Netty—Reactor线程模型详解
文章目录
- 前言
- 线程模型基本介绍
-
- 线程模型分类
- Reactor线程模型介绍
- Netty线程模型:
- 传统阻塞IO的缺点
- Reactor线程模型
-
- 单Reactor单线程模式
- 单Reactor多线程模式
- 主从Reactor多线程
- Reactor 模式小结
- Netty 线程模型
-
- 案例说明:
- Netty核心组件简介
-
- ChannelPipeline与Channel的关系
- 参考文献
前言
前面我们说了Netty中的NIO:Netty—NIO万字详解 ;其中涉及到一个重要的底层模型—Reactor线程模型,而Netty线程模型就是基于Reactor线程模型的改进,它也是Netty中个人认为是最重要的一个知识点,在我看来只有掌握了Netty线程模型才算是真正意义上的理解了Netty!!
所以本文将详细说明Reactor线程模型,以及Netty线程模型,帮助大家更好的理解Netty
线程模型基本介绍
线程模型是指在操作系统中,线程是如何被创建、调度和管理的
线程模型分类
- 单线程模型:如Redis,它采用单线程来处理命令,所有命令都回进入到一个队列中,然后逐个执行。
- 多线程模型:也被称为并发多线程模型。
如果细分的话有以下几种:
- 单线程模型: 在单线程模型中,程序只有一个执行线程,所有的任务按照顺序执行。这种模型的优点是简单,易于理解和调试。然而,缺点是无法充分利用多核处理器的优势,因为在任何时刻只有一个任务在执行。
- 多线程模型: 多线程模型允许程序同时执行多个线程,每个线程独立执行不同的任务。这可以提高程序的并发性和性能,特别是在多核处理器上。但多线程编程也引入了一些复杂性,例如需要处理线程同步、死锁等问题。
- 分布式模型: 在分布式模型中,任务被分布到多个计算节点上执行。这可以通过网络进行通信,每个节点独立运行。分布式模型通常用于大规模系统,以提高可伸缩性和容错性。
- Reactor模型: Reactor模型是一种事件驱动的模型,其中一个主线程负责监听和分发事件,而多个工作者线程负责处理事件。这样可以有效地处理大量并发连接,例如在网络编程中。
- Proactor模型: Proactor模型也是一种事件驱动的模型,但与Reactor不同,Proactor模型中事件处理由操作系统负责,而应用程序只需提供回调函数。这样可以实现异步非阻塞的I/O操作。
- Actor模型: Actor模型是一种并发计算模型,其中每个"Actor"都是独立的实体,通过消息传递进行通信。每个Actor都有自己的状态和行为,可以并发地执行。
Reactor线程模型介绍
Reactor线程模型是一种事件驱动的编程模式,主要用于处理高并发网络I/O操作。它的核心思想是使用一个或多个反应器(Reactor)来监听和分发网络事件,然后将这些事件分配给相应的处理器(Handler)或者线程池进行处理。
主要组成部分和工作流程:
- Reactor:这是模型的核心组件,负责监听所有的网络连接和相应事件。它通过使用
I/O多路复用技术(如Linux的epoll、Java的NIO Selector等)在一个单独的线程或者一组线程中监控多个socket的活动,这样可以避免传统阻塞I/O模型中为每个连接创建新线程带来的资源开销。- Dispatcher:在某些实现中,
dispatcher是一个逻辑角色,负责根据事件的类型将事件转发给合适的处理器。例如,新的连接请求可能被转发给Acceptor处理,而读写事件则被转发给对应的Handler。- Acceptor:在接收到新的连接请求时,
Acceptor负责接受这个连接,并将其配置为非阻塞模式,然后将其添加到Reactor的监听列表中。- Handler(也称为
