时间序列框架-Darts-用户指南(上)
你可以在这里找到更多关于Darts的详细信息。
注:用户指南尚未完成,仍在建设中。
时间序列
多变量时间序列 VS. 多个时间序列
我们区分单变量和多变量序列:
- Multivariate 包含多个维度(即每个时间步有多个值)。
- univariate只包含一个维度(即每个时间步的单个标量值)。
有时维度被称为分量。单个TimeSeries对象可以是单变量(如果它有一个组件),也可以是多变量(如果它有多个组件)。在多变量时间序列中,所有分量共享同一时间轴。也就是说,它们都共享相同的时间戳。
Darts中的一些模型(以及所有机器学习模型)支持多元序列。这意味着它们可以将多元序列作为输入(作为目标或协变量),它们产生的预测将具有与目标匹配的维度。
此外,一些模型可以在多个时间序列上工作,这意味着它们可以在多个TimeSeries对象上进行训练,并用于一次性预测多个TimeSeries对象。这有时被称为面板数据。在这种情况下,不同的TimeSeries不需要共享相同的时间索引—例如,一些系列可能在1990年,而其他系列在2000年。事实上,这些级数甚至不需要有相同的频率。处理多个系列的模型期望输入中的Python TimeSeries序列(例如,一个简单的TimeSeries列表)。
- 多变量序列例子:单个患者在一段时间内的血压和心率(一个多变量系列有两个组成部分)。
- 多个序列的例子:多个患者的血压和心率;可能在不同的时间对不同的患者进行测量(每个患者一个单变量序列)。
我应该用多元级数还是多元级数?
使用多变量序列将为模型提供联合捕捉维度的机会,而使用多个序列将使模型暴露于多种观察。因此,哪个表述是正确的取决于问题,在某些情况下甚至可能事先不清楚,需要实验。然而,如果你在一个情况下,你试图建模几个相关的组件一起随时间变化(例如,一个移动物体的坐标,或多个测量与一个单一实体),通常是很自然地捕获那些为单个系列中的多个组件。另一方面,如果您有多个这样的测量实例(例如,在不同的实验或观察中获得),这可能意味着您有多个时间序列。此外,如果您的值不共享相同的时间跨度,它们可能应该表示为不同的系列。
Probabilistic and deterministic series
在dart中,概率预测通过从潜在的概率模型中抽取蒙特卡洛样本来表示。这种表示允许TimeSeries表示任意联合分布(随时间和组件变化),而不需要依赖任何预定义的参数形式。在此基础上,我们定义了两类时间序列:
- 一个概率(或随机)序列包含多个样本。
- 确定性序列只包含一个样本。
构建时间序列
TimeSeries对象可以使用工厂方法创建,例如:
- TimeSeries.from_dataframe()可以从具有一个或多个列表示值的Pandas Dataframe创建TimeSeries(多个列将对应一个多元序列)。
- TimeSeries.from_values()可以从2-D或3-D NumPy数组创建TimeSeries。它将生成一个基于整数的时间索引(类型为panda . rangeindex)。二维对应确定性(可能是多元的)级数,三维对应随机级数。
- TimeSeries.from_times_and_values()类似于TimeSeries.from_values(),但也接受时间索引。
此外,还可以使用concatenate()函数沿着不同的轴连接序列。轴=0对应时间,轴=1对应分量,轴=2对应随机样本维数。例如:
from dart import concatenate
my_multivariate_series = concatenate([series1, series2, ...], axis=1)
从具有相同时间轴的某个级数产生一个多元序列。
Implementation
TimeSeries围绕着一个三维xarray.DataArray 对象。维度为(时间、分量、样本),其中多元序列的分量维度大于1,随机序列的样本维度大于1。DataArray本身由一个三维NumPy数组支持,它有一个时间索引(either pandas.DatetimeIndex or pandas.RangeIndex)的时间维度和另一个pandas。在组件(或“列”)维度上建立索引。TimeSeries是不可变的。
从TimeSeries导出数据
TimeSeries objects offer a few ways to export the data, for example:
- TimeSeries.pd_dataframe() to export a Pandas Dataframe (for
deterministic series) - TimeSeries.data_array() to export the xarray DataArray holding this
series’ data (and indexes). - TimeSeries.values() to export a NumPy array contaning the values of
one sample from the series. - TimeSeries.all_values() to export a NumPy array contaning the values
of all samples of a stochastic series.
