基于人气与协同过滤的图书推荐系统研究与实践

♂️ 个人主页:@艾派森的个人主页
✍作者简介:Python学习者
希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 点赞 收藏 加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据探索
4.3数据预处理
4.4基于人气的推荐系统
4.5基于协同过滤的推荐系统
5.总结
文末推荐与福利
1.项目背景
随着信息技术的不断发展,人们获取图书信息的方式发生了巨大变化。传统的图书推荐方式主要依赖于专业书评和图书馆员的推荐,但这种方式面临着信息获取成本高、推荐精准度低等问题。而随着互联网的普及,大量用户生成的数据成为了个性化推荐系统的宝贵资源。
在这一背景下,图书推荐系统应运而生,成为了图书行业提高用户体验、促进销售的有效工具。传统的图书推荐系统主要基于图书的内容属性进行推荐,然而,用户的个性化需求和兴趣爱好千差万别,因此单一的内容属性往往无法满足用户的需求。
为了提高图书推荐的精准度,研究者们开始关注协同过滤算法,并结合用户的行为数据,实现个性化的图书推荐。协同过滤算法通过分析用户行为数据,发现用户之间的相似性,从而向用户推荐他们可能感兴趣的图书。与此同时,考虑到图书的热门程度也是影响用户选择的一个重要因素,人气推荐成为了图书推荐系统中不可忽视的一部分。
因此,基于人气与协同过滤的图书推荐系统成为了当前研究的热点之一。通过深入研究用户行为数据和图书的人气信息,结合协同过滤算法,可以更好地满足用户的个性化需求,提高推荐系统的精准度和用户满意度。这也是本研究的动机所在,旨在探讨如何有效地整合人气信息和协同过滤算法,构建一种更为强大和智能的图书推荐系统。
2.数据集介绍
本数据集来源于Kaggle,原始数据集中有3个文件,这些文件是从一些图书销售网站中提取的。
Books——首先是关于书籍的,它包含了所有与书籍相关的信息,比如作者、书名、出版年份等。
Users——第二个文件包含注册用户的信息,如用户id、位置。
ratings——评级包含诸如哪个用户对哪本书给出了多少评级之类的信息。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings as w
w.filterwarnings('ignore')
from sklearn.metrics.pairwise import cosine_similarity
books = pd.read_csv('Books.csv')
users = pd.read_csv('Users.csv')
ratings = pd.read_csv('Ratings.csv')4.2数据探索
书籍数据集
# books
print('shape of books ',books.shape)
print()
books.info()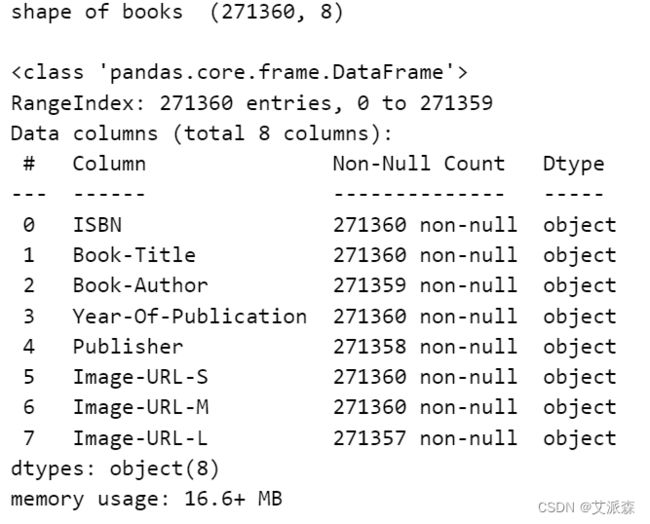
用户数据集
# user
print('shape of users',users.shape)
print()
users.info()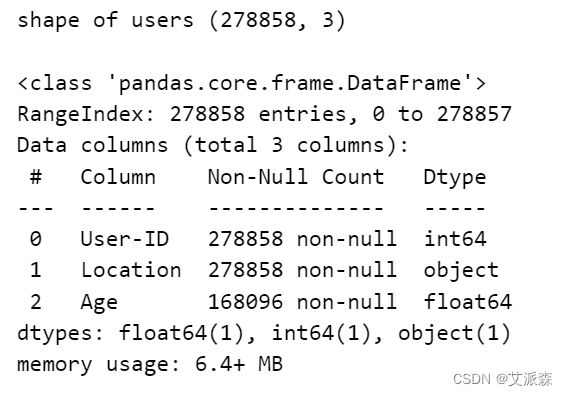
评分数据集
# ratings
print('shape of rating',ratings.shape)
print()
