NOSQL,Redis的备份和回收
Redis的超时命令和垃圾回收策略
如 Java 虚拟机,它提供了自动 GC(垃圾回收)的功能,来保证 Java 程序使用过且不再使用的 Java 对象及时的从内存中释放掉,从而保证内存空间可用。
当程序编写不当或考虑欠缺的时候(比如读入大文件),内存就可能存储不下运行所需要的数据,那么 Java 虚拟机就会抛出内存溢出的异常而导致服务失败。同样,Redis 也是基于内存而运行的数据集合,也存在着对内存垃圾的回收和管理的问题。
Redis 基于内存,而内存对于一个系统是最为宝贵的资源,而且它远远没有磁盘那么大,所以对于 Redis 的键值对的内存回收也是一个十分重要的问题,如果操作不当会产生 Redis 宕机的问题,使得系统性能低下。
一般而言,和 Java 虚拟机一样,当内存不足时 Redis 会触发自动垃圾回收的机制,而程序员可以通过 System.gc() 去建议 Java 虚拟机回收内存垃圾,它将“可能”(注意,System.gc() 并不一定会触发 JVM 去执行回收,它仅仅是建议 JVM 做回收)触发一次 Java 虚拟机的回收机制,但是如果这样做可能导致 Java 虚拟机在回收大量的内存空间的同时,引发性能低下的情况。
对于 Redis 而言,del 命令可以删除一些键值对,所以 Redis 比 Java 虚拟机更灵活,允许删除一部分的键值对。与此同时,当内存运行空间满了之后,它还会按照回收机制去自动回收一些键值对,这和 Java 虚拟机又有相似之处,但是当垃圾进行回收的时候,又有可能执行回收而引发系统停顿,因此选择适当的回收机制和时间将有利于系统性能的提高,这是我们需要去学习的。
在谈论 Redis 内存回收之前,首先要讨论的是键值对的超时命令,因为大部分情况下,我们都想回收那些超时的键值对,而不是那些非超时的键值对。
对于 Redis 而言,可以给对应的键值设置超时,相关命令如表 1 所示。
| 命 令 | 说 明 | 备 注 |
|---|---|---|
| persist key | 持久化 key,取消超时时间 | 移除 key 的超时时间 |
| ttl key | 査看 key 的超时时间 | 以秒计算,-1 代表没有超时时间,如果不存在 key 或者 key 已经超时则为 -2 |
| expire key seconds | 设置超时时间戳 | 以秒为单位 |
| expireat key timestamp | 设置超时时间点 | 用 uninx 时间戳确定 |
| pptl key milliseconds | 查看key的超时时间戳 | 用亳秒计算 |
| pexpire key | 设置键值超时的时间 | 以亳秒为单位 |
| Pexpireat key stamptimes | 设置超时时间点 | 以亳秒为单位的 uninx 时间戳 |
下面展示这些命令在 Redis 客户端的使用,如图 1 所示。
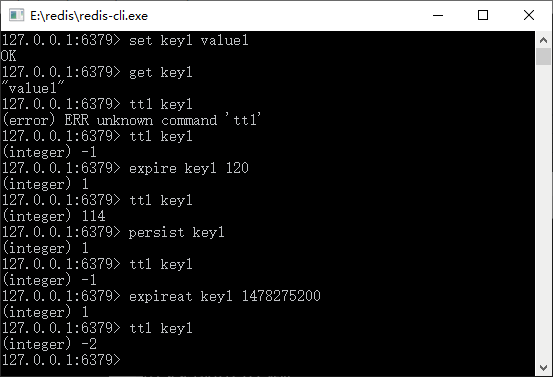
图 1 Redis超时命令
使用 Spring 也可以执行这样的一个过程,下面用 Spring 演示这个过程,代码如下所示。
public static void testExpire() {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext ("applicationContext.xml");
RedisTemplate redisTemplate = applicationContext.getBean(RedisTemplate.class);
redisTemplate.execute((RedisOperations ops) -> {
