Linux系统下CPU性能问题分析案例
(上)
本文涉及案例来自于学习极客时间专栏《Linux性能优化实战》精心整理而来,案例总结不到位的请各位多多指正。
某个应用的CPU使用率居然达到100%,我该怎么办?
分析过程
- 使用观察系统CPU使用情况(并按下数字 1 ,切换到每个 CPU 的使用率)
$ top
...
%Cpu0 : 98.7 us, 1.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 99.3 us, 0.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21514 daemon 20 0 336696 16384 8712 R 41.9 0.2 0:06.00 php-fpm
21513 daemon 20 0 336696 13244 5572 R 40.2 0.2 0:06.08 php-fpm
21515 daemon 20 0 336696 16384 8712 R 40.2 0.2 0:05.67 php-fpm
21512 daemon 20 0 336696 13244 5572 R 39.9 0.2 0:05.87 php-fpm
21516 daemon 20 0 336696 16384 8712 R 35.9 0.2 0:05.61 php-fpm这里可以看到,系统中有几个 php-fpm 进程的 CPU 使用率加起来接近 200%;而每个 CPU 的用户使用率(us)也已经超过了 98%,接近饱和。这样,我们就可以确认,正是用户空间的 php-fpm 进程,导致 CPU 使用率骤升
- 使用perf在进一步定位程序的函数调用开销
# -g开启调用关系分析,-p指定php-fpm的进程号21515
$ perf top -g -p 21515按方向键切换到 php-fpm,再按下回车键展开 php-fpm 的调用关系,你会发现,调用关系最终到了 sqrt 和 add_function
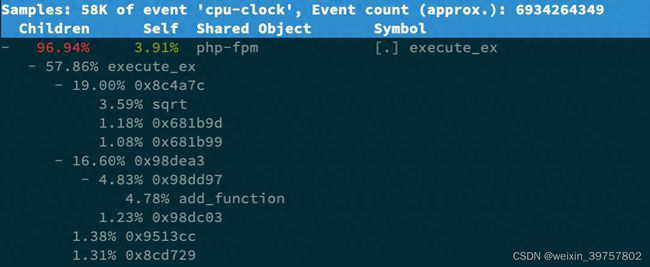
总结
CPU 使用率是最直观和最常用的系统性能指标,更是我们在排查性能问题时,更要熟悉它每个指标的的含义,尤其要弄清楚用户(%user)、Nice(%nice)、系统(%system) 、等待 I/O(%iowait) 、中断(%irq)以及软中断(%softirq)这几种不同 CPU 的使用率。比如说:
- 用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
- 系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
- I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
- 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
系统的 CPU 使用率很高,但为啥却找不到高 CPU 的应用?
分析过程
- 依然是使用top,观察系统CPU使用情况
$ top
...
%Cpu(s): 80.8 us, 15.1 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6882 root 20 0 8456 5052 3884 S 2.7 0.1 0:04.78 docker-containe
6947 systemd+ 20 0 33104 3716 2340 S 2.7 0.0 0:04.92 nginx
7494 daemon 20 0 336696 15012 7332 S 2.0 0.2 0:03.55 php-fpm
7495 daemon 20 0 336696 15160 7480 S 2.0 0.2 0:03.55 php-fpm
10547 daemon 20 0 336696 16200 8520 S 2.0 0.2 0:03.13 php-fpm
10155 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php-fpm
10552 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php-fpm
15006 root 20 0 1168608 66264 37536 S 1.0 0.8 9:39.51 dockerd
