PostgreSQL 可观测性最佳实践
简介
软件简述
PostgreSQL 是一种开源的关系型数据库管理系统 (RDBMS),它提供了许多可观测性选项,以确保数据库的稳定性和可靠性。
可观测性
可观测性(Observability)是指对数据库状态和操作进行监控和记录,以便在系统出现问题时能够快速诊断和修复。
数据采集
观测云提供了一套简单且高效的 PostgreSQL 观测方案,帮助客户快速定位及解决数据库相关问题。

DataKit 是观测云开发的一款开源、一体式的数据采集 Agent,它提供全平台操作系统支持,拥有全面数据采集能力,涵盖主机、容器、中间件、链路、日志以及安全等各种场景。通过其采集 PostgreSQL 数据只需要两步:
- 第一步:安装 DataKit 数据采集器
- 第二步:通过 DataKit 内置的 Postgresql 插件采集数据
配置示例:
[[inputs.postgresql]]
address = "postgres://postgres@localhost/test?sslmode=disable"
interval = "60s"
[[inputs.postgresql.relations]]
relation_regex = "test*"
schemas = ["public"]
relkind = ["r", "p"]
[inputs.postgresql.log]
files = ["/var/log/pgsql/*.log""]
pipeline = "postgresql.p"
指标详解
PostgreSQL 拥有众多的监控指标,通过 SQL 命令可以查看系统变量、系统函数和系统视图等信息。观测云已经把这些 SQL 编写成内置的指标集形式,开箱即用。
1.pg_stat_database (datakit postgresql)
示例语句:
postgres=# select * from pg_stat_database where datname='postgres';
-[ RECORD 1 ]------------+------------------------------
datid | 14486
datname | postgres
numbackends | 2
xact_commit | 1406600
xact_rollback | 20720
blks_read | 1558
blks_hit | 48043798
tup_returned | 289085449
tup_fetched | 21237763
tup_inserted | 174
tup_updated | 5
tup_deleted | 41
conflicts | 0
temp_files | 0
temp_bytes | 0
deadlocks | 0
checksum_failures |
checksum_last_failure |
blk_read_time | 0
blk_write_time | 0
session_time | 1030041341.636
active_time | 1740209.944
idle_in_transaction_time | 879253.682
sessions | 15950
sessions_abandoned | 2
sessions_fatal | 0
sessions_killed | 4
stats_reset | 2023-04-06 11:04:11.693074+08
通过 pg_stat_database 可以基本了解数据库的整体运行情况。
- 当 tup_returned 值远大于 tup_fetched,说明数据库历史执行的 sql 很多都是全表扫描,存在很多没有走索引的 sql,这时候可以结合 pg_stat_statments 来查找慢 sql,也可以通过 pg_stat_user_tables 找到全表扫描次数和行数最多的表。
- 当 tup_updated 很高说明数据库有很频繁的更新,这个时候就需要关注一下 vacuum 相关的指标和长事务,如果没有及时进行垃圾回收会造成数据膨胀的比较厉害,一定程度会响应表查询效率。
- 当 temp_files 的数值比较大时,说明存在很多的排序 hash,或者聚合操作,可以通过增大 work_mem 减少临时文件的产生,并且同时这些操作的性能也会有较大的提升。
2.pg_stat_user_tables (datakit postgresql_stat)