Worker):当Reactor检测到某个socket上有读写事件时,它会将事件转发给对应的Handler进行处理。Handler负责实际的业务逻辑,如读取数据、解析协议、执行操作并返回响应。
而根据Reactor和线程池的数量,Reactor线程模型可以有以下几种变体:
- 单Reactor单线程模型:所有事件的监听、分发和处理都在一个线程中完成。
- 单Reactor多线程模型:一个
Reactor线程负责监听和分发事件,而事件的处理则由一个线程池完成。 - 多Reactor多线程模型:多个
Reactor线程并行监听和分发事件,每个Reactor都有自己的线程池来处理事件。
这种模型的优势在于其高并发性和低资源消耗。通过复用线程和高效地调度事件,Reactor线程模型能够在处理大量并发连接时保持良好的性能和可扩展性。然而,其复杂性也较高,需要精心设计以确保线程安全和高效的事件处理。在许多现代高性能网络框架和库中,如Java的Netty和Python的Twisted,都采用了Reactor线程模型或者其变体。
举例说明:
假设我们有一个餐厅,这个餐厅有很多的桌子,每个桌子上有一个人在等待食物。当食物准备好后,服务员会通知对应桌子的人来取食物。在这个过程中,餐厅就相当于
Reactor,而桌子上的客人就是Handlers。当食物准备好后,餐厅会通知对应的桌子来取食物,也就是将事件分发给对应的处理程序来处理。
Netty线程模型:
虽然说Netty线程模型是由主从Reactor线程模型改进的,但Netty线程模型模型并不是一成不变的,它实际取决于启动参数配置。通过设置不同的启动参数来支持 Reactor 不同的线程模型。
- Netty单线程模型—> Reactor单线程模型—> 传统阻塞IO+多路复用器
- Netty多线程模型—> Reactor多线程模型—> Reactor单线程模型+线程池
- 主从Netty多线程模型—> 主从
Reactor多线程模型—>Reactor多线程模型+线程池
后面会详细说明!!
传统阻塞IO的缺点
传统阻塞
IO很容易理解,这里不做过多的解释,直接说缺点,然后后面看Reactor线程模式是怎么解决这些缺点的,先看图:

缺点主要包括以下3点:
- 性能低下:在等待
I/O操作完成期间,线程会被阻塞,无法执行其他任务。这会导致CPU资源的浪费,尤其是在需要处理大量I/O操作的情况下。 - 无法处理大量并发连接:由于每个
I/O操作都需要等待,因此无法高效地处理大量并发连接。这限制了系统的吞吐量和并发性。 - 无法充分利用多核资源:由于线程在等待
I/O操作完成时会被阻塞,因此无法充分利用多核资源。这限制了系统的性能和并发性。
Reactor线程模型
针对传统阻塞IO服务模型的缺点,Reactor线程模型的解决办法是:
1、基于I/O复用模型:
Reactor线程模型采用I/O复用技术,允许多个连接共享同一个阻塞对象。这意味着应用程序只需要在一个阻塞对象上等待,无需为每个连接都创建一个独立的线程。当某个连接有新的数据可以处理时,操作系统会通知应用程序,线程从阻塞状态返回,开始进行业务处理。
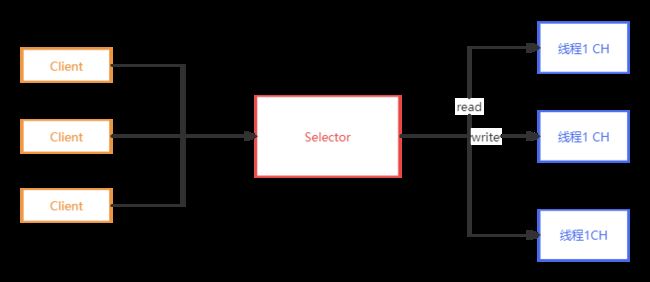
对上图说明:
这里很像我们前面讲过的NIO,在案例七中,就是采用基于I/0复用模型,Selector就相当于一个IO复用器;但这种模式是有问题的?它还是无法充分利用多核CPU的性能,也会有性能瓶颈,因为虽然IO复用了,但还是一个线程去处理所有事物
2、基于线程池复用线程资源:
Reactor线程模型通过线程池来复用线程资源。这意味着不必再为每个连接创建新的线程,而是将连接完成后的业务处理任务分配给线程池中的线程进行处理。一个线程可以处理多个连接的业务,提高了系统的并发性和效率。

对上图说明:
- Reactor模式,通过一个或多个输入同时传递给服务处理器的模式(基于事件驱动)
