Zookeeper基础
注册中心,配置中心,分布式协调中间件(决策者),让多个节点数据达成一致。
官网:https://zookeeper.apache.org/
常用客户端:PrettyZoo、zktools
zookeeper经典应用场景
- Naming service
- Configuration management
- Data synchronization
- Leader election
- Message queue
- Notification system
常用命令
bin/zkServer.sh status #查看zk状态
bin/zkServer.sh start #启动zk
bin/zkServer.sh stop #停止zk
bin/zkServer.sh restart #重启zk
bin/zkCli.sh -server 127.0.0.1:2181 #连接到zk启动zookeeper需要配置conf/zoo.cfg
tickTime=2000 #心跳过期时间ms
dataDir=/var/lib/zookeeper #数据存放目录
clientPort=2181 #客户端连接端口号
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888操作命令
create [-s] [-e] [-c] [-t ttl] path [data] [acl] #创建节点
set [-s] [-v version] path data #修改节点
delete [-v version] path #删除节点
deleteall path #删除节点及子节点
get [-s] [-w] path #获取节点下内容
stat [-w] path #查看节点状态-e表示临时节点:绑定会话周期,会话断开,节点会被删除
-s表示有序节点:生成节点带有有序编号(如seq-0000000001,seq-0000000002)
-c表示容器节点:容器节点的最后一个字节点被删除后,容器节点会被标注并在一段时间后被自动删除
-t表示ttl节点:ttl节点需要开启,可以指定节点过期时间,当节点在ttl时间内没有被修改并且没有子节点时会被删除
-w表示对此节点进行watch监听:-w创建一次性监听
zookeeper特性
zookeeper是一个树形结构的通过key-value存储文件的,key就是每个树形节点的全路径名,value就是当前节点的文件

节点类型
持久化节点
只要不删除,持久化保存在磁盘,默认创建的是持久化节点
临时节点
绑定在会话周期,会话断开,节点就会被删除;临时节点带有会话id:ephemeralOwner=xxxxxxxxxxxxxxxx
create -e /temp #通过-e创建临时节点有序节点
自动创建一个带有序号的节点(如seq-0000000001,seq-0000000002,seq-0000000003...),可以创建持久化有序和临时有序节点
create -s /seq/seq-容器节点
当容器节点的最后一个子节点被删除后,容器节点会被标注,并在一段时间后被删除
ttl节点
ttl节点只能针对持久化节点,并且需要开启,可以指定节点过期时间,当节点在ttl时间内没有被修改并且没有子节点时会被删除。
开启ttl功能:
(1) 在zkServer.sh文件中添加下面配置开启ttl功能:
![]()
"-Dzookeeper.extendedTypesEnabled=true"(2) 在zoo.cfg中配置[记得重启zkServer]
zookeeper.extendedTypesEnabled=true节点特性
- 同级目录下,不能存在名字相同的节点:基于此特性可实现分布式锁,可实现leader选举。多个节点抢占一个资源,那么可以让多个节点在同一个目录下创建临时有序节点,谁的序号最小,谁就可以获得锁,Leader选举同理。
- 临时节点不能存在子节点,容器节点正好可以解决这个问题
state状态
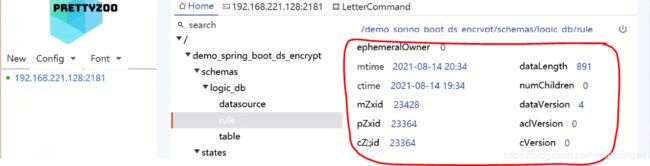
zxid
zxid是事务编号,长度为8字节的整型数,即64位的bit位,前32位标识epoch(代),后32位用来计数,每次操作加1.