静态协变量
TimeSeries对象可以包含静态数据(称为静态协变量),这可以被一些模型利用。静态协变量的例子可以是:
- 存储位置——例如多变量系列中的每个存储(组件)
- Product ID
- Sensor type
- …
静态协变量必须由一个pandas DataFrame指定,它的行匹配TimeSeries的组件,它的列表示静态协变量的维度。在使用大多数工厂方法时,可以使用static_covariates参数将它们添加到TimeSeries。还可以使用with_static_covariates()方法将它们添加到现有的TimeSeries中。
分层时间序列
可选地,TimeSeries对象可以包含层次结构,该层次结构指定如何将其不同的组件组合在一起。层次结构本身被指定为一个Python字典,将组件的名称映射到该层次结构中父组件的名称列表。
例如,下面的层次结构意味着两个组件“a”和“b”加起来等于“total”:
hierarchy = {"a": ["total"], "b", ["total"]}
层次结构可用于事后预测的调和。dart提供了几种协调转换器(可与fit()/transform()一起使用)—请参阅相应的API文档。
回归预测模型
预测模型是指根据某个时间序列的历史,可以对该序列的未来值做出预测的模型。dart中的预测模型在README中列出。它们具有不同的功能和特性。例如,一些模型处理多维序列,返回概率预测,或接受其他类型的外部协变量数据作为输入。
下面,我们将概述这些特性的含义。
概述
所有预测模型都以相同的方式工作:首先构建它们(在参数中接受一些超参数),然后通过调用fit()函数将它们适合于一个或几个序列,最后通过调用predict()函数来获得一个或几个预测。
Example:
from darts.models import NaiveSeasonal
naive_model = NaiveSeasonal(K=1) # init
naive_model.fit(train) # fit
naive_forecast = naive_model.predict(n=36) # predict
predict()的参数n表示要预测的时间戳数量。如果fit()只提供一个训练TimeSeries,并存储该系列,而predict()将返回该系列的预测。另一方面,一些模型支持对多个时间序列(Sequence[TimeSeries])调用fit()。在这种情况下,必须为predict()提供一个或多个序列,该模型将对这个/这些时间序列进行预测。
Example:
from darts.models import NBEATSModel
model = NBEATSModel(input_chunk_length=24, # init
output_chunk_length=12)
model.fit([series1, series2]) # fit on two series
forecast = model.predict(series=[series3, series4], n=36) # predict potentially different series
此外,我们定义了以下类型的时间序列由模型完成:
- Target series: the series that we are interested in forecasting.
- Covariate series: some other series that we are not interested in forecasting, but that can provide valuable inputs to the forecasting model.