- 服务器端程序处理传入的多个请求,并将它们同步分派到相应的处理线程,因此Reactor模式也叫Dispatcher模式
- Reactor模式使用10复用监听事件,收到事件后,分发给某个线程(进程),这点就是网络服务器高并发处理关键
用前文说得NIO举例就是在传统的NIO处理读写事件时加入了线程池,如下:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ReactorMultiThread {
public static void main(String[] args) throws IOException {
// 创建一个ServerSocketChannel
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 设置为非阻塞模式
serverSocketChannel.configureBlocking(false);
// 绑定到端口8080
serverSocketChannel.bind(new InetSocketAddress(8080));
// 创建一个Selector
Selector selector = Selector.open();
// 将ServerSocketChannel注册到Selector上,监听连接事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
// 创建一个线程池
ExecutorService executorService = Executors.newFixedThreadPool(10);
while (true) {
// 轮询Selector,等待事件发生
int readyChannels = selector.select();
if (readyChannels == 0) {
continue;
}
// 处理发生的事件
for (SelectionKey key : selector.selectedKeys()) {
// 处理连接事件
if (key.isAcceptable()) {
// 接受连接
ServerSocketChannel acceptChannel = (ServerSocketChannel) key.channel();
SocketChannel socketChannel = acceptChannel.accept();
// 将SocketChannel注册到Selector上,监听读写事件
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ | SelectionKey.OP_WRITE);
}
// 处理读写事件
if (key.isReadable() || key.isWritable()) {
// 提交给线程池处理
executorService.submit(() -> {
// 处理读写事件
SocketChannel socketChannel = (SocketChannel) key.channel();
// 读取数据
byte[] buffer = new byte[1024];
int readBytes = socketChannel.read(buffer);
if (readBytes > 0) {
// 处理读取到的数据
}
// 写数据
socketChannel.write(buffer);
});
}
}
// 清空已处理的事件
selector.selectedKeys().clear();
}
}
}
