常见的锁和zookeeper
zookeeper
本文由 简悦 SimpRead 转码, 原文地址 zhuanlan.zhihu.com
前言
只有光头才能变强。
文本已收录至我的 GitHub 仓库,欢迎 Star:https://github.com/ZhongFuCheng3y/3y
上次写了一篇 什么是消息队列?以后,本来想入门一下 Kafka 的 (装一下环境、看看 Kafka 一些概念啥的)。后来发现 Kafka 用到了 ZooKeeper,而我又对 ZooKeeper 不了解,所以想先来学学什么是 ZooKeeper,再去看看什么是 Kafka。
ZooKeeper 相信大家已经听过这个词了,不知道大家对他了解多少呢?我第一次听到 ZooKeeper 的时候是在学 Eureka 的时候(外行人都能看懂的 SpringCloud,错过了血亏!),同样 ZooKeeper 也可以作为注册中心。
后面听到 ZooKeeper 的时候,是因为 ZooKeeper 可以作为分布式锁的一种实现。
直至在了解 Kafka 的时候,发现 Kafka 也需要依赖 ZooKeeper。Kafka 使用 ZooKeeper 管理自己的元数据配置。
这篇文章来写写我学习 ZooKeeper 的笔记,如果有错的地方希望大家可以在评论区指出。
一、什么是 ZooKeeper
从上面我们也可以发现,好像哪都有 ZooKeeper 的身影,那什么是 ZooKeeper 呢?我们先去官网看看介绍:

官网还有另一段话:
ZooKeeper: A Distributed Coordination Service for Distributed Applications
相比于官网的介绍,我其实更喜欢 Wiki 中对 ZooKeeper 的介绍:

(留下不懂英语的泪水)
我简单概括一下:
-
ZooKeeper 主要服务于分布式系统,可以用 ZooKeeper 来做:统一配置管理、统一命名服务、分布式锁、集群管理。
-
使用分布式系统就无法避免对节点管理的问题 (需要实时感知节点的状态、对节点进行统一管理等等),而由于这些问题处理起来可能相对麻烦和提高了系统的复杂性,ZooKeeper 作为一个能够通用解决这些问题的中间件就应运而生了。
二、为什么 ZooKeeper 能干这么多?
从上面我们可以知道,可以用 ZooKeeper 来做:统一配置管理、统一命名服务、分布式锁、集群管理。
- 这里我们先不管
统一配置管理、统一命名服务、分布式锁、集群管理每个具体的含义 (后面会讲)
那为什么 ZooKeeper 可以干那么多事?来看看 ZooKeeper 究竟是何方神物,在 Wiki 中其实也有提到:
ZooKeeper nodes store their data in a hierarchical name space, much like a file system or a tree data structure
ZooKeeper 的数据结构,跟 Unix 文件系统非常类似,可以看做是一颗树,每个节点叫做 ZNode。每一个节点可以通过路径来标识,结构图如下:

那 ZooKeeper 这颗 “树” 有什么特点呢??ZooKeeper 的节点我们称之为 Znode,Znode 分为两种类型:
- 短暂 / 临时 (Ephemeral):当客户端和服务端断开连接后,所创建的 Znode(节点) 会自动删除
- 持久 (Persistent):当客户端和服务端断开连接后,所创建的 Znode(节点) 不会删除
ZooKeeper 和 Redis 一样,也是 C/S 结构 (分成客户端和服务端)

2.1 监听器
在上面我们已经简单知道了 ZooKeeper 的数据结构了,ZooKeeper 还配合了监听器才能够做那么多事的。
常见的监听场景有以下两项:
- 监听 Znode 节点的数据变化
- 监听子节点的增减变化


没错,通过监听 + Znode 节点 (持久 / 短暂 [临时]),ZooKeeper 就可以玩出这么多花样了。
三、ZooKeeper 是怎么做到的?
下面我们来看看用 ZooKeeper 怎么来做:统一配置管理、统一命名服务、分布式锁、集群管理。
3.1 统一配置管理
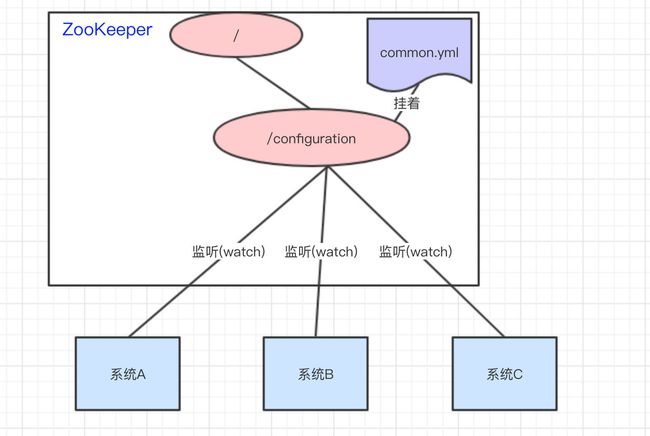
比如我们现在有三个系统 A、B、C,他们有三份配置,分别是ASystem.yml、BSystem.yml、CSystem.yml,然后,这三份配置又非常类似,很多的配置项几乎都一样。
- 此时,如果我们要改变其中一份配置项的信息,很可能其他两份都要改。并且,改变了配置项的信息很可能就要重启系统
于是,我们希望把ASystem.yml、BSystem.yml、CSystem.yml相同的配置项抽取出来成一份公用的配置common.yml,并且即便common.yml改了,也不需要系统 A、B、C 重启。