ops.boundValueOps("key1").set("value1");
String keyValue = (String)ops.boundValueOps("key1").get();
Long expSecond = ops.getExpire("key1");
System.err.println(expSecond);
boolean b = false;
b = ops.expire("key1", 120L, TimeUnit.SECONDS);
b = ops.persist("key1")
Long l = 0L;
l = ops.getExpire("key1");
Long now = System.currentTimeMillis();
Date date = new Date();
date.setTime(now + 120000);
ops.expireAt("key", date);
return null;
});
}
上面这段代码采用的就是 Spring 操作 Redis 超时命令的一个过程,感兴趣的读者可以打断点一步步验证这个过程。
这里有一个问题需要讨论:如果 key 超时了,Redis 会回收 key 的存储空间吗?这也是面试时常常被问到的一个问题。
答案是不会。
这里需要非常注意的是:Redis 的 key 超时不会被其自动回收,它只会标识哪些键值对超时了。
这样做的一个好处在于,如果一个很大的键值对超时,比如一个列表或者哈希结构,存在数以百万个元素,要对其回收需要很长的时间。如果采用超时回收,则可能产生停顿。坏处也很明显,这些超时的键值对会浪费比较多的空间。
Redis 提供两种方式回收这些超时键值对,它们是定时回收和惰性回收。
- 定时回收是指在确定的某个时间触发一段代码,回收超时的键值对。
- 惰性回收则是当一个超时的键,被再次用 get 命令访问时,将触发 Redis 将其从内存中清空。
定时回收可以完全回收那些超时的键值对,但是缺点也很明显,如果这些键值对比较多,则 Redis 需要运行较长的时间,从而导致停顿。所以系统设计者一般会选择在没有业务发生的时刻触发 Redis 的定时回收,以便清理超时的键值对。
对于惰性回收而言,它的优势是可以指定回收超时的键值对,它的缺点是要执行一个莫名其妙的 get 操作,或者在某些时候,也难以判断哪些键值对已经超时。
无论是定时回收还是惰性回收,都要依据自身的特点去定制策略,如果一个键值对,存储的是数以千万的数据,使用 expire 命令使其到达一个时间超时,然后用 get 命令访问触发其回收,显然会付出停顿代价,这是现实中需要考虑的。
Redis中使用Lua语言
在 Redis 的 2.6 以上版本中,除了可以使用命令外,还可以使用 Lua 语言操作 Redis。从前面的命令可以看出 Redis 命令的计算能力并不算很强大,而使用 Lua 语言则在很大程度上弥补了 Redis 的这个不足。
只是在 Redis 中,执行 Lua 语言是原子性的,也就说 Redis 执行 Lua 的时候是不会被中断的,具备原子性,这个特性有助于 Redis 对并发数据一致性的支持。
Redis 支持两种方法运行脚本,一种是直接输入一些 Lua 语言的程序代码;另外一种是将 Lua 语言编写成文件。
在实际应用中,一些简单的脚本可以采取第一种方式,对于有一定逻辑的一般采用第二种方式。而对于采用简单脚本的,Redis 支持缓存脚本,只是它会使用 SHA-1 算法对脚本进行签名,然后把 SHA-1 标识返回回来,只要通过这个标识运行就可以了。
执行输入 Lua 程序代码
它的命令格式为:
eval lua-script key-num [key1 key2 key3 ...] [value1 value2 value3 ...]