Reactor线程模型就是通过 单个线程 使用Java NIO包中的Selector的select()方法,进行监听。当获取到事件(如accept、read等)后,就会分配(dispatch)事件进行相应的事件处理(handle)。
如果要给 Reactor线程模型 下一个更明确的定义,应该是:
Reactor线程模式 = Reactor(I/O多路复用)+ 线程池
单Reactor单线程模式
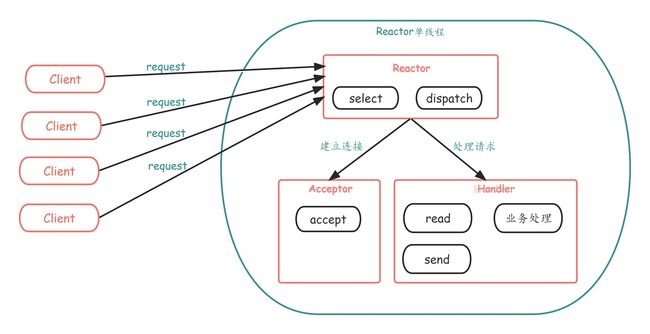
Select是前面1/0复用模型介绍的标准网络编程API,可以实现应用程序通过一个阻塞对象监听多路连接请求- Reactor 对象通过
Select监控客户端请求事件,收到事件后通过Dispatch进行分发 - 如果是建立连接请求事件,则由
Acceptor通过Accept处理连接请求,然后创建一个Handler对象处理连接完成后的后续业务处理 - 如果不是建立连接事件,则
Reactor会分发调用连接对应的Handler来响应 - Handler 会完成
Read→业务处理→Send的完整业务流程
结合实例:服务器端用一个线程通过多路复用搞定所有的10操作(包括连接,读、写等),编码简单,清晰明了,但是如果客户端连接数量较多,将无法支撑,上篇文章中的的NIO案例就属于这种模型。
无论是事件监听、事件分发、还是事件处理,都始终只有 一个线程 执行所有的事情
优点:
模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成
缺点:
- 性能问题,只有一个线程,无法完全发挥多核
CPU的性能。Handler在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈- 可靠性问题,线程意外终止,或者进入死循环,会导致整个系统通信模块不可用,不能接收和处理外部消息,造成节点故障
使用场景:
- 低负载的应用程序:当应用程序的负载较低,同时并发连接数也相对较少时,使用
Reactor单线程模式可以满足需求,并且可以简化代码的编写和维护。- 短时间处理的任务:如果应用程序的任务处理时间较短,不会导致单线程阻塞过长时间,那么使用
Reactor单线程模式可以获得良好的性能。- 资源有限的环境:在一些资源有限的环境中,如嵌入式设备或特定的服务器环境,使用
Reactor单线程模式可以减少线程创建和上下文切换的开销,提高系统的效率。
比如Redis在业务处理的时间复杂度
O(1)的情况
单Reactor多线程模式
为了提高性能,我们可以把复杂的事件处理handler交给线程池,那就可以演进为 「单Reactor多线程模型」
Reactor多线程模式 = Reactor单线程模式 + 线程池

- Reactor对象通过select监控客户端请求事件,收到事件后,通过dispatch进行分发
- 如果建立连接请求,则右Acceptor通过accept处理连接请求,然后创建一个Handler对象处理完成连接后的各种事件
- 如果不是连接请求,则由reactor分发调用连接对应的handler来处理
- handler只负责响应事件,不做具体的业务处理,通过read读取数据后,会分发给后面的worker线程池的某个线程处理业务
- worker线程池会分配独立线程完成真正的业务,并将结果返回给handler
- handler收到响应后,通过send将结果返回给client
优点:可以充分的利用多核cpu的处理能力
缺点:在极个别特殊场景中,一个Reactor线程负责监听和处理所有的客户端连接可能会存在性能问题。例如并发百万客户端连接(双十一、春运抢票)
适用于以下场景:
- 高并发的应用程序:当应用程序需要处理大量并发连接时,使用单Reactor多线程模式可以提高并发处理能力,每个连接都可以在独立的线程中进行处理,避免了线程之间的竞争。