4323 root 20 0 0 0 0 I 0.3 0.0 0:00.87 kworker/u4:1通过以上输出分析
- 系统的整体 CPU 使用率是比较高的: 用户CPU到了80%,系统CPU为15.1%,空闲CPU只有2.8%。(用户CPU使用率高,肯定是有用户进程占用CPU导致)
- CPU 使用率最高的进程也只不过才 2.7%,并不高
- 观察进程状态发现:Nginx 和所有的 php-fpm 都处于 Sleep(S)状态,而真正处于 Running(R)状态的,却是几个 stress 进程
- 使用pidstat命令分析stress进程
# 使用 -p 选项指定stress进程的 PID
$ pidstat -p 24344
16:14:55 UID PID %usr %system %guest %wait %CPU CPU Command没有任何输出。现在终于发现问题,原来这个进程已经不存在了,所以 pidstat 就没有任何输出,而且从top的输出我们看到stress的PID一直在变化,出现这种情况的无非就两个原因:
- 第一个原因,进程在不停地崩溃重启,比如因为段错误、配置错误等等,这时,进程在退出后可能又被监控系统自动重启了。
- 第二个原因,这些进程都是短时进程,也就是在其他应用内部通过 exec 调用的外面命令。这些命令一般都只运行很短的时间就会结束,你很难用 top 这种间隔时间比较长的工具发现(上面的案例,我们碰巧发现了)。
- 使用pstree查询下stress进程的父进程
$ pstree | grep stress
|-docker-containe-+-php-fpm-+-php-fpm---sh---stress
| |-3*[php-fpm---sh---stress---stress]从这里可以看到,stress 是被 php-fpm 调用的子进程,并且进程数量不止一个(这里是 3 个),接下来就是去看php-fpm的内部代码逻辑了,不在展开
- 使用perf继续分析下stress的cpu占用函数
# 记录性能事件,等待大约15秒后按 Ctrl+C 退出
$ perf record -g
# 查看报告
$ perf report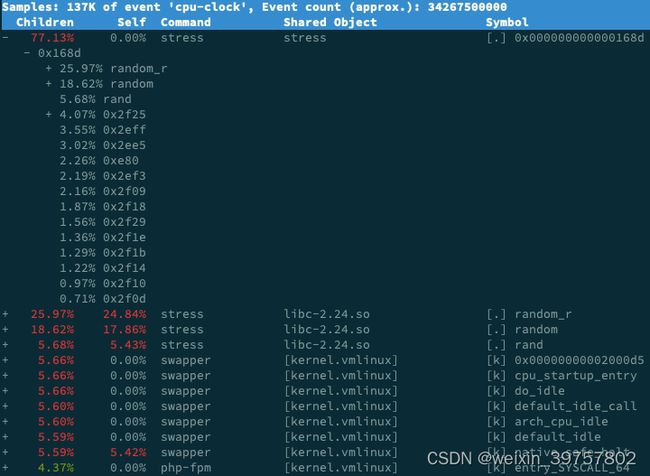
perf输出分析:
- stress 占了所有 CPU 时钟事件的 77%,而 stress 调用调用栈中比例最高的,是随机数生成函数 random(),看来它的确就是 CPU 使用率升高的元凶了。
总结
碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有可能是短时应用导致的问题,比如有可能是下面这两种情况。
- 第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现。
- 第二,应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU。
对于短时进程,我们可以通过pstree命令找到它们的父进程,再从父进程所在的应用入手,排查问题的根源
(中)
在前一篇文章 Linux系统下CPU性能问题分析案例(上)中我们看到的系统CPU使用率高的表现都是用户态(us)下使用率过高场景的排查过程,关于CPU使用率相关重要指标,我们经常在使用top、dstat、vmstat等工具看到,这里解读一下:
- user(通常缩写为us),代表用户态CPU时间
- nice(通常缩写为ni),代表低优先级用户态CPU时间,nice可取值范围是-20到19,数值越大,优先级反而越低,默认值是0
- system(通常缩写为sys),代表内核态CPU时间
- idle(通常缩写为id),代表空闲时间。注意,它不包括等待I/O的时间(iowait)
- iowait(通常缩写为wa),代表等待 I/O的CPU时间
- irq(通常缩写为hi),代表处理硬中断的CPU时间
- softirq(通常缩写为si),代表处理软中断的CPU时间
- steal(通常缩写为st),代表当系统运行在虚拟机中的时候,虚拟机占用的CPU时间
- guest(通常缩写为guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的CPU时间
- guest_nice(通常缩写为gnice),代表以低优先级运行虚拟机的时间
CPU的iowait突然升高,我该怎么处理?