其中:
- eval 代表执行 Lua 语言的命令。
- Lua-script 代表 Lua 语言脚本。
- key-num 整数代表参数中有多少个 key,需要注意的是 Redis 中 key 是从 1 开始的,如果没有 key 的参数,那么写 0。
- [key1key2key3…] 是 key 作为参数传递给 Lua 语言,也可以不填它是 key 的参数,但是需要和 key-num 的个数对应起来。
- [value1 value2 value3…] 这些参数传递给 Lua 语言,它们是可填可不填的。
这里难理解的是 key-num 的意义,举例说明就能很快掌握它了,如图 1 所示。
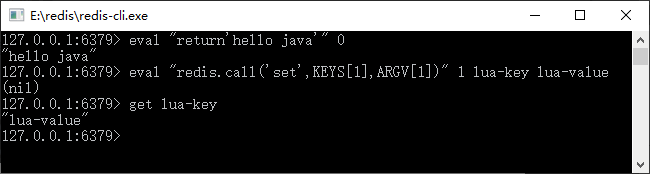
图 1 Redis 执行 Lua 语言脚本
这里可以看到执行了两个 Lua 脚本。
eval "return'hello java'" 0
这个脚本只是返回一个字符串,并不需要任何参数,所以 key-num 填写了 0,代表着没有任何 key 参数。按照脚本的结果就是返回了 hello java,所以执行后 Redis 也是这样返回的。
这个例子很简单,只是返回一个字符串。
eval "redis.call('set',KEYS[1],ARGV[1])" 1 lua-key lua-value
设置一个键值对,可以在 Lua 语言中采用 redis.call(command,key[param1,param2…]) 进行操作,其中:
- command 是命令,包括 set、get、del 等。
- Key 是被操作的键。
- param1,param2…代表给 key 的参数。
脚本中的 KEYS[1] 代表读取传递给 Lua 脚本的第一个 key 参数,而 ARGV[1] 代表第一个非 key 参数。
这里共有一个 key 参数,所以填写的 key-num 为 1,这样 Redis 就知道 key-value 是 key 参数,而 lua-value 是其他参数,它起到的是一种间隔的作用。
最后我们可以看到使用 get 命令获取数据是成功的,所以 Lua 脚本运行成功了。
有时可能需要多次执行同样一段脚本,这个时候可以使用 Redis 缓存脚本的功能,在 Redis 中脚本会通过 SHA-1 签名算法加密脚本,然后返回一个标识字符串,可以通过这个字符串执行加密后的脚本。
这样的一个好处在于,如果脚本很长,从客户端传输可能需要很长的时间,那么使用标识字符串,则只需要传递 32 位字符串即可,这样就能提高传输的效率,从而提高性能。
首先使用命令:
script load script
这个脚本的返回值是一个 SHA-1 签名过后的标识字符串,我们把它记为 shastring。通过 shastring 可以使用命令执行签名后的脚本,命令的格式是:
evalsha shastring keynum [key1 key2 key3 ...] [param1 param2 param3 ...]
下面演示这样的一个过程,如图 2 所示。

图 2 使用签名运行 Lua 脚本
对脚本签名后就可以使用 SHA-1 签名标识运行脚本了。在 Spring 中演示这样的一个过程,如果是简单存储,笔者认为原来的 API 中的 Jedis 对象就简单些,所以先获取了原来的 connection 对象,代码如下所示。
// 如果是简单的对象,使用原来的封装会简易些
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(
"applicationContext.xml");
RedisTemplate redisTemplate = applicationContext.getBean(RedisTemplate.class);
applicationContext.getBean(RedisTemplate.class);
// 如果是简单的操作,使用原来的Jedis会简易些
Jedis jedis = (Jedis) redisTemplate.getConnectionFactory().getConnection().getNativeConnection();
// 执行简单的脚本
String helloJava = (String) jedis.eval("return 'hello java'");
System.out.println(helloJava);
// 执行带参数的脚本
jedis.eval("redis.call ('set', KEYS [1],ARGV [1])", 1, "lua-key",
"lua-value");
String luaKey = (String) jedis.get("lua-key");
System.out.println(luaKey);
// 缓存脚本,返回shal签名标识
String shal = jedis.scriptLoad("redis.call('set',KEYS[1], ARGV[1])");
// 通过标识执行脚本
jedis.evalsha(shal, 1, new String[] { "sha-key", "sha-val" });
// 获取执行脚本后的数据
String shaVal = jedis.get("sha-key");
System.out.println(shaVal);
// 关闭连接
jedis.close();