zxid初始值为0,16进制0x0,二进制00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
每一次事务请求都会把后面32位的值 +1,比如10次事务请求,那么zxid会变成00000000 00000000 00000000 00000000 00000000 00000000 00000000 00001010,16进制表示为0xa
每进行一次leader选举,前32位的值 +1,并把后面32位清零,那么zxid会变成00000000 00000000 00000000 00000001 00000000 00000000 00000000 00000000,16进制表示为1x0
如果一直没有进性leader选举,但是一直发生事务请求,后面32位值一直累加,直到后32位全为1,即00000000 00000000 00000000 00000000 11111111 11111111 11111111 11111111,此时如果再有事务请求,则把前面32位的值 +1,同时后32位清零,即00000000 00000000 00000000 00000001 00000000 00000000 00000000 00000000
- cZxid:该数据节点被创建时的事务id
- mZxid:该节点最后一次被更新时的事务id
- pZxid:该节点的子节点列表最后一次被修改时的事务id,只有子节点列表变更时pZxid才会变,子节点内容变更不影响pZxid
- ctime:该节点被创建的时间
- mtime:该节点最后一次被更新的时间
- dataVersion:数据节点的版本号,节点数据每次变更,版本号递增。通过数据版本号来解决多线程下线程安全问题,这是一种乐观锁机制。
- cVersion:子节点的版本号
- aclVersion:节点的ACL版本号,访问权限控制
- dataLength:数据内容的长度
- numChildren:当前节点的字节点个数
- ephemeralOwner:区分持久化节点和临时节点,如果是持久化节点,值为0,如果是临时节点,则值为绑定的临时会话的sessionId
高级特性
watcher监听机制
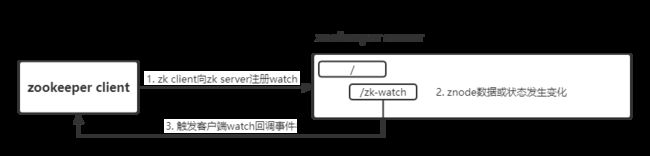
application监听中间件数据变化,有两种方式:pull、push,都需要拿到目标服务的IP:port实现连接;然后通过NIO / Netty维持会话长连接
zookeeper中对某个节点建立监听,有两种方式:一种是一次性监听,另一种是持久化监听
(1) 通过 -w 命令建立一次性监听
配置中心、注册中心、分布式锁、leader选举等都会用到watch机制
get [-s] [-w] path #监听是一次性的,只对ZNode节点数据的变化有效果
ls [-s] [-w] [-R] path #当前ZNode创建或删除,以及子节点创建或删除都会有效果
stat [-w] path #案例1
create /zk-watch data1 #创建节点/zk-watch并赋值data1
get -w /zk-watch #给节点/zk-watch添加一次性监听
set /zk-watch data2 #在任意一个zk客户端修改节点/zk-watch的值为data2
#可以发现第一个zkClient收到通知
WATCHER:: WatchedEvent state:SyncConnected type:NodeDataChanged path:/zk-watch
案例2
create /zk-watch/sub1 #创建子节点/sub1
get -w /zk-watch #给节点/zk-watch添加一次性监听
set /zk-watch/sub1 data1 #修改/zk-watch/sub1的数据为data1,发现没有任何watch,因为get只监听单个节点,对子节点无效
ls -w /zk-watch #通过ls添加对子节点增加和删除操作的监听
create /zk-watch/sub2 data2 #添加子节点/sub2并赋值data2,会发现触发了zk-watch上的监听事件
create /zk-watch/sub3 data3 #再次添加子节点/sub3,会发现不再收到通知,因为ls添加的监听也是一次性的
(2) 通过 addWatch 建立持久化监听
mode:[PERSISTENT, PERSISTENT_RECURSIVE],默认是PERSISTENT_RECURSIVE
PERSISTENT持久化监听,PERSISTENT_RECURSIVE持久化递归监听(子节点发生变动也会触发)
addWatch [-m mode] path监控zk-server
(1) The Four Letter Words
由四个字母组成的命令,可以通过telnet或ncat使用客户端向zkServer发送命令
修改zoo.cfg文件配置4lw:
1)打开zoo.cfg文件,添加一行配置:
4lw.commands.whitelist=*
echo "4lw.commands.whitelist=*" >> zoo.cfg
2)重启zkServer:
zkServer.sh start
使用 4lw 命令操作:
1)安装ncat:yum install -y nc
2)查看节点是否正常
echo ruok | ncat localhost 2181
3)查看节点相关配置
echo conf | ncat localhost 2181
4)查看节点状态
echo stat | ncat localhost 2181
5)查看server所有详细情况
echo srvr | ncat localhost 2181
6)查看临时节点
echo dump | ncat localhost 2181
7)查看watch
echo wchc | ncat localhost 2181
8)查看server的environment
echo envi | ncat localhost 2181
9)查看snapshot快照和log文件的总大小
echo dirs | ncat localhost 2181
(2) AdminServer