ratings.info()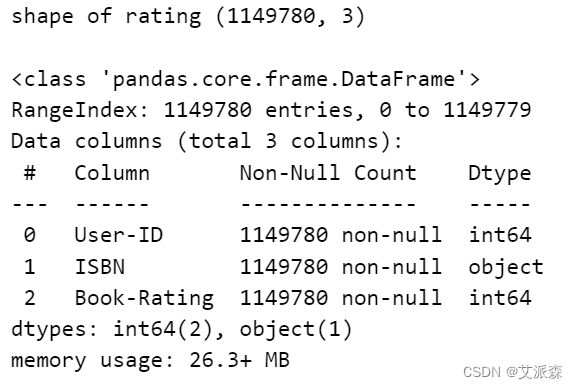
该数据集是可靠的,可以考虑作为一个大数据集。我们有271360本书的数据,网站上的注册用户总数约为27.8万,他们给出了近110万次评级。因此,我们可以说我们拥有的数据集是好的和可靠的。
4.3数据预处理
ratings['Book-Rating'].value_counts().plot(kind='bar')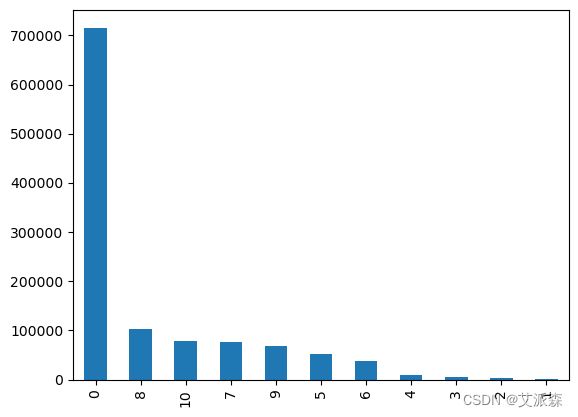
在推荐系统中,通常会有隐式反馈数据,用户不会明确地提供评级,但他们的行为可以作为偏好的指示。在这种情况下,0的评级可能表示缺失或未知的评级,这通常被视为“隐含的负面反馈”。这意味着没有给一本书打分的用户并不一定表示他们不喜欢这本书;他们可能只是没有对此表达任何意见。
# 查找图书数据集中的空值
books.isnull().sum()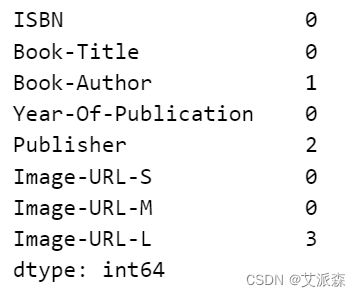
books['Year-Of-Publication'].value_counts().index.values
存在无效值或非年份值,如'0'和'1376'。
# Step 1: 过滤掉无效或非年份值
valid_years = books['Year-Of-Publication'].astype(str).str.isnumeric()
books = books[valid_years]
# Step 2: 将列数据转换为整数
books['Year-Of-Publication'] = books['Year-Of-Publication'].astype(int)
# Step 3: 从表示年份的整数中创建新的datetime列
books['Publication_Date'] = pd.to_datetime(books['Year-Of-Publication'], format='%Y', errors='coerce')
# 如果你不再需要旧的“出版年份”栏,请删除它
books.drop(columns=['Year-Of-Publication'], inplace=True)
# 显示DataFrame以检查新的日期时间列
books = pd.DataFrame(books)
# Step 4: 创建一个只有年份部分为整数的新列
books['Year-Of-Publication'] = books['Publication_Date'].dt.yearbooks['Year-Of-Publication'].value_counts().index.values
# 这是目前所有无效的数据
books = books[~(books['Year-Of-Publication'] == 2037)]
books = books[~(books['Year-Of-Publication'] == 2026)]
books = books[~(books['Year-Of-Publication'] == 2030)]
books = books[~(books['Year-Of-Publication'] == 2050)]
books = books[~(books['Year-Of-Publication'] == 2038)]plt.figure(figsize=(20,10))
sns.countplot(x=books['Year-Of-Publication']);