分析过程
从上面的介绍可以看出,iowait升高,第一反应会想到查看系统的 I/O情况,I/O又分为磁盘I/O和网络I/O,这里先分析磁盘I/O
1.运行 dstat 命令,观察 CPU 和 I/O 的使用情况

- 结果分析
- 在iowait升高(wai)时,磁盘的读请求(read)都很高,最高时1271M
- 充分说明iowait的升高是磁盘I/O导致的,确切的说,是大量读磁盘导致的
2.通过pidstat查询进程的I/O情况
# -d:统计进程的磁盘使用情况 1: 采集周期1s 10: 采集10次
pidstat -d 1 10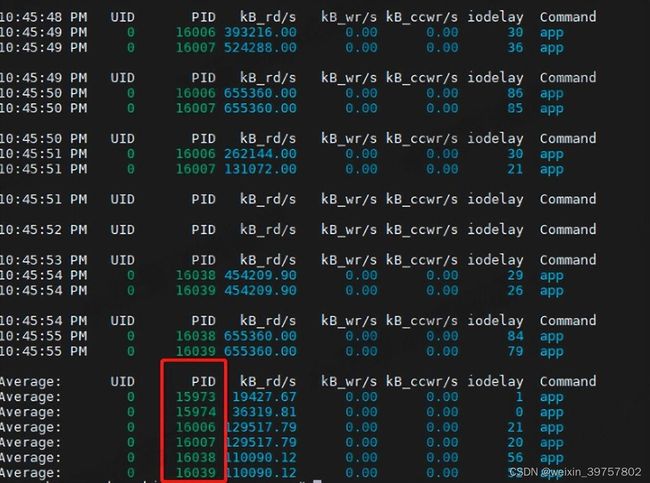
- 结果分析
- 大量读磁盘的进程名称是app,而且app进程的pid在不停变化(短时进程?)
3.使用ps命令查看下app进程
![]()
- 结果分析
- 进程的状态是Z+,命令行参数
,进程变成僵尸进程了 - 僵尸进程的产生和处理方法,这里暂不展开,有想了解的可以评论留言或者自行学习
- app的是谁创建的,是下一步分析的重点
4.查询app进程的父进程
![]()
- 结果分析
- pid为51780的父进程id是51688,进程名称也是app
5.使用perf命令采集性能事件分析app函数调用
# 录制全局性能事件,如果只想录制某个进程的,可以使用-p指定
# perf record -ag -p {pid} -- sleep 10 #采集指定pid所有cpu的性能事件,周期是10s
perf record -g
# 分析报告
perf report 
- 分析结果
- app进程正在对磁盘进行直接读,也就是绕过了系统缓存,每个读请求都会从磁盘直接读
思路总结
- 使用dstat命令查看系统I/O情况(dstat可以同时观察cpu和磁盘的情况)
- 使用pidstat命令可以定位到进程维度的磁盘读写情况,找出可疑进程
- 使用ps、top等命令可以观测到进程的状态(D、R、S、Z、T等)
- 使用pstree命令我们找出了app进程的父进程(子进程的pid一直在变)
- 使用perf命令就可以对进程的函数调用关系分析了
- 没啥需要使用的啦。哈哈,点赞+收藏
知识补充
- 进程状态
- R 是Running或Runnable 的缩写,表示进程在CPU的就绪队列中,正在运行或者正在等待运行
- D 是Disk Sleep的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断。
- Z 是Zombie的缩写,进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID 等)
- S 是Interruptible Sleep的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入R状态
- I 是Idle的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上
- T 或者 t,也就是Stopped或Traced的缩写,表示进程处于暂停或者跟踪状态
- 僵尸进程
- 一旦父进程没有处理子进程的终止,还一直保持运行状态,那么子进程就会一直处于僵尸状态
- 大量的僵尸进程会用尽PID进程号,导致新进程不能创建
- 僵尸进程在父进程回收它的资源后就会消亡,或者在父进程退出后,由init进程回收后也会消亡
你在日常工作中是如何分析CPU的iowait升高的过程的?欢迎一起交流、一起讨论。无论是编码的乐趣还是系统的构建,让我们共同在这个科技的大舞台上创造奇迹。
(下)
在我的前一篇文章 Linux系统下CPU性能问题分析案例(中)中介绍了CPU使用率的重要指标,包括User、System、Idle、IOwait、Irq、Softirq、Steal、Guest等CPU时间的说明,通过具体案例分析了User、Iowait等CPU使用率过高的排查思路,感兴趣的可以回去翻看,今天我们来对看下中断对CPU影响的案例和分析过程。
基本概念
- 我们常说的中断是什么?