上面演示的是简单字符串的存储,但现实中可能要存储对象,这个时候可以考虑使用 Spring 提供的 RedisScript 接口,它还是提供了一个实现类—— DefaultRedisScript,让我们来了解它的使用方法。
这里先来定义一个可序列化的对象 Role,因为要序列化所以需要实现 Serializable 接口,代码如下所示。
public class Role implements Serializable {
/**
* 注意,对象要可序列化,需要实现Serializable接口,往往要重写serialVersionUID
*/
private static final long serialVersionUID = 3447499459461375642L;
private long id;
private String roleName;
private String note;
// 省略setter和getter
}
这个时候,就可以通过 Spring 提供的 DefaultRedisScript 对象执行 Lua 脚本来操作对象了,代码如下所示。
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(
"applicationContext.xml");
RedisTemplate redisTemplate = applicationContext.getBean(RedisTemplate.class);
// 定义默认脚本封装类
DefaultRedisScript<Role> redisScript = new DefaultRedisScript<Role>();
// 设置脚本
redisScript.setScriptText("redis.call('set',KEYS[1], ARGV[1]) return redis.call('get', KEYS[1])");
// 定义操作的key列表
List<String> keyList = new ArrayList<String>();
keyList.add("role1");
// 需要序列化保存和读取的对象
Role role = new Role();
role.setId(1L);
role.setRoleName("role_name_1");
role.setNote("note_1");
// 获得标识字符串
String sha1 = redisScript.getSha1();
System.out.println(sha1);
// 设置返回结果类型,如果没有这句话,结果返回为空
redisScript.setResultType(Role.class);
// 定义序列化器
JdkSerializationRedisSerializer serializer = new JdkSerializationRedisSerializer();
// 执行脚本
// 第一个是RedisScript接口对象,第二个是参数序列化器
// 第三个是结果序列化器,第四个是Reids的key列表,最后是参数列表
Role obj = (Role) redisTemplate.execute(redisScript, serializer,
serializer, keyList, role);
// 打印结果
System.out.println(obj);
注意加粗的代码,两个序列化器第一个是参数序列化器,第二个是结果序列化器。这里配置的是 Spring 提供的 JdkSerializationRedisSerializer,如果在 Spring 配置文件中将 RedisTemplate 的 valueSerializer 属性设置为 JdkSerializationRedisSerializer,那么使用默认的序列化器即可。
执行 Lua 文件
我们把 Lua 变为一个字符串传递给 Redis 执行,而有些时候要直接执行 Lua 文件,尤其是当 Lua 脚本存在较多逻辑的时候,就很有必要单独编写一个独立的 Lua 文件。比如编写了一段 Lua 脚本,代码如下所示。
redis.call('set',KEYS[1],ARGV[1])
redis.call('set',KEYS[2],ARGV[2])
local n1 = tonumber(redis.call('get',KEYS[1]))
local n2 = tonumber(redis.call('get',KEYS[2]))
if n1 > n2 then
return 1
end
if n1 == n2 then
return 0
end
if n1 < n2 then
return 2
end
这是一个可以输入两个键和两个数字(记为 n1 和 n2)的脚本,其意义就是先按键保存两个数字,然后去比较这两个数字的大小。当 n1==n2 时,就返回 0;当 n1>n2 时,就返回 1;当 n1 redis-cli --eval test.lua key1 key2 , 2 4 注意,redis-cli 的命令需要注册环境,或者把文件放置在正确的目录下才能正确执行,这样就能看到效果,如图 3 所示。 图 3 redis-cli的命令执行 看到结果就知道已经运行成功了。只是这里需要非常注意命令,执行的命令键和参数是使用逗号分隔的,而键之间用空格分开。在本例中 key2 和参数之间是用逗号分隔的,而这个逗号前后的空格是不能省略的,这是要非常注意的地方,一旦左边的空格被省略了,那么 Redis 就会认为“key2,”是一个键,一旦右边的空格被省略了,Redis 就会认为“,2”是一个键。 