plt.xticks(rotation=90)
plt.show()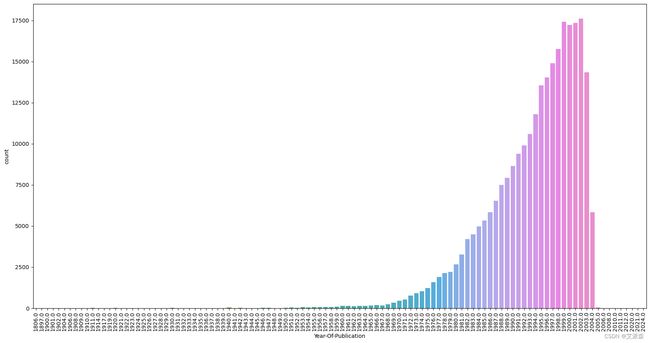
注:最多的书出版年份是1980-2004年
# 十大出版商
books['Publisher'].value_counts().head(10).plot(kind='bar')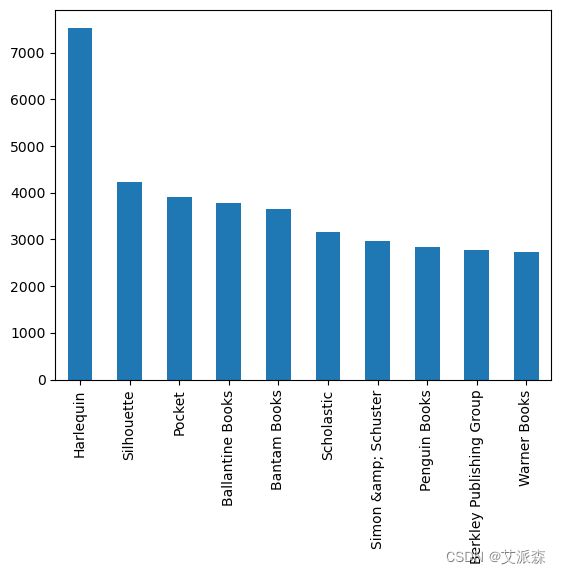
# 查找空值
round(100*(users.isnull().sum()/len(users.index)),2)
# 删除age列
users.drop('Age',axis=1,inplace=True)
users['Location'] = users['Location'].apply(lambda x:x.split(',')[-1])# 十大用户位置
users['Location'].value_counts().head(10).plot(kind='bar')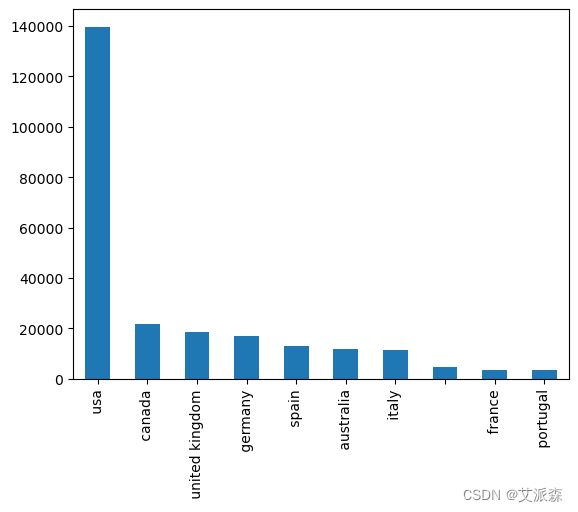
4.4基于人气的推荐系统
我们将显示平均评分最高的前50本书,但我们只考虑那些获得至少250票的书。
#合并数据评级和图书基于“ISBN”列
rating_books_name = ratings.merge(books,on='ISBN')
rating_books_name.head()
# 首先按“Book-Title”分组,找出投票总数(计数)
numer_rating = rating_books_name.groupby('Book-Title').count()['Book-Rating'].reset_index()
numer_rating.rename(columns={'Book-Rating':'Totle_number_rating'},inplace=True)
numer_rating.head()
# 总的平均评级
avg_rating = rating_books_name.groupby('Book-Title')['Book-Rating'].mean().reset_index()
avg_rating.rename(columns={'Book-Rating':'Totle_avg_rating'},inplace=True)
avg_rating.head()
# 合并'avg_rating'和'number_rating'基于'Book-Title'
popular_df = numer_rating.merge(avg_rating,on='Book-Title')
popular_df.head()
最高的平均评分,但我们只考虑那些获得至少250票的书
popular_df = popular_df[popular_df['Totle_number_rating'] >= 250].sort_values('Totle_avg_rating',ascending=False).head(50)
popular_df.head()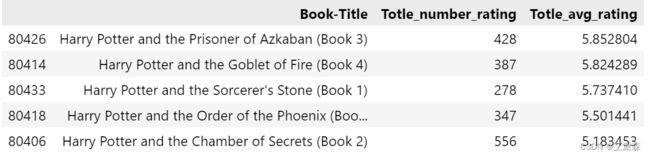