- 长时间处理的任务:如果应用程序需要处理耗时较长的任务,使用单Reactor多线程模式可以避免阻塞主线程,提高系统的响应性能。主线程负责接收和分发事件,而具体的任务处理则由其他线程完成。
- 资源充足的环境:在资源充足的环境下,可以使用单Reactor多线程模式来充分利用多核处理器的性能优势,提高系统的吞吐量。 需要注意的是,单Reactor多线程模式需要合理配置线程池的大小,避免线程数过多导致资源浪费或线程数过少导致性能瓶颈。此外,多线程模式下需要注意线程安全性和资源共享的问题。
主从Reactor多线程
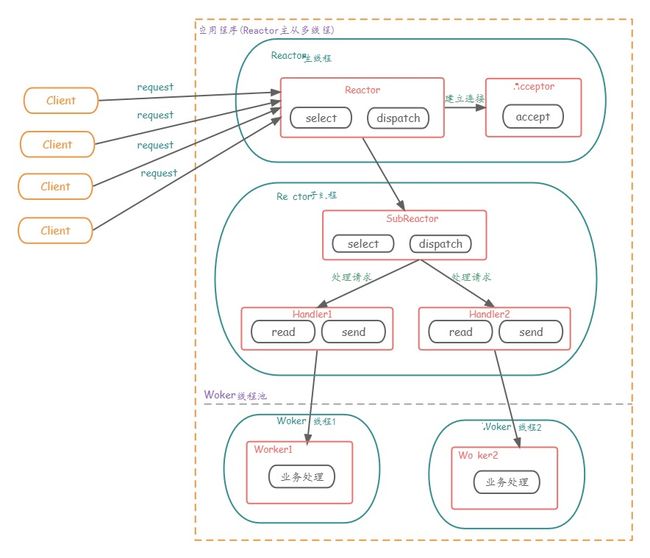
- Reactor主线程
MainReactor对象通过select监听连接事件,收到事件后,通过Acceptor处理连接事件 - 当
Acceptor处理连接事件后,MainReactor将连接分配给SubReactor subreactor将连接加入到连接队列进行监听,并创建handler进行各种事件处理- 当有新事件发生时,
subreactor就会调用对应的handler处理 handler通过read读取数据,分发给后面的worker线程处理worker线程池分配独立的worker线程进行业务处理,并返回结果handler收到响应的结果后,再通过send将结果返回给clientReactor主线程可以对应多个Reactor子线程,即MainRecator可以关联多个SubReactor
Reactor 模式小结
用生活中的例子说明:
- 单Reactor单线程模型,前台和服务员都是一个人,全称为客户服务
- 单Reactor多线程模型,一个前台接待员和多个服务员,前台只负责接待
- 主从Recator多线程模型,多个前台,多个服务员
Reactor线程模型的优点:
- 高效事件处理:通过I/O多路复用技术,Reactor能够同时监控多个连接,减少了系统的阻塞情况,提高了系统的并发性能。
- 非阻塞IO:Reactor模型基于异步非阻塞IO,使得线程在等待网络IO操作完成时,可以去处理其他任务,提高了资源利用率。
- 职责分离:Reactor模型将事件的分发和处理分离,父线程(或主Reactor)负责监听和分发事件,子线程(或工作线程、从Reactor)负责具体的业务处理,这种分工使得系统结构清晰,易于维护和扩展。
- 可伸缩性:根据系统的负载情况,可以通过增加或减少工作线程来调整系统的处理能力,具有良好的水平扩展性。
- 避免数据竞争:通过线程间的通信机制,如队列或者直接的数据传递,可以有效地避免多线程环境中的数据竞争问题。
- 降低上下文切换开销:由于父线程主要负责事件分发,子线程主要负责业务处理,这种分工可以减少不必要的上下文切换,提高系统效率。
- 支持高并发:尤其在高并发场景下,Reactor线程模型能够更好地处理大量的客户端请求,保持系统的响应能力和稳定性。
- 灵活的线程模型选择:Reactor模型有多种变体,如单线程、多线程和主从多线程模型,可以根据具体的应用需求和性能目标选择最适合的线程模型。
- 易于实现和使用:许多成熟的网络框架,如Netty,已经实现了Reactor线程模型,开发者可以直接使用这些框架,而无需从头开始实现复杂的网络编程逻辑。
其实这三种模型的演变就一句话:
没有什么是加一层解决不了的,如果有,那就再加一层!!!
Netty 线程模型
Netty的线程模型是基于主从Reactor多线程模型做了一定改进的,能理解Reactor线程模型,Netty线程模型基本也就理解了,只是要懂各个组件之间的功能和组合,先看图:
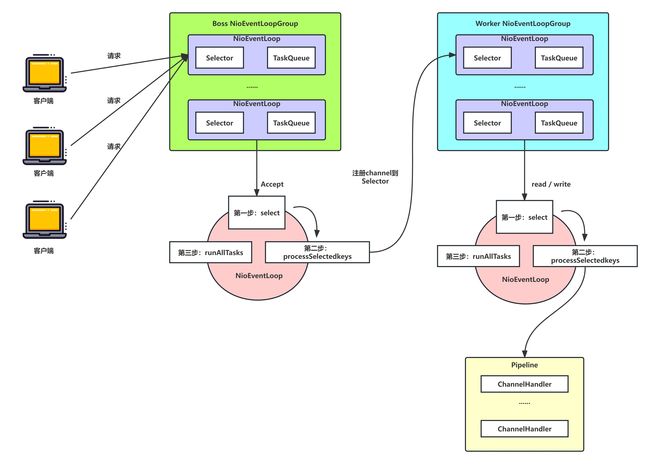
不是说Netty线程模型只能是主从Reactor线程模型,而是可以根据传入的参数,来改变它的线程模式的!!!
