R语言数据处理:tidyr包学习
文章目录
- 前言
- 1、gather()函数
- 2、spread()函数
- 3、unite()函数
- 4、separate()函数
- 5、缺失值处理
- 总结
前言
在R语言中,tidyr包的应用 tidyr主要提供了一个类似Excel中数据透视表 (pivottable)的功能; gather和spread函数将数据在长格式和宽格式之间相互转化,应用在比如稀疏矩阵和稠密矩阵之间的转化; separate和union方法提供了数据分组拆分、合并的功能,应用在nominal数据的转化上 R将整洁数据定义为:每个变量的数据存储在自身的列中,每个观测值的数据存储在其自身的行中。整洁数据是进行数据再加工的基础。在tidyr包中,一般包括几个函数:
1、gather()函数
2、spread()函数
3、separate()函数
4、unite()函数
5、缺失值处理replace_na()函数
安装tidyr包与使用tidyr包;
install.packages("tidyr")
library(tidyr)
1、gather()函数
gather()函数,它可以实现将以列位字段的数据表,转化为一列长数据格式。函数使用规则为:
gather(
data,#需要转换的数据,按列排开
key = "key",#将数据表中的所有列赋值给key
value = "value",#将数据表中的所有值赋值给value
...,
na.rm = FALSE,#表示是否删除缺失值,默认为否
convert = FALSE,
factor_key = FALSE
)
示例 1:某班五位同学的考试成绩存在一个宽度数据表中,现在需要我们将这个数据表转化为长度格式的数据。
df <- data.frame(姓名=c('赵','钱','孙','李','周'),
语文=c(95,89,79,88,81),
数学=c(89,88,81,78,90),
英语=c(89,78,73,69,80))
df2 <- gather(df,long,成绩,语文,数学,英语)
运行结果
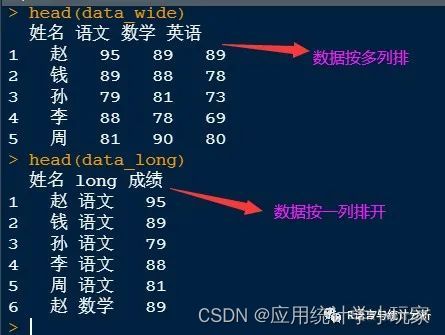
上图可知,我们将多列的成绩转化为了所有成绩在一列出现。
2、spread()函数
spread()函数可与gather()函数进行互相转换。其函数使用规范为:
spread(data, #需要转换的表
key, #将变量转化为字段
value, #需要分散的值
fill = NA,#转化后对于缺失值可用fill的值填补
convert = FALSE, drop = TRUE, sep = NULL)
还是刚才的数据,我们使用spread()函数将数据再转化回去。
data_spread <- spread(data_long,科目,成绩)

从图中来看,我们已将原始宽度数据表转化为长度数据表后,又将长度数据表转化为了原始的宽度数据表。因此,对于spread()函数可与gather()函数来说,它们之间可以进行互相转换。
3、unite()函数
unite()函数可以合并不同的变量值,其函数使用格式为:
unite(data,#数据框
col,#合并后的名称
...,
sep = "_",#合并连接符
remove = TRUE,#是否删除被组合的列
na.rm = FALSE)
依旧使用刚才的数据,在原始数据多加一列字,将姓名与字合并,组成新的列名字。
data_unite <- unite(data_wide,
名字,
姓名,字,
sep=" ",
remove=F)
运行结果:
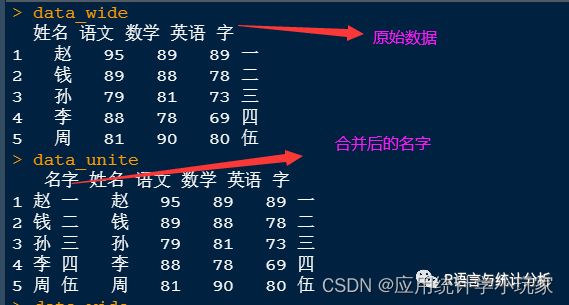
从上图来看,姓名与字已经合并,连接符为空格,因为remove为F,所以不删除被合并的列。
4、separate()函数
separate()函数可以将一列拆分为多列,多用于时间型数据。该函数的使用规范为:
separate(
data,#数据框
col,#准备拆分的列
into,#拆分后新列名
sep = "[^[:alnum:]]+",#拆分分隔符
remove = TRUE,#是否删除被分割的列
convert = FALSE,
extra = "warn",
fill = "warn",
...)
利用刚才合并的数据进行拆分,将名字一列拆分为姓名1,字1。因为我们上面remove选择了F,所以我们这里是姓名1,字1,如果我们选择了T,那么我们这里直接改为姓名,字就行。
data_separate <- separate(data_unite,
名字,
c("姓名1","字1"),
sep = " ",
remove = T)
运行结果:
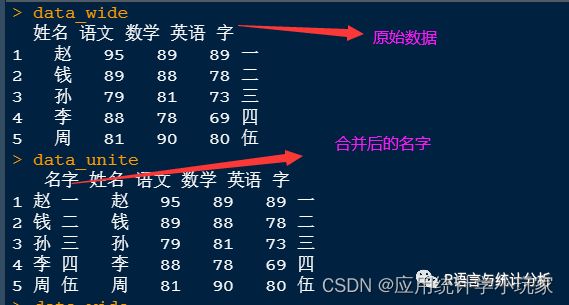
从上图可知,之前合并的列已经被拆分了,由于之前合并的时候remove的值为F,所以在后面拆分的时候会看到两个姓名与字。
由此可见,separate()函数、unite()函数也是一个互相转换的函数,两者之间可以对数据进行互相拆分与合并。
5、缺失值处理
在日常生活中,我们拿到的数据很有可能有缺失值,因此我们需要对缺失值进行处理。在tidyr包中,缺失值处理可以用replace_na()函数进行处理。replace_na()函数使用格式为:
replace(x,list, values)#list为一个列表,将插入的值放在list里面
依然使用上面的数据,随机改两个数据为缺失值,进行缺失值填补。
data_wide <- data.frame(姓名=c('赵','钱','孙','李','周'),
语文=c(95,89,79,88,NA),
数学=c(89,88,81,78,90),
英语=c(89,78,73,69,NA))
#以60分为几个,将它填入数据缺失值中。
data_wide %>%
replace_na(list(语文=60,英语=60))
运行结果:

总结
tidyr包是数据处理数据操作很方便的一个包,他能实现与excel数据分列合并之类的功能。