# 合并' popul_df '和'books'数据集
popular_df = popular_df.merge(books,on='Book-Title').drop_duplicates('Book-Title')[['Book-Title','Book-Author', 'Image-URL-M', 'Totle_number_rating','Totle_avg_rating']]
popular_df.head()
# 这都是前50本书
popular_df.head()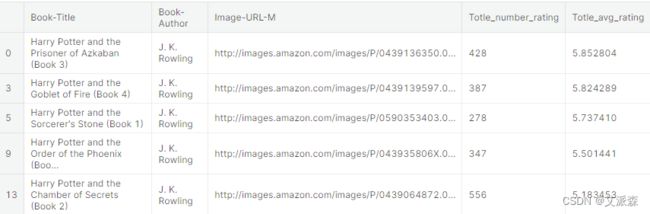
4.5基于协同过滤的推荐系统
我们不想在用户或书籍之间找到相似之处。我们想这样做,如果用户A读过并点赞x和y本书,用户B也点赞这两本书,现在用户A读过并点赞了B没有读过的z本书,所以我们必须向用户B推荐z本书,这就是协同过滤。
因此,这是使用矩阵分解实现的,我们将创建一个矩阵,其中列是用户,索引是图书,值是评级。比如我们需要创建一个数据透视表。
如果我们把所有的书和用户都拿来建模,你不觉得会产生问题吗?所以我们要做的就是减少用户和图书的数量,因为我们不能考虑只在网站上注册过或只读过一两本书的用户。对于这样的用户,我们不能依赖于向其他人推荐书籍,因为我们必须从数据中提取知识。所以我们会限制这个数字,我们会选择一个至少评价了200本书的用户,我们也会限制书籍,我们只会选择那些从用户那里得到至少50个评价的书。
因此,让我们开始分析并准备数据集,正如我们讨论的建模。让我们看看有多少用户给出了评分,并提取那些评分超过200的用户。
步骤1)提取超过200个的用户和评分
现在我们将提取给出超过200个评分的用户id,当我们有用户id时,我们将从评分数据框中提取仅该用户id的评分。
x = ratings['User-ID'].value_counts() > 200
y = x[x].index
print(y.shape)
只有899个用户的评分超过200
ratings = ratings[ratings['User-ID'].isin(y)]步骤2)将评级与书籍合并
900名用户给出了52万的评分,这是我们想要的。现在,我们将根据ISBN合并评分与图书,这样我们将得到每个用户对每个图书id的评分,而没有对该图书id评分的用户的值将为零。
rating_with_books = ratings.merge(books, on='ISBN')
rating_with_books.head(2)
步骤3)提取评分超过50的书籍
现在数据帧的大小减小了,我们有48万,因为当我们合并数据帧时,我们没有所有的book id-data。现在我们将计算每本书的评级,因此我们将根据标题对数据进行分组,并根据评级进行汇总。
number_rating = rating_with_books.groupby('Book-Title')['Book-Rating'].count().reset_index()
number_rating.rename(columns= {'Book-Rating':'number_of_ratings'}, inplace=True)
number_rating.head()
final_rating = rating_with_books.merge(number_rating, on='Book-Title')
final_rating = final_rating[final_rating['number_of_ratings'] >= 50]