-
Nety抽象出两组线程池
BossGroup (Boos NioEventLoopGroup)专门负责接收客户端的连接,WorkerGroup专门负责网络的读写 -
BossGroup和WorkerGroup类型都是
NioEventLoopGroup -
NioEventLoopGroup相当于一个事件循环组,这个组中含有多个事件循环,每一个事件循环是
NioEventLoop -
NioEventLoop表示一个不断循环的执行处理任务的线程,每个NioEventLoop都有一个
selector,用于监听绑定在其上的socket的网络通讯 -
NioEventLoopGroup可以有多个线程,即可以含有多个
NioEventLoop -
每个Boss NioEventLoop循环执行的步骤有3步
-
轮询accept事件
-
处理accept事件,与client建立连接,生成NioScocketChannel,并将其注册到某个worker NIOEventLoop上的selector
-
处理任务队列的任务,即unAllTasks T)
-
-
每个Worker NIOEventLoop循环执行的3个步骤
- 轮询read,write事件
- 处理IO事件,即read,write事件,在对应NioScocketChannel处理
- 处理任务队列的任务,即runAllTasks
-
每个Worker NIOEventLoop处理业务时,会使用pipeline(管道),pipeline中包含了channel,即通过pipeline可以获取到对应通道,管道中维护了很多的处理器
案例说明:
服务端:
/**
* com.atguigu.netty
*
* @author co_wb_junjie_qiu
* @version Id: NettyServer, v 0.1 2023/12/19 9:23 co_wb_junjie_qiu Exp $
*/
public class NettyServer {
public static void main(String[] args) throws InterruptedException {
//创建 BossGroup 和 WorkerGroup
//1.创建两个线程组 bossGroup 和 workerGroup
//2.bossGroup 只是处理连接请求,真正的和客户端业务处理,会交给 workerGroup 完成
//3.两个都是无限循环
//4.bossGroup 和 workerGroup 含有的子线程(NioEventLoop)的个数
//默认实际 cpu 核数*2
NioEventLoopGroup boosGroup = new NioEventLoopGroup();
NioEventLoopGroup workerGroup = new NioEventLoopGroup();
try {
// 服务端的辅助程序
// 创建服务器端的启动对象,配置参数
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(boosGroup, workerGroup) // 设置两个线程组
// 设置服务器用于接受新的连接的通道为NioServerSocketChannel类。这是一个非阻塞的NIO服务器套接字通道。
.channel(NioServerSocketChannel.class)
// 设置服务器的TCP参数,SO_BACKLOG表示在拒绝新的连接之前,服务器可以排队等待的连接数。
.option(ChannelOption.SO_BACKLOG, 128)
// 为接受的新连接设置TCP参数,开启keep-alive机制,以避免长时间的不活动导致的连接中断(保持长连接)。
.childOption(ChannelOption.SO_KEEPALIVE, true)
// 设置处理新连接的初始化程序。当有新连接到达时,这个初始化程序会被用来配置新连接的管道。
.childHandler(new ChannelInitializer<SocketChannel>() {
// 创建一个通道初始化对象
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
// 给Pipeline 设置处理器(自定义)
socketChannel.pipeline().addLast(new NettyServerHandler());
}
});// 给workerGroup 的 EventLoop 对应的管道设置处理器
// 启动服务器,并绑定端口
ChannelFuture sync = bootstrap.bind(6668).sync();
// 对关闭通道进行监听
sync.channel().closeFuture().sync();
} finally {
boosGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
服务端处理器:
/**
* com.atguigu.netty
*
* 说明
* 1.我们自定义一个Handler需要继续netty规定好的某个HandlerAdapter(规范)
* 2.这时我们自定义一个Handler,才能称为一个handler
*
* @author co_wb_junjie_qiu
* @version Id: NettyServerHandler, v 0.1 2023/12/25 15:10 co_wb_junjie_qiu Exp $
