pcc
PCC指标,即Pearson相关系数(Pearson Correlation Coefficient),是用来衡量两个变量之间线性相关程度的统计指标。它是一种最常用的相关系数,主要用于度量两个变量X和Y之间的相关(线性相关)程度。其取值范围在-1到1之间。
-
计算公式:
Pearson相关系数的计算公式是: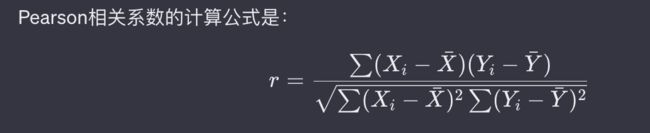
[
r = \frac{\sum (X_i - \bar{X})(Y_i - \bar{Y})}{\sqrt{\sum (X_i - \bar{X})^2 \sum (Y_i - \bar{Y})^2}}
]
其中,(X_i) 和 (Y_i) 是两个变量的观测值,(\bar{X}) 和 (\bar{Y}) 分别是这两个变量的均值。 -
解释:
- 当 (r = 1) 时,表示两个变量之间有完美的正相关关系。
- 当 (r = -1) 时,表示两个变量之间有完美的负相关关系。
- 当 (r = 0) 时,表示两个变量之间没有线性相关关系。
- (r) 的绝对值越大,表示相关性越强;绝对值越小,表示相关性越弱。
-
应用:
- 在统计分析中,PCC常用于探索数据之间的关系,如在生物医学、心理学、市场研究等领域。
- 它也被用于特征选择,即在机器学习和数据挖掘中识别重要的变量。
-
注意事项:
- PCC只能衡量线性关系,对于非线性关系可能无法有效反映。
- 高的相关系数并不意味着因果关系。
- 对于离群值敏感,极端值可能会显著影响相关系数的大小。
总的来说,Pearson相关系数是一种描述两个变量线性关系强度和方向的有效工具,但在使用时需要注意其局限性和适用条件。
NSE
NSE(Nash-Sutcliffe Efficiency)是水文学和环境科学中常用的一种模型评估指标,用于评估模型对观测数据的拟合程度。它是由John Nash和J.V. Sutcliffe于1970年提出的。NSE值的范围通常在-∞到1之间,可以用来量化模型预测值与实际观测值之间的一致性。
-
计算公式:
NSE的计算公式为: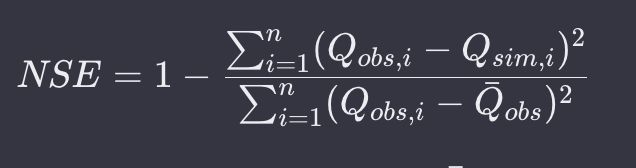
[
NSE = 1 - \frac{\sum_{i=1}^{n}(Q_{obs,i} - Q_{sim,i})2}{\sum_{i=1}(Q_{obs,i} - \bar{Q}{obs})^2}
]
其中,(Q) 是第i个观测值,(Q_{sim,i}) 是第i个模型模拟值,(\bar{Q}_{obs}) 是观测值的平均值,n是观测次数。 -
解释:
- 当 NSE = 1 时,表明模型模拟值与观测值完全吻合。
- 当 0 ≤ NSE < 1 时,表示模型具有一定的预测能力。
- 当 NSE = 0 时,表明模型预测的效果与平均值没有差别。
- 当 NSE < 0 时,表示模型预测的效果比平均值还差。
-
应用:
- NSE广泛应用于水文模型、气象模型和环境模型的效果评估。
- 它有助于了解模型对流域水文过程模拟的准确性。
-
注意事项:
- NSE对极端值较为敏感,因此在评估模型性能时需要考虑数据的特点。
- 它不能提供关于模型错误分布的信息。
NSE是一个非常有用的工具,可以帮助科学家和工程师评估和改进他们的模型,特别是在水资源管理和环境监测领域。然而,它也有局限性,通常需要与其他指标一起使用来全面评估模型性能。
RV
在土壤湿度预测领域,RV(Root Mean Square Error,均方根误差)是一个常用的性能评价指标。它主要用于衡量模型预测值与实际观测值之间的差异。RV值越小,表示模型的预测准确度越高。
-
计算公式:
RV的计算公式为:
[
RV = \sqrt{\frac{\sum_{i=1}^{n}(P_i - O_i)^2}{n}}
]
其中,(P_i) 是第i个预测值,(O_i) 是第i个观测值,n是观测次数。 -
解释:
- RV值提供了一个量化模型预测误差的手段。