示例语句:
select * from pg_stat_user_tables where relname='test';
-[ RECORD 1 ]-------+--------
relid | 16455
schemaname | public
relname | test
seq_scan | 1
seq_tup_read | 0
idx_scan | 0
idx_tup_fetch | 0
n_tup_ins | 7
n_tup_upd | 0
n_tup_del | 0
n_tup_hot_upd | 0
n_live_tup | 7
n_dead_tup | 0
n_mod_since_analyze | 7
n_ins_since_vacuum | 7
last_vacuum |
last_autovacuum |
last_analyze |
last_autoanalyze |
vacuum_count | 0
autovacuum_count | 0
analyze_count | 0
autoanalyze_count | 0
通过 pg_stat_user_tables ,可以知道当前数据库下哪些表发生全表扫描频繁,哪些表变更比较频繁,对于变更较频繁的表可多关注其 vacuum 相关的指标,避免表膨胀。
3.pg_stat_user_indexes (datakit postgresql_index)
示例语句:
select * from pg_stat_user_indexes where relname='test';
-[ RECORD 1 ]-+-------------
relid | 16455
indexrelid | 16460
schemaname | public
relname | test
indexrelname | test_pkey
idx_scan | 0
idx_tup_read | 0
idx_tup_fetch | 0
通过 pg_stat_user_indexes 可以查看对应索引的使用情况,协助我们判断哪些索引当前基本不使用,对这些无效的冗余索引,可进行删除。
4.pg_statio_user_tables (datakit postgresql_statio)
示例语句:
select * from pg_statio_user_tables where relname='test';
-[ RECORD 1 ]---+--------
relid | 16455
schemaname | public
relname | test
heap_blks_read | 1
heap_blks_hit | 6
idx_blks_read | 2
idx_blks_hit | 8
toast_blks_read | 0
toast_blks_hit | 0
tidx_blks_read | 0
tidx_blks_hit | 0
通过对 pg_statio_user_tables 的查询,如果 heap_blks_read,idx_blks_read 很高说明 shared_buffer 较小,存在频繁需要从磁盘或者 page cache 读取到 shared_buffer 中。
5.pg_stat_bgwriter (datakit postgresql_bgwriter)
示例语句:
select * from pg_stat_bgwriter;
-[ RECORD 1 ]---------+------------------------------
checkpoints_timed | 14438
checkpoints_req | 14
checkpoint_write_time | 64064
checkpoint_sync_time | 83
buffers_checkpoint | 656
buffers_clean | 0
maxwritten_clean | 0
buffers_backend | 220
buffers_backend_fsync | 0
buffers_alloc | 4674
stats_reset | 2023-04-06 11:00:39.227749+08