在 Java 中没有办法执行这样的文件脚本,可以考虑使用 evalsha 命令,这里更多的时候我们会考虑 evalsha 而不是 eval,因为 evalsha 可以缓存脚本,并返回 32 位 sha1 标识,我们只需要传递这个标识和参数给 Redis 就可以了,使得通过网络传递给 Redis 的信息较少,从而提高了性能。 如果使用 eval 命令去执行文件里的字符串,一旦文件很大,那么就需要通过网络反复传递文件,问题往往就出现在网络上,而不是 Redis 的执行效率上了。参考上面的例子去执行,下面我们模拟这样的一个过程,使用 Java 执行 Redis 脚本代码如下所示。 如果我们将 sha1 这个二进制标识保存下来,那么可以通过这个标识反复执行脚本,只需要传递 32 位标识和参数即可,无需多次传递脚本。 从对 Redis 的流水线的分析可知,系统性能不佳的问题往往并非是 Redis 服务器的处理能力,更多的是网络传递,因此传递更少的内容,有利于系统性能的提高。 这里采用比较原始的 Java Redis 连接操作 Redis,还可以采用 Spring 提供的 RedisScript 操作文件,这样就可以通过序列化器直接操作对象了。 在 Redis 中存在两种方式的备份: 对于快照备份(RDB)而言,如果当前 Redis 的数据量大,备份可能造成 Redis 卡顿,但是恢复重启是比较快速的; 对于 AOF 备份,它只是追加写入命令,所以备份一般不会造成 Redis 卡顿,但是恢复重启要执行更多的命令,备份文件可能也很大,使用者使用的时候要注意。 在 Redis 中允许使用其中的一种、同时使用两种,或者两种都不用,所以具体使用何种方式进行备份和持久化是用户可以通过配置决定的。 对于Redis而言,它的默认配置为: 对于快照模式的备份而言,它的配置项如下: 这 3 个配置项的含义分别为: Redis 执行 save 命令的时候,将禁止写入命令。 这里先谈谈 bgsave 命令,它是一个异步保存命令,也就是系统将启动另外一条进程,把 Redis 的数据保存到对应的数据文件中。它和 save 命令最大的不同是它不会阻塞客户端的写入,也就是在执行 bgsave 的时候,允许客户端继续读/写 Redis。 在默认情况下,如果 Redis 执行 bgsave 失败后,Redis 将停止接受写操作,这样以一种强硬的方式让用户知道数据不能正确的持久化到磁盘,否则就会没人注意到灾难的发生,如果后台保存进程重新启动工作了,Redis 也将自动允许写操作。然而如果安装了靠谱的监控,可能不希望 Redis 这样做,那么你可以将其修改为 no。 这个命令意思是是否对 rbd 文件进行检验,如果是将对 rdb 文件检验。从 dbfilename 的配置可以知道,rdb 文件实际是 Redis 持久化的数据文件。 它是数据文件。当采用快照模式备份(持久化)时,Redis 将使用它保存数据,将来可以使用它恢复数据。 如果 appendonly 配置为 no,则不启用 AOF 方式进行备份。如果 appendonly 配置为 yes,则以 AOF 方式备份 Redis 数据,那么此时 Redis 会按照配置,在特定的时候执行追加命令,用以备份数据。 这里定义追加的写入文件为 appendonly.aof,采用 AOF 追加文件备份的时候命令都会写到这里。 AOF 文件和 Redis 命令是同步频率的,假设配置为 always,其含义为当 Redis 执行命令的时候,则同时同步到 AOF 文件,这样会使得 Redis 同步刷新 AOF 文件,造成缓慢。而采用 evarysec 则代表每秒同步一次命令到 AOF 文件。 采用 no 的时候,则由客户端调用命令执行备份,Redis 本身不备份文件。对于采用 always 配置的时候,每次命令都会持久化,它的好处在于安全,坏处在于每次都持久化性能较差。 采用 evarysec 则每秒同步,安全性不如 always,备份可能会丢失 1 秒以内的命令,但是隐患也不大,安全度尚可,性能可以得到保障。采用 no,则性能有所保障,但是由于失去备份,所以安全性比较差。笔者建议采用默认配置 everysec,这样在保证性能的同时,也在一定程度上保证了安全性。 它指定是否在后台 AOF 文件 rewrite(重写)期间调用 fsync,默认为 no,表示要调用 fsync(无论后台是否有子进程在刷盘)。Redis 在后台写 RDB 文件或重写 AOF 文件期间会存在大量磁盘 I/O,此时,在某些 Linux 系统中,调用 fsync 可能会阻塞。 它指定 Redis 重写 AOF 文件的条件,默认为 100,表示与上次 rewrite 的 AOF 文件大小相比,当前 AOF 文件增长量超过上次 AOF 文件大小的 100% 时,就会触发 background rewrite。若配置为 0,则会禁用自动 rewrite。 它指定触发 rewrite 的AOF文件大小。若AOF文件小于该值,即使当前文件的增量比例达到 auto-aof-rewrite-percentage 的配置值,也不会触发自动 rewrite。即这两个配置项同时满足时,才会触发rewrite。 Redis 在恢复时会忽略最后一条可能存在问题的指令,默认为 yes。即在 AOF 写入时,可能存在指令写错的问题(突然断电、写了一半),这种情况下 yes 会 log 并继续,而 no 会直接恢复失败。 