- 它是所有预测值与观测值差的平方和的均方根。
- RV值越接近0,表示模型的预测越准确。
-
应用:
- 在土壤湿度预测领域,RV用于评价各种模型(如机器学习模型、统计模型等)预测土壤湿度的准确性。
- 通过比较不同模型的RV值,可以选出最佳的模型进行土壤湿度预测。
-
注意事项:
- RV对异常值非常敏感,一个较大的误差值会显著增加RV值。
- 它不区分过估计和低估,仅提供总体误差的度量。
- RV值本身没有提供关于误差分布的信息,所以通常需要与其他统计指标一起使用。
总的来说,RV是评估土壤湿度预测模型性能的一个重要工具,但在使用时应结合其他指标和模型特性进行综合考虑。
FLV(Flow Low Volume,低流量偏差)
FLV(低流量偏差):FLV计算的是模型在预测低流量情况时与观测值之间的平均百分比偏差。同样地,FLV值越接近0,表示模型预测的低流量值越接近实际观测值,表明模型在预测极端低流量事件时的性能更好。
您提供的这个函数 _flv 定义了一个名为 FLV(可能代表“流量偏差”或类似概念)的指标,用于计算模型在预测低流量(或类似概念,如低土壤湿度值)时的平均百分比偏差。让我们分步解析这个函数:
-
数据组合与排序:
首先,函数将观测值(y_true)和模拟值(y_pred)合并,并按照模拟值(即预测值)进行升序排序。这样做是为了识别出低流量的情况。 -
确定低流量范围:
函数接着确定了低流量的范围,这里使用了底部30%作为低流量的判定标准。这意味着所有数据中预测值最低的30%被认为是低流量情况。 -
提取低流量数据:
接下来,提取这30%的低流量数据,用于后续计算。 -
计算百分偏差:
函数最后计算了模拟值与观测值之间的百分比偏差。计算公式为:
[
FLV = \text{mean}\left(\frac{\text{模拟值} - \text{观测值}}{\text{观测值}}\right)
]
这里使用的是平均值,意味着它是这30%低流量情况下偏差的平均表现。
此指标用于评估模型在预测低流量(或低土壤湿度等类似情况)时的准确性。特别地,它关注的是模型在极端条件下的表现,这在实际应用中很重要,因为模型在极端条件下的表现往往对决策影响更大。FLV指标的一个重要特性是它专注于数据的一个子集(即低流量部分),而不是整个数据集。
FHV(Flood High Volume,洪水高流量偏差)
FHV(洪水高流量偏差):FHV计算的是模型在预测高流量情况时与观测值之间的平均百分比偏差。FHV值越接近0,意味着模型预测的高流量值越接近实际观测值,表明模型在预测极端高流量事件时的性能更好。
您提供的 _fhv 函数定义了一个名为 FHV(可能代表“高峰流量偏差”或类似概念)的指标,用于计算模型在预测高峰流量(或类似概念,如高土壤湿度值)时的平均百分比偏差。这个函数的工作流程如下:
-
数据组合与排序:
函数将观测值(y_true)和模拟值(y_pred)合并,并按照模拟值(即预测值)进行升序排序。排序后,高峰值会位于数组的末端。 -
确定高峰流量范围:
接着,函数确定了高峰流量的范围,这里使用了前2%作为高峰流量的标准。这意味着所有数据中预测值最高的2%被视为高峰流量情况。 -
提取高峰流量数据:
函数提取这2%的高峰流量数据,用于后续计算。 -
计算百分偏差:
最后,计算了模拟值与观测值之间的百分比偏差。计算公式为:
[
FHV = \text{mean}\left(\frac{\text{模拟值} - \text{观测值}}{\text{观测值}}\right)
]
采用平均值计算表示它是这2%高峰流量情况下偏差的平均表现。
与 FLV 类似,FHV 指标专注于评估模型在特定极端条件下(这里是高峰流量)的预测性能。这种指标对于评价模型在极端情况下的表现尤为重要,因为这些情况往往对实际应用影响较大。例如,在水文模型中,准确预测高峰洪水流量对于防洪管理和规划至关重要。通过专注于数据的一个特定子集(这里是高峰值部分),FHV 提供了对模型在这些关键情况下表现的洞察。