AdminServer是一个内嵌了Jetty 的服务接口,提供http接口去访问 4lw 命令,可以通过网页路径访问监控zk-server,默认server 启动端口是8080,访问 4lw 命令通过如下路径: http://localhost:8080/commands/stat
(3) JMX
Java Management Extensions
1)在zkServer.sh配置JMX
ZOOMAIN="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=8888
-Dcom.sun.management.jmxremote.authenticate=false -
Dcom.sun.management.jmxremote.ssl=false
-Djava.rmi.server.hostname=192.168.0.8
-Dcom.sun.management.jmxremote.local.only=false
org.apache.zookeeper.server.quorum.QuorumPeerMain"2)重启zkServer
zkServer.sh restart3)查看8888端口监听
lsof -i:88884)打开本地 jconsole, 连接指定JMX的ip和port: 192.168.1.8:8888
zookeeper的ACL权限
查询到的ACL权限规则:scheme:expression, perms
设置ACL权限规则:scheme:id:perms
scheme(权限模式)
- world:默认所有人可以访问全部权限(cdrwa),格式为 world:anyone:permission
- auth:认证授权,对应注册的用户需要拥有权限才可以访问,格式为 auth:user:password:permission
- digest:加密认证授权, 格式为 digest:username:BASE64(password):permission
- ip:指定某些IP或IP段可以访问, 格式为 ip:localhost:permission
- super:表示超管,拥有所有权限
id(授权对象)
针对权限模式,设置的对应授权对象,如果权限模式是auth,那么就是username:password,如果权限模式是ip,那么这里就是配置的ip或者ip段
perm(授予的权限)
cdrwa:create、delete、read、write、admin(允许对本节点进行ACL操作)
- CREATE: you can create a child node
- READ: you can get data from a node and list its children.
- WRITE: you can set data for a node
- DELETE: you can delete a child node
- ADMIN: you can set permissions
创建的节点默认schema是world,默认所有人拥有cdrwa权限:

ACL操作命令
getAcl [-s] path
# setAcl /user world:anyone:cdrw
setAcl [-s] [-v version] [-R] path acl
# addauth digest root:root
# setAcl /user auth:root:cdrw
addauth scheme auth案例
#创建节点并查看权限
create /zk-acl data1
getAcl /zk-acl
#设置用户user1对节点/zk-acl的访问权限
addauth digest user1:123456 #先在zk中注册用户user1
setAcl /zk-acl auth:user1:123456:cdrwa
#这样一来,对/zk-acl节点的操作就需要先登录,打开其他客户端,执行如下命令,会提示:Insufficient permission : /zk-acl
ls /zk-acl
get /zk-acl
#其他客户端访问此节点,需要另外注册用户并授权
addauth digest user1:123456
get /zk-acl
Java操作ACL权限
curatorFramework = CuratorFrameworkFactory.builder()
.connectString("192.168.221.128:2181,192.168.221.129:2181")
.connectionTimeoutMs(2000)
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.authorization("digest", "root:root".getBytes()) //授权
.sessionTimeoutMs(20000)
.build();
curatorFramework.start();//启动
public void aclOperation() throws Exception {
Id id = new Id("digest", DigestAuthenticationProvider.generateDigest("root:root"));
List acls = new ArrayList<>();
acls.add(new ACL(ZooDefs.Perms.CREATE, id));
acls.add(new ACL(ZooDefs.Perms.READ, id));
acls.add(new ACL(ZooDefs.Perms.WRITE, id));
acls.add(new ACL(ZooDefs.Perms.DELETE, id));
String nodePath = curatorFramework.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).withACL(acls).forPath("/user", "Lucifer".getBytes());
System.out.println("创建节点" + nodePath + "成功");
} 序列化和反序列化
在zookeeper中使用jute对数据进行网络传输,将java对象序列化转换成二进制存储在磁盘,或者将磁盘二进制文件反序列化转换为java对象
需要序列化反序列化的java类必须实现Record接口,底层是使用DataInput和DataOuput.