final_rating.drop_duplicates(['User-ID','Book-Title'], inplace=True)我们必须删除重复的值,因为如果同一用户多次评价同一本书,这将产生一个问题。最后,我们有一个用户的数据集,该用户对200多本图书进行了评分,并对50多本图书进行了评分。最终数据框的形状是59850行和8列。
步骤4)创建数据透视表
我们将创建一个数据透视表,其中列是用户id,索引是书名,值是评级。没有给任何一本书打分的用户id的value为NAN,因此将其归为0。
book_pivot = final_rating.pivot_table(columns='User-ID', index='Book-Title', values="Book-Rating")
book_pivot.fillna(0, inplace=True)
book_pivot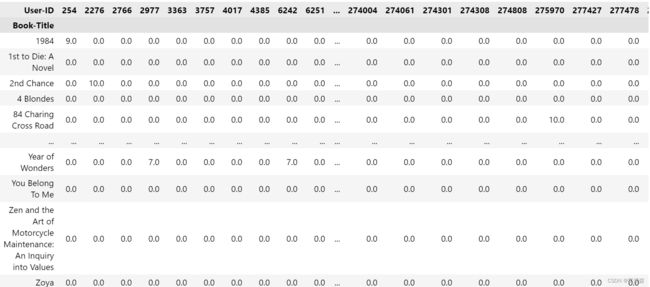
总计42本图书和888名用户
我们可以看到超过11个用户被移出,因为他们的评分是在那些评分不超过50的书上,所以他们被移出了。
建模
现在每本书都变成了888维空间中的向量,我们必须找到类似的向量。现在我们要计算每个向量和其他向量之间的欧氏距离根据这个距离我们就能知道哪本书是相似的。
使用余弦相似距离查找所有推荐的书籍
from sklearn.metrics.pairwise import cosine_similarity
similarity_scores = cosine_similarity(book_pivot)
similarity_scores
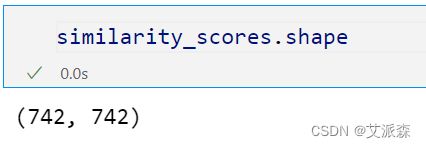
(742,742)意味着每本书距离电影都很远
# 这是第一本书的距离,每本书的相似性
similarity_scores[0]
# 定义一个根据书名进行推荐的函数
def recommend(book_name):
index = np.where(book_pivot.index==book_name)[0][0]
similar_items = sorted(list(enumerate(similarity_scores[index])),key=lambda x:x[1],reverse=True)[1:5]
data = []
for i in similar_items:
item = []
temp_df = books[books['Book-Title'] == book_pivot.index[i[0]]]
item.extend(list(temp_df.drop_duplicates('Book-Title')['Book-Title'].values))
item.extend(list(temp_df.drop_duplicates('Book-Title')['Book-Author'].values))
item.extend(list(temp_df.drop_duplicates('Book-Title')['Image-URL-M'].values))
data.append(item)
return data# 调用推荐函数,以“Harry Potter and the Chamber of Secrets (Book 2)”进行推荐
recommend('Harry Potter and the Chamber of Secrets (Book 2)')
5.总结