支持多变量序列
一些模型支持多元时间序列。这意味着拟合和预测阶段提供给模型的目标(和潜在协变量)序列可以具有多个维度。然后,该模型将反过来产生多元预测。
下面是一个例子,使用卡尔曼预测器来预测一个由两个组成部分组成的单一多元系列:
import darts.utils.timeseries_generation as tg
from darts.models import KalmanForecaster
import matplotlib.pyplot as plt
series1 = tg.sine_timeseries(value_frequency=0.05, length=100) + 0.1 * tg.gaussian_timeseries(length=100)
series2 = tg.sine_timeseries(value_frequency=0.02, length=100) + 0.2 * tg.gaussian_timeseries(length=100)
multivariate_series = series1.stack(series2)
model = KalmanForecaster(dim_x=4)
model.fit(multivariate_series)
pred = model.predict(n=50, num_samples=100)
plt.figure(figsize=(8,6))
multivariate_series.plot(lw=3)
pred.plot(lw=3, label='forecast')
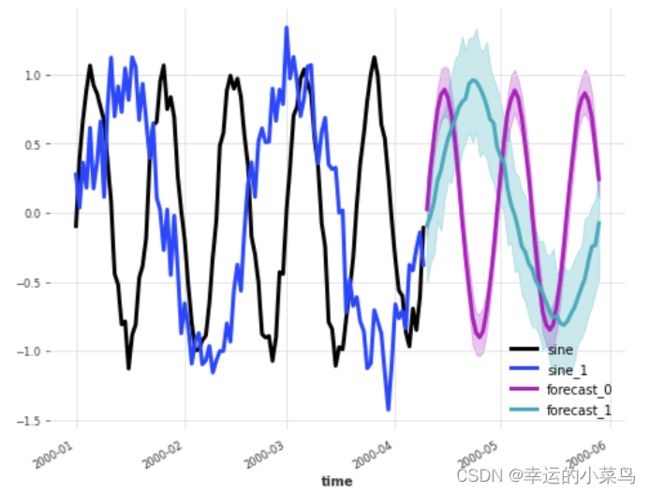 这些模型在模型列表的多元列下显示为“✅”。
这些模型在模型列表的多元列下显示为“✅”。
处理多个时间序列
一些模型支持适用于多个时间序列。为此,只需提供一个Python TimeSeries序列(例如一个TimeSeries列表)来fit()就足够了。当模型适合这种方式时,predict()函数将期望设置参数序列,其中包含一个或多个需要预测的TimeSeries(即单个或一系列TimeSeries)。在多个系列上进行训练的优点是,单个模型可以暴露于训练数据集中所有系列中出现的更多模式。这通常是有益的,特别是对于基于表达的模型。
反过来,让predict()同时为可能的多个序列提供预测的好处是,计算通常可以对多个序列进行批处理和向量化,这比在孤立的序列上多次调用predict()要快得多。
这些模型在模型列表的Multiple-series training列下以“✅”显示。
支持协变量
一些模型支持协变量序列。协变量序列是模型可以作为输入但不能预测的时间序列。我们区分过去协变量和未来协变量:
- 过去协变量是协变量时间序列,其值在预测时对未来是未知的。例如,这些可以代表信号,必须测量,但不知道提前。模型在进行预测时不使用
past_covariates的未来值。 - 未来协变量是协变量时间序列,其值在未来的预测时间(直到预测地平线)是已知的。它们可以表示诸如日历信息、假期、天气预报等信号。接受
future_covariates的模型在进行预测时将使用未来值(直到预测视界)。
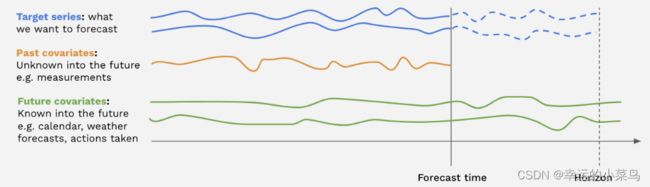
过去和未来的协变量可以通过分别为fit()和predict()提供past_covariates和future_covariates参数来使用。当一个模型在多个目标序列上训练时,每个目标序列必须提供一个协变量。协变量序列本身可以是多元的,并且包含多个“协变量维度”;请参阅TimeSeries指南了解如何构建多元序列。
没有必要担心协变量序列具有准确的时间跨度(例如,使未来协变量的最后一个时间戳与预测的范围匹配)。dart基于目标的时间轴和协变量的时间轴,负责对幕后的协变量进行切片。
支持过去的模型(对应。未来)协变量在过去观察协变量支持下用“✅”表示(对应。未来已知协变量支持)列在模型列表中,
概率预测
dart中的一些模型可以产生概率预测。对于这些模型,predict()返回的TimeSeries将是概率的,并且包含一定数量的蒙特卡洛样本,描述随时间和分量的联合分布。样本的数量可以由predict()函数的参数num_samples直接确定(让num_samples=1将返回一个确定的TimeSeries)。
支持概率预测的模型在模型列表的概率栏中用“✅”表示。预测的实际概率分布取决于模型。
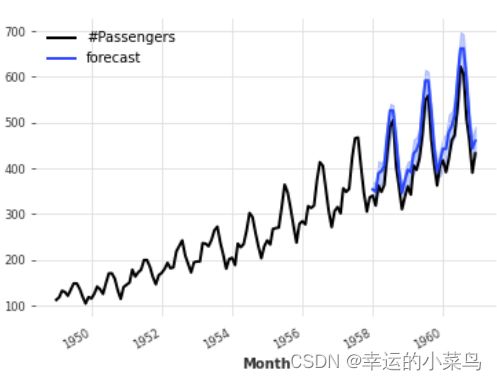
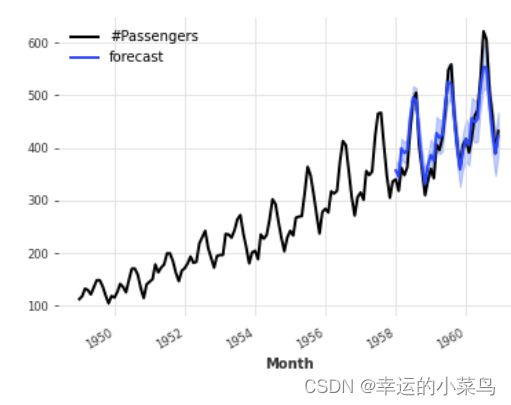