通过对 pg_stat_bgwriter 的查询,可以查看后端写进程活动的统计信息。bgwriter、checkpointer 和 backend 都可能把脏数据回写到存储上。正常情况下,我们希望大部分的脏数据都是 bgwriter 写回存储的,少量的脏数据是 checkpoint 写入的,更少的数据是 backend 写入的。因为 backend 写入数据是十分高成本的,不过好像事实上并非如此,backend 写入的比例很高。
6.pg_stat_replication (datakit postgresql_replication)
示例语句:
select * from pg_stat_replication;
-[ RECORD 1 ]----+-----------------------------
pid | 1492
usesysid | 12849
usename | guance
application_name | walreceiver
client_addr | 192.168.0.187
client_hostname |
client_port | 41760
backend_start | 2023-05-12 16:41:09.54947+08
backend_xmin |
state | streaming
sent_lsn | 2/100001B0
write_lsn | 2/100001B0
flush_lsn | 2/100001B0
replay_lsn | 2/100001B0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
pg_stat_replication 仅仅在主从架构下才会显示相关数据,根据对 pg_stat_replication 表的查询可以查看当前复制的模式、复制配置信息、复制位点信息等。
例如 sync_state 可以分为 :
- async:表示备库为异步同步模式
- potential :表示备库当前为异步同步模式,如果当前的同步备库宕机,异步备库可升级成为同步备库
- sync : 表示当前备库为同步模式
- quorum :表示备库为 quorumstandbys 的候选
日志相关
PostgreSQL 有 3 种日志,分别是:
| 日志目录 | 作用 | 可读性 | 默认状态 |
|---|---|---|---|
| pg_log | 数据库运行日志 | 内容可读 | 默认关闭,需要设置参数启动 |
| pg_xlog | WAL 日志,即重做日志 | 内容一般不具有可读性 | 强制开启 |
| pg_clog | 事务提交日志,记录的是事务的元数据 | 内容一般不具有可读性 | 强制开启 |
日志路径
pg_xlog 和 pg_clog 一般是在 postgresql 安装目录的文件夹下。
pg_log 默认路径是 postgresql 安装目录下的 pg_log,实际路径可以在 postgresql.conf 文件中设置。
日志解析
1.pg_log
这个日志一般是记录服务器与 DB 的状态,比如各种 Error 信息,定位慢查询 SQL,数据库的启动关闭信息,发生 checkpoint 过于频繁等的告警信息,诸如此类。该日志有 .csv 格式和 .log。建议使用 .csv 格式,因为它一般会按大小和时间自动切割,毕竟查看一个巨大的日志文件比查看不同时间段的多个日志要难得多。
清理原则:pg_log 是可以被 清理删除,压缩打包或者转移,同时并 不影响 数据库的正常运行。
2.pg_xlog
这个日志是记录的 Postgresql 的 WAL 信息,也就是一些事务日志信息 (transaction log)。这种日志形如 ‘00000001000000000000008E’,包含的是最近失误的数据镜像,这些日志会在定时回滚恢复(PITR),流复制(Replication Stream)以及归档时能被用到。
当你的归档或者流复制发生异常的时候,事务日志会不断地生成,有可能会造成你的磁盘空间被塞满,最终导致数据库挂掉或者起不来。遇到这种情况不用慌,可以先关闭归档或者流复制功能,备份 pg_xlog 日志到其他地方,但不要删除,然后删除较早时间的的 pg_xlog,有一定空间后再试着启动 Postgresql。
清理原则:这些日志 非常重要 ,记录着数据库发生的各种事务信息,不得随意删除 或者移动这类日志文件,不然你的数据库会有 无法恢复 的风险。
什么是 WAL ?
PostgreSQL 在将缓存的数据刷入到磁盘之前,先写日志,这就是PostgreSQL WAL ( Write-Ahead Log ) 方式,也就是预写日志方式 。
3.pg_clog