本实验基于人气与协同过滤的图书推荐系统,旨在提高图书推荐的精准度和用户满意度。通过对用户行为数据和图书人气信息的深入研究,以及协同过滤算法的应用,我们得出了以下几点总结:
-
个性化推荐的重要性: 传统的图书推荐系统主要依赖于内容属性,但个性化推荐系统的兴起使得系统能够更好地理解用户的兴趣和需求。结合协同过滤算法,系统能够根据用户的历史行为数据,为每个用户提供更为个性化的图书推荐,从而提高推荐的精准度。
-
人气信息的价值: 图书的人气信息是用户选择图书的重要参考因素之一。在推荐系统中,将人气信息纳入考虑范围,可以使系统更好地把握热门图书,为用户提供具有广泛吸引力的推荐。这对于提高用户体验、吸引更多读者具有积极作用。
-
协同过滤的优越性: 协同过滤算法通过挖掘用户行为数据中的相似性,为用户提供与其兴趣相近的图书推荐。实验结果表明,协同过滤算法在提高推荐系统准确性方面具有显著优势。通过引入该算法,系统能够更好地适应用户的个性化需求,增强了推荐系统的智能化水平。
-
综合优化: 在实验中,我们探索了如何综合利用人气信息和协同过滤算法,以进一步提高推荐系统的性能。通过精细调节算法参数和权重,我们成功实现了在保持系统简单性的同时提高了推荐的准确性。这为未来推荐系统的研究和应用提供了有益的经验。
综合而言,基于人气与协同过滤的图书推荐系统在本实验中取得了良好的效果,为提高图书推荐系统的智能化水平和用户体验提供了有益的参考。未来的研究方向可以在更多算法创新和用户反馈挖掘的基础上进一步完善推荐系统,以满足不断变化的用户需求。
文末推荐与福利
《从概念到现实:ChatGPT和Midjourney的设计之旅》免费包邮送出3本!

内容简介:
《从概念到现实:ChatGPT和Midjourney的设计之旅》详细介绍了ChatGPT与Midjourney的使用方法和应用场景,并结合设计案例讲解了如何利用AIGC辅助不同行业的设计师提升工作效率和创造力,共涉及8个应用领域,近60个案例演示,生动展示了各行各业中融入AIGC技术的设计成果,为设计师提供了更开阔的设计思路。同时,书中还有很多实用的技巧和建议,可以帮助设计师更快地掌握相关技术。对于不熟悉AI技术的设计师来说,这将是一本很有价值的指南书。通过阅读《从概念到现实:ChatGPT和Midjourney的设计之旅》,插画设计师、UI和UX设计师、游戏设计师、电商设计师、文创设计师、服装设计师、家居建筑设计师、工业设计师及相关设计人员可以更好地理解AI工具的工作原理,并更加灵活地加以运用。
《从概念到现实:ChatGPT和Midjourney的设计之旅》不仅适合对设计充满热情的专业人士,还适合广大热爱设计艺术的读者。愿我们共同开启这段关于AI与设计的奇妙旅程,探索无限的创作空间!编辑推荐:
君子生非异也,善假于物也。让AI成为设计师的亲密助手,激发设计师的创造力!减少简单工作,提升设计效率!8个应用领域,插画设计 UI和UX设计 游戏设计 平面和电商设计 文创设计 服装设计 家居建筑设计 工业设计,近60个案例讲解。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-12-18 20:00:00
当当链接:http://product.dangdang.com/29628718.html
京东链接:https://item.jd.com/13864763.html
名单公布时间:2023-12-18 21:00:00

资料获取,更多粉丝福利,关注下方公众号获取