一些模型,如ARIMA,指数平滑,(T)BATS或KalmanForecaster作出正态假设,得到的分布是一个具有时变参数的高斯分布。例如:
from darts.datasets import AirPassengersDataset
from darts import TimeSeries
from darts.models import ExponentialSmoothing
series = AirPassengersDataset().load()
train, val = series[:-36], series[-36:]
model = ExponentialSmoothing()
model.fit(train)
pred = model.predict(n=36, num_samples=500)
series.plot()
pred.plot(label='forecast')
概率神经网络
译文:
dart中的所有神经网络(基于torch的模型)都为估计不同类型的概率分布提供了丰富的支持。在创建模型时,可以提供darts.utils.likelihood_models中可用的可能性模型之一。似然模型,它决定由模型估计的分布。在这种情况下,模型将输出分布的参数,并通过最小化训练样本的负对数似然来进行训练。大多数似然模型也支持分布参数的先验值,在这种情况下,训练损失通过一个Kullback-Leibler散度项来正则化,将结果分布推向由先验参数指定的分布方向。该正则化项的强度也可以在创建似然模型对象时指定。
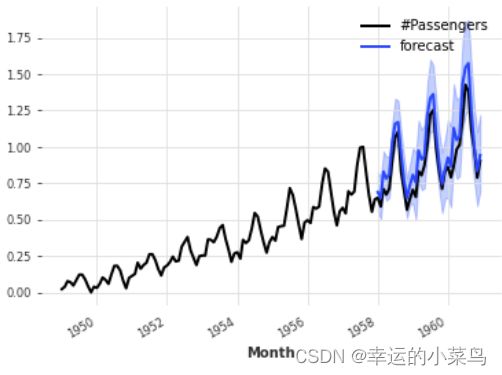
例如,下面的代码训练一个TCNModel来拟合拉普拉斯分布。 因此,神经网络输出拉普拉斯分布的2个参数(位置和尺度)。 我们还在scale参数上指定了0.1的先验值。
from darts.datasets import AirPassengersDataset
from darts import TimeSeries
from darts.models import TCNModel
from darts.dataprocessing.transformers import Scaler
from darts.utils.likelihood_models import LaplaceLikelihood
series = AirPassengersDataset().load()
train, val = series[:-36], series[-36:]
scaler = Scaler()
train = scaler.fit_transform(train)
val = scaler.transform(val)
series = scaler.transform(series)
model = TCNModel(input_chunk_length=30,
output_chunk_length=12,
likelihood=LaplaceLikelihood(prior_b=0.1))
model.fit(train, epochs=400)
pred = model.predict(n=36, num_samples=500)
series.plot()
pred.plot(label='forecast')
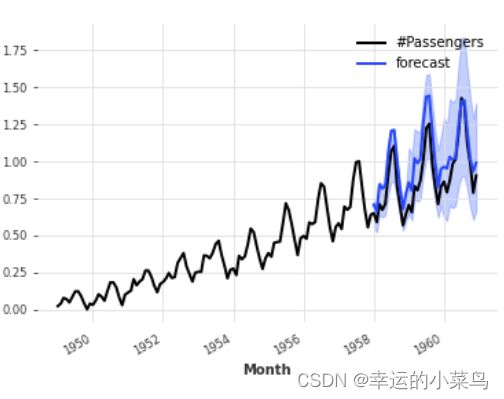
通过使用dartmouth .utils.likelihood . models,也可以使用神经网络执行分位数回归(使用任意的分位数)。量化回归,在这种情况下,网络将与pinball loss训练。这产生了一个经验的非参数分布,在实践中,当一个人不确定真实的分布,或者当拟合参数似然给出较差的结果时,它通常是一个很好的选择。例如,下面的代码片段几乎与前面的代码片段完全相同;唯一的区别是它现在使用的是QuantileRegression可能性,这意味着神经网络将用弹球损失进行训练,其输出数量将动态配置为匹配分位数的数量。
from darts.datasets import AirPassengersDataset
from darts import TimeSeries
from darts.models import TCNModel
from darts.dataprocessing.transformers import Scaler
from darts.utils.likelihood_models import QuantileRegression
