):
year_list.append(str(movie_years[i]).split('-')[0])
data_year = Counter(year_list)
# 排序
data_year = sorted(data_year.items(), key=lambda x: x[1], reverse=True)
x_years = []
y_years = []
for k, v in data_year:
x_years.append(k)
y_years.append(v)
# 生成网页
bar = Bar()
# 展示年份最多的,前15个年份
bar.add_xaxis(x_years[:number + 1])
bar.add_yaxis("电影年代", y_years[:number + 1])
bar.set_global_opts(title_opts=opts.TitleOpts(title="电影年代-电影数量", subtitle="统计"))
# render 会生成本地 HTML 文件,默认会在当前目录生成 render.html 文件
# 也可以传入路径参数,如 bar.render("mycharts.html")
bar.render("templates/fc_show.html")
4.8 数据可视化-电影类型分析
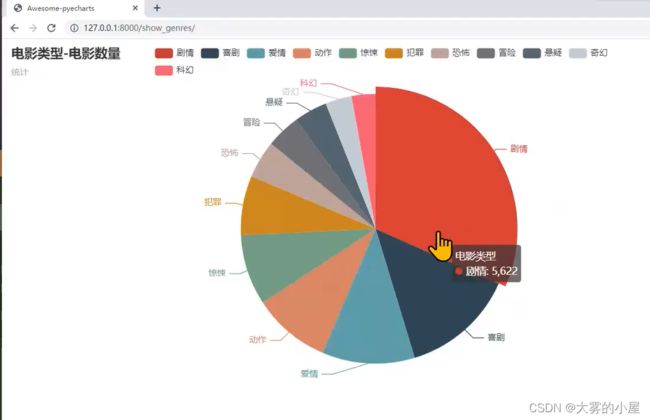
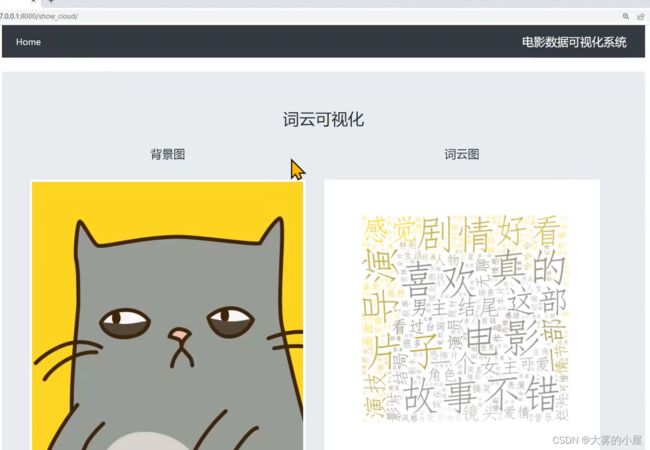
4.9 电影评价词云图分析
此部分使用了搜索中的模糊匹配的电影数据进行词云图展示,大家可以根据自己的喜好修改想展示的词云图内容,以及背景图片
五、完整代码地址
由于项目代码量和数据集较大,感兴趣的同学可以下载完整代码,使用过程中如遇到任何问题可以在评论区评论或者私信我,我都会一一解答。
完整代码下载:
【代码分享】手把手教你:电影数据分析与可视化系统