pg_clog 这个文件也是事务日志文件,但与 pg_xlog 不同的是它记录的是事务的元数据 (metadata),这个日志告诉我们哪些事务完成了,哪些没有完成。
清理原则:这个日志文件一般非常小,但是 重要性 也是相当高,不得随意删除 或者对其更改信息。
日志配置
可以通过配置文件 postgresql.conf 进行设置
主要参数说明:
- logging_collector = on/off
是否将日志重定向至文件中,默认是 off。 - log_directory =
pg_log
日志文件目录,默认是 pgdata 的相对路径,即 pgdata 的相对路径,即 {pgdata}/pg_log,也可以改为绝对路径。日志文件可能会非常多,建议将日志重定向到其他目录或分区。将此配置修改其他目录时,必须先创建此目录,并修改权限,使得 postgres 用户对该目录有写权限。 - log_filename =
postgresql-%Y-%m-%d*%H%M%S.log
日志文件命名形式,使用默认即可 - log_rotation_age = 1d
单个日志文件的生存期,默认 1 天,在日志文件大小没有达到 log_rotation_size 时,一天只生成一个日志文件。 - log_rotation_size = 10MB
单个日志文件的大小,如果时间没有超过 log_rotation_age,一个日志文件最大只能到 10M,否则将新生成一个日志文件。 - log_truncate_on_rotation = off
当日志文件已存在时,该配置如果为 off,新生成的日志将在文件尾部追加,如果为 on,则会覆盖原来的日志。 - log_lock_waits = off
控制当一个会话等待时间超过 deadlock_timeout 而被锁时是否产生一个日志信息。在判断一个锁等待是否会影响性能时是有用的,缺省是 off。 - log_statement =
none# none, ddl, mod, all
控制记录哪些 SQL 语句。none 不记录,ddl 记录所有数据定义命令,比如 CREATE,ALTER 和 DROP 语句。mod 记录所有 ddl 语句,加上数据修改语句 INSERT,UPDATE 等。all 记录所有执行的语句,将此配置设置为 all 可跟踪整个数据库执行的 SQL 语句。 - log_duration = off
记录每条 SQL 语句执行完成消耗的时间,将此配置设置为 on ,用于统计哪些 SQL 语句耗时较长。 - log_min_duration_statement = -1
-1 表示关闭记录。0 表示记录所有 statements 的执行时间按,若为>0(单位为 ms)的一个值,则记录执行时间大于该值的 statements。可以使用该配置来跟踪那些耗时较长,可能存在性能问题的 SQL 语句。虽然使用 log_statement 和 log_duration 也能够统计 SQL 语句及耗时,但是 SQL 语句和耗时统计结果可能相差很多行,或在不同的文件中,但是 log_min_duration_statement 会将 SQL 语句和耗时在同一行记录,更方便阅读。 - log_connections = off
是否记录连接日志 - log_disconnections = off
是否记录连接断开日志 - log_line_prefix =
%m %p %u %d %r
日志输出格式(%m,%p 实际意义配置文件中有解释),可根据自己需要设置(能够记录时间,用户名称,数据库名称,客户端 IP 和端口,方便定位问题)。 - log_timezone =
Asia/Shanghai
日志时区,最好和服务器设置同一个时区,方便问题定位
场景视图
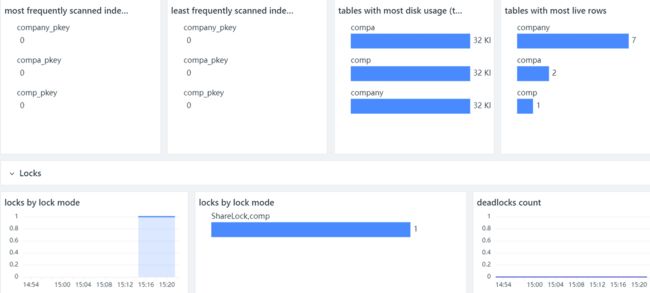
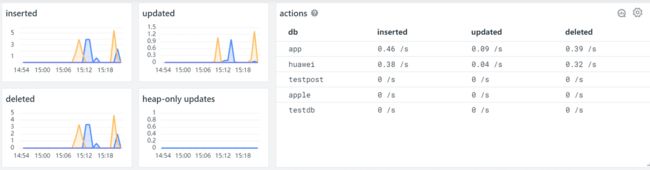
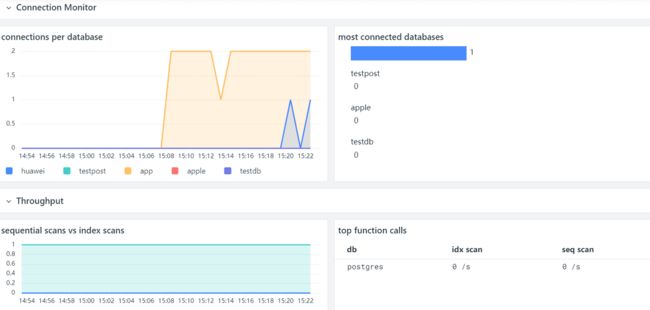
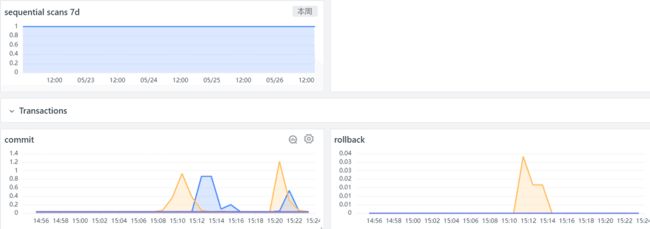
观测云已经内置了 PostgreSQL 的场景视图,直接使用即可,用户也可以自定义修改任何想要的指标视图。
添加方式
登录「观测云控制台」-「场景」-「仪表板」-「新建仪表板」-「系统视图」,搜索“PostgreSQL”,添加即可。

效果展示
若想要在此基础上自定义图表,可以参考《观测云文档:可视化图表》。