series = AirPassengersDataset().load()
train, val = series[:-36], series[-36:]
scaler = Scaler()
train = scaler.fit_transform(train)
val = scaler.transform(val)
series = scaler.transform(series)
model = TCNModel(input_chunk_length=30,
output_chunk_length=12,
likelihood=QuantileRegression(quantiles=[0.01, 0.05, 0.2, 0.5, 0.8, 0.95, 0.99]))
model.fit(train, epochs=400)
pred = model.predict(n=36, num_samples=500)
series.plot()
pred.plot(label='forecast')
使用蒙特卡洛Dropout捕获模型的不确定性
在dart中,dropout还可以按照[1]中描述的方法作为捕获模型不确定性的另一种方法。这有时被称为认知的不确定性,可以被视为一种边缘化的方式,在一个由所有不同的退出激活函数代表的模型家族。
该特性对于集成了一些dropout的所有深度学习模型都是可用的(RNN模型除外——我们可以参考dropout API参考文档中提到的支持该特性的模型)。它只需要在预测时指定mc_dropout=True。例如,下面的代码训练一个TCN模型(使用默认的MSE损失),辍学率为10%,然后使用蒙特卡洛辍学率产生一个概率预测。
from darts.datasets import AirPassengersDataset
from darts import TimeSeries
from darts.models import TCNModel
from darts.dataprocessing.transformers import Scaler
from darts.utils.likelihood_models import QuantileRegression
series = AirPassengersDataset().load()
train, val = series[:-36], series[-36:]
scaler = Scaler()
train = scaler.fit_transform(train)
val = scaler.transform(val)
series = scaler.transform(series)
model = TCNModel(input_chunk_length=30,
output_chunk_length=12,
dropout=0.1)
model.fit(train, epochs=400)
pred = model.predict(n=36, mc_dropout=True, num_samples=500)
series.plot()
pred.plot(label='forecast')

蒙特卡洛Dropout可以结合其他似然估计,这可以解释为一种方法,以捕获认知和任意不确定性。
概率回归模型
一些回归模型也可以配置为产生概率预测。在撰写本文时,LinearRegressionModel和LightGBMModel支持似然论证。当设置为“泊松”时,模型将符合泊松分布,当设置为“Example:”时,模型将使用pinball loss 失来执行分位数回归(分位数本身可以使用quantiles参数指定)。
Example:
from darts.datasets import AirPassengersDataset
from darts import TimeSeries
from darts.models import LinearRegressionModel
series = AirPassengersDataset().load()
train, val = series[:-36], series[-36:]
model = LinearRegressionModel(lags=30,
likelihood="quantile",
quantiles=[0.05, 0.1, 0.25, 0.5, 0.75, 0.9, 0.95])
model.fit(train)
pred = model.predict(n=36, num_samples=500)
series.plot()
pred.plot(label='forecast')