*/
public class NettyServerHandler extends ChannelInboundHandlerAdapter {
/**
* 读取通道数据
* @param ctx 上下文对象,含有 管道pipeline,通道 channel 、地址
* @param msg 客户端发送过来的数据,默认Object
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("服务器读取线程 "+ Thread.currentThread().getName());
ChannelPipeline pipeline = ctx.pipeline();
System.out.println("pipeline 本身是一个双向列表" + pipeline);
ByteBuf buf = (ByteBuf)msg;
System.out.println("客户端发送的消息是:"+buf.toString(CharsetUtil.UTF_8));
System.out.println("客户端地址:"+ctx.channel().remoteAddress());
}
/**
* 数据读取完成之后
* 一般来说,我们会对这个发送的数据进行编码
*/
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
// writeAndFlush 是 写入和刷新
// 将数据写入缓存并刷新
// 一般讲,我们队这个发送的数据进行编码
ctx.writeAndFlush(Unpooled.copiedBuffer("hello 客户端",CharsetUtil.UTF_8));
}
/**
* 处理异常,一般需要关闭通道
*/
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
ctx.close();
}
}
客户端:
/**
* com.atguigu.netty
*
* @author co_wb_junjie_qiu
* @version Id: NettyClient, v 0.1 2023/12/25 15:20 co_wb_junjie_qiu Exp $
*/
public class NettyClient {
public static void main(String[] args) throws InterruptedException {
NioEventLoopGroup group = new NioEventLoopGroup();
try {
Bootstrap bootstrap = new Bootstrap();
bootstrap.group(group)
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new NettyClientHandler());
}
});
ChannelFuture channelFuture = bootstrap.connect("127.0.0.1", 6668).sync();
channelFuture.channel().closeFuture().sync();
} finally {
group.shutdownGracefully();
}
}
}
客户端处理器:
/**
* com.atguigu.netty
*
* @author co_wb_junjie_qiu
* @version Id: NettyClientHandler, v 0.1 2023/12/25 15:30 co_wb_junjie_qiu Exp $
*/
public class NettyClientHandler extends ChannelInboundHandlerAdapter {
/**
* 当通道就绪就会触发该方法
*/
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
System.out.println("client channelActive");
ctx.writeAndFlush(Unpooled.copiedBuffer("hello server", CharsetUtil.UTF_8));
}
/**
* 当通道有读取事件时会触发
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buf = (ByteBuf) msg;
System.out.println("服务器回复的消息:"+buf.toString(CharsetUtil.UTF_8));
System.out.println("服务器的地址:"+ctx.channel().remoteAddress());
}
/**
* 处理异常,一般需要关闭通道
*/
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
cause.printStackTrace();
ctx.close();
}
}
Netty核心组件简介
- Channel:
Channel是Netty中的核心概念,代表了应用程序和网络之间的连接。- 它封装了网络套接字,并提供了读写数据、绑定端口、连接远程地址、关闭连接等基本的
I/O操作。 Channel提供了非阻塞的I/O操作,使得Netty能够在单个线程中处理多个连接。