- 硬中断:
- 概念: 硬中断是由硬件设备发送给CPU的一种中断信号。这可以是来自外部设备(如磁盘、网络接口卡、键盘)的信号,需要CPU的处理。
- 工作原理: 当硬件设备需要CPU的处理时,它会发送一个硬中断信号,中断控制器接收到信号后将其传递给CPU。CPU会立即中断当前执行的任务,保存当前状态,然后执行与中断相关的中断处理程序。(硬件触发,快速执行)
- 软中断:
- 概念: 软中断是由软件生成的中断信号,通常是由内核或操作系统的组件触发的,而不是外部硬件设备。
- 工作原理: 软中断是通过在内存中设置一个特殊的中断标志位来触发的。当CPU执行到一个允许软中断的位置时,它会检查这个标志位,如果被设置,CPU将跳转到相应的软中断处理程序执行。(内核触发,延迟执行)
- 中断处理程序:
- 概念: 中断处理程序是用于响应中断事件的一段代码,它负责处理中断并执行必要的操作。
- 工作原理: 当中断被触发,CPU会跳转到相应的中断处理程序。中断处理程序执行与中断相关的任务,可能包括保存当前状态、处理中断源产生的事件、执行特定的操作,最后恢复先前的执行状态。
- 如何查看软中断和内核线程?
- /proc/interrupts 提供了硬中断的运行情况(系统硬件触发,不需要太关注)
- /proc/softirqs 提供了软中断的运行情况(下图中第一列是中断类型,后面案例分析会说到)
 不同软中断类型在每个CPU上的累积运行次数
不同软中断类型在每个CPU上的累积运行次数
 内核中断线程
内核中断线程
软中断CPU使用率升高,我该怎么办?
- 案例现象
- 软中断线程(ksoftirqd/1)使用率超高,处理中断的CPU占比也很高
- 分析过程
1.使用watch动态观测,确认是什么类型的软中断?
watch -d "/bin/cat /proc/softirqs"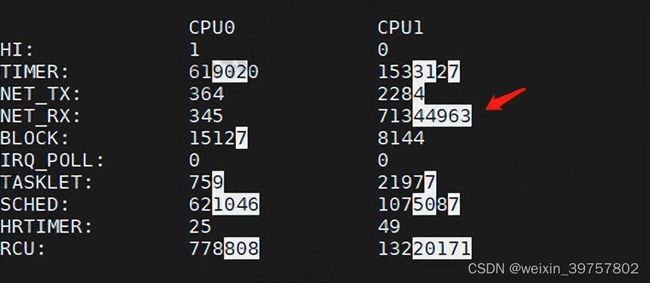
- 分析结果
- TIMER(定时中断)、 NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁)等这几个软中断都在不停变化
- 而 NET_RX,就是网络数据包接收软中断的变化速率最快
- 其他几种类型的软中断,是保证 Linux 调度、时钟、临界区保护这些正常工作所必需的,所以有变化时正常的
2.使用sar查询网络收发情况
# 使用sar是因为不仅可以观察网络收发的吞吐量(BPS),还可以观察网络收发的网络帧数( PPS)
sar -n DEV 1
- 分析结果
- 网卡ens33:每秒接收的网络帧数比较大,几乎达到8w,而发送的网络帧数较小,只有接近4w;每秒接收的千字节数只有 4611 KB,发送的千字节数更小,只有2314 KB(接收的PPS达到8w,但接收的BPS只有5k不到,网络帧看起来是比较小的)
- docker0和veth04076e3:数据跟 ens33 基本一致只是发送和接收相反,发送的数据较大而接收的数据较小,这是 Linux 内部网桥转发导致的,属于正常情况
3.使用tcpdump抓包一探究竟
tcpdump -i ens33 -n tcp port 80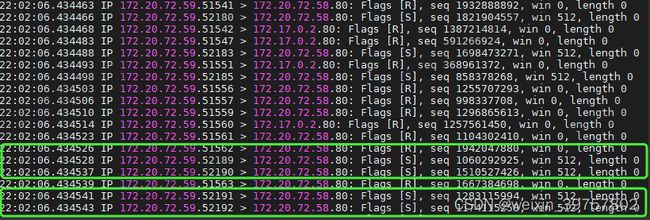
- 分析结果
- Flags [S]: 表示这是一个SYN包。而且是大量的SYN在发过来,很明显这就是SYN FLOOD攻击
- SYN FLOOD解决方法
- 如果有防护设备(F5等),通过硬件来防护
- 利用iptables临时封掉攻击的IP或IP号段,也可以根据访问频次来限制
- 优化系统内核相关参数,增加抵御能力。这个后期会在后期单独详细解决
欢迎一起交流、一起讨论。无论是编码的乐趣还是系统的构建,让我们共同在这个科技的大舞台上创造奇迹。