1)引入依赖
org.apache.zookeeper
zookeeper
3.7.1
org.projectlombok
lombok
1.18.24
2)定义java类实现Record接口
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Person implements Record {
private String username;
private Integer age;
@Override
public void serialize(OutputArchive archive, String tag) throws IOException {
archive.startRecord(this, tag);
archive.writeString(username, "username");
archive.writeInt(age, "age");
archive.endRecord(this, tag);
}
@Override
public void deserialize(InputArchive archive, String tag) throws IOException {
archive.startRecord(tag);
username = archive.readString("username");
age = archive.readInt("age");
archive.endRecord(tag);
}
public static void main(String[] args) throws IOException {
// 序列化
ByteArrayOutputStream byteArrayOutputStream = new
ByteArrayOutputStream();
BinaryOutputArchive binaryOutputArchive =
BinaryOutputArchive.getArchive(byteArrayOutputStream);
new Person("Jack", 16).serialize(binaryOutputArchive, "person");
ByteBuffer byteBuffer = ByteBuffer.wrap(byteArrayOutputStream.toByteArray());
// 反序列化
ByteBufferInputStream byteBufferInputStream = new ByteBufferInputStream(byteBuffer);
BinaryInputArchive binaryInputArchive = BinaryInputArchive.getArchive(byteBufferInputStream);
Person person = new Person();
person.deserialize(binaryInputArchive, "person");
System.out.println(person.toString());
// 关闭资源
byteArrayOutputStream.close();
byteBufferInputStream.close();
}
}
快照数据和事务日志
快照数据
记录某一时刻所有ZNode节点及数据的快照,全量的序列化到磁盘中进行保存,保存在zoo.cfg中配置的dataDir目录下的version-num中,快照文件格式为snapshot.zxid
事务日志数据
记录每一次事务操作的记录,保存在dataDir路径 + version-num下,格式为log.zxid
查看快照数据和日志数据
zkSnapShotToolkit.sh snapshot.zxid
zkTxnLogToolkit.sh log.zxid文件什么时候创建?
zkServer第一次启动
zkServer第一次启动时,此时zxid值为0,会生成一个snapshot.0 的数据快照文件,对应的zookeeper源码为FileTnxSnapLog#save方法。
快照文件不会预分配空间,而是取决于内存DataTree的大小。
snapLog.serialize(dataTree, sessionsWithTimeouts, snapshotFile, syncSnap);
new SnapshotInfo(Util.getZxidFromName(snapShot.getName(),
SNAPSHOT_FILE_PREFIX),snapShot.lastModified() / 1000)第一次创建事务日志文件
当使用zkClient(如prettyZoo)去连接zkServer时,会生成一个log.1的事务日志文件,对应的zookeeper源码是FileTxnLog#append方法。
日志文件会进行预分配空间,默认是64M大小,在源码中是FilePadding#preAllocaSize = 65536 * 1024 Byte = 64M,也就是说每一个事务日志文件一创建默认大小就是64M。
如果事务日志文件的空间剩余不足4KB时,则会再次预分配64M磁盘空间。
snapshot是全量,log文件是增量
何时新建快照文件和日志文件?
- 每一次重启zkServer,如果重启之前有zxid的变化(有事务操作),会创建一个新的快照文件;
- 重启之后如果有事务操作,也会触发新建一个事务日志文件。
如果一直没有重启zkServer,每进行一次事务操作,事务日志中都会新增一条记录,并且zxid会+1,当经过snapCount的过半随机次数(5W - 10W)的事务写入之后,就会触发新建一个快照文件,同时也会新建一个事务日志文件。
具体源码见SyncRequestProcessor#shouldSnapshot()方法
private boolean shouldSnapshot() {
int logCount = zks.getZKDatabase().getTxnCount();
long logSize = zks.getZKDatabase().getTxnSize();
return (logCount > (snapCount / 2 + randRoll)) || (snapSizeInBytes > 0 && logSize > (snapSizeInBytes / 2 + randSize));
}
注意:如果光重启,没有任何事务操作,只生成snapshot文件;如果重启后有事务操作,会生成新的snapshot文件和log文件。
快照文件和日志文件的清理
QuorumPeerConfig中有默认配置
purgeInterval=0 触发自动清理的时间间隔,单位是小时,默认值为0,表示不开启自动清理的功能
snapRetainCount=3 自动清理保留3个事务日志和快照数据
客户端连接
centos7.x
通过zkCli.sh连接
zkCli.sh # 默认连接本机的2181端口
zkCli.sh -server 127.0.0.1:2181 # 指定zk serverzookeeper源码
找到zkCli.cmd,发现客户端是通过ZookeeperMain运行的

prettyZoo
web图形化界面zkui
github:https://github.com/DeemOpen/zkui
- 来到zk-server所在机器
- 下载源码:git clone https://github.com/DeemOpen/zkui
- mvn clean install