- EventLoop:
EventLoop是Netty中负责处理Channel事件的组件。- 每个
EventLoop负责监听和处理其关联的Channel上的事件,包括读写操作、连接建立、连接关闭等。 - 一个
EventLoop在其生命周期内通常会与一个或多个Channel关联,确保Channel的所有操作都在同一个线程上下文中执行,从而避免了线程安全问题。
- ChannelHandler:
- ChannelHandler 是 Netty 中处理 Channel 事件的接口或者类。
- 应用程序通过实现
ChannelHandler接口或者扩展ChannelInboundHandler或ChannelOutboundHandler类来定制自己的业务逻辑。 ChannelHandler可以参与到Channel的生命周期中的多个阶段,如连接建立、数据读取、数据写入、连接关闭等。
- ChannelPipeline:
- ChannelPipeline 是一个处理链,包含了多个 ChannelHandler。
- 当 Channel 上发生事件时,这些事件会在
ChannelPipeline中按照一定的顺序传递给各个ChannelHandler进行处理。 - ChannelPipeline 允许开发者灵活地配置和组织 ChannelHandler,以实现复杂的业务逻辑和协议解析。
- EventLoopGroup:
- EventLoopGroup 是一组 EventLoop 的集合。
- Netty 通常会为服务器和客户端分别创建一个
EventLoopGroup。 - EventLoopGroup 负责分配
EventLoop给新的Channel,以及管理它们的生命周期。
- ChannelFuture:
- ChannelFuture 表示一个异步操作的结果。
- 当在 Channel 上执行诸如连接、写入数据等异步操作时,会返回一个 ChannelFuture。
- 通过注册
ChannelFutureListener,应用程序可以监听操作的完成、失败或者取消等事件。
- Bootstrap、ServerBootstrap(引导器):
Bootstrap是启动Netty应用程序的入口,用于配置Channel和其他相关的参数。- 通过
Bootstrap可以配置客户端和服务器,包括线程模型、Channel类型、ChannelHandler等。
- ByteBuf(字节缓冲区):
ByteBuf是Netty中用于处理字节数据的缓冲区,提供了灵活的API用于读取、写入和操作字节数据。ByteBuf具有池化和零拷贝等优化特性,使得数据的处理更加高效。
- Codec(编解码器):
- Netty提供了丰富的编解码器,用于处理字节数据的编码和解码,包括
StringDecoder、StringEncoder、ObjectDecoder、ObjectEncoder等。 - 编解码器可以简化开发者的工作,实现对各种协议的支持
- Netty提供了丰富的编解码器,用于处理字节数据的编码和解码,包括
其中最核心的是前4个 ,可以说其他组件都是为了辅助它们的。
- Channel:通道是 Netty 中的基本组件,它表示一个网络连接。
- EventLoop:事件循环是 Netty 中负责处理 I/O 事件的组件。
- ChannelHandler:通道处理器是 Netty 中负责处理 I/O 事件的组件。
- ChannelPipeline:通道管道是 Netty 中负责将 I/O 事件从
Channel传递到ChannelHandler的组件。
ChannelPipeline与Channel的关系
其中比较难理解是ChannelPipeline通道与Channel管道,这两个概念,下面将详细说明:
- 每个
Channel都有一个与之关联的ChannelPipeline。 ChannelPipeline是Channel的一部分,它负责处理所有与该Channel相关的事件和数据。- 当
Channel接收到数据或者发生其他事件时,这些事件会被自动地传递到其关联的ChannelPipeline中进行处理。 - 开发者可以通过操作
ChannelPipeline来添加、删除或者替换ChannelHandler,从而改变事件处理的逻辑。
生活中的例子说明:
假设你正在经营一家快递公司,
Channel可以类比为公司的运输车辆,它负责实际的包裹运输。
ChannelPipeline则可以看作是包裹从发出到接收过程中的一系列处理环节。例如,当一个包裹(相当于网络数据)进入你的公司时,它首先会经过收件区(相当于ChannelPipeline中的第一个ChannelHandler),在那里进行登记和初步检查。然后,包裹被送到分拣区(第二个ChannelHandler),根据目的地进行分类。接着,包裹被装载到相应的运输车辆(Channel)上,运往目标城市。到达目标城市后,包裹再次经过一系列的处理环节(更多的ChannelHandler),如卸货、本地配送等,最终送达客户手中。在这个例子中,每辆运输车辆(
Channel)都有自己的运输流程(ChannelPipeline),包括了各个环节的处理步骤(ChannelHandler)。通过调整运输流程中的处理环节,你可以优化整体的运输效率和服务质量。同样,在 Netty 中,通过配置和操作ChannelPipeline,你可以定制网络通信的处理逻辑,提高系统的性能和灵活性。
参考文献
尚硅谷Netty教程