Redis 也会因为内存不足而产生错误,也可能因为回收过久而导致系统长期的停顿,因此掌握执行回收策略十分有必要。在 Redis 的配置文件中,当 Redis 的内存达到规定的最大值时,允许配置 6 种策略中的一种进行淘汰键值,并且将一些键值对进行回收,让我们来看看它们的特点。 首先,Redis 的配置文件放在 Redis 的安装目录下, Redis 对其中的一个配置项——maxmemory-policy,提供了这样的一段描述: Redis 在默认情况下会采用 noeviction 策略。换句话说,如果内存已满,则不再提供写入操作,而只提供读取操作。显然这往往并不能满足我们的要求,因为对于互联网系统而言,常常会涉及数以百万甚至更多的用户,所以往往需要设置回收策略。 这里需要指出的是:LRU 算法或者 TTL 算法都是不是很精确算法,而是一个近似的算法。Redis 不会通过对全部的键值对进行比较来确定最精确的时间值,从而确定删除哪个键值对,因为这将消耗太多的时间,导致回收垃圾执行的时间太长,造成服务停顿。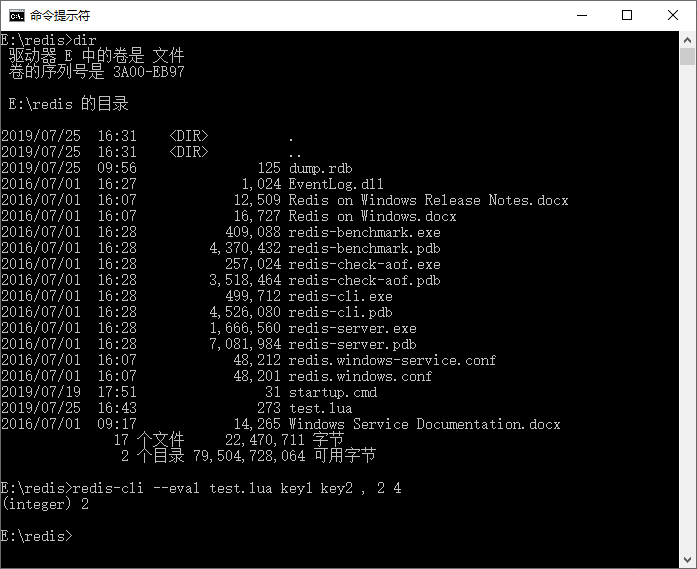
public static void testLuaFile() {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
RedisTemplate redisTemplate = applicationContext.getBean(RedisTemplate.class);
//读入文件流
File file = new File("G:\\dev\\redis\\test.lua");
byte[] bytes = getFileToByte(file);
Jedis jedis = (Jedis)redisTemplate.getConnectionFactory().getConnection().getNativeConnection();
//发送文件二进制给Redis,这样REdis就会返回shal标识
byte[] shal = jedis.scriptLoad(bytes);
//使用返回的标识执行,其中第二个参数2,表示使用2个键
//而后面的字符串都转化为了二进制字节进行传输
Object obj = jedis.evalsha(shal,2, "key1".getBytes(),"key2".getBytes(),"2".getBytes(), "4".getBytes());
System.out.println(obj);
}
/**
* 把文件转化为二进制数组
* @param file 文件
* return二进制数组
*/
public static byte[] getFileToByte(File file) {
byte[] by = new byte[(int) file.length()];
try {
InputStream is = new FileinputStream(file);
ByteArrayOutputStream bytestream = new ByteArrayOutputStream(); byte[] bb = new byte[2048];
int ch;
ch = is.read(bb);
while (ch != -1) {
bytestream.write(bb, 0, ch);
ch = is.read(bb);
}
by = bytestream.toByteArray();
} catch (Exception ex) {
ex.printStackTrace();
}
return by;
}
Redis的备份(持久化)方式
RDB备份
\################################## SNAPSHOTTING###################################
......
save 900 1
save 300 10
save 60 10000
......
stop-writes-on-bgsave-error yes
......
rdbcompression yes
......
dbfilename dump.rdb
\############################## APPEND ONLY MODE###############################
......
appendonly no
......
appendfilename "appendonly.aof"
......
\#appendfsync always
appendfsync everysec
\# appendfsync no......
......
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
......
aof-load-truncated yes
......
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
dbfilename dump.rdb
appendonly no
AOF备份
appendfilename "appendonly.aof"
\#appendfsync always
appendfsync everysec
\# appendfsync no......
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
Redis内存回收策略