- 复制config.cfg到jar包所在目录: target
- 打开配置文件,配置zkServer=zkServer=192.168.0.8:2181
- zkui默认端口在9090: serverPort=9090
- 运行jar包: java -jar zkui-2.0-SNAPSHOT-jar-with-dependencies.jar
- 访问地址: localhost:9090
- 默认用户名密码:admin manager,可以通过userSet修改

Curator - 基于java操作Zookeeper
java操作zookeeper,一般要么通过zookeeper原生api,但是比较复杂,所以有了zkClient和Curator对zookeeper API进行了封装,简化了原生API的复杂操作
org.apache.curator
curator-recipes
5.2.0
常用CRUD操作
/**
* 建立连接(session)
* CRUD操作
* 基于zk特性提供解决方案的封装
*/
public class CuratorDemo {
private final CuratorFramework curatorFramework;
public CuratorDemo() {
curatorFramework = CuratorFrameworkFactory.builder()
.connectString("192.168.221.128:2181,192.168.221.129:2181")
.connectionTimeoutMs(2000)
/**
* ExponentialBackoffRetry指数衰减重试:
* baseSleepTimeMs * Math.max(1, this.random.nextInt(1 << retryCount + 1))
* RetryNTimes:重试N次
* RetryOneTime:重试一次
* RetryUntilElapsed:重试直到达到规定时间
*/
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.sessionTimeoutMs(20000)
.build();
curatorFramework.start();//启动
}
public void nodeCRUD() throws Exception {
// 创建持久化节点,如果父节点不存在则创建
String node = curatorFramework.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).forPath("/user", "Lucifer".getBytes());
Stat stat = new Stat(); //存储状态信息的对象
byte[] bytes = curatorFramework.getData().storingStatIn(stat).forPath(node);
System.out.println(new String(bytes));
// 更新数据时携带版本号,乐观锁机制保证数据一致性
stat = curatorFramework.setData().withVersion(1).forPath("/user", "Lucifer1".getBytes());
curatorFramework.delete().forPath(node);
Stat stat1 = curatorFramework.checkExists().forPath(node);
if (stat1 == null) {
System.out.println("节点" + node + "删除成功");
}
}
// 通过inBackground方法实现异步执行
public void asyncCRUD() throws Exception {
CountDownLatch countDownLatch = new CountDownLatch(1);
String path = curatorFramework.create().withMode(CreateMode.PERSISTENT).inBackground((curatorFramework, event) -> {
countDownLatch.countDown(); //通过countDownLatch保证异步回调创建成功
}).forPath("/async-node", "hello".getBytes());
countDownLatch.await();
}
}基于curator实现watch
普通监听
public void normalWatcher() throws Exception {
CuratorWatcher curatorWatcher = new CuratorWatcher() {
@Override
public void process(WatchedEvent watchedEvent) throws Exception {
System.out.println("监听到的事件" + watchedEvent.toString());
//设置循环监听
curatorFramework.checkExists().usingWatcher(this).forPath(watchedEvent.getPath());
}
};
String nodePath = curatorFramework.create().forPath("/user", "Tom".getBytes());
byte[] bytes = curatorFramework.getData().usingWatcher(curatorWatcher).forPath(nodePath);
System.out.println("设置监听节点并获取到数据:" + new String(bytes));
}持久化监听
public void persistentWatcher() {
// 创建节点 curator-watch-persistent
String nodePath = curatorFramework.create().forPath("/curator-watch-persistent", "Lucifer".getBytes());
// 设置永久监听
CuratorCache curatorCache = CuratorCache.build(curatorFramework, nodePath, CuratorCache.Options.SINGLE_NODE_CACHE);
CuratorCacheListener listener = CuratorCacheListener.builder().forAll(new CuratorCacheListener() {
@Override
public void event(Type type, ChildData oldData, ChildData data) {
System.out.println("监听到事件类型:" + type + ",旧数据:" + oldData + ",新数据:" + data);
}
}).build();
curatorCache.listenable().addListener(listener);
curatorCache.start();
// 让当前进程不结束
System.in.read();
}