做法:我们可以将common.yml这份配置放在 ZooKeeper 的 Znode 节点中,系统 A、B、C 监听着这个 Znode 节点有无变更,如果变更了,及时响应。
参考资料:
-
基于 zookeeper 实现统一配置管理
-
https://blog.csdn.net/u011320740/article/details/78742625
3.2 统一命名服务
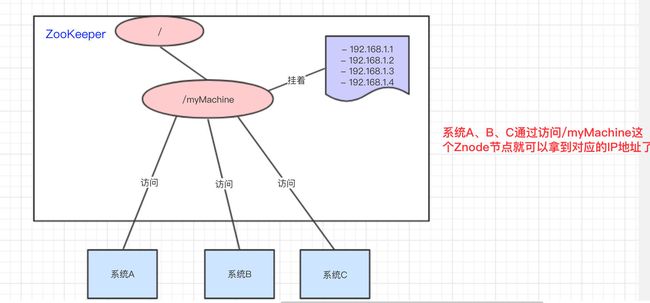
统一命名服务的理解其实跟域名一样,是我们为这某一部分的资源给它取一个名字,别人通过这个名字就可以拿到对应的资源。
比如说,现在我有一个域名www.java3y.com,但我这个域名下有多台机器:
- 192.168.1.1
- 192.168.1.2
- 192.168.1.3
- 192.168.1.4
别人访问www.java3y.com即可访问到我的机器,而不是通过 IP 去访问。
3.3 分布式锁
锁的概念在这我就不说了,如果对锁概念还不太了解的同学,可参考下面的文章
- Java 锁?分布式锁?乐观锁?行锁?
我们可以使用 ZooKeeper 来实现分布式锁,那是怎么做的呢??下面来看看:
系统 A、B、C 都去访问/locks节点

访问的时候会创建带顺序号的临时 / 短暂 (EPHEMERAL_SEQUENTIAL) 节点,比如,系统 A 创建了id_000000节点,系统 B 创建了id_000002节点,系统 C 创建了id_000001节点。

接着,拿到/locks节点下的所有子节点 (id_000000,id_000001,id_000002),判断自己创建的是不是最小的那个节点
-
如果是,则拿到锁。
-
释放锁:执行完操作后,把创建的节点给删掉
-
如果不是,则监听比自己要小 1 的节点变化
举个例子:
-
系统 A 拿到
/locks节点下的所有子节点,经过比较,发现自己 (id_000000),是所有子节点最小的。所以得到锁 -
系统 B 拿到
/locks节点下的所有子节点,经过比较,发现自己 (id_000002),不是所有子节点最小的。所以监听比自己小 1 的节点id_000001的状态 -
系统 C 拿到
/locks节点下的所有子节点,经过比较,发现自己 (id_000001),不是所有子节点最小的。所以监听比自己小 1 的节点id_000000的状态 -
……
-
等到系统 A 执行完操作以后,将自己创建的节点删除 (
id_000000)。通过监听,系统 C 发现id_000000节点已经删除了,发现自己已经是最小的节点了,于是顺利拿到锁 -
…. 系统 B 如上
3.4 集群状态
经过上面几个例子,我相信大家也很容易想到 ZooKeeper 是怎么 " 感知 " 节点的动态新增或者删除的了。
还是以我们三个系统 A、B、C 为例,在 ZooKeeper 中创建临时节点即可:

只要系统 A 挂了,那/groupMember/A这个节点就会删除,通过监听groupMember下的子节点,系统 B 和 C 就能够感知到系统 A 已经挂了。(新增也是同理)
除了能够感知节点的上下线变化,ZooKeeper 还可以实现动态选举 Master 的功能。(如果集群是主从架构模式下)
原理也很简单,如果想要实现动态选举 Master 的功能,Znode 节点的类型是带顺序号的临时节点 (EPHEMERAL_SEQUENTIAL) 就好了。
- Zookeeper 会每次选举最小编号的作为 Master,如果 Master 挂了,自然对应的 Znode 节点就会删除。然后让新的最小编号作为 Master,这样就可以实现动态选举的功能了。
最后
这篇文章主要讲解了 ZooKeeper 的入门相关的知识,ZooKeeper 通过 Znode 的节点类型 + 监听机制就实现那么多好用的功能了!
当然了,ZooKeeper 要考虑的事没那么简单的,后面有机会深入的话,我还会继续分享,希望这篇文章对大家有所帮助~
参考资料:
-
分布式服务框架 Zookeeper
-
https://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/index.html
-
ZooKeeper 初识整理 (老酒装新瓶)
-
https://lxkaka.wang/2017/12/21/zookeeper/
-
ZooKeeper
-
https://www.cnblogs.com/sunshine-long/p/9057191.html
-
ZooKeeper 的应用场景
-
https://zhuanlan.zhihu.com/p/59669985